 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Intent-aware Multi-source Contrastive Alignment for Tag-enhanced Recommendation
Nov 11, 2022
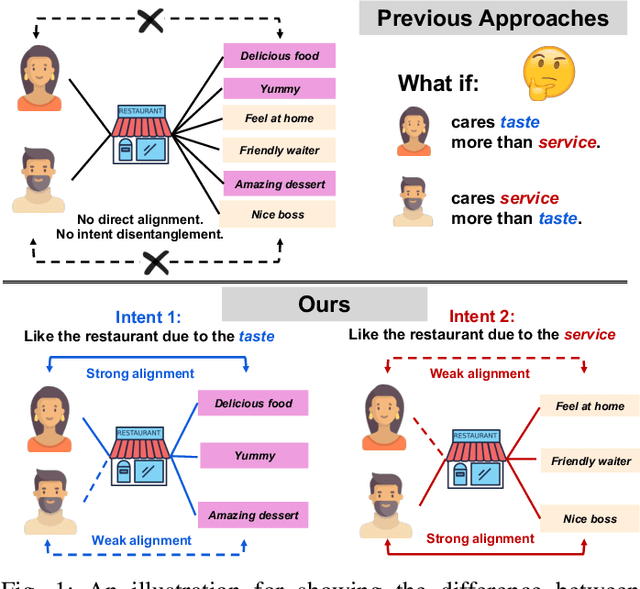
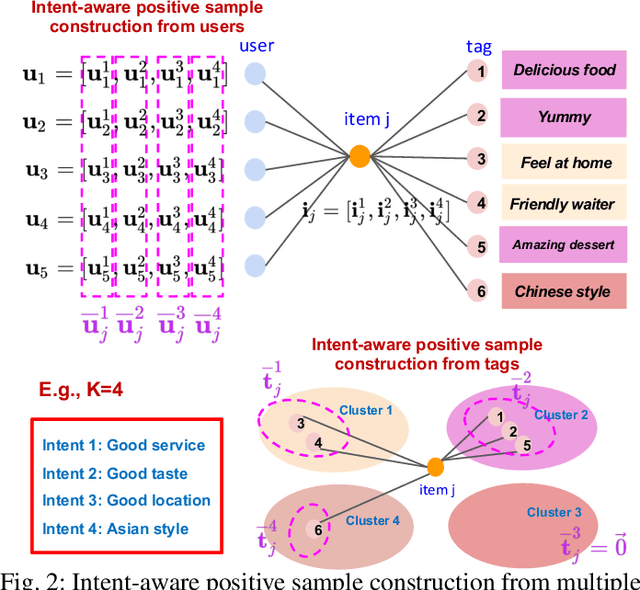
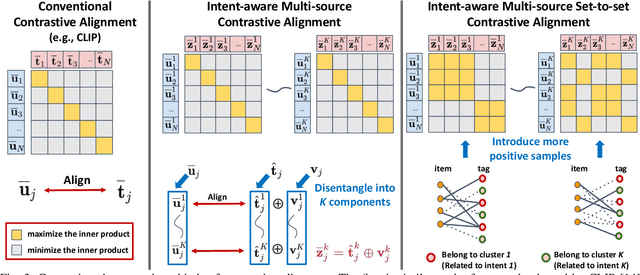
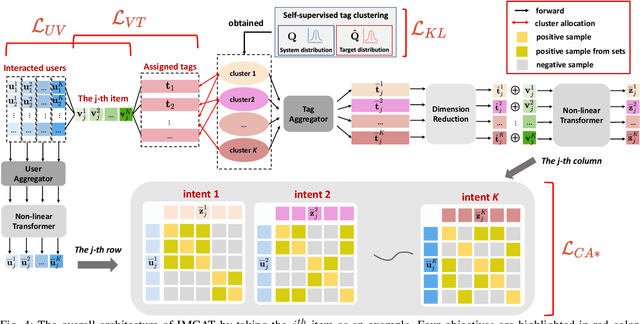
To offer accurate and diverse recommendation services, recent methods use auxiliary information to foster the learning process of user and item representations. Many SOTA methods fuse different sources of information (user, item, knowledge graph, tags, etc.) into a graph and use Graph Neural Networks to introduce the auxiliary information through the message passing paradigm. In this work, we seek an alternative framework that is light and effective through self-supervised learning across different sources of information, particularly for the commonly accessible item tag information. We use a self-supervision signal to pair users with the auxiliary information associated with the items they have interacted with before. To achieve the pairing, we create a proxy training task. For a given item, the model predicts the correct pairing between the representations obtained from the users that have interacted with this item and the assigned tags. This design provides an efficient solution, using the auxiliary information directly to enhance the quality of user and item embeddings. User behavior in recommendation systems is driven by the complex interactions of many factors behind the decision-making processes. To make the pairing process more fine-grained and avoid embedding collapse, we propose an intent-aware self-supervised pairing process where we split the user embeddings into multiple sub-embedding vectors. Each sub-embedding vector captures a specific user intent via self-supervised alignment with a particular cluster of tags. We integrate our designed framework with various recommendation models, demonstrating its flexibility and compatibility. Through comparison with numerous SOTA methods on seven real-world datasets, we show that our method can achieve better performance while requiring less training time. This indicates the potential of applying our approach on web-scale datasets.
