 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Linear Time Kernel Matrix Approximation via Hyperspherical Harmonics
Feb 08, 2022
We propose a new technique for constructing low-rank approximations of matrices that arise in kernel methods for machine learning. Our approach pairs a novel automatically constructed analytic expansion of the underlying kernel function with a data-dependent compression step to further optimize the approximation. This procedure works in linear time and is applicable to any isotropic kernel. Moreover, our method accepts the desired error tolerance as input, in contrast to prevalent methods which accept the rank as input. Experimental results show our approach compares favorably to the commonly used Nystrom method with respect to both accuracy for a given rank and computational time for a given accuracy across a variety of kernels, dimensions, and datasets. Notably, in many of these problem settings our approach produces near-optimal low-rank approximations. We provide an efficient open-source implementation of our new technique to complement our theoretical developments and experimental results.
Learning from Multiple Time Series: A Deep Disentangled Approach to Diversified Time Series Forecasting
Nov 09, 2021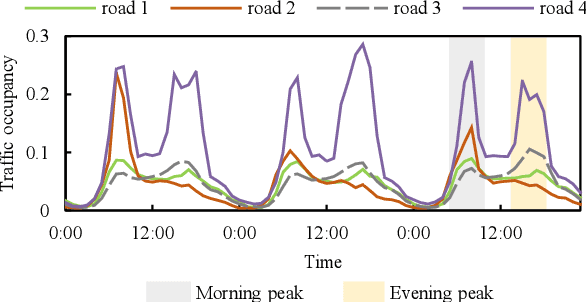
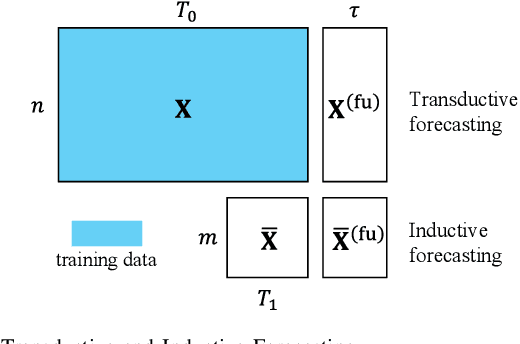
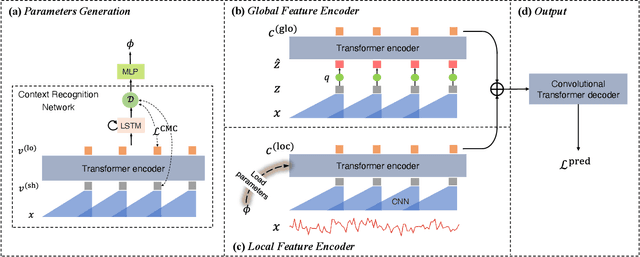
Time series forecasting is a significant problem in many applications, e.g., financial predictions and business optimization. Modern datasets can have multiple correlated time series, which are often generated with global (shared) regularities and local (specific) dynamics. In this paper, we seek to tackle such forecasting problems with DeepDGL, a deep forecasting model that disentangles dynamics into global and local temporal patterns. DeepDGL employs an encoder-decoder architecture, consisting of two encoders to learn global and local temporal patterns, respectively, and a decoder to make multi-step forecasting. Specifically, to model complicated global patterns, the vector quantization (VQ) module is introduced, allowing the global feature encoder to learn a shared codebook among all time series. To model diversified and heterogenous local patterns, an adaptive parameter generation module enhanced by the contrastive multi-horizon coding (CMC) is proposed to generate the parameters of the local feature encoder for each individual time series, which maximizes the mutual information between the series-specific context variable and the long/short-term representations of the corresponding time series. Our experiments on several real-world datasets show that DeepDGL outperforms existing state-of-the-art models.
