 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
End-to-End Neural Audio Coding for Real-Time Communications
Jan 25, 2022
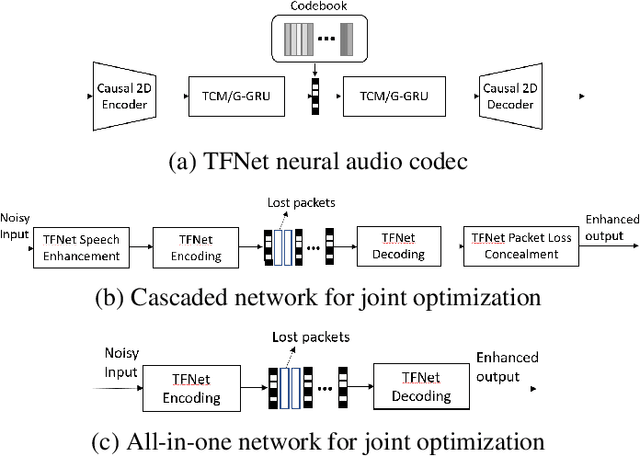
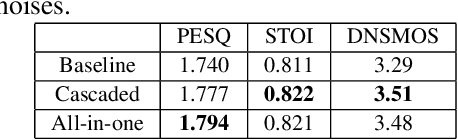
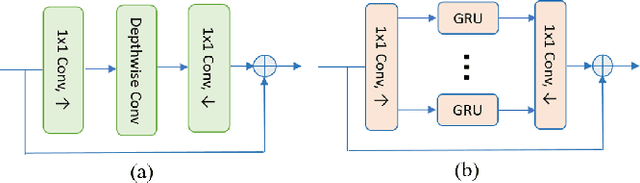
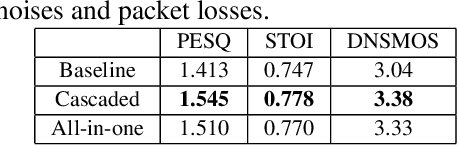
Deep-learning based methods have shown their advantages in audio coding over traditional ones but limited attention has been paid on real-time communications (RTC). This paper proposes the TFNet, an end-to-end neural audio codec with low latency for RTC. It takes an encoder-temporal filtering-decoder paradigm that seldom being investigated in audio coding. An interleaved structure is proposed for temporal filtering to capture both short-term and long-term temporal dependencies. Furthermore, with end-to-end optimization, the TFNet is jointly optimized with speech enhancement and packet loss concealment, yielding a one-for-all network for three tasks. Both subjective and objective results demonstrate the efficiency of the proposed TFNet.
Optimizing Industrial HVAC Systems with Hierarchical Reinforcement Learning
Sep 16, 2022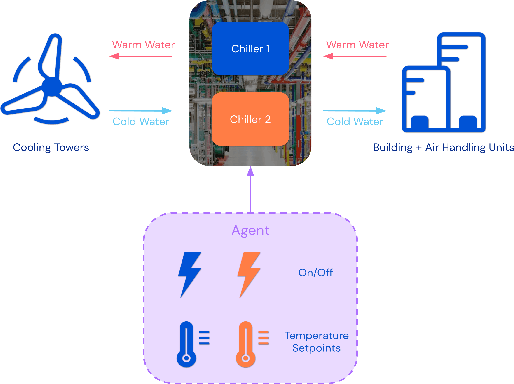
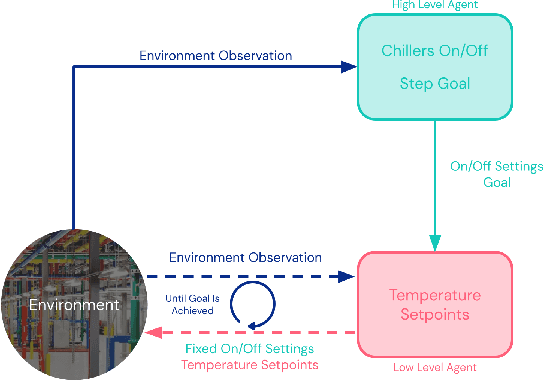
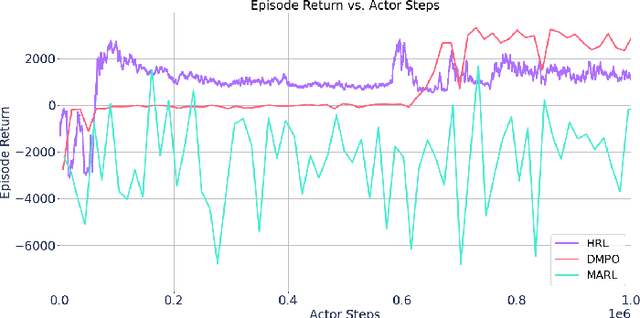
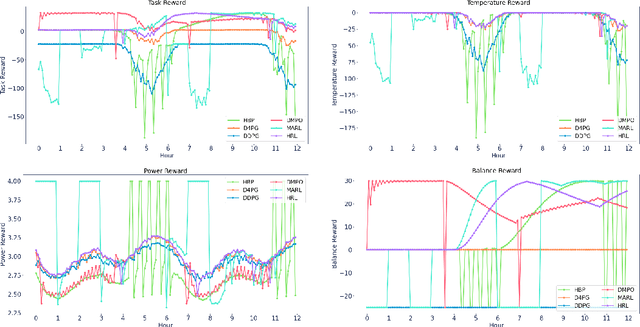
Reinforcement learning (RL) techniques have been developed to optimize industrial cooling systems, offering substantial energy savings compared to traditional heuristic policies. A major challenge in industrial control involves learning behaviors that are feasible in the real world due to machinery constraints. For example, certain actions can only be executed every few hours while other actions can be taken more frequently. Without extensive reward engineering and experimentation, an RL agent may not learn realistic operation of machinery. To address this, we use hierarchical reinforcement learning with multiple agents that control subsets of actions according to their operation time scales. Our hierarchical approach achieves energy savings over existing baselines while maintaining constraints such as operating chillers within safe bounds in a simulated HVAC control environment.
