 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulation-based inference for rapid Bayesian parameter estimation in epidemiological models: a comparison with MCMC
Jun 25, 2026Mechanistic epidemiological models are widely used to support infectious disease forecasting and public-health decision making. Bayesian calibration of such models is commonly performed using Markov chain Monte Carlo (MCMC), which can become computationally expensive for high-dimensional nonlinear systems and repeated near-real-time analyses. Here, we investigate simulation-based inference (SBI) using neural posterior estimation as a scalable alternative for Bayesian calibration of a mechanistic SECIR epidemiological model using COVID-19 intensive care unit (ICU) occupancy data from Germany during 2020. We compared SBI and MCMC across multiple epidemic phases using both 31-day inference windows and a substantially more challenging 201-day reconstruction problem involving multiple transmission change points. Posterior agreement was evaluated quantitatively using Wasserstein distances and Kullback-Leibler divergences together with posterior predictive checks. Across the 31-day windows, SBI recovered posterior distributions in strong agreement with MCMC while accurately reproducing observed ICU trajectories. In the 201-day setting, SBI preserved the dominant posterior structure despite increased uncertainty. SBI, by combining CPU and GPU resources, substantially reduced computational runtime compared with MCMC, which was restricted to running on CPUs. Whereas MCMC required approximately 1000 seconds for the 31-day inference problems, SBI achieved comparable posterior and predictive performance in approximately 60-70 seconds on a single GPU. For the 201-day inference problem, SBI required an average of 157 seconds, while the MCMC runs took over 19,000 seconds. Our results demonstrate that SBI provides a rapid and computationally efficient framework for Bayesian calibration of mechanistic epidemiological models, supporting repeated near-real-time inference and rapid outbreak analysis.
Machine learning in bioprocess development: From promise to practice
Oct 04, 2022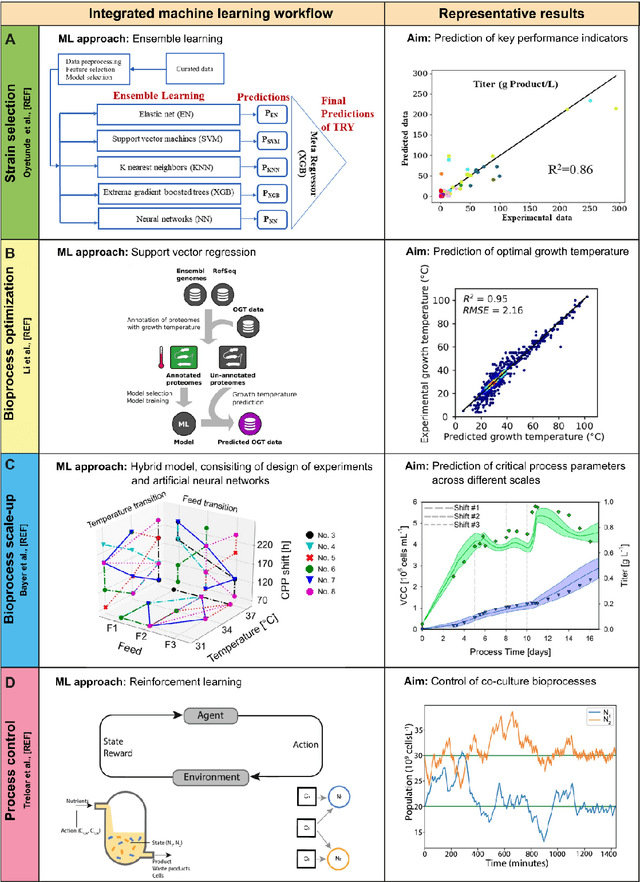
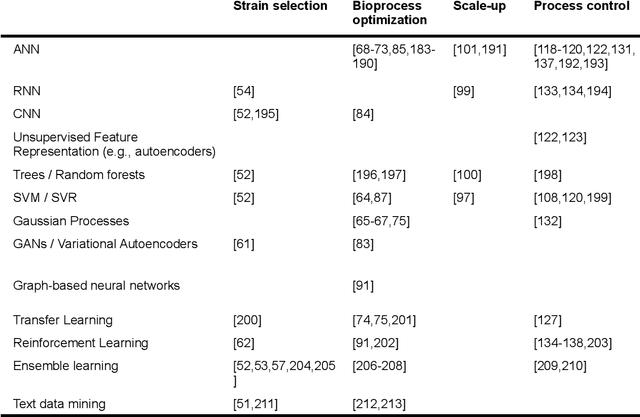
Fostered by novel analytical techniques, digitalization and automation, modern bioprocess development provides high amounts of heterogeneous experimental data, containing valuable process information. In this context, data-driven methods like machine learning (ML) approaches have a high potential to rationally explore large design spaces while exploiting experimental facilities most efficiently. The aim of this review is to demonstrate how ML methods have been applied so far in bioprocess development, especially in strain engineering and selection, bioprocess optimization, scale-up, monitoring and control of bioprocesses. For each topic, we will highlight successful application cases, current challenges and point out domains that can potentially benefit from technology transfer and further progress in the field of ML.
