 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
End-to-end deep learning for directly estimating grape yield from ground-based imagery
Aug 04, 2022
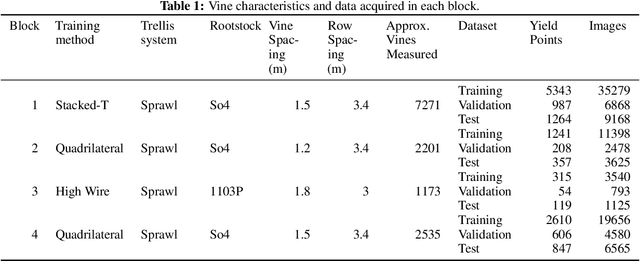
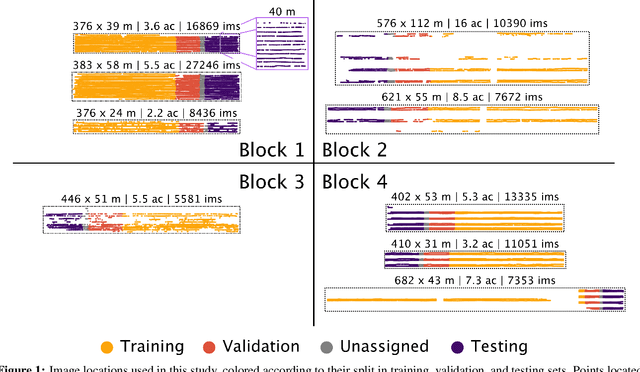
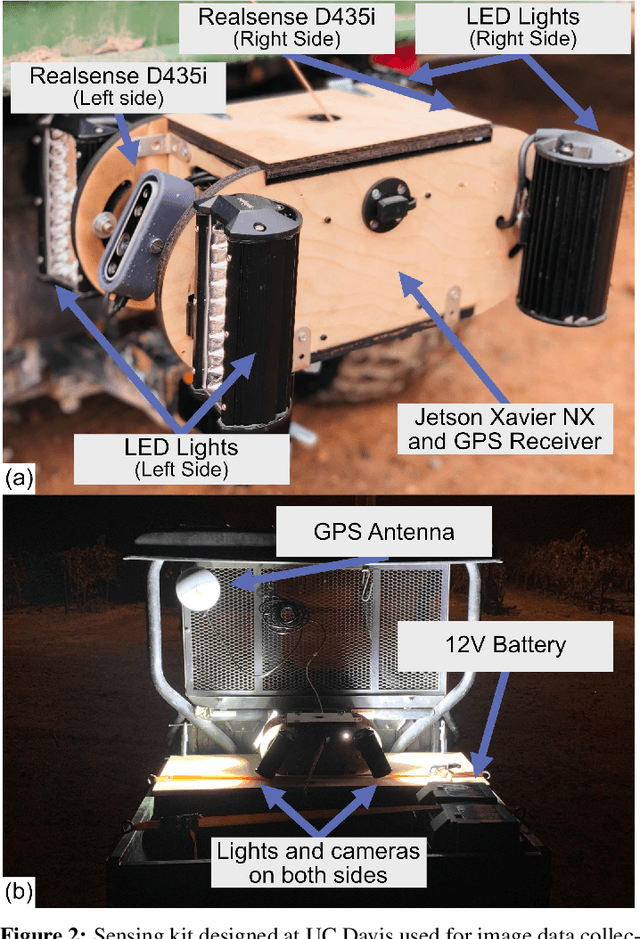
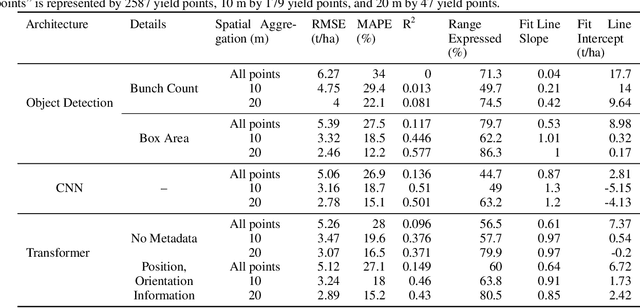
Yield estimation is a powerful tool in vineyard management, as it allows growers to fine-tune practices to optimize yield and quality. However, yield estimation is currently performed using manual sampling, which is time-consuming and imprecise. This study demonstrates the application of proximal imaging combined with deep learning for yield estimation in vineyards. Continuous data collection using a vehicle-mounted sensing kit combined with collection of ground truth yield data at harvest using a commercial yield monitor allowed for the generation of a large dataset of 23,581 yield points and 107,933 images. Moreover, this study was conducted in a mechanically managed commercial vineyard, representing a challenging environment for image analysis but a common set of conditions in the California Central Valley. Three model architectures were tested: object detection, CNN regression, and transformer models. The object detection model was trained on hand-labeled images to localize grape bunches, and either bunch count or pixel area was summed to correlate with grape yield. Conversely, regression models were trained end-to-end to predict grape yield from image data without the need for hand labeling. Results demonstrated that both a transformer as well as the object detection model with pixel area processing performed comparably, with a mean absolute percent error of 18% and 18.5%, respectively on a representative holdout dataset. Saliency mapping was used to demonstrate the attention of the CNN model was localized near the predicted location of grape bunches, as well as on the top of the grapevine canopy. Overall, the study showed the applicability of proximal imaging and deep learning for prediction of grapevine yield on a large scale. Additionally, the end-to-end modeling approach was able to perform comparably to the object detection approach while eliminating the need for hand-labeling.
