 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Deep Generative Approach to Oversampling in Ptychography
Jul 28, 2022
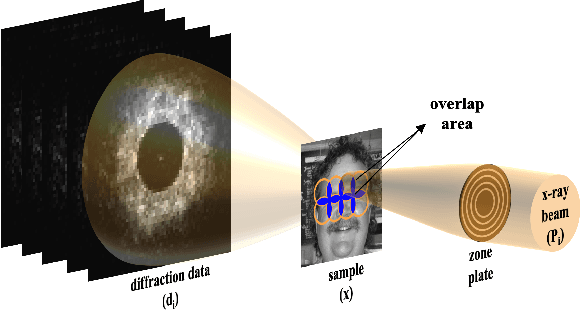

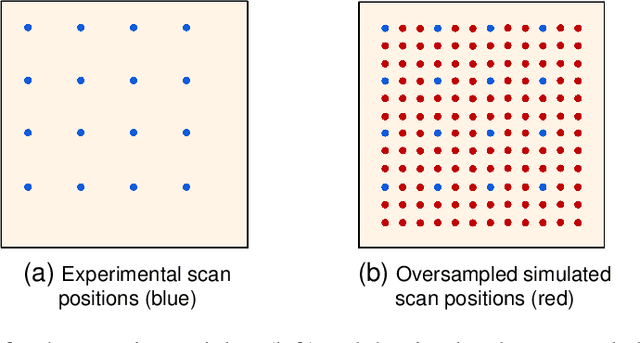

Ptychography is a well-studied phase imaging method that makes non-invasive imaging possible at a nanometer scale. It has developed into a mainstream technique with various applications across a range of areas such as material science or the defense industry. One major drawback of ptychography is the long data acquisition time due to the high overlap requirement between adjacent illumination areas to achieve a reasonable reconstruction. Traditional approaches with reduced overlap between scanning areas result in reconstructions with artifacts. In this paper, we propose complementing sparsely acquired or undersampled data with data sampled from a deep generative network to satisfy the oversampling requirement in ptychography. Because the deep generative network is pre-trained and its output can be computed as we collect data, the experimental data and the time to acquire the data can be reduced. We validate the method by presenting the reconstruction quality compared to the previously proposed and traditional approaches and comment on the strengths and drawbacks of the proposed approach.
DMF-Net: A decoupling-style multi-band fusion model for real-time full-band speech enhancement
Mar 02, 2022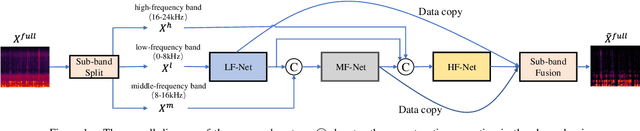
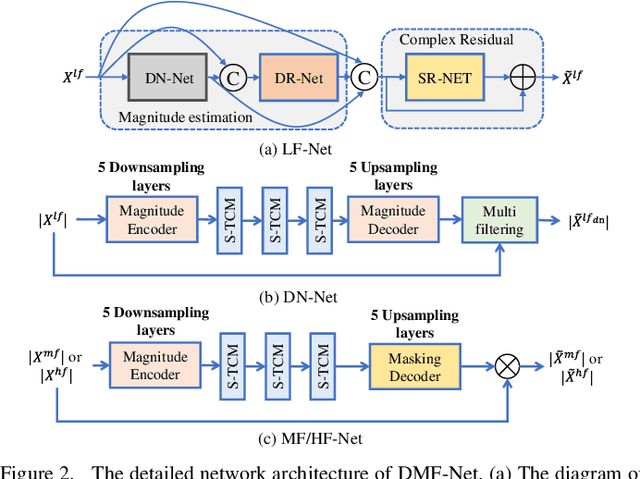
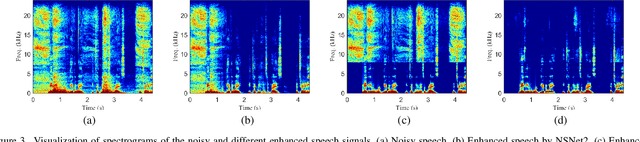
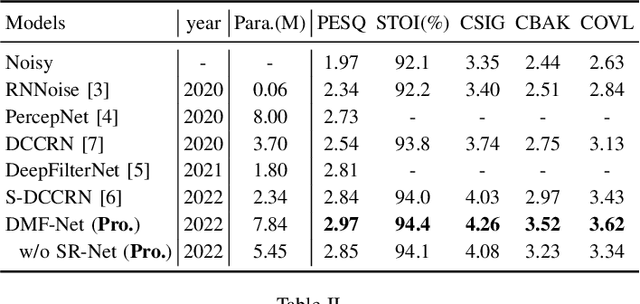
