 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Toward Intention Discovery for Early Malice Detection in Bitcoin
Sep 24, 2022
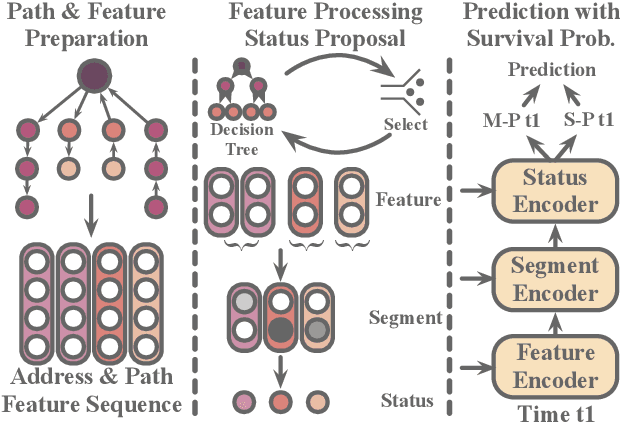
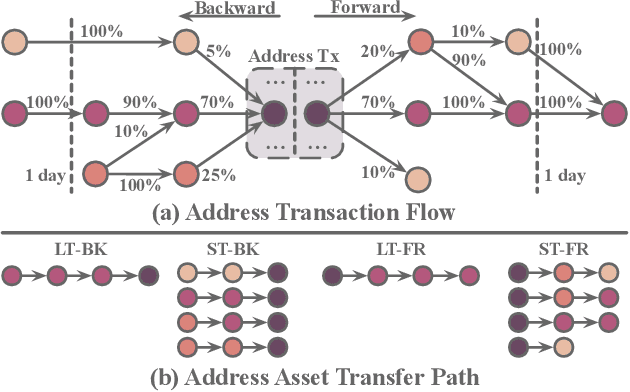
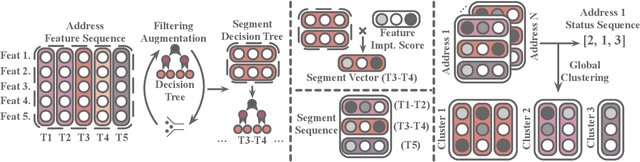
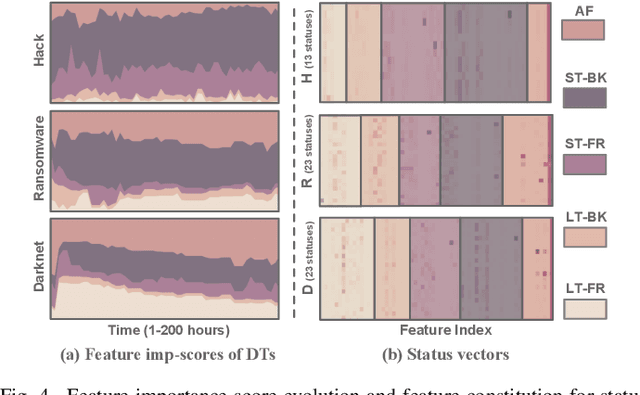
Bitcoin has been subject to illicit activities more often than probably any other financial assets, due to the pseudo-anonymous nature of its transacting entities. An ideal detection model is expected to achieve all the three properties of (I) early detection, (II) good interpretability, and (III) versatility for various illicit activities. However, existing solutions cannot meet all these requirements, as most of them heavily rely on deep learning without satisfying interpretability and are only available for retrospective analysis of a specific illicit type. First, we present asset transfer paths, which aim to describe addresses' early characteristics. Next, with a decision tree based strategy for feature selection and segmentation, we split the entire observation period into different segments and encode each as a segment vector. After clustering all these segment vectors, we get the global status vectors, essentially the basic unit to describe the whole intention. Finally, a hierarchical self-attention predictor predicts the label for the given address in real time. A survival module tells the predictor when to stop and proposes the status sequence, namely intention. % With the type-dependent selection strategy and global status vectors, our model can be applied to detect various illicit activities with strong interpretability. The well-designed predictor and particular loss functions strengthen the model's prediction speed and interpretability one step further. Extensive experiments on three real-world datasets show that our proposed algorithm outperforms state-of-the-art methods. Besides, additional case studies justify our model can not only explain existing illicit patterns but can also find new suspicious characters.
