 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
MITFAS: Mutual Information based Temporal Feature Alignment and Sampling for Aerial Video Action Recognition
Mar 05, 2023
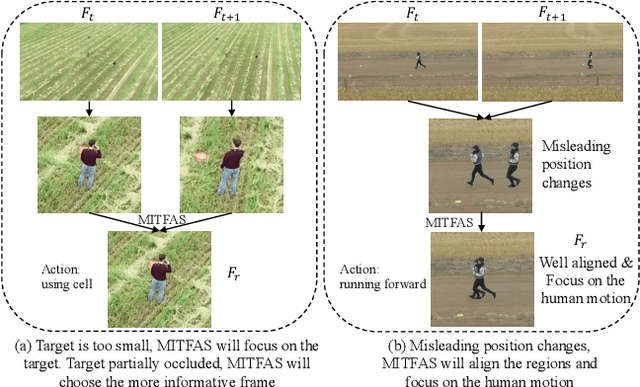
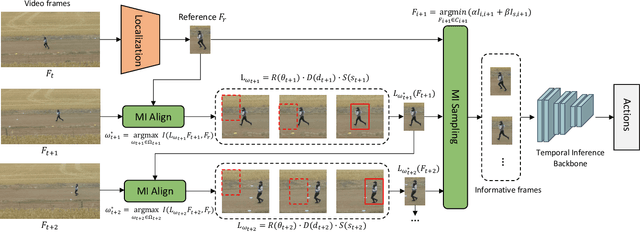
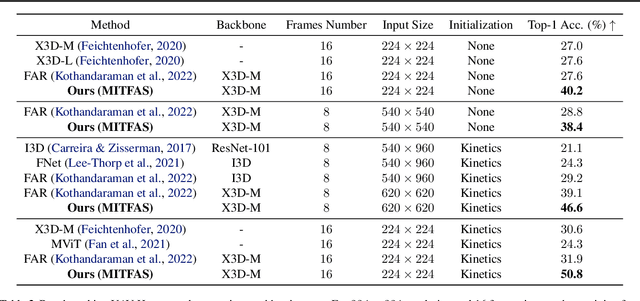
We present a novel approach for action recognition in UAV videos. Our formulation is designed to handle occlusion and viewpoint changes caused by the movement of a UAV. We use the concept of mutual information to compute and align the regions corresponding to human action or motion in the temporal domain. This enables our recognition model to learn from the key features associated with the motion. We also propose a novel frame sampling method that uses joint mutual information to acquire the most informative frame sequence in UAV videos. We have integrated our approach with X3D and evaluated the performance on multiple datasets. In practice, we achieve 18.9% improvement in Top-1 accuracy over current state-of-the-art methods on UAV-Human(Li et al., 2021), 7.3% improvement on Drone-Action(Perera et al., 2019), and 7.16% improvement on NEC Drones(Choi et al., 2020). We will release the code at the time of publication
Best Arm Identification for Stochastic Rising Bandits
Feb 15, 2023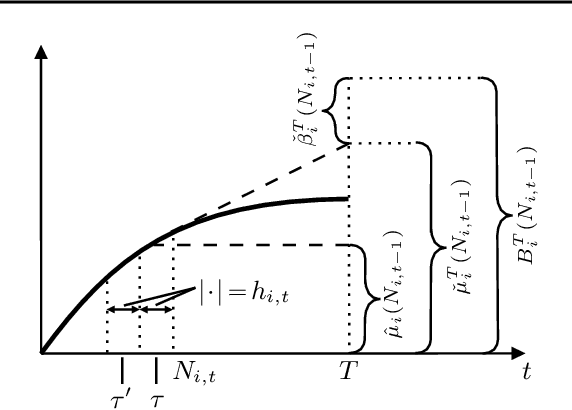
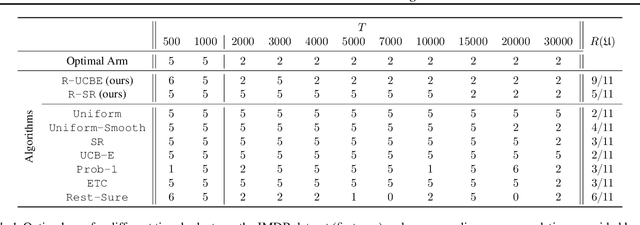
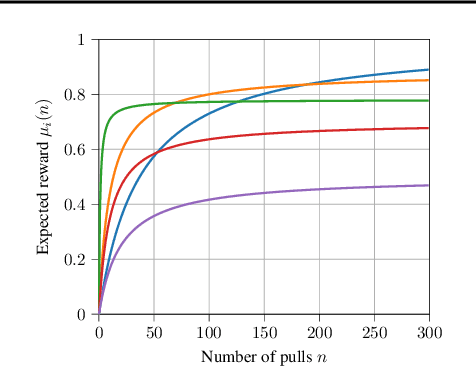
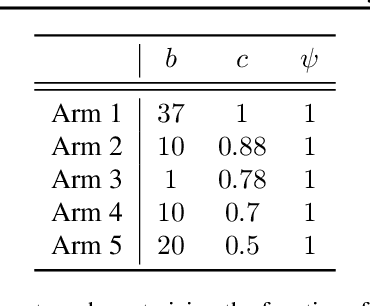
Stochastic Rising Bandits is a setting in which the values of the expected rewards of the available options increase every time they are selected. This framework models a wide range of scenarios in which the available options are learning entities whose performance improves over time. In this paper, we focus on the Best Arm Identification (BAI) problem for the stochastic rested rising bandits. In this scenario, we are asked, given