 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Explaining Dynamic Graph Neural Networks via Relevance Back-propagation
Jul 22, 2022
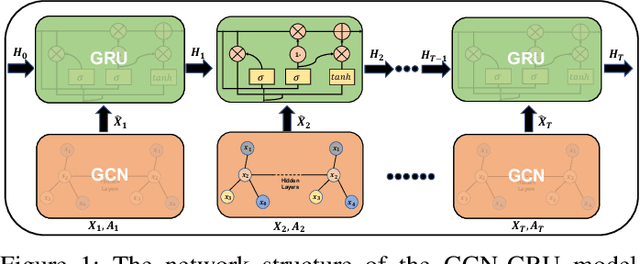
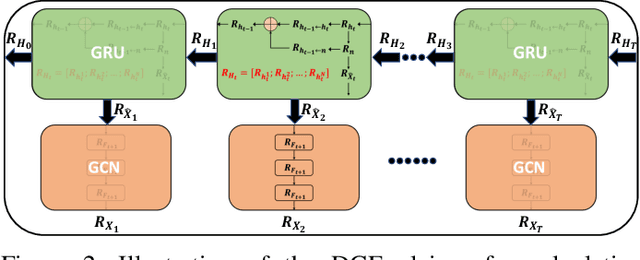
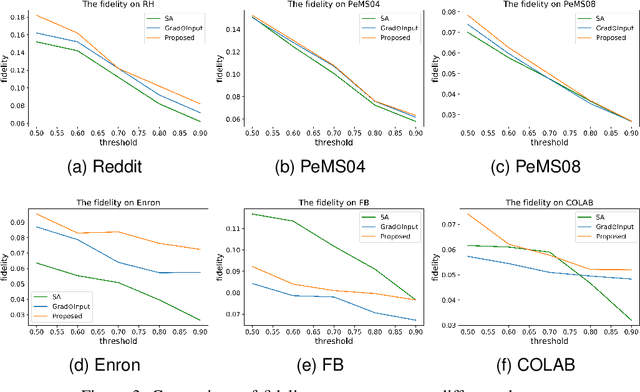
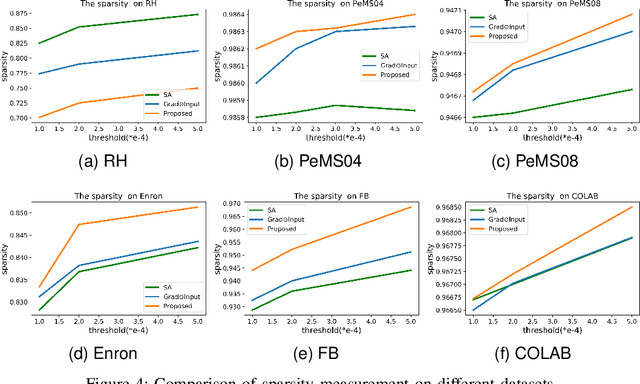
Graph Neural Networks (GNNs) have shown remarkable effectiveness in capturing abundant information in graph-structured data. However, the black-box nature of GNNs hinders users from understanding and trusting the models, thus leading to difficulties in their applications. While recent years witness the prosperity of the studies on explaining GNNs, most of them focus on static graphs, leaving the explanation of dynamic GNNs nearly unexplored. It is challenging to explain dynamic GNNs, due to their unique characteristic of time-varying graph structures. Directly using existing models designed for static graphs on dynamic graphs is not feasible because they ignore temporal dependencies among the snapshots. In this work, we propose DGExplainer to provide reliable explanation on dynamic GNNs. DGExplainer redistributes the output activation score of a dynamic GNN to the relevances of the neurons of its previous layer, which iterates until the relevance scores of the input neuron are obtained. We conduct quantitative and qualitative experiments on real-world datasets to demonstrate the effectiveness of the proposed framework for identifying important nodes for link prediction and node regression for dynamic GNNs.
