 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Private Isotonic Regression
Oct 27, 2022
In this paper, we consider the problem of differentially private (DP) algorithms for isotonic regression. For the most general problem of isotonic regression over a partially ordered set (poset) $\mathcal{X}$ and for any Lipschitz loss function, we obtain a pure-DP algorithm that, given $n$ input points, has an expected excess empirical risk of roughly $\mathrm{width}(\mathcal{X}) \cdot \log|\mathcal{X}| / n$, where $\mathrm{width}(\mathcal{X})$ is the width of the poset. In contrast, we also obtain a near-matching lower bound of roughly $(\mathrm{width}(\mathcal{X}) + \log |\mathcal{X}|) / n$, that holds even for approximate-DP algorithms. Moreover, we show that the above bounds are essentially the best that can be obtained without utilizing any further structure of the poset. In the special case of a totally ordered set and for $\ell_1$ and $\ell_2^2$ losses, our algorithm can be implemented in near-linear running time; we also provide extensions of this algorithm to the problem of private isotonic regression with additional structural constraints on the output function.
FCTalker: Fine and Coarse Grained Context Modeling for Expressive Conversational Speech Synthesis
Oct 27, 2022
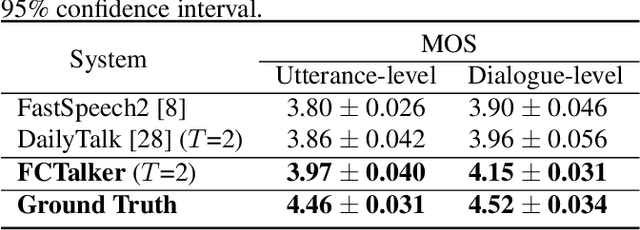
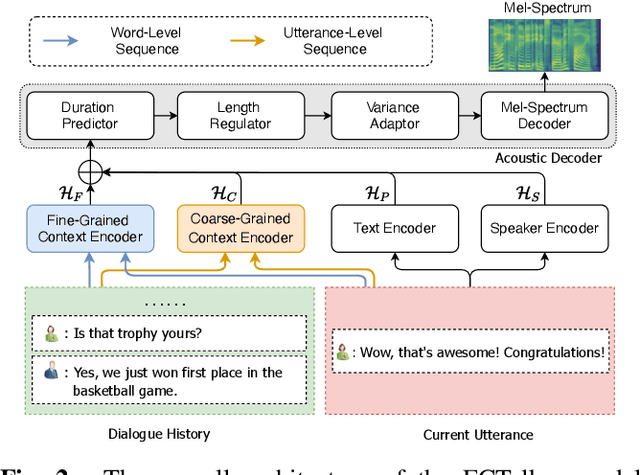
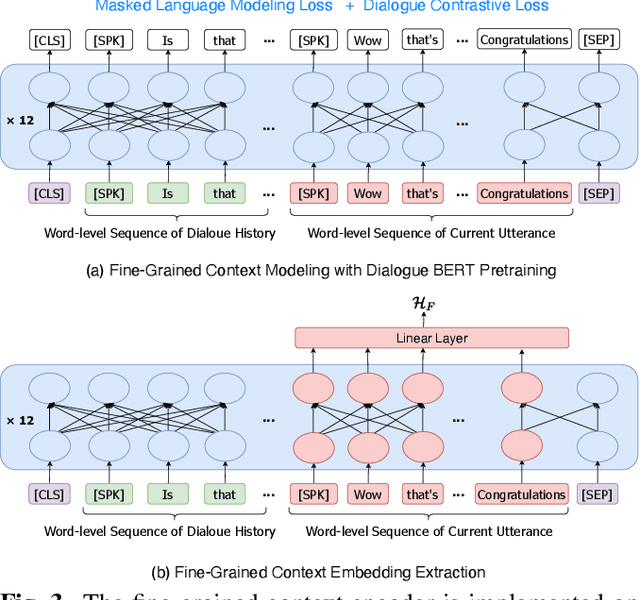
Conversational Text-to-Speech (TTS) aims to synthesis an utterance with the right linguistic and affective prosody in a conversational context. The correlation between the current utterance and the dialogue history at the utterance level was used to improve the expressiveness of synthesized speech. However, the fine-grained information in the dialogue history at the word level also has an important impact on the prosodic expression of an utterance, which has not been well studied in the prior work. Therefore, we propose a novel expressive conversational TTS model, termed as FCTalker, that learn the fine and coarse grained context dependency at the same time during speech generation. Specifically, the FCTalker includes fine and coarse grained encoders to exploit the word and utterance-level context dependency. To model the word-level dependencies between an utterance and its dialogue history, the fine-grained dialogue encoder is built on top of a dialogue BERT model. The experimental results show that the proposed method outperforms all baselines and generates more expressive speech that is contextually appropriate. We release the source code at: https://github.com/walker-hyf/FCTalker.
