 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Sensing-Throughput Tradeoffs with Generative Adversarial Networks for NextG Spectrum Sharing
Dec 27, 2022

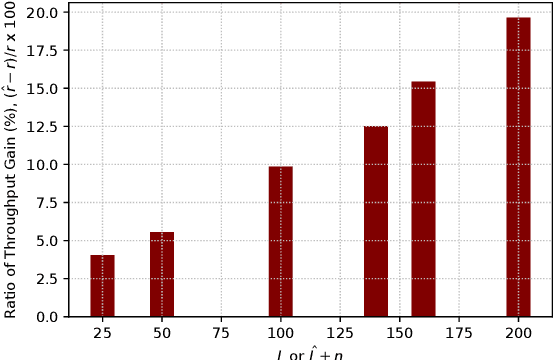
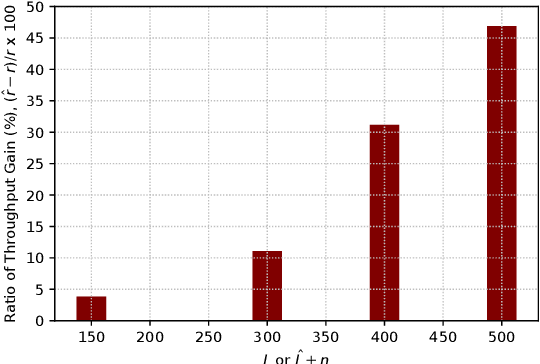
Spectrum coexistence is essential for next generation (NextG) systems to share the spectrum with incumbent (primary) users and meet the growing demand for bandwidth. One example is the 3.5 GHz Citizens Broadband Radio Service (CBRS) band, where the 5G and beyond communication systems need to sense the spectrum and then access the channel in an opportunistic manner when the incumbent user (e.g., radar) is not transmitting. To that end, a high-fidelity classifier based on a deep neural network is needed for low misdetection (to protect incumbent users) and low false alarm (to achieve high throughput for NextG). In a dynamic wireless environment, the classifier can only be used for a limited period of time, i.e., coherence time. A portion of this period is used for learning to collect sensing results and train a classifier, and the rest is used for transmissions. In spectrum sharing