Full-band speech enhancement based on deep neural networks is still challenging for the difficulty of modeling more frequency bands and real-time implementation. Previous studies usually adopt compressed full-band speech features in Bark and ERB scale with relatively low frequency resolution, leading to degraded performance, especially in the high-frequency region. In this paper, we propose a decoupling-style multi-band fusion model to perform full-band speech denoising and dereverberation. Instead of optimizing the full-band speech by a single network structure, we decompose the full-band target into multi sub bands and then employ a multi-stage chain optimization strategy to estimate clean spectrum stage by stage. Specifically, the low- (0-8 kHz), middle- (8-16 kHz), and high-frequency (16-24 kHz) regions are mapped by three separate sub-networks and are then fused to obtain the full-band clean target STFT spectrum. Comprehensive experiments on two public datasets demonstrate that the proposed method outperforms previous advanced systems and yields promising performance in terms of speech quality and intelligibility in real complex scenarios.
Virtual staining of defocused autofluorescence images of unlabeled tissue using deep neural networks
Jul 06, 2022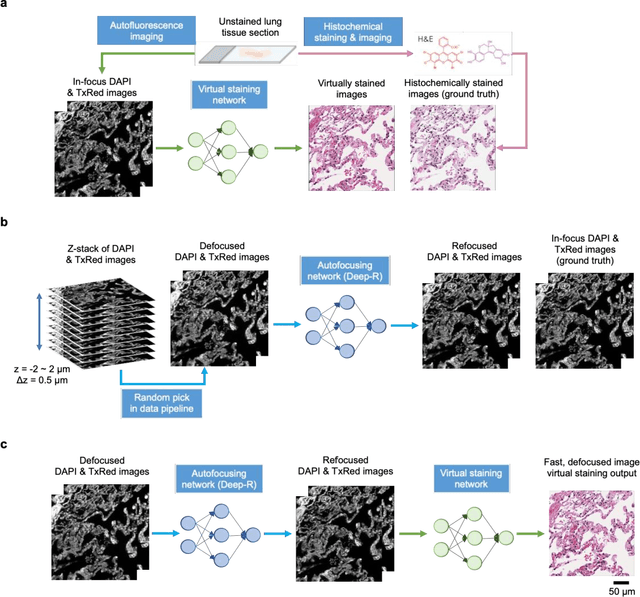
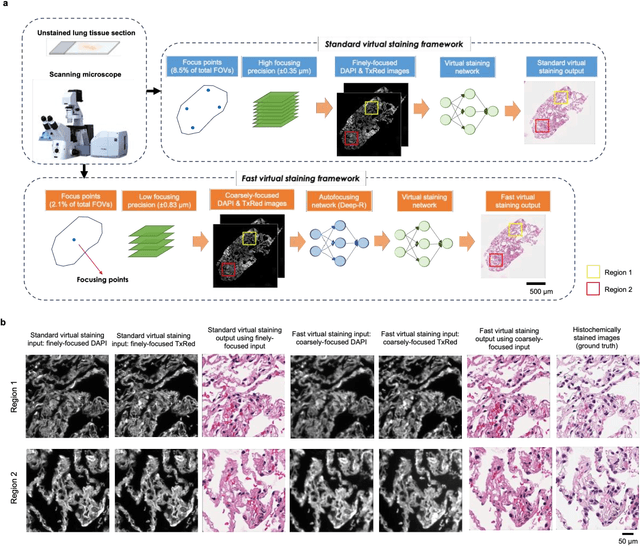
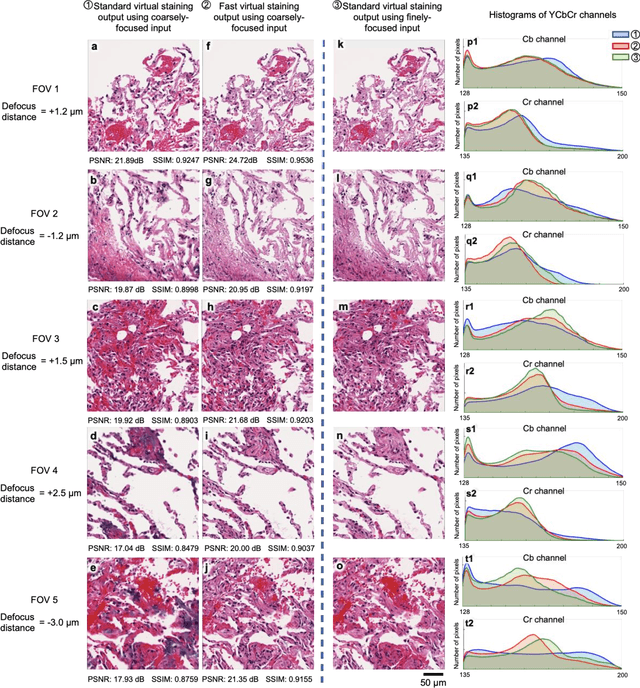
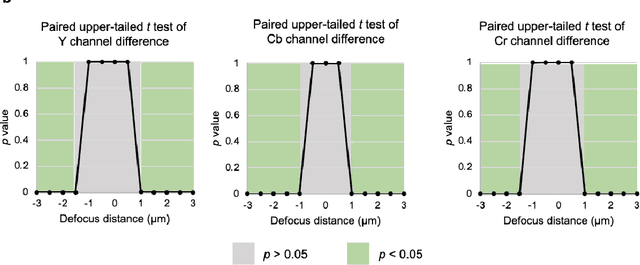
