 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards Improving Workers' Safety and Progress Monitoring of Construction Sites Through Construction Site Understanding
Oct 27, 2022
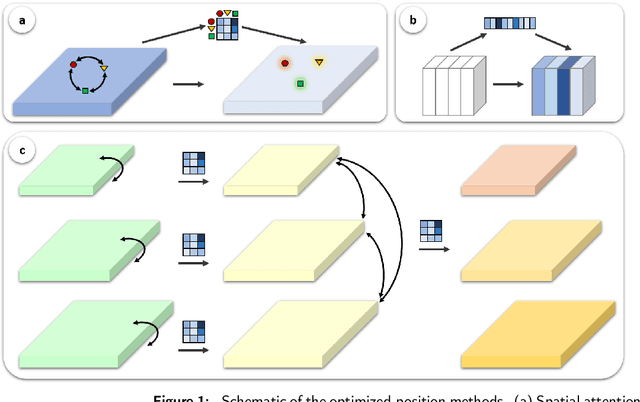
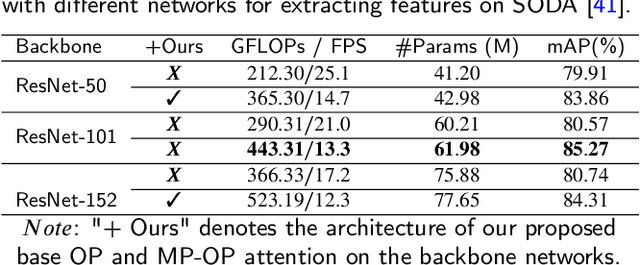
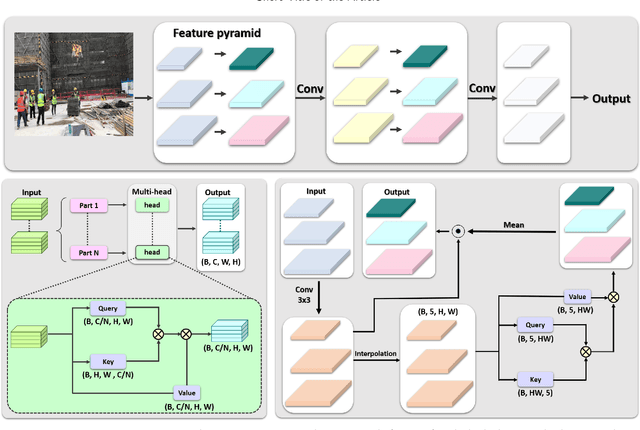
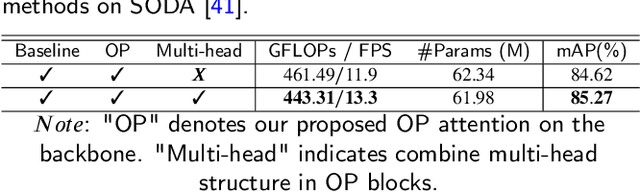
An important component of computer vision research is object detection. In recent years, there has been tremendous progress in the study of construction site images. However, there are obvious problems in construction object detection, including complex backgrounds, varying-sized objects, and poor imaging quality. In the state-of-the-art approaches, elaborate attention mechanisms are developed to handle space-time features, but rarely address the importance of channel-wise feature adjustments. We propose a lightweight Optimized Positioning (OP) module to improve channel relation based on global feature affinity association, which can be used to determine the Optimized weights adaptively for each channel. OP first computes the intermediate optimized position by comparing each channel with the remaining channels for a given set of feature maps. A weighted aggregation of all the channels will then be used to represent each channel. The OP-Net module is a general deep neural network module that can be plugged into any deep neural network. Algorithms that utilize deep learning have demonstrated their ability to identify a wide range of objects from images nearly in real time. Machine intelligence can potentially benefit the construction industry by automatically analyzing productivity and monitoring safety using algorithms that are linked to construction images. The benefits of on-site automatic monitoring are immense when it comes to hazard prevention. Construction monitoring tasks can also be automated once construction objects have been correctly recognized. Object detection task in construction site images is experimented with extensively to demonstrate its efficacy and effectiveness. A benchmark test using SODA demonstrated that our OP-Net was capable of achieving new state-of-the-art performance in accuracy while maintaining a reasonable computational overhead.