systems, there is a well-known tradeoff between the sensing time and the transmission time. While increasing the sensing time can increase the spectrum sensing accuracy, there is less time left for data transmissions. In this paper, we present a generative adversarial network (GAN) approach to generate synthetic sensing results to augment the training data for the deep learning classifier so that the sensing time can be reduced (and thus the transmission time can be increased) while keeping high accuracy of the classifier. We consider both additive white Gaussian noise (AWGN) and Rayleigh channels, and show that this GAN-based approach can significantly improve both the protection of the high-priority user and the throughput of the NextG user (more in Rayleigh channels than AWGN channels).
A Framework for Evaluating the Impact of Food Security Scenarios
Jan 24, 2023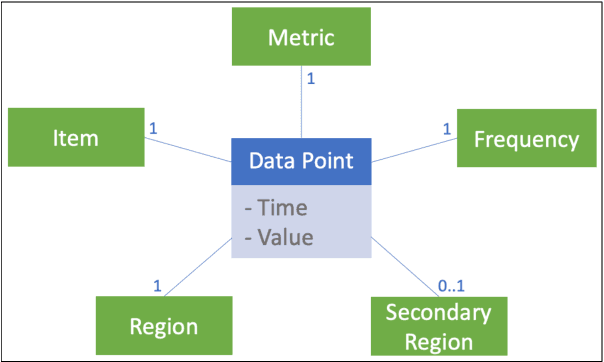
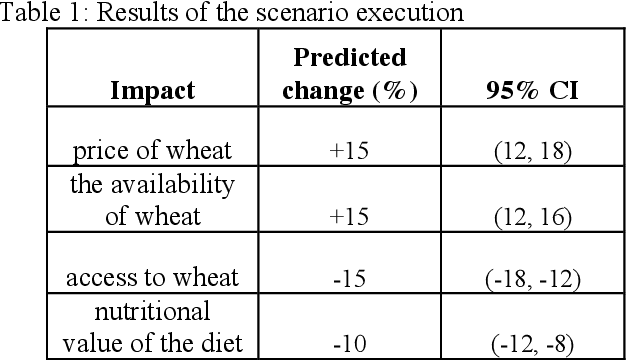
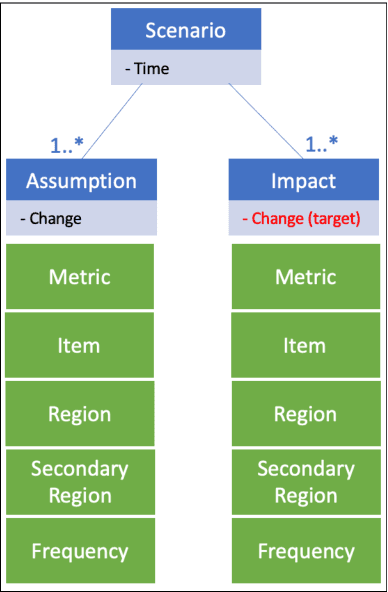
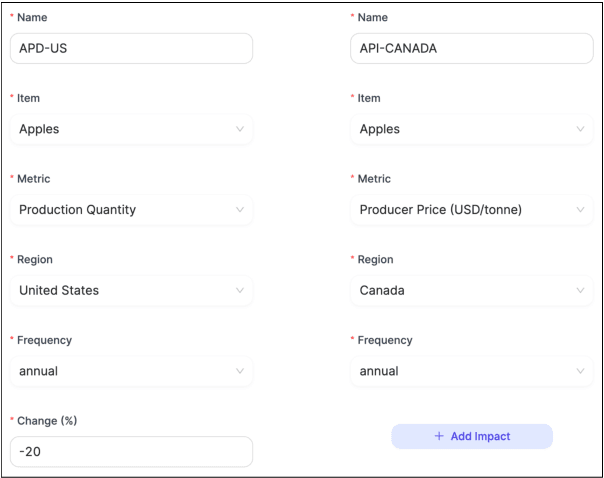