Stochastic Robustness Interval for Motion Planning with Signal Temporal Logic
Oct 10, 2022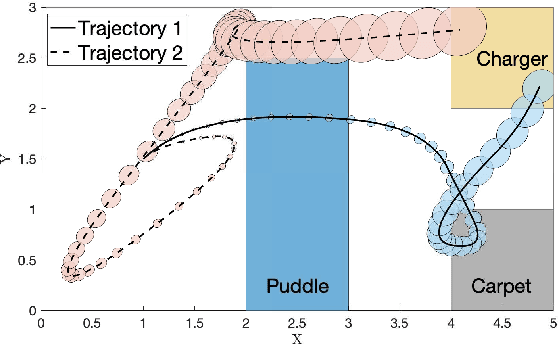

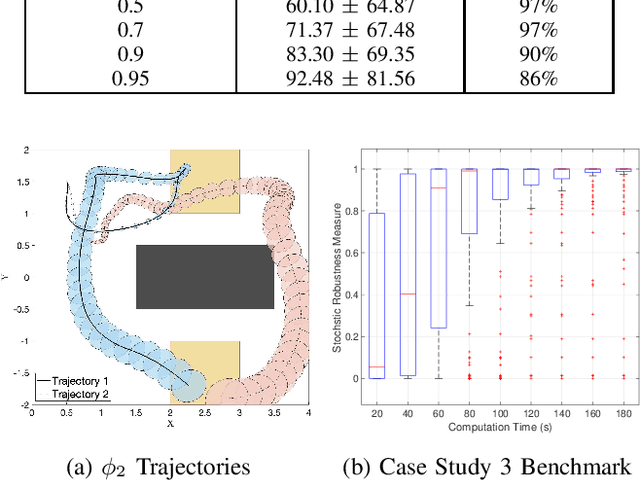
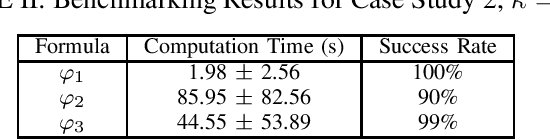
In this work, we present a novel robustness measure for continuous-time stochastic trajectories with respect to Signal Temporal Logic (STL) specifications. We show the soundness of the measure and develop a monitor for reasoning about partial trajectories. Using this monitor, we introduce an STL sampling-based motion planning algorithm for robots under uncertainty. Given a minimum robustness requirement, this algorithm finds satisfying motion plans; alternatively, the algorithm also optimizes for the measure. We prove probabilistic completeness and asymptotic optimality, and demonstrate the effectiveness of our approach on several case studies.
