 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient Enumeration of Markov Equivalent DAGs
Jan 28, 2023
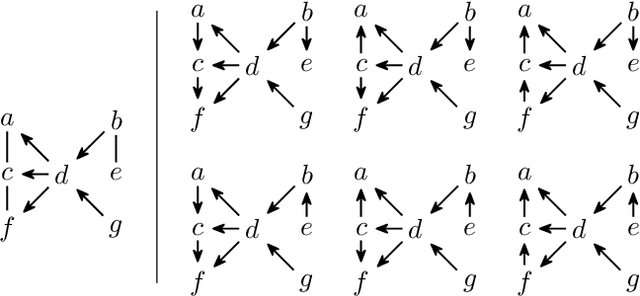
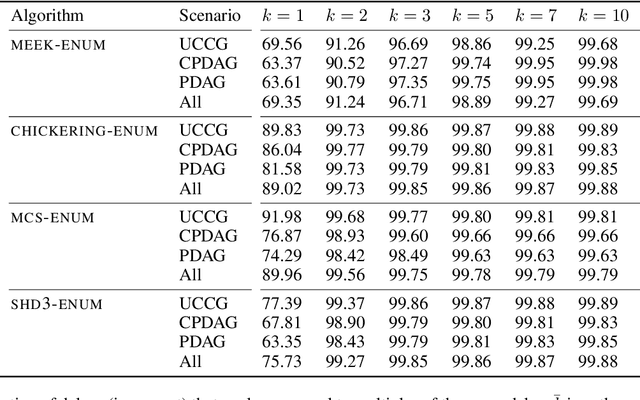
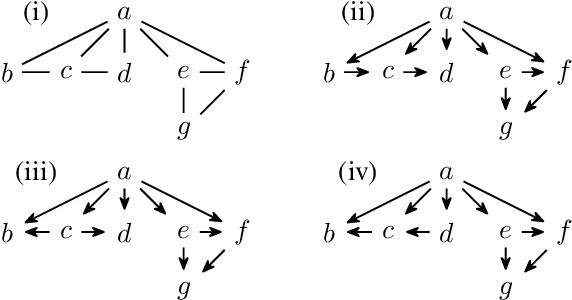
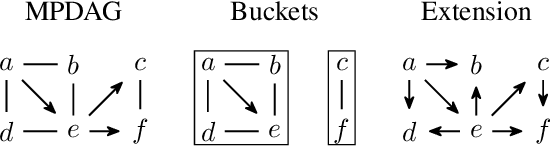
Enumerating the directed acyclic graphs (DAGs) of a Markov equivalence class (MEC) is an important primitive in causal analysis. The central resource from the perspective of computational complexity is the delay, that is, the time an algorithm that lists all members of the class requires between two consecutive outputs. Commonly used algorithms for this task utilize the rules proposed by Meek (1995) or the transformational characterization by Chickering (1995), both resulting in superlinear delay. In this paper, we present the first linear-time delay algorithm. On the theoretical side, we show that our algorithm can be generalized to enumerate DAGs represented by models that incorporate background knowledge, such as MPDAGs; on the practical side, we provide an efficient implementation and evaluate it in a series of experiments. Complementary to the linear-time delay algorithm, we also provide intriguing insights into Markov equivalence itself: All members of an MEC can be enumerated such that two successive DAGs have structural Hamming distance at most three.
