 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Benchmarking variational quantum circuits with permutation symmetry
Nov 23, 2022
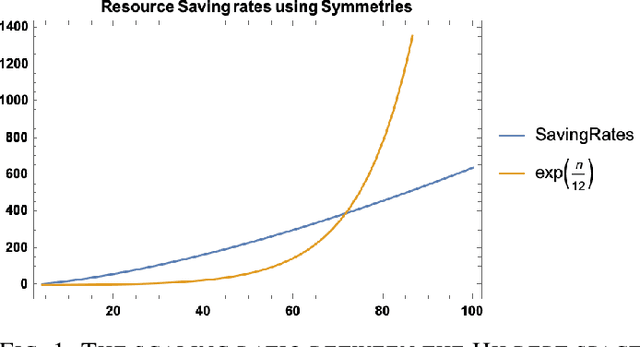
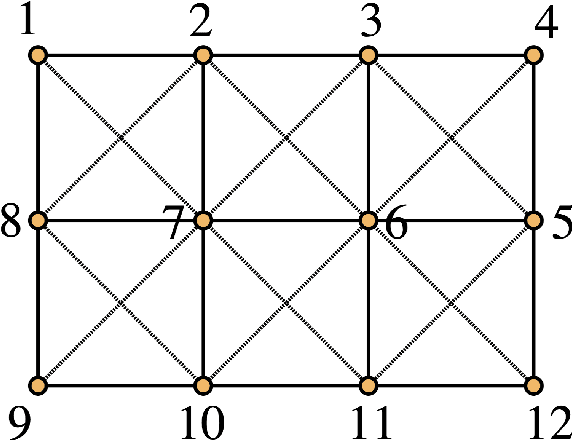
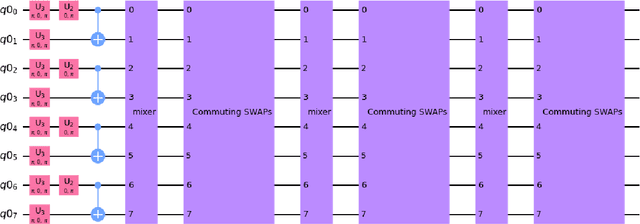
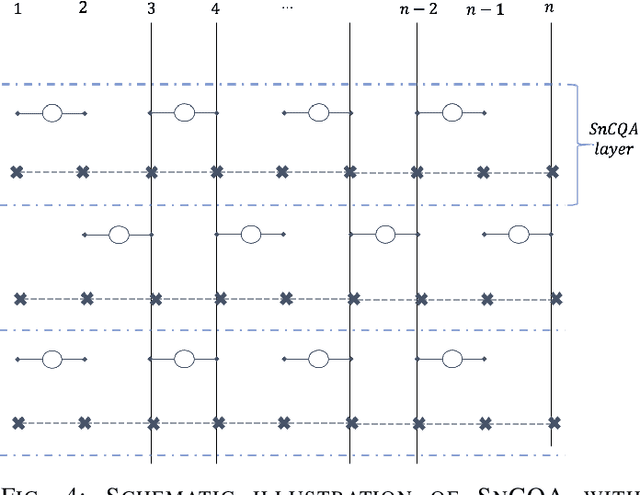
We propose SnCQA, a set of hardware-efficient variational circuits of equivariant quantum convolutional circuits respective to permutation symmetries and spatial lattice symmetries with the number of qubits $n$. By exploiting permutation symmetries of the system, such as lattice Hamiltonians common to many quantum many-body and quantum chemistry problems, Our quantum neural networks are suitable for solving machine learning problems where permutation symmetries are present, which could lead to significant savings of computational costs. Aside from its theoretical novelty, we find our simulations perform well in practical instances of learning ground states in quantum computational chemistry, where we could achieve comparable performances to traditional methods with few tens of parameters. Compared to other traditional variational quantum circuits, such as the pure hardware-efficient ansatz (pHEA), we show that SnCQA is more scalable, accurate, and noise resilient (with $20\times$ better performance on $3 \times 4$ square lattice and $200\% - 1000\%$ resource savings in various lattice sizes and key criterions such as the number of layers, parameters, and times to converge in our cases), suggesting a potentially favorable experiment on near-time quantum devices.