Deep learning-based virtual staining was developed to introduce image contrast to label-free tissue sections, digitally matching the histological staining, which is time-consuming, labor-intensive, and destructive to tissue. Standard virtual staining requires high autofocusing precision during the whole slide imaging of label-free tissue, which consumes a significant portion of the total imaging time and can lead to tissue photodamage. Here, we introduce a fast virtual staining framework that can stain defocused autofluorescence images of unlabeled tissue, achieving equivalent performance to virtual staining of in-focus label-free images, also saving significant imaging time by lowering the microscope's autofocusing precision. This framework incorporates a virtual-autofocusing neural network to digitally refocus the defocused images and then transforms the refocused images into virtually stained images using a successive network. These cascaded networks form a collaborative inference scheme: the virtual staining model regularizes the virtual-autofocusing network through a style loss during the training. To demonstrate the efficacy of this framework, we trained and blindly tested these networks using human lung tissue. Using 4x fewer focus points with 2x lower focusing precision, we successfully transformed the coarsely-focused autofluorescence images into high-quality virtually stained H&E images, matching the standard virtual staining framework that used finely-focused autofluorescence input images. Without sacrificing the staining quality, this framework decreases the total image acquisition time needed for virtual staining of a label-free whole-slide image (WSI) by ~32%, together with a ~89% decrease in the autofocusing time, and has the potential to eliminate the laborious and costly histochemical staining process in pathology.