Self-Supervised Contrastive Pre-Training For Time Series via Time-Frequency Consistency
Jun 17, 2022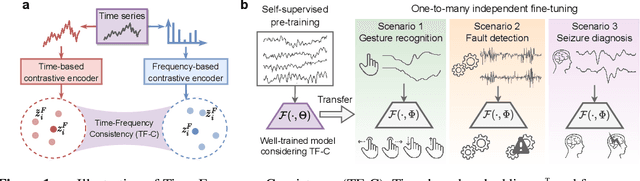
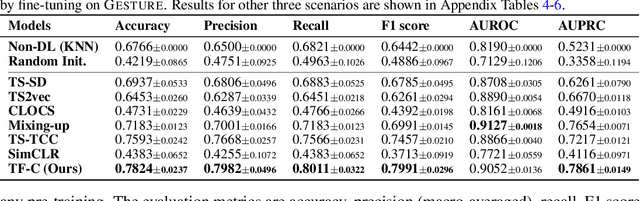
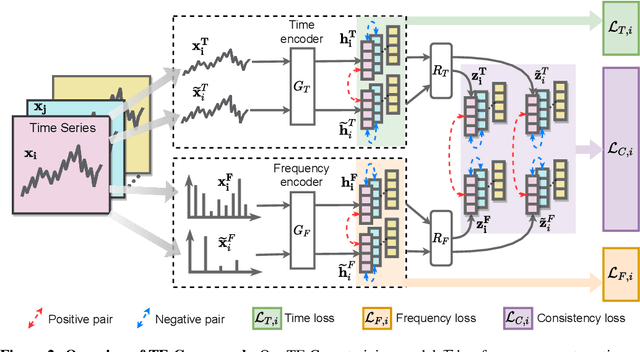
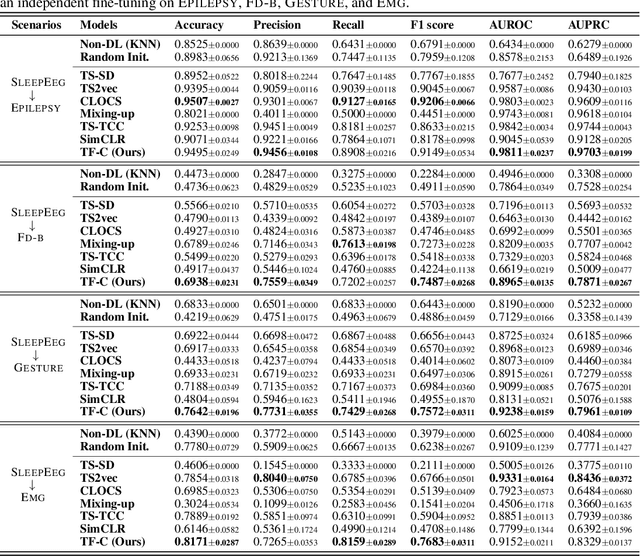
Pre-training on time series poses a unique challenge due to the potential mismatch between pre-training and target domains, such as shifts in temporal dynamics, fast-evolving trends, and long-range and short cyclic effects, which can lead to poor downstream performance. While domain adaptation methods can mitigate these shifts, most methods need examples directly from the target domain, making them suboptimal for pre-training. To address this challenge, methods need to accommodate target domains with different temporal dynamics and be capable of doing so without seeing any target examples during pre-training. Relative to other modalities, in time series, we expect that time-based and frequency-based representations of the same example are located close together in the time-frequency space. To this end, we posit that time-frequency consistency (TF-C) -- embedding a time-based neighborhood of a particular example close to its frequency-based neighborhood and back -- is desirable for pre-training. Motivated by TF-C, we define a decomposable pre-training model, where the self-supervised signal is provided by the distance between time and frequency components, each individually trained by contrastive estimation. We evaluate the new method on eight datasets, including electrodiagnostic testing, human activity recognition, mechanical fault detection, and physical status monitoring. Experiments against eight state-of-the-art methods show that TF-C outperforms baselines by 15.4% (F1 score) on average in one-to-one settings (e.g., fine-tuning an EEG-pretrained model on EMG data) and by up to 8.4% (F1 score) in challenging one-to-many settings, reflecting the breadth of scenarios that arise in real-world applications. The source code and datasets are available at https: //anonymous.4open.science/r/TFC-pretraining-6B07.