Automated Characterization of Catalytically Active Inclusion Body Production in Biotechnological Screening Systems
Sep 30, 2022
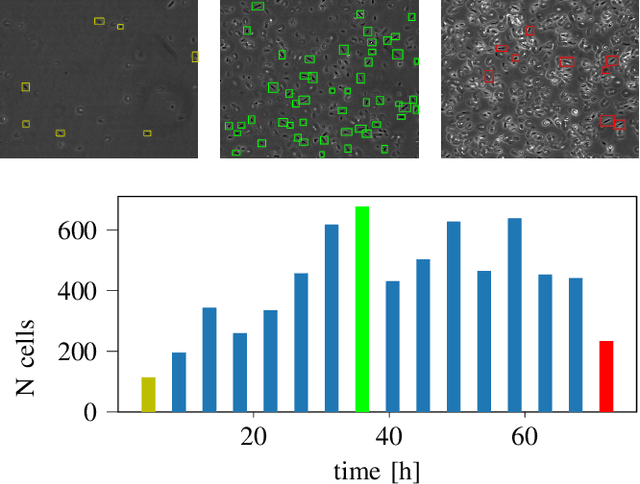

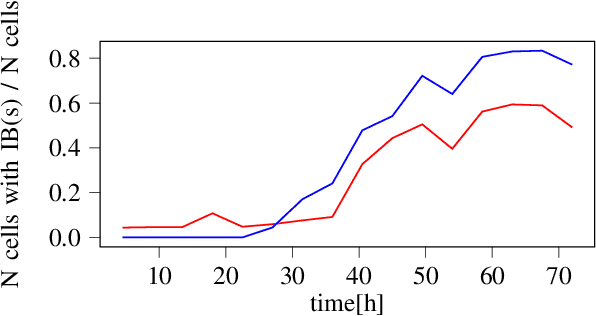
We here propose an automated pipeline for the microscopy image-based characterization of catalytically active inclusion bodies (CatIBs), which includes a fully automatic experimental high-throughput workflow combined with a hybrid approach for multi-object microbial cell segmentation. For automated microscopy, a CatIB producer strain was cultivated in a microbioreactor from which samples were injected into a flow chamber. The flow chamber was fixed under a microscope and an integrated camera took a series of images per sample. To explore heterogeneity of CatIB development during the cultivation and track the size and quantity of CatIBs over time, a hybrid image processing pipeline approach was developed, which combines an ML-based detection of in-focus cells with model-based segmentation. The experimental setup in combination with an automated image analysis unlocks high-throughput screening of CatIB production, saving time and resources. Biotechnological relevance - CatIBs have wide application in synthetic chemistry and biocatalysis, but also could have future biomedical applications such as therapeutics. The proposed hybrid automatic image processing pipeline can be adjusted to treat comparable biological microorganisms, where fully data-driven ML-based segmentation approaches are not feasible due to the lack of training data. Our work is the first step towards image-based bioprocess control.