Fourier Disentangled Space-Time Attention for Aerial Video Recognition
Mar 21, 2022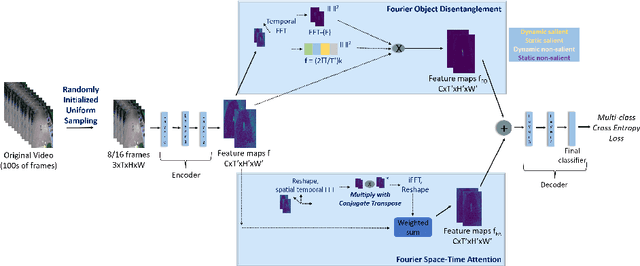


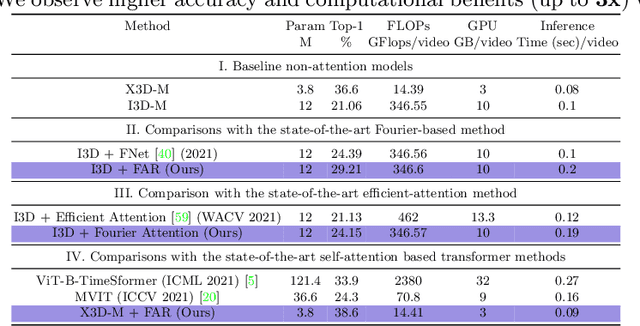
We present an algorithm, Fourier Activity Recognition (FAR), for UAV video activity recognition. Our formulation uses a novel Fourier object disentanglement method to innately separate out the human agent (which is typically small) from the background. Our disentanglement technique operates in the frequency domain to characterize the extent of temporal change of spatial pixels, and exploits convolution-multiplication properties of Fourier transform to map this representation to the corresponding object-background entangled features obtained from the network. To encapsulate contextual information and long-range space-time dependencies, we present a novel Fourier Attention algorithm, which emulates the benefits of self-attention by modeling the weighted outer product in the frequency domain. Our Fourier attention formulation uses much fewer computations than self-attention. We have evaluated our approach on multiple UAV datasets including UAV Human RGB, UAV Human Night, Drone Action, and NEC Drone. We demonstrate a relative improvement of 8.02% - 38.69% in top-1 accuracy and up to 3 times faster over prior works.
HTGN-BTW: Heterogeneous Temporal Graph Network with Bi-Time-Window Training Strategy for Temporal Link Prediction
Feb 25, 2022
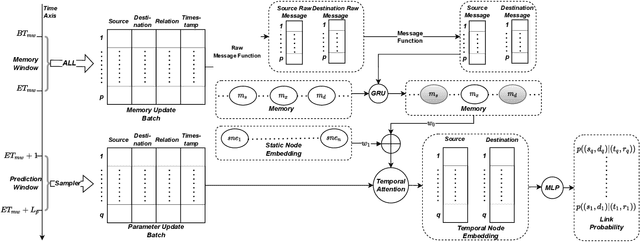
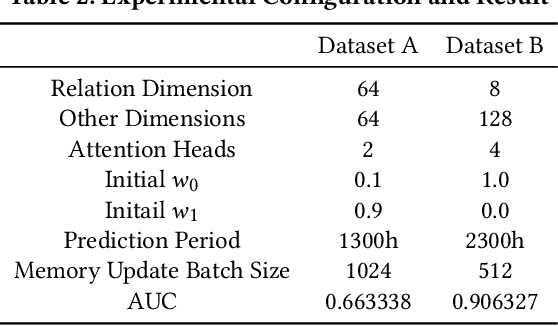
With the development of temporal networks such as E-commerce networks and social networks, the issue of temporal link prediction has attracted increasing attention in recent years. The Temporal Link Prediction task of WSDM Cup 2022 expects a single model that can work well on two kinds of temporal graphs simultaneously, which have quite different characteristics and data properties, to predict whether a link of a given type will occur between two given nodes within a given time span. Our team, named as nothing here, regards this task as a link prediction task in heterogeneous temporal networks and proposes a generic model, i.e., Heterogeneous Temporal Graph Network (HTGN), to solve such temporal link prediction task with the unfixed time intervals and the diverse link types. That is, HTGN can adapt to the heterogeneity of links and the prediction with unfixed time intervals within an arbitrary given time period. To train the model, we design a Bi-Time-Window training strategy (BTW) which has two kinds of mini-batches from two kinds of time windows. As a result, for the final test, we achieved an AUC of 0.662482 on dataset A, an AUC of 0.906923 on dataset B, and won 2nd place with an Average T-scores of 0.628942.