Fairness-aware Network Revenue Management with Demand Learning
Jul 22, 2022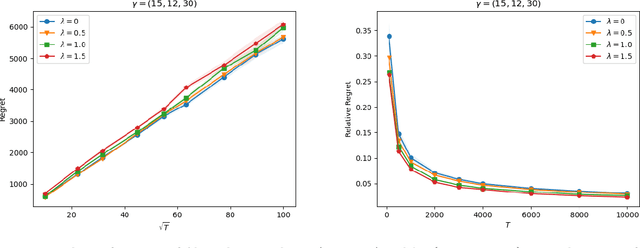
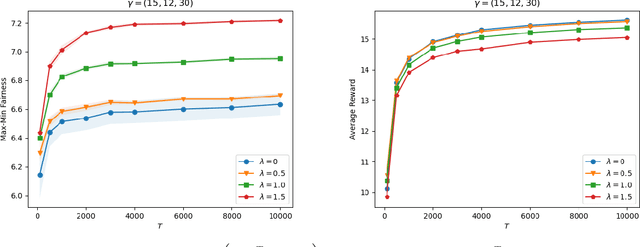
In addition to maximizing the total revenue, decision-makers in lots of industries would like to guarantee fair consumption across different resources and avoid saturating certain resources. Motivated by these practical needs, this paper studies the price-based network revenue management problem with both demand learning and fairness concern about the consumption across different resources. We introduce the regularized revenue, i.e., the total revenue with a fairness regularization, as our objective to incorporate fairness into the revenue maximization goal. We propose a primal-dual-type online policy with the Upper-Confidence-Bound (UCB) demand learning method to maximize the regularized revenue. We adopt several innovative techniques to make our algorithm a unified and computationally efficient framework for the continuous price set and a wide class of fairness regularizers. Our algorithm achieves a worst-case regret of $\tilde O(N^{5/2}\sqrt{T})$, where $N$ denotes the number of products and $T$ denotes the number of time periods. Numerical experiments in a few NRM examples demonstrate the effectiveness of our algorithm for balancing revenue and fairness.
Seeing the forest and the tree: Building representations of both individual and collective dynamics with transformers
Jun 10, 2022Complex time-varying systems are often studied by abstracting away from the dynamics of individual components to build a model of the population-level dynamics from the start. However, when building a population-level description, it can be easy to lose sight of each individual and how each contributes to the larger picture. In this paper, we present a novel transformer architecture for learning from time-varying data that builds descriptions of both the individual as well as the collective population dynamics. Rather than combining all of our data into our model at the onset, we develop a separable architecture that operates on individual time-series first before passing them forward; this induces a permutation-invariance property and can be used to transfer across systems of different size and order. After demonstrating that our model can be applied to successfully recover complex interactions and dynamics in many-body systems, we apply our approach to populations of neurons in the nervous system. On neural activity datasets, we show that our multi-scale transformer not only yields robust decoding performance, but also provides impressive performance in transfer. Our results show that it is possible to learn from neurons in one animal's brain and transfer the model on neurons in a different animal's brain, with interpretable neuron correspondence across sets and animals. This finding opens up a new path to decode from and represent large collections of neurons.
