 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Enhanced Sampling of Configuration and Path Space in a Generalized Ensemble by Shooting Point Exchange
Feb 17, 2023

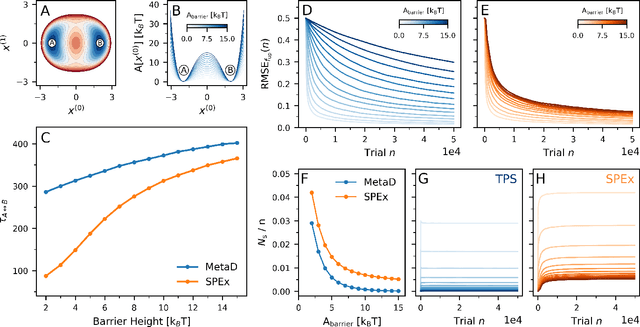
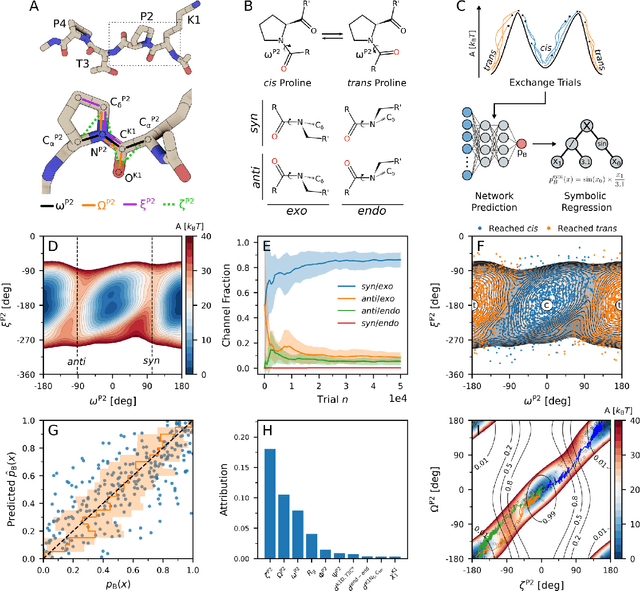
The computer simulation of many molecular processes is complicated by long time scales caused by rare transitions between long-lived states. Here, we propose a new approach to simulate such rare events, which combines transition path sampling with enhanced exploration of configuration space. The method relies on exchange moves between configuration and trajectory space, carried out based on a generalized ensemble. This scheme substantially enhances the efficiency of the transition path sampling simulations, particularly for systems with multiple transition channels, and yields information on thermodynamics, kinetics and reaction coordinates of molecular processes without distorting their dynamics. The method is illustrated using the isomerization of proline in the KPTP tetrapeptide.
Securing IoT Communication using Physical Sensor Data -- Graph Layer Security with Federated Multi-Agent Deep Reinforcement Learning
Feb 24, 2023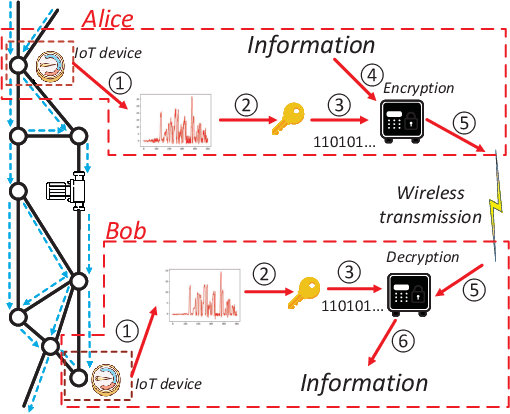
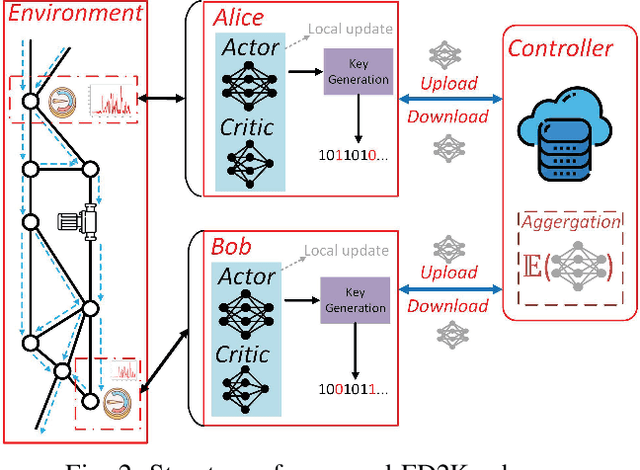
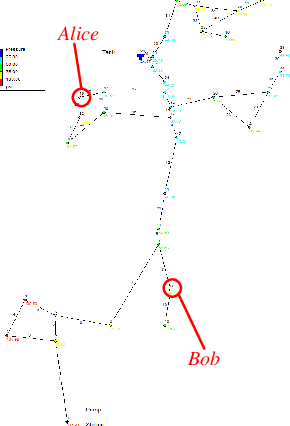
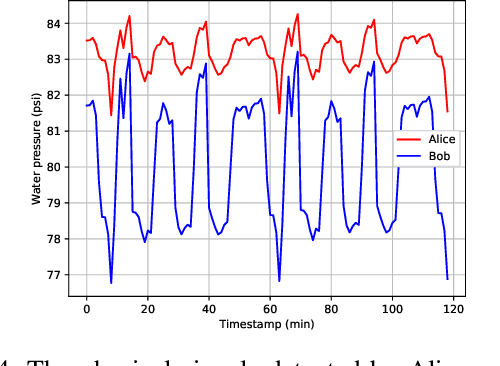
Internet-of-Things (IoT) devices are often used to transmit physical sensor data over digital wireless channels. Traditional Physical Layer Security (PLS)-based cryptography approaches rely on accurate channel estimation and information exchange for key generation, which irrevocably ties key quality with digital channel estimation quality. Recently, we proposed a new concept called Graph Layer Security (GLS), where digital keys are derived from physical sensor readings. The sensor readings between legitimate users are