 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Mitigating Unintended Memorization in Language Models via Alternating Teaching
Oct 13, 2022
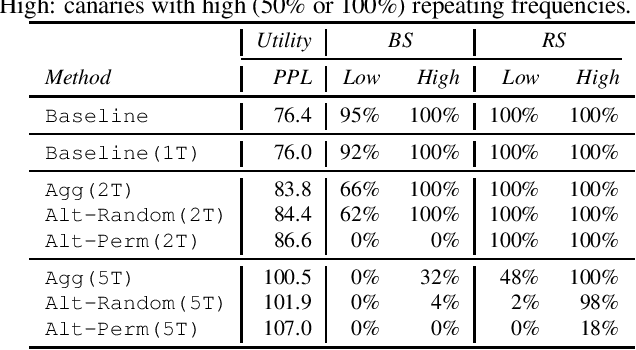
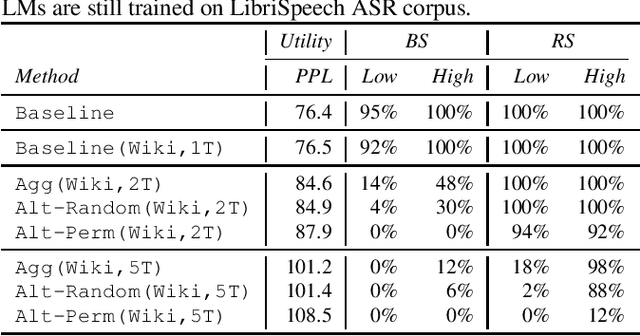
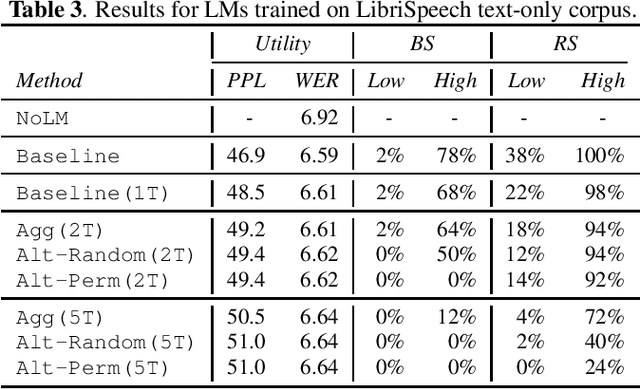
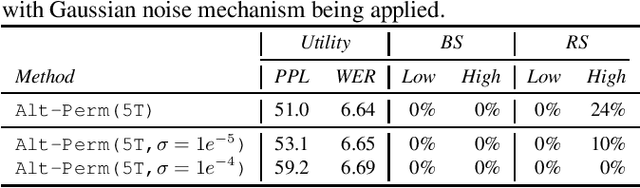
Recent research has shown that language models have a tendency to memorize rare or unique sequences in the training corpora which can thus leak sensitive attributes of user data. We employ a teacher-student framework and propose a novel approach called alternating teaching to mitigate unintended memorization in sequential modeling. In our method, multiple teachers are trained on disjoint training sets whose privacy one wishes to protect, and teachers' predictions supervise the training of a student model in an alternating manner at each time step. Experiments on LibriSpeech datasets show that the proposed method achieves superior privacy-preserving results than other counterparts. In comparison with no prevention for unintended memorization, the overall utility loss is small when training records are sufficient.