Multi-Scenario Bimetric-Balanced IoT Resource Allocation: An Evolutionary Approach
Nov 10, 2022
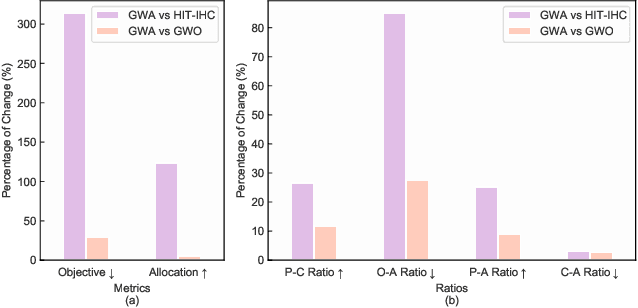
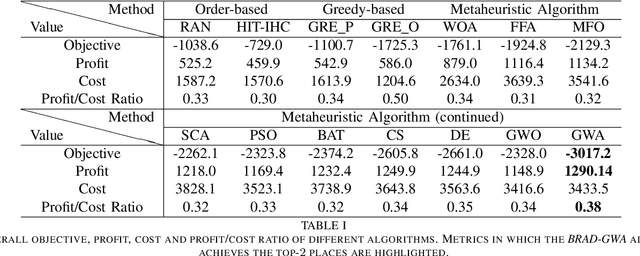
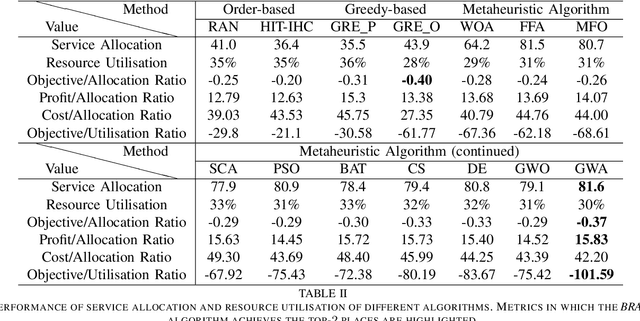
In this paper, we allocate IoT devices as resources for smart services with time-constrained resource requirements. The allocation method named as BRAD can work under multiple resource scenarios with diverse resource richnesses, availabilities and costs, such as the intelligent healthcare system deployed by Harbin Institute of Technology (HIT-IHC). The allocation aims for bimetric-balancing under the multi-scenario case, i.e., the profit and cost associated with service satisfaction are jointly optimised and balanced wisely. Besides, we abstract IoT devices as digital objects (DO) to make them easier to interact with during resource allocation. Considering that the problem is NP-Hard and the optimisation objective is not differentiable, we utilise Grey Wolf Optimisation (GWO) algorithm as the model optimiser. Specifically, we tackle the deficiencies of GWO and significantly improve its performance by introducing three new mechanisms to form the BRAD-GWA algorithm. Comprehensive experiments are conducted on realistic HIT-IHC IoT testbeds and several algorithms are compared, including the allocation method originally used by HIT-IHC system to verify the effectiveness of the BRAD-GWA. The BRAD-GWA achieves a 3.14 times and 29.6% objective reduction compared with the HIT-IHC and the original GWO algorithm, respectively.