Big data analysis and distributed deep learning for next-generation intrusion detection system optimization
Sep 28, 2022With the growing use of information technology in all life domains, hacking has become more negatively effective than ever before. Also with developing technologies, attacks numbers are growing exponentially every few months and become more sophisticated so that traditional IDS becomes inefficient detecting them. This paper proposes a solution to detect not only new threats with higher detection rate and lower false positive than already used IDS, but also it could detect collective and contextual security attacks. We achieve those results by using Networking Chatbot, a deep recurrent neural network: Long Short Term Memory (LSTM) on top of Apache Spark Framework that has an input of flow traffic and traffic aggregation and the output is a language of two words, normal or abnormal. We propose merging the concepts of language processing, contextual analysis, distributed deep learning, big data, anomaly detection of flow analysis. We propose a model that describes the network abstract normal behavior from a sequence of millions of packets within their context and analyzes them in near real-time to detect point, collective and contextual anomalies. Experiments are done on MAWI dataset, and it shows better detection rate not only than signature IDS, but also better than traditional anomaly IDS. The experiment shows lower false positive, higher detection rate and better point anomalies detection. As for prove of contextual and collective anomalies detection, we discuss our claim and the reason behind our hypothesis. But the experiment is done on random small subsets of the dataset because of hardware limitations, so we share experiment and our future vision thoughts as we wish that full prove will be done in future by other interested researchers who have better hardware infrastructure than ours.
Lightweight Spatial-Channel Adaptive Coordination of Multilevel Refinement Enhancement Network for Image Reconstruction
Sep 17, 2022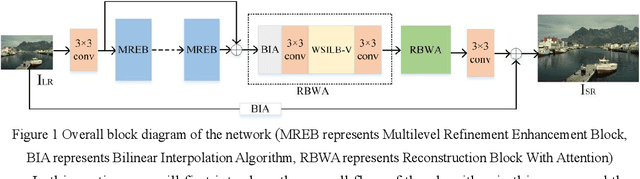
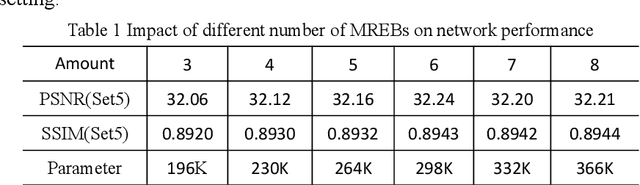
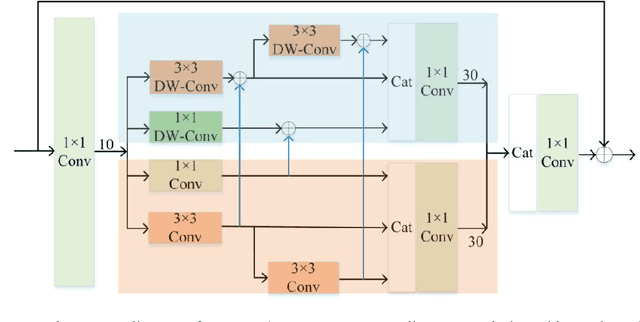
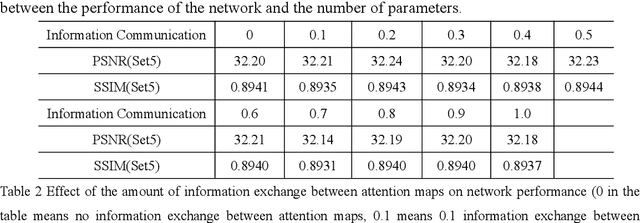
Benefiting from the vigorous development of deep learning, many CNN-based image super-resolution methods have emerged and achieved better results than traditional algorithms. However, it is difficult for most algorithms to adaptively adjust the spatial region and channel features at the same time, let alone the information exchange between them. In addition, the exchange of information between attention modules is even less visible to researchers. To solve these problems, we put forward a lightweight spatial-channel adaptive coordination of multilevel refinement enhancement networks(MREN). Specifically, we construct a space-channel adaptive coordination block, which enables the network to learn the spatial region and channel feature information of interest under different receptive fields. In addition, the information of the corresponding feature processing level between the spatial part and the channel part is exchanged with the help of jump connection to achieve the coordination between the two. We establish a communication bridge between attention modules through a simple linear combination operation, so as to more accurately and continuously guide the network to pay attention to the information of interest. Extensive experiments on several standard test sets have shown that our MREN achieves superior performance over other advanced algorithms with a very small number of parameters and very low computational complexity.