Asynchronous Federated Learning for Edge-assisted Vehicular Networks
Aug 03, 2022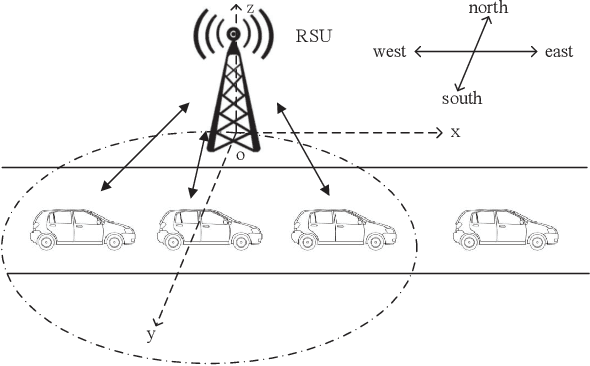
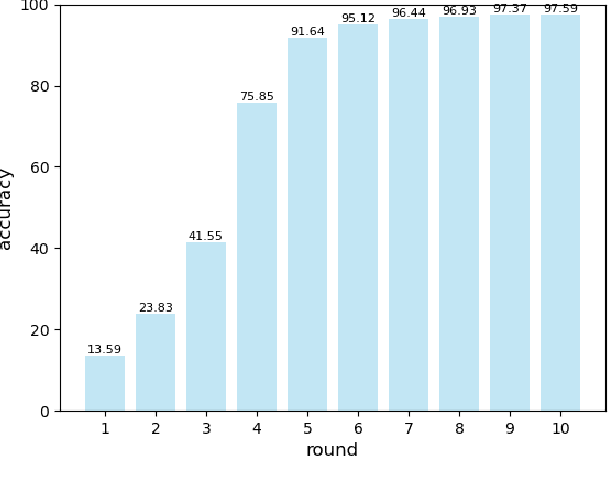
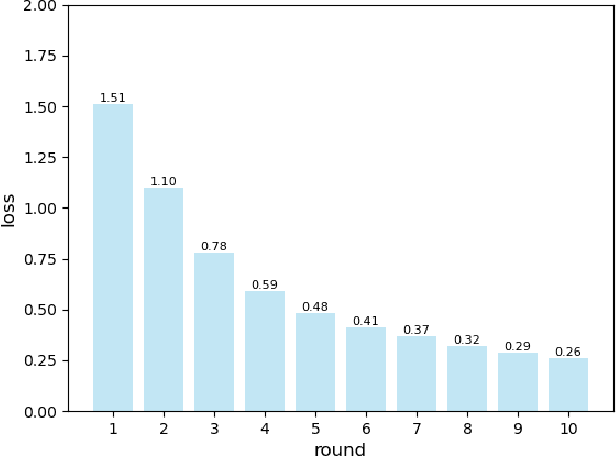
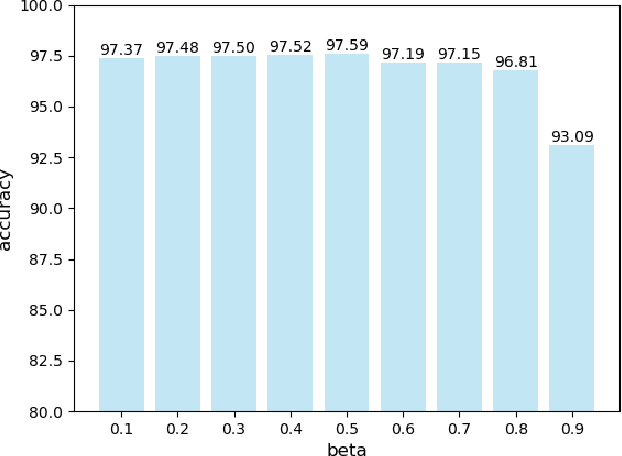
Vehicular networks enable vehicles support real-time vehicular applications through training data. Due to the limited computing capability, vehicles usually transmit data to a road side unit (RSU) at the network edge to process data. However, vehicles are usually reluctant to share data with each other due to the privacy issue. For the traditional federated learning (FL), vehicles train the data locally to obtain a local model and then upload the local model to the RSU to update the global model, thus the data privacy can be protected through sharing model parameters instead of data. The traditional FL updates the global model synchronously, i.e., the RSU needs to wait for all vehicles to upload their models for the global model updating. However, vehicles may usually drive out of the coverage of the RSU before they obtain their local models through training, which reduces the accuracy of the global model. It is necessary to propose an asynchronous federated learning (AFL) to solve this problem, where the RSU updates the global model once it receives a local model from a vehicle. However, the amount of data, computing capability and vehicle mobility may affect the accuracy of the global model. In this paper, we jointly consider the amount of data, computing capability and vehicle mobility to design an AFL scheme to improve the accuracy of the global model. Extensive simulation experiments have demonstrated that our scheme outperforms the FL scheme
Properly learning decision trees in almost polynomial time
Sep 01, 2021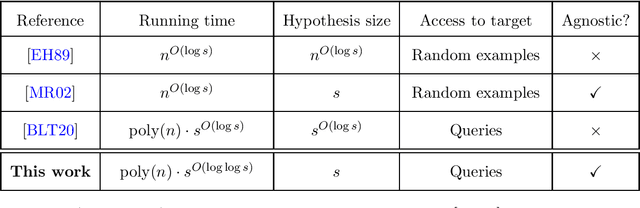


We give an $n^{O(\log\log n)}$-time membership query algorithm for properly and agnostically learning decision trees under the uniform distribution over $\{\pm 1\}^n$. Even in the realizable setting, the previous fastest runtime was $n^{O(\log n)}$, a consequence of a classic algorithm of Ehrenfeucht and Haussler. Our algorithm shares similarities with practical heuristics for learning decision trees, which we augment with additional ideas to circumvent known lower bounds against these heuristics. To analyze our algorithm, we prove a new structural result for decision trees that strengthens a theorem of O'Donnell, Saks, Schramm, and Servedio. While the OSSS theorem says that every decision tree has an influential variable, we show how every decision tree can be "pruned" so that every variable in the resulting tree is influential.