A Dataset for Answering Time-Sensitive Questions
Aug 17, 2021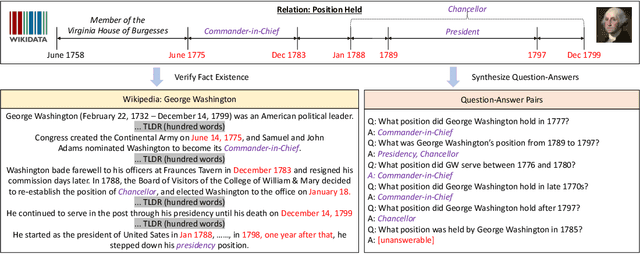
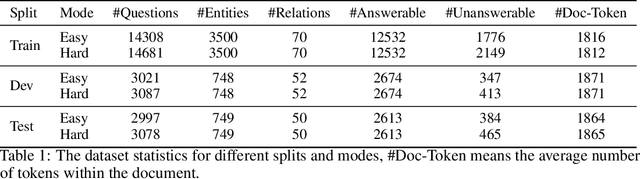
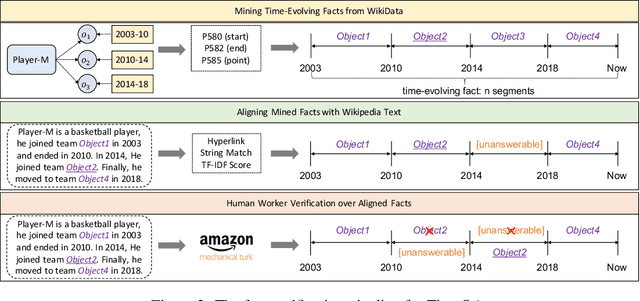
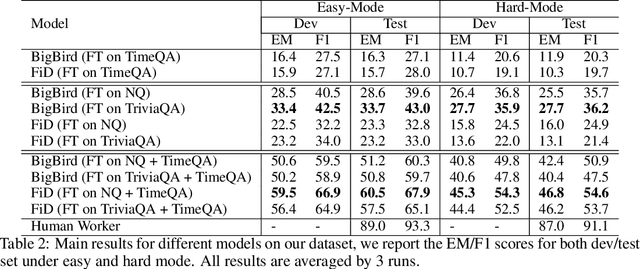
Time is an important dimension in our physical world. Lots of facts can evolve with respect to time. For example, the U.S. President might change every four years. Therefore, it is important to consider the time dimension and empower the existing QA models to reason over time. However, the existing QA datasets contain rather few time-sensitive questions, hence not suitable for diagnosing or benchmarking the model's temporal reasoning capability. In order to promote research in this direction, we propose to construct a time-sensitive QA dataset. The dataset is constructed by 1) mining time-evolving facts from WikiData and align them to their corresponding Wikipedia page, 2) employing crowd workers to verify and calibrate these noisy facts, 3) generating question-answer pairs based on the annotated time-sensitive facts. Our dataset poses two novel challenges: 1) the model needs to understand both explicit and implicit mention of time information in the long document, 2) the model needs to perform temporal reasoning like comparison, addition, subtraction. We evaluate different SoTA long-document QA systems like BigBird and FiD on our dataset. The best-performing model FiD can only achieve 46\% accuracy, still far behind the human performance of 87\%. We demonstrate that these models are still lacking the ability to perform robust temporal understanding and reasoning. Therefore, we believe that our dataset could serve as a benchmark to empower future studies in temporal reasoning. The dataset and code are released in~\url{https://github.com/wenhuchen/Time-Sensitive-QA}.