correlated through a common background infrastructure environment (e.g., a common water distribution network or electric grid). The challenge for GLS has been how to achieve distributed key generation. This paper presents a Federated multi-agent Deep reinforcement learning-assisted Distributed Key generation scheme (FD2K), which fully exploits the common features of physical dynamics to establish secret key between legitimate users. We present for the first time initial experimental results of GLS with federated learning, achieving considerable security performance in terms of key agreement rate (KAR), and key randomness.
A DeepONet Multi-Fidelity Approach for Residual Learning in Reduced Order Modeling
Feb 24, 2023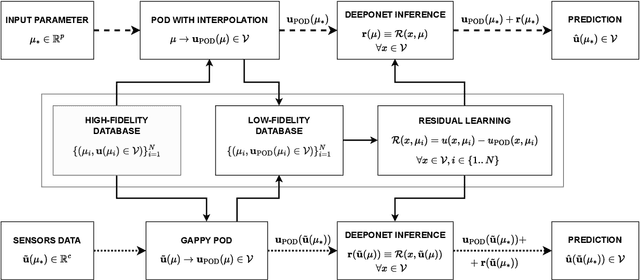
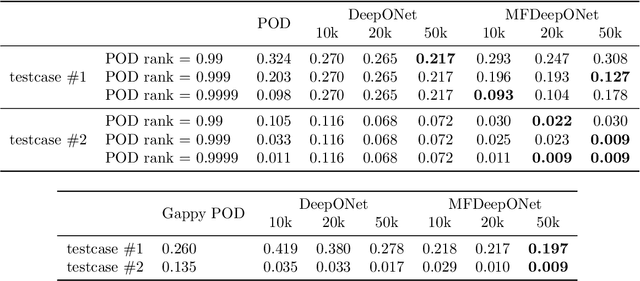
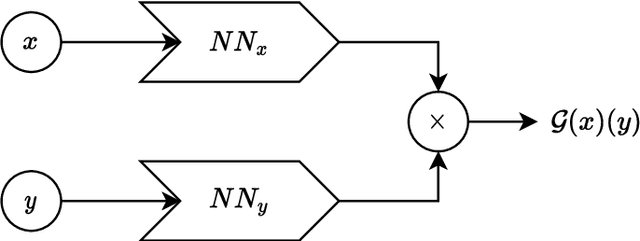
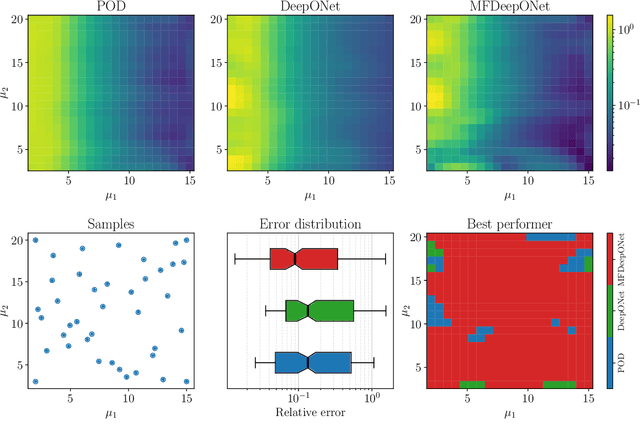
In the present work, we introduce a novel approach to enhance the precision of reduced order models by exploiting a multi-fidelity perspective and DeepONets. Reduced models provide a real-time numerical approximation by simplifying the original model. The error introduced by such operation is usually neglected and sacrificed in order to reach a fast computation. We propose to couple the model reduction to a machine learning residual learning, such that the above-mentioned error can be learnt by a neural network and inferred for new predictions. We emphasize that the framework maximizes the exploitation of the high-fidelity information, using it for building the reduced order model and for learning the residual. In this work we explore the integration of proper orthogonal decomposition (POD), and gappy POD for sensors data, with the recent DeepONet architecture. Numerical investigations for a parametric benchmark function and a nonlinear parametric Navier-Stokes problem are presented.