WeakIdent: Weak formulation for Identifying Differential Equations using Narrow-fit and Trimming
Nov 06, 2022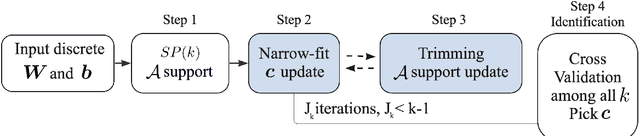

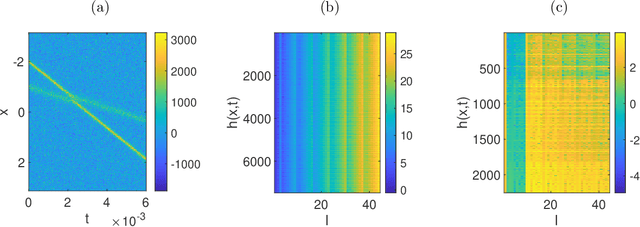

Data-driven identification of differential equations is an interesting but challenging problem, especially when the given data are corrupted by noise. When the governing differential equation is a linear combination of various differential terms, the identification problem can be formulated as solving a linear system, with the feature matrix consisting of linear and nonlinear terms multiplied by a coefficient vector. This product is equal to the time derivative term, and thus generates dynamical behaviors. The goal is to identify the correct terms that form the equation to capture the dynamics of the given data. We propose a general and robust framework to recover differential equations using a weak formulation, for both ordinary and partial differential equations (ODEs and PDEs). The weak formulation facilitates an efficient and robust way to handle noise. For a robust recovery against noise and the choice of hyper-parameters, we introduce two new mechanisms, narrow-fit and trimming, for the coefficient support and value recovery, respectively. For each sparsity level, Subspace Pursuit is utilized to find an initial set of support from the large dictionary. Then, we focus on highly dynamic regions (rows of the feature matrix), and error normalize the feature matrix in the narrow-fit step. The support is further updated via trimming of the terms that contribute the least. Finally, the support set of features with the smallest Cross-Validation error is chosen as the result. A comprehensive set of numerical experiments are presented for both systems of ODEs and PDEs with various noise levels. The proposed method gives a robust recovery of the coefficients, and a significant denoising effect which can handle up to $100\%$ noise-to-signal ratio for some equations. We compare the proposed method with several state-of-the-art algorithms for the recovery of differential equations.
Importance Tempering: Group Robustness for Overparameterized Models
Sep 19, 2022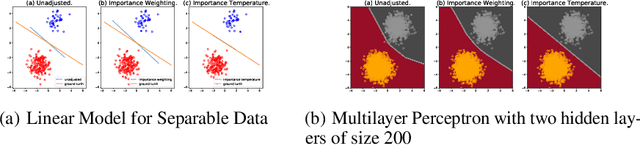
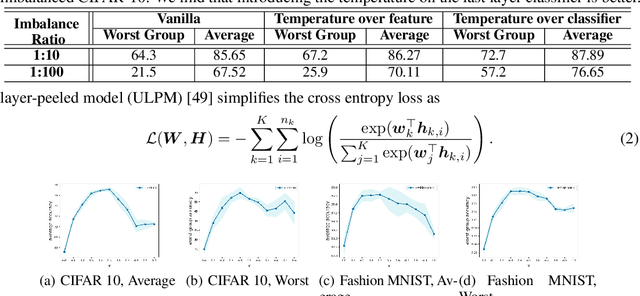
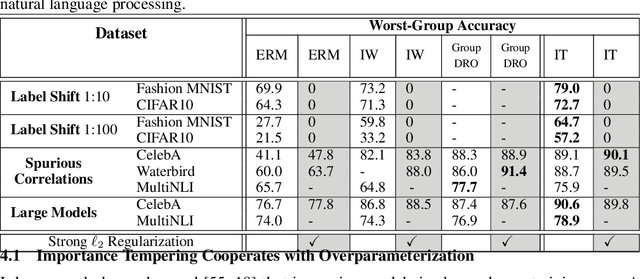

Although overparameterized models have shown their success on many machine learning tasks, the accuracy could drop on the testing distribution that is different from the training one. This accuracy drop still limits applying machine learning in the wild. At the same time, importance weighting, a traditional technique to handle distribution shifts, has been demonstrated to have less or even no effect on overparameterized models both empirically and theoretically. In this paper, we propose importance tempering to improve the decision boundary and achieve consistently better results for overparameterized models. Theoretically, we justify that the selection of group temperature can be different under label shift and spurious correlation setting. At the same time, we also prove that properly selected temperatures can extricate the minority collapse for imbalanced classification. Empirically, we achieve state-of-the-art results on worst group classification tasks using importance tempering.