Electroadhesive Auxetics as Programmable Layer Jamming Skins for Formable Crust Shape Displays
Nov 10, 2022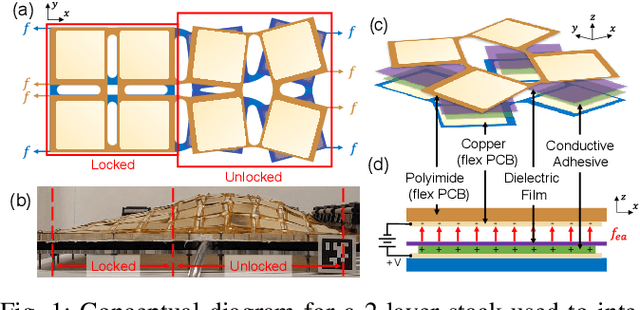
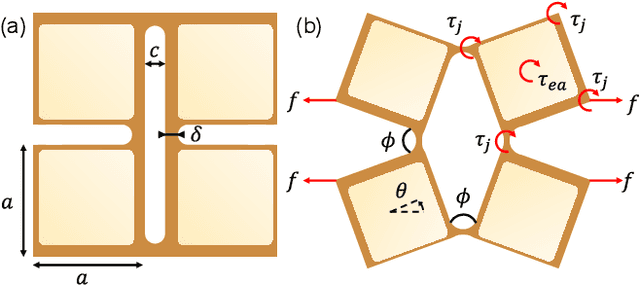
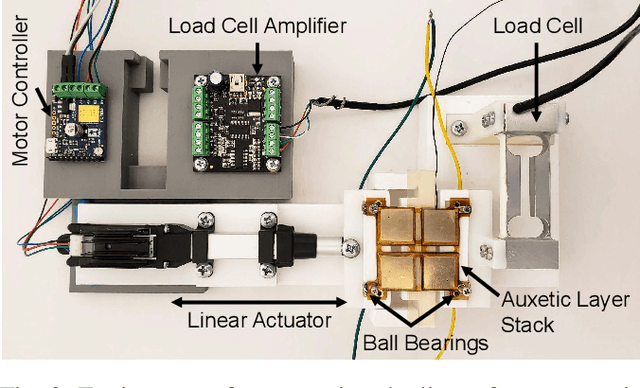
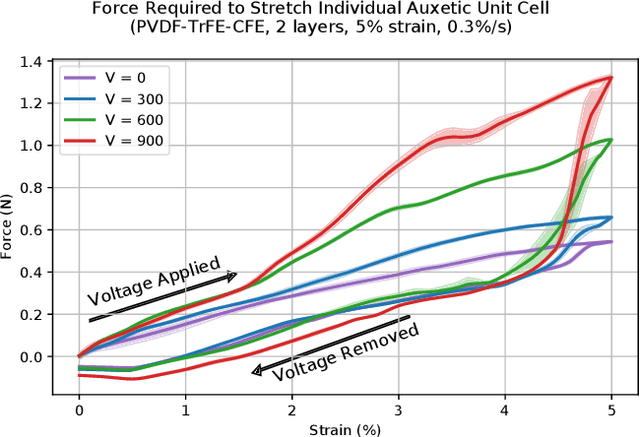
Shape displays are a class of haptic devices that enable whole-hand haptic exploration of 3D surfaces. However, their scalability is limited by the mechanical complexity and high cost of traditional actuator arrays. In this paper, we propose using electroadhesive auxetic skins as a strain-limiting layer to create programmable shape change in a continuous ("formable crust") shape display. Auxetic skins are manufactured as flexible printed circuit boards with dielectric-laminated electrodes on each auxetic unit cell (AUC), using monolithic fabrication to lower cost and assembly time. By layering multiple sheets and applying a voltage between electrodes on subsequent layers, electroadhesion locks individual AUCs, achieving a maximum in-plane stiffness variation of 7.6x with a power consumption of 50 uW/AUC. We first characterize an individual AUC and compare results to a kinematic model. We then validate the ability of a 5x5 AUC array to actively modify its own axial and transverse stiffness. Finally, we demonstrate this array in a continuous shape display as a strain-limiting skin to programmatically modulate the shape output of an inflatable LDPE pouch. Integrating electroadhesion with auxetics enables new capabilities for scalable, low-profile, and low-power control of flexible robotic systems.
