 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Using Infant Limb Movement Data to Control Small Aerial Robots
Aug 11, 2022
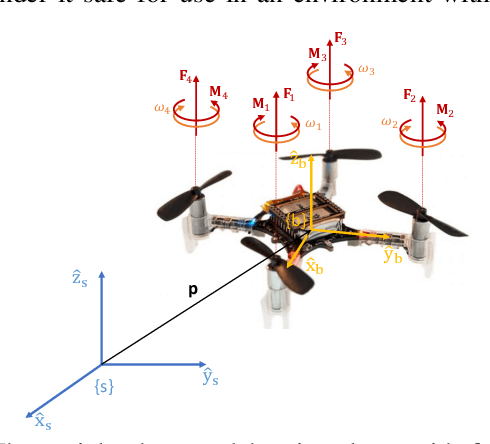
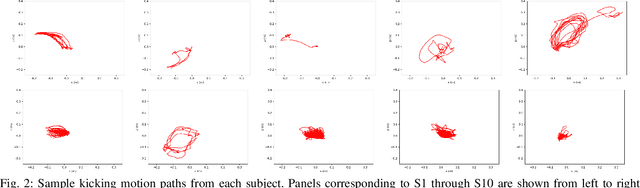
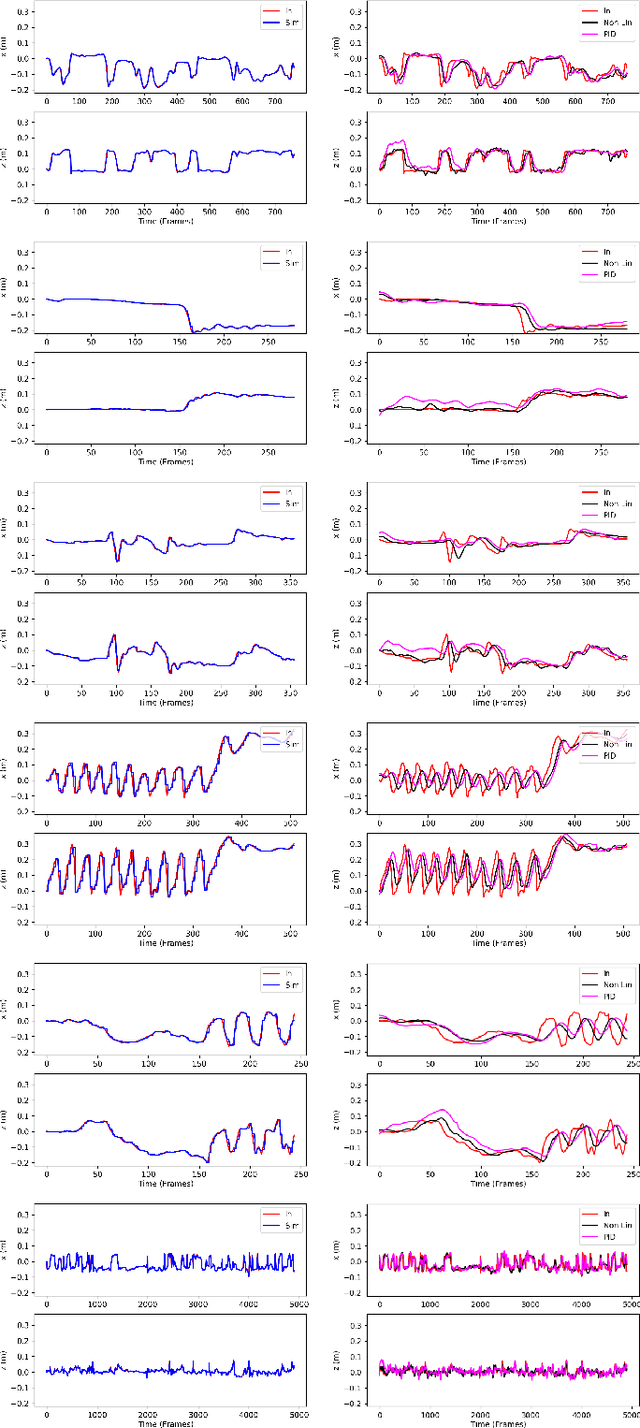
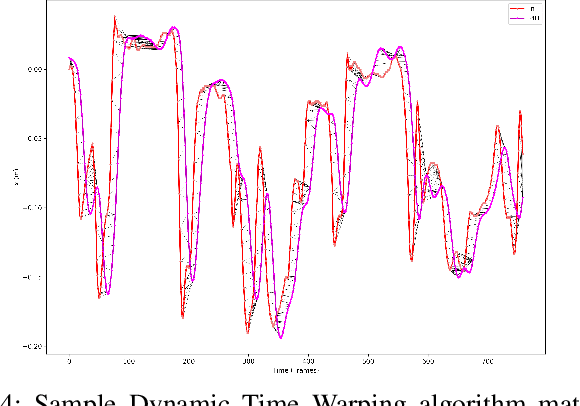
Promoting exploratory movements through contingent feedback can positively influence motor development in infancy. Our ongoing work gears toward the development of a robot-assisted contingency learning environment through the use of small aerial robots. This paper examines whether aerial robots and their associated motion controllers can be used to achieve efficient and highly-responsive robot flight for our purpose. Infant kicking kinematic data were extracted from videos and used in simulation and physical experiments with an aerial robot. The efficacy of two standard of practice controllers was assessed: a linear PID and a nonlinear geometric controller. The ability of the robot to match infant kicking trajectories was evaluated qualitatively and quantitatively via the mean squared error (to assess overall deviation from the input infant leg trajectory signals), and dynamic time warping algorithm (to quantify the signal synchrony). Results demonstrate that it is in principle possible to track infant kicking trajectories with small aerials robots, and identify areas of further development required to improve the tracking quality.
Automatic Calibration of a Six-Degrees-of-Freedom Pose Estimation System
Aug 23, 2022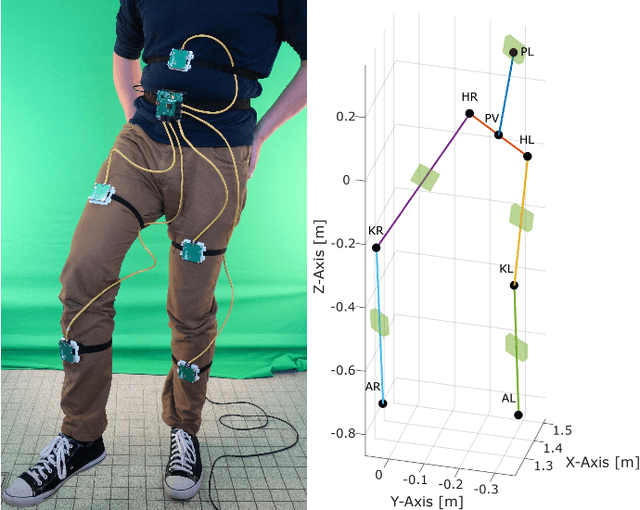