Toward Data-Driven Radar STAP
Sep 07, 2022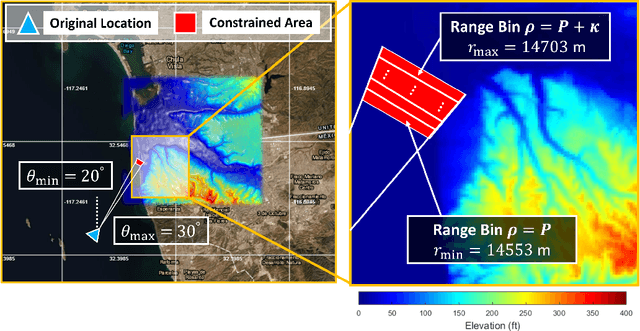
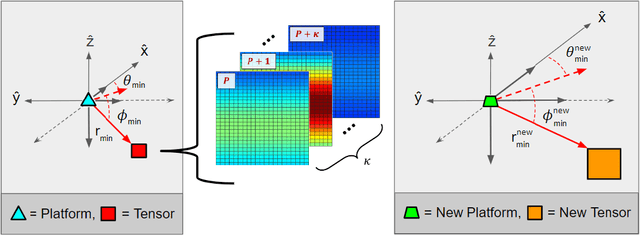
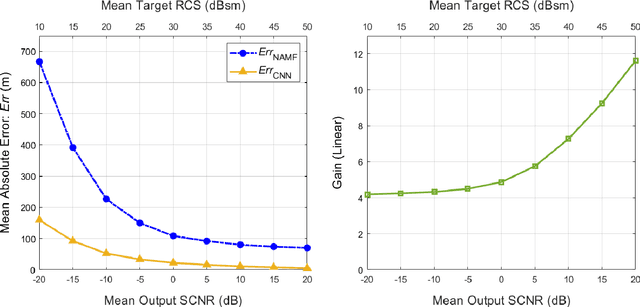
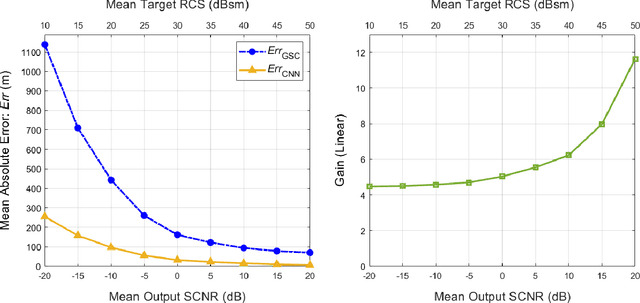
Catalyzed by the recent emergence of site-specific, high-fidelity radio frequency (RF) modeling and simulation tools purposed for radar, data-driven formulations of classical methods in radar have rapidly grown in popularity over the past decade. Despite this surge, limited focus has been directed toward the theoretical foundations of these classical methods. In this regard, as part of our ongoing data-driven approach to radar space-time adaptive processing (STAP), we analyze the asymptotic performance guarantees of select subspace separation methods in the context of radar target localization, and augment this analysis through a proposed deep learning framework for target location estimation. In our approach, we generate comprehensive datasets by randomly placing targets of variable strengths in predetermined constrained areas using RFView, a site-specific RF modeling and simulation tool developed by ISL Inc. For each radar return signal from these constrained areas, we generate heatmap tensors in range, azimuth, and elevation of the normalized adaptive matched filter (NAMF) test statistic, and of the output power of a generalized sidelobe canceller (GSC). Using our deep learning framework, we estimate target locations from these heatmap tensors to demonstrate the feasibility of and significant improvements provided by our data-driven approach in matched and mismatched settings.
