 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
TEP-GNN: Accurate Execution Time Prediction of Functional Tests using Graph Neural Networks
Aug 25, 2022

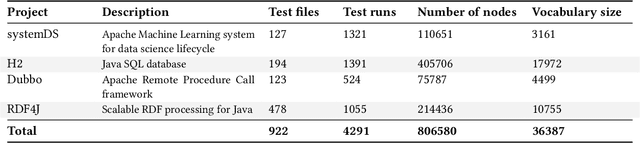
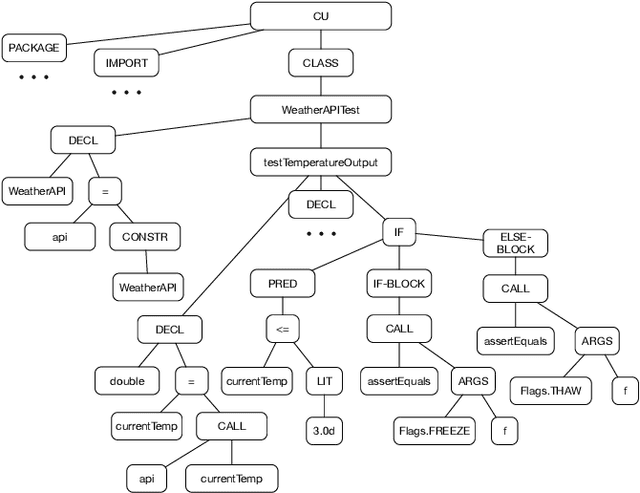
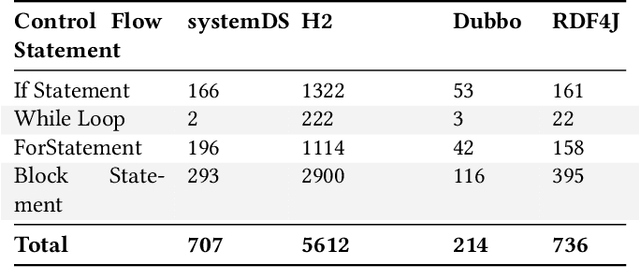
Predicting the performance of production code prior to actually executing or benchmarking it is known to be highly challenging. In this paper, we propose a predictive model, dubbed TEP-GNN, which demonstrates that high-accuracy performance prediction is possible for the special case of predicting unit test execution times. TEP-GNN uses FA-ASTs, or flow-augmented ASTs, as a graph-based code representation approach, and predicts test execution times using a powerful graph neural network (GNN) deep learning model. We evaluate TEP-GNN using four real-life Java open source programs, based on 922 test files mined from the projects' public repositories. We find that our approach achieves a high Pearson correlation of 0.789, considerable outperforming a baseline deep learning model. However, we also find that more work is needed for trained models to generalize to unseen projects. Our work demonstrates that FA-ASTs and GNNs are a feasible approach for predicting absolute performance values, and serves as an important intermediary step towards being able to predict the performance of arbitrary code prior to execution.
Category-Adaptive Label Discovery and Noise Rejection for Multi-label Image Recognition with Partial Positive Labels
Nov 15, 2022
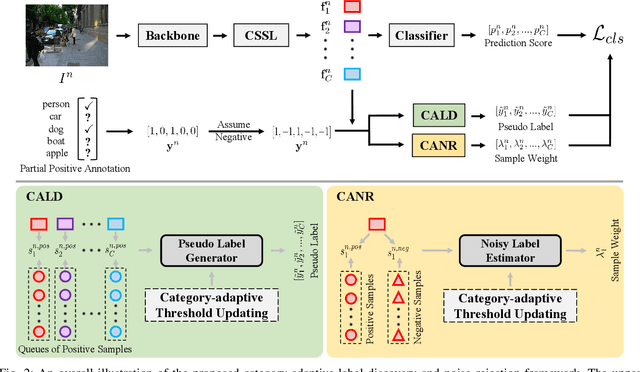
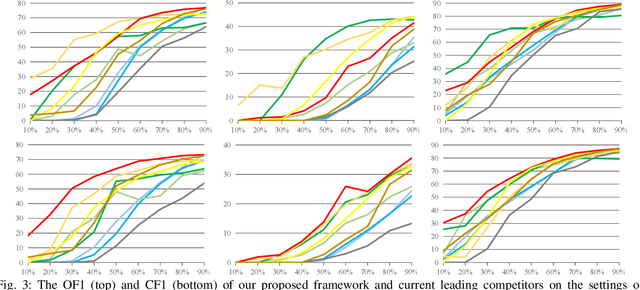
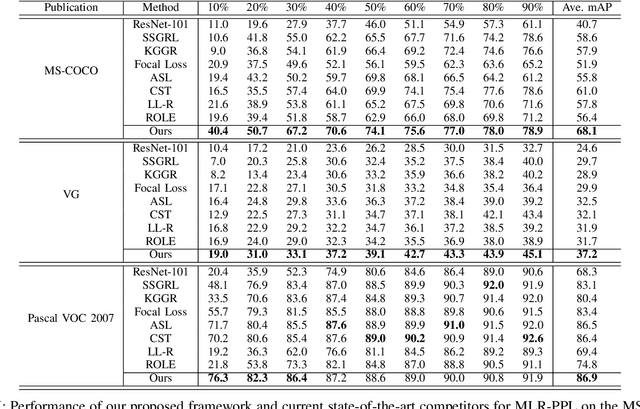
As a promising solution of reducing annotation cost, training multi-label models with partial positive labels (MLR-PPL), in which merely few positive labels are known while other are missing, attracts increasing attention. Due to the absence of any negative labels, previous works regard unknown labels as negative and adopt traditional MLR algorithms. To reject noisy labels, recent works regard large loss samples as noise but ignore the semantic correlation different multi-label images. In this work, we propose to explore semantic correlation among different images to facilitate the MLR-PPL task. Specifically, we design a unified