Towards more precise automatic analysis: a comprehensive survey of deep learning-based multi-organ segmentation
Mar 01, 2023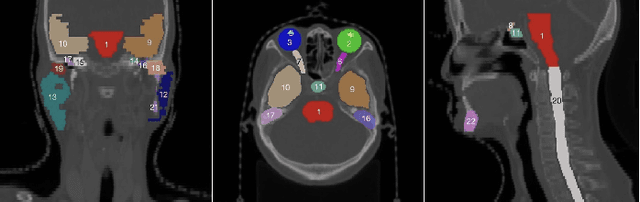
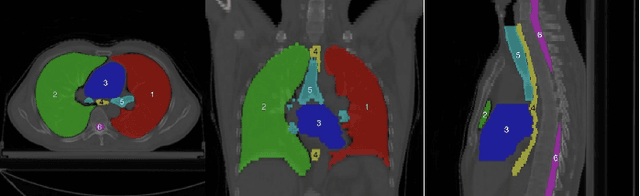
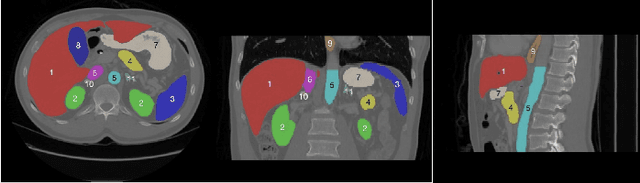
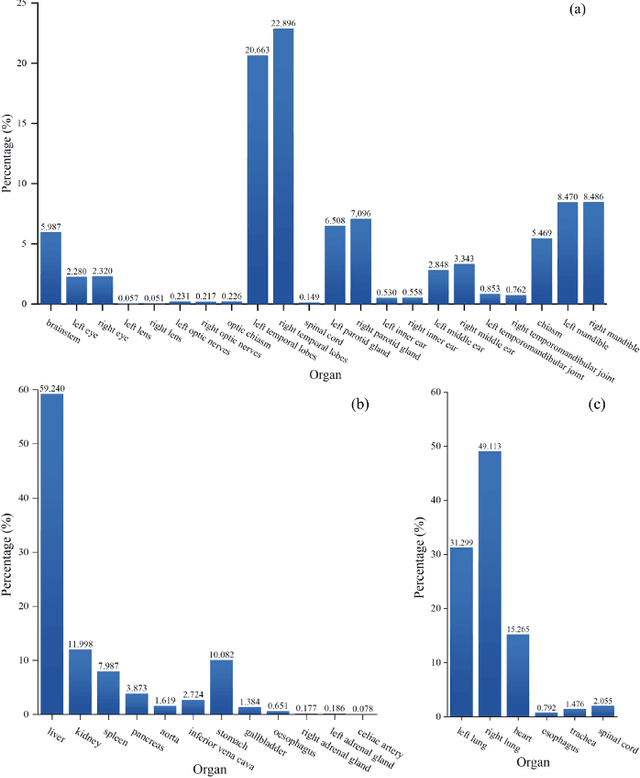
Accurate segmentation of multiple organs of the head, neck, chest, and abdomen from medical images is an essential step in computer-aided diagnosis, surgical navigation, and radiation therapy. In the past few years, with a data-driven feature extraction approach and end-to-end training, automatic deep learning-based multi-organ segmentation method has far outperformed traditional methods and become a new research topic. This review systematically summarizes the latest research in this field. For the first time, from the perspective of full and imperfect annotation, we comprehensively compile 161 studies on deep learning-based multi-organ segmentation in multiple regions such as the head and neck, chest, and abdomen, containing a total of 214 related references. The method based on full annotation summarizes the existing methods from four aspects: network architecture, network dimension, network dedicated modules, and network loss function. The method based on imperfect annotation summarizes the existing methods from two aspects: weak annotation-based methods and semi annotation-based methods. We also summarize frequently used datasets for multi-organ segmentation and discuss new challenges and new research trends in this field.