Continuous-Time Audiovisual Fusion with Recurrence vs. Attention for In-The-Wild Affect Recognition
Mar 29, 2022
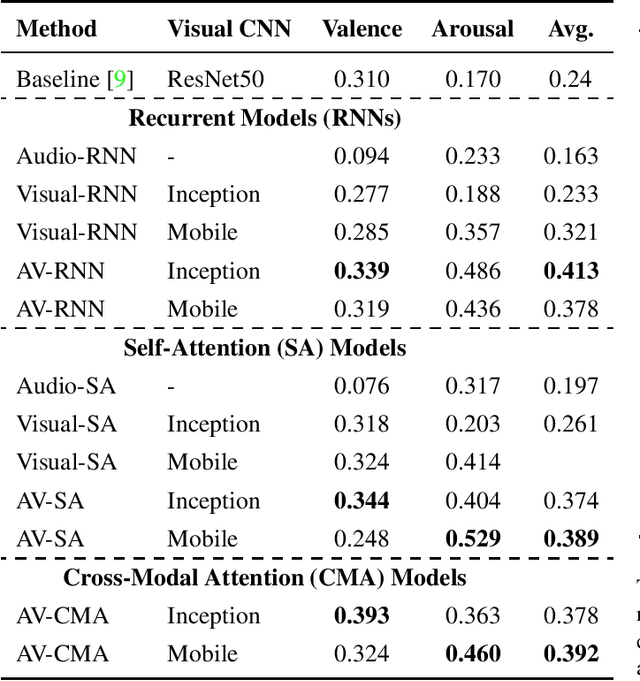
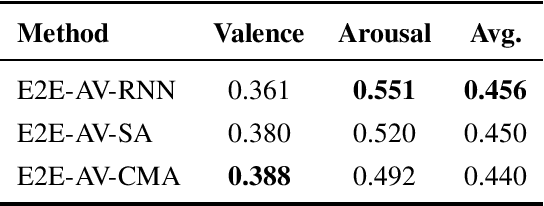
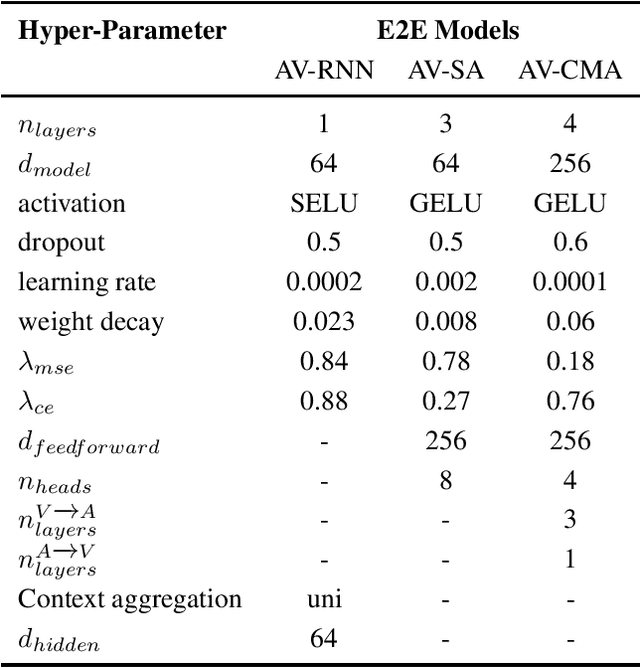
In this paper, we present our submission to 3rd Affective Behavior Analysis in-the-wild (ABAW) challenge. Learningcomplex interactions among multimodal sequences is critical to recognise dimensional affect from in-the-wild audiovisual data. Recurrence and attention are the two widely used sequence modelling mechanisms in the literature. To clearly understand the performance differences between recurrent and attention models in audiovisual affect recognition, we present a comprehensive evaluation of fusion models based on LSTM-RNNs, self-attention and cross-modal attention, trained for valence and arousal estimation. Particularly, we study the impact of some key design choices: the modelling complexity of CNN backbones that provide features to the the temporal models, with and without end-to-end learning. We trained the audiovisual affect recognition models on in-the-wild ABAW corpus by systematically tuning the hyper-parameters involved in the network architecture design and training optimisation. Our extensive evaluation of the audiovisual fusion models shows that LSTM-RNNs can outperform the attention models when coupled with low-complex CNN backbones and trained in an end-to-end fashion, implying that attention models may not necessarily be the optimal choice for continuous-time multimodal emotion recognition.