EgoSpeed-Net: Forecasting Speed-Control in Driver Behavior from Egocentric Video Data
Sep 27, 2022
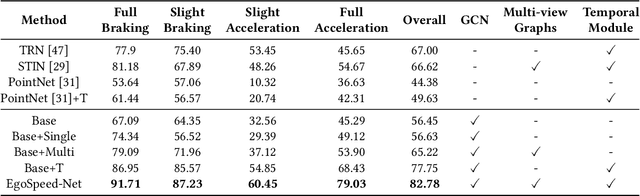
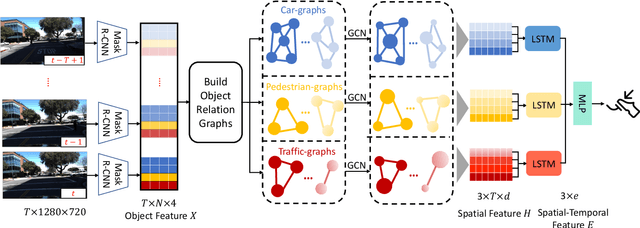
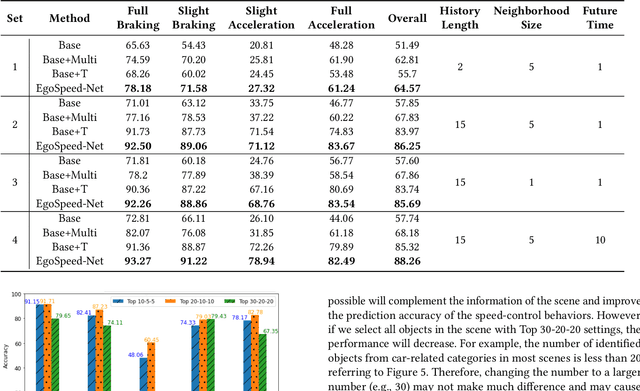
Speed-control forecasting, a challenging problem in driver behavior analysis, aims to predict the future actions of a driver in controlling vehicle speed such as braking or acceleration. In this paper, we try to address this challenge solely using egocentric video data, in contrast to the majority of works in the literature using either third-person view data or extra vehicle sensor data such as GPS, or both. To this end, we propose a novel graph convolutional network (GCN) based network, namely, EgoSpeed-Net. We are motivated by the fact that the position changes of objects over time can provide us very useful clues for forecasting the speed change in future. We first model the spatial relations among the objects from each class, frame by frame, using fully-connected graphs, on top of which GCNs are applied for feature extraction. Then we utilize a long short-term memory network to fuse such features per class over time into a vector, concatenate such vectors and forecast a speed-control action using a multilayer perceptron classifier. We conduct extensive experiments on the Honda Research Institute Driving Dataset and demonstrate the superior performance of EgoSpeed-Net.