Collective Control for Arbitrary Configurations of Docked Modboats
Sep 08, 2022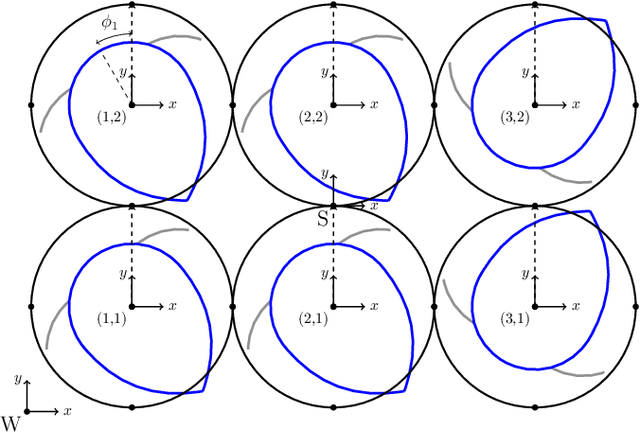
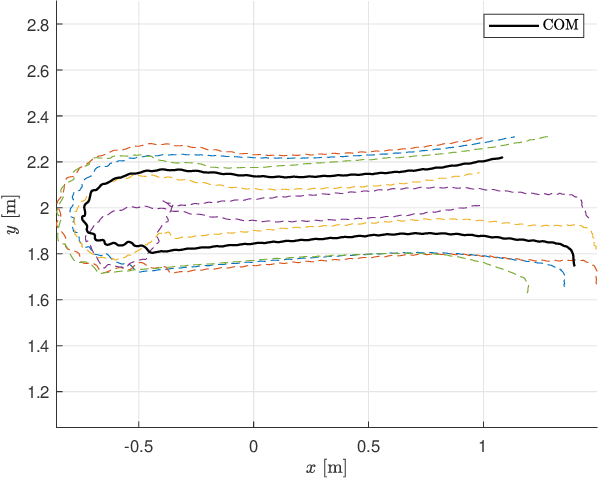
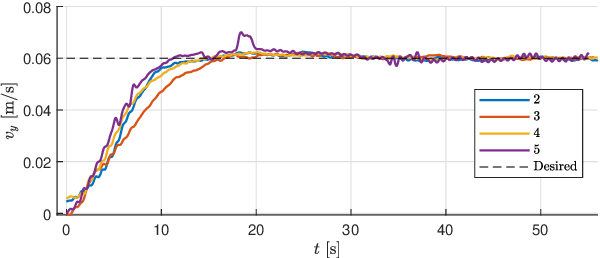
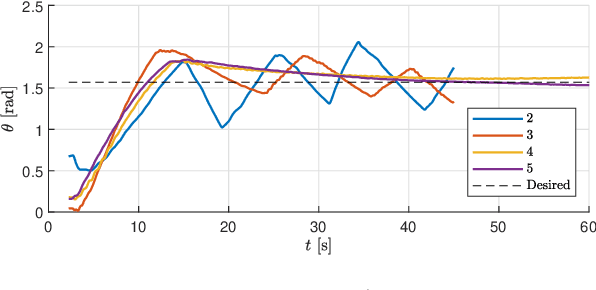
The Modboat is a low-cost, underactuated, modular robot capable of surface swimming, docking to other modules, and undocking from them using only a single motor and two passive flippers. Undocking is achieved by causing intentional self-collision between the tails of neighboring modules in certain configurations; this becomes a challenge, however, when collective swimming as one connected component is desirable. In this work, we develop a centralized control strategy to allow \textit{arbitrary} configurations of Modboats to swim as a single steerable vehicle and guarantee no accidental undocking. We also present a simplified model for hydrodynamic interactions between boats in a configuration that is tractable for real-time control. We experimentally demonstrate that our controller performs well, is consistent for configurations of various sizes and shapes, and can control both surge velocity and yaw angle simultaneously. Controllability is maintained while swimming, but pure yaw control causes lateral movement that cannot be counteracted by the presented framework.