Intra-operative Brain Tumor Detection with Deep Learning-Optimized Hyperspectral Imaging
Feb 06, 2023
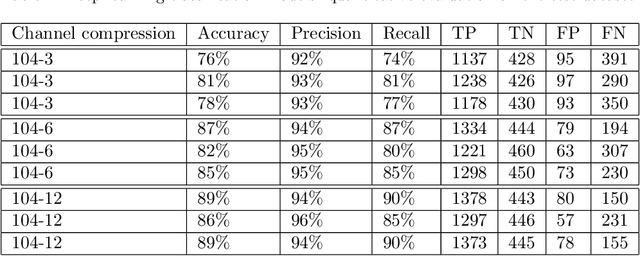
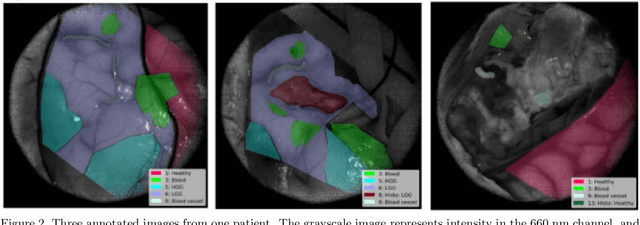
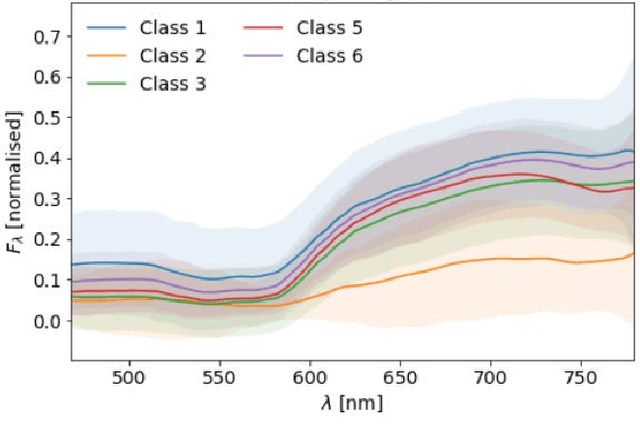
Surgery for gliomas (intrinsic brain tumors), especially when low-grade, is challenging due to the infiltrative nature of the lesion. Currently, no real-time, intra-operative, label-free and wide-field tool is available to assist and guide the surgeon to find the relevant demarcations for these tumors. While marker-based methods exist for the high-grade glioma case, there is no convenient solution available for the low-grade case; thus, marker-free optical techniques represent an attractive option. Although RGB imaging is a standard tool in surgical microscopes, it does not contain sufficient information for tissue differentiation. We leverage the richer information from hyperspectral imaging (HSI), acquired with a snapscan camera in the 468-787 nm range, coupled to a surgical microscope, to build a deep-learning-based diagnostic tool for cancer resection with potential for intra-operative guidance. However, the main limitation of the HSI snapscan camera is the image acquisition time, limiting its widespread deployment in the operation theater. Here, we investigate the effect of HSI channel reduction and pre-selection to scope the design space for the development of cheaper and faster sensors. Neural networks are used to identify the most important spectral channels for tumor tissue differentiation, optimizing the trade-off between the number of channels and precision to enable real-time intra-surgical application. We evaluate the performance of our method on a clinical dataset that was acquired during surgery on five patients. By demonstrating the possibility to efficiently detect low-grade glioma, these results can lead to better cancer resection demarcations, potentially improving treatment effectiveness and patient outcome.