A Unified Momentum-based Paradigm of Decentralized SGD for Non-Convex Models and Heterogeneous Data
Mar 01, 2023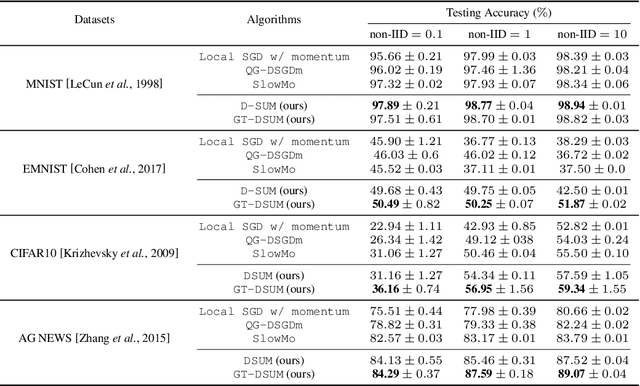
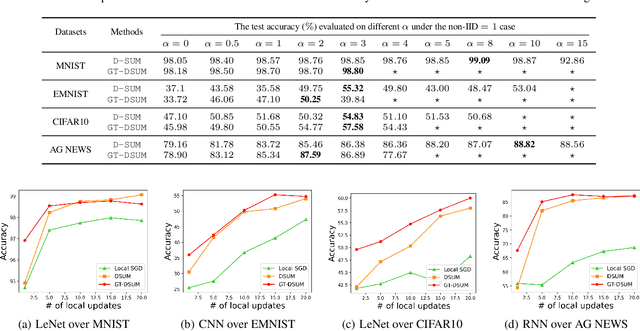
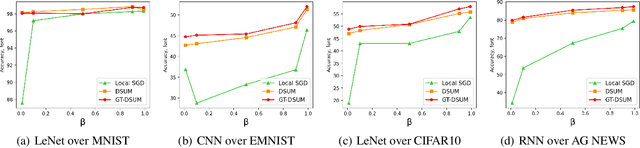
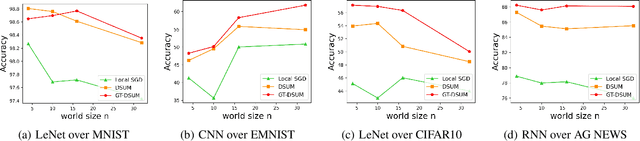
Emerging distributed applications recently boosted the development of decentralized machine learning, especially in IoT and edge computing fields. In real-world scenarios, the common problems of non-convexity and data heterogeneity result in inefficiency, performance degradation, and development stagnation. The bulk of studies concentrates on one of the issues mentioned above without having a more general framework that has been proven optimal. To this end, we propose a unified paradigm called UMP, which comprises two algorithms, D-SUM and GT-DSUM, based on the momentum technique with decentralized stochastic gradient descent(SGD). The former provides a convergence guarantee for general non-convex objectives. At the same time, the latter is extended by introducing gradient tracking, which estimates the global optimization direction to mitigate data heterogeneity(i.e., distribution drift). We can cover most momentum-based variants based on the classical heavy ball or Nesterov's acceleration with different parameters in UMP. In theory, we rigorously provide the convergence analysis of these two approaches for non-convex objectives and conduct extensive experiments, demonstrating a significant improvement in model accuracy by up to 57.6% compared to other methods in practice.