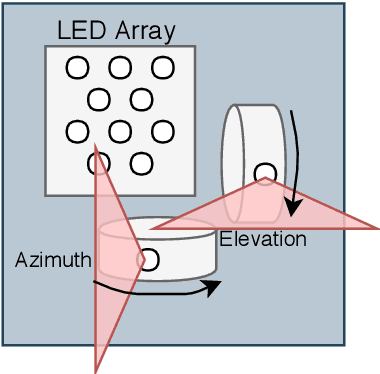
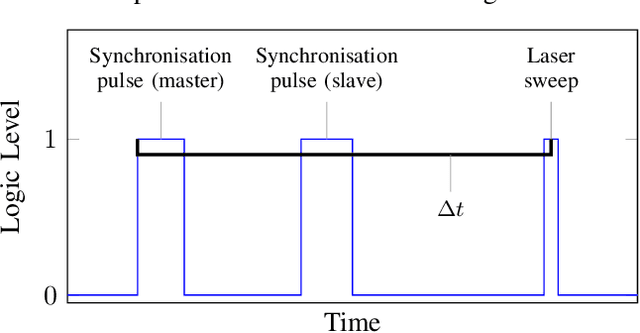

Systems for estimating the six-degrees-of-freedom human body pose have been improving for over two decades. Technologies such as motion capture cameras, advanced gaming peripherals and more recently both deep learning techniques and virtual reality systems have shown impressive results. However, most systems that provide high accuracy and high precision are expensive and not easy to operate. Recently, research has been carried out to estimate the human body pose using the HTC Vive virtual reality system. This system shows accurate results while keeping the cost under a 1000 USD. This system uses an optical approach. Two transmitter devices emit infrared pulses and laser planes are tracked by use of photo diodes on receiver hardware. A system using these transmitter devices combined with low-cost custom-made receiver hardware was developed previously but requires manual measurement of the position and orientation of the transmitter devices. These manual measurements can be time consuming, prone to error and not possible in particular setups. We propose an algorithm to automatically calibrate the poses of the transmitter devices in any chosen environment with custom receiver/calibration hardware. Results show that the calibration works in a variety of setups while being more accurate than what manual measurements would allow. Furthermore, the calibration movement and speed has no noticeable influence on the precision of the results.