DeVIS: Making Deformable Transformers Work for Video Instance Segmentation
Jul 22, 2022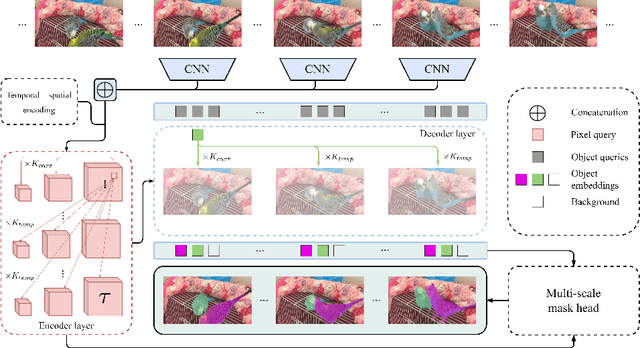
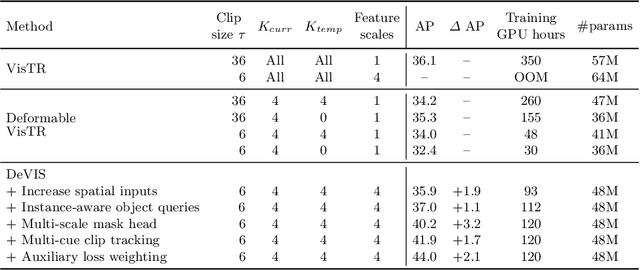
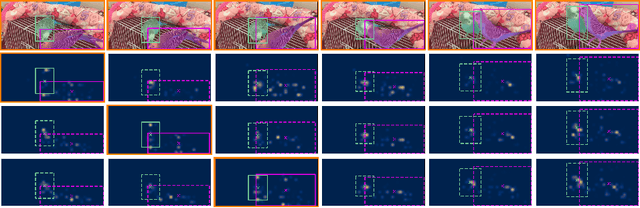
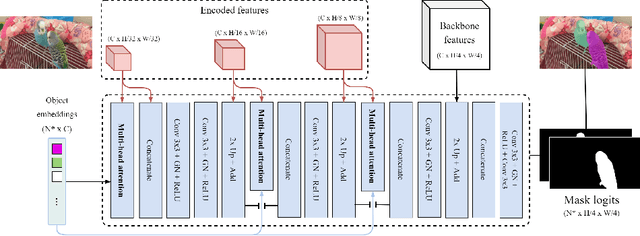
Video Instance Segmentation (VIS) jointly tackles multi-object detection, tracking, and segmentation in video sequences. In the past, VIS methods mirrored the fragmentation of these subtasks in their architectural design, hence missing out on a joint solution. Transformers recently allowed to cast the entire VIS task as a single set-prediction problem. Nevertheless, the quadratic complexity of existing Transformer-based methods requires long training times, high memory requirements, and processing of low-single-scale feature maps. Deformable attention provides a more efficient alternative but its application to the temporal domain or the segmentation task have not yet been explored. In this work, we present Deformable VIS (DeVIS), a VIS method which capitalizes on the efficiency and performance of deformable Transformers. To reason about all VIS subtasks jointly over multiple frames, we present temporal multi-scale deformable attention with instance-aware object queries. We further introduce a new image and video instance mask head with multi-scale features, and perform near-online video processing with multi-cue clip tracking. DeVIS reduces memory as well as training time requirements, and achieves state-of-the-art results on the YouTube-VIS 2021, as well as the challenging OVIS dataset. Code is available at https://github.com/acaelles97/DeVIS.