a fixed budget of rounds, to provide a recommendation about the best option at the end of the selection process. We propose two algorithms to tackle the above-mentioned setting, namely R-UCBE, which resorts to a UCB-like approach, and R-SR, which employs a successive reject procedure. We show that they provide guarantees on the probability of properly identifying the optimal option at the end of the learning process. Finally, we numerically validate the proposed algorithms in synthetic and realistic environments and compare them with the currently available BAI strategies.
That Escalated Quickly: An ML Framework for Alert Prioritization
Feb 15, 2023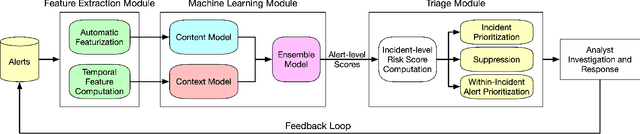
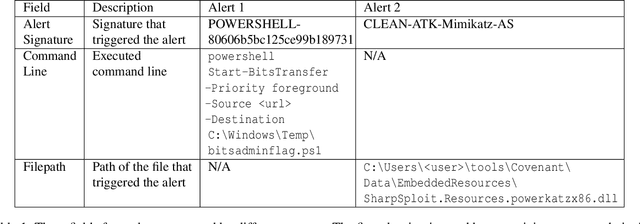

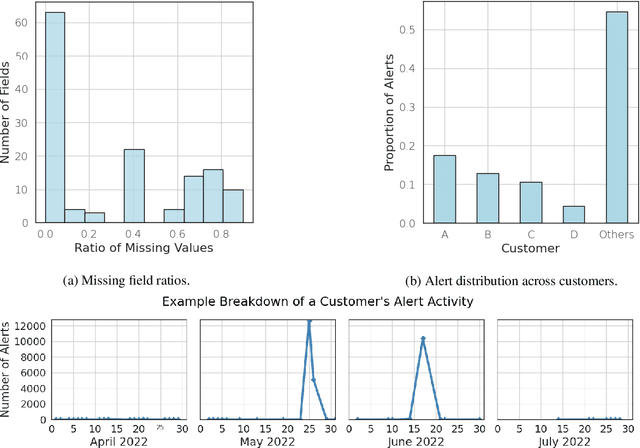
In place of in-house solutions, organizations are increasingly moving towards managed services for cyber defense. Security Operations Centers are specialized cybersecurity units responsible for the defense of an organization, but the large-scale centralization of threat detection is causing SOCs to endure an overwhelming amount of false positive alerts -- a phenomenon known as alert fatigue. Large collections of imprecise sensors, an inability to adapt to known false positives, evolution of the threat landscape, and inefficient use of analyst time all contribute to the alert fatigue problem. To combat these issues, we present That Escalated Quickly (TEQ), a machine learning framework that reduces alert fatigue with minimal changes to SOC workflows by predicting alert-level and incident-level actionability. On real-world data, the system is able to reduce the time it takes to respond to actionable incidents by $22.9\%$, suppress $54\%$ of false positives with a $95.1\%$ detection rate, and reduce the number of alerts an analyst needs to investigate within singular incidents by $14\%$.
