 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning to Learn with Generative Models of Neural Network Checkpoints
Sep 26, 2022
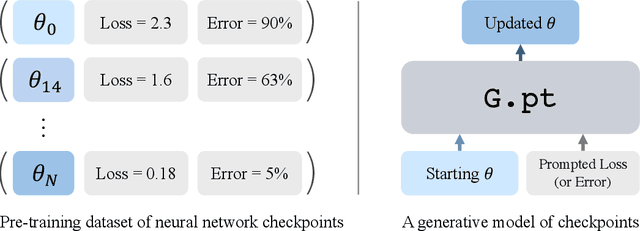
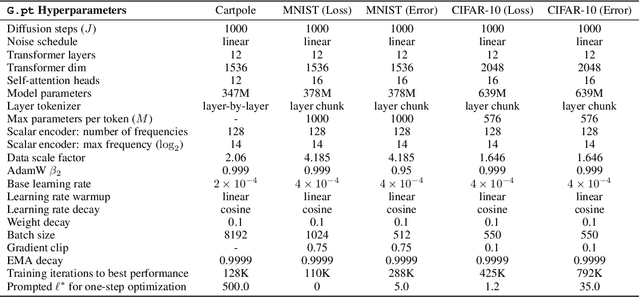
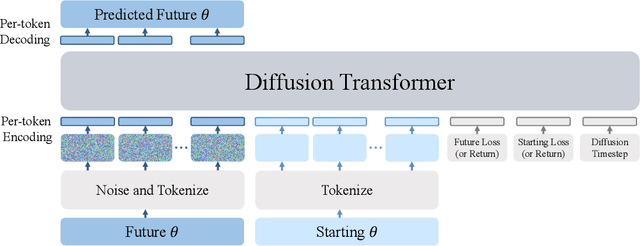
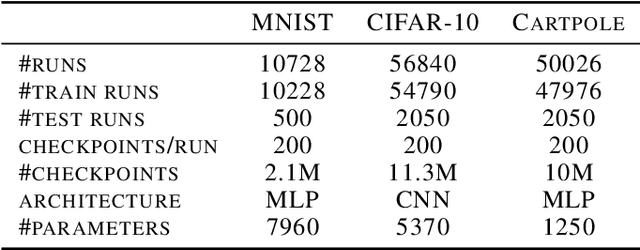
We explore a data-driven approach for learning to optimize neural networks. We construct a dataset of neural network checkpoints and train a generative model on the parameters. In particular, our model is a conditional diffusion transformer that, given an initial input parameter vector and a prompted loss, error, or return, predicts the distribution over parameter updates that achieve the desired metric. At test time, it can optimize neural networks with unseen parameters for downstream tasks in just one update. We find that our approach successfully generates parameters for a wide range of loss prompts. Moreover, it can sample multimodal parameter solutions and has favorable scaling properties. We apply our method to different neural network architectures and tasks in supervised and reinforcement learning.
TAKDE: Temporal Adaptive Kernel Density Estimator for Real-Time Dynamic Density Estimation
Mar 15, 2022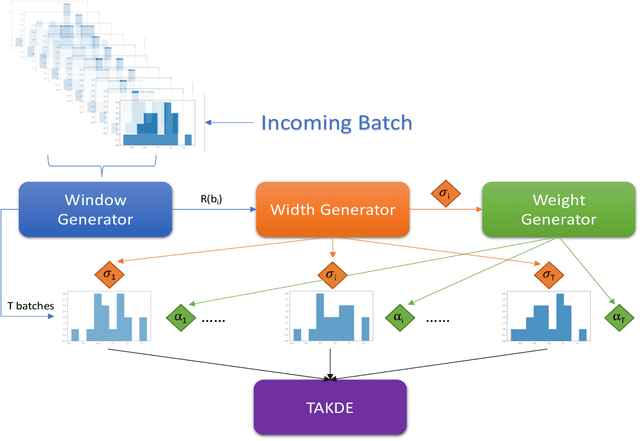
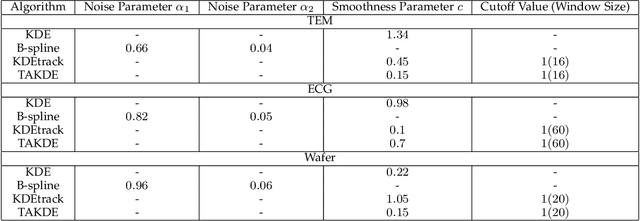
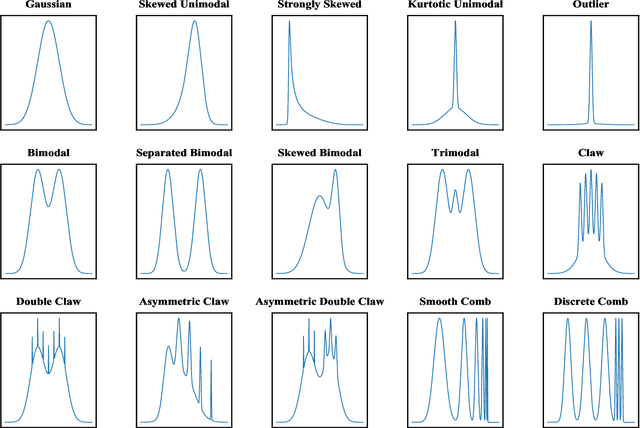
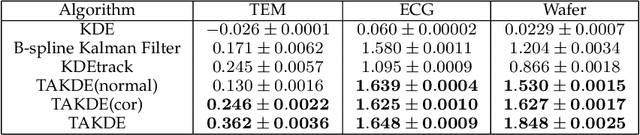
Real-time density estimation is ubiquitous in many applications, including computer vision and signal processing. Kernel density estimation is arguably one of the most commonly used density estimation techniques, and the use of "sliding window" mechanism adapts kernel density estimators to dynamic processes. In this paper, we derive the asymptotic mean integrated squared error (AMISE) upper bound for the "sliding window" kernel density estimator. This upper bound provides a principled guide to devise a novel estimator, which we name the temporal adaptive kernel density estimator (TAKDE). Compared to heuristic approaches for "sliding window" kernel density estimator, TAKDE is theoretically optimal in terms of the worst-case AMISE. We provide numerical experiments using synthetic and real-world datasets, showing that TAKDE outperforms other state-of-the-art dynamic density estimators (including those outside of kernel family). In particular, TAKDE achieves a superior test log-likelihood with a smaller runtime.