Reliable Extraction of Semantic Information and Rate of Innovation Estimation for Graph Signals
Nov 10, 2022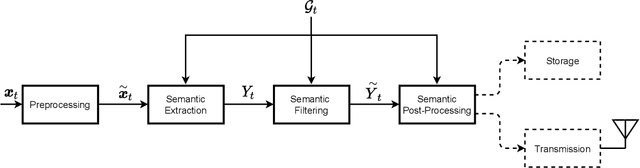
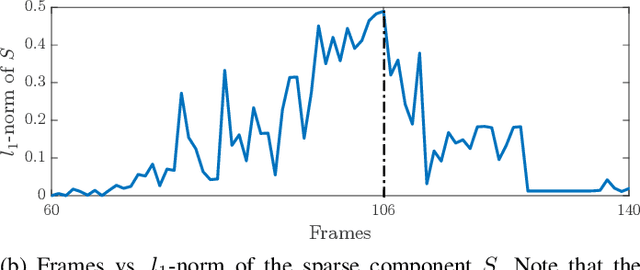
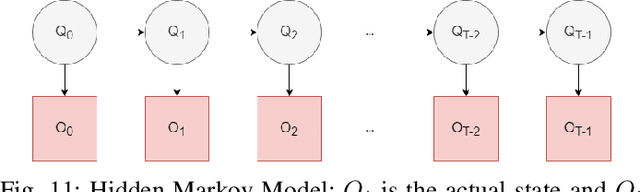
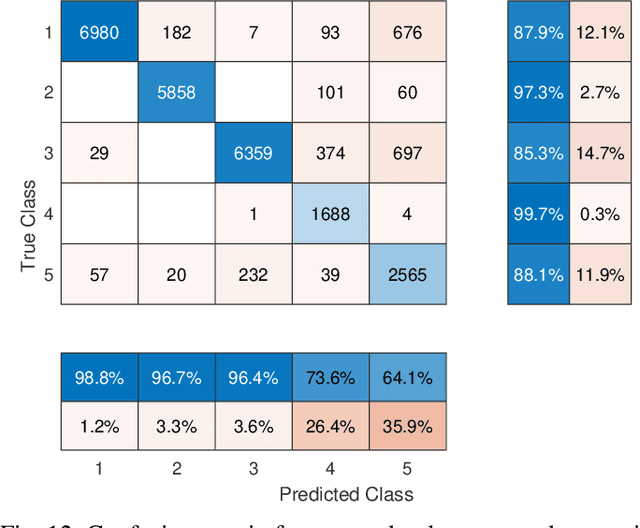
Semantic signal processing and communications are poised to play a central part in developing the next generation of sensor devices and networks. A crucial component of a semantic system is the extraction of semantic signals from the raw input signals, which has become increasingly tractable with the recent advances in machine learning (ML) and artificial intelligence (AI) techniques. The accurate extraction of semantic signals using the aforementioned ML and AI methods, and the detection of semantic innovation for scheduling transmission and/or storage events are critical tasks for reliable semantic signal processing and communications. In this work, we propose a reliable semantic information extraction framework based on our previous work on semantic signal representations in a hierarchical graph-based structure. The proposed framework includes a time integration method to increase fidelity of ML outputs in a class-aware manner, a graph-edit-distance based metric to detect innovation events at the graph-level and filter out sporadic errors, and a Hidden Markov Model (HMM) to produce smooth and reliable graph signals. The proposed methods within the framework are demonstrated individually and collectively through simulations and case studies based on real-world computer vision examples.