NICE-Beam: Neural Integrated Covariance Estimators for Time-Varying Beamformers
Dec 08, 2021
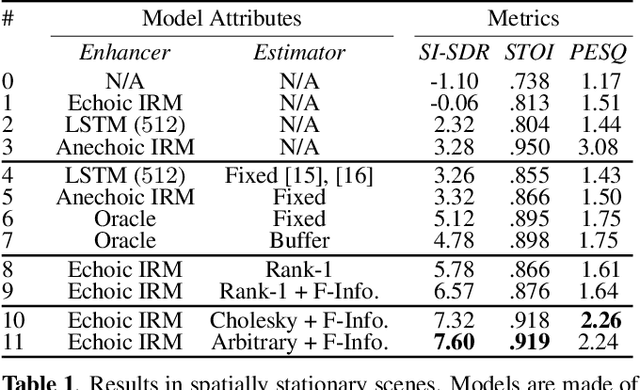
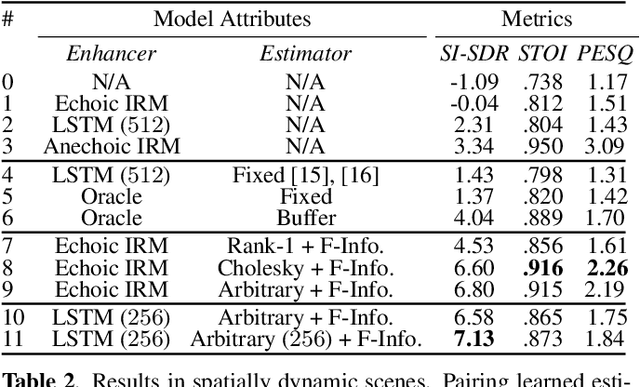

Estimating a time-varying spatial covariance matrix for a beamforming algorithm is a challenging task, especially for wearable devices, as the algorithm must compensate for time-varying signal statistics due to rapid pose-changes. In this paper, we propose Neural Integrated Covariance Estimators for Beamformers, NICE-Beam. NICE-Beam is a general technique for learning how to estimate time-varying spatial covariance matrices, which we apply to joint speech enhancement and dereverberation. It is based on training a neural network module to non-linearly track and leverage scene information across time. We integrate our solution into a beamforming pipeline, which enables simple training, faster than real-time inference, and a variety of test-time adaptation options. We evaluate the proposed model against a suite of baselines in scenes with both stationary and moving microphones. Our results show that the proposed method can outperform a hand-tuned estimator, despite the hand-tuned estimator using oracle source separation knowledge.
Broad-persistent Advice for Interactive Reinforcement Learning Scenarios
Oct 11, 2022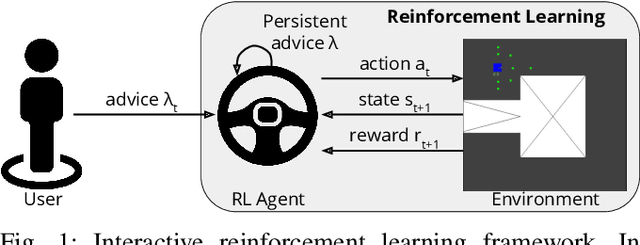
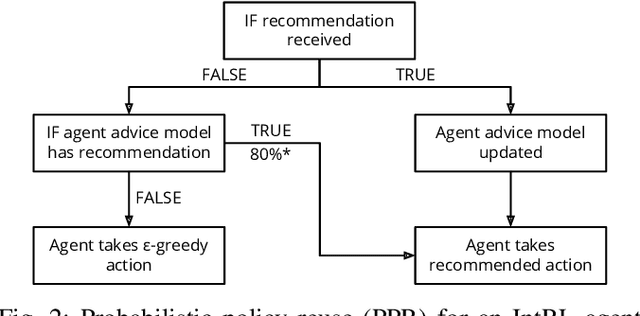
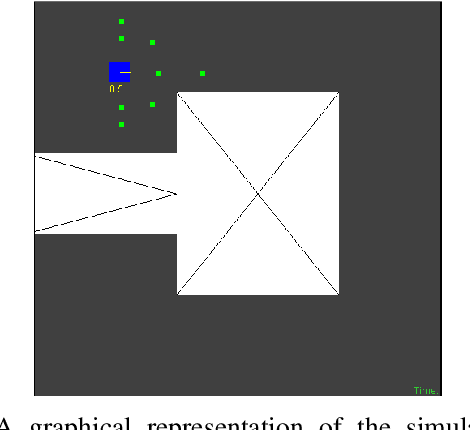

The use of interactive advice in reinforcement learning scenarios allows for speeding up the learning process for autonomous agents. Current interactive reinforcement learning research has been limited to real-time interactions that offer relevant user advice to the current state only. Moreover, the information provided by each interaction is not retained and instead discarded by the agent after a single use. In this paper, we present a method for retaining and reusing provided knowledge, allowing trainers to give general advice relevant to more than just the current state. Results obtained show that the use of broad-persistent advice substantially improves the performance of the agent while reducing the number of interactions required for the trainer.