Z-GCNETs: Time Zigzags at Graph Convolutional Networks for Time Series Forecasting
May 10, 2021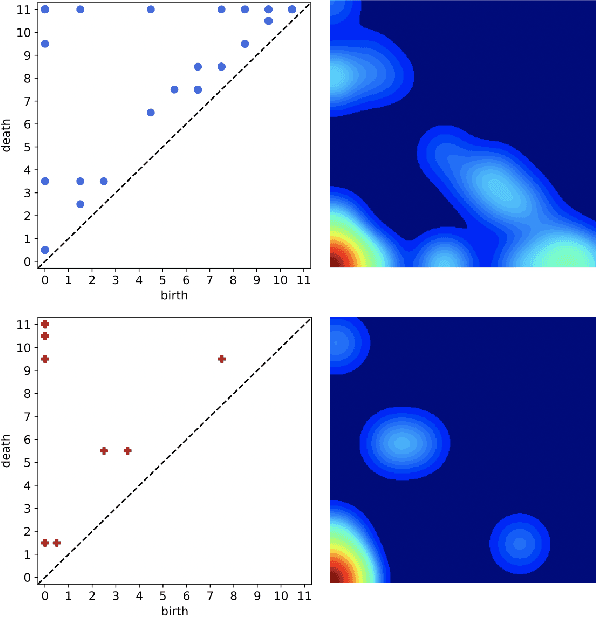
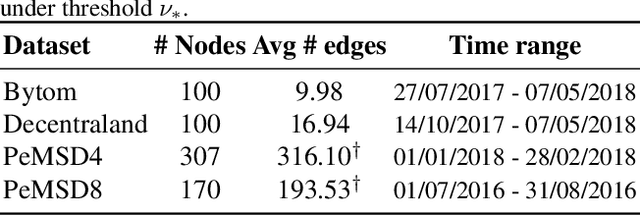
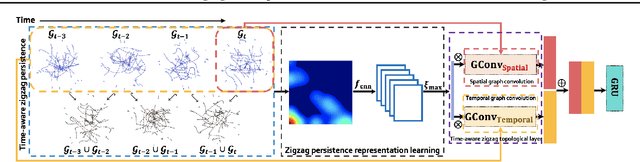
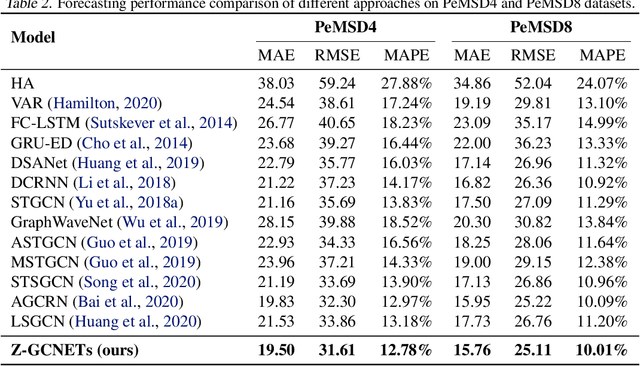
There recently has been a surge of interest in developing a new class of deep learning (DL) architectures that integrate an explicit time dimension as a fundamental building block of learning and representation mechanisms. In turn, many recent results show that topological descriptors of the observed data, encoding information on the shape of the dataset in a topological space at different scales, that is, persistent homology of the data, may contain important complementary information, improving both performance and robustness of DL. As convergence of these two emerging ideas, we propose to enhance DL architectures with the most salient time-conditioned topological information of the data and introduce the concept of zigzag persistence into time-aware graph convolutional networks (GCNs). Zigzag persistence provides a systematic and mathematically rigorous framework to track the most important topological features of the observed data that tend to manifest themselves over time. To integrate the extracted time-conditioned topological descriptors into DL, we develop a new topological summary, zigzag persistence image, and derive its theoretical stability guarantees. We validate the new GCNs with a time-aware zigzag topological layer (Z-GCNETs), in application to traffic forecasting and Ethereum blockchain price prediction. Our results indicate that Z-GCNET outperforms 13 state-of-the-art methods on 4 time series datasets.