Risk-Aware Model Predictive Path Integral Control Using Conditional Value-at-Risk
Sep 26, 2022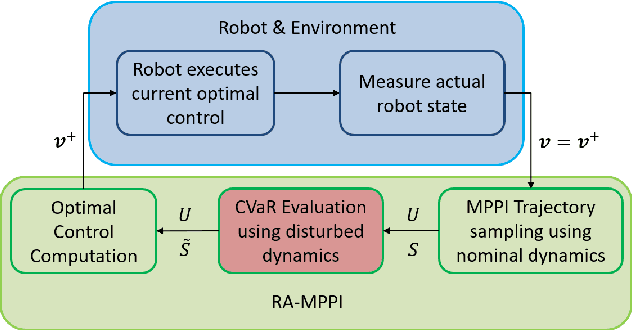
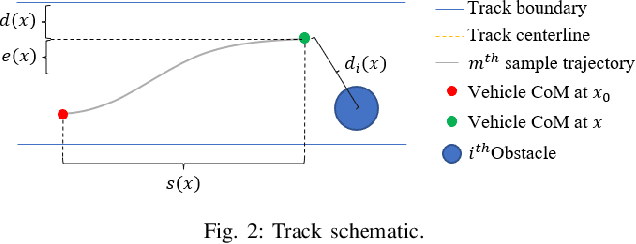
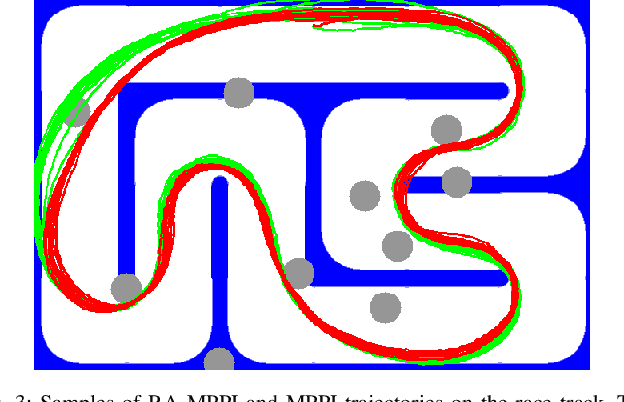
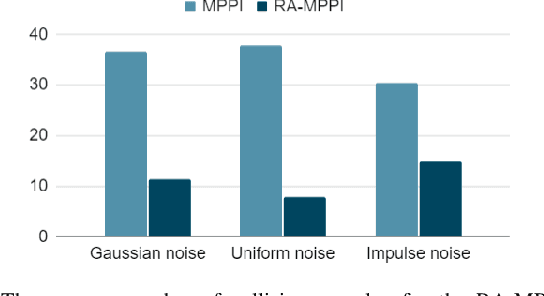
In this paper, we present a novel Model Predictive Control method for autonomous robots subject to arbitrary forms of uncertainty. The proposed Risk-Aware Model Predictive Path Integral (RA-MPPI) control utilizes the Conditional Value-at-Risk (CVaR) measure to generate optimal control actions for safety-critical robotic applications. Different from most existing Stochastic MPCs and CVaR optimization methods that linearize the original dynamics and formulate control tasks as convex programs, the proposed method directly uses the original dynamics without restricting the form of the cost functions or the noise. We apply the novel RA-MPPI controller to an autonomous vehicle to perform aggressive driving maneuvers in cluttered environments. Our simulations and experiments show that the proposed RA-MPPI controller can achieve about the same lap time with significantly fewer collisions compared to the baseline MPPI controller. The proposed controller performs on-line computation at an update frequency of up to 80Hz, utilizing modern Graphics Processing Units (GPUs) to multi-thread the generation of trajectories as well as the CVaR values.