A Practical Upper Bound for the Worst-Case Attribution Deviations
Mar 01, 2023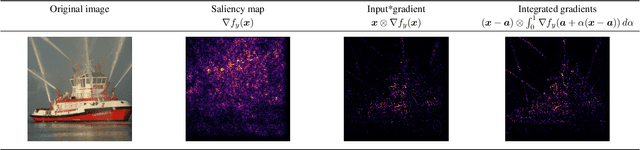
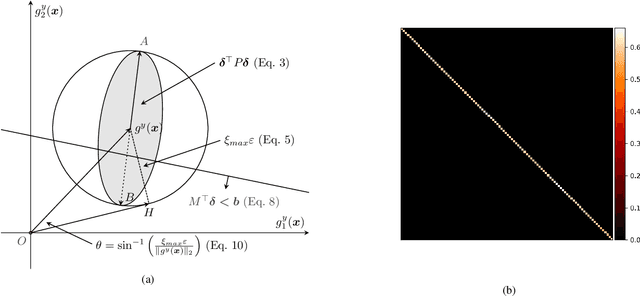

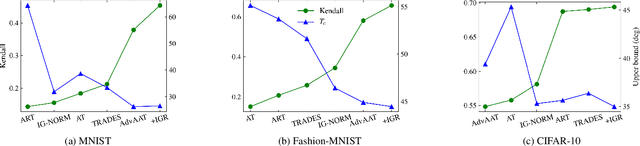
Model attribution is a critical component of deep neural networks (DNNs) for its interpretability to complex models. Recent studies bring up attention to the security of attribution methods as they are vulnerable to attribution attacks that generate similar images with dramatically different attributions. Existing works have been investigating empirically improving the robustness of DNNs against those attacks; however, none of them explicitly quantifies the actual deviations of attributions. In this work, for the first time, a constrained optimization problem is formulated to derive an upper bound that measures the largest dissimilarity of attributions after the samples are perturbed by any noises within a certain region while the classification results remain the same. Based on the formulation, different practical approaches are introduced to bound the attributions above using Euclidean distance and cosine similarity under both $\ell_2$ and $\ell_\infty$-norm perturbations constraints. The bounds developed by our theoretical study are validated on various datasets and two different types of attacks (PGD attack and IFIA attribution attack). Over 10 million attacks in the experiments indicate that the proposed upper bounds effectively quantify the robustness of models based on the worst-case attribution dissimilarities.
Robotic Perception-motion Synergy for Novel Rope Wrapping Tasks
Feb 22, 2023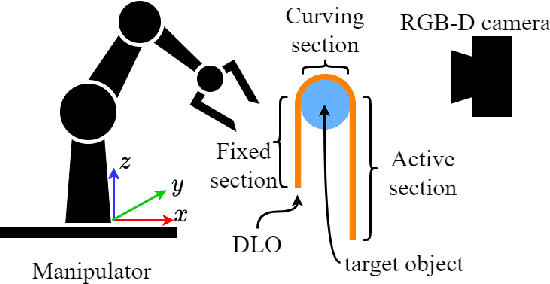


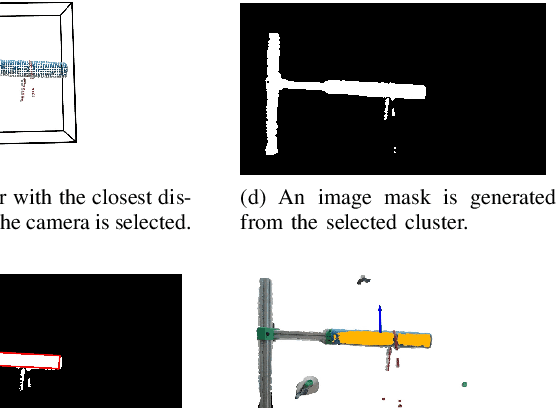
This paper introduces a novel and general method to address the problem of using a general-purpose robot manipulator with a parallel gripper to wrap a deformable linear object (DLO), called a rope, around a rigid object, called a rod, autonomously. Our method does not require prior knowledge of the physical and geometrical properties of the objects but enables the robot to use real-time RGB-D perception to determine the wrapping state and feedback control to achieve high-quality results. As such, it provides the robot manipulator with the general capabilities to handle wrapping tasks of different rods or ropes. We tested our method on 6 combinations of 3 different ropes and 2 rods. The result shows that the wrapping quality improved and converged within 5 wraps for all test cases.