Validity Assessment of Legal Will Statements as Natural Language Inference
Oct 30, 2022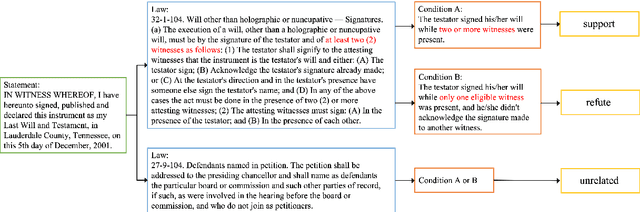
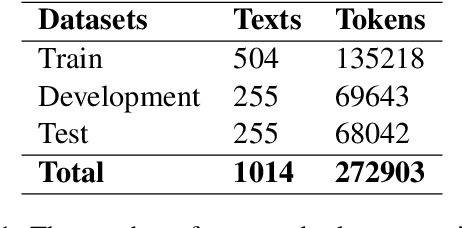
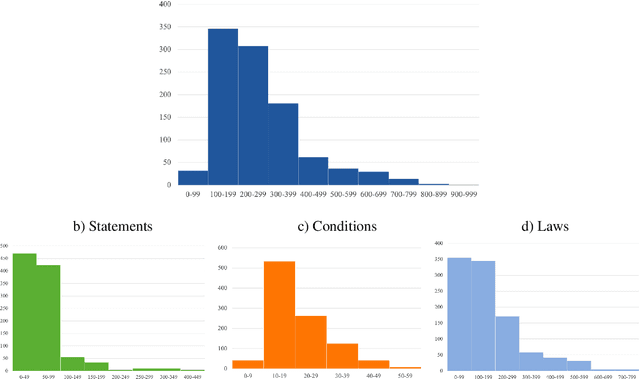
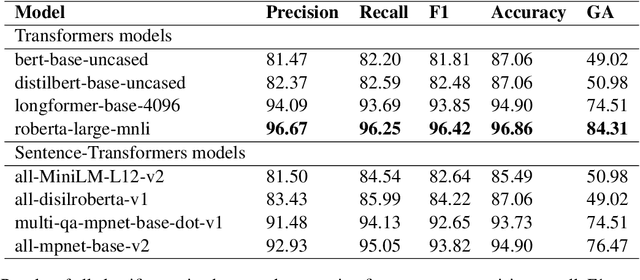
This work introduces a natural language inference (NLI) dataset that focuses on the validity of statements in legal wills. This dataset is unique because: (a) each entailment decision requires three inputs: the statement from the will, the law, and the conditions that hold at the time of the testator's death; and (b) the included texts are longer than the ones in current NLI datasets. We trained eight neural NLI models in this dataset. All the models achieve more than 80% macro F1 and accuracy, which indicates that neural approaches can handle this task reasonably well. However, group accuracy, a stricter evaluation measure that is calculated with a group of positive and negative examples generated from the same statement as a unit, is in mid 80s at best, which suggests that the models' understanding of the task remains superficial. Further ablative analyses and explanation experiments indicate that all three text segments are used for prediction, but some decisions rely on semantically irrelevant tokens. This indicates that overfitting on these longer texts likely happens, and that additional research is required for this task to be solved.
Scalable and self-correcting photonic computation using balanced photonic binary tree cascades
Oct 30, 2022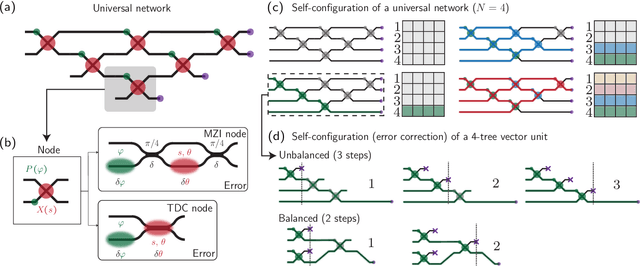
Programmable unitary photonic networks that interfere hundreds of modes are emerging as a key technology in energy-efficient sensing, machine learning, cryptography, and linear optical quantum computing applications. In this work, we establish a theoretical framework to quantify error tolerance and scalability in a more general class of "binary tree cascade'' programmable photonic networks that accept up to tens of thousands of discrete input modes $N$. To justify this scalability claim, we derive error tolerance and configuration time that scale with $\log_2 N$ for balanced trees versus $N$ in unbalanced trees, despite the same number of total components. Specifically, we use second-order perturbation theory to compute phase sensitivity in each waveguide of balanced and unbalanced networks, and we compute the statistics of the sensitivity given random input vectors. We also evaluate such networks after they self-correct, or self-configure, themselves for errors in the circuit due to fabrication error and environmental drift. Our findings have important implications for scaling photonic circuits to much larger circuit sizes; this scaling is particularly critical for applications such as principal component analysis and fast Fourier transforms, which are important algorithms for machine learning and signal processing.