A Real-time System for Detecting Landslide Reports on Social Media using Artificial Intelligence
Feb 14, 2022This paper presents an online system that leverages social media data in real time to identify landslide-related information automatically using state-of-the-art artificial intelligence techniques. The designed system can (i) reduce the information overload by eliminating duplicate and irrelevant content, (ii) identify landslide images, (iii) infer geolocation of the images, and (iv) categorize the user type (organization or person) of the account sharing the information. The system was deployed in February 2020 online at https://landslide-aidr.qcri.org/landslide_system.php to monitor live Twitter data stream and has been running continuously since then to provide time-critical information to partners such as British Geological Survey and European Mediterranean Seismological Centre. We trust this system can both contribute to harvesting of global landslide data for further research and support global landslide maps to facilitate emergency response and decision making.
Communication-Efficient Topologies for Decentralized Learning with $O(1)$ Consensus Rate
Oct 14, 2022
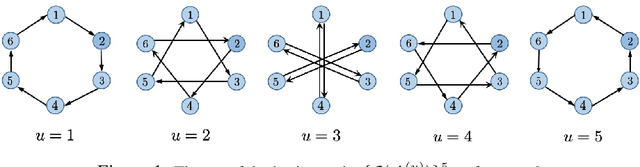
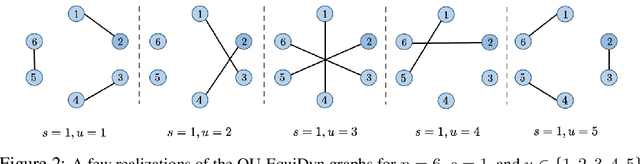

Decentralized optimization is an emerging paradigm in distributed learning in which agents achieve network-wide solutions by peer-to-peer communication without the central server. Since communication tends to be slower than computation, when each agent communicates with only a few neighboring agents per iteration, they can complete iterations faster than with more agents or a central server. However, the total number of iterations to reach a network-wide solution is affected by the speed at which the agents' information is ``mixed'' by communication. We found that popular