Estimation of Correlation Matrices from Limited time series Data using Machine Learning
Sep 02, 2022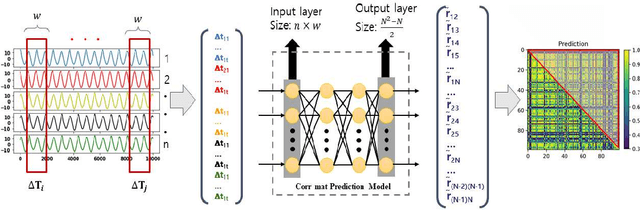

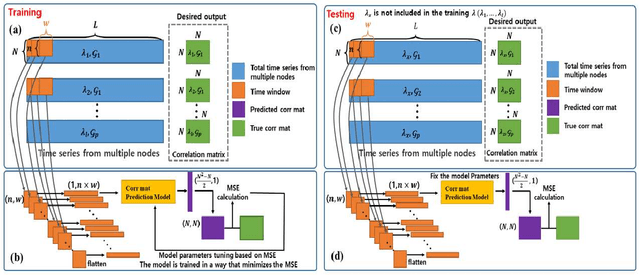
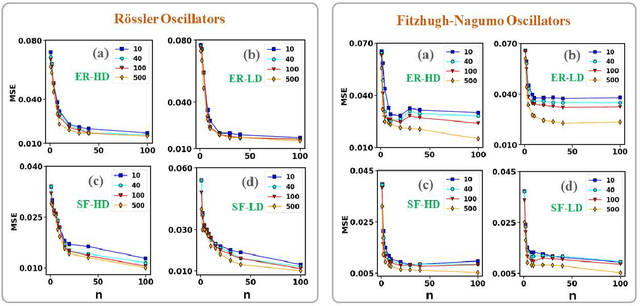
Prediction of correlation matrices from given time series data has several applications for a range of problems, such as inferring neuronal connections from spiking data, deducing causal dependencies between genes from expression data, and discovering long spatial range influences in climate variations. Traditional methods of predicting correlation matrices utilize time series data of all the nodes of the underlying networks. Here, we use a supervised machine learning technique to predict the correlation matrix of entire systems from finite time series information of a few randomly selected nodes. The accuracy of the prediction from the model confirms that only a limited time series of a subset of the entire system is enough to make good correlation matrix predictions. Furthermore, using an unsupervised learning algorithm, we provide insights into the success of the predictions from our model. Finally, we apply the machine learning model developed here to real-world data sets.
Two-Stage Constrained Actor-Critic for Short Video Recommendation
Feb 06, 2023
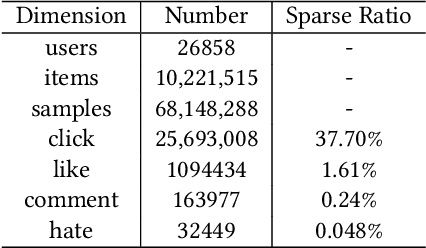
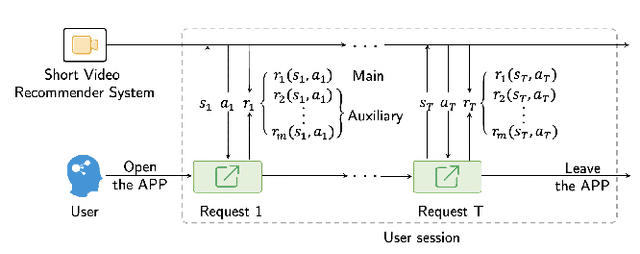
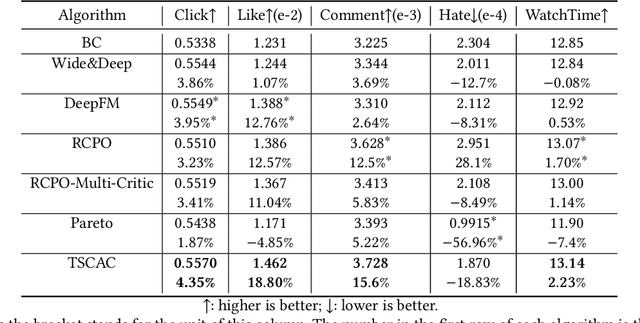
The wide popularity of short videos on social media poses new opportunities and challenges to optimize recommender systems on the video-sharing platforms. Users sequentially interact with the system and provide complex and multi-faceted responses, including watch time and various types of interactions with multiple videos. One the one hand, the platforms aims at optimizing the users' cumulative watch time (main goal) in long term, which can be effectively optimized by Reinforcement Learning. On the other hand, the platforms also needs to satisfy the constraint of accommodating the responses of multiple user interactions (auxiliary goals) such like, follow, share etc. In this paper, we