Responsible AI Pattern Catalogue: a Multivocal Literature Review
Sep 12, 2022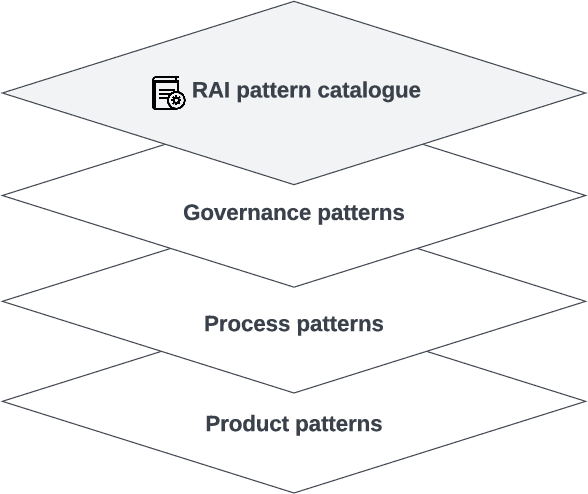

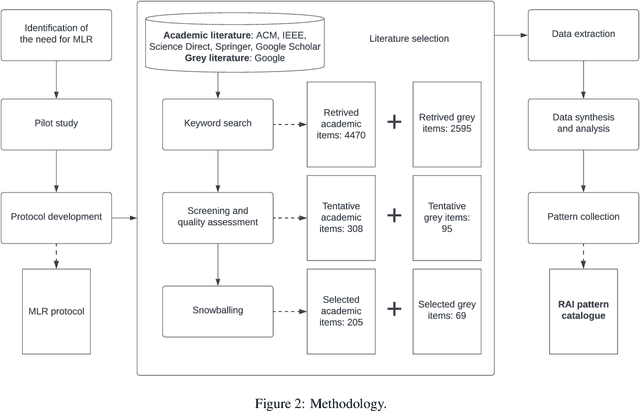
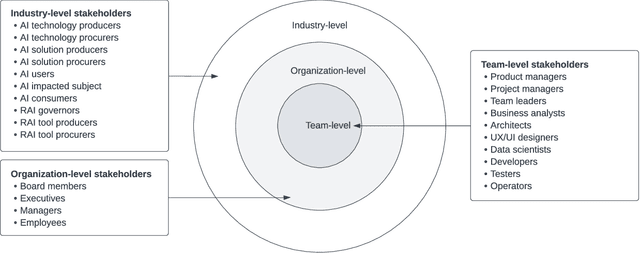
Responsible AI has been widely considered as one of the greatest scientific challenges of our time and the key to unlock the AI market and increase the adoption. To address the responsible AI challenge, a number of AI ethics principles frameworks have been published recently, which AI systems are supposed to conform to. However, without further best practice guidance, practitioners are left with nothing much beyond truisms. Also, significant efforts have been placed at algorithm-level rather than system-level, mainly focusing on a subset of mathematics-amenable ethical principles (such as privacy and fairness). Nevertheless, ethical issues can occur at any step of the development lifecycle crosscutting many AI, non-AI and data components of systems beyond AI algorithms and models. To operationalize responsible AI from a system perspective, in this paper, we adopt a pattern-oriented approach and present a Responsible AI Pattern Catalogue based on the results of a systematic Multivocal Literature