communication topologies either have large maximum degrees (such as stars and complete graphs) or are ineffective at mixing information (such as rings and grids). To address this problem, we propose a new family of topologies, EquiTopo, which has an (almost) constant degree and a network-size-independent consensus rate that is used to measure the mixing efficiency. In the proposed family, EquiStatic has a degree of $\Theta(\ln(n))$, where $n$ is the network size, and a series of time-dependent one-peer topologies, EquiDyn, has a constant degree of 1. We generate EquiDyn through a certain random sampling procedure. Both of them achieve an $n$-independent consensus rate. We apply them to decentralized SGD and decentralized gradient tracking and obtain faster communication and better convergence, theoretically and empirically. Our code is implemented through BlueFog and available at \url{https://github.com/kexinjinnn/EquiTopo}
Bayesian Regularization on Function Spaces via Q-Exponential Process
Oct 14, 2022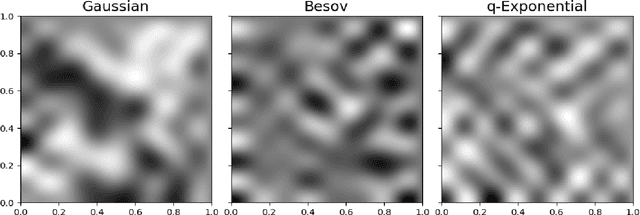
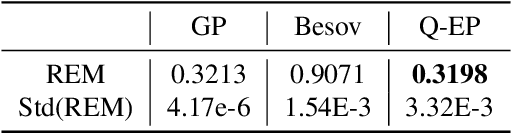
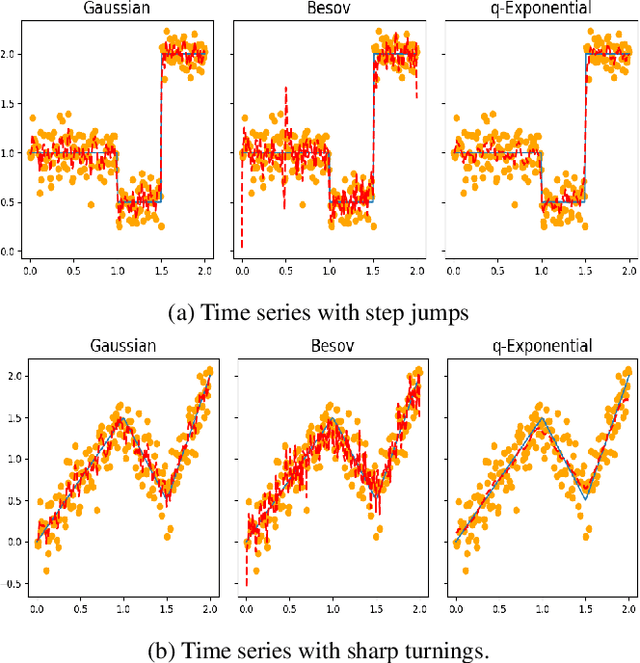
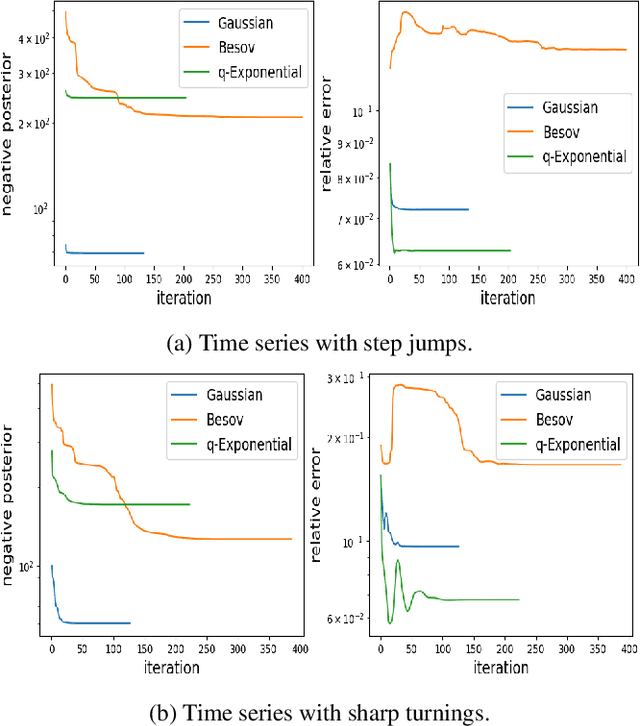
Regularization is one of the most important topics in optimization, statistics and machine learning. To get sparsity in estimating a parameter $u\in\mbR^d$, an $\ell_q$ penalty term, $\Vert u\Vert_q$, is usually added to the objective function. What is the probabilistic distribution corresponding to such $\ell_q$ penalty? What is the correct stochastic process corresponding to $\Vert u\Vert_q$ when we model functions $u\in L^q$? This is important for statistically modeling large dimensional objects, e.g. images, with penalty to preserve certainty properties, e.g. edges in the image. In this work, we generalize the $q$-exponential distribution (with density proportional to) $\exp{(- \half|u|^q)}$ to a stochastic process named \emph{$Q$-exponential (Q-EP) process} that corresponds to the $L_q$ regularization of functions. The key step is to specify consistent multivariate $q$-exponential distributions by choosing from a large family of elliptic