This study proposes an approach for predicting the impacts of scenarios on food security and demonstrates its application in a case study. The approach involves two main steps: (1) scenario definition, in which the end user specifies the assumptions and impacts of the scenario using a scenario template, and (2) scenario evaluation, in which a Vector Autoregression (VAR) model is used in combination with Monte Carlo simulation to generate predictions for the impacts of the scenario based on the defined assumptions and impacts. The case study is based on a proprietary time series food security database created using data from the Food and Agriculture Organization of the United Nations (FAOSTAT), the World Bank, and the United States Department of Agriculture (USDA). The database contains a wide range of data on various indicators of food security, such as production, trade, consumption, prices, availability, access, and nutritional value. The results show that the proposed approach can be used to predict the potential impacts of scenarios on food security and that the proprietary time series food security database can be used to support this approach. The study provides specific insights on how this approach can inform decision-making processes related to food security such as food prices and availability in the case study region.
Diffusion-based Time Series Imputation and Forecasting with Structured State Space Models
Aug 19, 2022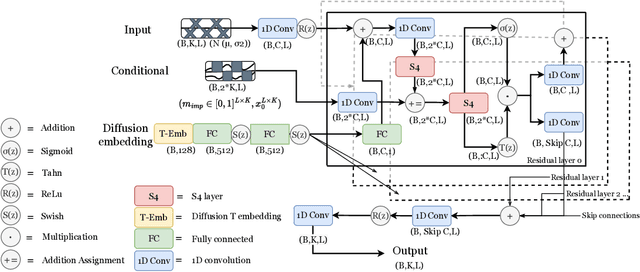
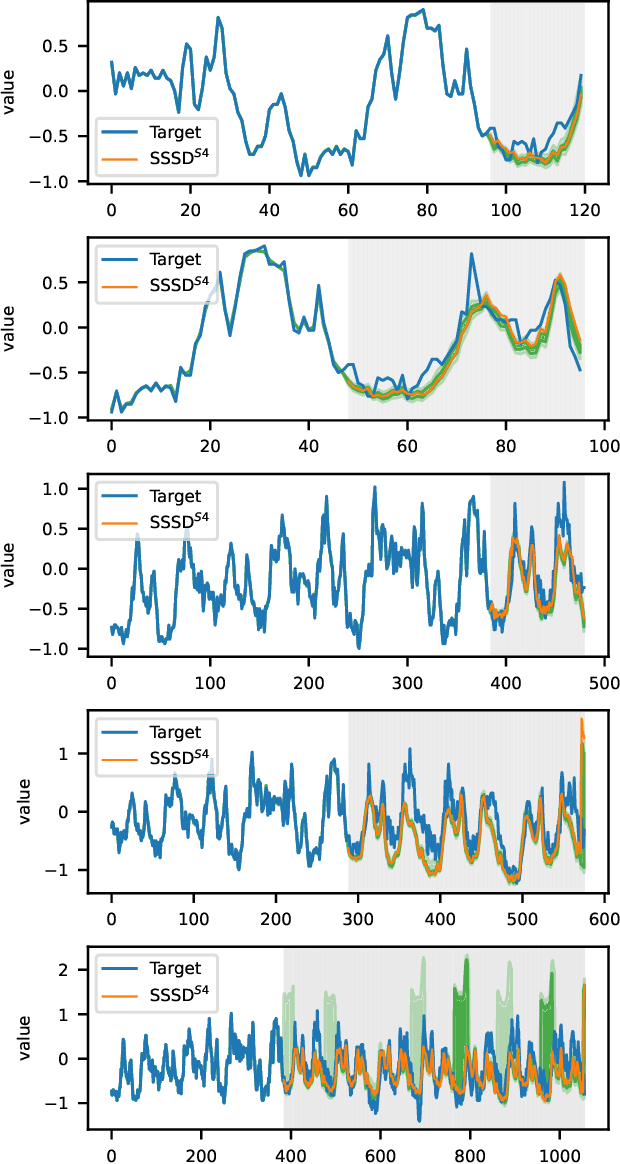
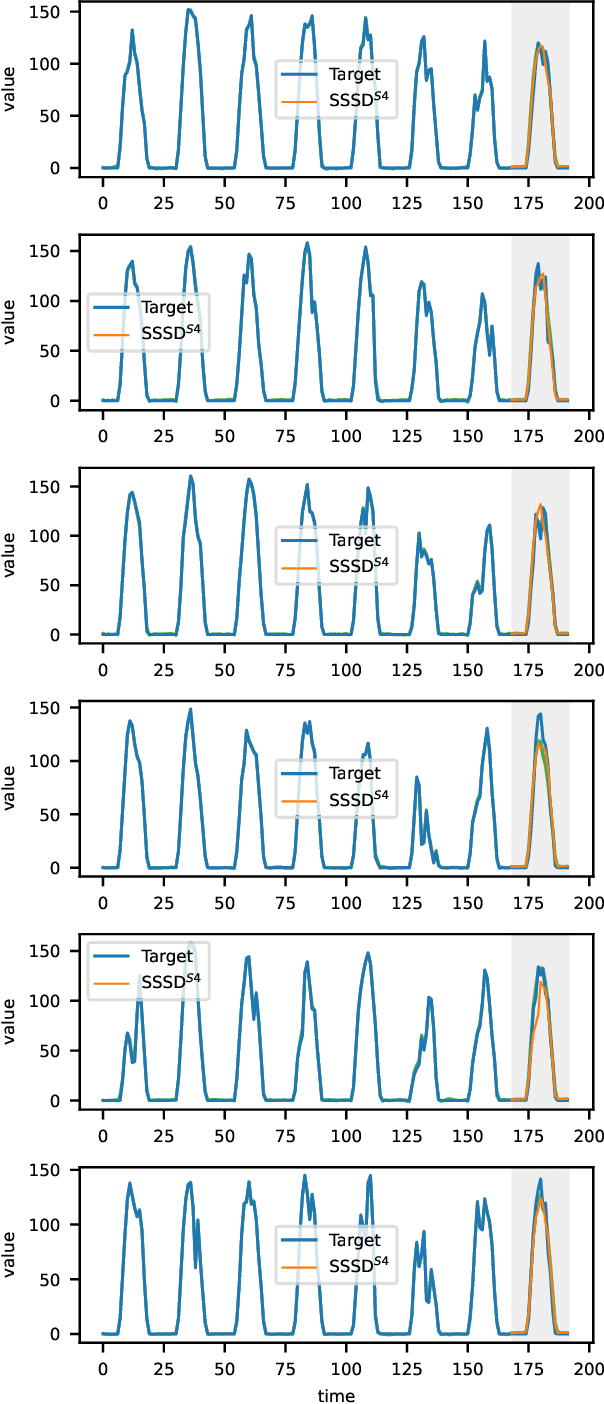
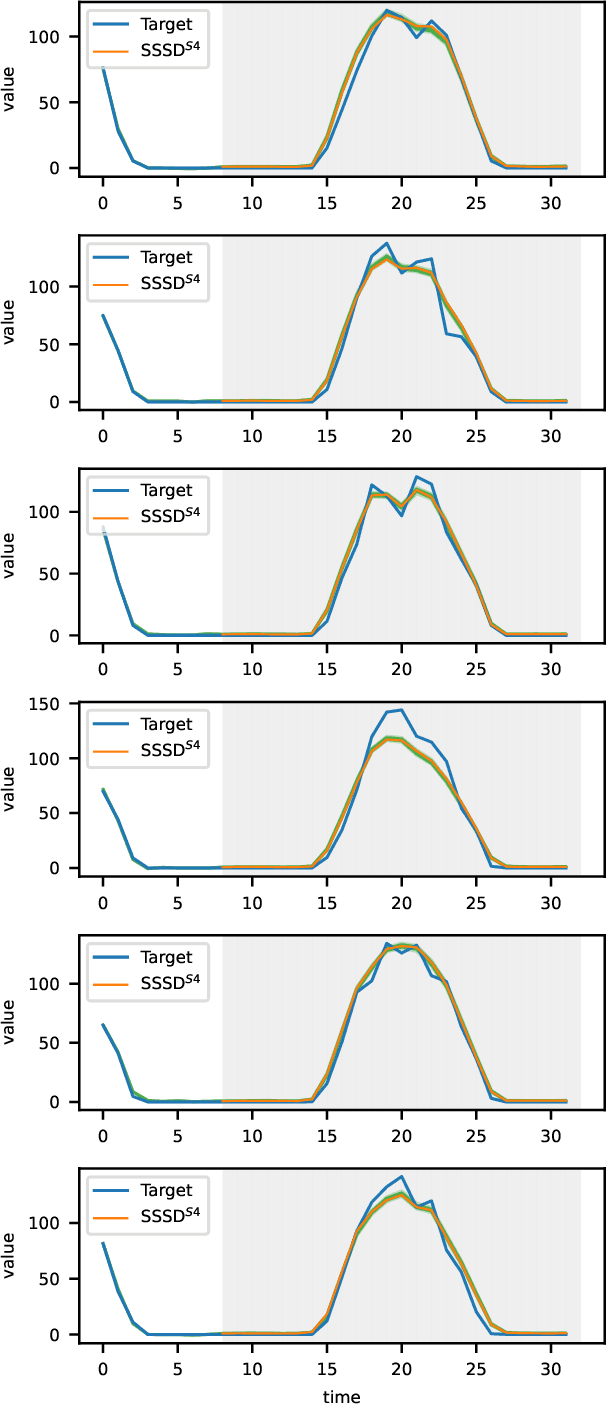
The imputation of missing values represents a significant obstacle for many real-world data analysis pipelines. Here, we focus on time series data and put forward SSSD, an imputation model that relies on two emerging technologies, (conditional) diffusion models as state-of-the-art generative models and structured state space models as internal model architecture, which are particularly suited to capture long-term dependencies in time series data. We demonstrate that SSSD matches or even exceeds state-of-the-art probabilistic imputation and forecasting performance on a broad range of data sets and different missingness scenarios, including the challenging blackout-missing scenarios, where prior approaches failed to provide meaningful results.