Conformal Navigation Transformations with Application to Robot Navigation in Complex Workspaces
Aug 14, 2022
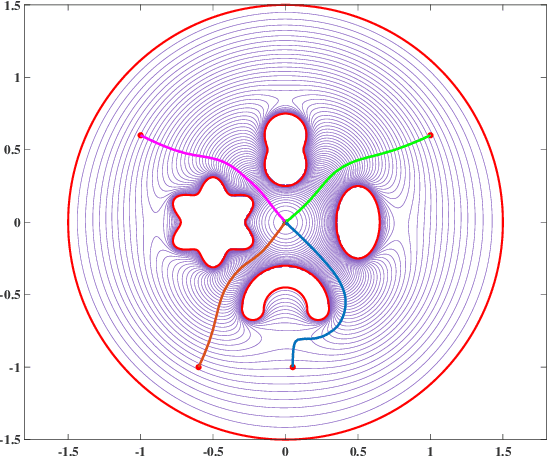
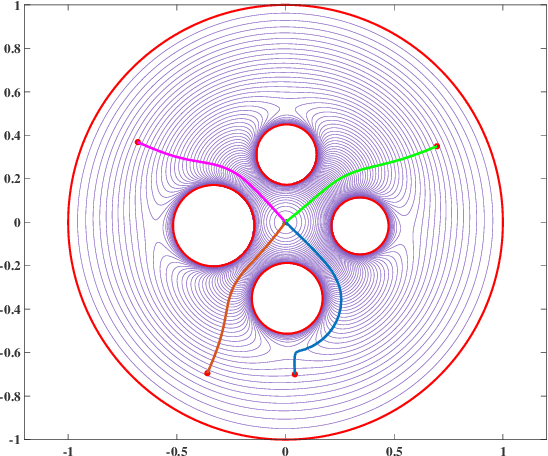
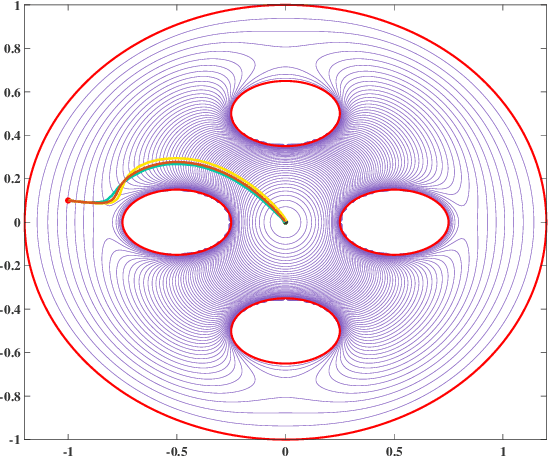
Navigation functions provide both path and motion planning, which can be used to ensure obstacle avoidance and convergence in the sphere world. When dealing with complex and realistic scenarios, constructing a transformation to the sphere world is essential and, at the same time, challenging. This work proposes a novel transformation termed the conformal navigation transformation to achieve collision-free navigation of a robot in a workspace populated with obstacles of arbitrary shapes. The properties of the conformal navigation transformation, including uniqueness, invariance of navigation properties, and no angular deformation, are investigated, which contribute to the solution of the robot navigation problem in complex environments. Based on navigation functions and the proposed transformation, feedback controllers are derived for the automatic guidance and motion control of kinematic and dynamic mobile robots. Moreover, an iterative method is proposed to construct the conformal navigation transformation in a multi-connected workspace, which transforms the multi-connected problem into multiple single-connected problems to achieve fast convergence. In addition to the analytic guarantees, simulation studies verify the effectiveness of the proposed methodology in workspaces with non-trivial obstacles.