framework, Category-Adaptive Label Discovery and Noise Rejection, that discovers unknown labels and rejects noisy labels for each category in an adaptive manner. The framework consists of two complementary modules: (1) Category-Adaptive Label Discovery module first measures the semantic similarity between positive samples and then complement unknown labels with high similarities; (2) Category-Adaptive Noise Rejection module first computes the sample weights based on semantic similarities from different samples and then discards noisy labels with low weights. Besides, we propose a novel category-adaptive threshold updating that adaptively adjusts the threshold, to avoid the time-consuming manual tuning process. Extensive experiments demonstrate that our proposed method consistently outperforms current leading algorithms.
Deep scene-scale material estimation from multi-view indoor captures
Nov 15, 2022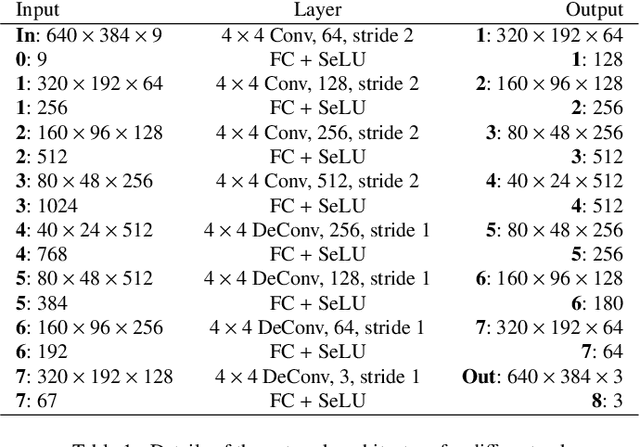

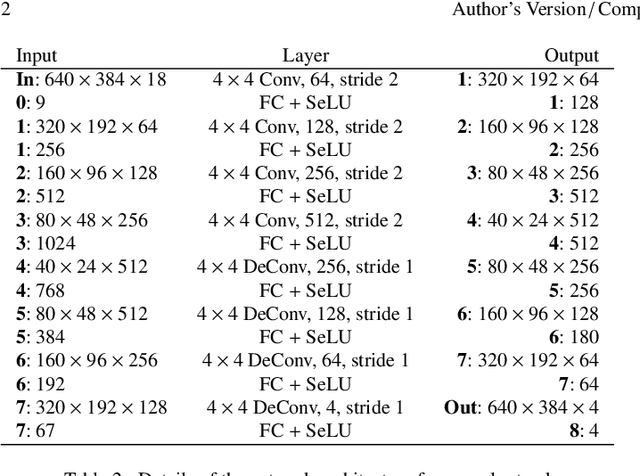
The movie and video game industries have adopted photogrammetry as a way to create digital 3D assets from multiple photographs of a real-world scene. But photogrammetry algorithms typically output an RGB texture atlas of the scene that only serves as visual guidance for skilled artists to create material maps suitable for physically-based rendering. We present a learning-based approach that automatically produces digital assets ready for physically-based rendering, by estimating approximate material maps from multi-view captures of indoor scenes that are used with retopologized geometry. We base our approach on a material estimation Convolutional Neural Network (CNN) that we execute on each input image. We leverage the view-dependent visual cues provided by the multiple observations of the scene by gathering, for each pixel of a given image, the color of the corresponding point in other images. This image-space CNN provides us with an ensemble of predictions, which we merge in texture space as the last step of our approach. Our results demonstrate that the recovered assets can be directly used for physically-based rendering and editing of real indoor scenes from any viewpoint and novel lighting. Our method generates approximate material maps in a fraction of time compared to the closest previous solutions.