Persistence Initialization: A novel adaptation of the Transformer architecture for Time Series Forecasting
Aug 30, 2022
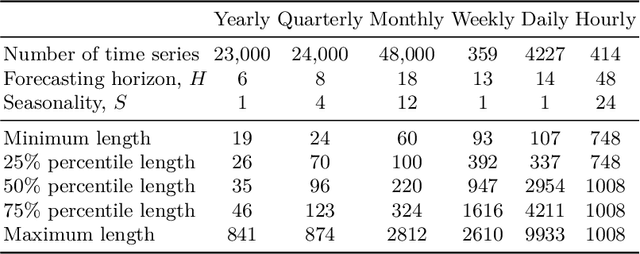
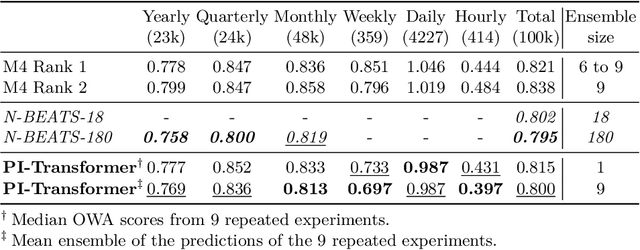
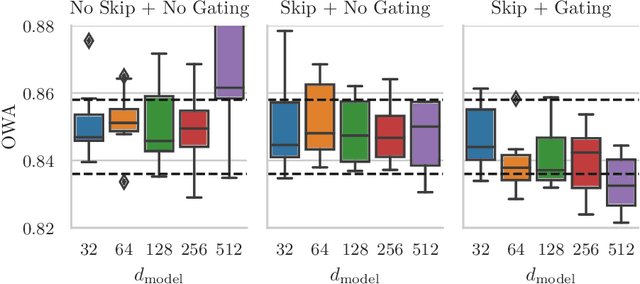
Time series forecasting is an important problem, with many real world applications. Ensembles of deep neural networks have recently achieved impressive forecasting accuracy, but such large ensembles are impractical in many real world settings. Transformer models been successfully applied to a diverse set of challenging problems. We propose a novel adaptation of the original Transformer architecture focusing on the task of time series forecasting, called Persistence Initialization. The model is initialized as a naive persistence model by using a multiplicative gating mechanism combined with a residual skip connection. We use a decoder Transformer with ReZero normalization and Rotary positional encodings, but the adaptation is applicable to any auto-regressive neural network model. We evaluate our proposed architecture on the challenging M4 dataset, achieving competitive performance compared to ensemble based methods. We also compare against existing recently proposed Transformer models for time series forecasting, showing superior performance on the M4 dataset. Extensive ablation studies show that Persistence Initialization leads to better performance and faster convergence. As the size of the model increases, only the models with our proposed adaptation gain in performance. We also perform an additional ablation study to determine the importance of the choice of normalization and positional encoding, and find both the use of Rotary encodings and ReZero normalization to be essential for good forecasting performance.
Complex QA and language models hybrid architectures, Survey
Feb 17, 2023
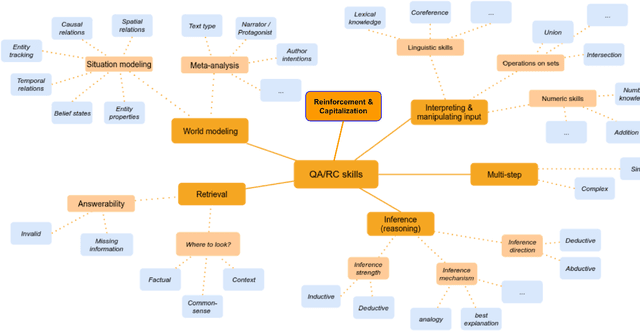
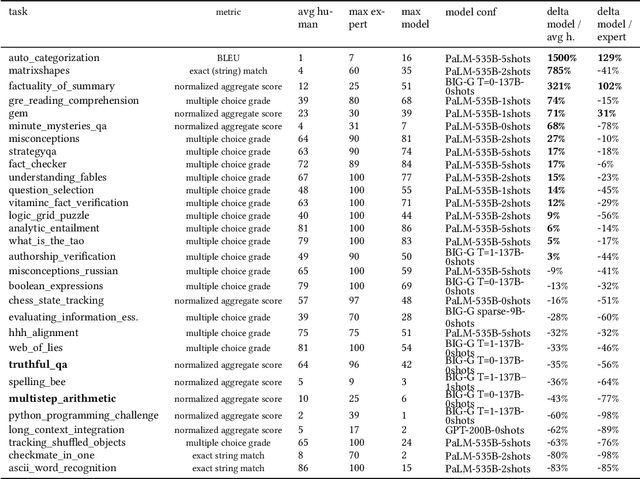
This paper provides a survey of the state of the art of hybrid language models architectures and strategies for "complex" question-answering (QA, CQA, CPS). Very large language models are good at leveraging public data on standard problems but once you want to tackle more specific complex questions or problems you may need specific architecture, knowledge, skills, tasks, methods, sensitive data, performance, human approval and versatile feedback... This survey extends findings from the robust community edited research papers BIG, BLOOM and HELM which open source, benchmark and analyze limits and challenges of large language models in terms of tasks complexity and strict evaluation on accuracy (e.g. fairness, robustness, toxicity, ...). It identifies the key elements used with Large Language Models (LLM) to solve complex questions or problems. Recent projects like ChatGPT and GALACTICA have allowed non-specialists to grasp the great potential as well as the equally strong limitations of language models in complex QA. Hybridizing these models with different components could allow to overcome these different limits and go much further. We discuss some challenges associated with complex QA, including domain adaptation, decomposition and efficient multi-step QA, long form QA, non-factoid QA, safety and multi-sensitivity data protection, multimodal search, hallucinations, QA explainability and truthfulness, time dimension. Therefore we review current solutions and promising strategies, using elements such as hybrid LLM architectures, human-in-the-loop reinforcement learning, prompting adaptation, neuro-symbolic and structured knowledge grounding, program synthesis, and others. We analyze existing solutions and provide an overview of the current research and trends in the area of complex QA.