Factorized Fusion Shrinkage for Dynamic Relational Data
Sep 30, 2022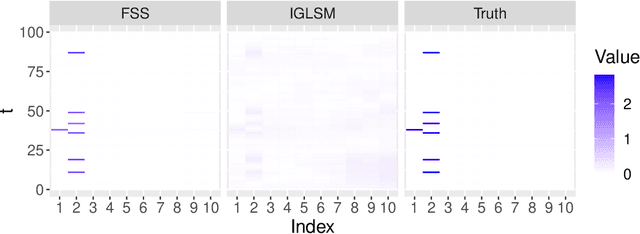
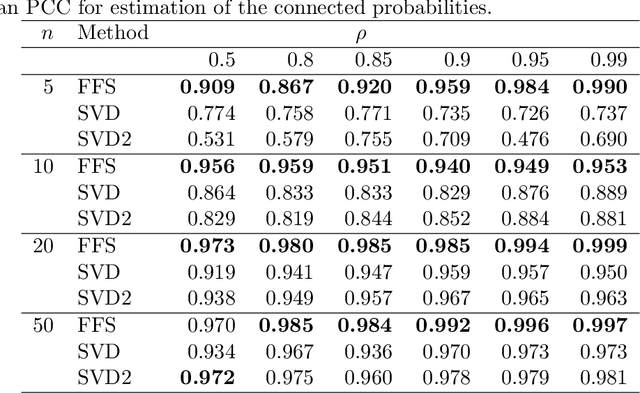
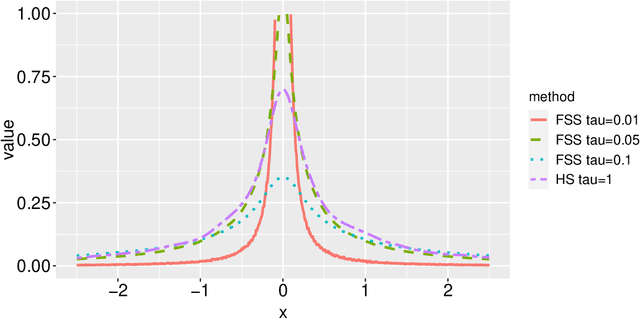
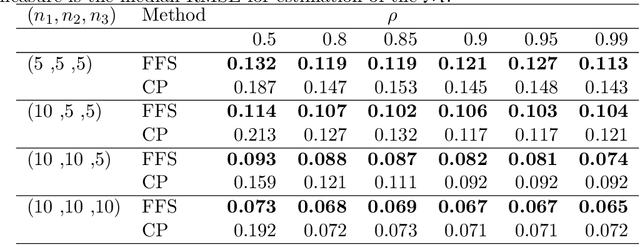
Modern data science applications often involve complex relational data with dynamic structures. An abrupt change in such dynamic relational data is typically observed in systems that undergo regime changes due to interventions. In such a case, we consider a factorized fusion shrinkage model in which all decomposed factors are dynamically shrunk towards group-wise fusion structures, where the shrinkage is obtained by applying global-local shrinkage priors to the successive differences of the row vectors of the factorized matrices. The proposed priors enjoy many favorable properties in comparison and clustering of the estimated dynamic latent factors. Comparing estimated latent factors involves both adjacent and long-term comparisons, with the time range of comparison considered as a variable. Under certain conditions, we demonstrate that the posterior distribution attains the minimax optimal rate up to logarithmic factors. In terms of computation, we present a structured mean-field variational inference framework that balances optimal posterior inference with computational scalability, exploiting both the dependence among components and across time. The framework can accommodate a wide variety of models, including dynamic matrix factorization, latent space models for networks and low-rank tensors. The effectiveness of our methodology is demonstrated through extensive simulations and real-world data analysis.