Rastreo muscular móvil usando magnetomicrometría -- traducción al español del articulo "Untethered Muscle Tracking Using Magnetomicrometry" por el autor Cameron R. Taylor
Nov 19, 2022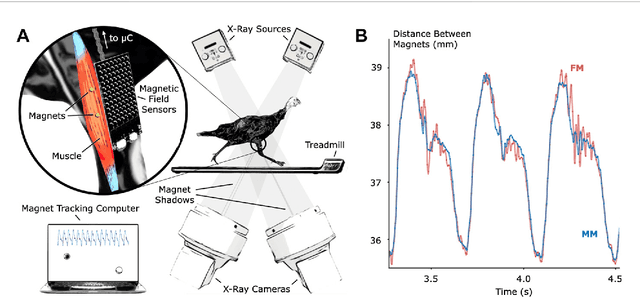

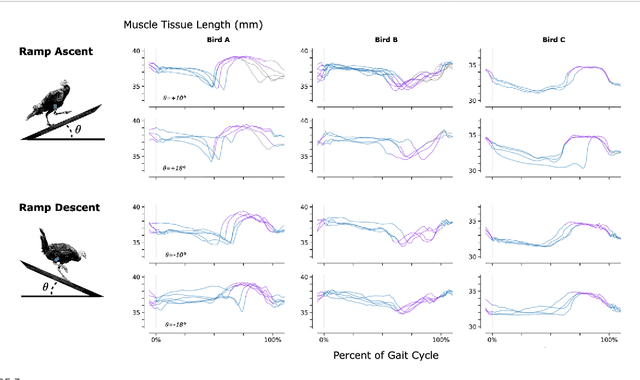
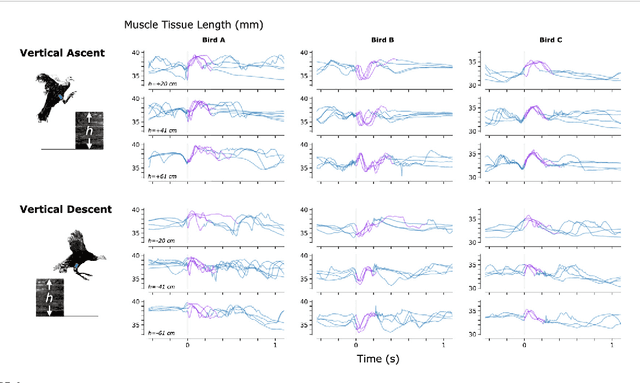
Muscle tissue drives nearly all movement in the animal kingdom, providing power, mobility, and dexterity. Technologies for measuring muscle tissue motion, such as sonomicrometry, fluoromicrometry, and ultrasound, have significantly advanced our understanding of biomechanics. Yet, the field lacks the ability to monitor muscle tissue motion for animal behavior outside the lab. Towards addressing this issue, we previously introduced magnetomicrometry, a method that uses magnetic beads to wirelessly monitor muscle tissue length changes, and we validated magnetomicrometry via tightly-controlled in situ testing. In this study we validate the accuracy of magnetomicrometry against fluoromicrometry during untethered running in an in vivo turkey model. We demonstrate real-time muscle tissue length tracking of the freely-moving turkeys executing various motor activities, including ramp ascent and descent, vertical ascent and descent, and free roaming movement. Given the demonstrated capacity of magnetomicrometry to track muscle movement in untethered animals, we feel that this technique will enable new scientific explorations and an improved understanding of muscle function. -- -- El tejido muscular es el motor de casi todos los movimientos del reino animal, ya que proporciona fuerza, movilidad y destreza. Las tecnolog\'ias para medir el movimiento del tejido muscular, como la sonomicrometr\'ia, la fluoromicrometr\'ia y el ultrasonido, han avanzado considerablemente la comprensi\'on de la biomec\'anica. Sin embargo, este campo carece de la capacidad de rastrear el movimiento del tejido muscular en el comportamiento animal fuera del laboratorio. Para abordar este problema, presentamos previamente la magnetomicrometr\'ia, un m\'etodo que utiliza peque\~nos imanes para rastrear de forma inal\'ambrica los cambios de longitud del tejido muscular, y validamos la magnetomicrometr\'ia mediante pruebas estrechamente controladas in situ. En este estudio validamos la precisi\'on de la magnetomicrometr\'ia en comparaci\'on con la fluoromicrometr\'ia usando un modelo de pavo in vivo mientras corre libremente. Demostramos el rastreo en tiempo real de la longitud del tejido muscular de los pavos que se mueven libremente ejecutando varias actividades motoras, incluyendo el ascenso y el descenso en rampa, el ascenso y el descenso vertical, y el movimiento libre. Dada la capacidad demostrada de la magnetomicrometr\'ia para rastrear el movimiento muscular en animales en un contexto m\'ovil, creemos que esta t\'ecnica permitir\'a nuevas exploraciones cient\'ificas y una mejor comprensi\'on de la funci\'on muscular.