contour distributions. The work is closely related to Besov process which is usually defined by the expanded series. Q-EP can be regarded as a definition of Besov process with explicit probabilistic formulation and direct control on the correlation length. From the Bayesian perspective, Q-EP provides a flexible prior on functions with sharper penalty ($q<2$) than the commonly used Gaussian process (GP). We compare GP, Besov and Q-EP in modeling time series and reconstructing images and demonstrate the advantage of the proposed methodology.
Synthetic-to-real Composite Semantic Segmentation in Additive Manufacturing
Oct 14, 2022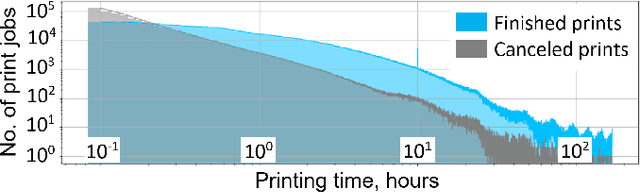
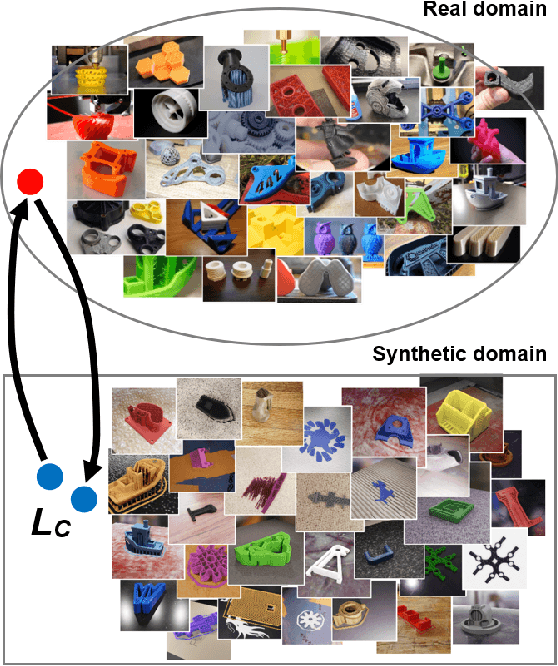


The application of computer vision and machine learning methods in the field of additive manufacturing (AM) for semantic segmentation of the structural elements of 3-D printed products will improve real-time failure analysis systems and can potentially reduce the number of defects by enabling in situ corrections. This work demonstrates the possibilities of using physics-based rendering for labeled image dataset generation, as well as image-to-image translation capabilities to improve the accuracy of real image segmentation for AM systems. Multi-class semantic segmentation experiments were carried out based on the U-Net model and cycle generative adversarial network. The test results demonstrated the capacity of detecting such structural elements of 3-D printed parts as a top layer, infill, shell, and support. A basis for further segmentation system enhancement by utilizing image-to-image style transfer and domain adaptation technologies was also developed. The results indicate that using style transfer as a precursor to domain adaptation can significantly improve real 3-D printing image segmentation in situations where a model trained on synthetic data is the only tool available. The mean intersection over union (mIoU) scores for synthetic test datasets included 94.90% for the entire 3-D printed part, 73.33% for the top layer, 78.93% for the infill, 55.31% for the shell, and 69.45% for supports.