Reliable Robustness Evaluation via Automatically Constructed Attack Ensembles
Nov 23, 2022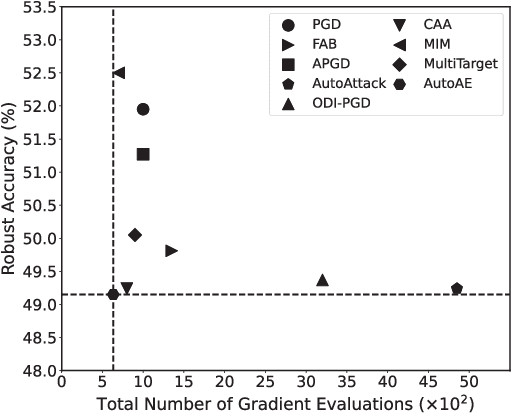
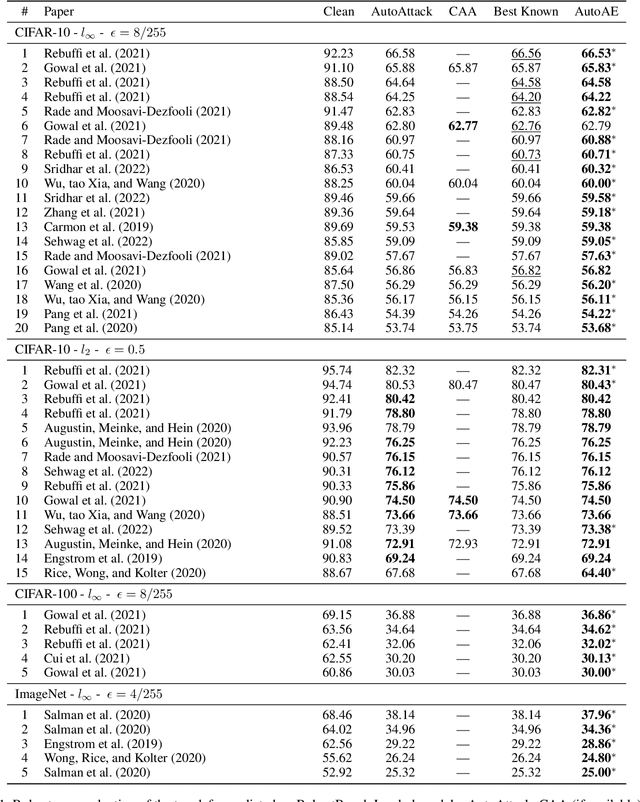
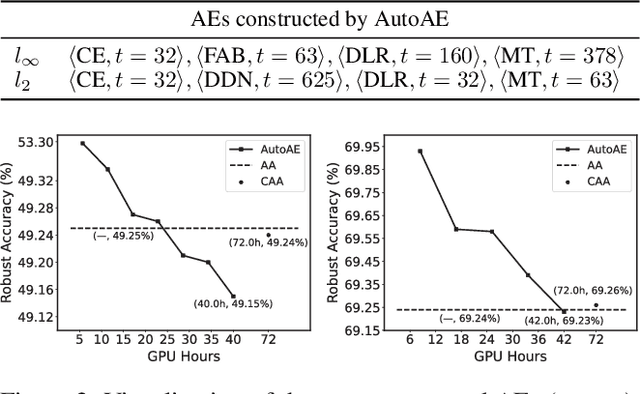
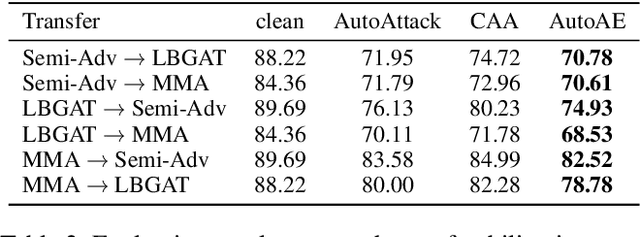
Attack Ensemble (AE), which combines multiple attacks together, provides a reliable way to evaluate adversarial robustness. In practice, AEs are often constructed and tuned by human experts, which however tends to be sub-optimal and time-consuming. In this work, we present AutoAE, a conceptually simple approach for automatically constructing AEs. In brief, AutoAE repeatedly adds the attack and its iteration steps to the ensemble that maximizes ensemble improvement per additional iteration consumed. We show theoretically that AutoAE yields AEs provably within a constant factor of the optimal for a given defense. We then use AutoAE to construct two AEs for $l_{\infty}$ and $l_2$ attacks, and apply them without any tuning or adaptation to 45 top adversarial defenses on the RobustBench leaderboard. In all except one cases we achieve equal or better (often the latter) robustness evaluation than existing AEs, and notably, in 29 cases we achieve better robustness evaluation than the best known one. Such performance of AutoAE shows itself as a reliable evaluation protocol for adversarial robustness, which further indicates the huge potential of automatic AE construction. Code is available at \url{https://github.com/LeegerPENG/AutoAE}.