* in Spanish language. Translation of the postprint, with the published version in English appended to the end of the PDF. Shared First Authorship: Cameron R. Taylor and Seong Ho Yeon; Shared Senior and Corresponding Authorship: Thomas J. Roberts and Hugh M. Herr
Short-time Fourier transform based on stimulated Brillouin scattering
Nov 26, 2021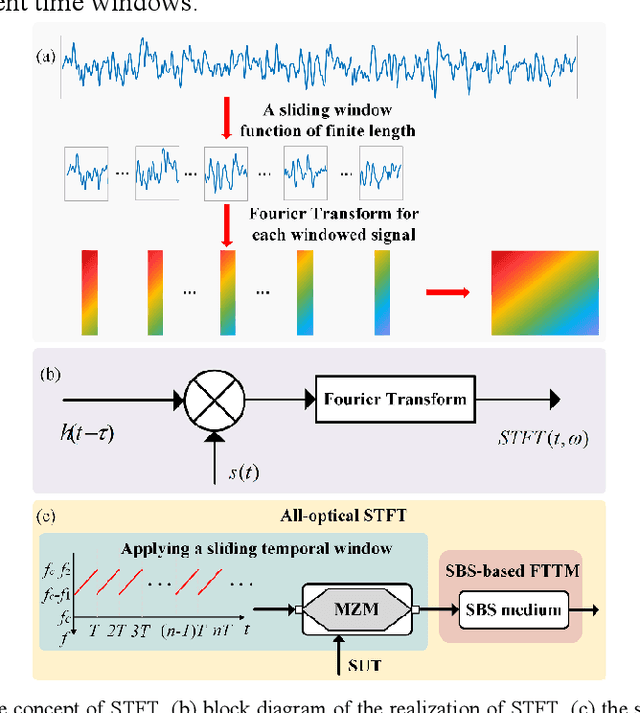
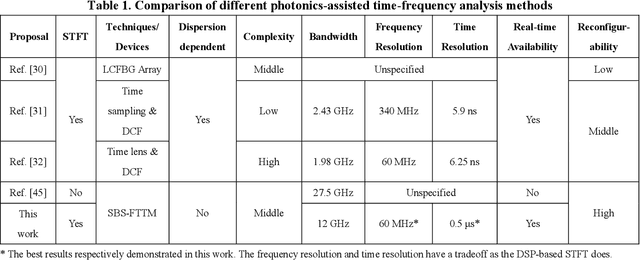
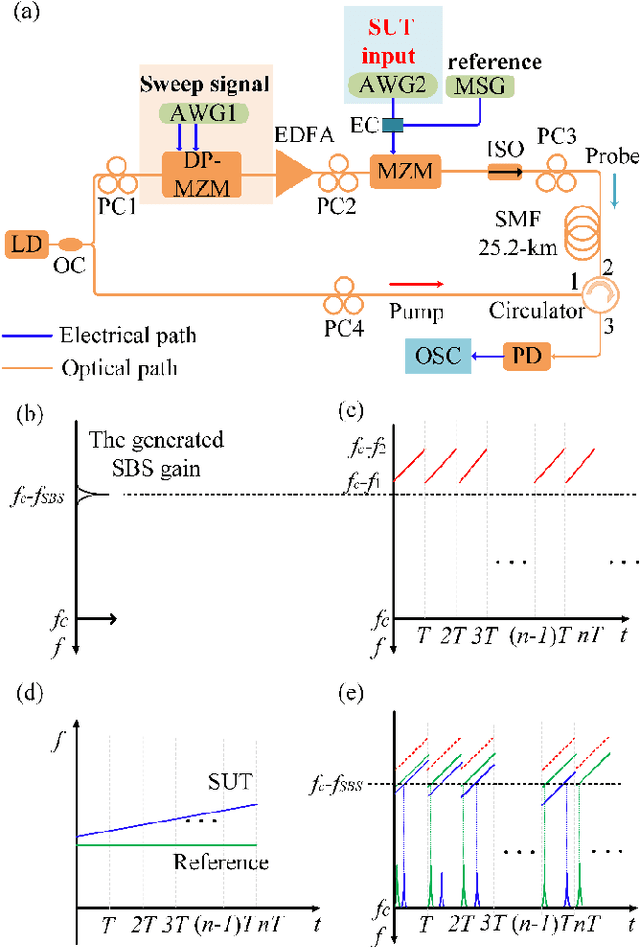
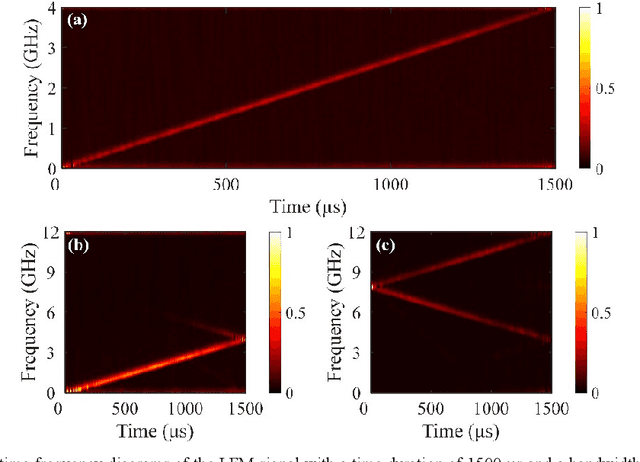
In this paper, all-optical short-time Fourier transform (STFT) based on stimulated Brillouin scattering (SBS) is proposed and further used for real-time time-frequency analysis of different radio frequency (RF) signals. In the proposed all-optical STFT system, SBS not only provides a band-pass filter for implementing the window function in conjunction with a periodic frequency-sweep optical signal but also obtains the frequency domain information in different time windows through the generated waveform via frequency-to-time mapping (FTTM). A periodic frequency-sweep optical signal is generated and then modulated at a Mach-Zehnder modulator by the electrical signal under test (SUT). During different sweep periods, the fixed Brillouin gain functions as a bandpass filter to select a specific range of the spectrum, which is equivalent to applying a sliding window function to the corresponding section of the temporal signal with the help of the sweep optical signal. At the same time, after the optical signal is selectively amplified by the SBS gain and converted back to the electrical domain, SBS also implements the real-time FTTM, which can be utilized to obtain the frequency domain information corresponding to different time windows through the generated waveforms via the FTTM. The frequency domain