Contribution of clinical course to outcome after traumatic brain injury: mining patient trajectories from European intensive care unit data
Mar 08, 2023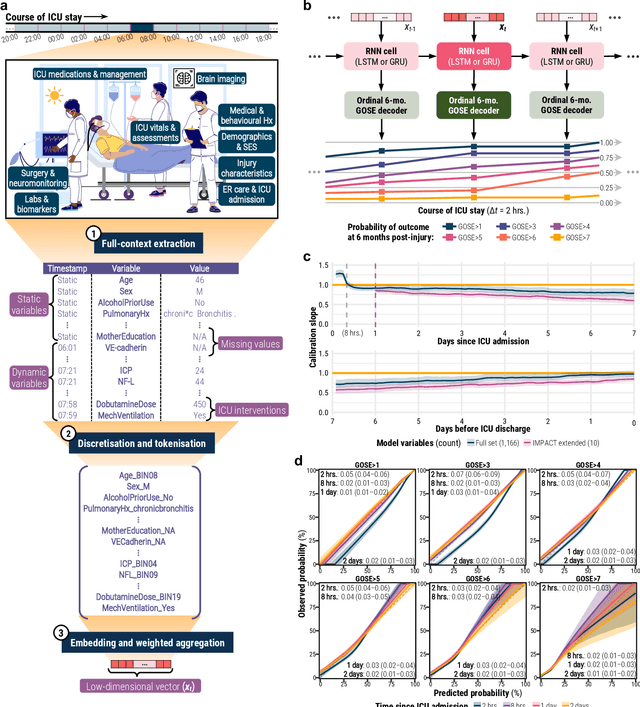
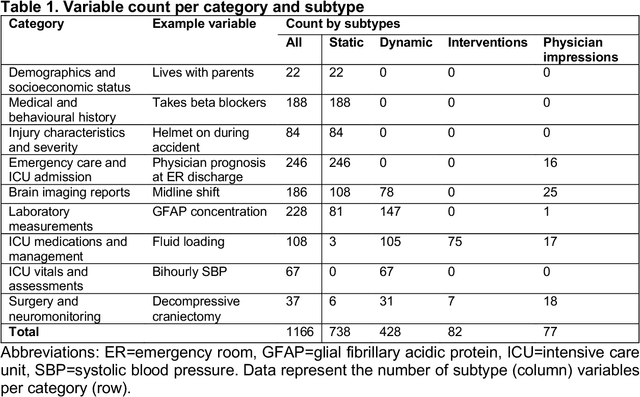
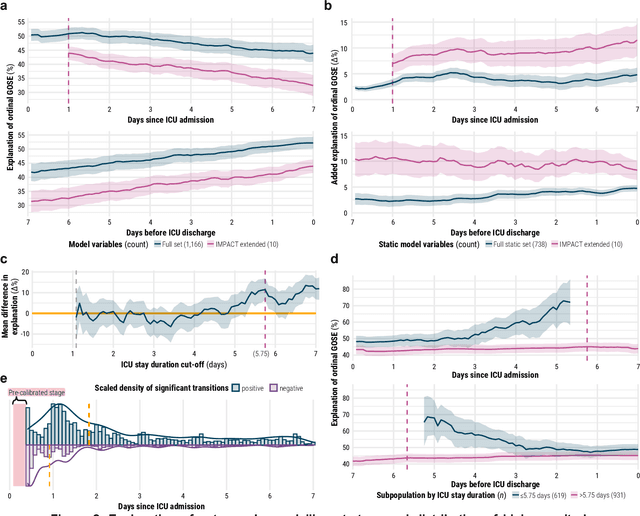
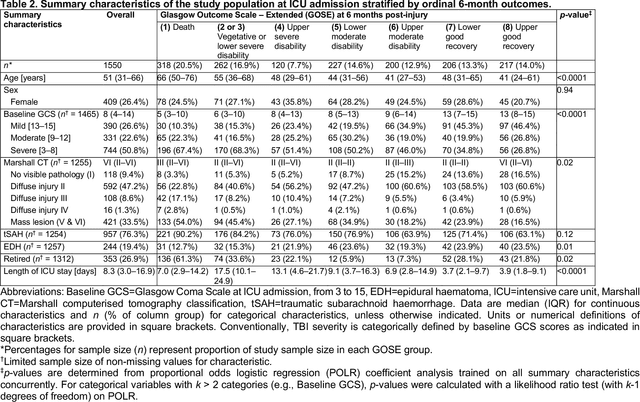
Existing methods to characterise the evolving condition of traumatic brain injury (TBI) patients in the intensive care unit (ICU) do not capture the context necessary for individualising treatment. We aimed to develop a modelling strategy which integrates all data stored in medical records to produce an interpretable disease course for each TBI patient's ICU stay. From a prospective, European cohort (n=1,550, 65 centres, 19 countries) of TBI patients, we extracted all 1,166 variables collected before or during ICU stay as well as 6-month functional outcome on the Glasgow Outcome Scale-Extended (GOSE). We trained recurrent neural network models to map a token-embedded time series representation of all variables (including missing data) to an ordinal GOSE prognosis every 2 hours. With repeated cross-validation, we evaluated calibration and the explanation of ordinal variance in GOSE with Somers' Dxy. Furthermore, we applied TimeSHAP to calculate the contribution of variables and prior timepoints towards transitions in patient trajectories. Our modelling strategy achieved calibration at 8 hours, and the full range of variables explained up to 52% (95% CI: 50-54%) of the variance in ordinal functional outcome. Up to 91% (90-91%) of this explanation was derived from pre-ICU and admission information. Information collected in the ICU increased explanation (by up to 5% [4-6%]), though not enough to counter poorer performance in longer-stay (>5.75 days) patients. Static variables with the highest contributions were physician prognoses and certain demographic and CT features. Among dynamic variables, markers of intracranial hypertension and neurological function contributed the most. Whilst static information currently accounts for the majority of functional outcome explanation, our data-driven analysis highlights investigative avenues to improve dynamic characterisation of longer-stay patients.