Power Transformer Fault Diagnosis with Intrinsic Time-scale Decomposition and XGBoost Classifier
Oct 21, 2021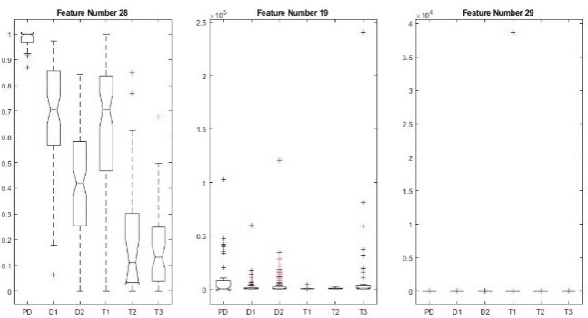
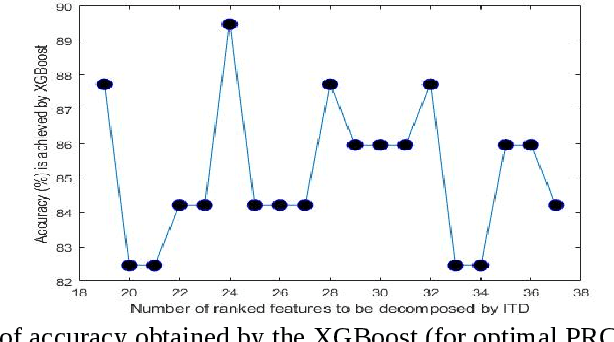
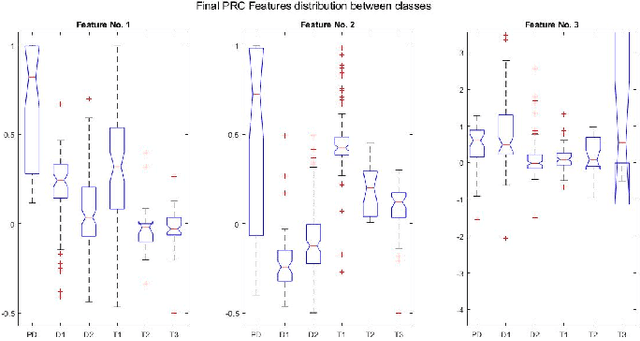
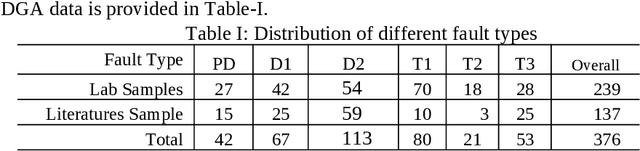
An intrinsic time-scale decomposition (ITD) based method for power transformer fault diagnosis is proposed. Dissolved gas analysis (DGA) parameters are ranked according to their skewness, and then ITD based features extraction is performed. An optimal set of PRC features are determined by an XGBoost classifier. For classification purpose, an XGBoost classifier is used to the optimal PRC features set. The proposed method's performance in classification is studied using publicly available DGA data of 376 power transformers and employing an XGBoost classifier. The Proposed method achieves more than 95% accuracy and high sensitivity and F1-score, better than conventional methods and some recent machine learning-based fault diagnosis approaches. Moreover, it gives better Cohen Kappa and F1-score as compared to the recently introduced EMD-based hierarchical technique for fault diagnosis in power transformers.