Desire Backpropagation: A Lightweight Training Algorithm for Multi-Layer Spiking Neural Networks based on Spike-Timing-Dependent Plasticity
Nov 10, 2022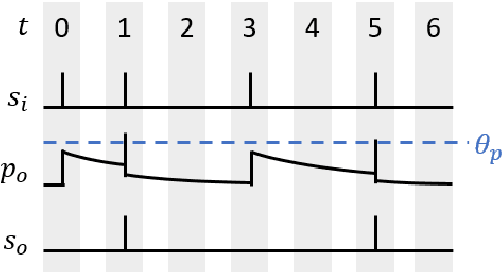
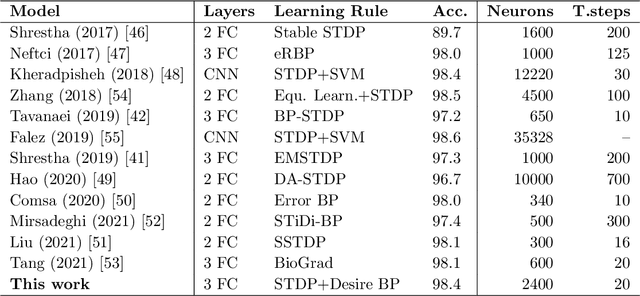
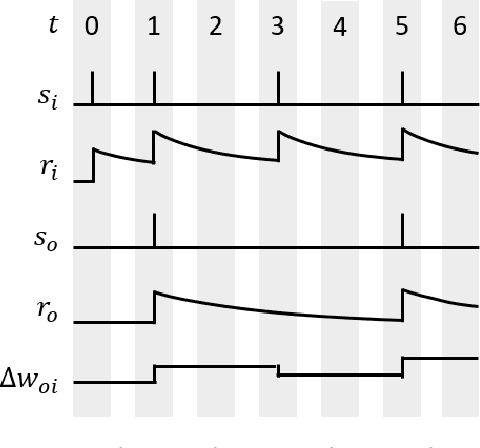

Spiking neural networks (SNN) are a viable alternative to conventional artificial neural networks when energy efficiency and computational complexity are of importance. A major advantage of SNNs is their binary information transfer through spike trains. The training of SNN has, however, been a challenge, since neuron models are non-differentiable and traditional gradient-based backpropagation algorithms cannot be applied directly. Furthermore, spike-timing-dependent plasticity (STDP), albeit being a spike-based learning rule, updates weights locally and does not optimize for the output error of the network. We present desire backpropagation, a method to derive the desired spike activity of neurons from the output error. The loss function can then be evaluated locally for every neuron. Incorporating the desire values into the STDP weight update leads to global error minimization and increasing classification accuracy. At the same time, the neuron dynamics and computational efficiency of STDP are maintained, making it a spike-based supervised learning rule. We trained three-layer networks to classify MNIST and Fashion-MNIST images and reached an accuracy of 98.41% and 87.56%, respectively. Furthermore, we show that desire backpropagation is computationally less complex than backpropagation in traditional neural networks.
Sinusoidal Frequency Estimation by Gradient Descent
Oct 26, 2022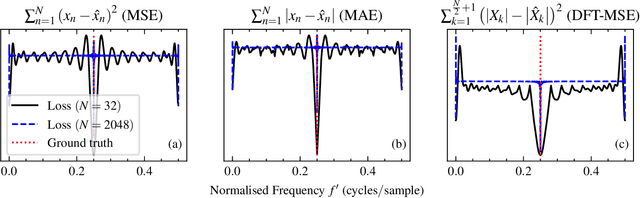
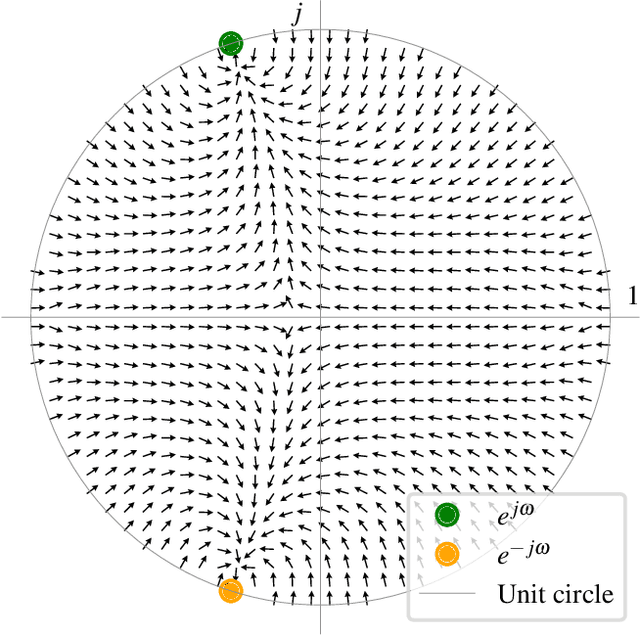
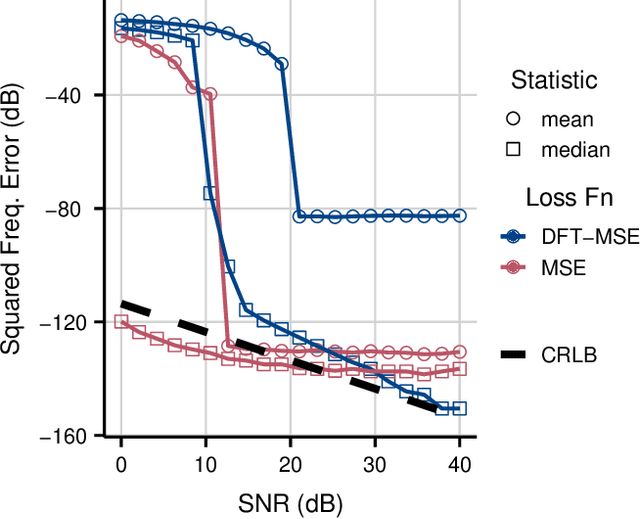
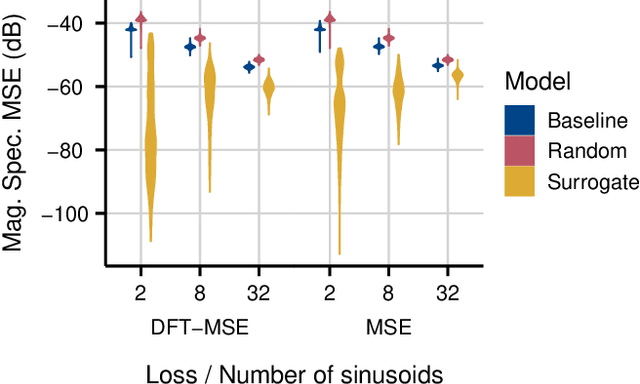