Automated Characterization of Catalytically Active Inclusion Body Production in Biotechnological Screening Systems
Sep 30, 2022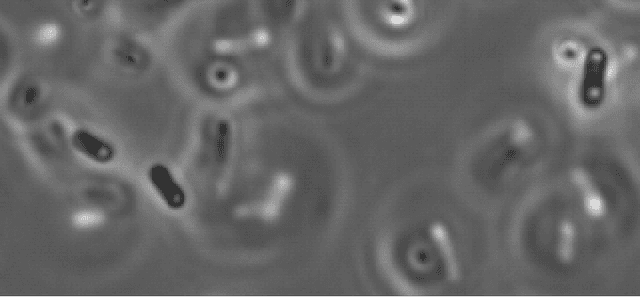
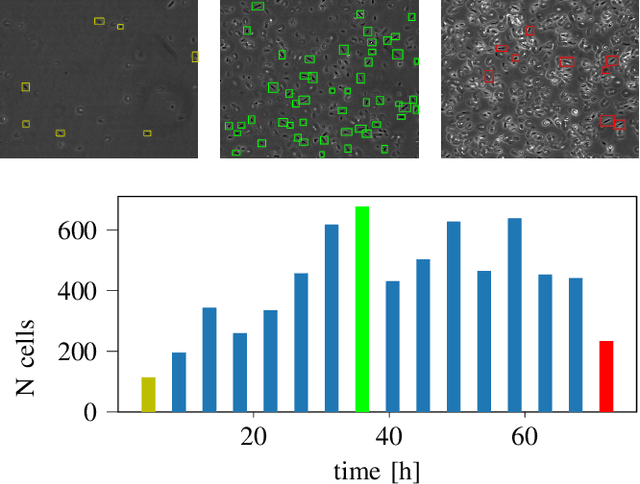

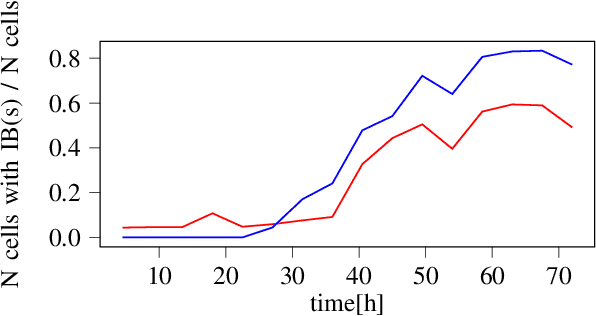
We here propose an automated pipeline for the microscopy image-based characterization of catalytically active inclusion bodies (CatIBs), which includes a fully automatic experimental high-throughput workflow combined with a hybrid approach for multi-object microbial cell segmentation. For automated microscopy, a CatIB producer strain was cultivated in a microbioreactor from which samples were injected into a flow chamber. The flow chamber was fixed under a microscope and an integrated camera took a series of images per sample. To explore heterogeneity of CatIB development during the cultivation and track the size and quantity of CatIBs over time, a hybrid image processing pipeline approach was developed, which combines an ML-based detection of in-focus cells with model-based segmentation. The experimental setup in combination with an automated image analysis unlocks high-throughput screening of CatIB production, saving time and resources. Biotechnological relevance - CatIBs have wide application in synthetic chemistry and biocatalysis, but also could have future biomedical applications such as therapeutics. The proposed hybrid automatic image processing pipeline can be adjusted to treat comparable biological microorganisms, where fully data-driven ML-based segmentation approaches are not feasible due to the lack of training data. Our work is the first step towards image-based bioprocess control.