Towards Unsupervised Learning based Denoising of Cyber Physical System Data to Mitigate Security Concerns
Mar 13, 2023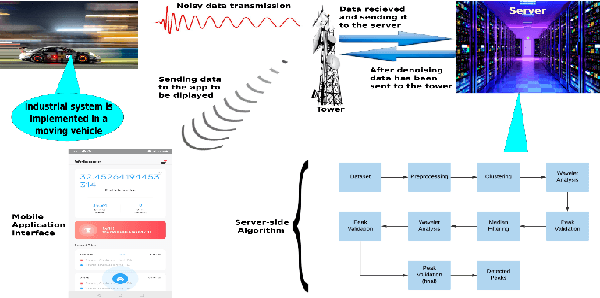
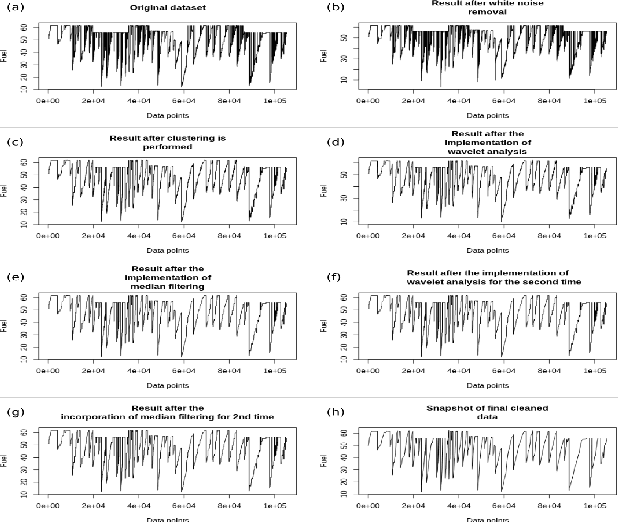
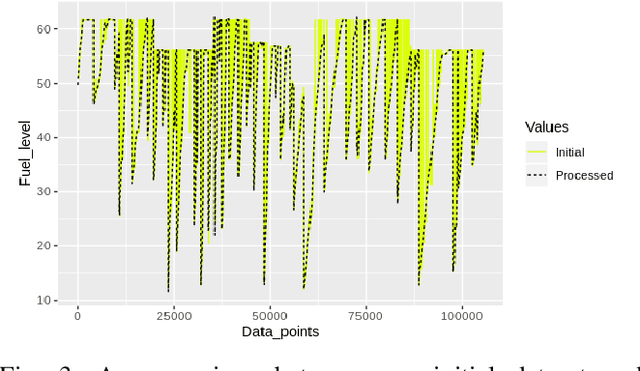
A dataset, collected under an industrial setting, often contains a significant portion of noises. In many cases, using trivial filters is not enough to retrieve useful information i.e., accurate value without the noise. One such data is time-series sensor readings collected from moving vehicles containing fuel information. Due to the noisy dynamics and mobile environment, the sensor readings can be very noisy. Denoising such a dataset is a prerequisite for any useful application and security issues. Security is a primitive concern in present vehicular schemes. The server side for retrieving the fuel information can be easily hacked. Providing the accurate and noise free fuel information via vehicular networks become crutial. Therefore, it has led us to develop a system that can remove noise and keep the original value. The system is also helpful for vehicle industry, fuel station, and power-plant station that require fuel. In this work, we have only considered the value of fuel level, and we have come up with a unique solution to filter out the noise of high magnitudes using several algorithms such as interpolation, extrapolation, spectral clustering, agglomerative clustering, wavelet analysis, and median filtering. We have also employed peak detection and peak validation algorithms to detect fuel refill and consumption in charge-discharge cycles. We have used the R-squared metric to evaluate our model, and it is 98 percent In most cases, the difference between detected value and real value remains within the range of 1L.