Sinusoidal parameter estimation is a fundamental task in applications from spectral analysis to time-series forecasting. Estimating the sinusoidal frequency parameter by gradient descent is, however, often impossible as the error function is non-convex and densely populated with local minima. The growing family of differentiable signal processing methods has therefore been unable to tune the frequency of oscillatory components, preventing their use in a broad range of applications. This work presents a technique for joint sinusoidal frequency and amplitude estimation using the Wirtinger derivatives of a complex exponential surrogate and any first order gradient-based optimizer, enabling end to-end training of neural network controllers for unconstrained sinusoidal models.
Hierarchical Federated Learning with Momentum Acceleration in Multi-Tier Networks
Oct 26, 2022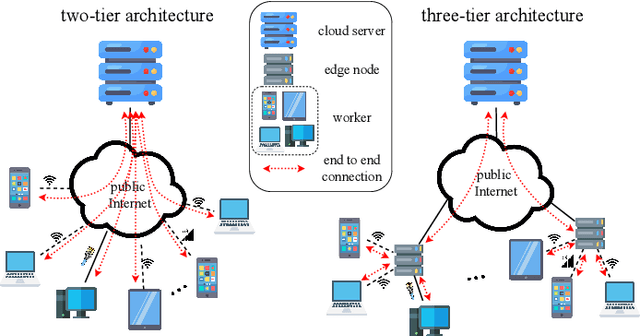
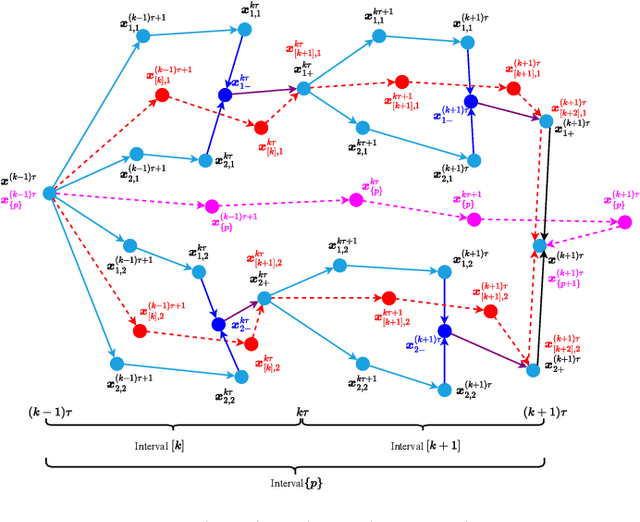
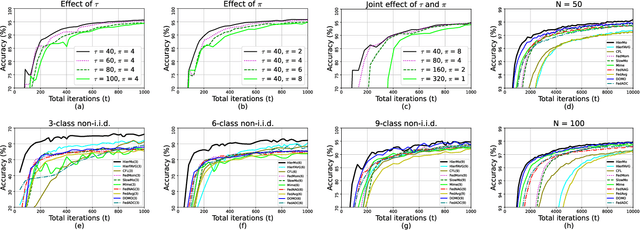
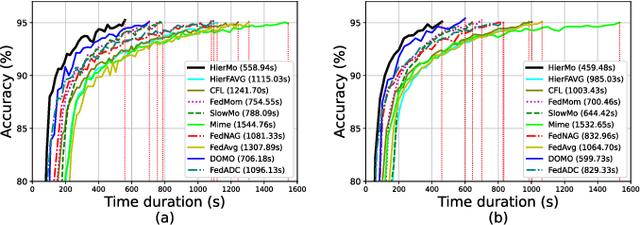
In this paper, we propose Hierarchical Federated Learning with Momentum Acceleration (HierMo), a three-tier worker-edge-cloud federated learning algorithm that applies momentum for training acceleration. Momentum is calculated and aggregated in the three tiers. We provide convergence analysis for HierMo, showing a convergence rate of O(1/T). In the analysis, we develop a new approach to characterize model aggregation, momentum aggregation, and their interactions. Based on this result, {we prove that HierMo achieves a tighter convergence upper bound compared with HierFAVG without momentum}. We also propose HierOPT, which optimizes the aggregation periods (worker-edge and edge-cloud aggregation periods) to minimize the loss given a limited training time.