Stackelberg Meta-Learning for Strategic Guidance in Multi-Robot Trajectory Planning
Nov 23, 2022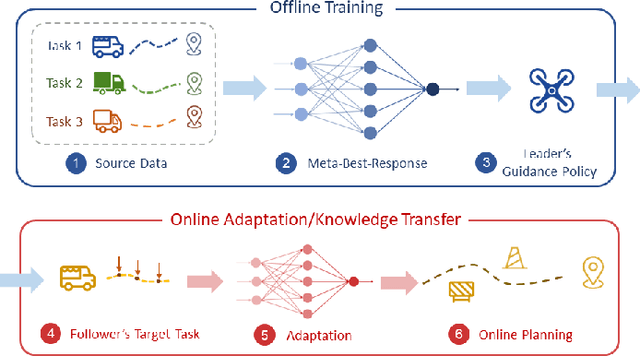

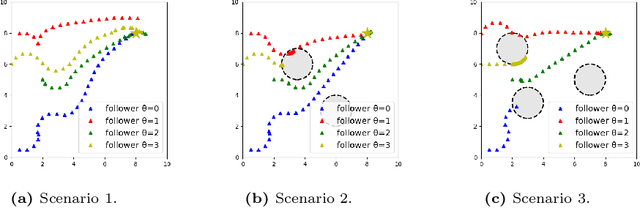
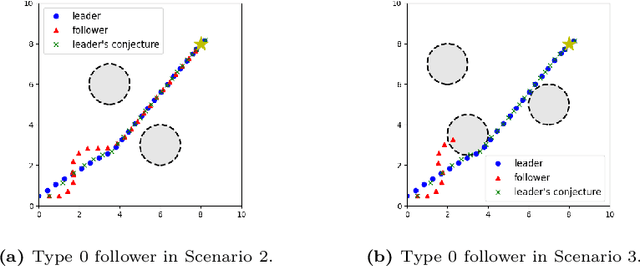
Guided cooperation is a common task in many multi-agent teaming applications. The planning of the cooperation is difficult when the leader robot has incomplete information about the follower, and there is a need to learn, customize, and adapt the cooperation plan online. To this end, we develop a learning-based Stackelberg game-theoretic framework to address this challenge to achieve optimal trajectory planning for heterogeneous robots. We first formulate the guided trajectory planning problem as a dynamic Stackelberg game and design the cooperation plans using open-loop Stackelberg equilibria. We leverage meta-learning to deal with the unknown follower in the game and propose a Stackelberg meta-learning framework to create online adaptive trajectory guidance plans, where the leader robot learns a meta-best-response model from a prescribed set of followers offline and then fast adapts to a specific online trajectory guidance task using limited learning data. We use simulations in three different scenarios to elaborate on the effectiveness of our framework. Comparison with other learning approaches and no guidance cases show that our framework provides a more time- and data-efficient planning method in trajectory guidance tasks.