A Multi-Dimensional Matrix Pencil-Based Channel Prediction Method for Massive MIMO with Mobility
Aug 03, 2022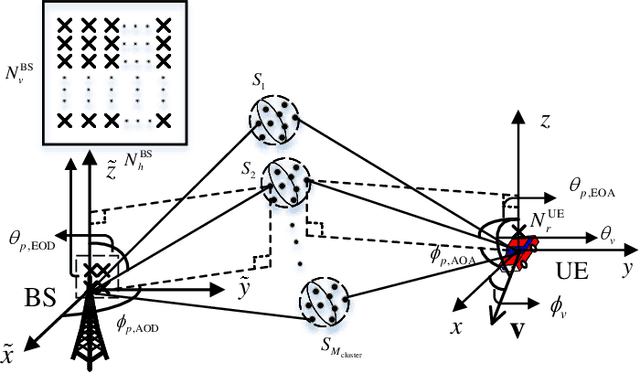
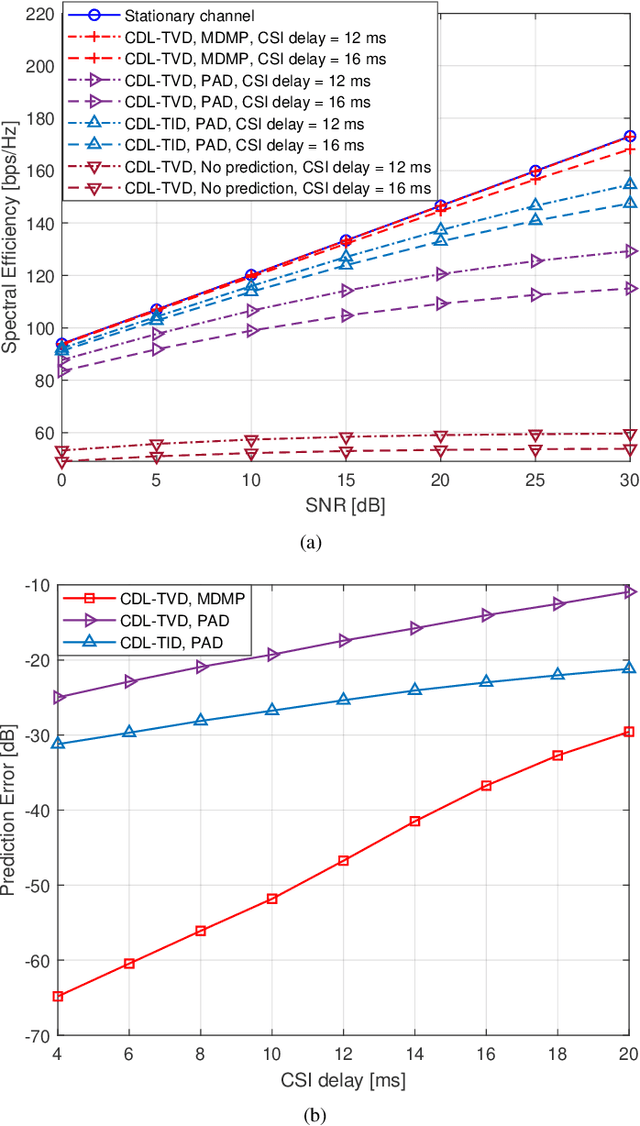
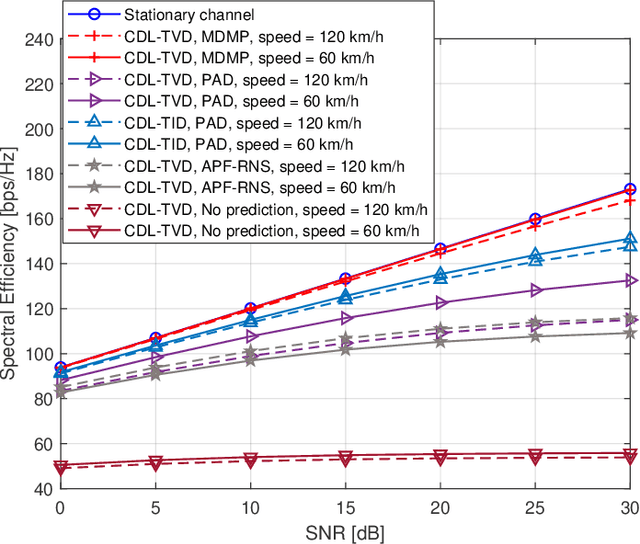
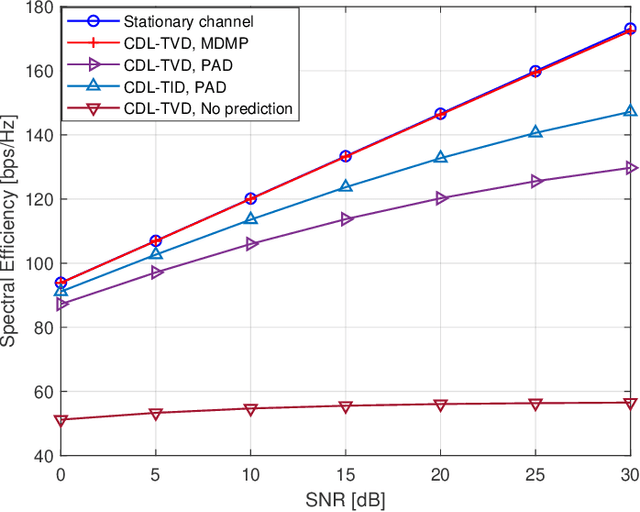
This paper addresses the mobility problem in massive multiple-input multiple-output systems, which leads to significant performance losses in the practical deployment of the fifth generation mobile communication networks. We propose a novel channel prediction method based on multi-dimensional matrix pencil (MDMP), which estimates the path parameters by exploiting the angular-frequency-domain and angular-time-domain structures of the wideband channel. The MDMP method also entails a novel path pairing scheme to pair the delay and Doppler, based on the super-resolution property of the angle estimation. Our method is able to deal with the realistic constraint of time-varying path delays introduced by user movements, which has not been considered so far in the literature. We prove theoretically that in the scenario with time-varying path delays, the prediction error converges to zero with the increasing number of the base station (BS) antennas, providing that only two arbitrary channel samples are known. We also derive a lower-bound of the number of the BS antennas to achieve a satisfactory performance. Simulation results under the industrial channel model of 3GPP demonstrate that our proposed MDMP method approaches the performance of the stationary scenario even when the users' velocity reaches 120 km/h and the latency of the channel state information is as large as 16 ms.
Private and polynomial time algorithms for learning Gaussians and beyond
Nov 22, 2021We present a fairly general framework for reducing $(\varepsilon, \delta)$ differentially private (DP) statistical estimation to its non-private counterpart. As the main application of this framework, we give a polynomial time and $(\varepsilon,\delta)$-DP algorithm for learning (unrestricted) Gaussian distributions in $\mathbb{R}^d$. The sample complexity of our approach for learning the Gaussian up to