CVR-LSE: Compact Vectorization Representation of Local Static Environments for Unmanned Ground Vehicles
Jun 14, 2022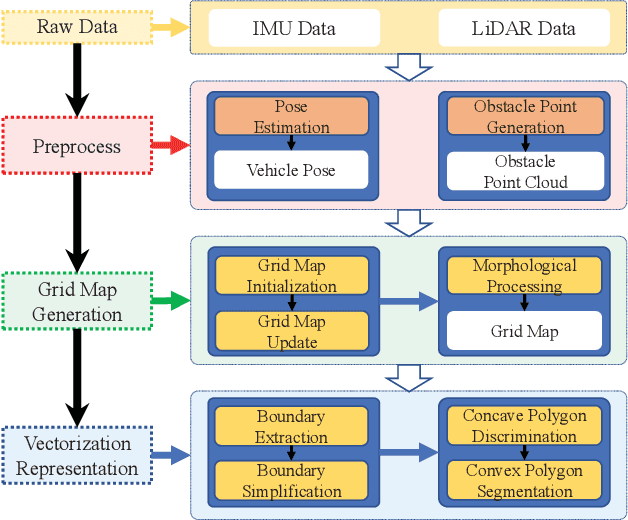
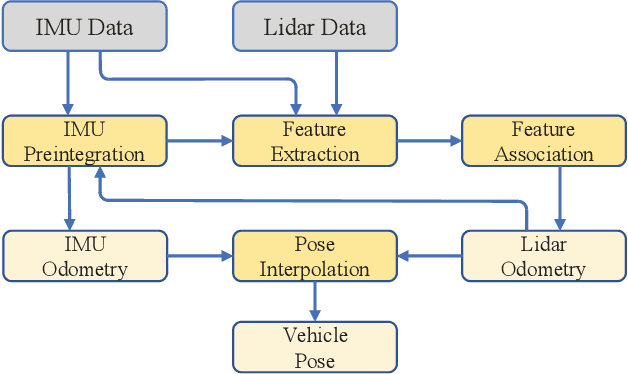
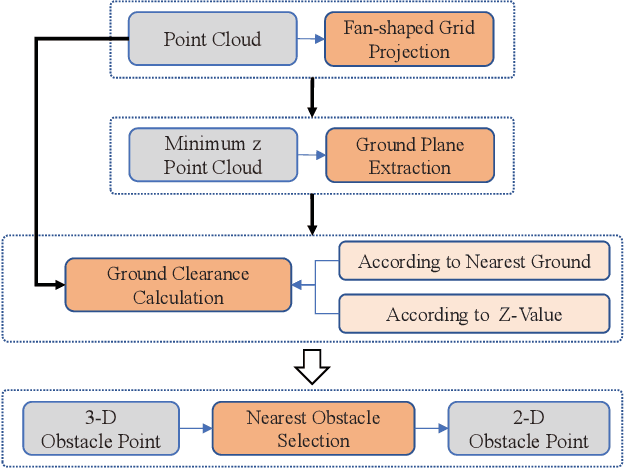
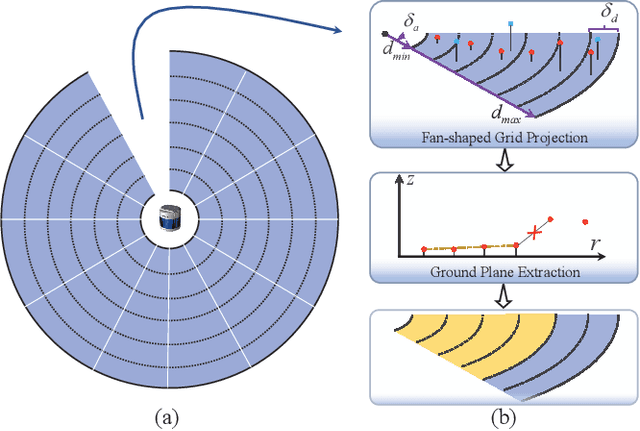
According to the requirement of general static obstacle detection, this paper proposes a compact vectorization representation approach of local static environments for unmanned ground vehicles. At first, by fusing the data of LiDAR and IMU, high-frequency pose information is obtained. Then, through the two-dimensional (2D) obstacle points generation, the process of grid map maintenance with a fixed size is proposed. Finally, the local static environment is described via multiple convex polygons, which is realized throungh the double threshold-based boundary simplification and the convex polygon segmentation. Our proposed approach has been applied in a practical driverless project in the park, and the qualitative experimental results on typical scenes verify the effectiveness and robustness. In addition, the quantitative evaluation shows the superior performance on making use of fewer number of points information (decreased by about 60%) to represent the local static environment compared with the traditional grid map-based methods. Furthermore, the performance of running time (15ms) shows that the proposed approach can be used for real-time local static environment perception. The corresponding code can be accessed at https://github.com/ghm0819/cvr_lse.