Clinical Courses of Acute Kidney Injury in Hospitalized Patients: A Multistate Analysis
Mar 08, 2023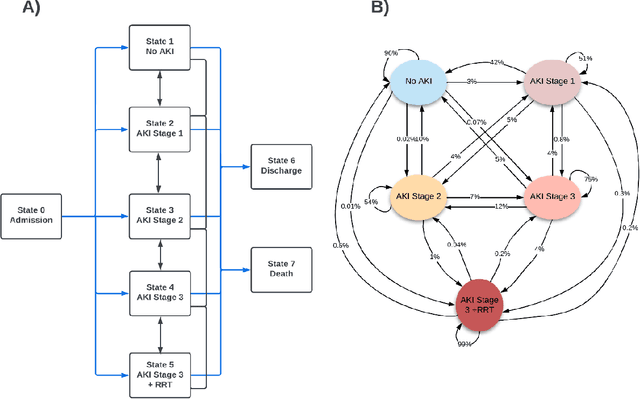
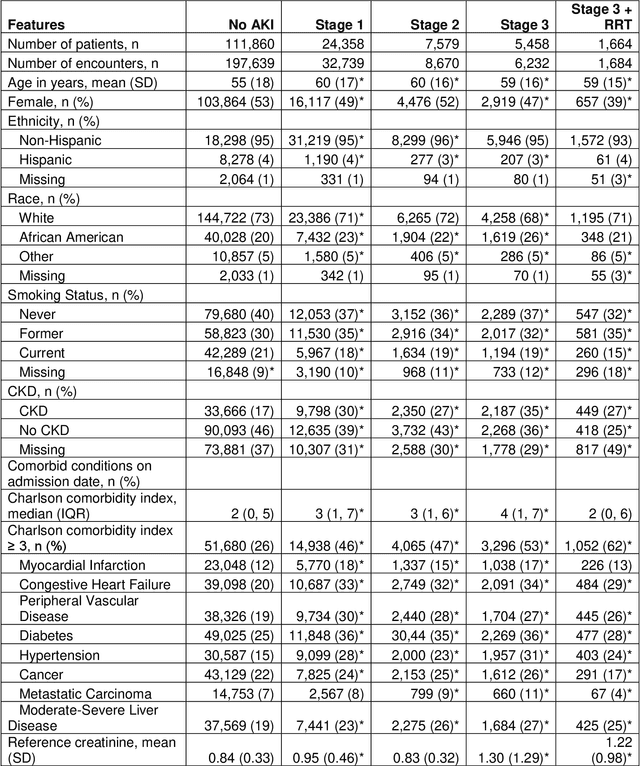
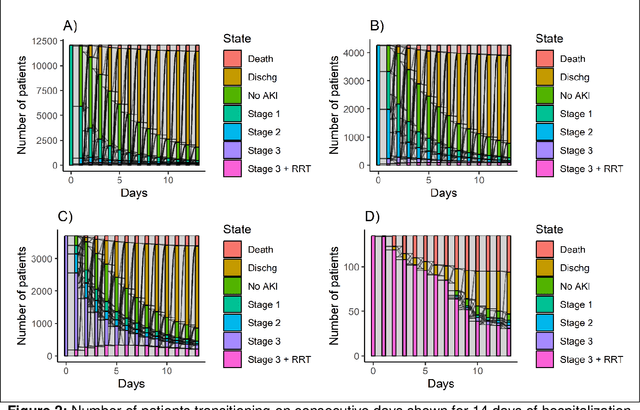
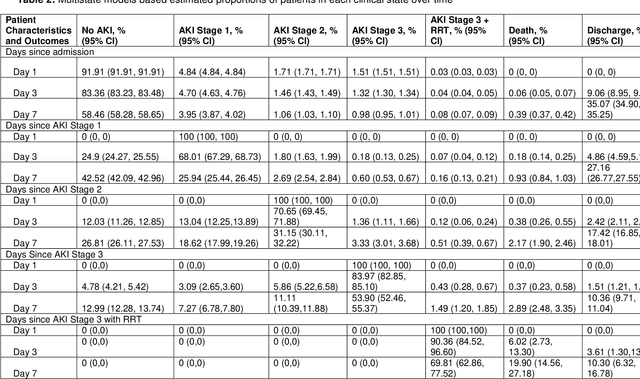
Objectives: We aim to quantify longitudinal acute kidney injury (AKI) trajectories and to describe transitions through progressing and recovery states and outcomes among hospitalized patients using multistate models. Methods: In this large, longitudinal cohort study, 138,449 adult patients admitted to a quaternary care hospital between 2012 and 2019 were staged based on Kidney Disease: Improving Global Outcomes serum creatinine criteria for the first 14 days of their hospital stay. We fit multistate models to estimate probability of being in a certain clinical state at a given time after entering each one of the AKI stages. We investigated the effects of selected variables on transition rates via Cox proportional hazards regression models. Results: Twenty percent of hospitalized encounters (49,325/246,964) had AKI; among patients with AKI, 66% had Stage 1 AKI, 18% had Stage 2 AKI, and 17% had AKI Stage 3 with or without RRT. At seven days following Stage 1 AKI, 69% (95% confidence interval [CI]: 68.8%-70.5%) were either resolved to No AKI or discharged, while smaller proportions of recovery (26.8%, 95% CI: 26.1%-27.5%) and discharge (17.4%, 95% CI: 16.8%-18.0%) were observed following AKI Stage 2. At 14 days following Stage 1 AKI, patients with more frail conditions (Charlson comorbidity index greater than or equal to 3 and had prolonged ICU stay) had lower proportion of transitioning to No AKI or discharge states. Discussion: Multistate analyses showed that the majority of Stage 2 and higher severity AKI patients could not resolve within seven days; therefore, strategies preventing the persistence or progression of AKI would contribute to the patients' life quality. Conclusions: We demonstrate multistate modeling framework's utility as a mechanism for a better understanding of the clinical course of AKI with the potential to facilitate treatment and resource planning.