* 17 pages
Improved techniques for deterministic l2 robustness
Nov 15, 2022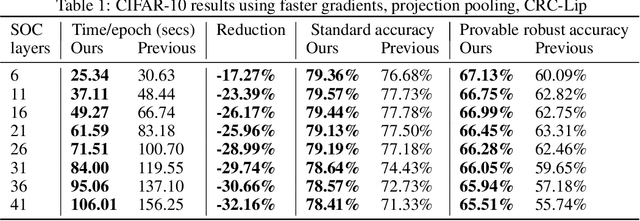


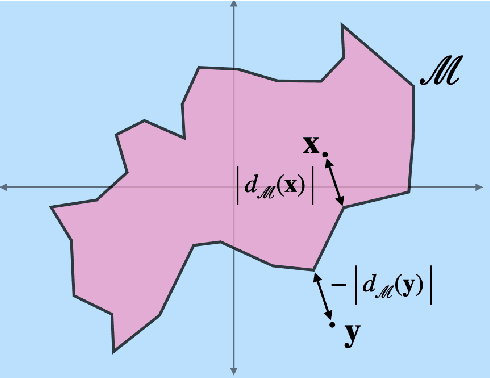
Training convolutional neural networks (CNNs) with a strict 1-Lipschitz constraint under the $l_{2}$ norm is useful for adversarial robustness, interpretable gradients and stable training. 1-Lipschitz CNNs are usually designed by enforcing each layer to have an orthogonal Jacobian matrix (for all inputs) to prevent the gradients from vanishing during backpropagation. However, their performance often significantly lags behind that of heuristic methods to enforce Lipschitz constraints where the resulting CNN is not \textit{provably} 1-Lipschitz. In this work, we reduce this gap by introducing (a) a procedure to certify robustness of 1-Lipschitz CNNs by replacing the last linear layer with a 1-hidden layer MLP that significantly improves their performance for both standard and provably robust accuracy, (b) a method to significantly reduce the training time per epoch for Skew Orthogonal Convolution (SOC) layers (>30\% reduction for deeper networks) and (c) a class of pooling layers using the mathematical property that the $l_{2}$ distance of an input to a manifold is 1-Lipschitz. Using these methods, we significantly advance the state-of-the-art for standard and provable robust accuracies on CIFAR-10 (gains of +1.79\% and +3.82\%) and similarly on CIFAR-100 (+3.78\% and +4.75\%) across all networks. Code is available at \url{https://github.com/singlasahil14/improved_l2_robustness}.
