 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't worry about mistakes! Glass Segmentation Network via Mistake Correction
Apr 21, 2023Recall one time when we were in an unfamiliar mall. We might mistakenly think that there exists or does not exist a piece of glass in front of us. Such mistakes will remind us to walk more safely and freely at the same or a similar place next time. To absorb the human mistake correction wisdom, we propose a novel glass segmentation network to detect transparent glass, dubbed GlassSegNet. Motivated by this human behavior, GlassSegNet utilizes two key stages: the identification stage (IS) and the correction stage (CS). The IS is designed to simulate the detection procedure of human recognition for identifying transparent glass by global context and edge information. The CS then progressively refines the coarse prediction by correcting mistake regions based on gained experience. Extensive experiments show clear improvements of our GlassSegNet over thirty-four state-of-the-art methods on three benchmark datasets.
Time-Variance Aware Real-Time Speech Enhancement
Feb 25, 2023



Time-variant factors often occur in real-world full-duplex communication applications. Some of them are caused by the complex environment such as non-stationary environmental noises and varying acoustic path while some are caused by the communication system such as the dynamic delay between the far-end and near-end signals. Current end-to-end deep neural network (DNN) based methods usually model the time-variant components implicitly and can hardly handle the unpredictable time-variance in real-time speech enhancement. To explicitly capture the time-variant components, we propose a dynamic kernel generation (DKG) module that can be introduced as a learnable plug-in to a DNN-based end-to-end pipeline. Specifically, the DKG module generates a convolutional kernel regarding to each input audio frame, so that the DNN model is able to dynamically adjust its weights according to the input signal during inference. Experimental results verify that DKG module improves the performance of the model under time-variant scenarios, in the joint acoustic echo cancellation (AEC) and deep noise suppression (DNS) tasks.
Real-time speech enhancement with dynamic attention span
Feb 21, 2023



For real-time speech enhancement (SE) including noise suppression, dereverberation and acoustic echo cancellation, the time-variance of the audio signals becomes a severe challenge. The causality and memory usage limit that only the historical information can be used for the system to capture the time-variant characteristics. We propose to adaptively change the receptive field according to the input signal in deep neural network based SE model. Specifically, in an encoder-decoder framework, a dynamic attention span mechanism is introduced to all the attention modules for controlling the size of historical content used for processing the current frame. Experimental results verify that this dynamic mechanism can better track time-variant factors and capture speech-related characteristics, benefiting to both interference removing and speech quality retaining.
Scale-Semantic Joint Decoupling Network for Image-text Retrieval in Remote Sensing
Dec 12, 2022



Image-text retrieval in remote sensing aims to provide flexible information for data analysis and application. In recent years, state-of-the-art methods are dedicated to ``scale decoupling'' and ``semantic decoupling'' strategies to further enhance the capability of representation. However, these previous approaches focus on either the disentangling scale or semantics but ignore merging these two ideas in a union model, which extremely limits the performance of cross-modal retrieval models. To address these issues, we propose a novel Scale-Semantic Joint Decoupling Network (SSJDN) for remote sensing image-text retrieval. Specifically, we design the Bidirectional Scale Decoupling (BSD) module, which exploits Salience Feature Extraction (SFE) and Salience-Guided Suppression (SGS) units to adaptively extract potential features and suppress cumbersome features at other scales in a bidirectional pattern to yield different scale clues. Besides, we design the Label-supervised Semantic Decoupling (LSD) module by leveraging the category semantic labels as prior knowledge to supervise images and texts probing significant semantic-related information. Finally, we design a Semantic-guided Triple Loss (STL), which adaptively generates a constant to adjust the loss function to improve the probability of matching the same semantic image and text and shorten the convergence time of the retrieval model. Our proposed SSJDN outperforms state-of-the-art approaches in numerical experiments conducted on four benchmark remote sensing datasets.
End-to-End Neural Audio Coding for Real-Time Communications
Jan 25, 2022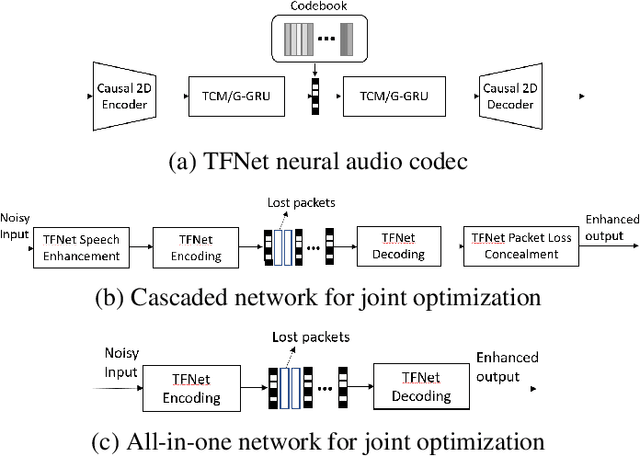
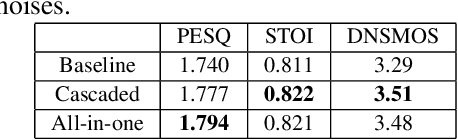
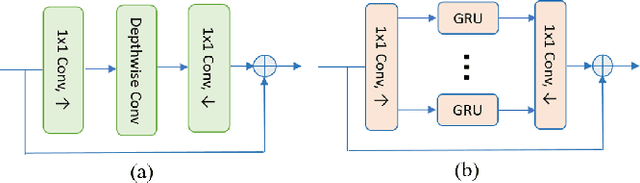
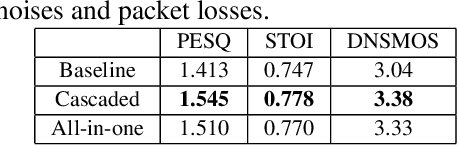
Deep-learning based methods have shown their advantages in audio coding over traditional ones but limited attention has been paid on real-time communications (RTC). This paper proposes the TFNet, an end-to-end neural audio codec with low latency for RTC. It takes an encoder-temporal filtering-decoder paradigm that seldom being investigated in audio coding. An interleaved structure is proposed for temporal filtering to capture both short-term and long-term temporal dependencies. Furthermore, with end-to-end optimization, the TFNet is jointly optimized with speech enhancement and packet loss concealment, yielding a one-for-all network for three tasks. Both subjective and objective results demonstrate the efficiency of the proposed TFNet.