Thompson Sampling Efficiently Learns to Control Diffusion Processes
Jun 20, 2022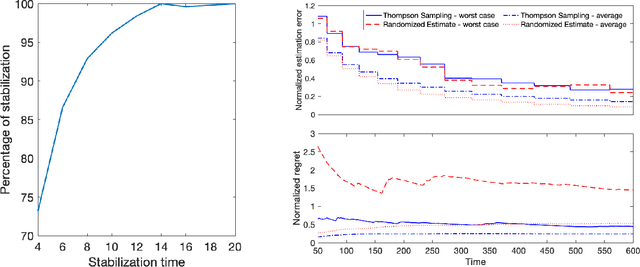
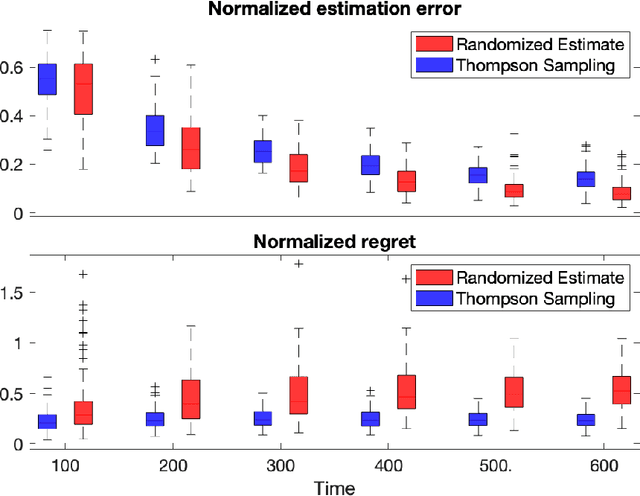
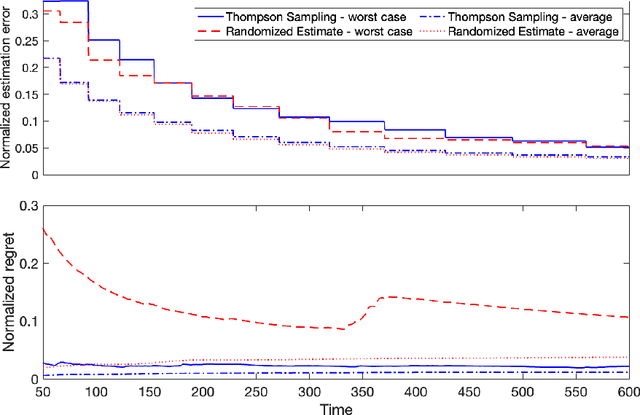
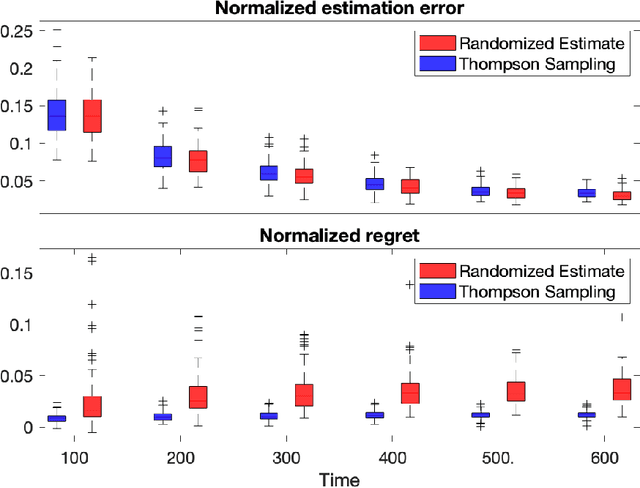
Diffusion processes that evolve according to linear stochastic differential equations are an important family of continuous-time dynamic decision-making models. Optimal policies are well-studied for them, under full certainty about the drift matrices. However, little is known about data-driven control of diffusion processes with uncertain drift matrices as conventional discrete-time analysis techniques are not applicable. In addition, while the task can be viewed as a reinforcement learning problem involving exploration and exploitation trade-off, ensuring system stability is a fundamental component of designing optimal policies. We establish that the popular Thompson sampling algorithm learns optimal actions fast, incurring only a square-root of time regret, and also stabilizes the system in a short time period. To the best of our knowledge, this is the first such result for Thompson sampling in a diffusion process control problem. We validate our theoretical results through empirical simulations with real parameter matrices from two settings of airplane and blood glucose control. Moreover, we observe that Thompson sampling significantly improves (worst-case) regret, compared to the state-of-the-art algorithms, suggesting Thompson sampling explores in a more guarded fashion. Our theoretical analysis involves characterization of a certain optimality manifold that ties the local geometry of the drift parameters to the optimal control of the diffusion process. We expect this technique to be of broader interest.