Lightweight Automated Feature Monitoring for Data Streams
Jul 19, 2022
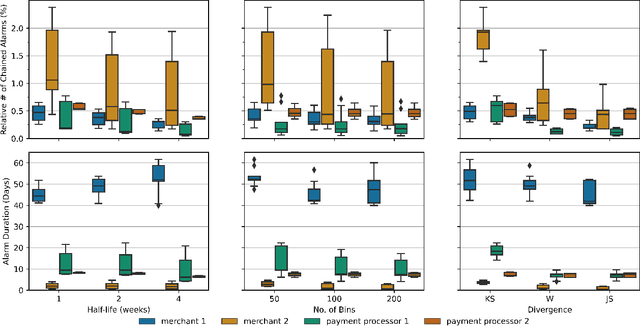
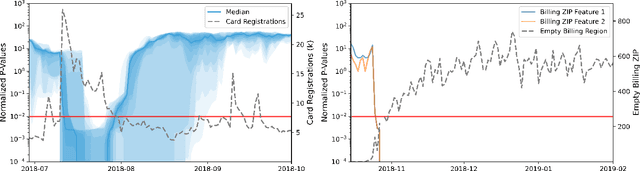
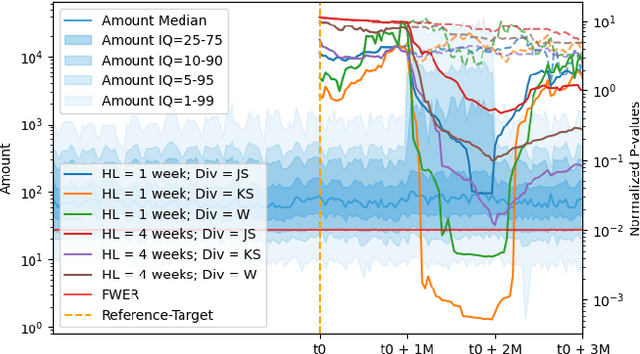
Monitoring the behavior of automated real-time stream processing systems has become one of the most relevant problems in real world applications. Such systems have grown in complexity relying heavily on high dimensional input data, and data hungry Machine Learning (ML) algorithms. We propose a flexible system, Feature Monitoring (FM), that detects data drifts in such data sets, with a small and constant memory footprint and a small computational cost in streaming applications. The method is based on a multi-variate statistical test and is data driven by design (full reference distributions are estimated from the data). It monitors all features that are used by the system, while providing an interpretable features ranking whenever an alarm occurs (to aid in root cause analysis). The computational and memory lightness of the system results from the use of Exponential Moving Histograms. In our experimental study, we analyze the system's behavior with its parameters and, more importantly, show examples where it detects problems that are not directly related to a single feature. This illustrates how FM eliminates the need to add custom signals to detect specific types of problems and that monitoring the available space of features is often enough.
Predicting the Output Structure of Sparse Matrix Multiplication with Sampled Compression Ratio
Jul 28, 2022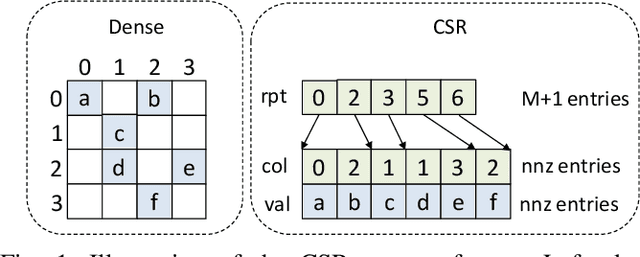
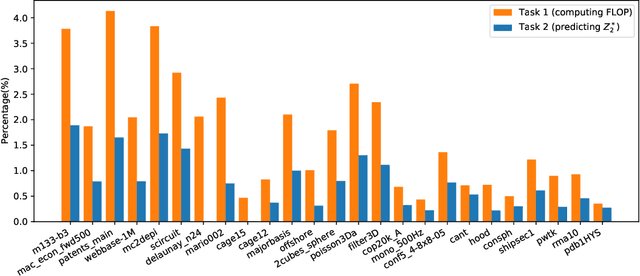
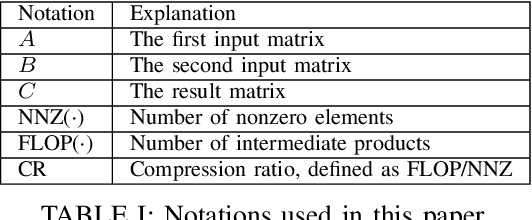
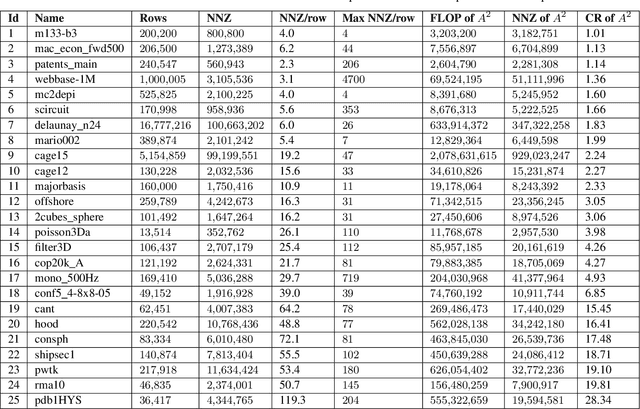
Sparse general matrix multiplication (SpGEMM) is a fundamental building block in numerous scientific applications. One critical task of SpGEMM is to compute or predict the structure of the output matrix (i.e., the number of nonzero elements per output row) for efficient memory allocation and load balance, which impact the overall performance of SpGEMM. Existing work either precisely calculates the output structure or adopts upper-bound or sampling-based methods to predict the output structure. However, these methods either take much execution time or are not accurate enough. In this paper, we propose a novel sampling-based method with better accuracy and low costs compared to the existing sampling-based method. The proposed method first predicts the compression ratio of SpGEMM by leveraging the number of intermediate products (denoted as FLOP) and the number of nonzero elements (denoted as NNZ) of the same sampled result matrix. And then, the predicted output structure is obtained by dividing the FLOP per output row by the predicted compression ratio. We also propose a reference design of the existing sampling-based method with optimized computing overheads to demonstrate the better accuracy of the proposed method. We construct 625 test cases with various matrix dimensions and sparse structures to evaluate the prediction accuracy. Experimental results show that the absolute relative errors of the proposed method and the reference design are 1.56\% and 8.12\%, respectively, on average, and 25\% and 156\%, respectively, in the worst case.