Efficient Per-Shot Convex Hull Prediction By Recurrent Learning
Jun 10, 2022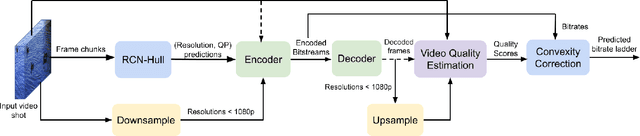
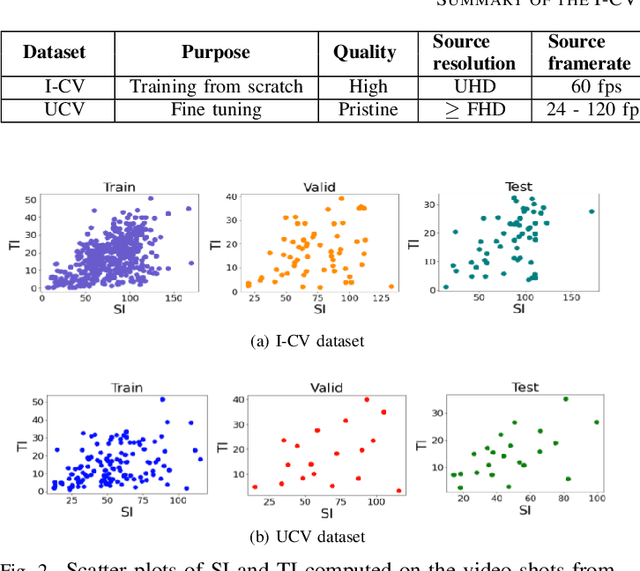
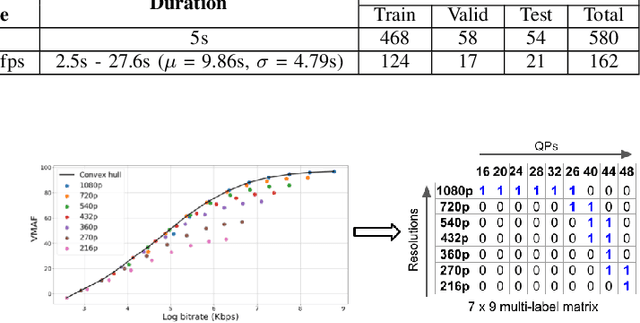
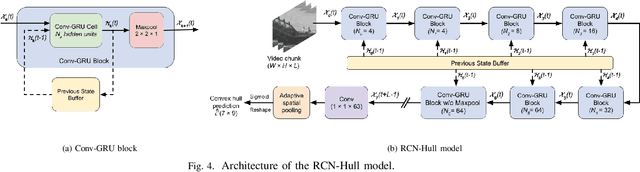
Adaptive video streaming relies on the construction of efficient bitrate ladders to deliver the best possible visual quality to viewers under bandwidth constraints. The traditional method of content dependent bitrate ladder selection requires a video shot to be pre-encoded with multiple encoding parameters to find the optimal operating points given by the convex hull of the resulting rate-quality curves. However, this pre-encoding step is equivalent to an exhaustive search process over the space of possible encoding parameters, which causes significant overhead in terms of both computation and time expenditure. To reduce this overhead, we propose a deep learning based method of content aware convex hull prediction. We employ a recurrent convolutional network (RCN) to implicitly analyze the spatiotemporal complexity of video shots in order to predict their convex hulls. A two-step transfer learning scheme is adopted to train our proposed RCN-Hull model, which ensures sufficient content diversity to analyze scene complexity, while also making it possible capture the scene statistics of pristine source videos. Our experimental results reveal that our proposed model yields better approximations of the optimal convex hulls, and offers competitive time savings as compared to existing approaches. On average, the pre-encoding time was reduced by 58.0% by our method, while the average Bjontegaard delta bitrate (BD-rate) of the predicted convex hulls against ground truth was 0.08%, while the mean absolute deviation of the BD-rate distribution was 0.44%