Scalable neural quantum states architecture for quantum chemistry
Aug 11, 2022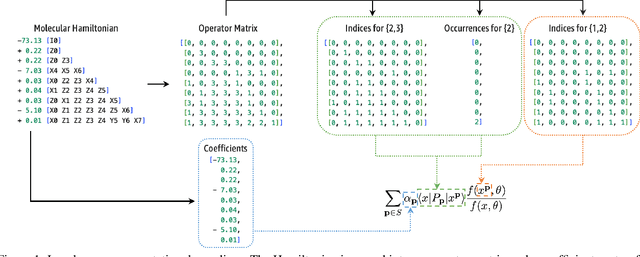
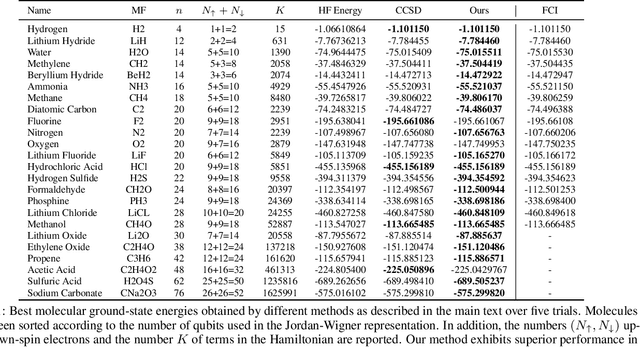
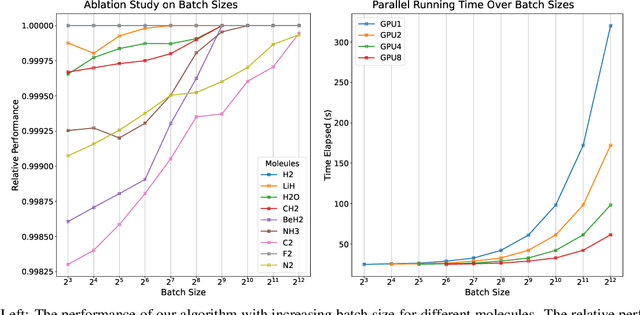
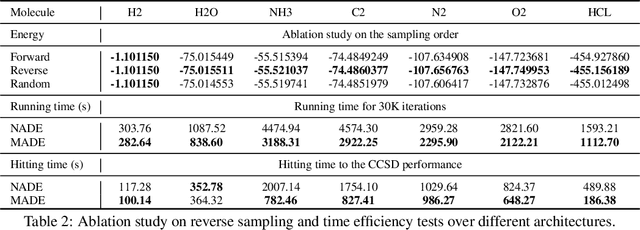
Variational optimization of neural-network representations of quantum states has been successfully applied to solve interacting fermionic problems. Despite rapid developments, significant scalability challenges arise when considering molecules of large scale, which correspond to non-locally interacting quantum spin Hamiltonians consisting of sums of thousands or even millions of Pauli operators. In this work, we introduce scalable parallelization strategies to improve neural-network-based variational quantum Monte Carlo calculations for ab-initio quantum chemistry applications. We establish GPU-supported local energy parallelism to compute the optimization objective for Hamiltonians of potentially complex molecules. Using autoregressive sampling techniques, we demonstrate systematic improvement in wall-clock timings required to achieve CCSD baseline target energies. The performance is further enhanced by accommodating the structure of resultant spin Hamiltonians into the autoregressive sampling ordering. The algorithm achieves promising performance in comparison with the classical approximate methods and exhibits both running time and scalability advantages over existing neural-network based methods.