Where to Begin? On the Impact of Pre-Training and Initialization in Federated Learning
Oct 14, 2022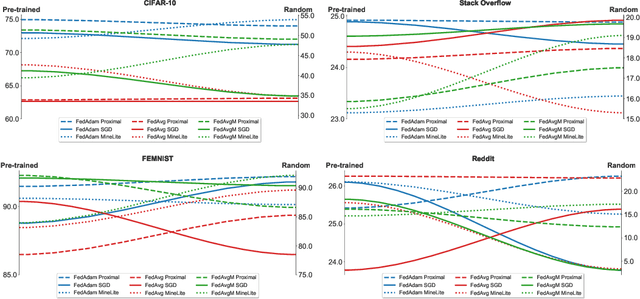

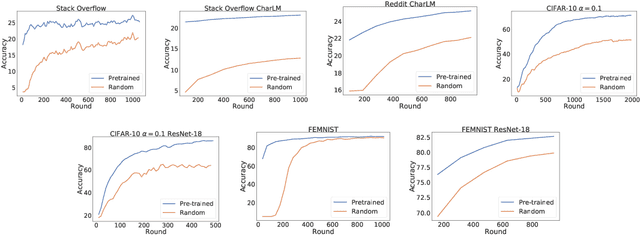
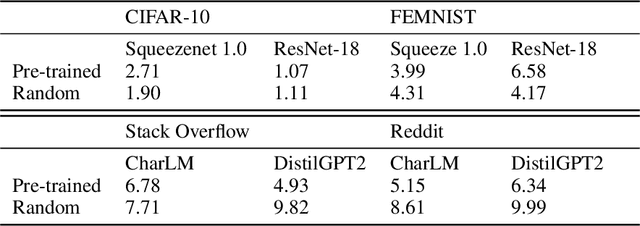
An oft-cited challenge of federated learning is the presence of heterogeneity. \emph{Data heterogeneity} refers to the fact that data from different clients may follow very different distributions. \emph{System heterogeneity} refers to the fact that client devices have different system capabilities. A considerable number of federated optimization methods address this challenge. In the literature, empirical evaluations usually start federated training from random initialization. However, in many practical applications of federated learning, the server has access to proxy data for the training task that can be used to pre-train a model before starting federated training. We empirically study the impact of starting from a pre-trained model in federated learning using four standard federated learning benchmark datasets. Unsurprisingly, starting from a pre-trained model reduces the training time required to reach a target error rate and enables the training of more accurate models (up to 40\%) than is possible when starting from random initialization. Surprisingly, we also find that starting federated learning from a pre-trained initialization reduces the effect of both data and system heterogeneity. We recommend that future work proposing and evaluating federated optimization methods evaluate the performance when starting from random and pre-trained initializations. We also believe this study raises several questions for further work on understanding the role of heterogeneity in federated optimization.
AR Training App for Energy Optimal Programming of Cobots
Oct 14, 2022
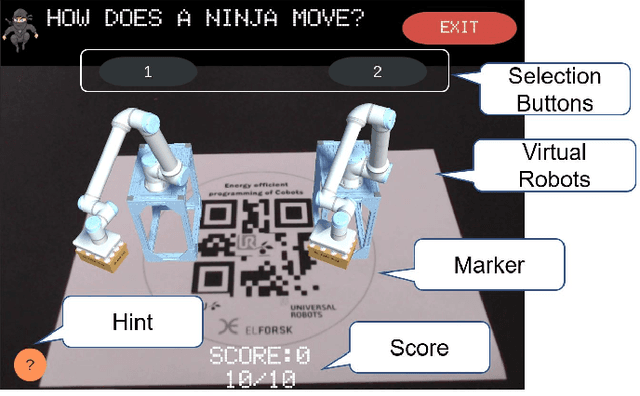
Worldwide most factories aim for low-cost and fast production ignoring resources and energy consumption. But, high revenues have been accompanied by environmental degradation. The United Nations reacted to the ecological problem and proposed the Sustainable Development Goals, and one of them is Sustainable Production (Goal 12). In addition, the participation of lightweight robots, such as collaborative robots, in modern industrial production is increasing. The energy consumption of a single collaborative robot is not significant, however, the consumption of more and more cobots worldwide is representative. Consequently, our research focuses on strategies to reduce the energy consumption of lightweight robots aiming for sustainable production. Firstly, the energy consumption of the lightweight robot UR10e is assessed by a set of experiments. We analyzed the results of the experiments to describe the relationship between the energy consumption and the evaluation parameters, thus paving the way to optimization strategies. Next, we propose four strategies to reduce energy consumption: 1) optimal standby position, 2) optimal robot instruction, 3) optimal motion time, and 4) reduction of dissipative energy. The results show that cobots potentially reduce from 3\% up to 37\% of their energy consumption, depending on the optimization technique. To disseminate the results of our research, we developed an AR game in which the users learn how to energy-efficiently program cobots.