DeepRGVP: A Novel Microstructure-Informed Supervised Contrastive Learning Framework for Automated Identification Of The Retinogeniculate Pathway Using dMRI Tractography
Nov 15, 2022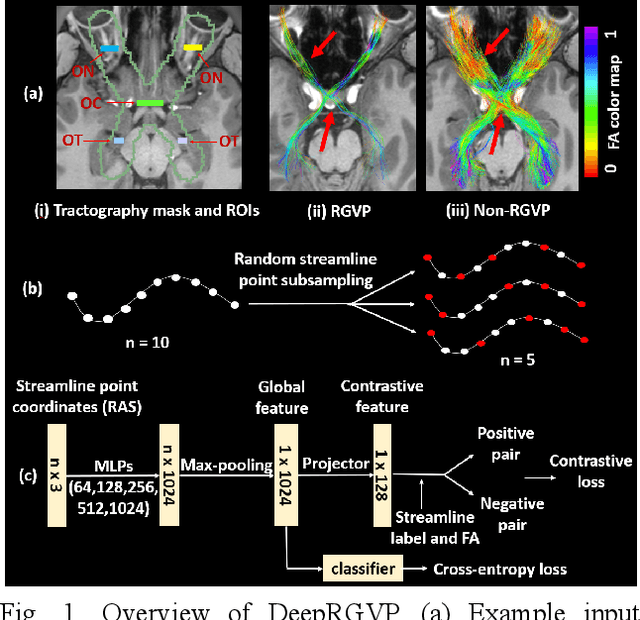

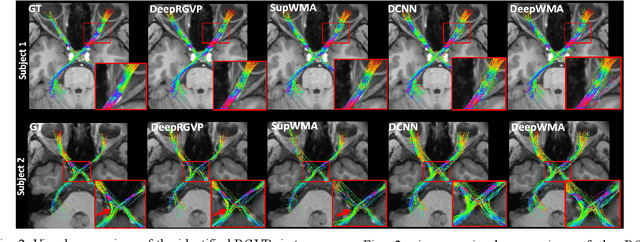
The retinogeniculate pathway (RGVP) is responsible for carrying visual information from the retina to the lateral geniculate nucleus. Identification and visualization of the RGVP are important in studying the anatomy of the visual system and can inform treatment of related brain diseases. Diffusion MRI (dMRI) tractography is an advanced imaging method that uniquely enables in vivo mapping of the 3D trajectory of the RGVP. Currently, identification of the RGVP from tractography data relies on expert (manual) selection of tractography streamlines, which is time-consuming, has high clinical and expert labor costs, and affected by inter-observer variability. In this paper, we present what we believe is the first deep learning framework, namely DeepRGVP, to enable fast and accurate identification of the RGVP from dMRI tractography data. We design a novel microstructure-informed supervised contrastive learning method that leverages both streamline label and tissue microstructure information to determine positive and negative pairs. We propose a simple and successful streamline-level data augmentation method to address highly imbalanced training data, where the number of RGVP streamlines is much lower than that of non-RGVP streamlines. We perform comparisons with several state-of-the-art deep learning methods that were designed for tractography parcellation, and we show superior RGVP identification results using DeepRGVP.
Motor imagery classification using EEG spectrograms
Nov 15, 2022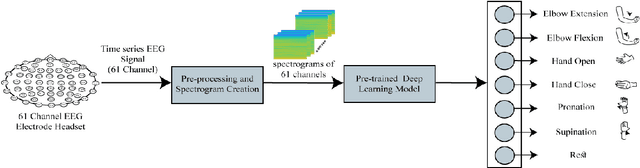
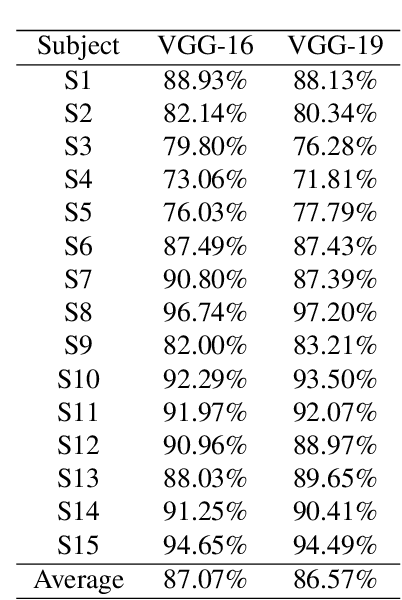
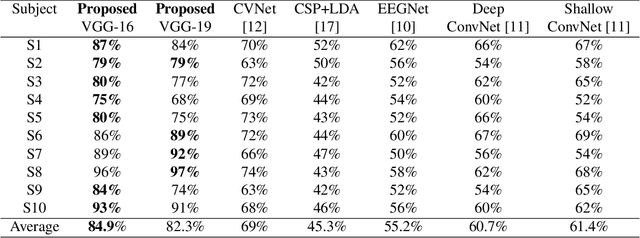
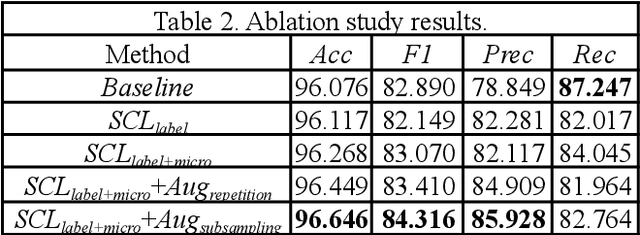
The loss of limb motion arising from damage to the spinal cord is a disability that could effect people while performing their day-to-day activities. The restoration of limb movement would enable people with spinal cord injury to interact with their environment more naturally and this is where a brain-computer interface (BCI) system could be beneficial. The detection of limb movement imagination (MI) could be significant for such a BCI, where the detected MI can guide the computer system. Using MI detection through electroencephalography (EEG), we can recognize the imagination of movement in a user and translate this into a physical movement. In this paper, we utilize pre-trained deep learning (DL) algorithms for the classification of imagined upper limb movements. We use a publicly available EEG dataset with data representing seven classes of limb movements. We compute the spectrograms of the time series EEG signal and use them as an input to the DL model for MI classification. Our novel approach for the classification of upper limb movements using pre-trained DL algorithms and spectrograms has achieved significantly improved results for seven movement classes. When compared with the recently proposed state-of-the-art methods, our algorithm achieved a significant average accuracy of 84.9% for classifying seven movements.
