 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMFormer: Empowering Self-supervised Stereo Matching via Foundation Models and Data Augmentation
Apr 11, 2026Recent self-supervised stereo matching methods have made significant progress. They typically rely on the photometric consistency assumption, which presumes corresponding points across views share the same appearance. However, this assumption could be compromised by real-world disturbances, resulting in invalid supervisory signals and a significant accuracy gap compared to supervised methods. To address this issue, we propose SMFormer, a framework integrating more reliable self-supervision guided by the Vision Foundation Model (VFM) and data augmentation. We first incorporate the VFM with the Feature Pyramid Network (FPN), providing a discriminative and robust feature representation against disturbance in various scenarios. We then devise an effective data augmentation mechanism that ensures robustness to various transformations. The data augmentation mechanism explicitly enforces consistency between learned features and those influenced by illumination variations. Additionally, it regularizes the output consistency between disparity predictions of strong augmented samples and those generated from standard samples. Experiments on multiple mainstream benchmarks demonstrate that our SMFormer achieves state-of-the-art (SOTA) performance among self-supervised methods and even competes on par with supervised ones. Remarkably, in the challenging Booster benchmark, SMFormer even outperforms some SOTA supervised methods, such as CFNet.
Hierarchical Federated Learning with Momentum Acceleration in Multi-Tier Networks
Oct 26, 2022In this paper, we propose Hierarchical Federated Learning with Momentum Acceleration (HierMo), a three-tier worker-edge-cloud federated learning algorithm that applies momentum for training acceleration. Momentum is calculated and aggregated in the three tiers. We provide convergence analysis for HierMo, showing a convergence rate of O(1/T). In the analysis, we develop a new approach to characterize model aggregation, momentum aggregation, and their interactions. Based on this result, {we prove that HierMo achieves a tighter convergence upper bound compared with HierFAVG without momentum}. We also propose HierOPT, which optimizes the aggregation periods (worker-edge and edge-cloud aggregation periods) to minimize the loss given a limited training time.
Federated Learning with Nesterov Accelerated Gradient Momentum Method
Sep 18, 2020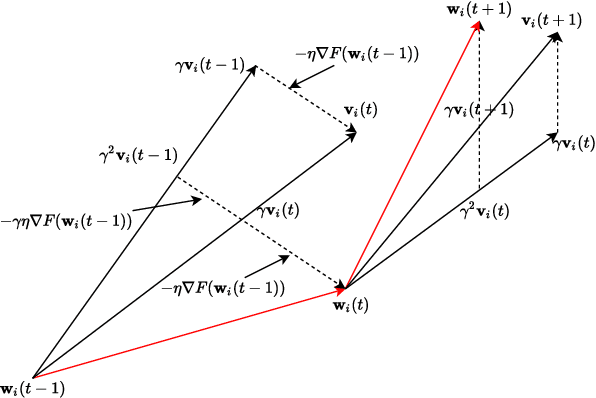
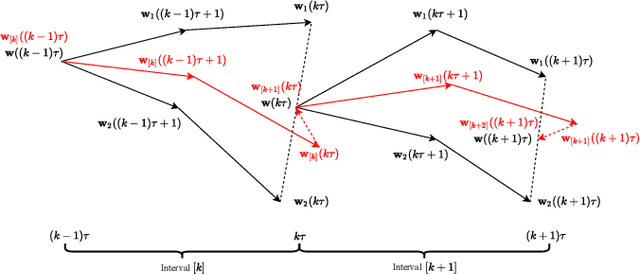
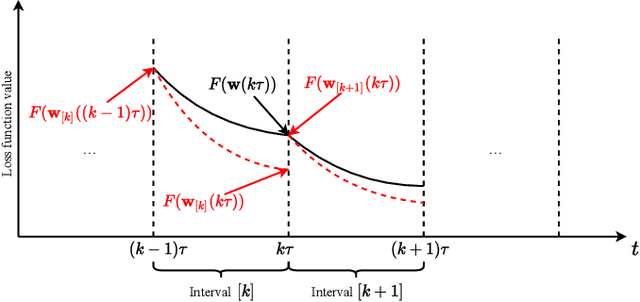
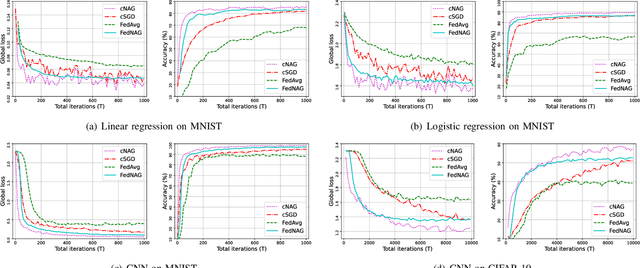
Federated learning (FL) is a fast-developing technique that allows multiple workers to train a global model based on a distributed dataset. Conventional FL employs gradient descent algorithm, which may not be efficient enough. It is well known that Nesterov Accelerated Gradient (NAG) is more advantageous in centralized training environment, but it is not clear how to quantify the benefits of NAG in FL so far. In this work, we focus on a version of FL based on NAG (FedNAG) and provide a detailed convergence analysis. The result is compared with conventional FL based on gradient descent. One interesting conclusion is that as long as the learning step size is sufficiently small, FedNAG outperforms FedAvg. Extensive experiments based on real-world datasets are conducted, verifying our conclusions and confirming the better convergence performance of FedNAG.