Semantic Segmentation under Adverse Conditions: A Weather and Nighttime-aware Synthetic Data-based Approach
Oct 11, 2022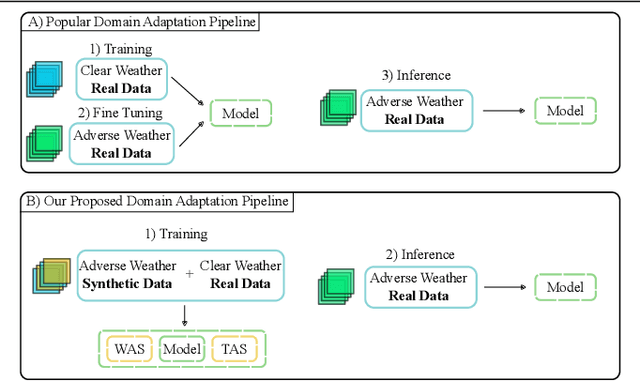


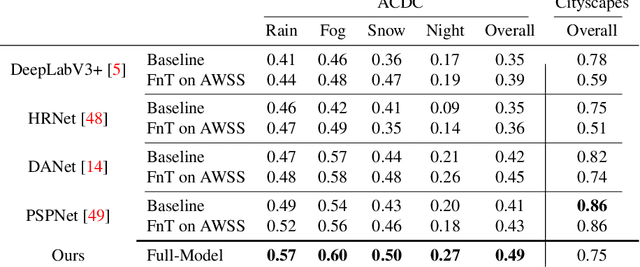
Recent semantic segmentation models perform well under standard weather conditions and sufficient illumination but struggle with adverse weather conditions and nighttime. Collecting and annotating training data under these conditions is expensive, time-consuming, error-prone, and not always practical. Usually, synthetic data is used as a feasible data source to increase the amount of training data. However, just directly using synthetic data may actually harm the model's performance under normal weather conditions while getting only small gains in adverse situations. Therefore, we present a novel architecture specifically designed for using synthetic training data for domain adaptation. We propose a simple yet powerful addition to DeepLabV3+ by using weather and time-of-the-day supervisors trained with multi-task learning, making it both weather and nighttime aware, which improves its mIoU accuracy by $14$ percentage points on the ACDC dataset while maintaining a score of $75\%$ mIoU on the Cityscapes dataset. Our code is available at https://github.com/lsmcolab/Semantic-Segmentation-under-Adverse-Conditions.
Asynchronous Actor-Critic for Multi-Agent Reinforcement Learning
Oct 11, 2022



Synchronizing decisions across multiple agents in realistic settings is problematic since it requires agents to wait for other agents to terminate and communicate about termination reliably. Ideally, agents should learn and execute asynchronously instead. Such asynchronous methods also allow temporally extended actions that can take different amounts of time based on the situation and action executed. Unfortunately, current policy gradient methods are not applicable in asynchronous settings, as they assume that agents synchronously reason about action selection at every time step. To allow asynchronous learning and decision-making, we formulate a set of asynchronous multi-agent actor-critic methods that allow agents to directly optimize asynchronous policies in three standard training paradigms: decentralized learning, centralized learning, and centralized training for decentralized execution. Empirical results (in simulation and hardware) in a variety of realistic domains demonstrate the superiority of our approaches in large multi-agent problems and validate the effectiveness of our algorithms for learning high-quality and asynchronous solutions.