Indian Commercial Truck License Plate Detection and Recognition for Weighbridge Automation
Nov 23, 2022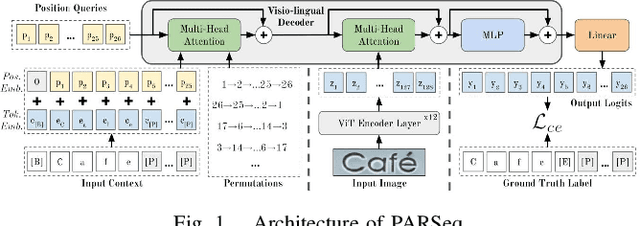



Detection and recognition of a licence plate is important when automating weighbridge services. While many large databases are available for Latin and Chinese alphanumeric license plates, data for Indian License Plates is inadequate. In particular, databases of Indian commercial truck license plates are inadequate, despite the fact that commercial vehicle license plate recognition plays a profound role in terms of logistics management and weighbridge automation. Moreover, models to recognise license plates are not effectively able to generalise to such data due to its challenging nature, and due to the abundant frequency of handwritten license plates, leading to the usage of diverse font styles. Thus, a database and effective models to recognise and detect such license plates are crucial. This paper provides a database on commercial truck license plates, and using state-of-the-art models in real-time object Detection: You Only Look Once Version 7, and SceneText Recognition: Permuted Autoregressive Sequence Models, our method outperforms the other cited references where the maximum accuracy obtained was less than 90%, while we have achieved 95.82% accuracy in our algorithm implementation on the presented challenging license plate dataset. Index Terms- Automatic License Plate Recognition, character recognition, license plate detection, vision transformer.
Real-time HOG+SVM based object detection using SoC FPGA for a UHD video stream
Apr 22, 2022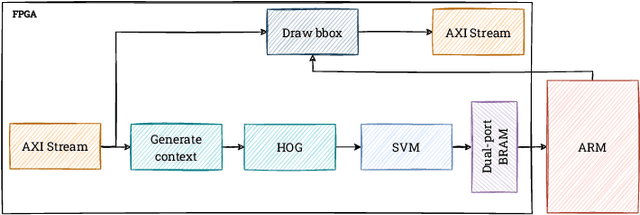
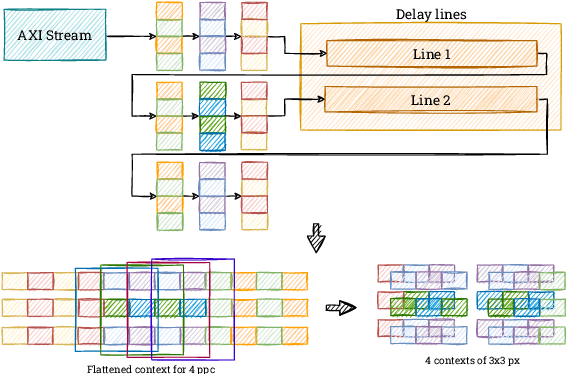
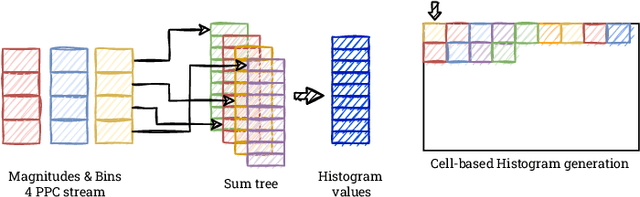
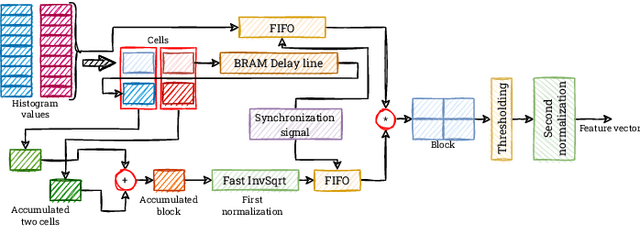
Object detection is an essential component of many vision systems. For example, pedestrian detection is used in advanced driver assistance systems (ADAS) and advanced video surveillance systems (AVSS). Currently, most detectors use deep convolutional neural networks (e.g., the YOLO -- You Only Look Once -- family), which, however, due to their high computational complexity, are not able to process a very high-resolution video stream in real-time, especially within a limited energy budget. In this paper we present a hardware implementation of the well-known pedestrian detector with HOG (Histogram of Oriented Gradients) feature extraction and SVM (Support Vector Machine) classification. Our system running on AMD Xilinx Zynq UltraScale+ MPSoC (Multiprocessor System on Chip) device allows real-time processing of 4K resolution (UHD -- Ultra High Definition, 3840 x 2160 pixels) video for 60 frames per second. The system is capable of detecting a pedestrian in a single scale. The results obtained confirm the high suitability of reprogrammable devices in the real-time implementation of embedded vision systems.