Learnable Polyphase Sampling for Shift Invariant and Equivariant Convolutional Networks
Oct 14, 2022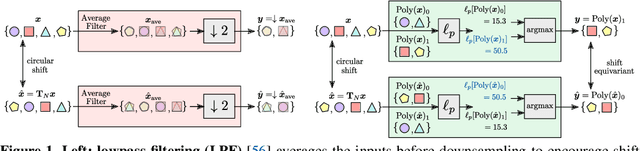
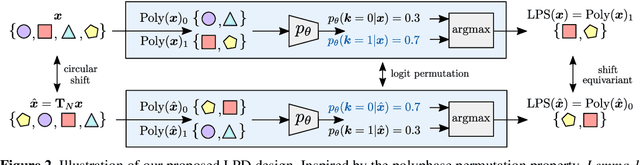
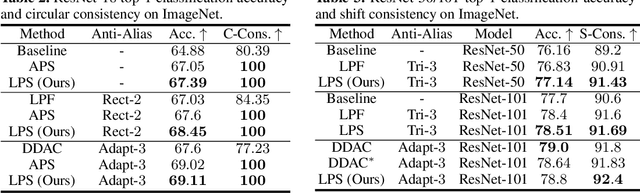
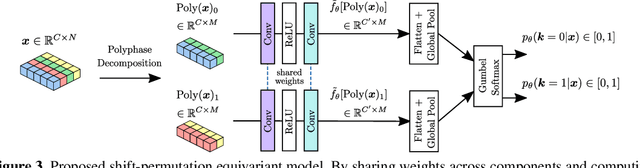
We propose learnable polyphase sampling (LPS), a pair of learnable down/upsampling layers that enable truly shift-invariant and equivariant convolutional networks. LPS can be trained end-to-end from data and generalizes existing handcrafted downsampling layers. It is widely applicable as it can be integrated into any convolutional network by replacing down/upsampling layers. We evaluate LPS on image classification and semantic segmentation. Experiments show that LPS is on-par with or outperforms existing methods in both performance and shift consistency. For the first time, we achieve true shift-equivariance on semantic segmentation (PASCAL VOC), i.e., 100% shift consistency, outperforming baselines by an absolute 3.3%.
Training neural network ensembles via trajectory sampling
Sep 22, 2022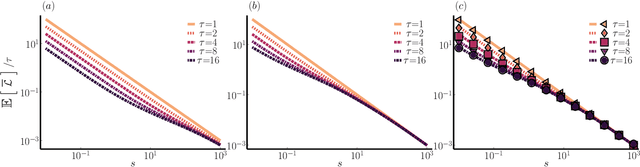
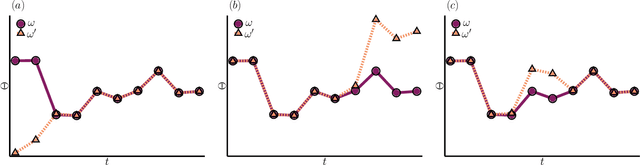
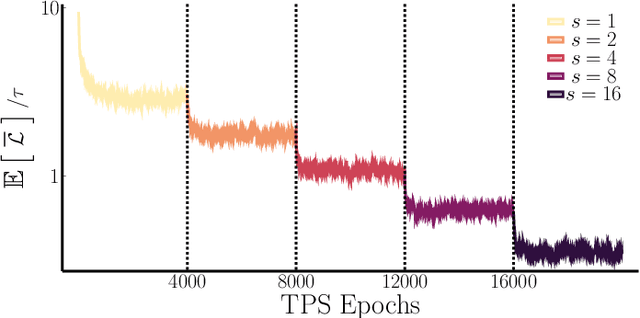
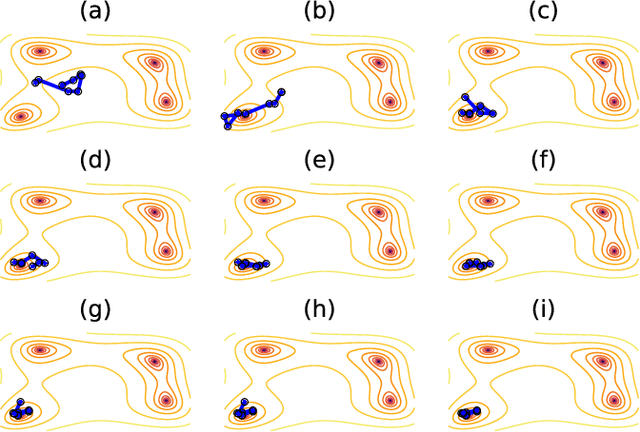
In machine learning, there is renewed interest in neural network ensembles (NNEs), whereby predictions are obtained as an aggregate from a diverse set of smaller models, rather than from a single larger model. Here, we show how to define and train a NNE using techniques from the study of rare trajectories in stochastic systems. We define an NNE in terms of the trajectory of the model parameters under a simple, and discrete in time, diffusive dynamics, and train the NNE by biasing these trajectories towards a small time-integrated loss, as controlled by appropriate counting fields which act as hyperparameters. We demonstrate the viability of this technique on a range of simple supervised learning tasks. We discuss potential advantages of our trajectory sampling approach compared with more conventional gradient based methods.