Boosting Performance of a Baseline Visual Place Recognition Technique by Predicting the Maximally Complementary Technique
Oct 14, 2022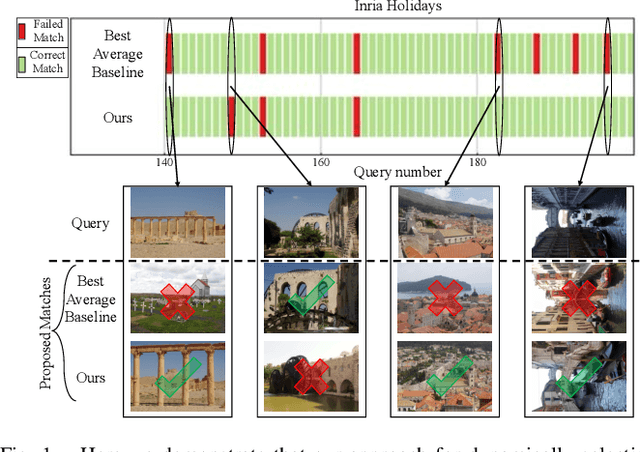
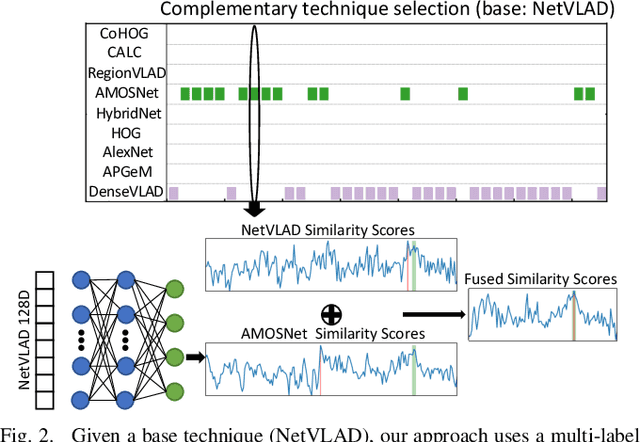
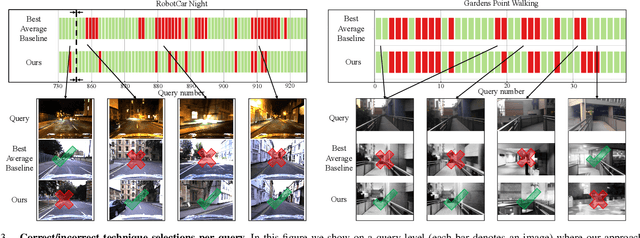
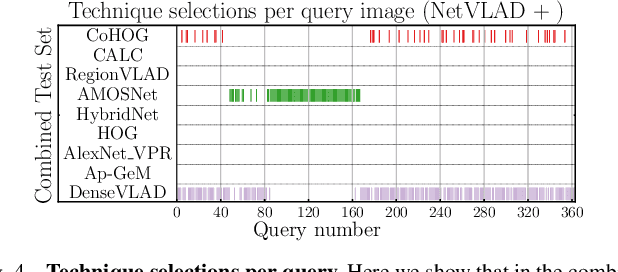
One recent promising approach to the Visual Place Recognition (VPR) problem has been to fuse the place recognition estimates of multiple complementary VPR techniques using methods such as SRAL and multi-process fusion. These approaches come with a substantial practical limitation: they require all potential VPR methods to be brute-force run before they are selectively fused. The obvious solution to this limitation is to predict the viable subset of methods ahead of time, but this is challenging because it requires a predictive signal within the imagery itself that is indicative of high performance methods. Here we propose an alternative approach that instead starts with a known single base VPR technique, and learns to predict the most complementary additional VPR technique to fuse with it, that results in the largest improvement in performance. The key innovation here is to use a dimensionally reduced difference vector between the query image and the top-retrieved reference image using this baseline technique as the predictive signal of the most complementary additional technique, both during training and inference. We demonstrate that our approach can train a single network to select performant, complementary technique pairs across datasets which span multiple modes of transportation (train, car, walking) as well as to generalise to unseen datasets, outperforming multiple baseline strategies for manually selecting the best technique pairs based on the same training data.