Machine learning based surrogate models for microchannel heat sink optimization
Aug 20, 2022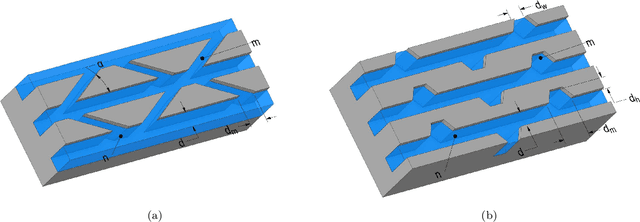


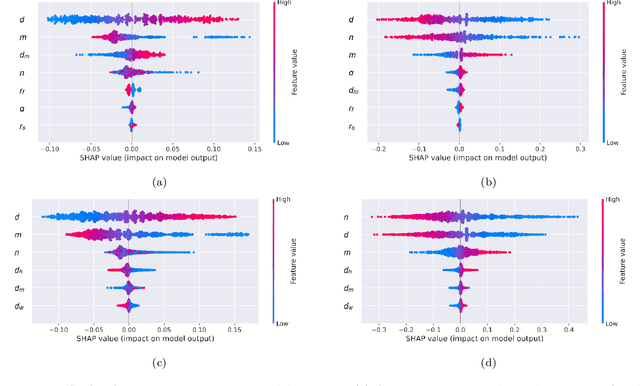
In this paper, microchannel designs with secondary channels and with ribs are investigated using computational fluid dynamics and are coupled with a multi-objective optimization algorithm to determine and propose optimal solutions based on observed thermal resistance and pumping power. A workflow that combines Latin hypercube sampling, machine learning-based surrogate modeling and multi-objective optimization is proposed. Random forests, gradient boosting algorithms and neural networks were considered during the search for the best surrogate. We demonstrated that tuned neural networks can make accurate predictions and be used to create an acceptable surrogate model. Optimized solutions show a negligible difference in overall performance when compared to the conventional optimization approach. Additionally, solutions are calculated in one-fifth of the original time. Generated designs attain temperatures that are lower by more than 10% under the same pressure limits as a convectional microchannel design. When limited by temperature, pressure drops are reduced by more than 25%. Finally, the influence of each design variable on the thermal resistance and pumping power was investigated by employing the SHapley Additive exPlanations technique. Overall, we have demonstrated that the proposed framework has merit and can be used as a viable methodology in microchannel heat sink design optimization.
Transforming Autoregression: Interpretable and Expressive Time Series Forecast
Oct 15, 2021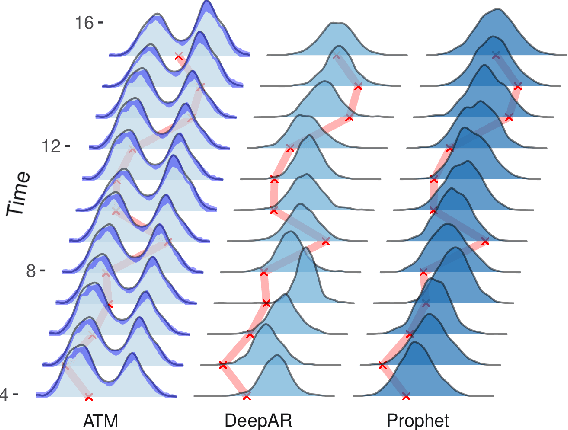

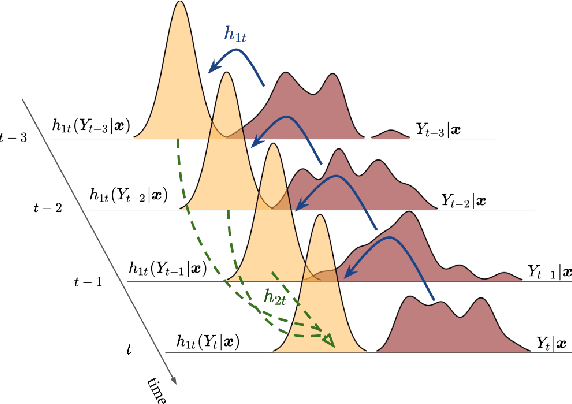

Probabilistic forecasting of time series is an important matter in many applications and research fields. In order to draw conclusions from a probabilistic forecast, we must ensure that the model class used to approximate the true forecasting distribution is expressive enough. Yet, characteristics of the model itself, such as its uncertainty or its general functioning are not of lesser importance. In this paper, we propose Autoregressive Transformation Models (ATMs), a model class inspired from various research directions such as normalizing flows and autoregressive models. ATMs unite expressive distributional forecasts using a semi-parametric distribution assumption with an interpretable model specification and allow for uncertainty quantification based on (asymptotic) Maximum Likelihood theory. We demonstrate the properties of ATMs both theoretically and through empirical evaluation on several simulated and real-world forecasting datasets.