On the Regret of Online Edge Service Hosting
Mar 13, 2023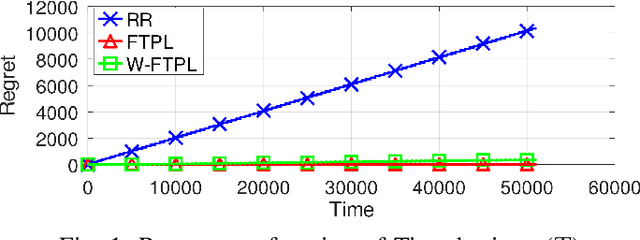
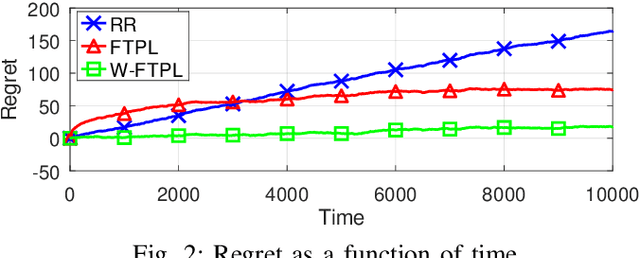
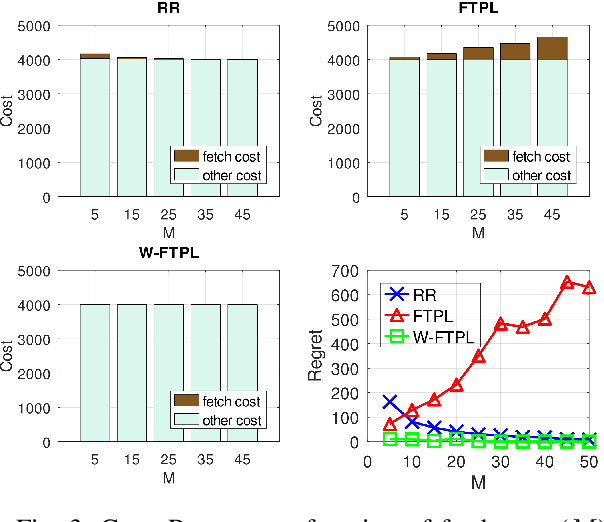
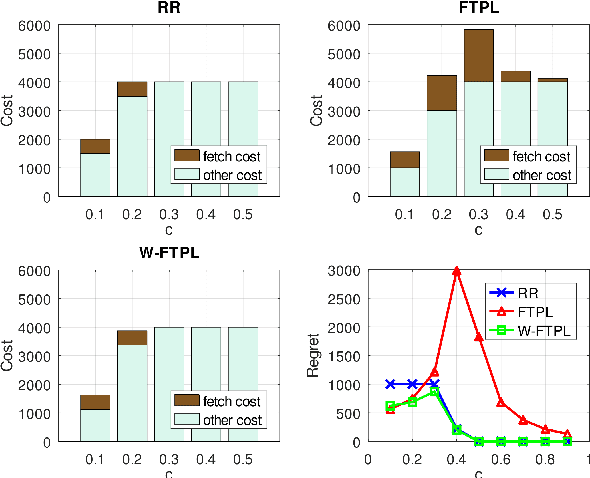
We consider the problem of service hosting where a service provider can dynamically rent edge resources via short term contracts to ensure better quality of service to its customers. The service can also be partially hosted at the edge, in which case, customers' requests can be partially served at the edge. The total cost incurred by the system is modeled as a combination of the rent cost, the service cost incurred due to latency in serving customers, and the fetch cost incurred as a result of the bandwidth used to fetch the code/databases of the service from the cloud servers to host the service at the edge. In this paper, we compare multiple hosting policies with regret as a metric, defined as the difference in the cost incurred by the policy and the optimal policy over some time horizon $T$. In particular we consider the Retro Renting (RR) and Follow The Perturbed Leader (FTPL) policies proposed in the literature and provide performance guarantees on the regret of these policies. We show that under i.i.d stochastic arrivals, RR policy has linear regret while FTPL policy has constant regret. Next, we propose a variant of FTPL, namely Wait then FTPL (W-FTPL), which also has constant regret while demonstrating much better dependence on the fetch cost. We also show that under adversarial arrivals, RR policy has linear regret while both FTPL and W-FTPL have regret $\mathrm{O}(\sqrt{T})$ which is order-optimal.