Real-Time Seizure Detection using EEG: A Comprehensive Comparison of Recent Approaches under a Realistic Setting
Jan 21, 2022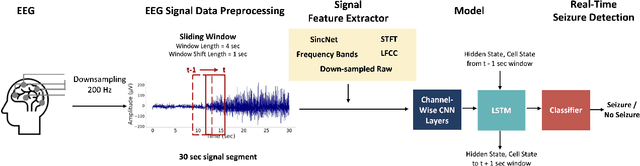
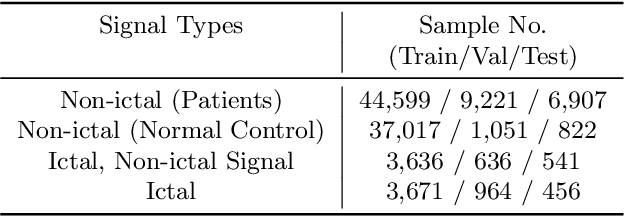
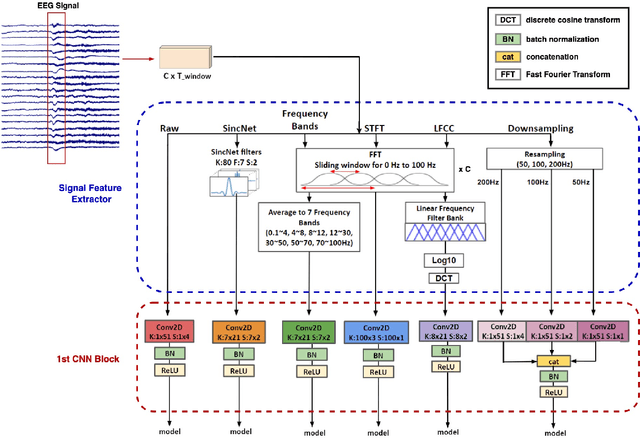
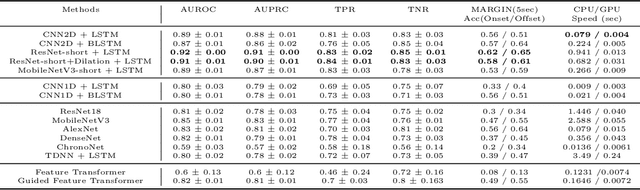
Electroencephalogram (EEG) is an important diagnostic test that physicians use to record brain activity and detect seizures by monitoring the signals. There have been several attempts to detect seizures and abnormalities in EEG signals with modern deep learning models to reduce the clinical burden. However, they cannot be fairly compared against each other as they were tested in distinct experimental settings. Also, some of them are not trained in real-time seizure detection tasks, making it hard for on-device applications. Therefore in this work, for the first time, we extensively compare multiple state-of-the-art models and signal feature extractors in a real-time seizure detection framework suitable for real-world application, using various evaluation metrics including a new one we propose to evaluate more practical aspects of seizure detection models. Our code is available at https://github.com/AITRICS/EEG_real_time_seizure_detection.