Modeling Price Elasticity for Occupancy Prediction in Hotel Dynamic Pricing
Aug 11, 2022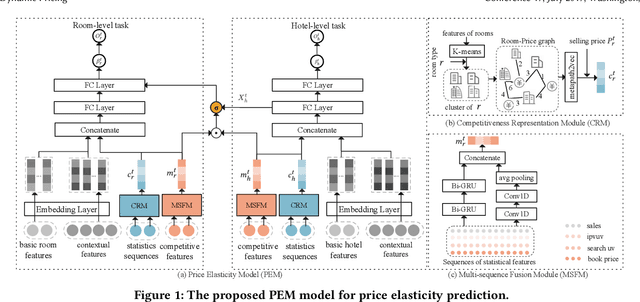
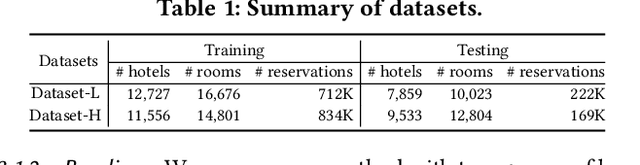
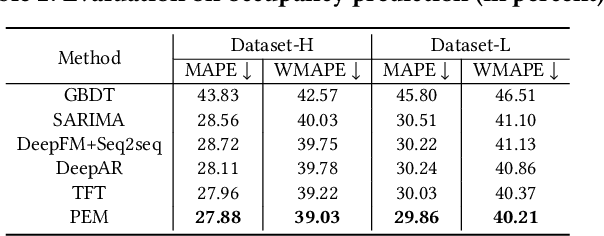

Demand estimation plays an important role in dynamic pricing where the optimal price can be obtained via maximizing the revenue based on the demand curve. In online hotel booking platform, the demand or occupancy of rooms varies across room-types and changes over time, and thus it is challenging to get an accurate occupancy estimate. In this paper, we propose a novel hotel demand function that explicitly models the price elasticity of demand for occupancy prediction, and design a price elasticity prediction model to learn the dynamic price elasticity coefficient from a variety of affecting factors. Our model is composed of carefully designed elasticity learning modules to alleviate the endogeneity problem, and trained in a multi-task framework to tackle the data sparseness. We conduct comprehensive experiments on real-world datasets and validate the superiority of our method over the state-of-the-art baselines for both occupancy prediction and dynamic pricing.
Transformer-Based Deep Learning Model for Stock Price Prediction: A Case Study on Bangladesh Stock Market
Aug 17, 2022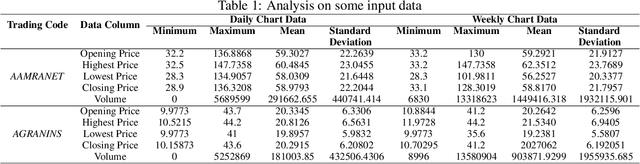
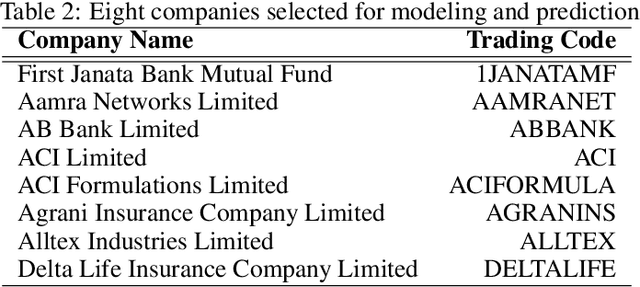
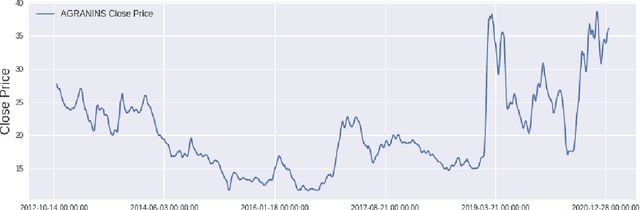
In modern capital market the price of a stock is often considered to be highly volatile and unpredictable because of various social, financial, political and other dynamic factors. With calculated and thoughtful investment, stock market can ensure a handsome profit with minimal capital investment, while incorrect prediction can easily bring catastrophic financial loss to the investors. This paper introduces the application of a recently introduced machine learning model - the Transformer model, to predict the future price of stocks of Dhaka Stock Exchange (DSE), the leading stock exchange in Bangladesh. The transformer model has been widely leveraged for natural language processing and computer vision tasks, but, to the best of our knowledge, has never been used for stock price prediction task at DSE. Recently the introduction of time2vec encoding to represent the time series features has made it possible to employ the transformer model for the stock price prediction. This paper concentrates on the application of transformer-based model to predict the price movement of eight specific stocks listed in DSE based on their historical daily and weekly data. Our experiments demonstrate promising results and acceptable root mean squared error on most of the stocks.
