 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTunable Soft Equivariance with Guarantees
Mar 27, 2026Equivariance is a fundamental property in computer vision models, yet strict equivariance is rarely satisfied in real-world data, which can limit a model's performance. Controlling the degree of equivariance is therefore desirable. We propose a general framework for constructing soft equivariant models by projecting the model weights into a designed subspace. The method applies to any pre-trained architecture and provides theoretical bounds on the induced equivariance error. Empirically, we demonstrate the effectiveness of our method on multiple pre-trained backbones, including ViT and ResNet, across image classification, semantic segmentation, and human-trajectory prediction tasks. Notably, our approach improves the performance while simultaneously reducing equivariance error on the competitive ImageNet benchmark.
Local Scale Equivariance with Latent Deep Equilibrium Canonicalizer
Aug 19, 2025



Scale variation is a fundamental challenge in computer vision. Objects of the same class can have different sizes, and their perceived size is further affected by the distance from the camera. These variations are local to the objects, i.e., different object sizes may change differently within the same image. To effectively handle scale variations, we present a deep equilibrium canonicalizer (DEC) to improve the local scale equivariance of a model. DEC can be easily incorporated into existing network architectures and can be adapted to a pre-trained model. Notably, we show that on the competitive ImageNet benchmark, DEC improves both model performance and local scale consistency across four popular pre-trained deep-nets, e.g., ViT, DeiT, Swin, and BEiT. Our code is available at https://github.com/ashiq24/local-scale-equivariance.
Making Vision Transformers Truly Shift-Equivariant
May 25, 2023



For computer vision tasks, Vision Transformers (ViTs) have become one of the go-to deep net architectures. Despite being inspired by Convolutional Neural Networks (CNNs), ViTs remain sensitive to small shifts in the input image. To address this, we introduce novel designs for each of the modules in ViTs, such as tokenization, self-attention, patch merging, and positional encoding. With our proposed modules, we achieve truly shift-equivariant ViTs on four well-established models, namely, Swin, SwinV2, MViTv2, and CvT, both in theory and practice. Empirically, we tested these models on image classification and semantic segmentation, achieving competitive performance across three different datasets while maintaining 100% shift consistency.
Learnable Polyphase Sampling for Shift Invariant and Equivariant Convolutional Networks
Oct 14, 2022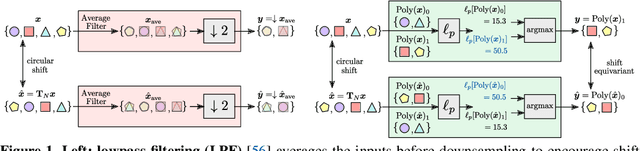
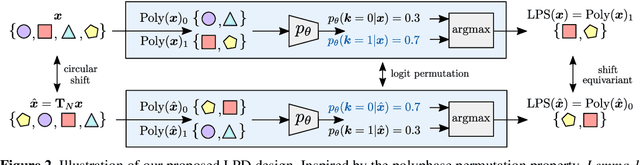
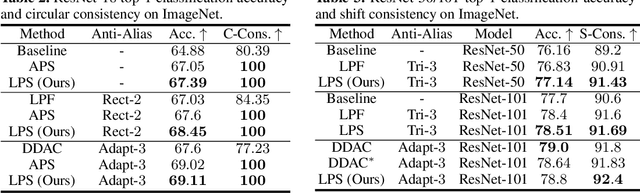
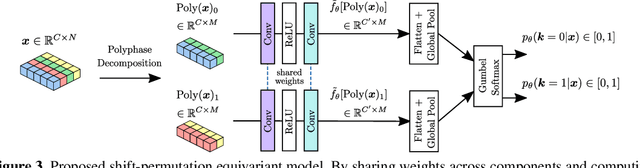
We propose learnable polyphase sampling (LPS), a pair of learnable down/upsampling layers that enable truly shift-invariant and equivariant convolutional networks. LPS can be trained end-to-end from data and generalizes existing handcrafted downsampling layers. It is widely applicable as it can be integrated into any convolutional network by replacing down/upsampling layers. We evaluate LPS on image classification and semantic segmentation. Experiments show that LPS is on-par with or outperforms existing methods in both performance and shift consistency. For the first time, we achieve true shift-equivariance on semantic segmentation (PASCAL VOC), i.e., 100% shift consistency, outperforming baselines by an absolute 3.3%.