Ensemble uncertainty as a criterion for dataset expansion in distinct bone segmentation from upper-body CT images
Aug 19, 2022
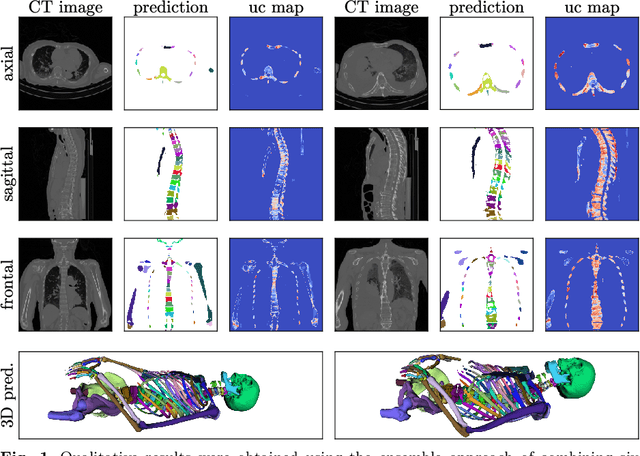
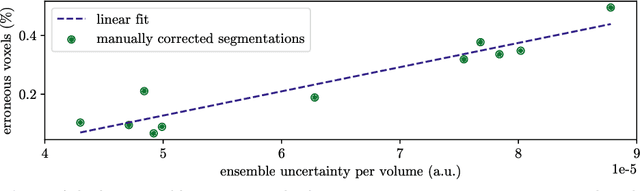
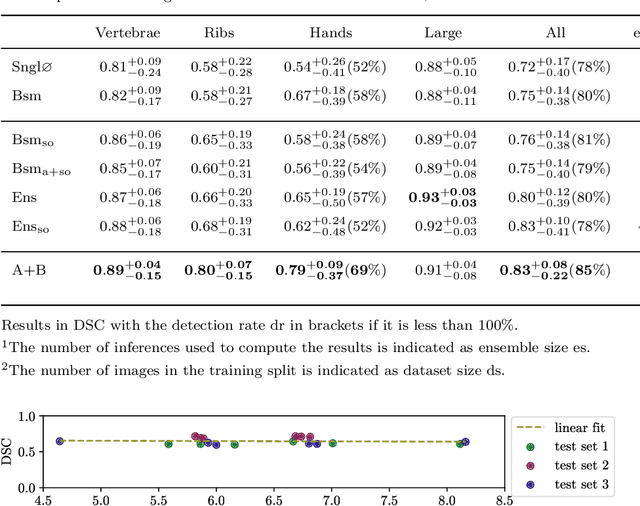
Purpose: The localisation and segmentation of individual bones is an important preprocessing step in many planning and navigation applications. It is, however, a time-consuming and repetitive task if done manually. This is true not only for clinical practice but also for the acquisition of training data. We therefore not only present an end-to-end learnt algorithm that is capable of segmenting 125 distinct bones in an upper-body CT, but also provide an ensemble-based uncertainty measure that helps to single out scans to enlarge the training dataset with. Methods We create fully automated end-to-end learnt segmentations using a neural network architecture inspired by the 3D-Unet and fully supervised training. The results are improved using ensembles and inference-time augmentation. We examine the relationship of ensemble-uncertainty to an unlabelled scan's prospective usefulness as part of the training dataset. Results: Our methods are evaluated on an in-house dataset of 16 upper-body CT scans with a resolution of \SI{2}{\milli\meter} per dimension. Taking into account all 125 bones in our label set, our most successful ensemble achieves a median dice score coefficient of 0.83. We find a lack of correlation between a scan's ensemble uncertainty and its prospective influence on the accuracies achieved within an enlarged training set. At the same time, we show that the ensemble uncertainty correlates to the number of voxels that need manual correction after an initial automated segmentation, thus minimising the time required to finalise a new ground truth segmentation. Conclusion: In combination, scans with low ensemble uncertainty need less annotator time while yielding similar future DSC improvements. They are thus ideal candidates to enlarge a training set for upper-body distinct bone segmentation from CT scans. }