total variation distance $\alpha$ is $\widetilde{O}\left(\frac{d^2}{\alpha^2}+\frac{d^2 \sqrt{\ln{1/\delta}}}{\alpha\varepsilon} \right)$, matching (up to logarithmic factors) the best known information-theoretic (non-efficient) sample complexity upper bound of Aden-Ali, Ashtiani, Kamath~(ALT'21). In an independent work, Kamath, Mouzakis, Singhal, Steinke, and Ullman~(arXiv:2111.04609) proved a similar result using a different approach and with $O(d^{5/2})$ sample complexity dependence on $d$. As another application of our framework, we provide the first polynomial time $(\varepsilon, \delta)$-DP algorithm for robust learning of (unrestricted) Gaussians.
LoRD: Local 4D Implicit Representation for High-Fidelity Dynamic Human Modeling
Aug 18, 2022


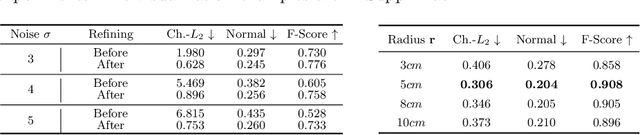
Recent progress in 4D implicit representation focuses on globally controlling the shape and motion with low dimensional latent vectors, which is prone to missing surface details and accumulating tracking error. While many deep local representations have shown promising results for 3D shape modeling, their 4D counterpart does not exist yet. In this paper, we fill this blank by proposing a novel Local 4D implicit Representation for Dynamic clothed human, named LoRD, which has the merits of both 4D human modeling and local representation, and enables high-fidelity reconstruction with detailed surface deformations, such as clothing wrinkles. Particularly, our key insight is to encourage the network to learn the latent codes of local part-level representation, capable of explaining the local geometry and temporal deformations. To make the inference at test-time, we first estimate the inner body skeleton motion to track local parts at each time step, and then optimize the latent codes for each part via auto-decoding based on different types of observed data. Extensive experiments demonstrate that the proposed method has strong capability for representing 4D human, and outperforms state-of-the-art methods on practical applications, including 4D reconstruction from sparse points, non-rigid depth fusion, both qualitatively and quantitatively.