Topological Data Analysis in Time Series: Temporal Filtration and Application to Single-Cell Genomics
Apr 29, 2022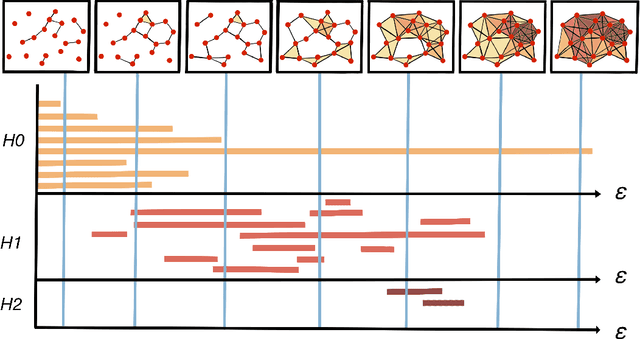
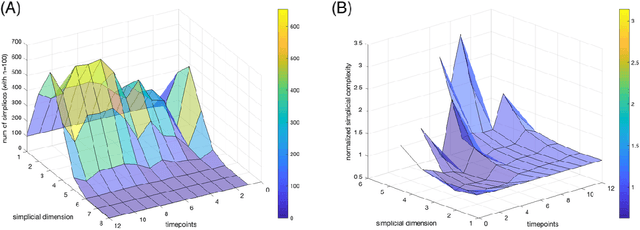
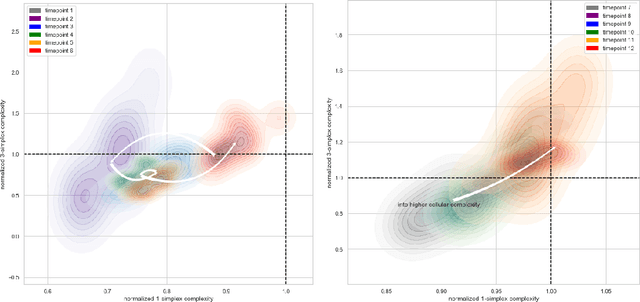
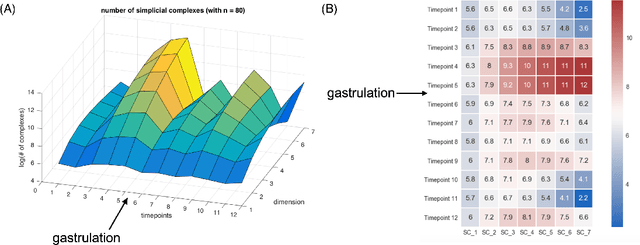
The absence of a conventional association between the cell-cell cohabitation and its emergent dynamics into cliques during development has hindered our understanding of how cell populations proliferate, differentiate, and compete, i.e. the cell ecology. With the recent advancement of the single-cell RNA-sequencing (RNA-seq), we can potentially describe such a link by constructing network graphs that characterize the similarity of the gene expression profiles of the cell-specific transcriptional programs, and analyzing these graphs systematically using the summary statistics informed by the algebraic topology. We propose the single-cell topological simplicial analysis (scTSA). Applying this approach to the single-cell gene expression profiles from local networks of cells in different developmental stages with different outcomes reveals a previously unseen topology of cellular ecology. These networks contain an abundance of cliques of single-cell profiles bound into cavities that guide the emergence of more complicated habitation forms. We visualize these ecological patterns with topological simplicial architectures of these networks, compared with the null models. Benchmarked on the single-cell RNA-seq data of zebrafish embryogenesis spanning 38,731 cells, 25 cell types and 12 time steps, our approach highlights the gastrulation as the most critical stage, consistent with consensus in developmental biology. As a nonlinear, model-independent, and unsupervised framework, our approach can also be applied to tracing multi-scale cell lineage, identifying critical stages, or creating pseudo-time series.