Can we do that simpler? Simple, Efficient, High-Quality Evaluation Metrics for NLG
Sep 20, 2022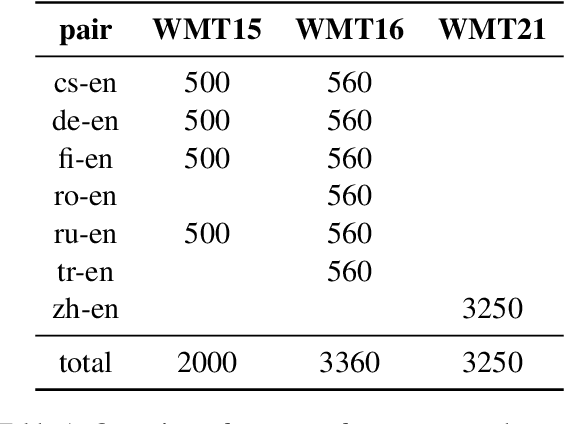
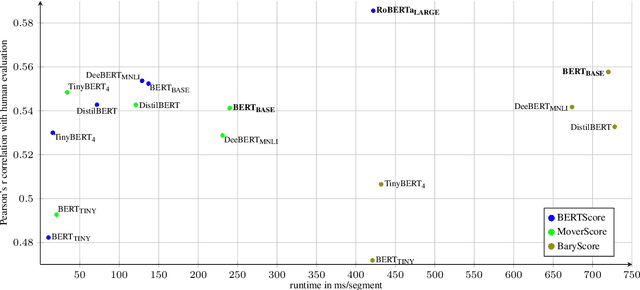
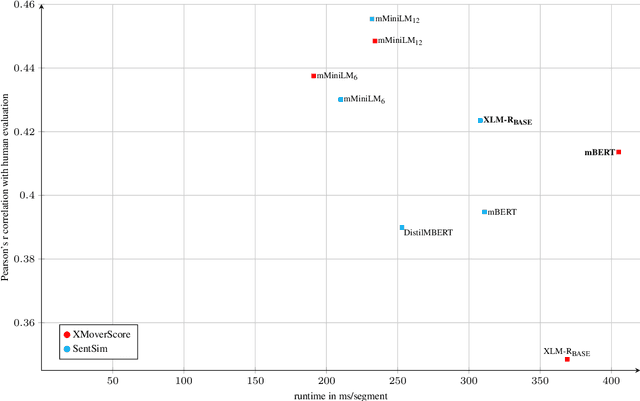
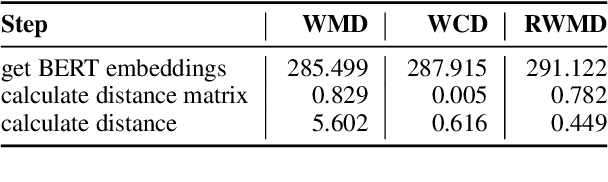
We explore efficient evaluation metrics for Natural Language Generation (NLG). To implement efficient metrics, we replace (i) computation-heavy transformers in metrics such as BERTScore, MoverScore, BARTScore, XMoverScore, etc. with lighter versions (such as distilled ones) and (ii) cubic inference time alignment algorithms such as Word Mover Distance with linear and quadratic approximations. We consider six evaluation metrics (both monolingual and multilingual), assessed on three different machine translation datasets, and 16 light-weight transformers as replacement. We find, among others, that (a) TinyBERT shows best quality-efficiency tradeoff for semantic similarity metrics of the BERTScore family, retaining 97\% quality and being 5x faster at inference time on average, (b) there is a large difference in speed-ups on CPU vs. GPU (much higher speed-ups on CPU), and (c) WMD approximations yield no efficiency gains but lead to a substantial drop in quality on 2 out of 3 datasets we examine.