Analysis of the Spatio-temporal Dynamics of COVID-19 in Massachusetts via Spectral Graph Wavelet Theory
Jul 28, 2022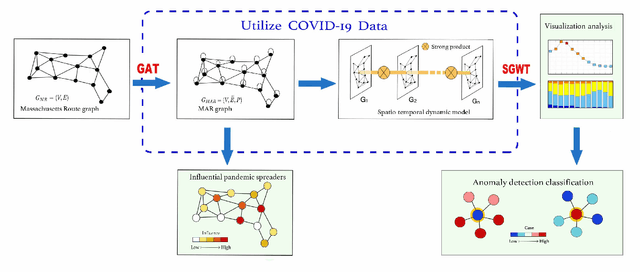
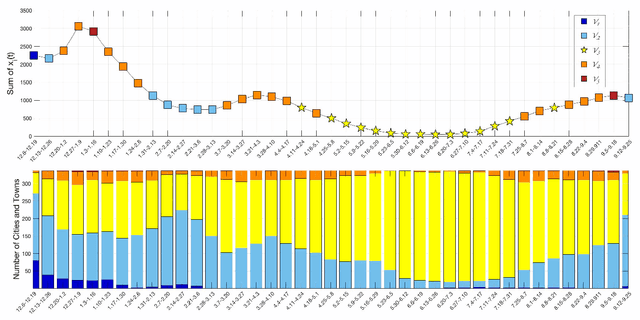
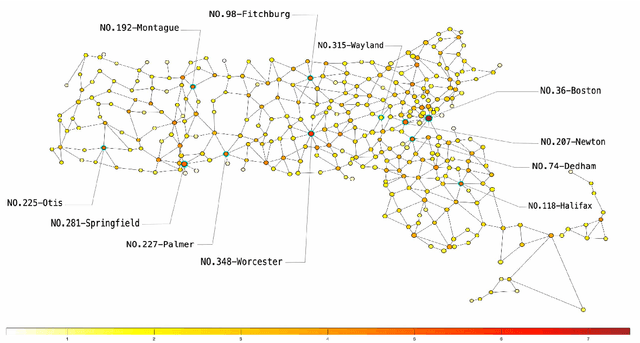
The rapid spread of COVID-19 disease has had a significant impact on the world. In this paper, we study COVID-19 data interpretation and visualization using open-data sources for 351 cities and towns in Massachusetts from December 6, 2020 to September 25, 2021. Because cities are embedded in rather complex transportation networks, we construct the spatio-temporal dynamic graph model, in which the graph attention neural network is utilized as a deep learning method to learn the pandemic transition probability among major cities in Massachusetts. Using the spectral graph wavelet transform (SGWT), we process the COVID-19 data on the dynamic graph, which enables us to design effective tools to analyze and detect spatio-temporal patterns in the pandemic spreading. We design a new node classification method, which effectively identifies the anomaly cities based on spectral graph wavelet coefficients. It can assist administrations or public health organizations in monitoring the spread of the pandemic and developing preventive measures. Unlike most work focusing on the evolution of confirmed cases over time, we focus on the spatio-temporal patterns of pandemic evolution among cities. Through the data analysis and visualization, a better understanding of the epidemiological development at the city level is obtained and can be helpful with city-specific surveillance.