Detection of Interacting Variables for Generalized Linear Models via Neural Networks
Sep 16, 2022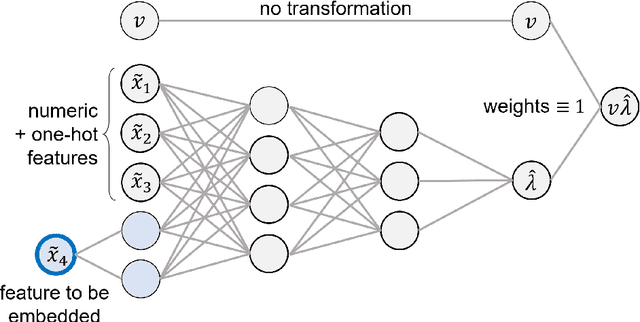
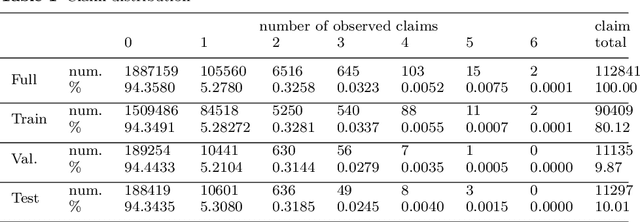
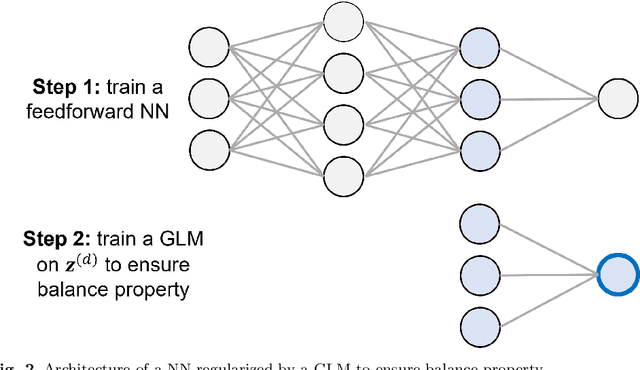

The quality of generalized linear models (GLMs), frequently used by insurance companies, depends on the choice of interacting variables. The search for interactions is time-consuming, especially for data sets with a large number of variables, depends much on expert judgement of actuaries, and often relies on visual performance indicators. Therefore, we present an approach to automating the process of finding interactions that should be added to GLMs to improve their predictive power. Our approach relies on neural networks and a model-specific interaction detection method, which is computationally faster than the traditionally used methods like Friedman H-Statistic or SHAP values. In numerical studies, we provide the results of our approach on different data sets: open-source data, artificial data, and proprietary data.
Time in a Box: Advancing Knowledge Graph Completion with Temporal Scopes
Nov 12, 2021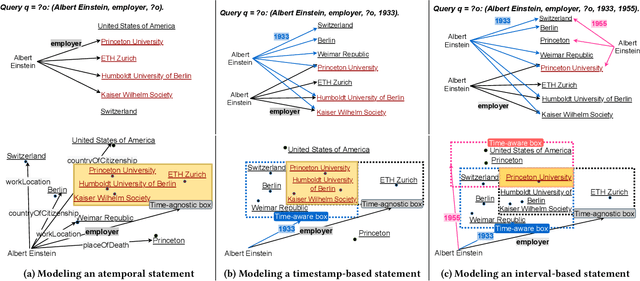
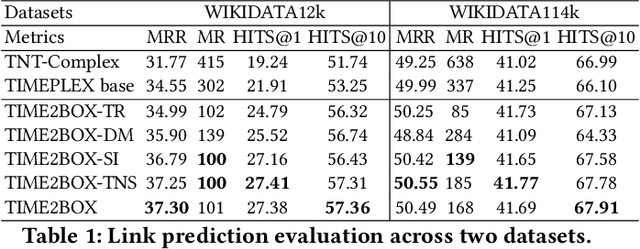
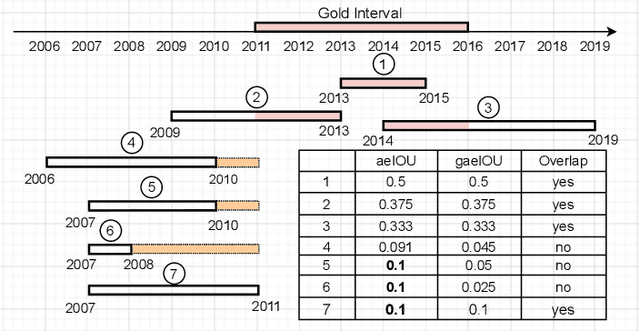
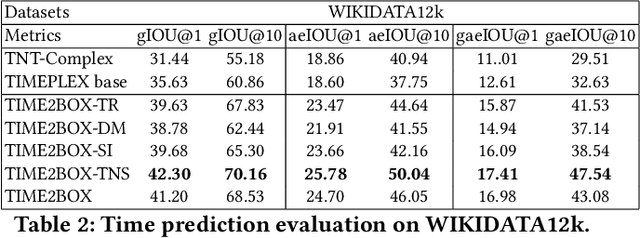
Almost all statements in knowledge bases have a temporal scope during which they are valid. Hence, knowledge base completion (KBC) on temporal knowledge bases (TKB), where each statement \textit{may} be associated with a temporal scope, has attracted growing attention. Prior works assume that each statement in a TKB \textit{must} be associated with a temporal scope. This ignores the fact that the scoping information is commonly missing in a KB. Thus prior work is typically incapable of handling generic use cases where a TKB is composed of temporal statements with/without a known temporal scope. In order to address this issue, we establish a new knowledge base embedding framework, called TIME2BOX, that can deal with atemporal and temporal statements