SCARA: Scalable Graph Neural Networks with Feature-Oriented Optimization
Jul 19, 2022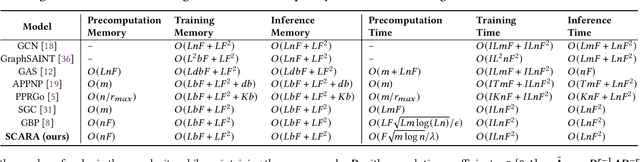
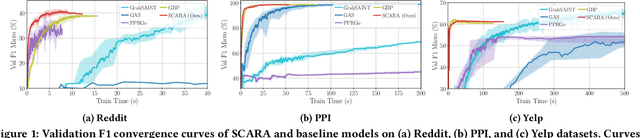

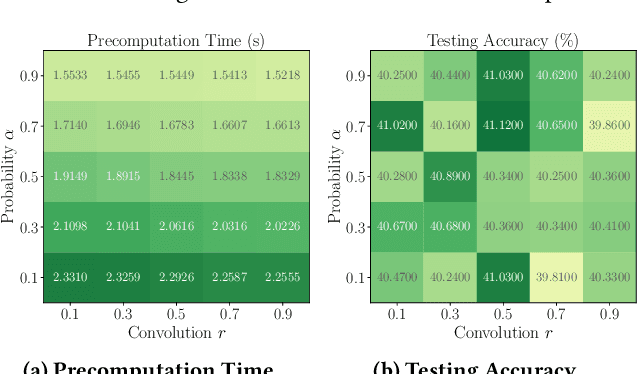
Recent advances in data processing have stimulated the demand for learning graphs of very large scales. Graph Neural Networks (GNNs), being an emerging and powerful approach in solving graph learning tasks, are known to be difficult to scale up. Most scalable models apply node-based techniques in simplifying the expensive graph message-passing propagation procedure of GNN. However, we find such acceleration insufficient when applied to million- or even billion-scale graphs. In this work, we propose SCARA, a scalable GNN with feature-oriented optimization for graph computation. SCARA efficiently computes graph embedding from node features, and further selects and reuses feature computation results to reduce overhead. Theoretical analysis indicates that our model achieves sub-linear time complexity with a guaranteed precision in propagation process as well as GNN training and inference. We conduct extensive experiments on various datasets to evaluate the efficacy and efficiency of SCARA. Performance comparison with baselines shows that SCARA can reach up to 100x graph propagation acceleration than current state-of-the-art methods with fast convergence and comparable accuracy. Most notably, it is efficient to process precomputation on the largest available billion-scale GNN dataset Papers100M (111M nodes, 1.6B edges) in 100 seconds.