Multiagent Rollout with Reshuffling for Warehouse Robots Path Planning
Nov 15, 2022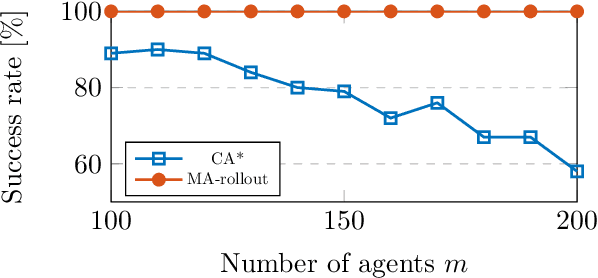
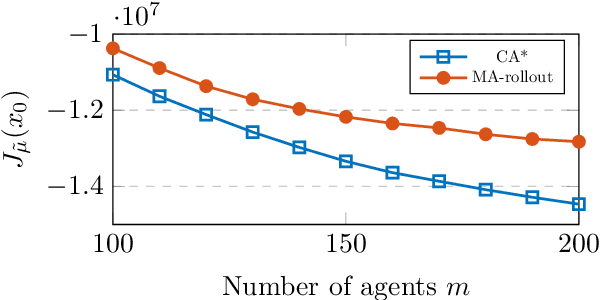
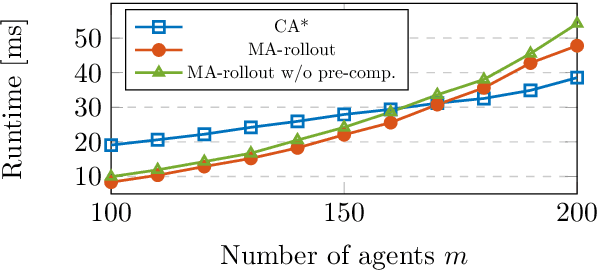
Efficiently solving path planning problems for a large number of robots is critical to the successful operation of modern warehouses. The existing approaches adopt classical shortest path algorithms to plan in environments whose cells are associated with both space and time in order to avoid collision between robots. In this work, we achieve the same goal by means of simulation in a smaller static environment. Built upon the new framework introduced in (Bertsekas, 2021a), we propose multiagent rollout with reshuffling algorithm, and apply it to address the warehouse robots path planning problem. The proposed scheme has a solid theoretical guarantee and exhibits consistent performance in our numerical studies. Moreover, it inherits from the generic rollout methods the ability to adapt to a changing environment by online replanning, which we demonstrate through examples where some robots malfunction.