Label-Efficient Self-Training for Attribute Extraction from Semi-Structured Web Documents
Aug 27, 2022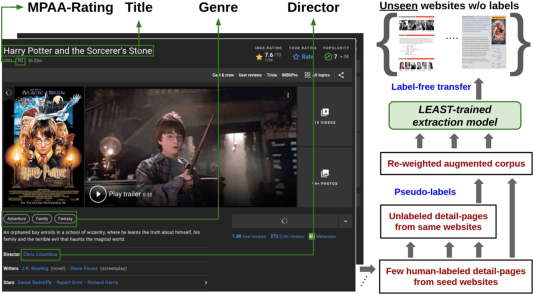

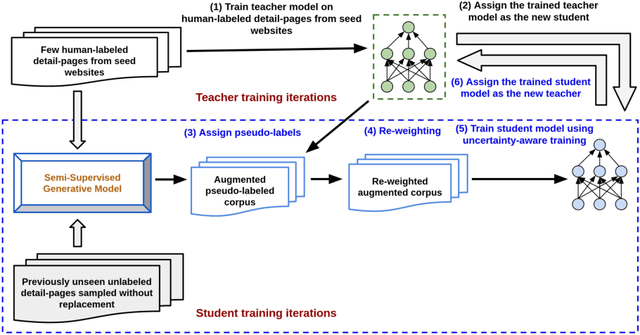
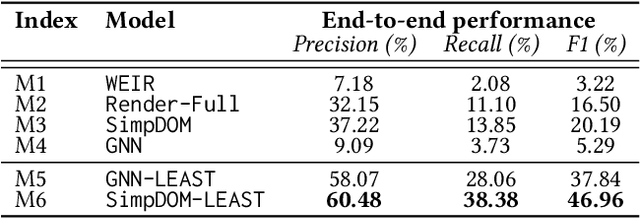
Extracting structured information from HTML documents is a long-studied problem with a broad range of applications, including knowledge base construction, faceted search, and personalized recommendation. Prior works rely on a few human-labeled web pages from each target website or thousands of human-labeled web pages from some seed websites to train a transferable extraction model that generalizes on unseen target websites. Noisy content, low site-level consistency, and lack of inter-annotator agreement make labeling web pages a time-consuming and expensive ordeal. We develop LEAST -- a Label-Efficient Self-Training method for Semi-Structured Web Documents to overcome these limitations. LEAST utilizes a few human-labeled pages to pseudo-annotate a large number of unlabeled web pages from the target vertical. It trains a transferable web-extraction model on both human-labeled and pseudo-labeled samples using self-training. To mitigate error propagation due to noisy training samples, LEAST re-weights each training sample based on its estimated label accuracy and incorporates it in training. To the best of our knowledge, this is the first work to propose end-to-end training for transferable web extraction models utilizing only a few human-labeled pages. Experiments on a large-scale public dataset show that using less than ten human-labeled pages from each seed website for training, a LEAST-trained model outperforms previous state-of-the-art by more than 26 average F1 points on unseen websites, reducing the number of human-labeled pages to achieve similar performance by more than 10x.