On-Demand Redundancy Grouping: Selectable Soft-Error Tolerance for a Multicore Cluster
May 25, 2022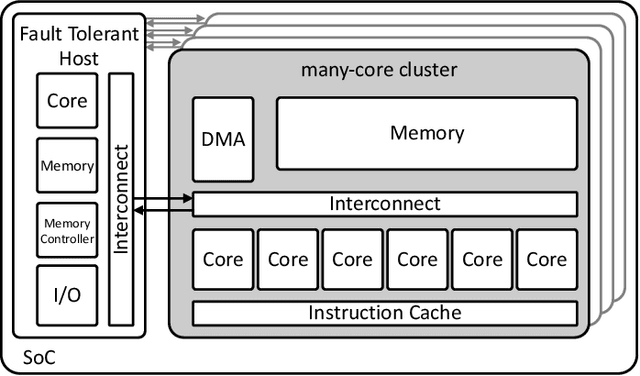
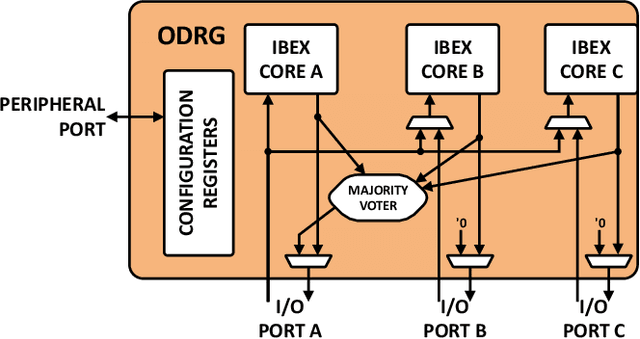
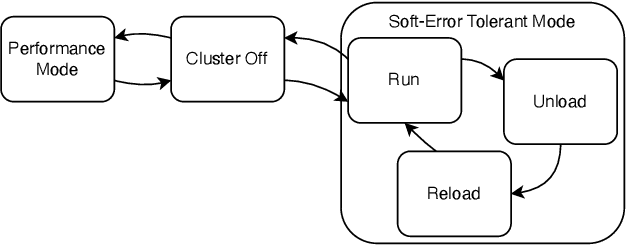
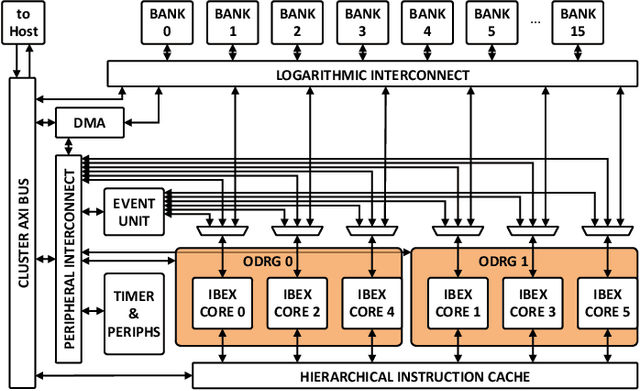
With the shrinking of technology nodes and the use of parallel processor clusters in hostile and critical environments, such as space, run-time faults caused by radiation are a serious cross-cutting concern, also impacting architectural design. This paper introduces an architectural approach to run-time configurable soft-error tolerance at the core level, augmenting a six-core open-source RISC-V cluster with a novel On-Demand Redundancy Grouping (ODRG) scheme. ODRG allows the cluster to operate either as two fault-tolerant cores, or six individual cores for high-performance, with limited overhead to switch between these modes during run-time. The ODRG unit adds less than 11% of a core's area for a three-core group, or a total of 1% of the cluster area, and shows negligible timing increase, which compares favorably to a commercial state-of-the-art implementation, and is 2.5$\times$ faster in fault recovery re-synchronization. Furthermore, unlike other implementations, when redundancy is not necessary, the ODRG approach allows the redundant cores to be used for independent computation, allowing up to 2.96$\times$ increase in performance for selected applications.
Centralized and Decentralized ML-Enabled Integrated Terrestrial and Non-Terrestrial Networks
Jul 22, 2022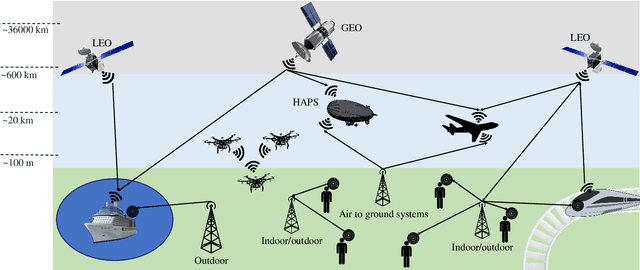
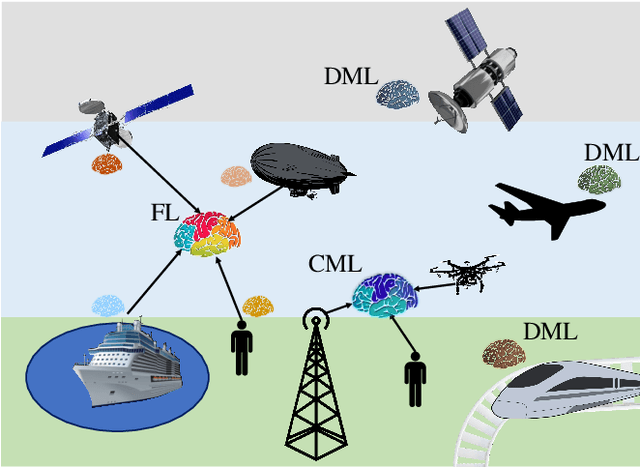
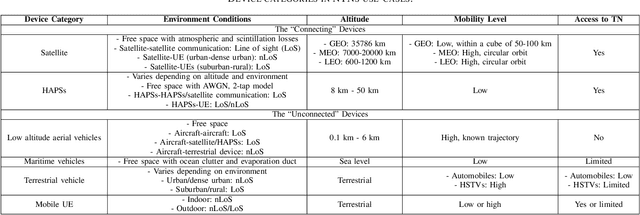
Non-terrestrial networks (NTNs) are a critical enabler of the persistent connectivity vision of sixth-generation networks, as they can service areas where terrestrial infrastructure falls short. However, the integration of these networks with the terrestrial network is laden with obstacles. The dynamic nature of NTN communication scenarios and numerous variables render conventional model-based solutions computationally costly