A Temporal Graphlet Kernel for Classifying Dissemination in Evolving Networks
Sep 12, 2022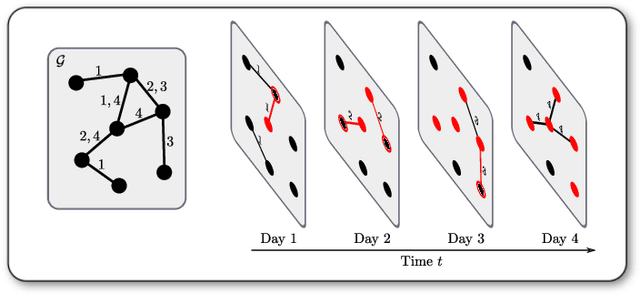
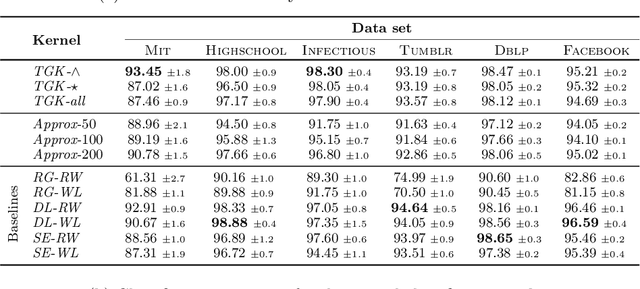
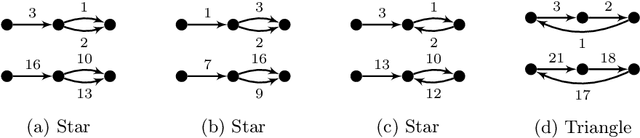

We introduce the \emph{temporal graphlet kernel} for classifying dissemination processes in labeled temporal graphs. Such dissemination processes can be spreading (fake) news, infectious diseases, or computer viruses in dynamic networks. The networks are modeled as labeled temporal graphs, in which the edges exist at specific points in time, and node labels change over time. The classification problem asks to discriminate dissemination processes of different origins or parameters, e.g., infectious diseases with different infection probabilities. Our new kernel represents labeled temporal graphs in the feature space of temporal graphlets, i.e., small subgraphs distinguished by their structure, time-dependent node labels, and chronological order of edges. We introduce variants of our kernel based on classes of graphlets that are efficiently countable. For the case of temporal wedges, we propose a highly efficient approximative kernel with low error in expectation. We show that our kernels are faster to compute and provide better accuracy than state-of-the-art methods.
Coresets for Time Series Clustering
Oct 28, 2021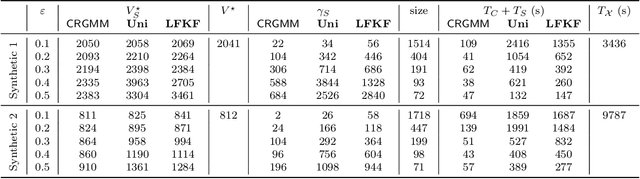
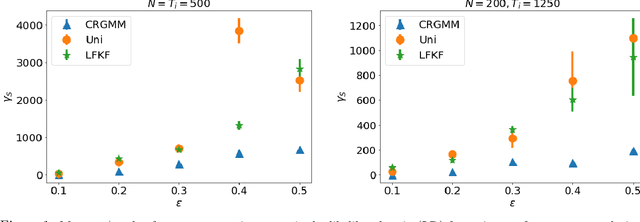
We study the problem of constructing coresets for clustering problems with time series data. This problem has gained importance across many fields including biology, medicine, and economics due to the proliferation of sensors facilitating real-time measurement and rapid drop in storage costs. In particular, we consider the setting where the time series data on $N$ entities is generated from a Gaussian mixture model with autocorrelations over $k$ clusters in $\mathbb{R}^d$. Our main contribution is an algorithm to construct coresets for the maximum likelihood objective for this mixture model. Our algorithm is efficient, and under a mild boundedness assumption on the covariance matrices of the underlying Gaussians, the size of the coreset is independent of the number of entities $N$ and the number of observations for each entity, and depends only polynomially on $k$, $d$ and $1/\varepsilon$, where $\varepsilon$ is the error parameter. We empirically assess the performance of our coreset with synthetic data.