Path Planning Considering Time-Varying and Uncertain Movement Speed in Multi-Robot Automatic Warehouses: Problem Formulation and Algorithm
Dec 01, 2022

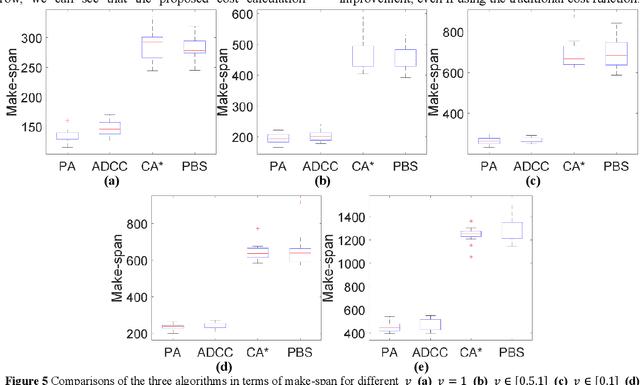
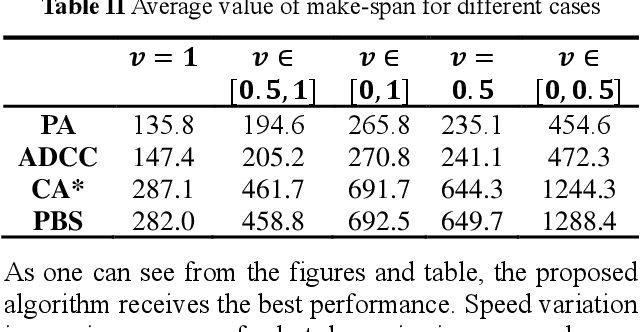
Path planning in the multi-robot system refers to calculating a set of actions for each robot, which will move each robot to its goal without conflicting with other robots. Lately, the research topic has received significant attention for its extensive applications, such as airport ground, drone swarms, and automatic warehouses. Despite these available research results, most of the existing investigations are concerned with the cases of robots with a fixed movement speed without considering uncertainty. Therefore, in this work, we study the problem of path-planning in the multi-robot automatic warehouse context, which considers the time-varying and uncertain robots' movement speed. Specifically, the path-planning module searches a path with as few conflicts as possible for a single agent by calculating traffic cost based on customarily distributed conflict probability and combining it with the classic A* algorithm. However, this probability-based method cannot eliminate all conflicts, and speed's uncertainty will constantly cause new conflicts. As a supplement, we propose the other two modules. The conflict detection and re-planning module chooses objects requiring re-planning paths from the agents involved in different types of conflicts periodically by our designed rules. Also, at each step, the scheduling module fills up the agent's preserved queue and decides who has a higher priority when the same element is assigned to two agents simultaneously. Finally, we compare the proposed algorithm with other algorithms from academia and industry, and the results show that the proposed method is validated as the best performance.