One Network, Many Robots: Generative Graphical Inverse Kinematics
Sep 22, 2022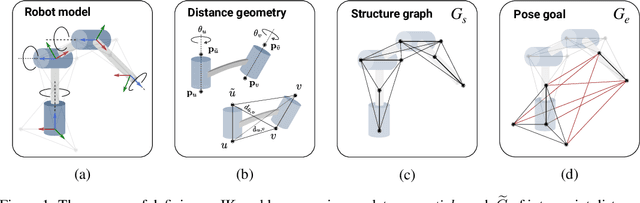
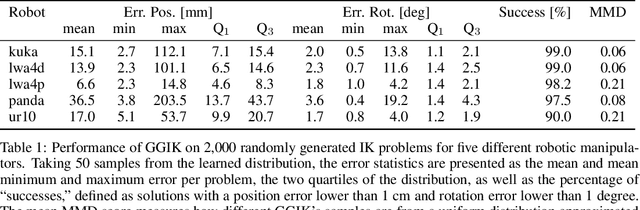
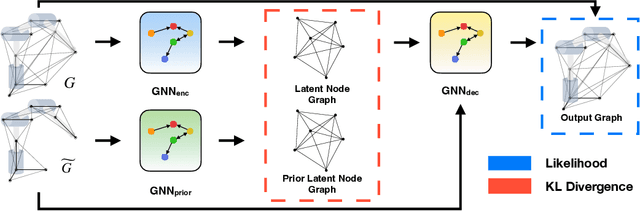

Quickly and reliably finding accurate inverse kinematics (IK) solutions remains a challenging problem for robotic manipulation. Existing numerical solvers are broadly applicable, but rely on local search techniques to manage highly nonconvex objective functions. Recently, learning-based approaches have shown promise as a means to generate fast and accurate IK results; learned solvers can easily be integrated with other learning algorithms in end-to-end systems. However, learning-based methods have an Achilles' heel: each robot of interest requires a specialized model which must be trained from scratch. To address this key shortcoming, we investigate a novel distance-geometric robot representation coupled with a graph structure that allows us to leverage the flexibility of graph neural networks (GNNs). We use this approach to train the first learned generative graphical inverse kinematics (GGIK) solver that is, crucially, "robot-agnostic"-a single model is able to provide IK solutions for a variety of different robots. Additionally, the generative nature of GGIK allows the solver to produce a large number of diverse solutions in parallel with minimal additional computation time, making it appropriate for applications such as sampling-based motion planning. Finally, GGIK can complement local IK solvers by providing reliable initializations. These advantages, as well as the ability to use task-relevant priors and to continuously improve with new data, suggest that GGIK has the potential to be a key component of flexible, learning-based robotic manipulation systems.
RetiFluidNet: A Self-Adaptive and Multi-Attention Deep Convolutional Network for Retinal OCT Fluid Segmentation
Sep 26, 2022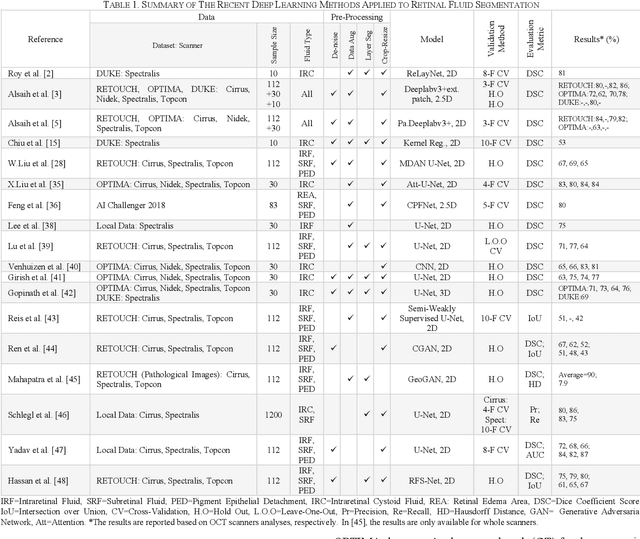
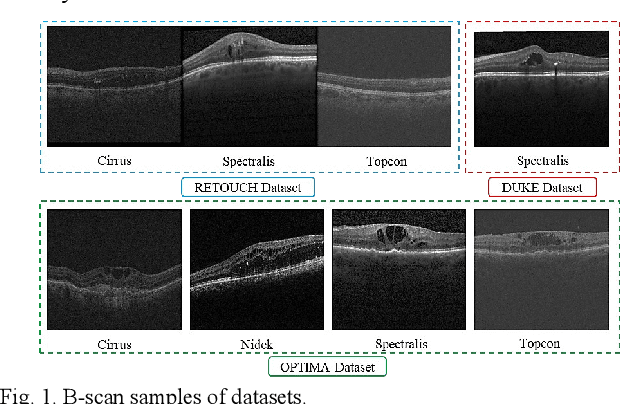
