 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking the Generality of Vision-Language-Action Models
Dec 12, 2025Generalist multimodal agents are expected to unify perception, language, and control - operating robustly across diverse real world domains. However, current evaluation practices remain fragmented across isolated benchmarks, making it difficult to assess whether today's foundation models truly generalize beyond their training distributions. We introduce MultiNet v1.0, a unified benchmark for measuring the cross domain generality of vision language models (VLMs) and vision language action models (VLAs) across six foundational capability regimes. Visual grounding, spatial reasoning, tool use, physical commonsense, multi agent coordination, and continuous robot control. Evaluating GPT 5, Pi0, and Magma, we find that no model demonstrates consistent generality. All exhibit substantial degradation on unseen domains, unfamiliar modalities, or cross domain task shifts despite strong performance within their training distributions.These failures manifest as modality misalignment, output format instability, and catastrophic knowledge degradation under domain transfer.Our findings reveal a persistent gap between the aspiration of generalist intelligence and the actual capabilities of current foundation models.MultiNet v1.0 provides a standardized evaluation substrate for diagnosing these gaps and guiding the development of future generalist agents.Code, data, and leaderboards are publicly available.
Test-time augmentation improves efficiency in conformal prediction
May 28, 2025A conformal classifier produces a set of predicted classes and provides a probabilistic guarantee that the set includes the true class. Unfortunately, it is often the case that conformal classifiers produce uninformatively large sets. In this work, we show that test-time augmentation (TTA)--a technique that introduces inductive biases during inference--reduces the size of the sets produced by conformal classifiers. Our approach is flexible, computationally efficient, and effective. It can be combined with any conformal score, requires no model retraining, and reduces prediction set sizes by 10%-14% on average. We conduct an evaluation of the approach spanning three datasets, three models, two established conformal scoring methods, different guarantee strengths, and several distribution shifts to show when and why test-time augmentation is a useful addition to the conformal pipeline.
Instance-based Explanations for Gradient Boosting Machine Predictions with AXIL Weights
Jan 05, 2023



We show that regression predictions from linear and tree-based models can be represented as linear combinations of target instances in the training data. This also holds for models constructed as ensembles of trees, including Random Forests and Gradient Boosting Machines. The weights used in these linear combinations are measures of instance importance, complementing existing measures of feature importance, such as SHAP and LIME. We refer to these measures as AXIL weights (Additive eXplanations with Instance Loadings). Since AXIL weights are additive across instances, they offer both local and global explanations. Our work contributes to the broader effort to make machine learning predictions more interpretable and explainable.
Improved Text Classification via Test-Time Augmentation
Jun 27, 2022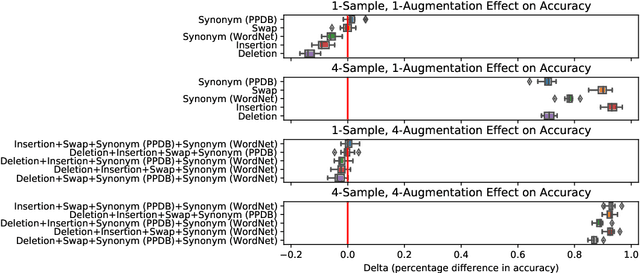

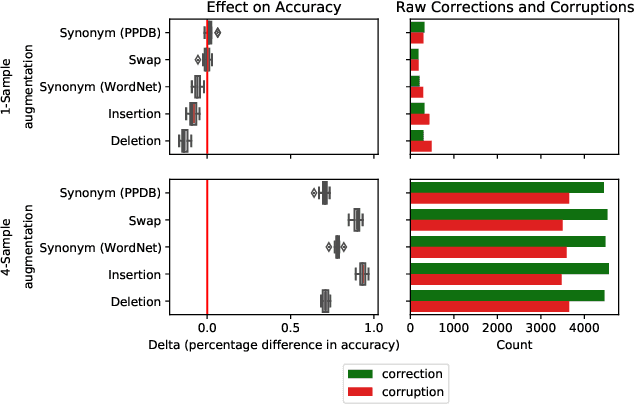
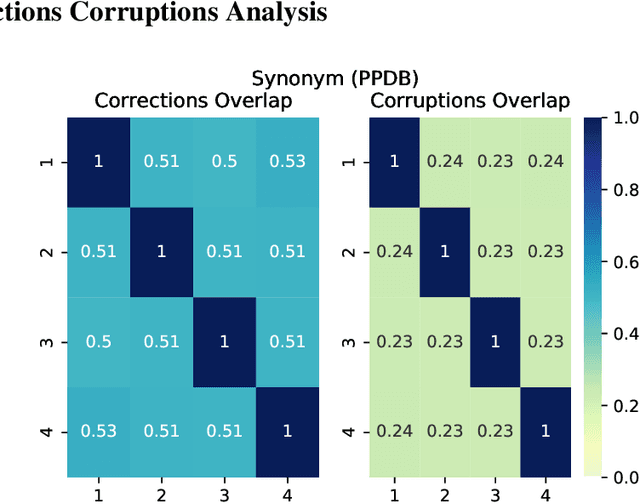
Test-time augmentation -- the aggregation of predictions across transformed examples of test inputs -- is an established technique to improve the performance of image classification models. Importantly, TTA can be used to improve model performance post-hoc, without additional training. Although test-time augmentation (TTA) can be applied to any data modality, it has seen limited adoption in NLP due in part to the difficulty of identifying label-preserving transformations. In this paper, we present augmentation policies that yield significant accuracy improvements with language models. A key finding is that augmentation policy design -- for instance, the number of samples generated from a single, non-deterministic augmentation -- has a considerable impact on the benefit of TTA. Experiments across a binary classification task and dataset show that test-time augmentation can deliver consistent improvements over current state-of-the-art approaches.