of different types simultaneously. Our main insight is that answers to a temporal query always belong to a subset of answers to a time-agnostic counterpart. Put differently, time is a filter that helps pick out answers to be correct during certain periods. We introduce boxes to represent a set of answer entities to a time-agnostic query. The filtering functionality of time is modeled by intersections over these boxes. In addition, we generalize current evaluation protocols on time interval prediction. We describe experiments on two datasets and show that the proposed method outperforms state-of-the-art (SOTA) methods on both link prediction and time prediction.
Differentiable physics-enabled closure modeling for Burgers' turbulence
Sep 23, 2022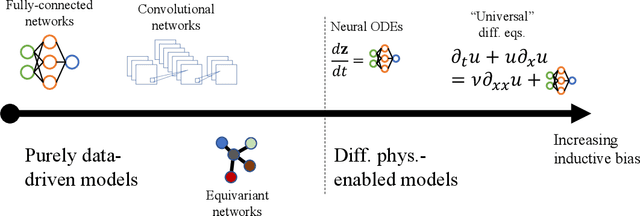
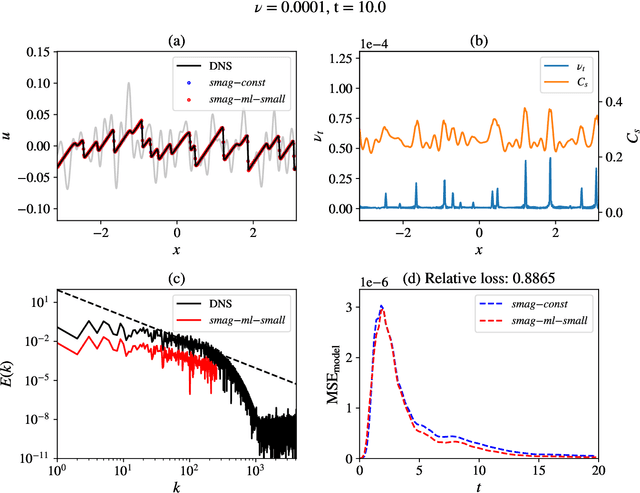
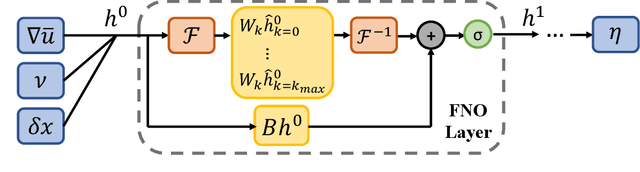
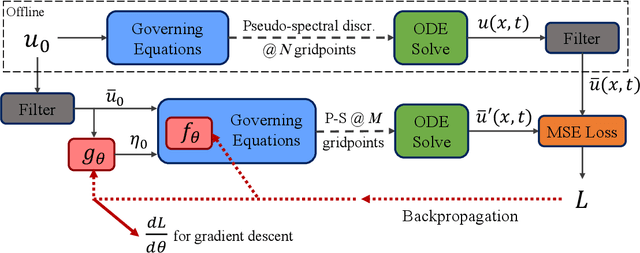
Data-driven turbulence modeling is experiencing a surge in interest following algorithmic and hardware developments in the data sciences. We discuss an approach using the differentiable physics paradigm that combines known physics with machine learning to develop closure models for Burgers' turbulence. We consider the 1D Burgers system as a prototypical test problem for modeling the unresolved terms in advection-dominated turbulence problems. We train a series of models that incorporate varying degrees of physical assumptions on an a posteriori loss function to test the efficacy of models across a range of system parameters, including viscosity, time, and grid resolution. We find that constraining models with inductive biases in the form of partial differential equations that contain known physics or existing closure approaches produces highly data-efficient, accurate, and generalizable models, outperforming state-of-the-art baselines. Addition of structure in the form of physics information also brings a level of interpretability to the models, potentially offering a stepping stone to the future of closure modeling.