Using U-Net Network for Efficient Brain Tumor Segmentation in MRI Images
Nov 03, 2022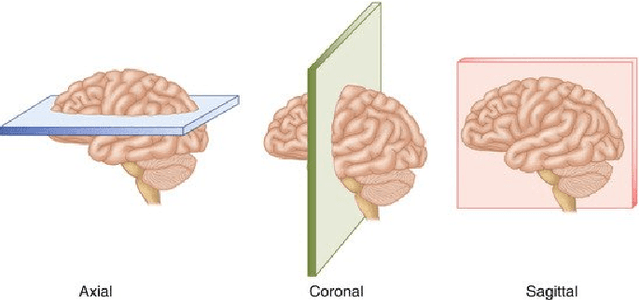
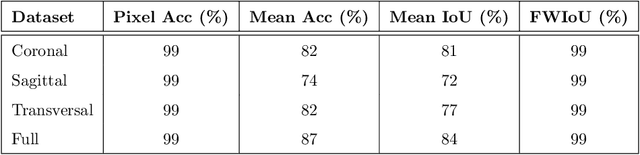
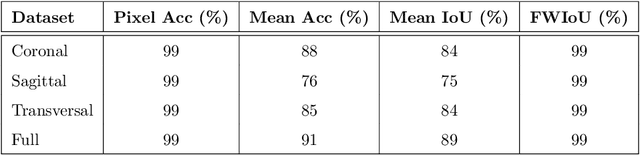
Magnetic Resonance Imaging (MRI) is the most commonly used non-intrusive technique for medical image acquisition. Brain tumor segmentation is the process of algorithmically identifying tumors in brain MRI scans. While many approaches have been proposed in the literature for brain tumor segmentation, this paper proposes a lightweight implementation of U-Net. Apart from providing real-time segmentation of MRI scans, the proposed architecture does not need large amount of data to train the proposed lightweight U-Net. Moreover, no additional data augmentation step is required. The lightweight U-Net shows very promising results on BITE dataset and it achieves a mean intersection-over-union (IoU) of 89% while outperforming the standard benchmark algorithms. Additionally, this work demonstrates an effective use of the three perspective planes, instead of the original three-dimensional volumetric images, for simplified brain tumor segmentation.
Estimating the Carbon Footprint of BLOOM, a 176B Parameter Language Model
Nov 03, 2022


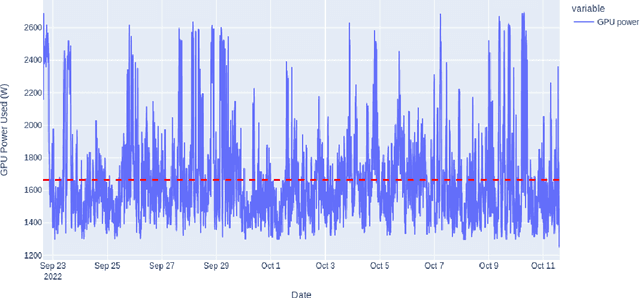
Progress in machine learning (ML) comes with a cost to the environment, given that training ML models requires significant computational resources, energy and materials. In the present article, we aim to quantify the carbon footprint of BLOOM, a 176-billion parameter language model, across its life cycle. We estimate that BLOOM's final training emitted approximately 24.7 tonnes of~\carboneq~if we consider only the dynamic power consumption, and 50.5 tonnes if we account for all processes ranging from equipment manufacturing to energy-based operational consumption. We also study the energy requirements and carbon emissions of its deployment for inference via an API endpoint receiving user queries in real-time. We conclude with a discussion regarding the difficulty of precisely estimating the carbon footprint of ML models and future research directions that can contribute towards improving carbon emissions reporting.