Non-contrastive approaches to similarity learning: positive examples are all you need
Sep 28, 2022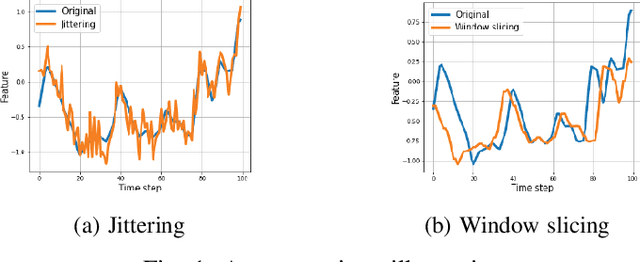



The similarity learning problem in the oil \& gas industry aims to construct a model that estimates similarity between interval measurements for logging data. Previous attempts are mostly based on empirical rules, so our goal is to automate this process and exclude expensive and time-consuming expert labelling. One of the approaches for similarity learning is self-supervised learning (SSL). In contrast to the supervised paradigm, this one requires little or no labels for the data. Thus, we can learn such models even if the data labelling is absent or scarce. Nowadays, most SSL approaches are contrastive and non-contrastive. However, due to possible wrong labelling of positive and negative samples, contrastive methods don't scale well with the number of objects. Non-contrastive methods don't rely on negative samples. Such approaches are actively used in the computer vision. We introduce non-contrastive SSL for time series data. In particular, we build on top of BYOL and Barlow Twins methods that avoid using negative pairs and focus only on matching positive pairs. The crucial part of these methods is an augmentation strategy. Different augmentations of time series exist, while their effect on the performance can be both positive and negative. Our augmentation strategies and adaption for BYOL and Barlow Twins together allow us to achieve a higher quality (ARI $= 0.49$) than other self-supervised methods (ARI $= 0.34$ only), proving usefulness of the proposed non-contrastive self-supervised approach for the interval similarity problem and time series representation learning in general.