DCSF: Deep Convolutional Set Functions for Classification of Asynchronous Time Series
Aug 24, 2022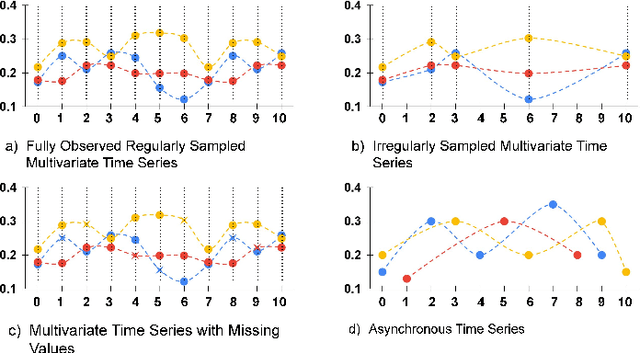
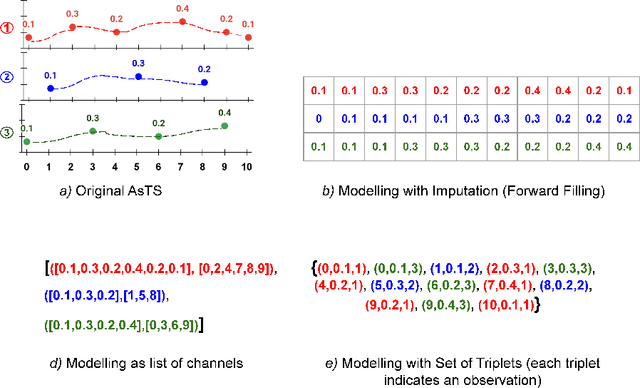

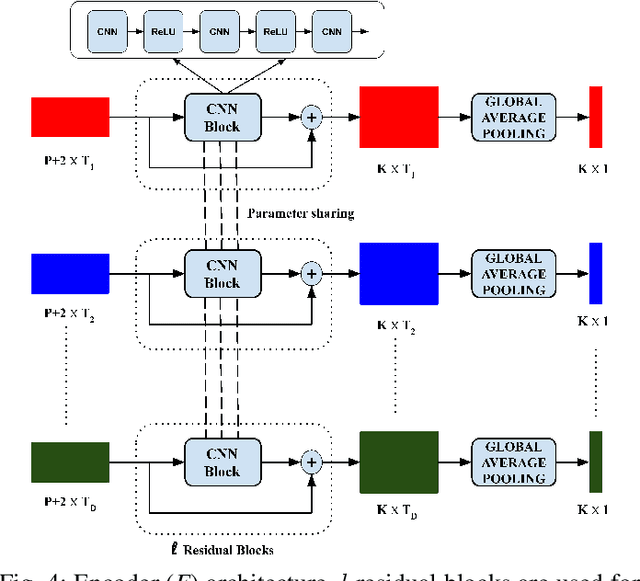
Asynchronous Time Series is a multivariate time series where all the channels are observed asynchronously-independently, making the time series extremely sparse when aligning them. We often observe this effect in applications with complex observation processes, such as health care, climate science, and astronomy, to name a few. Because of the asynchronous nature, they pose a significant challenge to deep learning architectures, which presume that the time series presented to them are regularly sampled, fully observed, and aligned with respect to time. This paper proposes a novel framework, that we call Deep Convolutional Set Functions (DCSF), which is highly scalable and memory efficient, for the asynchronous time series classification task. With the recent advancements in deep set learning architectures, we introduce a model that is invariant to the order in which time series' channels are presented to it. We explore convolutional neural networks, which are well researched for the closely related problem-classification of regularly sampled and fully observed time series, for encoding the set elements. We evaluate DCSF for AsTS classification, and online (per time point) AsTS classification. Our extensive experiments on multiple real-world and synthetic datasets verify that the suggested model performs substantially better than a range of state-of-the-art models in terms of accuracy and run time.