Deep Learning for Event-based Vision: A Comprehensive Survey and Benchmarks
Feb 17, 2023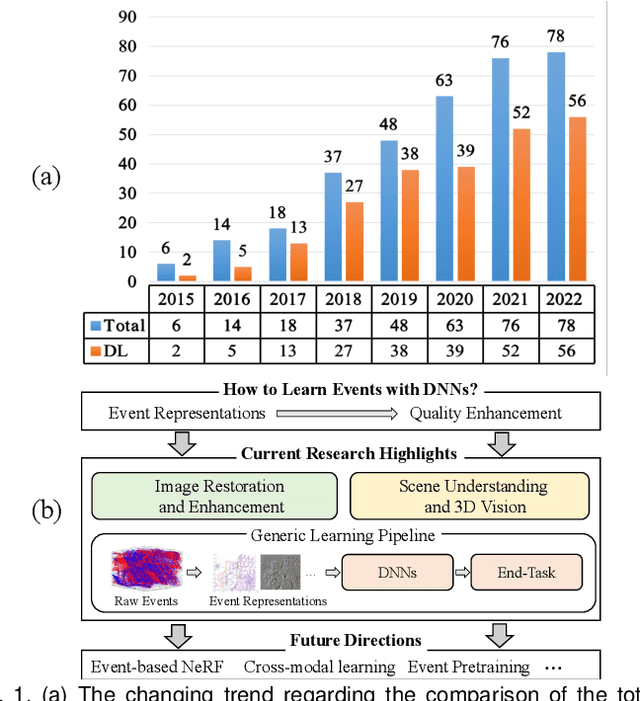
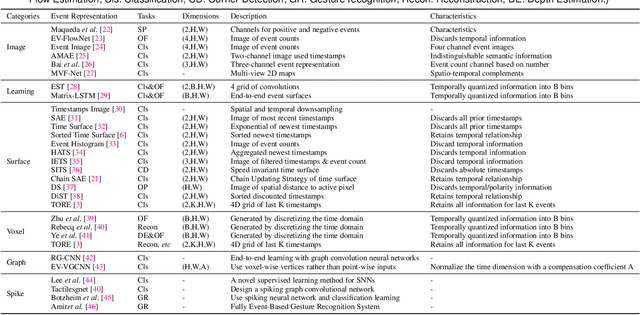

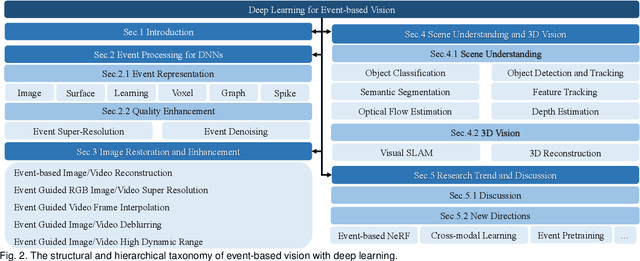
Event cameras are bio-inspired sensors that capture the per-pixel intensity changes asynchronously and produce event streams encoding the time, pixel position, and polarity (sign) of the intensity changes. Event cameras possess a myriad of advantages over canonical frame-based cameras, such as high temporal resolution, high dynamic range, low latency, etc. Being capable of capturing information in challenging visual conditions, event cameras have the potential to overcome the limitations of frame-based cameras in the computer vision and robotics community. In very recent years, deep learning (DL) has been brought to this emerging field and inspired active research endeavors in mining its potential. However, the technical advances still remain unknown, thus making it urgent and necessary to conduct a systematic overview. To this end, we conduct the first yet comprehensive and in-depth survey, with a focus on the latest developments of DL techniques for event-based vision. We first scrutinize the typical event representations with quality enhancement methods as they play a pivotal role as inputs to the DL models. We then provide a comprehensive taxonomy for existing DL-based methods by structurally grouping them into two major categories: 1) image reconstruction and restoration; 2) event-based scene understanding 3D vision. Importantly, we conduct benchmark experiments for the existing methods in some representative research directions (eg, object recognition and optical flow estimation) to identify some critical insights and problems. Finally, we make important discussions regarding the challenges and provide new perspectives for motivating future research studies.