formulate the problem of short video recommendation as a Constrained Markov Decision Process (CMDP). We find that traditional constrained reinforcement learning algorithms can not work well in this setting. We propose a novel two-stage constrained actor-critic method: At stage one, we learn individual policies to optimize each auxiliary signal. At stage two, we learn a policy to (i) optimize the main signal and (ii) stay close to policies learned at the first stage, which effectively guarantees the performance of this main policy on the auxiliaries. Through extensive offline evaluations, we demonstrate effectiveness of our method over alternatives in both optimizing the main goal as well as balancing the others. We further show the advantage of our method in live experiments of short video recommendations, where it significantly outperforms other baselines in terms of both watch time and interactions. Our approach has been fully launched in the production system to optimize user experiences on the platform.
* arXiv admin note: substantial text overlap with arXiv:2205.13248
A benchmark for toxic comment classification on Civil Comments dataset
Jan 26, 2023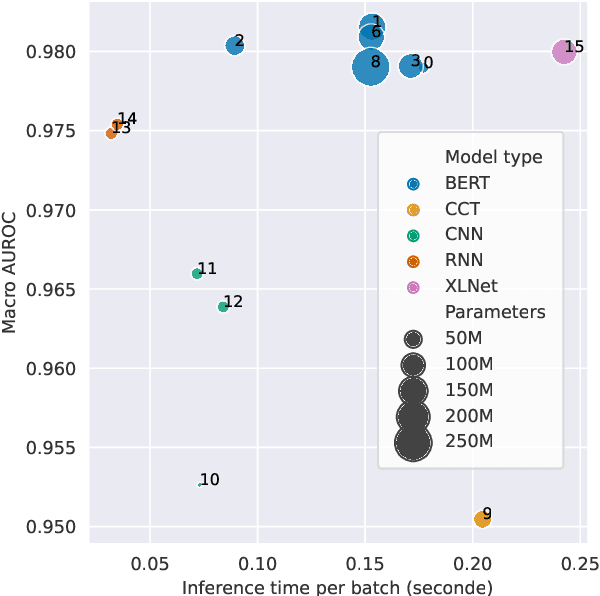
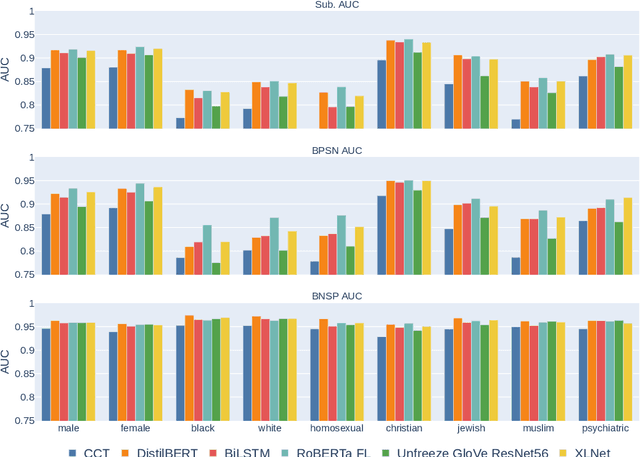
Toxic comment detection on social media has proven to be essential for content moderation. This paper compares a wide set of different models on a highly skewed multi-label hate speech dataset. We consider inference time and several metrics to measure performance and bias in our comparison. We show that all BERTs have similar performance regardless of the size, optimizations or language used to pre-train the models. RNNs are much faster at inference than any of the BERT. BiLSTM remains a good compromise between performance and inference time. RoBERTa with Focal Loss offers the best performance on biases and AUROC. However, DistilBERT combines both good AUROC and a low inference time. All models are affected by the bias of associating identities. BERT, RNN, and XLNet are less sensitive than the CNN and Compact Convolutional Transformers.