A Constant-per-Iteration Likelihood Ratio Test for Online Changepoint Detection for Exponential Family Models
Feb 09, 2023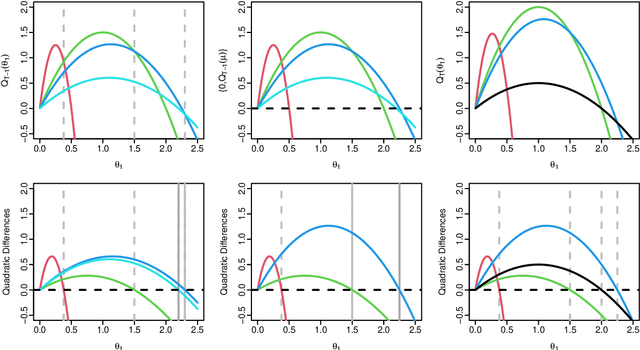
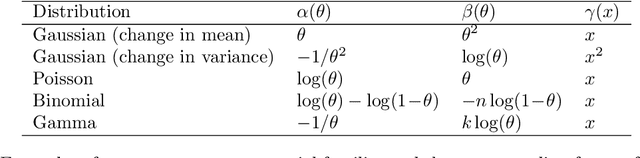
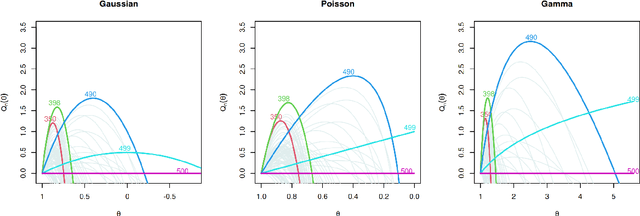
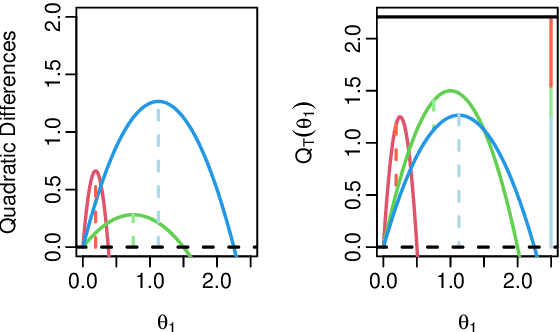
Online changepoint detection algorithms that are based on likelihood-ratio tests have been shown to have excellent statistical properties. However, a simple online implementation is computationally infeasible as, at time $T$, it involves considering $O(T)$ possible locations for the change. Recently, the FOCuS algorithm has been introduced for detecting changes in mean in Gaussian data that decreases the per-iteration cost to $O(\log T)$. This is possible by using pruning ideas, which reduce the set of changepoint locations that need to be considered at time $T$ to approximately $\log T$. We show that if one wishes to perform the likelihood ratio test for a different one-parameter exponential family model, then exactly the same pruning rule can be used, and again one need only consider approximately $\log T$ locations at iteration $T$. Furthermore, we show how we can adaptively perform the maximisation step of the algorithm so that we need only maximise the test statistic over a small subset of these possible locations. Empirical results show that the resulting online algorithm, which can detect changes under a wide range of models, has a constant-per-iteration cost on average.
2D-Empowered 3D Object Detection on the Edge
Feb 18, 2023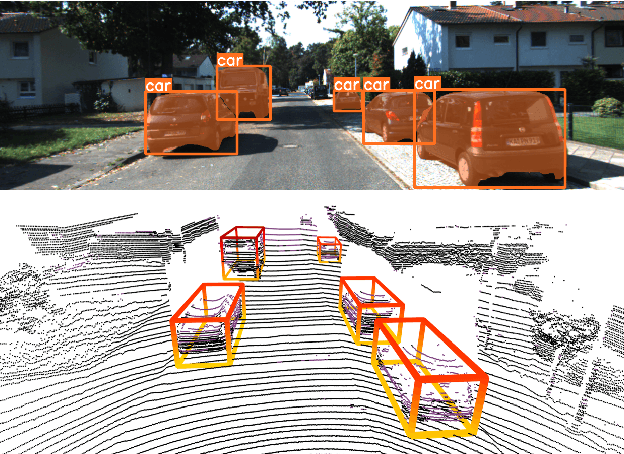
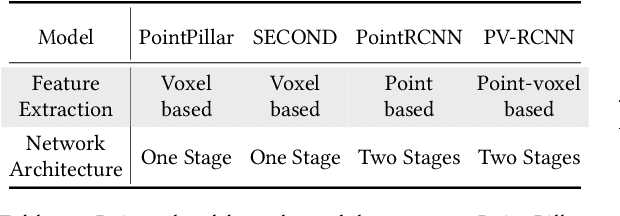
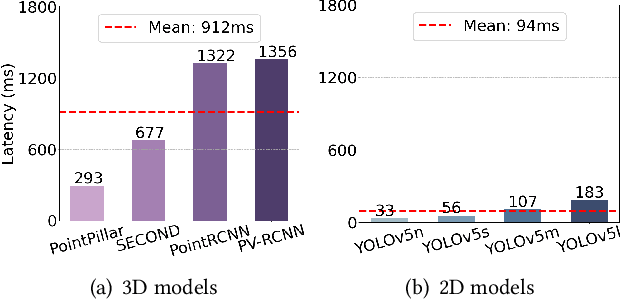
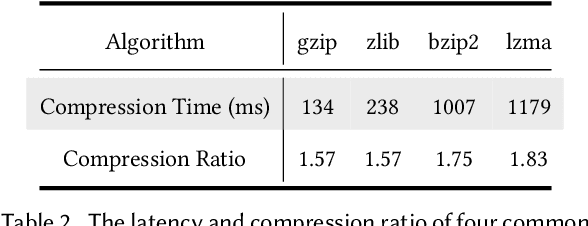
3D object detection has a pivotal role in a wide range of applications, most notably autonomous driving and robotics. These applications are commonly deployed on edge devices to promptly interact with the environment, and often require near real-time response. With limited computation power, it is challenging to execute 3D detection on the edge using highly complex neural networks. Common approaches such as offloading to the cloud brings latency overheads due to the large amount of 3D point cloud data during transmission. To resolve the tension between wimpy edge devices and compute-intensive inference workloads, we explore the possibility of transforming fast 2D detection results to extrapolate 3D bounding boxes. To this end, we present Moby, a novel system that