 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollision-aware In-hand 6D Object Pose Estimation using Multiple Vision-based Tactile Sensors
Jan 31, 2023



In this paper, we address the problem of estimating the in-hand 6D pose of an object in contact with multiple vision-based tactile sensors. We reason on the possible spatial configurations of the sensors along the object surface. Specifically, we filter contact hypotheses using geometric reasoning and a Convolutional Neural Network (CNN), trained on simulated object-agnostic images, to promote those that better comply with the actual tactile images from the sensors. We use the selected sensors configurations to optimize over the space of 6D poses using a Gradient Descent-based approach. We finally rank the obtained poses by penalizing those that are in collision with the sensors. We carry out experiments in simulation using the DIGIT vision-based sensor with several objects, from the standard YCB model set. The results demonstrate that our approach estimates object poses that are compatible with actual object-sensor contacts in $87.5\%$ of cases while reaching an average positional error in the order of $2$ centimeters. Our analysis also includes qualitative results of experiments with a real DIGIT sensor.
Towards Confidence-guided Shape Completion for Robotic Applications
Sep 09, 2022
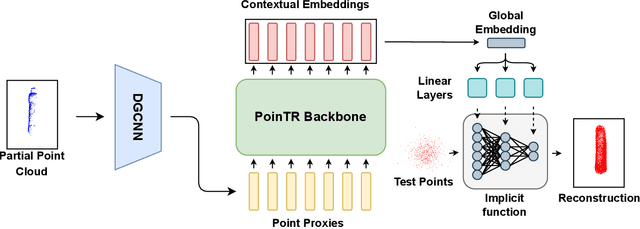


Many robotic tasks involving some form of 3D visual perception greatly benefit from a complete knowledge of the working environment. However, robots often have to tackle unstructured environments and their onboard visual sensors can only provide incomplete information due to limited workspaces, clutter or object self-occlusion. In recent years, deep learning architectures for shape completion have begun taking traction as effective means of inferring a complete 3D object representation from partial visual data. Nevertheless, most of the existing state-of-the-art approaches provide a fixed output resolution in the form of voxel grids, strictly related to the size of the neural network output stage. While this is enough for some tasks, e.g. obstacle avoidance in navigation, grasping and manipulation require finer resolutions and simply scaling up the neural network outputs is computationally expensive. In this paper, we address this limitation by proposing an object shape completion method based on an implicit 3D representation providing a confidence value for each reconstructed point. As a second contribution, we propose a gradient-based method for efficiently sampling such implicit function at an arbitrary resolution, tunable at inference time. We experimentally validate our approach by comparing reconstructed shapes with ground truths, and by deploying our shape completion algorithm in a robotic grasping pipeline. In both cases, we compare results with a state-of-the-art shape completion approach.
GRASPA 1.0: GRASPA is a Robot Arm graSping Performance benchmArk
Feb 12, 2020
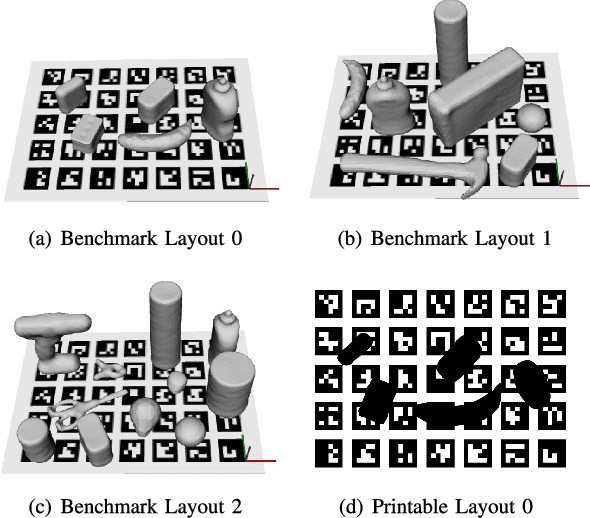

The use of benchmarks is a widespread and scientifically meaningful practice to validate performance of different approaches to the same task. In the context of robot grasping the use of common object sets has emerged in recent years, however no dominant protocols and metrics to test grasping pipelines have taken root yet. In this paper, we present version 1.0 of GRASPA, a benchmark to test effectiveness of grasping pipelines on physical robot setups. This approach tackles the complexity of such pipelines by proposing different metrics that account for the features and limits of the test platform. As an example application, we deploy GRASPA on the iCub humanoid robot and use it to benchmark our grasping pipeline. As closing remarks, we discuss how the GRASPA indicators we obtained as outcome can provide insight into how different steps of the pipeline affect the overall grasping performance.
* To cite this work, please refer to the journal reference entry. For more information, code, pictures and video please visit https://github.com/robotology/GRASPA-benchmark