GRADE: Generating Realistic Animated Dynamic Environments for Robotics Research
Mar 08, 2023
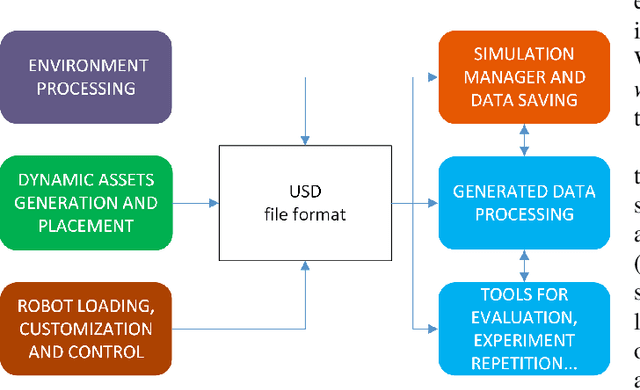
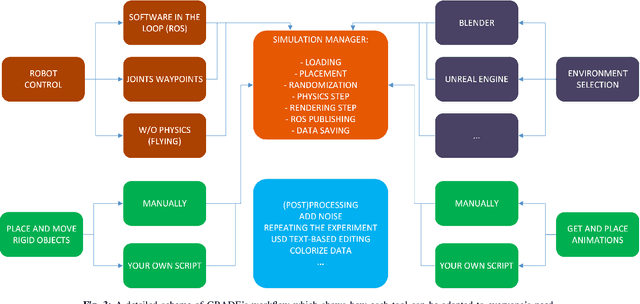

Simulation engines like Gazebo, Unity and Webots are widely adopted in robotics. However, they lack either full simulation control, ROS integration, realistic physics, or photorealism. Recently, synthetic data generation and realistic rendering advanced tasks like target tracking and human pose estimation. However, when focusing on vision applications, there is usually a lack of information like sensor measurements (e.g. IMU, LiDAR, joint state), or time continuity. On the other hand, simulations for most robotics applications are obtained in (semi)static environments, with specific sensor settings and low visual fidelity. In this work, we present a solution to these issues with a fully customizable framework for generating realistic animated dynamic environments (GRADE) for robotics research. The data produced can be post-processed, e.g. to add noise, and easily expanded with new information using the tools that we provide. To demonstrate GRADE, we use it to generate an indoor dynamic environment dataset and then compare different SLAM algorithms on the produced sequences. By doing that, we show how current research over-relies on well-known benchmarks and fails to generalize. Furthermore, our tests with YOLO and Mask R-CNN provide evidence that our data can improve training performance and generalize to real sequences. Finally, we show GRADE's flexibility by using it for indoor active SLAM, with diverse environment sources, and in a multi-robot scenario. In doing that, we employ different control, asset placement, and simulation techniques. The code, results, implementation details, and generated data are provided as open-source. The main project page is https://eliabntt.github.io/grade-rr while the accompanying video can be found at https://youtu.be/cmywCSD-9TU.