information corresponding to different time windows is formed and spliced to analyze the time-frequency relationship of the SUT in real-time. An experiment is performed. STFTs of a variety of RF signals are carried out in a 12-GHz bandwidth limited only by the equipment, and the dynamic frequency resolution is better than 60 MHz.
Incremental Correction in Dynamic Systems Modelled with Neural Networks for Constraint Satisfaction
Sep 08, 2022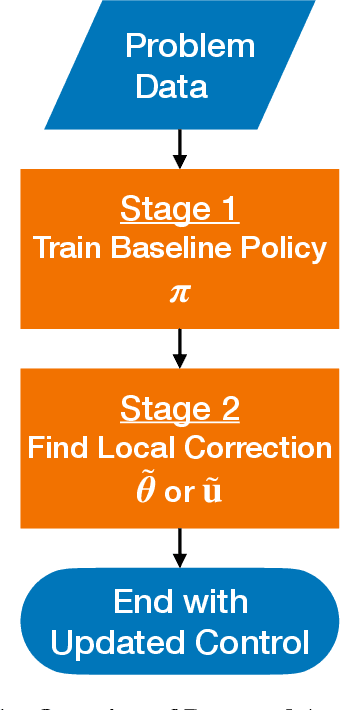

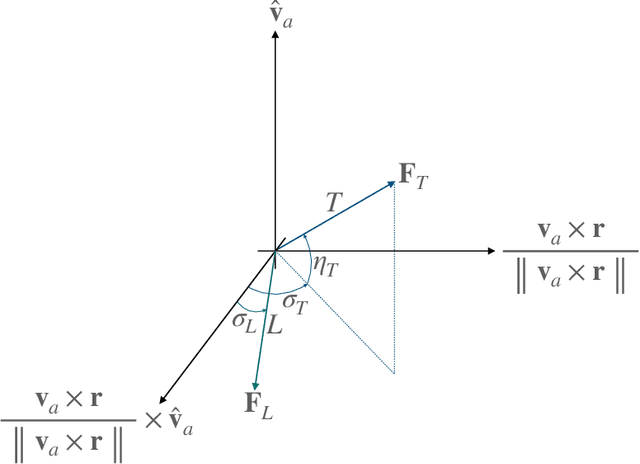
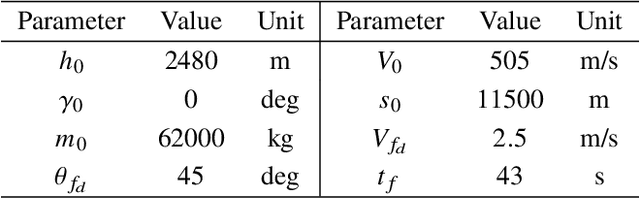
This study presents incremental correction methods for refining neural network parameters or control functions entering into a continuous-time dynamic system to achieve improved solution accuracy in satisfying the interim point constraints placed on the performance output variables. The proposed approach is to linearise the dynamics around the baseline values of its arguments, and then to solve for the corrective input required to transfer the perturbed trajectory to precisely known or desired values at specific time points, i.e., the interim points. Depending on the type of decision variables to adjust, parameter correction and control function correction methods are developed. These incremental correction methods can be utilised as a means to compensate for the prediction errors of pre-trained neural networks in real-time applications where high accuracy of the prediction of dynamical systems at prescribed time points is imperative. In this regard, the online update approach can be useful for enhancing overall targeting accuracy of finite-horizon control subject to point constraints using a neural policy. Numerical example demonstrates the effectiveness of the proposed approach in an application to a powered descent problem at Mars.