Reliable Malware Analysis and Detection using Topology Data Analysis
Nov 03, 2022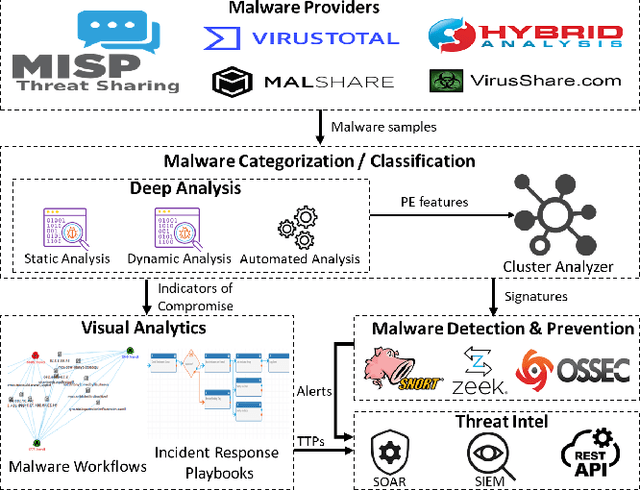
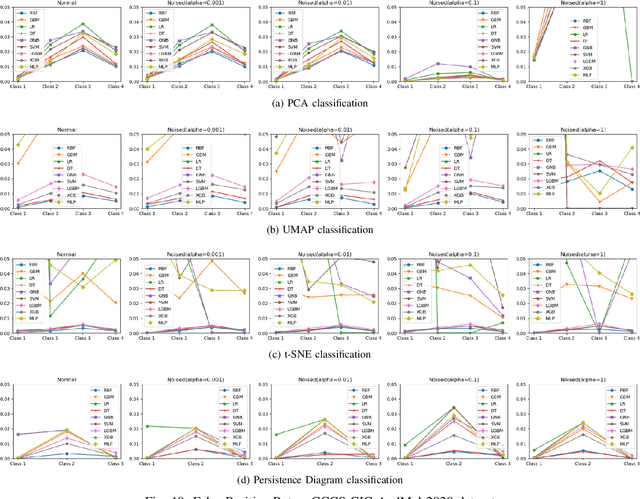
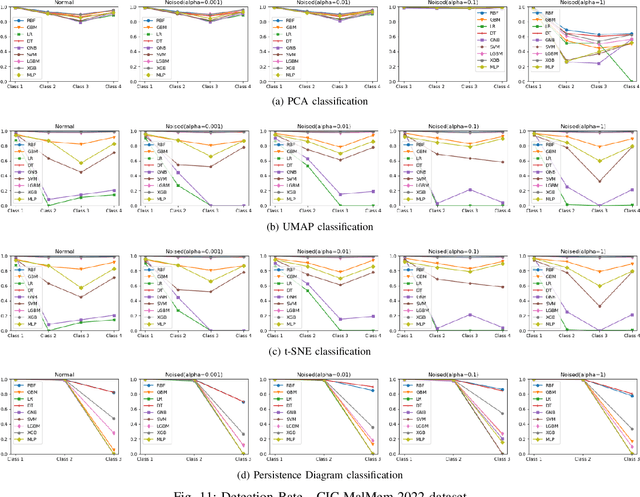
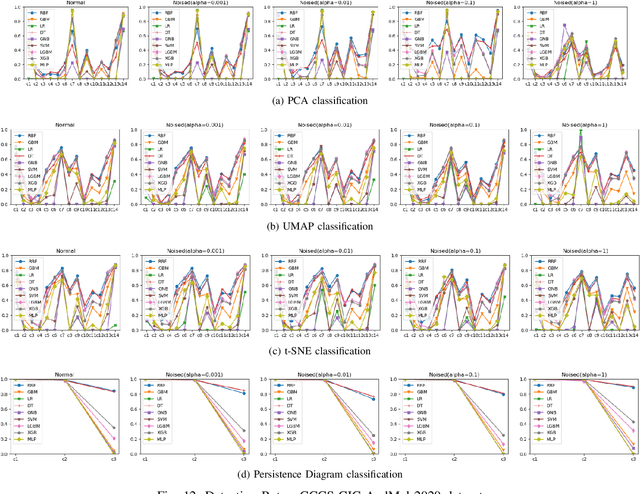
Increasingly, malwares are becoming complex and they are spreading on networks targeting different infrastructures and personal-end devices to collect, modify, and destroy victim information. Malware behaviors are polymorphic, metamorphic, persistent, able to hide to bypass detectors and adapt to new environments, and even leverage machine learning techniques to better damage targets. Thus, it makes them difficult to analyze and detect with traditional endpoint detection and response, intrusion detection and prevention systems. To defend against malwares, recent work has proposed different techniques based on signatures and machine learning. In this paper, we propose to use an algebraic topological approach called topological-based data analysis (TDA) to efficiently analyze and detect complex malware patterns. Next, we compare the different TDA techniques (i.e., persistence homology, tomato, TDA Mapper) and existing techniques (i.e., PCA, UMAP, t-SNE) using different classifiers including random forest, decision tree, xgboost, and lightgbm. We also propose some recommendations to deploy the best-identified models for malware detection at scale. Results show that TDA Mapper (combined with PCA) is better for clustering and for identifying hidden relationships between malware clusters compared to PCA. Persistent diagrams are better to identify overlapping malware clusters with low execution time compared to UMAP and t-SNE. For malware detection, malware analysts can use Random Forest and Decision Tree with t-SNE and Persistent Diagram to achieve better performance and robustness on noised data.
