 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Bayesian Belief States into Language Models for Auditable Negotiation
May 06, 2026Negotiation agents must infer what their counterpart values, update those beliefs over dialogue turns, and choose actions under uncertainty. End-to-end large language models (LLMs) can imitate negotiation dialogue, but their opponent beliefs are usually implicit and difficult to inspect. We propose BOND (Bayesian Opponent-belief Negotiation Distillation), a framework for auditable negotiation. BOND consists of an LLM-based Bayesian teacher that scores dialogue contexts against the six possible opponent priority orderings, updates a posterior over those orderings, and uses the posterior for menu-based decision making, as well as a smaller 8B student language model that emits both negotiation actions and normalized posterior beliefs as tagged text. In the CaSiNo negotiation dataset, BOND outperforms the state-of-the-art and achieves mean Brier score 0.085 over opponent-priority posteriors. The distilled student preserves much of this belief signal, achieving Brier 0.114, below the uniform six-ordering reference of 5/36, approximately 0.139. Compared with a 70B structured-CoT baseline, the significantly smaller 8B student model yields substantially better elicited posterior calibration. We further showcase auditability through posterior trajectories, belief-versus-policy error decomposition, and posterior-prefix interventions. These diagnostics reveal that distillation preserves a scoreable belief report more strongly than causal belief-conditioned control, making weak belief-action coupling visible, not hidden.
Directional Confusions Reveal Divergent Inductive Biases Through Rate-Distortion Geometry in Human and Machine Vision
Apr 23, 2026Humans and modern vision models can reach similar classification accuracy while making systematically different kinds of mistakes - differing not in how often they err, but in who gets mistaken for whom, and in which direction. We show that these directional confusions reveal distinct inductive biases that are invisible to accuracy alone. Using matched human and deep vision model responses on a natural-image categorization task under 12 perturbation types, we quantify asymmetry in confusion matrices and link it to generalization geometry through a Rate-Distortion (RD) framework, summarized by three geometric signatures (slope (beta), curvature (kappa)) and efficiency (AUC). We find that humans exhibit broad but weak asymmetries, whereas deep vision models show sparser, stronger directional collapses. Robustness training reduces global asymmetry but fails to recover the human-like breadth-strength profile of graded similarity. Mechanistic simulations further show that different asymmetry organizations shift the RD frontier in opposite directions, even when matched for performance. Together, these results position directional confusions and RD geometry as compact, interpretable signatures of inductive bias under distribution shift.
PeReGrINE: Evaluating Personalized Review Fidelity with User Item Graph Context
Apr 09, 2026We introduce PeReGrINE, a benchmark and evaluation framework for personalized review generation grounded in graph-structured user--item evidence. PeReGrINE restructures Amazon Reviews 2023 into a temporally consistent bipartite graph, where each target review is conditioned on bounded evidence from user history, item context, and neighborhood interactions under explicit temporal cutoffs. To represent persistent user preferences without conditioning directly on sparse raw histories, we compute a User Style Parameter that summarizes each user's linguistic and affective tendencies over prior reviews. This setup supports controlled comparison of four graph-derived retrieval settings: product-only, user-only, neighbor-only, and combined evidence. Beyond standard generation metrics, we introduce Dissonance Analysis, a macro-level evaluation framework that measures deviation from expected user style and product-level consensus. We also study visual evidence as an auxiliary context source and find that it can improve textual quality in some settings, while graph-derived evidence remains the main driver of personalization and consistency. Across product categories, PeReGrINE offers a reproducible way to study how evidence composition affects review fidelity, personalization, and grounding in retrieval-conditioned language models.