Benchmarking local motion planners for navigation of mobile manipulators
Nov 03, 2022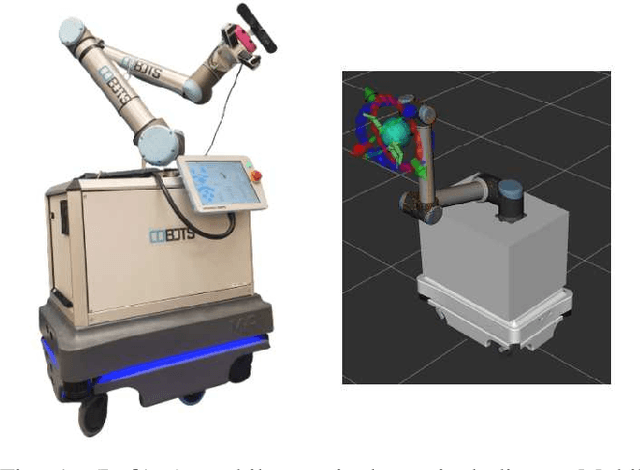

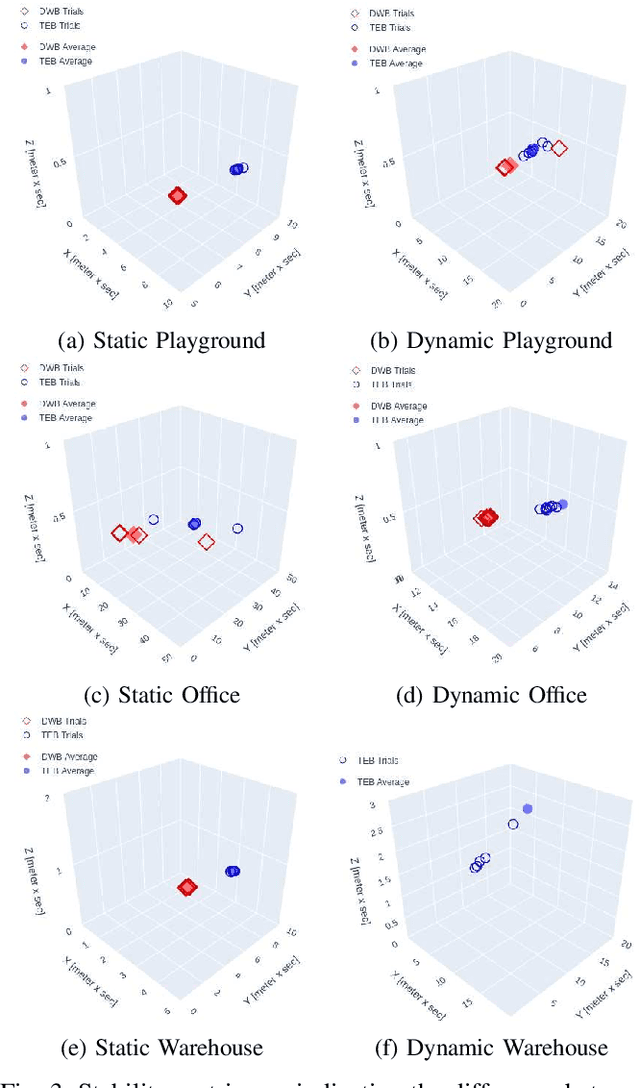
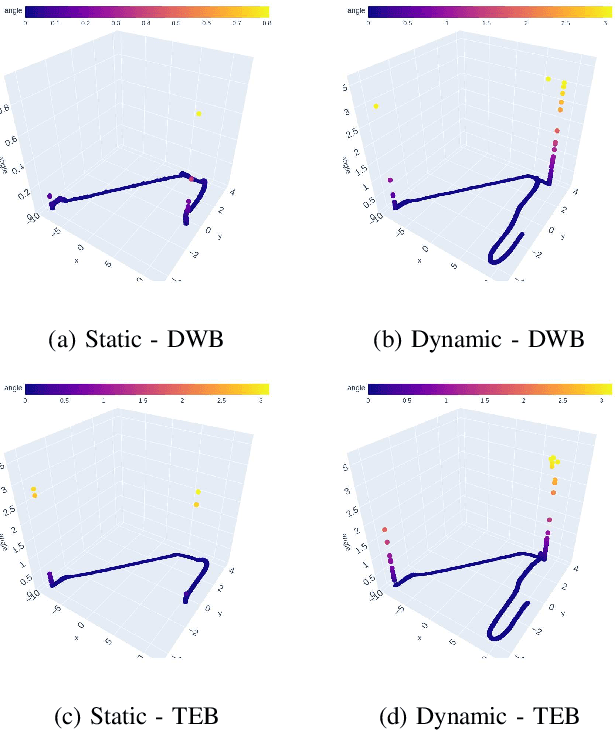
There are various trajectory planners for mobile manipulators. It is often challenging to compare their performance under similar circumstances due to differences in hardware, dissimilarity of tasks and objectives, as well as uncertainties in measurements and operating environments. In this paper, we propose a simulation framework to evaluate the performance of the local trajectory planners to generate smooth, and dynamically and kinematically feasible trajectories for mobile manipulators in the same environment. We focus on local planners as they are key components that provide smooth trajectories while carrying a load, react to dynamic obstacles, and avoid collisions. We evaluate two prominent local trajectory planners, Dynamic-Window Approach (DWA) and Time Elastic Band (TEB) using the metrics that we introduce. Moreover, our software solution is applicable to any other local planners used in the Robot Operating System (ROS) framework, without additional programming effort.