Evaluating the Faithfulness of Saliency-based Explanations for Deep Learning Models for Temporal Colour Constancy
Nov 15, 2022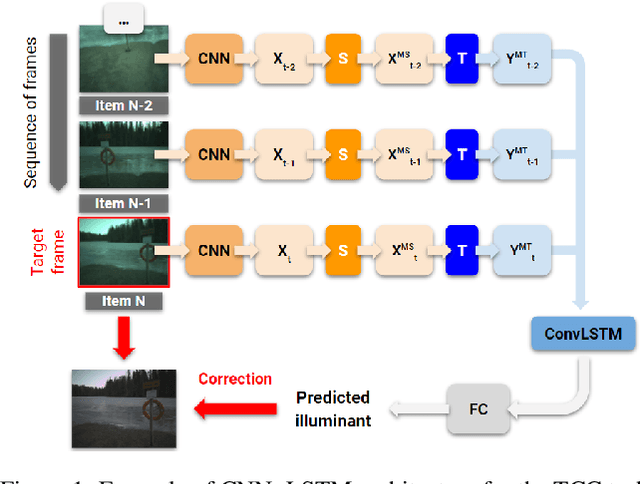


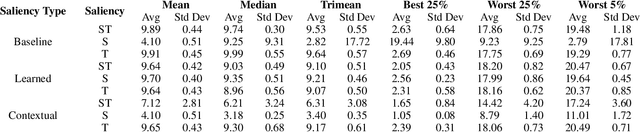
The opacity of deep learning models constrains their debugging and improvement. Augmenting deep models with saliency-based strategies, such as attention, has been claimed to help get a better understanding of the decision-making process of black-box models. However, some recent works challenged saliency's faithfulness in the field of Natural Language Processing (NLP), questioning attention weights' adherence to the true decision-making process of the model. We add to this discussion by evaluating the faithfulness of in-model saliency applied to a video processing task for the first time, namely, temporal colour constancy. We perform the evaluation by adapting to our target task two tests for faithfulness from recent NLP literature, whose methodology we refine as part of our contributions. We show that attention fails to achieve faithfulness, while confidence, a particular type of in-model visual saliency, succeeds.
FoReCo: a forecast-based recovery mechanism for real-time remote control of robotic manipulators
May 09, 2022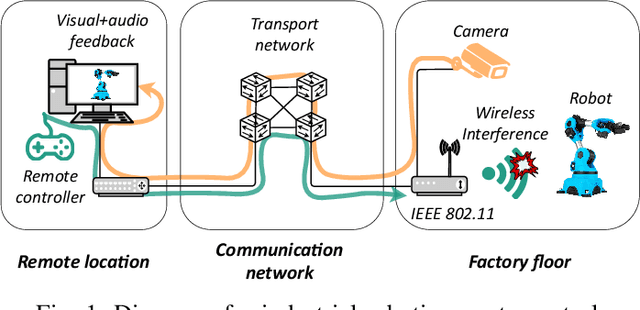
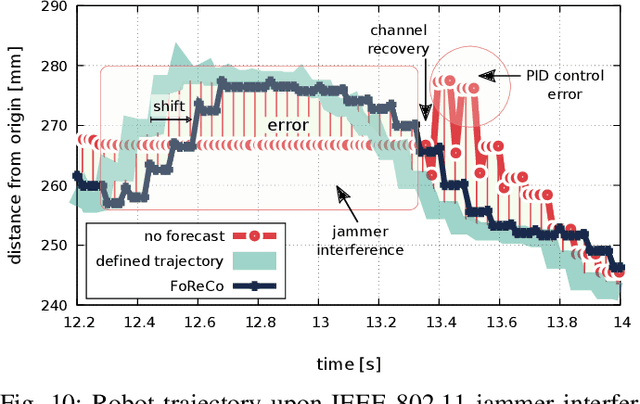
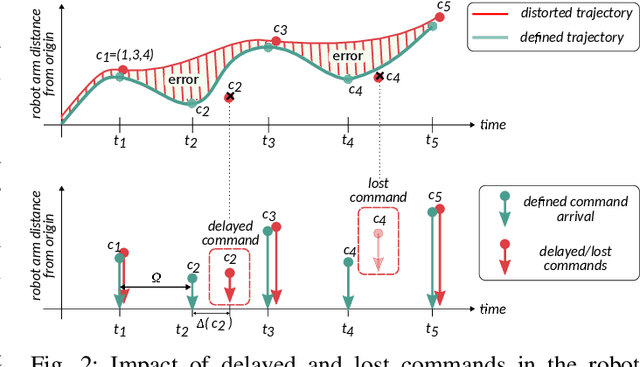
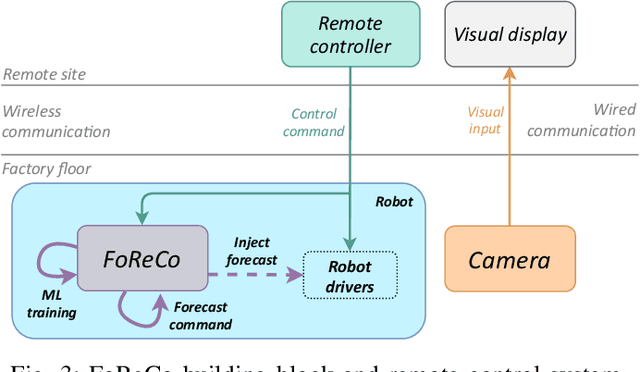
Wireless communications represent a game changer for future manufacturing plants, enabling flexible production chains as machinery and other components are not restricted to a location by the rigid wired connections on the factory floor. However, the presence of electromagnetic interference in the wireless spectrum may result in packet loss and delay, making it a challenging environment to meet the extreme reliability requirements of industrial applications. In such conditions, achieving real-time remote control, either from the Edge or Cloud, becomes complex. In this paper, we investigate a