Speaker Identification from emotional and noisy speech data using learned voice segregation and Speech VGG
Oct 23, 2022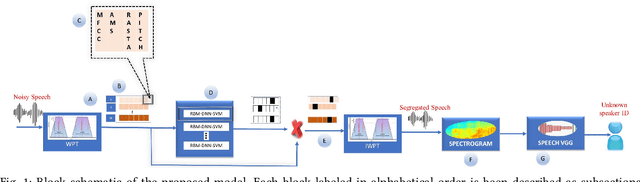
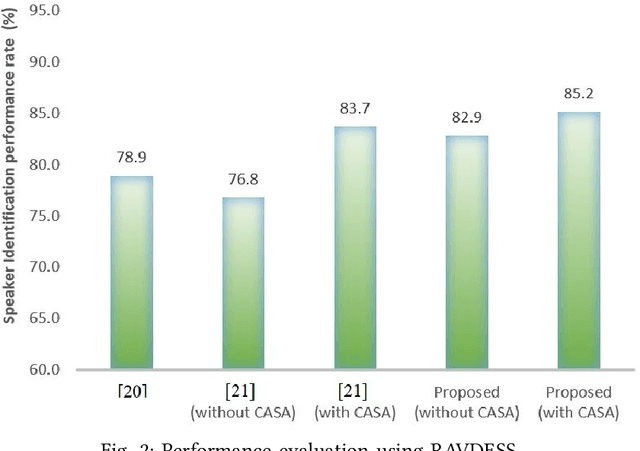
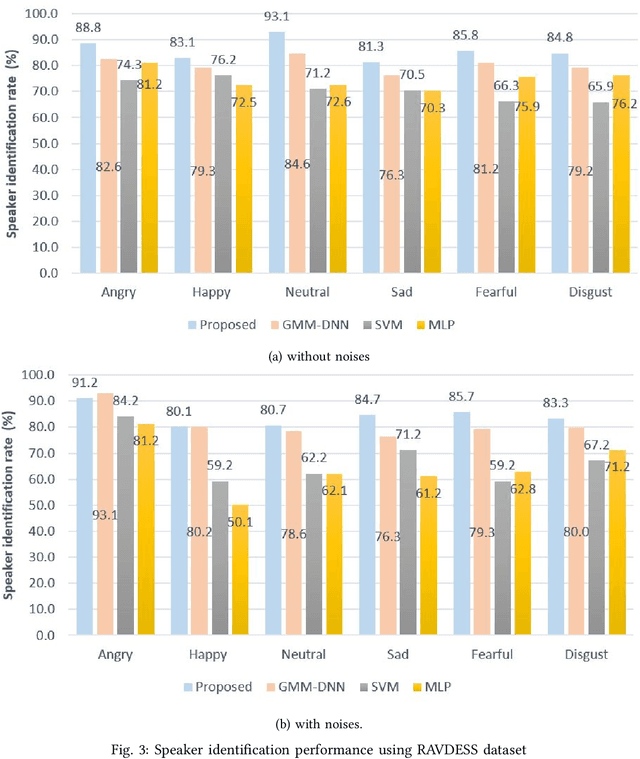
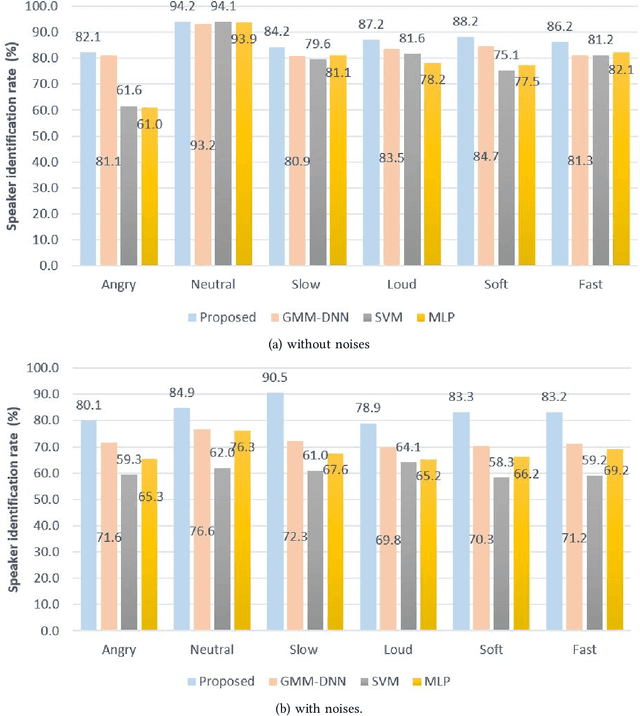
Speech signals are subjected to more acoustic interference and emotional factors than other signals. Noisy emotion-riddled speech data is a challenge for real-time speech processing applications. It is essential to find an effective way to segregate the dominant signal from other external influences. An ideal system should have the capacity to accurately recognize required auditory events from a complex scene taken in an unfavorable situation. This paper proposes a novel approach to speaker identification in unfavorable conditions such as emotion and interference using a pre-trained Deep Neural Network mask and speech VGG. The proposed model obtained superior performance over the recent literature in English and Arabic emotional speech data and reported an average speaker identification rate of 85.2\%, 87.0\%, and 86.6\% using the Ryerson audio-visual dataset (RAVDESS), speech under simulated and actual stress (SUSAS) dataset and Emirati-accented Speech dataset (ESD) respectively.