Review (MLR). Rather than staying at the ethical principle level or algorithm level, we focus on patterns that AI system stakeholders can undertake in practice to ensure that the developed AI systems are responsible throughout the entire governance and engineering lifecycle. The Responsible AI Pattern Catalogue classifies patterns into three groups: multi-level governance patterns, trustworthy process patterns, and responsible-AI-by-design product patterns. These patterns provide a systematic and actionable guidance for stakeholders to implement responsible AI.
A Linear and Exact Algorithm for Whole-Body Collision Evaluation via Scale Optimization
Aug 12, 2022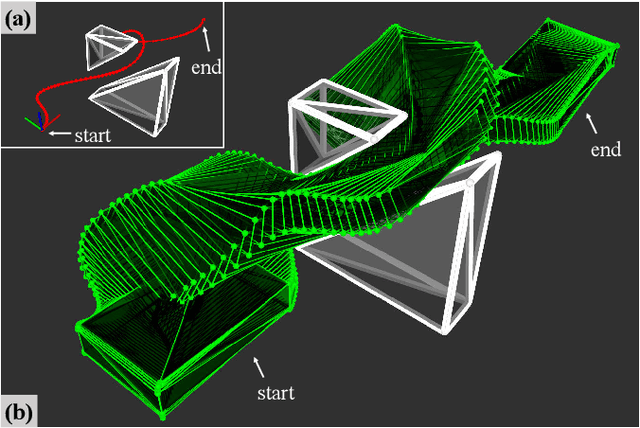
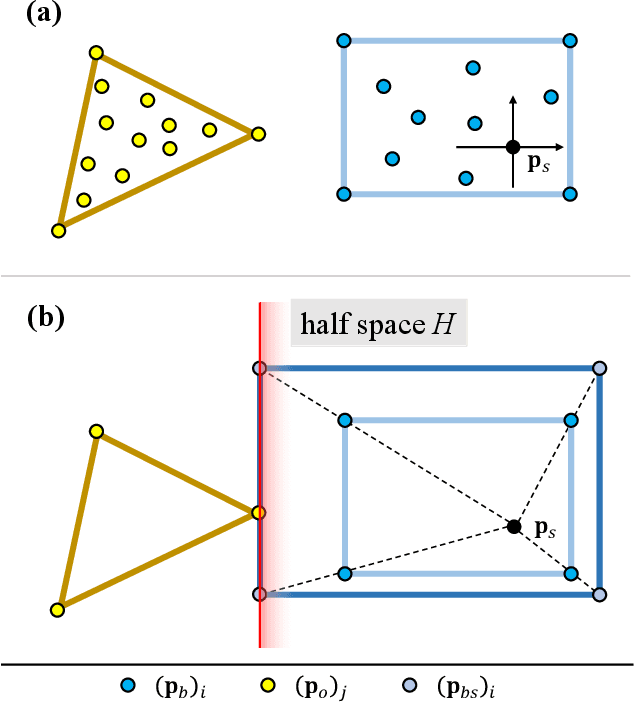
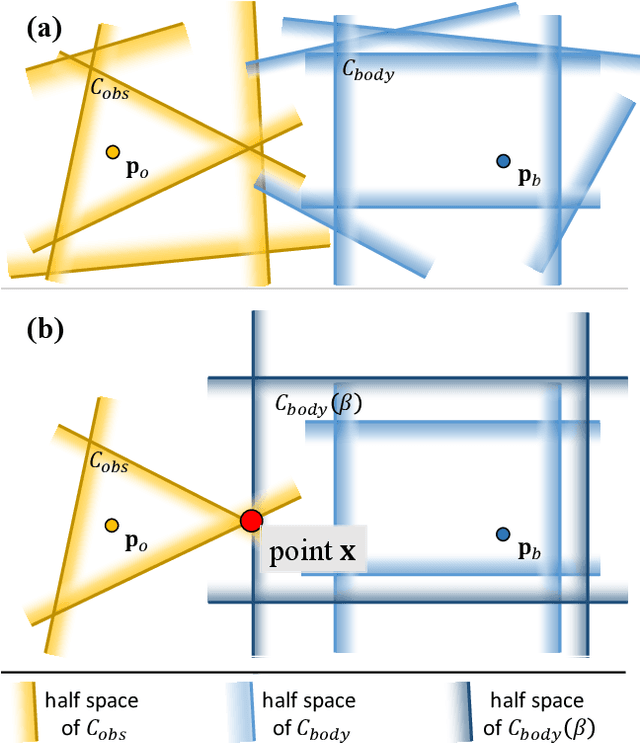
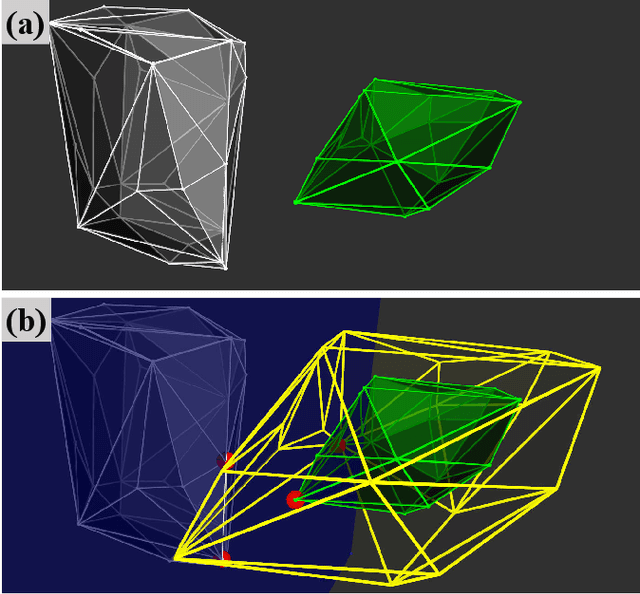
Collision evaluation is of vital importance in various applications. However, existing methods are either cumbersome to calculate or have a gap with the actual value. In this paper, we propose a zero-gap whole-body collision evaluation which can be formulated as a low dimensional linear program. This evaluation can be solved analytically in O(m) computational time, where m is the total number of the linear inequalities in this linear program. Moreover, the proposed method is efficient in obtaining its gradient, making it easy to apply to optimization-based applications.