iDriving: Toward Safe and Efficient Infrastructure-directed Autonomous Driving
Jul 18, 2022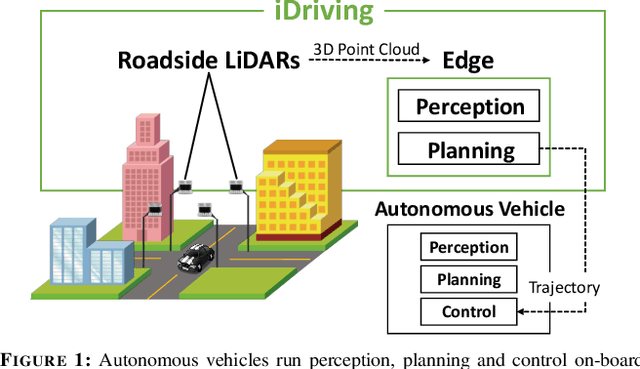
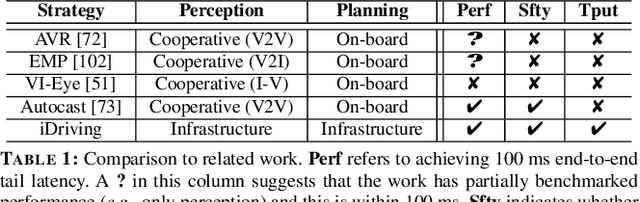
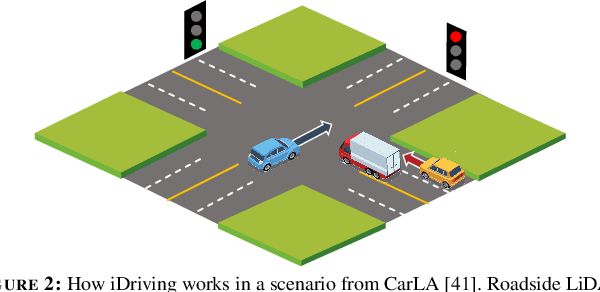
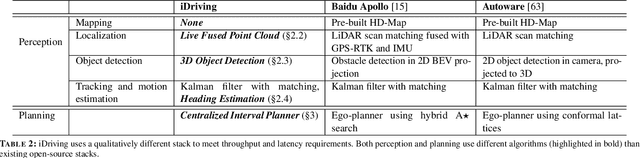
Autonomous driving will become pervasive in the coming decades. iDriving improves the safety of autonomous driving at intersections and increases efficiency by improving traffic throughput at intersections. In iDriving, roadside infrastructure remotely drives an autonomous vehicle at an intersection by offloading perception and planning from the vehicle to roadside infrastructure. To achieve this, iDriving must be able to process voluminous sensor data at full frame rate with a tail latency of less than 100 ms, without sacrificing accuracy. We describe algorithms and optimizations that enable it to achieve this goal using an accurate and lightweight perception component that reasons on composite views derived from overlapping sensors, and a planner that jointly plans trajectories for multiple vehicles. In our evaluations, iDriving always ensures safe passage of vehicles, while autonomous driving can only do so 27% of the time. iDriving also results in 5x lower wait times than other approaches because it enables traffic-light free intersections.
Deeply-Learned Generalized Linear Models with Missing Data
Jul 18, 2022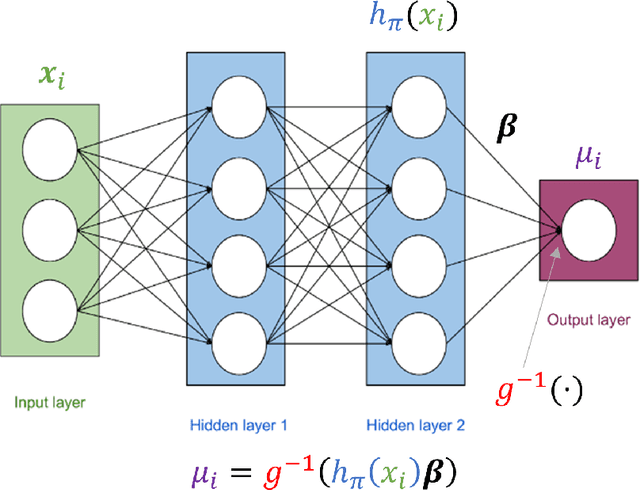
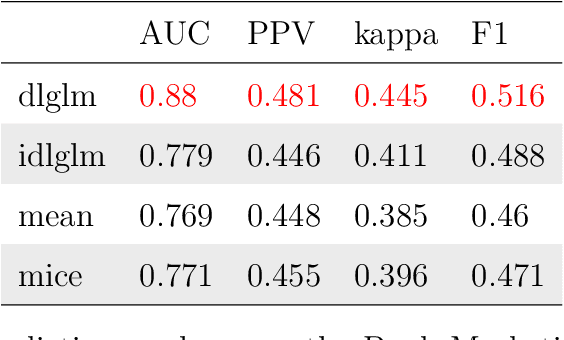
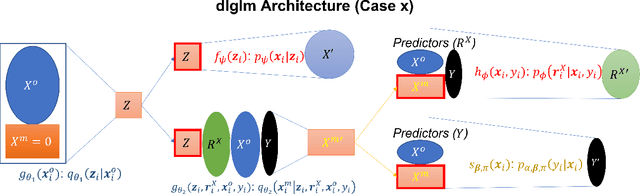
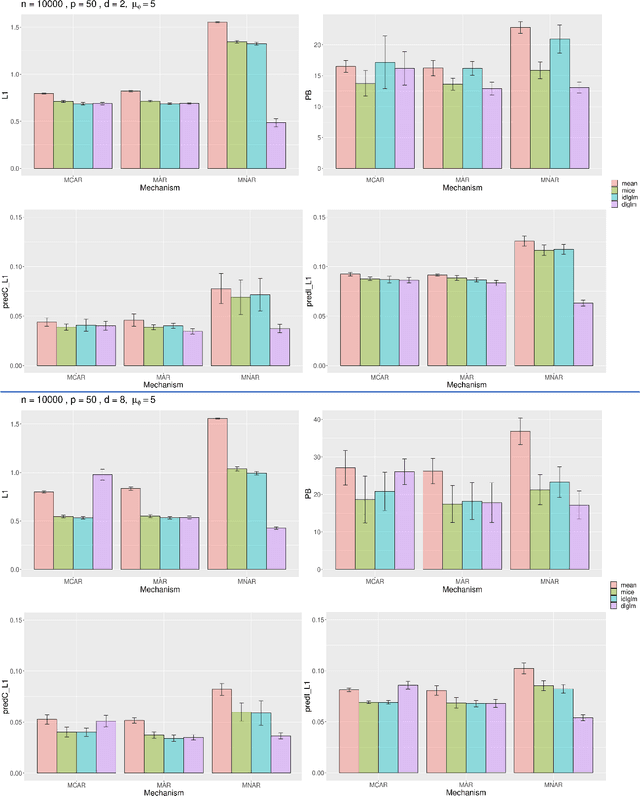
Deep Learning (DL) methods have dramatically increased in popularity in recent years, with significant growth in their application to supervised learning problems in the biomedical sciences. However, the greater prevalence and complexity of missing data in modern biomedical datasets present significant challenges for DL methods. Here, we provide a formal treatment of missing data in the context of deeply learned generalized linear models, a supervised DL architecture