Realistic Data Augmentation Framework for Enhancing Tabular Reasoning
Oct 23, 2022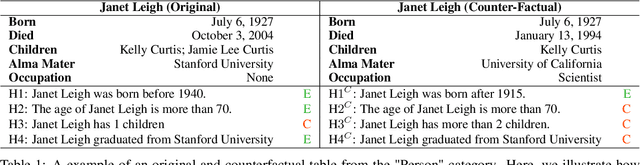
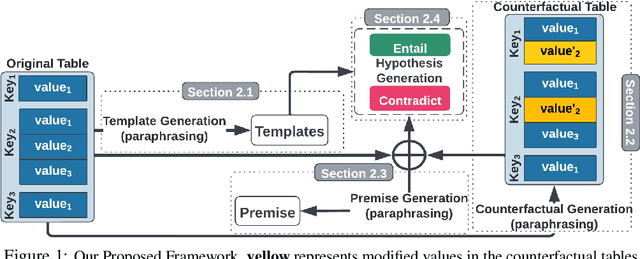
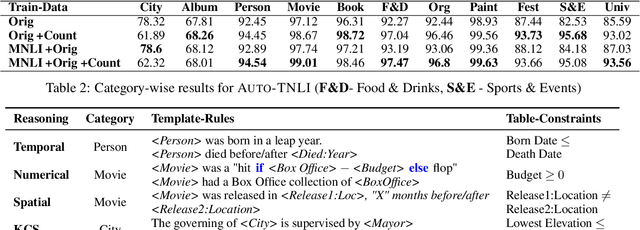
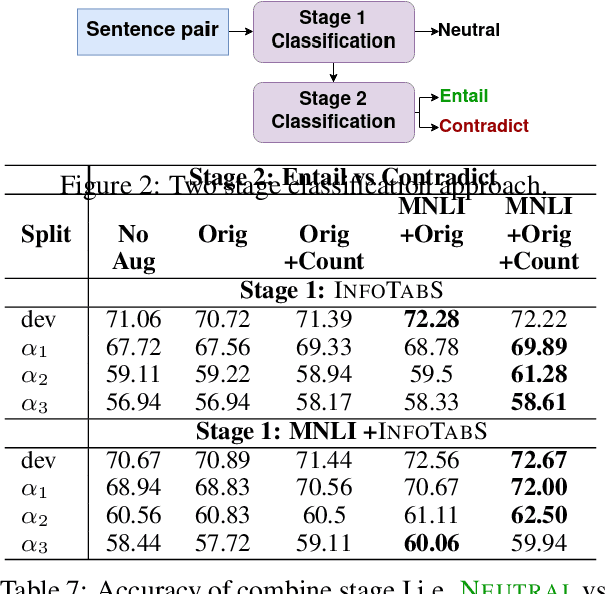
Existing approaches to constructing training data for Natural Language Inference (NLI) tasks, such as for semi-structured table reasoning, are either via crowdsourcing or fully automatic methods. However, the former is expensive and time-consuming and thus limits scale, and the latter often produces naive examples that may lack complex reasoning. This paper develops a realistic semi-automated framework for data augmentation for tabular inference. Instead of manually generating a hypothesis for each table, our methodology generates hypothesis templates transferable to similar tables. In addition, our framework entails the creation of rational counterfactual tables based on human written logical constraints and premise paraphrasing. For our case study, we use the InfoTabs, which is an entity-centric tabular inference dataset. We observed that our framework could generate human-like tabular inference examples, which could benefit training data augmentation, especially in the scenario with limited supervision.