forecast-based recovery mechanism for real-time remote control of robotic manipulators (FoReCo) that uses Machine Learning (ML) to infer lost commands caused by interference in the wireless channel. FoReCo is evaluated through both simulation and experimentation in interference prone IEEE 802.11 wireless links, and using a commercial research robot that performs pick-and-place tasks. Results show that in case of interference, FoReCo trajectory error is decreased by x18 and x2 times in simulation and experimentation, and that FoReCo is sufficiently lightweight to be deployed in the hardware of already used in existing solutions.
Unsupervised Visual Defect Detection with Score-Based Generative Model
Nov 29, 2022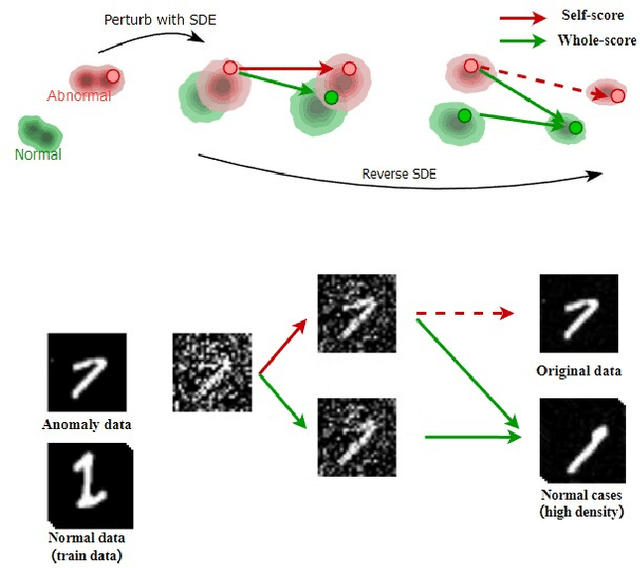
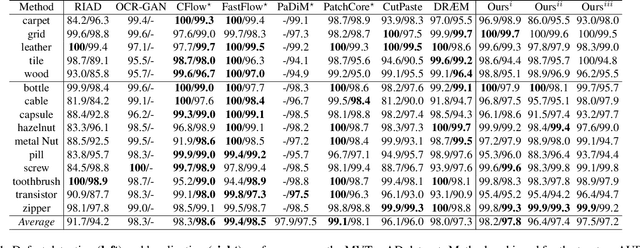

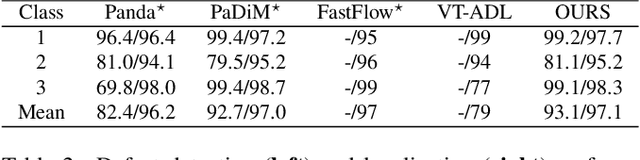
Anomaly Detection (AD), as a critical problem, has been widely discussed. In this paper, we specialize in one specific problem, Visual Defect Detection (VDD), in many industrial applications. And in practice, defect image samples are very rare and difficult to collect. Thus, we focus on the unsupervised visual defect detection and localization tasks and propose a novel framework based on the recent score-based generative models, which synthesize the real image by iterative denoising through stochastic differential equations (SDEs). Our work is inspired by the fact that with noise injected into the original image, the defects may be changed into normal cases in the denoising process (i.e., reconstruction). First, based on the assumption that the anomalous data lie in the low probability density region of the normal data distribution, we explain a common phenomenon that occurs when reconstruction-based approaches are applied to VDD: normal pixels also change during the reconstruction process. Second, due to the differences in normal pixels between the reconstructed and original images, a time-dependent gradient value (i.e., score) of normal data distribution