Rate-Distortion Signatures of Generalization and Information Trade-offs
Mar 02, 2026Generalization to novel visual conditions remains a central challenge for both human and machine vision, yet standard robustness metrics offer limited insight into how systems trade accuracy for robustness. We introduce a rate-distortion-theoretic framework that treats stimulus-response behavior as an effective communication channel, derives rate-distortion (RD) frontiers from confusion matrices, and summarizes each system with two interpretable geometric signatures - slope ($β$) and curvature ($κ$) - which capture the marginal cost and abruptness of accuracy-robustness trade-offs. Applying this framework to human psychophysics and 18 deep vision models under controlled image perturbations, we compare generalization geometry across model architectures and training regimes. We find that both biological and artificial systems follow a common lossy-compression principle but occupy systematically different regions of RD space. In particular, humans exhibit smoother, more flexible trade-offs, whereas modern deep networks operate in steeper and more brittle regimes even at matched accuracy. Across training regimes, robustness training induces systematic but dissociable shifts in beta/kappa, revealing cases where improved robustness or accuracy does not translate into more human-like generalization geometry. These results demonstrate that RD geometry provides a compact, model-agnostic lens for comparing generalization behavior across systems beyond standard accuracy-based metrics.
Word Clouds as Common Voices: LLM-Assisted Visualization of Participant-Weighted Themes in Qualitative Interviews
Aug 11, 2025


Word clouds are a common way to summarize qualitative interviews, yet traditional frequency-based methods often fail in conversational contexts: they surface filler words, ignore paraphrase, and fragment semantically related ideas. This limits their usefulness in early-stage analysis, when researchers need fast, interpretable overviews of what participant actually said. We introduce ThemeClouds, an open-source visualization tool that uses large language models (LLMs) to generate thematic, participant-weighted word clouds from dialogue transcripts. The system prompts an LLM to identify concept-level themes across a corpus and then counts how many unique participants mention each topic, yielding a visualization grounded in breadth of mention rather than raw term frequency. Researchers can customize prompts and visualization parameters, providing transparency and control. Using interviews from a user study comparing five recording-device configurations (31 participants; 155 transcripts, Whisper ASR), our approach surfaces more actionable device concerns than frequency clouds and topic-modeling baselines (e.g., LDA, BERTopic). We discuss design trade-offs for integrating LLM assistance into qualitative workflows, implications for interpretability and researcher agency, and opportunities for interactive analyses such as per-condition contrasts (``diff clouds'').
Conversational DNA: A New Visual Language for Understanding Dialogue Structure in Human and AI
Aug 11, 2025


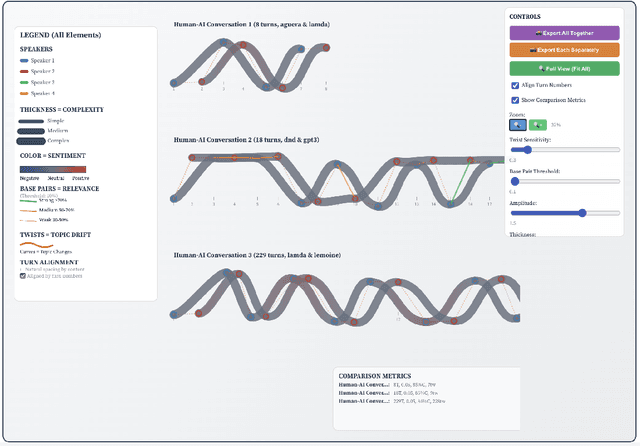
What if the patterns hidden within dialogue reveal more about communication than the words themselves? We introduce Conversational DNA, a novel visual language that treats any dialogue -- whether between humans, between human and AI, or among groups -- as a living system with interpretable structure that can be visualized, compared, and understood. Unlike traditional conversation analysis that reduces rich interaction to statistical summaries, our approach reveals the temporal architecture of dialogue through biological metaphors. Linguistic complexity flows through strand thickness, emotional trajectories cascade through color gradients, conversational relevance forms through connecting elements, and topic coherence maintains structural integrity through helical patterns. Through exploratory analysis of therapeutic conversations and historically significant human-AI dialogues, we demonstrate how this visualization approach reveals interaction patterns that traditional methods miss. Our work contributes a new creative framework for understanding communication that bridges data visualization, human-computer interaction, and the fundamental question of what makes dialogue meaningful in an age where humans increasingly converse with artificial minds.