An Empirical Analysis of the Use of Real-Time Reachability for the Safety Assurance of Autonomous Vehicles
May 03, 2022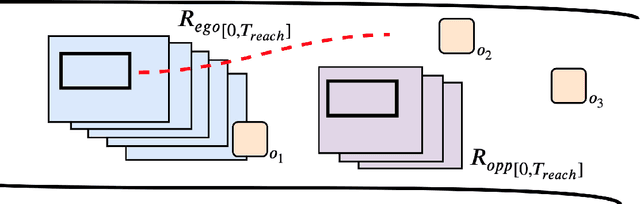

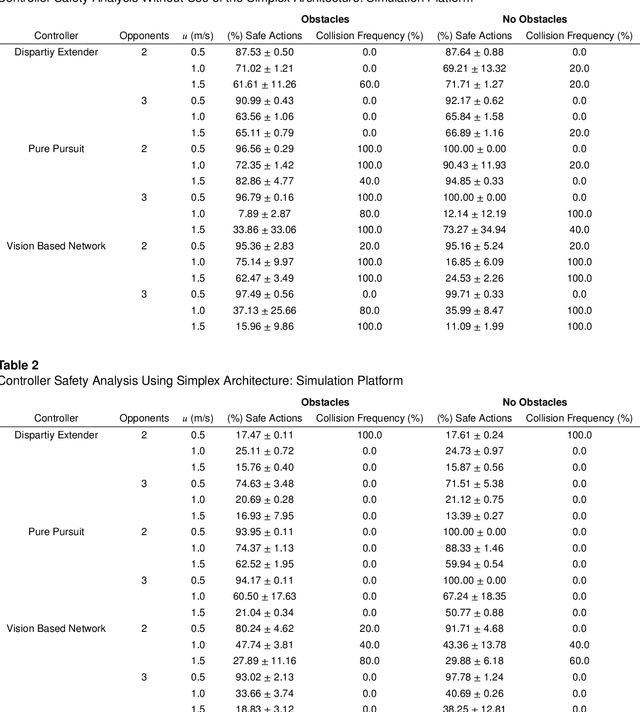
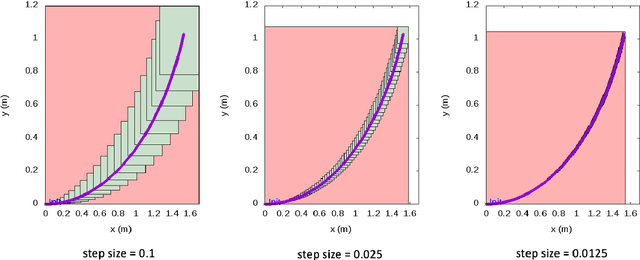
Recent advances in machine learning technologies and sensing have paved the way for the belief that safe, accessible, and convenient autonomous vehicles may be realized in the near future. Despite tremendous advances within this context, fundamental challenges around safety and reliability are limiting their arrival and comprehensive adoption. Autonomous vehicles are often tasked with operating in dynamic and uncertain environments. As a result, they often make use of highly complex components, such as machine learning approaches, to handle the nuances of sensing, actuation, and control. While these methods are highly effective, they are notoriously difficult to assure. Moreover, within uncertain and dynamic environments, design time assurance analyses may not be sufficient to guarantee safety. Thus, it is critical to monitor the correctness of these systems at runtime. One approach for providing runtime assurance of systems with components that may not be amenable to formal analysis is the simplex architecture, where an unverified component is wrapped with a safety controller and a switching logic designed to prevent dangerous behavior. In this paper, we propose using a real-time reachability algorithm for the implementation of the simplex architecture to assure the safety of a 1/10 scale open source autonomous vehicle platform known as F1/10. The reachability algorithm that we leverage (a) provides provable guarantees of safety, and (b) is used to detect potentially unsafe scenarios. In our approach, the need to analyze an underlying controller is abstracted away, instead focusing on the effects of the controller's decisions on the system's future states. We demonstrate the efficacy of our architecture through a vast set of experiments conducted both in simulation and on an embedded hardware platform.