demonstrates the feasibility and potential of our approach. Our main contributions are two-fold: First, we design a 2D-to-3D transformation pipeline that takes as input the point cloud data from LiDAR and 2D bounding boxes from camera that are captured at exactly the same time, and generate 3D bounding boxes efficiently and accurately based on detection results of the previous frames without running 3D detectors. Second, we design a frame offloading scheduler that dynamically launches a 3D detection when the error of 2D-to-3D transformation accumulates to a certain level, so the subsequent transformations can draw upon the latest 3D detection results with better accuracy. Extensive evaluation on NVIDIA Jetson TX2 with the autonomous driving dataset KITTI and real-world 4G/LTE traces shows that, Moby reduces the end-to-end latency by up to 91.9% with mild accuracy drop compared to baselines. Further, Moby shows excellent energy efficiency by saving power consumption and memory footprint up to 75.7% and 48.1%, respectively.
Koopman Operator Learning: Sharp Spectral Rates and Spurious Eigenvalues
Feb 07, 2023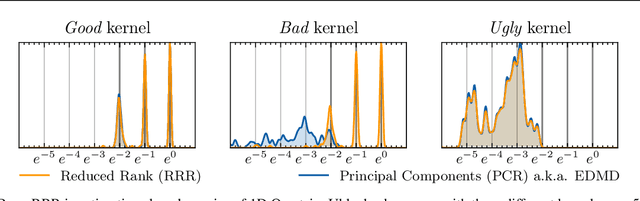
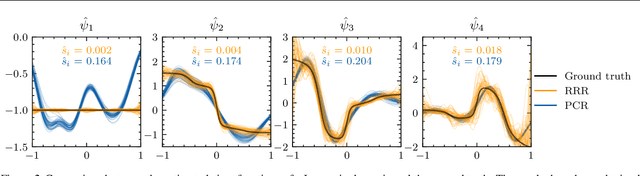
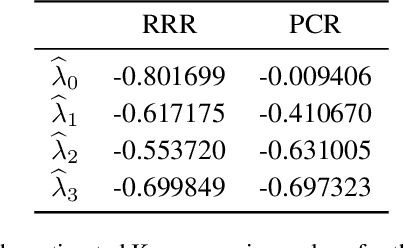
Non-linear dynamical systems can be handily described by the associated Koopman operator, whose action evolves every observable of the system forward in time. Learning the Koopman operator from data is enabled by a number of algorithms. In this work we present nonasymptotic learning bounds for the Koopman eigenvalues and eigenfunctions estimated by two popular algorithms: Extended Dynamic Mode Decomposition (EDMD) and Reduced Rank Regression (RRR). We focus on time-reversal-invariant Markov chains, implying that the Koopman operator is self-adjoint. This includes important examples of stochastic dynamical systems, notably Langevin dynamics. Our spectral learning bounds are driven by the simultaneous control of the operator norm risk of the estimators and a metric distortion associated to the corresponding eigenfunctions. Our analysis indicates that both algorithms have similar variance, but EDMD suffers from a larger bias which might be detrimental to its learning rate. We further argue that a large metric distortion may lead to spurious eigenvalues, a phenomenon which has been empirically observed, and note that metric distortion can be estimated from data. Numerical experiments complement the theoretical findings.