GRAIMATTER Green Paper: Recommendations for disclosure control of trained Machine Learning (ML) models from Trusted Research Environments (TREs)
Nov 03, 2022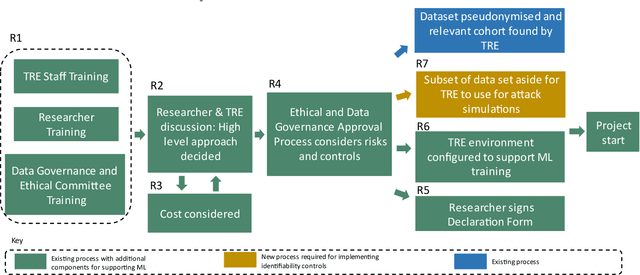
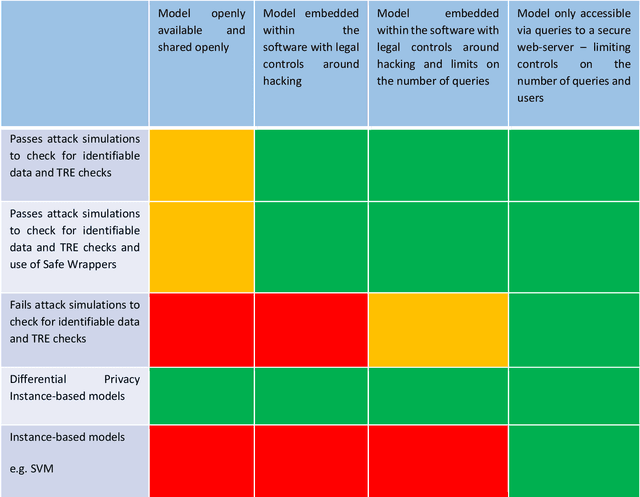
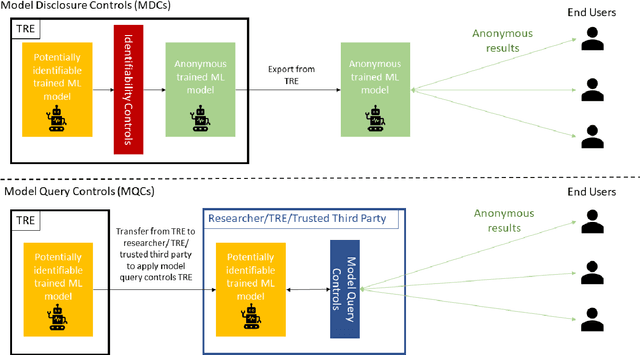

TREs are widely, and increasingly used to support statistical analysis of sensitive data across a range of sectors (e.g., health, police, tax and education) as they enable secure and transparent research whilst protecting data confidentiality. There is an increasing desire from academia and industry to train AI models in TREs. The field of AI is developing quickly with applications including spotting human errors, streamlining processes, task automation and decision support. These complex AI models require more information to describe and reproduce, increasing the possibility that sensitive personal data can be inferred from such descriptions. TREs do not have mature processes and controls against these risks. This is a complex topic, and it is unreasonable to expect all TREs to be aware of all risks or that TRE researchers have addressed these risks in AI-specific training. GRAIMATTER has developed a draft set of usable recommendations for TREs to guard against the additional risks when disclosing trained AI models from TREs. The development of these recommendations has been funded by the GRAIMATTER UKRI DARE UK sprint research project. This version of our recommendations was published at the end of the project in September 2022. During the course of the project, we have identified many areas for future investigations to expand and test these recommendations in practice. Therefore, we expect that this document will evolve over time.