Towards Confidence-guided Shape Completion for Robotic Applications
Sep 09, 2022
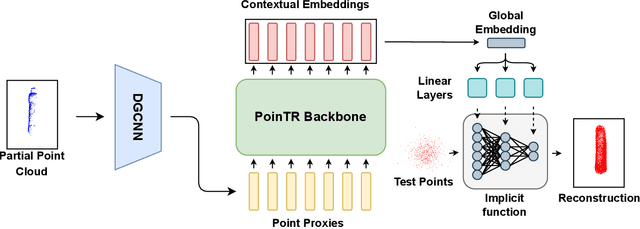


Many robotic tasks involving some form of 3D visual perception greatly benefit from a complete knowledge of the working environment. However, robots often have to tackle unstructured environments and their onboard visual sensors can only provide incomplete information due to limited workspaces, clutter or object self-occlusion. In recent years, deep learning architectures for shape completion have begun taking traction as effective means of inferring a complete 3D object representation from partial visual data. Nevertheless, most of the existing state-of-the-art approaches provide a fixed output resolution in the form of voxel grids, strictly related to the size of the neural network output stage. While this is enough for some tasks, e.g. obstacle avoidance in navigation, grasping and manipulation require finer resolutions and simply scaling up the neural network outputs is computationally expensive. In this paper, we address this limitation by proposing an object shape completion method based on an implicit 3D representation providing a confidence value for each reconstructed point. As a second contribution, we propose a gradient-based method for efficiently sampling such implicit function at an arbitrary resolution, tunable at inference time. We experimentally validate our approach by comparing reconstructed shapes with ground truths, and by deploying our shape completion algorithm in a robotic grasping pipeline. In both cases, we compare results with a state-of-the-art shape completion approach.
DC-MRTA: Decentralized Multi-Robot Task Allocation and Navigation in Complex Environments
Sep 07, 2022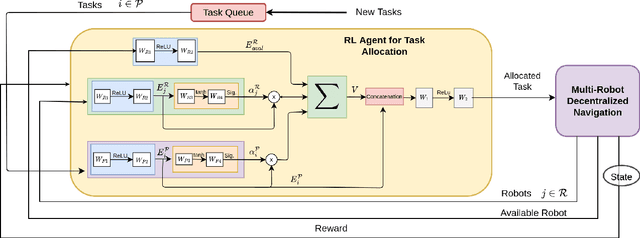
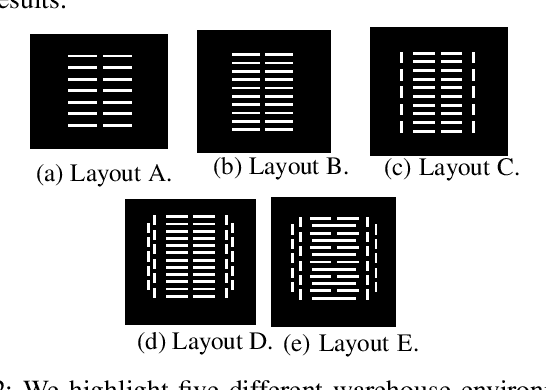
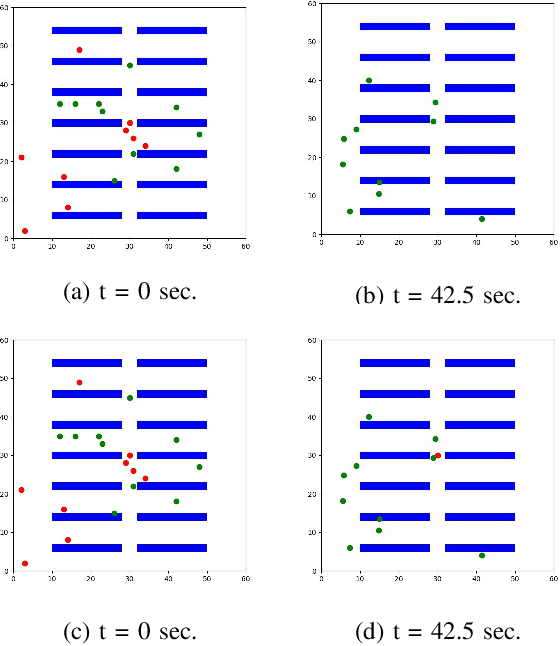
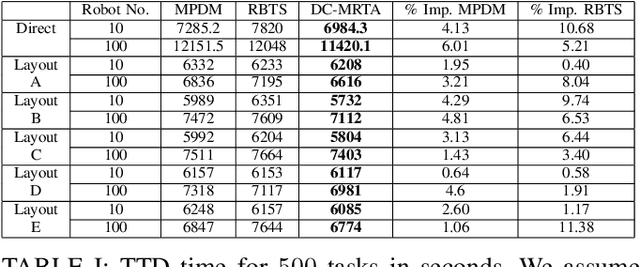
We present a novel reinforcement learning (RL) based task allocation and decentralized navigation algorithm for mobile robots in warehouse environments. Our approach is designed for scenarios in which multiple robots are used to perform various pick up and delivery tasks. We consider the problem of joint decentralized task allocation and navigation and present a two level approach to solve it. At the higher level, we solve the task allocation by formulating it in terms of Markov Decision Processes and choosing the appropriate rewards to minimize the Total Travel Delay (TTD). At the lower level, we use a decentralized navigation scheme based on ORCA that enables each robot to perform these tasks in an independent manner, and avoid collisions with other robots and dynamic obstacles. We combine these lower and upper levels by defining rewards for the higher level as the feedback from the lower level navigation algorithm. We perform extensive evaluation in complex warehouse layouts with large number of agents and highlight the benefits over state-of-the-art algorithms based on myopic pickup distance minimization and regret-based task selection. We observe improvement up to 14% in terms of task completion time and up-to 40% improvement in terms of computing collision-free trajectories for the robots.