and impracticable for resource allocation, parameter optimization, and other problems. Machine learning (ML)-based solutions, thus, can perform a pivotal role due to their inherent ability to uncover the hidden patterns in time-varying, multi-dimensional data with superior performance and less complexity. Centralized ML (CML) and decentralized ML (DML), named so based on the distribution of the data and computational load, are two classes of ML that are being studied as solutions for the various complications of terrestrial and non-terrestrial networks (TNTN) integration. Both have their benefits and drawbacks under different circumstances, and it is integral to choose the appropriate ML approach for each TNTN integration issue. To this end, this paper goes over the TNTN integration architectures as given in the 3rd generation partnership project standard releases, proposing possible scenarios. Then, the capabilities and challenges of CML and DML are explored from the vantage point of these scenarios.
Spatio-temporal prediction in video coding by spatially refined motion compensation
Jul 08, 2022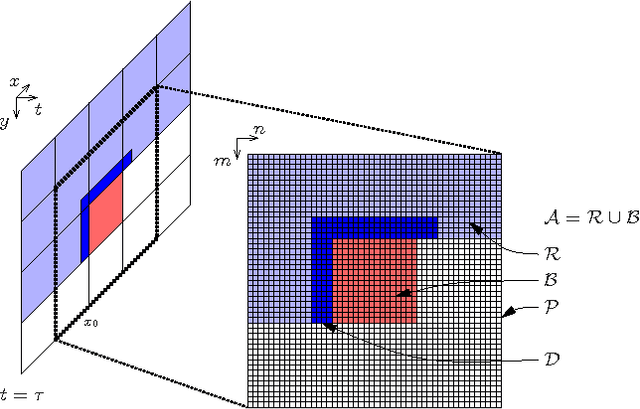
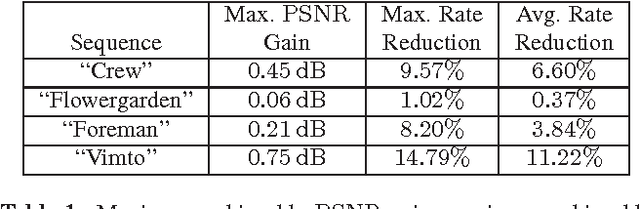
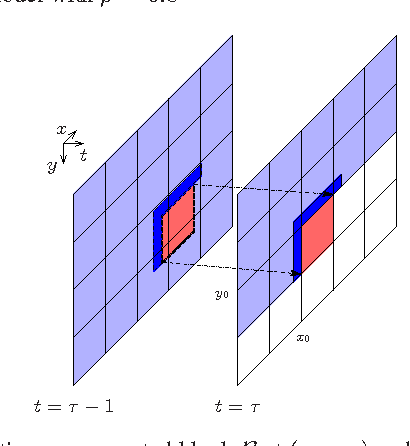
The purpose of this contribution is to introduce a new method of signal prediction in video coding. Unlike most existent prediction methods that either use temporal or use spatial correlations to generate the prediction signal, the proposed method uses spatial and temporal correlations at the same time. The spatio-temporal prediction is obtained by first performing motion compensation for a macroblock, followed by a refinement step that pays attention to the correlations between the macroblock and its surroundings. At the decoder, the refinement step can be performed in the same manner, thus no additional side information has to be transmitted. Implementation of the spatial refinement step into the H.264/AVC video codec leads to reduction in data rate of up to nearly 15% and increase in PSNR of up to 0.75 dB, compared to pure motion compensated prediction.