Q-Diffusion: Quantizing Diffusion Models
Feb 10, 2023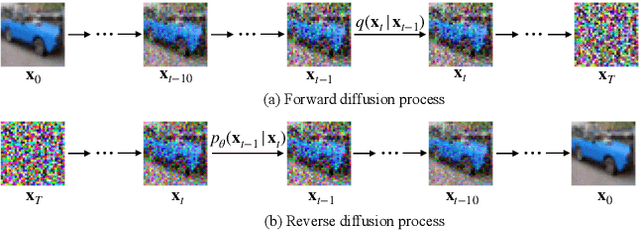

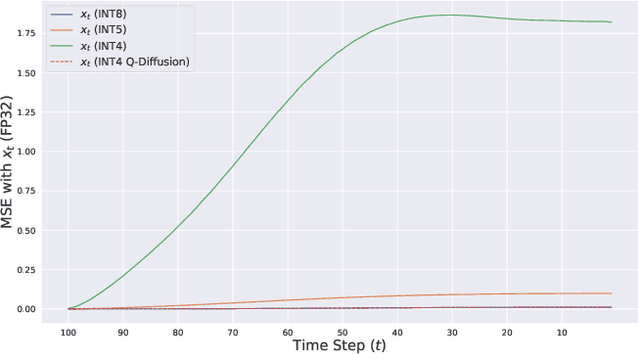
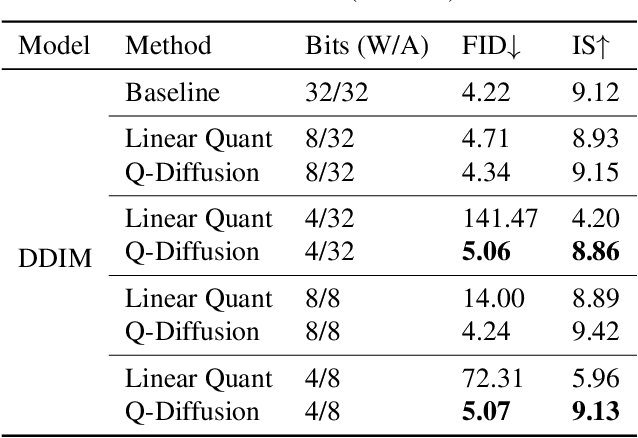
Diffusion models have achieved great success in synthesizing diverse and high-fidelity images. However, sampling speed and memory constraints remain a major barrier to the practical adoption of diffusion models, since the generation process for these models can be slow due to the need for iterative noise estimation using compute-intensive neural networks. We propose to tackle this problem by compressing the noise estimation network to accelerate the generation process through post-training quantization (PTQ). While existing PTQ approaches have not been able to effectively deal with the changing output distributions of noise estimation networks in diffusion models over multiple time steps, we are able to formulate a PTQ method that is specifically designed to handle the unique multi-timestep structure of diffusion models with a data calibration scheme using data sampled from different time steps. Experimental results show that our proposed method is able to directly quantize full-precision diffusion models into 8-bit or 4-bit models while maintaining comparable performance in a training-free manner, achieving a FID change of at most 1.88. Our approach can also be applied to text-guided image generation, and for the first time we can run stable diffusion in 4-bit weights without losing much perceptual quality, as shown in Figure 5 and Figure 9.