When to Laugh and How Hard? A Multimodal Approach to Detecting Humor and its Intensity
Nov 03, 2022


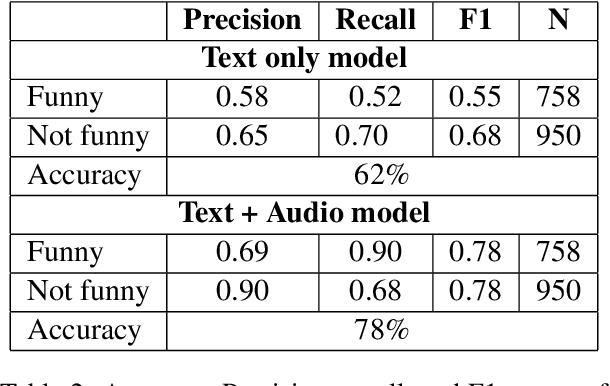
Prerecorded laughter accompanying dialog in comedy TV shows encourages the audience to laugh by clearly marking humorous moments in the show. We present an approach for automatically detecting humor in the Friends TV show using multimodal data. Our model is capable of recognizing whether an utterance is humorous or not and assess the intensity of it. We use the prerecorded laughter in the show as annotation as it marks humor and the length of the audience's laughter tells us how funny a given joke is. We evaluate the model on episodes the model has not been exposed to during the training phase. Our results show that the model is capable of correctly detecting whether an utterance is humorous 78% of the time and how long the audience's laughter reaction should last with a mean absolute error of 600 milliseconds.
Deep Equilibrium Approaches to Diffusion Models
Oct 23, 2022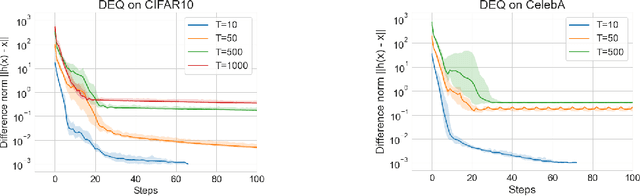
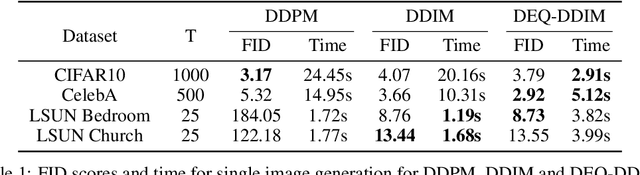

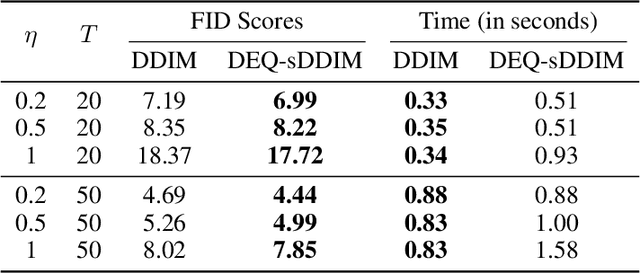
Diffusion-based generative models are extremely effective in generating high-quality images, with generated samples often surpassing the quality of those produced by other models under several metrics. One distinguishing feature of these models, however, is that they typically require long sampling chains to produce high-fidelity images. This presents a challenge not only from the lenses of sampling time, but also from the inherent difficulty in backpropagating through these chains in order to accomplish tasks such as model inversion, i.e. approximately finding latent states that generate known images. In this paper, we look at diffusion models through a different perspective, that of a (deep) equilibrium (DEQ) fixed point model. Specifically, we extend the recent denoising diffusion implicit model (DDIM; Song et al. 2020), and model the entire sampling chain as a joint, multivariate fixed point system. This setup provides an elegant unification of diffusion and equilibrium models, and shows benefits in 1) single image sampling, as it replaces the fully-serial typical sampling process with a parallel one; and 2) model inversion, where we can leverage fast gradients in the DEQ setting to much more quickly find the noise that generates a given image. The approach is also orthogonal and thus complementary to other methods used to reduce the sampling time, or improve model inversion. We demonstrate our method's strong performance across several datasets, including CIFAR10, CelebA, and LSUN Bedrooms and Churches.