Feature embedding in click-through rate prediction
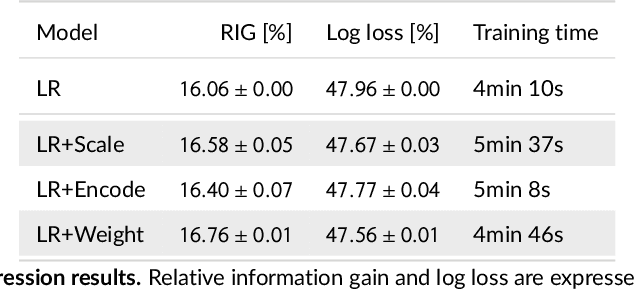
Sep 20, 2022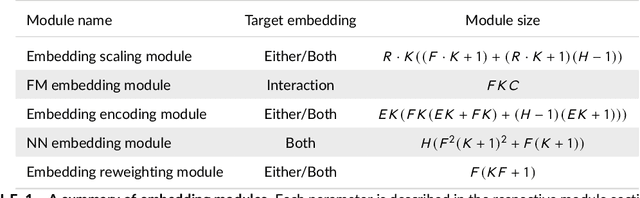
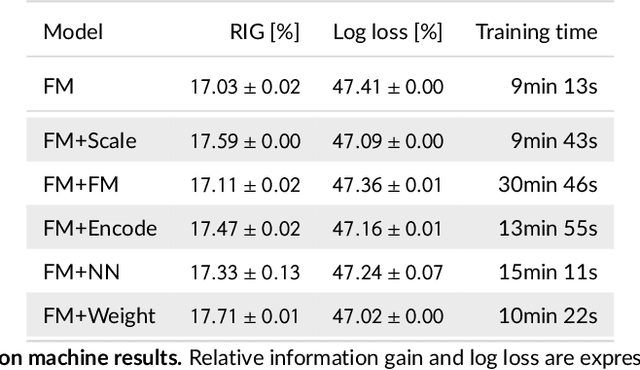
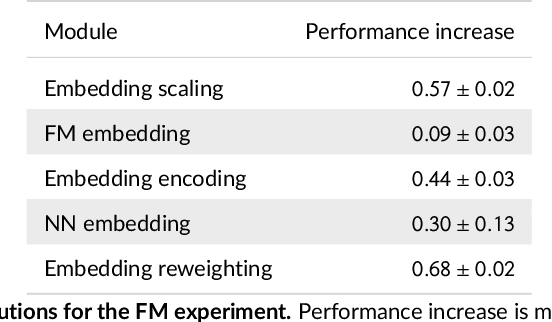
We tackle the challenge of feature embedding for the purposes of improving the click-through rate prediction process. We select three models: logistic regression, factorization machines and deep factorization machines, as our baselines and propose five different feature embedding modules: embedding scaling, FM embedding, embedding encoding, NN embedding and the embedding reweighting module. The embedding modules act as a way to improve baseline model feature embeddings and are trained alongside the rest of the model parameters in an end-to-end manner. Each module is individually added to a baseline model to obtain a new augmented model. We test the predictive performance of our augmented models on a publicly accessible dataset used for benchmarking click-through rate prediction models. Our results show that several proposed embedding modules provide an important increase in predictive performance without a drastic increase in training time.