Liability regimes in the age of AI: a use-case driven analysis of the burden of proof
Nov 03, 2022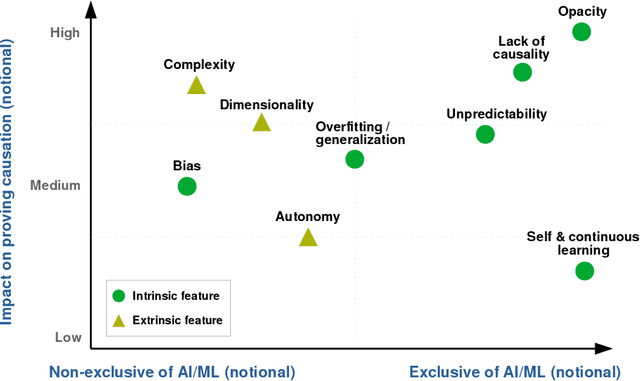
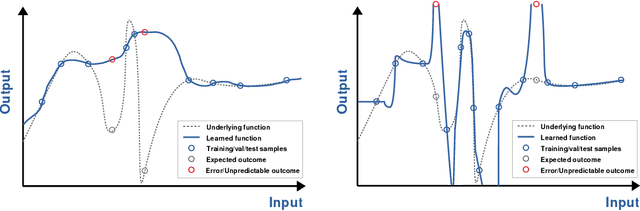
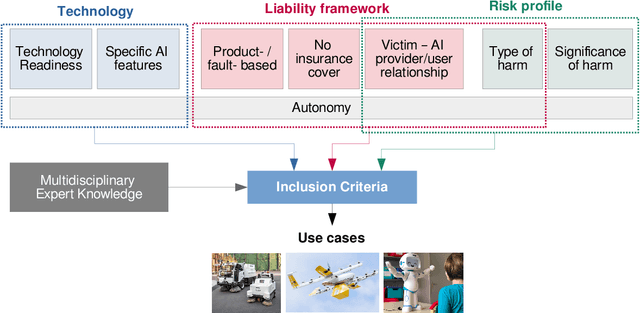
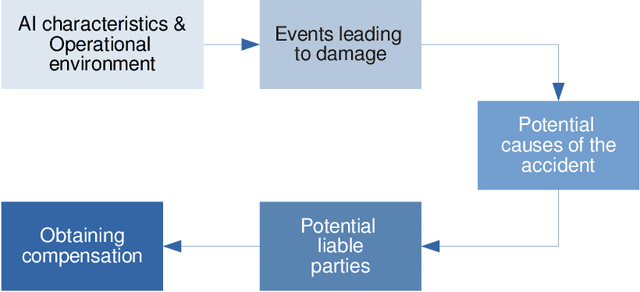
New emerging technologies powered by Artificial Intelligence (AI) have the potential to disruptively transform our societies for the better. In particular, data-driven learning approaches (i.e., Machine Learning (ML)) have been a true revolution in the advancement of multiple technologies in various application domains. But at the same time there is growing concerns about certain intrinsic characteristics of these methodologies that carry potential risks to both safety and fundamental rights. Although there are mechanisms in the adoption process to minimize these risks (e.g., safety regulations), these do not exclude the possibility of harm occurring, and if this happens, victims should be able to seek compensation. Liability regimes will therefore play a key role in ensuring basic protection for victims using or interacting with these systems. However, the same characteristics that make AI systems inherently risky, such as lack of causality, opacity, unpredictability or their self and continuous learning capabilities, lead to considerable difficulties when it comes to proving causation. This paper presents three case studies, as well as the methodology to reach them, that illustrate these difficulties. Specifically, we address the cases of cleaning robots, delivery drones and robots in education. The outcome of the proposed analysis suggests the need to revise liability regimes to alleviate the burden of proof on victims in cases involving AI technologies.