Minimizing the Age of Information Over an Erasure Channel for Random Packet Arrivals With a Storage Option at the Transmitter
Jan 10, 2023
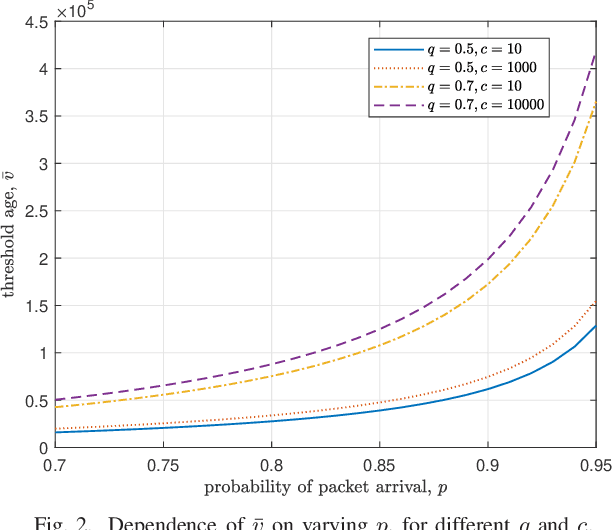
We consider a time slotted communication system consisting of a base station (BS) and a user. At each time slot an update packet arrives at the BS with probability $p$, and the BS successfully transmits the update packet with probability $q$ over an erasure channel. We assume that the BS has a unit size buffer where it can store an update packet upon paying a storage cost $c$. There is a trade-off between the age of information and the storage cost. We formulate this trade-off as a Markov decision process and find an optimal switching type storage policy.
From Continual Learning to Causal Discovery in Robotics
Jan 10, 2023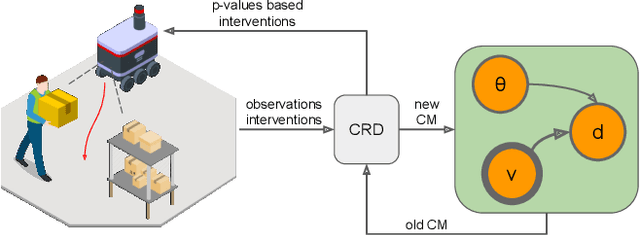
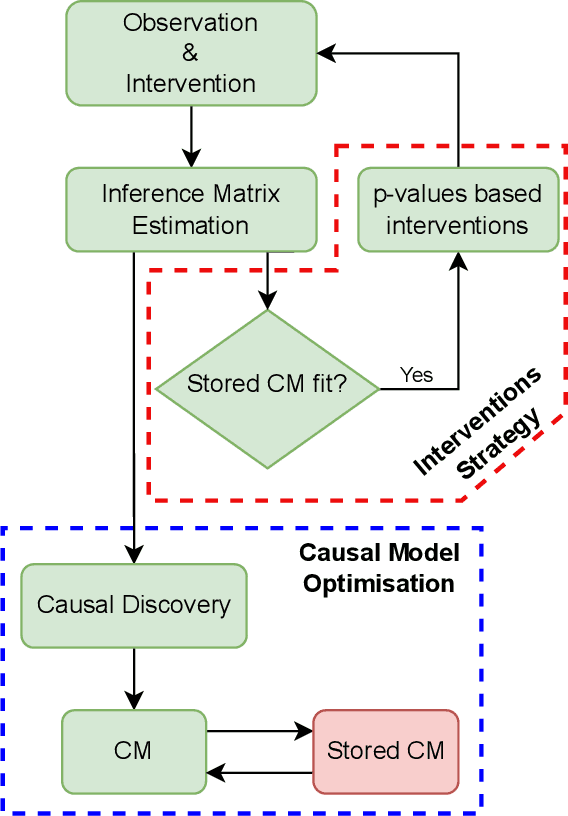
Reconstructing accurate causal models of dynamic systems from time-series of sensor data is a key problem in many real-world scenarios. In this paper, we present an overview based on our experience about practical challenges that the causal analysis encounters when applied to autonomous robots and how Continual Learning~(CL) could help to overcome them. We propose a possible way to leverage the CL paradigm to make causal discovery feasible for robotics applications where the computational resources are limited, while at the same time exploiting the robot as an active agent that helps to increase the quality of the reconstructed causal models.