Predicting Eye Gaze Location on Websites
Nov 15, 2022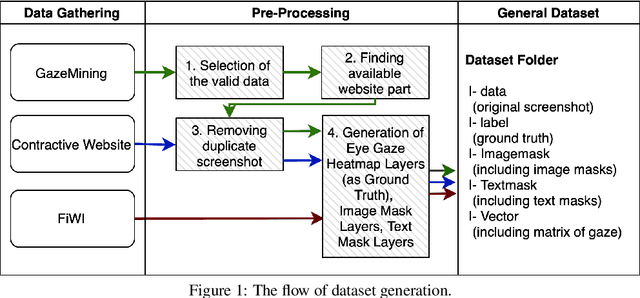
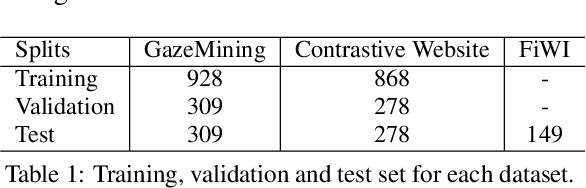
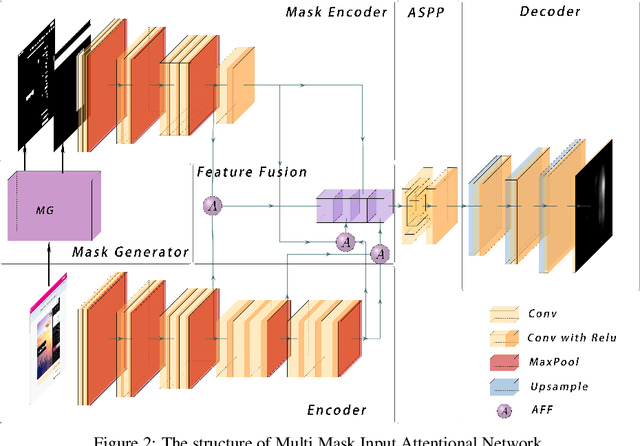
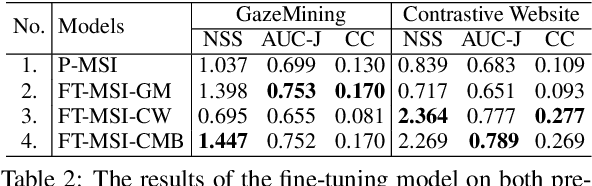
World-wide-web, with the website and webpage as the main interface, facilitates the dissemination of important information. Hence it is crucial to optimize them for better user interaction, which is primarily done by analyzing users' behavior, especially users' eye-gaze locations. However, gathering these data is still considered to be labor and time intensive. In this work, we enable the development of automatic eye-gaze estimations given a website screenshots as the input. This is done by the curation of a unified dataset that consists of website screenshots, eye-gaze heatmap and website's layout information in the form of image and text masks. Our pre-processed dataset allows us to propose an effective deep learning-based model that leverages both image and text spatial location, which is combined through attention mechanism for effective eye-gaze prediction. In our experiment, we show the benefit of careful fine-tuning using our unified dataset to improve the accuracy of eye-gaze predictions. We further observe the capability of our model to focus on the targeted areas (images and text) to achieve high accuracy. Finally, the comparison with other alternatives shows the state-of-the-art result of our model establishing the benchmark for the eye-gaze prediction task.