You Need Multiple Exiting: Dynamic Early Exiting for Accelerating Unified Vision Language Model
Nov 21, 2022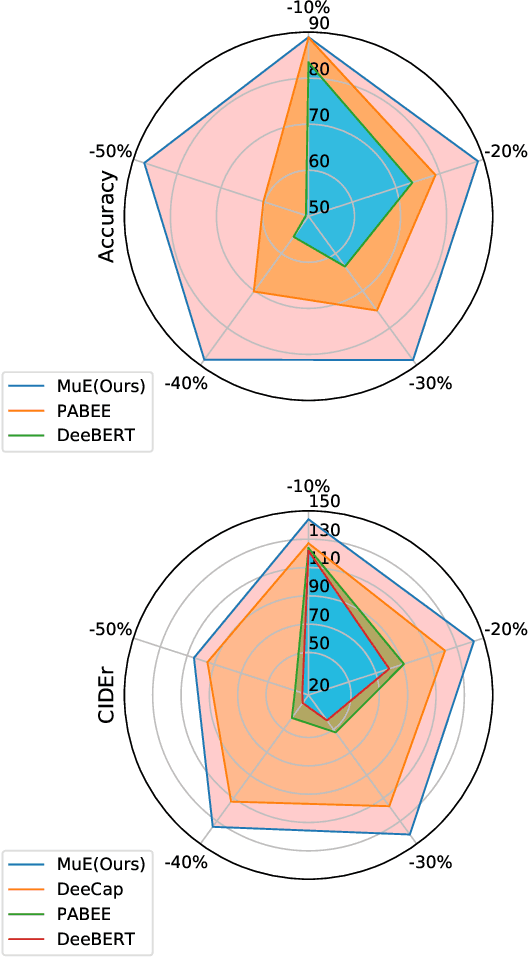
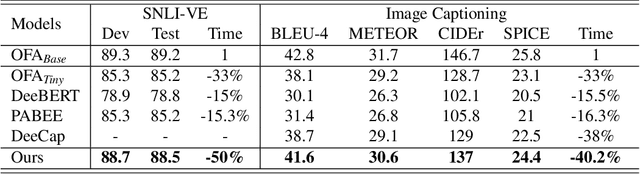
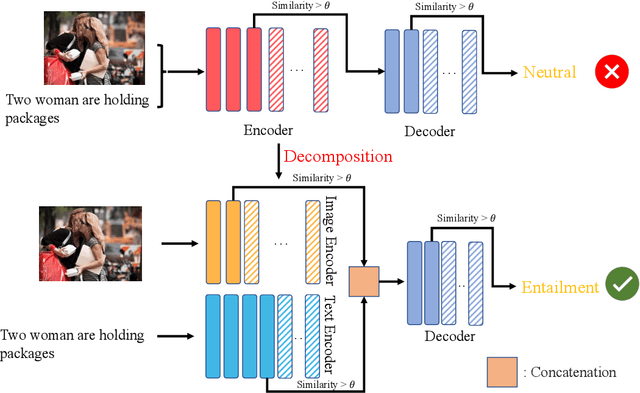
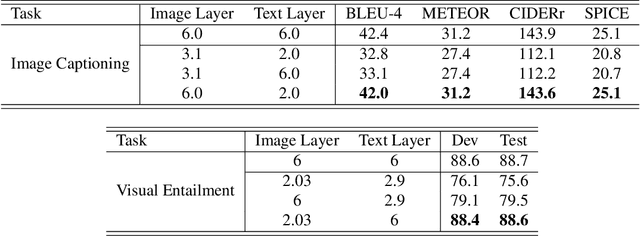
Large-scale Transformer models bring significant improvements for various downstream vision language tasks with a unified architecture. The performance improvements come with increasing model size, resulting in slow inference speed and increased cost for severing. While some certain predictions benefit from the full complexity of the large-scale model, not all of inputs need the same amount of computation to conduct, potentially leading to computation resource waste. To handle this challenge, early exiting is proposed to adaptively allocate computational power in term of input complexity to improve inference efficiency. The existing early exiting strategies usually adopt output confidence based on intermediate layers as a proxy of input complexity to incur the decision of skipping following layers. However, such strategies cannot apply to encoder in the widely-used unified architecture with both encoder and decoder due to difficulty of output confidence estimation in the encoder. It is suboptimal in term of saving computation power to ignore the early exiting in encoder component. To handle this challenge, we propose a novel early exiting strategy for unified visual language models, which allows dynamically skip the layers in encoder and decoder simultaneously in term of input layer-wise similarities with multiple times of early exiting, namely \textbf{MuE}. By decomposing the