for regression and classification problems. We propose a new architecture, \textit{dlglm}, that is one of the first to be able to flexibly account for both ignorable and non-ignorable patterns of missingness in input features and response at training time. We demonstrate through statistical simulation that our method outperforms existing approaches for supervised learning tasks in the presence of missing not at random (MNAR) missingness. We conclude with a case study of a Bank Marketing dataset from the UCI Machine Learning Repository, in which we predict whether clients subscribed to a product based on phone survey data.
Evolutionary Robust Clustering Over Time for Temporal Data
Jun 14, 2021
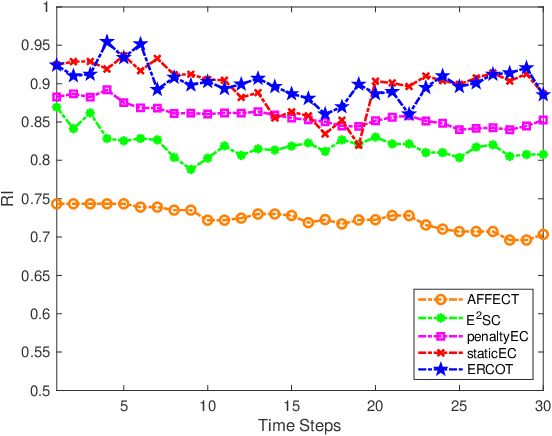


In many clustering scenes, data samples' attribute values change over time. For such data, we are often interested in obtaining a partition for each time step and tracking the dynamic change of partitions. Normally, a smooth change is assumed for data to have a temporal smooth nature. Existing algorithms consider the temporal smoothness as an a priori preference and bias the search towards the preferred direction. This a priori manner leads to a risk of converging to an unexpected region because it is not always the case that a reasonable preference can be elicited given the little prior knowledge about the data. To address this issue, this paper proposes a new clustering framework called evolutionary robust clustering over time. One significant innovation of the proposed framework is processing the temporal smoothness in an a posteriori manner, which avoids unexpected convergence that occurs in existing algorithms. Furthermore, the proposed framework automatically tunes the weight of smoothness without data's affinity matrix and predefined parameters, which holds better applicability and scalability. The effectiveness and efficiency of the proposed framework are confirmed by comparing with state-of-the-art algorithms on both synthetic and real datasets.