Breakpoint Transformers for Modeling and Tracking Intermediate Beliefs
Nov 15, 2022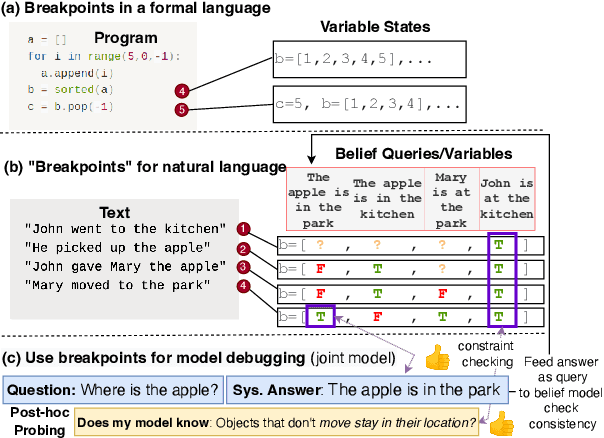

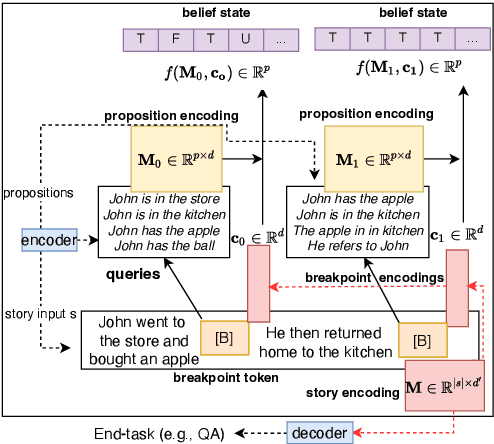
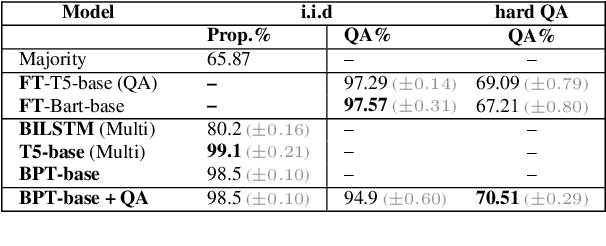
Can we teach natural language understanding models to track their beliefs through intermediate points in text? We propose a representation learning framework called breakpoint modeling that allows for learning of this type. Given any text encoder and data marked with intermediate states (breakpoints) along with corresponding textual queries viewed as true/false propositions (i.e., the candidate beliefs of a model, consisting of information changing through time) our approach trains models in an efficient and end-to-end fashion to build intermediate representations that facilitate teaching and direct querying of beliefs at arbitrary points alongside solving other end tasks. To show the benefit of our approach, we experiment with a diverse set of NLU tasks including relational reasoning on CLUTRR and narrative understanding on bAbI. Using novel belief prediction tasks for both tasks, we show the benefit of our main breakpoint transformer, based on T5, over conventional representation learning approaches in terms of processing efficiency, prediction accuracy and prediction consistency, all with minimal to no effect on corresponding QA end tasks. To show the feasibility of incorporating our belief tracker into more complex reasoning pipelines, we also obtain SOTA performance on the three-tiered reasoning challenge for the TRIP benchmark (around 23-32% absolute improvement on Tasks 2-3).