image and text modalities in the encoder, MuE is flexible and can skip different layers in term of modalities, advancing the inference efficiency while minimizing performance drop. Experiments on the SNLI-VE and MS COCO datasets show that the proposed approach MuE can reduce expected inference time by up to 50\% and 40\% while maintaining 99\% and 96\% performance respectively.
Travel time optimization on multi-AGV routing by reverse annealing
Apr 25, 2022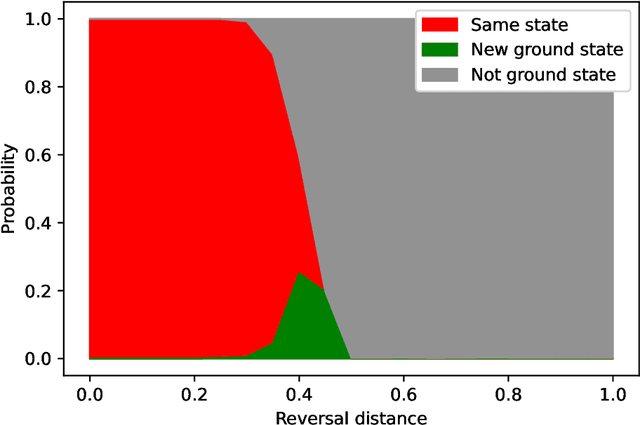

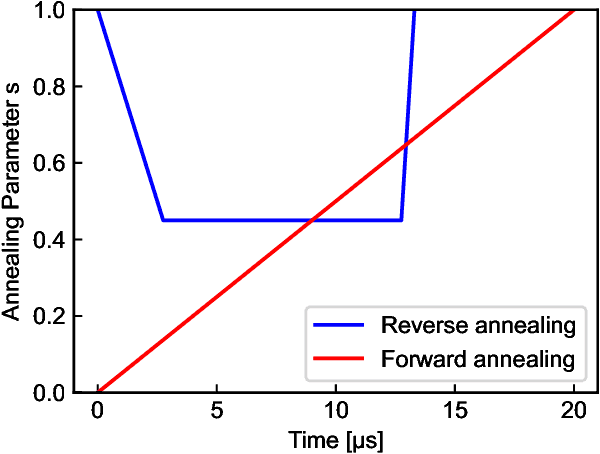
Quantum annealing has been actively researched since D-Wave Systems produced the first commercial machine in 2011. Controlling a large fleet of automated guided vehicles is one of the real-world applications utilizing quantum annealing. In this study, we propose a formulation to control the traveling routes to minimize the travel time. We validate our formulation through simulation in a virtual plant and authenticate the effectiveness for faster distribution compared to a greedy algorithm that does not consider the overall detour distance. Furthermore, we utilize reverse annealing to maximize the advantage of the D-Wave's quantum annealer. Starting from relatively good solutions obtained by a fast greedy algorithm, reverse annealing searches for better solutions around them. Our reverse annealing method improves the performance compared to standard quantum annealing alone and performs up to 10 times faster than the strong classical solver, Gurobi. This study extends a use of optimization with general problem solvers in the application of multi-AGV systems and reveals the potential of reverse annealing as an optimizer.