is utilized as a metric, rather than reconstruction loss, to gauge the defects. Third, a novel $T$ scales approach is developed to dramatically reduce the required number of iterations, accelerating the inference process. These practices allow our model to generalize VDD in an unsupervised manner while maintaining reasonably good performance. We evaluate our method on several datasets to demonstrate its effectiveness.
Transcervical Ultrasound Image Guidance System for Transoral Robotic Surgery
Nov 29, 2022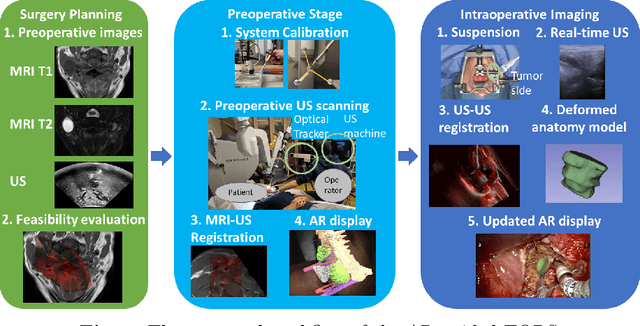
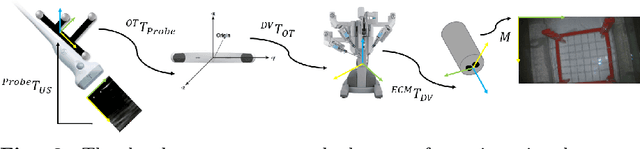


Purpose: Trans-oral robotic surgery (TORS) using the da Vinci surgical robot is a new minimally-invasive surgery method to treat oropharyngeal tumors, but it is a challenging operation. Augmented reality (AR) based on intra-operative ultrasound (US) has the potential to enhance the visualization of the anatomy and cancerous tumors to provide additional tools for decision-making in surgery. Methods: We propose and carry out preliminary evaluations of a US-guided AR system for TORS, with the transducer placed on the neck for a transcervical view. Firstly, we perform a novel MRI-transcervical 3D US registration study. Secondly, we develop a US-robot calibration method with an optical tracker and an AR system to display the anatomy mesh model in the real-time endoscope images inside the surgeon console. Results: Our AR system reaches a mean projection error of 26.81 and 27.85 pixels for the projection from the US to stereo cameras in a water bath experiment. The average target registration error for MRI to 3D US is 8.90 mm for the 3D US transducer and 5.85 mm for freehand 3D US, and the average distance between the vessel centerlines is 2.32 mm. Conclusion: We demonstrate the first proof-of-concept transcervical US-guided AR system for TORS and the feasibility of trans-cervical 3D US-MRI registration. Our results show that trans-cervical 3D US is a promising technique for TORS image guidance.