Graph Neural Networks for temporal graphs: State of the art, open challenges, and opportunities
Feb 02, 2023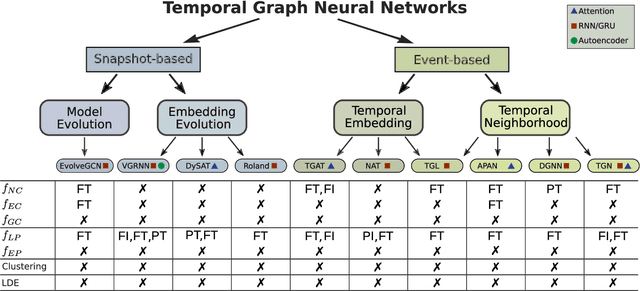
Graph Neural Networks (GNNs) have become the leading paradigm for learning on (static) graph-structured data. However, many real-world systems are dynamic in nature, since the graph and node/edge attributes change over time. In recent years, GNN-based models for temporal graphs have emerged as a promising area of research to extend the capabilities of GNNs. In this work, we provide the first comprehensive overview of the current state-of-the-art of temporal GNN, introducing a rigorous formalization of learning settings and tasks and a novel taxonomy categorizing existing approaches in terms of how the temporal aspect is represented and processed. We conclude the survey with a discussion of the most relevant open challenges for the field, from both research and application perspectives.
Improved Text Classification via Test-Time Augmentation
Jun 27, 2022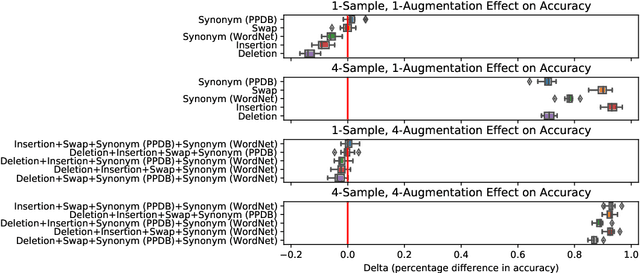

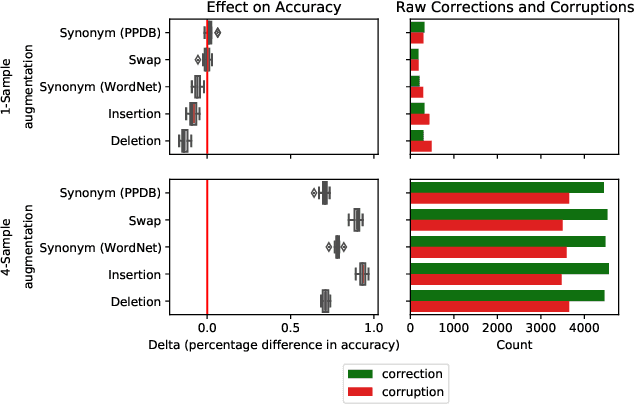
Test-time augmentation -- the aggregation of predictions across transformed examples of test inputs -- is an established technique to improve the performance of image classification models. Importantly, TTA can be used to improve model performance post-hoc, without additional training. Although test-time augmentation (TTA) can be applied to any data modality, it has seen limited adoption in NLP due in part to the difficulty of identifying label-preserving transformations. In this paper, we present augmentation policies that yield significant accuracy improvements with language models. A key finding is that augmentation policy design -- for instance, the number of samples generated from a single, non-deterministic augmentation -- has a considerable impact on the benefit of TTA. Experiments across a binary classification task and dataset show that test-time augmentation can deliver consistent improvements over current state-of-the-art approaches.