AgileAvatar: Stylized 3D Avatar Creation via Cascaded Domain Bridging
Nov 15, 2022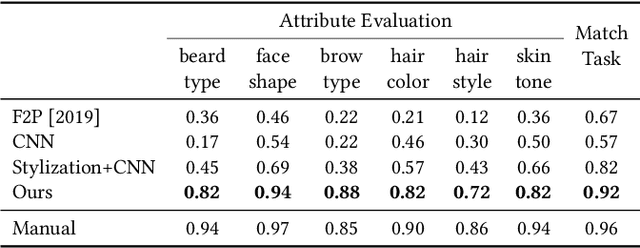
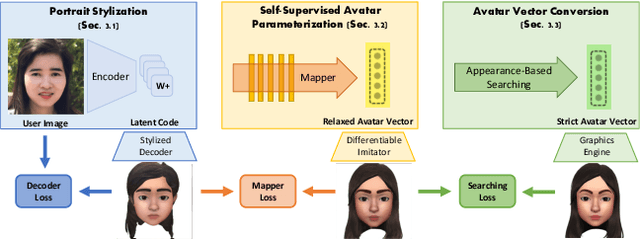


Stylized 3D avatars have become increasingly prominent in our modern life. Creating these avatars manually usually involves laborious selection and adjustment of continuous and discrete parameters and is time-consuming for average users. Self-supervised approaches to automatically create 3D avatars from user selfies promise high quality with little annotation cost but fall short in application to stylized avatars due to a large style domain gap. We propose a novel self-supervised learning framework to create high-quality stylized 3D avatars with a mix of continuous and discrete parameters. Our cascaded domain bridging framework first leverages a modified portrait stylization approach to translate input selfies into stylized avatar renderings as the targets for desired 3D avatars. Next, we find the best parameters of the avatars to match the stylized avatar renderings through a differentiable imitator we train to mimic the avatar graphics engine. To ensure we can effectively optimize the discrete parameters, we adopt a cascaded relaxation-and-search pipeline. We use a human preference study to evaluate how well our method preserves user identity compared to previous work as well as manual creation. Our results achieve much higher preference scores than previous work and close to those of manual creation. We also provide an ablation study to justify the design choices in our pipeline.
Latent Prompt Tuning for Text Summarization
Nov 03, 2022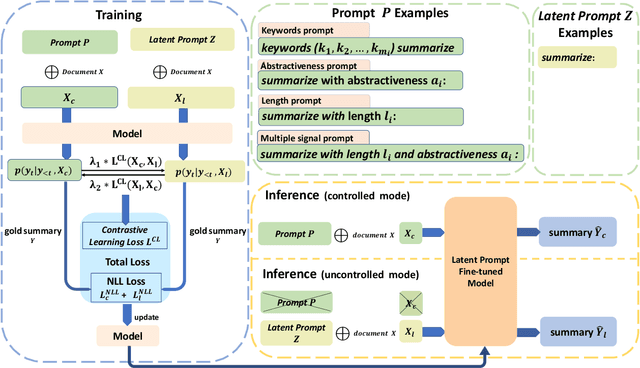
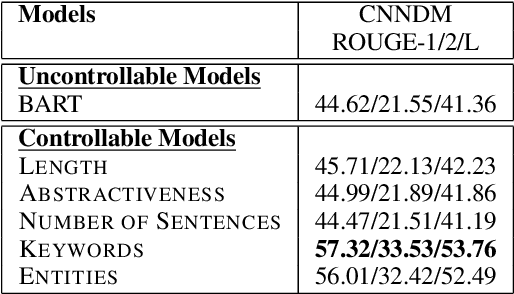
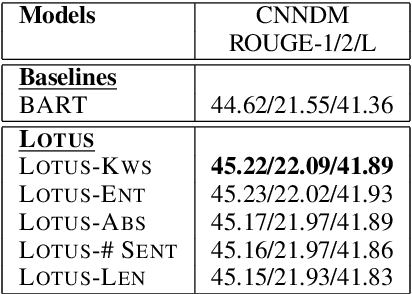
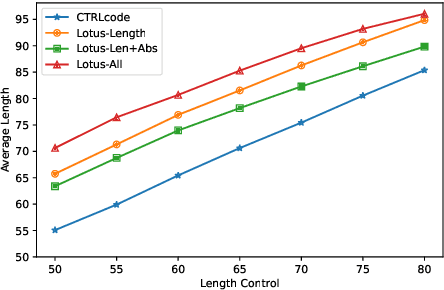
Prompts with different control signals (e.g., length, keywords, etc.) can be used to control text summarization. When control signals are available, they can control the properties of generated summaries and potentially improve summarization quality (since more information are given). Unfortunately, control signals are not already available during inference time. In this paper, we propose Lotus (shorthand for Latent Prompt Tuning for Summarization), which is a single model that can be applied in both controlled and uncontrolled (without control signals) modes. During training, Lotus learns latent prompt representations from prompts with gold control signals using a contrastive learning objective. Experiments show Lotus in uncontrolled mode consistently improves upon strong (uncontrollable) summarization models across four different summarization datasets. We also demonstrate generated summaries can be controlled using prompts with user specified control tokens.