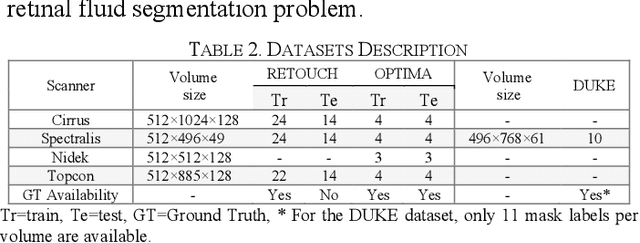
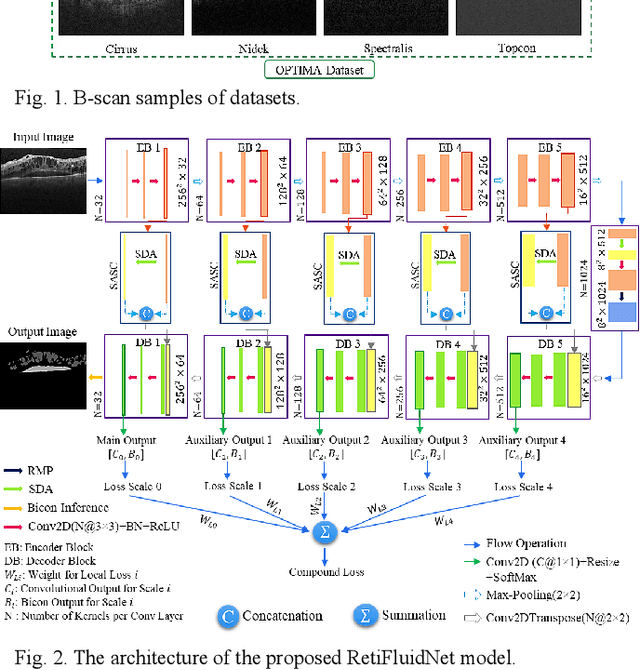
Optical coherence tomography (OCT) helps ophthalmologists assess macular edema, accumulation of fluids, and lesions at microscopic resolution. Quantification of retinal fluids is necessary for OCT-guided treatment management, which relies on a precise image segmentation step. As manual analysis of retinal fluids is a time-consuming, subjective, and error-prone task, there is increasing demand for fast and robust automatic solutions. In this study, a new convolutional neural architecture named RetiFluidNet is proposed for multi-class retinal fluid segmentation. The model benefits from hierarchical representation learning of textural, contextual, and edge features using a new self-adaptive dual-attention (SDA) module, multiple self-adaptive attention-based skip connections (SASC), and a novel multi-scale deep self supervision learning (DSL) scheme. The attention mechanism in the proposed SDA module enables the model to automatically extract deformation-aware representations at different levels, and the introduced SASC paths further consider spatial-channel interdependencies for concatenation of counterpart encoder and decoder units, which improve representational capability. RetiFluidNet is also optimized using a joint loss function comprising a weighted version of dice overlap and edge-preserved connectivity-based losses, where several hierarchical stages of multi-scale local losses are integrated into the optimization process. The model is validated based on three publicly available datasets: RETOUCH, OPTIMA, and DUKE, with comparisons against several baselines. Experimental results on the datasets prove the effectiveness of the proposed model in retinal OCT fluid segmentation and reveal that the suggested method is more effective than existing state-of-the-art fluid segmentation algorithms in adapting to retinal OCT scans recorded by various image scanning instruments.