The Gradient of Health Data Privacy
Oct 01, 2024



In the era of digital health and artificial intelligence, the management of patient data privacy has become increasingly complex, with significant implications for global health equity and patient trust. This paper introduces a novel "privacy gradient" approach to health data governance, offering a more nuanced and adaptive framework than traditional binary privacy models. Our multidimensional concept considers factors such as data sensitivity, stakeholder relationships, purpose of use, and temporal aspects, allowing for context-sensitive privacy protections. Through policy analyses, ethical considerations, and case studies spanning adolescent health, integrated care, and genomic research, we demonstrate how this approach can address critical privacy challenges in diverse healthcare settings worldwide. The privacy gradient model has the potential to enhance patient engagement, improve care coordination, and accelerate medical research while safeguarding individual privacy rights. We provide policy recommendations for implementing this approach, considering its impact on healthcare systems, research infrastructures, and global health initiatives. This work aims to inform policymakers, healthcare leaders, and digital health innovators, contributing to a more equitable, trustworthy, and effective global health data ecosystem in the digital age.
Topological Representational Similarity Analysis in Brains and Beyond
Aug 21, 2024Understanding how the brain represents and processes information is crucial for advancing neuroscience and artificial intelligence. Representational similarity analysis (RSA) has been instrumental in characterizing neural representations, but traditional RSA relies solely on geometric properties, overlooking crucial topological information. This thesis introduces Topological RSA (tRSA), a novel framework combining geometric and topological properties of neural representations. tRSA applies nonlinear monotonic transforms to representational dissimilarities, emphasizing local topology while retaining intermediate-scale geometry. The resulting geo-topological matrices enable model comparisons robust to noise and individual idiosyncrasies. This thesis introduces several key methodological advances: (1) Topological RSA (tRSA) for identifying computational signatures and testing topological hypotheses; (2) Adaptive Geo-Topological Dependence Measure (AGTDM) for detecting complex multivariate relationships; (3) Procrustes-aligned Multidimensional Scaling (pMDS) for revealing neural computation stages; (4) Temporal Topological Data Analysis (tTDA) for uncovering developmental trajectories; and (5) Single-cell Topological Simplicial Analysis (scTSA) for characterizing cell population complexity. Through analyses of neural recordings, biological data, and neural network simulations, this thesis demonstrates the power and versatility of these methods in understanding brains, computational models, and complex biological systems. They not only offer robust approaches for adjudicating among competing models but also reveal novel theoretical insights into the nature of neural computation. This work lays the foundation for future investigations at the intersection of topology, neuroscience, and time series analysis, paving the way for more nuanced understanding of brain function and dysfunction.
Conversational Topic Recommendation in Counseling and Psychotherapy with Decision Transformer and Large Language Models
May 08, 2024



Given the increasing demand for mental health assistance, artificial intelligence (AI), particularly large language models (LLMs), may be valuable for integration into automated clinical support systems. In this work, we leverage a decision transformer architecture for topic recommendation in counseling conversations between patients and mental health professionals. The architecture is utilized for offline reinforcement learning, and we extract states (dialogue turn embeddings), actions (conversation topics), and rewards (scores measuring the alignment between patient and therapist) from previous turns within a conversation to train a decision transformer model. We demonstrate an improvement over baseline reinforcement learning methods, and propose a novel system of utilizing our model's output as synthetic labels for fine-tuning a large language model for the same task. Although our implementation based on LLaMA-2 7B has mixed results, future work can undoubtedly build on the design.
The Machine Can't Replace the Human Heart
Mar 01, 2024What is the true heart of mental healthcare -- innovation or humanity? Can virtual therapy ever replicate the profound human bonds where healing arises? As artificial intelligence and immersive technologies promise expanded access, safeguards must ensure technologies remain supplementary tools guided by providers' wisdom. Implementation requires nuance balancing efficiency and empathy. If conscious of ethical risks, perhaps AI could restore humanity by automating tasks, giving providers more time to listen. Yet no algorithm can replicate the seat of dignity within. We must ask ourselves: What future has people at its core? One where AI thoughtfully plays a collaborative role? Or where pursuit of progress leaves vulnerability behind? This commentary argues for a balanced approach thoughtfully integrating technology while retaining care's irreplaceable human essence, at the heart of this profoundly human profession. Ultimately, by nurturing innovation and humanity together, perhaps we reach new heights of empathy previously unimaginable.