Continuous-time stochastic gradient descent for optimizing over the stationary distribution of stochastic differential equations
Feb 14, 2022We develop a new continuous-time stochastic gradient descent method for optimizing over the stationary distribution of stochastic differential equation (SDE) models. The algorithm continuously updates the SDE model's parameters using an estimate for the gradient of the stationary distribution. The gradient estimate is simultaneously updated, asymptotically converging to the direction of steepest descent. We rigorously prove convergence of our online algorithm for linear SDE models and present numerical results for nonlinear examples. The proof requires analysis of the fluctuations of the parameter evolution around the direction of steepest descent. Bounds on the fluctuations are challenging to obtain due to the online nature of the algorithm (e.g., the stationary distribution will continuously change as the parameters change). We prove bounds for the solutions of a new class of Poisson partial differential equations, which are then used to analyze the parameter fluctuations in the algorithm.
Towards Better Long-range Time Series Forecasting using Generative Adversarial Networks
Oct 17, 2021
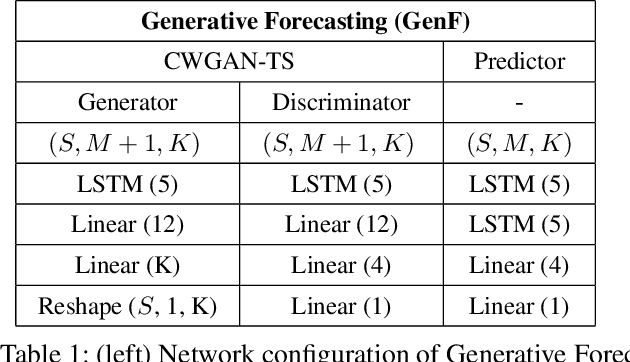

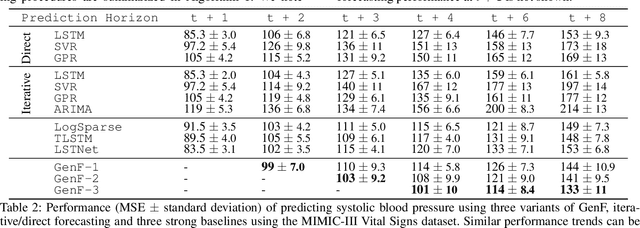
Accurate long-range forecasting of time series data is an important problem in many sectors, such as energy, healthcare, and finance. In recent years, Generative Adversarial Networks (GAN) have provided a revolutionary approach to many problems. However, the use of GAN to improve long-range time series forecasting remains relatively unexplored. In this paper, we utilize a Conditional Wasserstein GAN (CWGAN) and augment it with an error penalty term, leading to a new generative model which aims to generate high-quality synthetic time series data, called CWGAN-TS. By using such synthetic data, we develop a long-range forecasting approach, called Generative Forecasting (GenF), consisting of three components: (i) CWGAN-TS to generate synthetic data for the next few time steps. (ii) a predictor which makes long-range predictions based on generated and observed data. (iii) an information theoretic clustering (ITC) algorithm to better train the CWGAN-TS and the predictor. Our experimental results on three public datasets demonstrate that GenF significantly outperforms a diverse range of state-of-the-art benchmarks and classical approaches. In most cases, we find a 6% - 12% improvement in predictive performance (mean absolute error) and a 37% reduction in parameters compared to the best performing benchmark. Lastly, we conduct an ablation study to demonstrate the effectiveness of the CWGAN-TS and the ITC algorithm.