VCSE: Time-Domain Visual-Contextual Speaker Extraction Network
Oct 09, 2022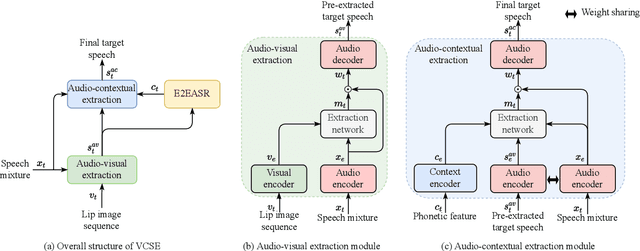
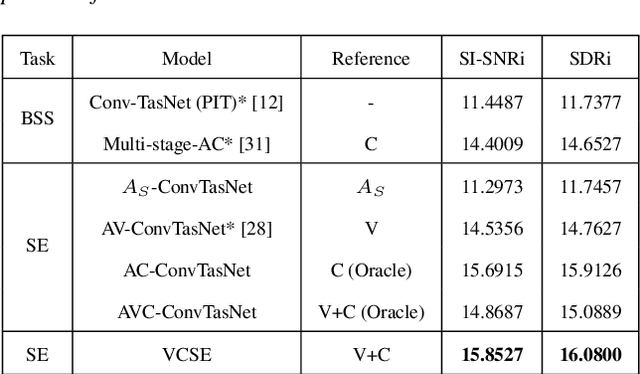
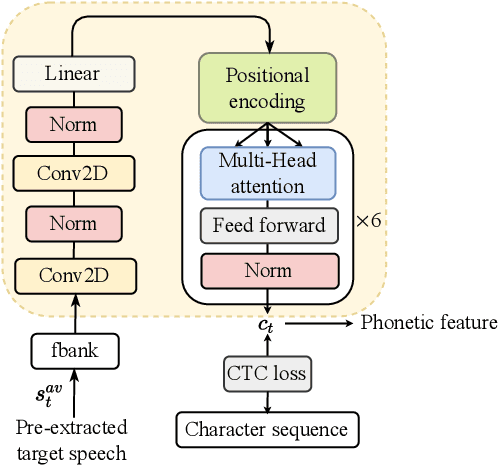
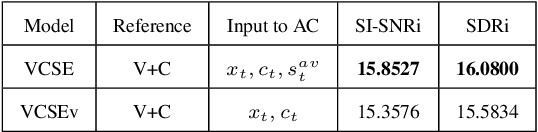
Speaker extraction seeks to extract the target speech in a multi-talker scenario given an auxiliary reference. Such reference can be auditory, i.e., a pre-recorded speech, visual, i.e., lip movements, or contextual, i.e., phonetic sequence. References in different modalities provide distinct and complementary information that could be fused to form top-down attention on the target speaker. Previous studies have introduced visual and contextual modalities in a single model. In this paper, we propose a two-stage time-domain visual-contextual speaker extraction network named VCSE, which incorporates visual and self-enrolled contextual cues stage by stage to take full advantage of every modality. In the first stage, we pre-extract a target speech with visual cues and estimate the underlying phonetic sequence. In the second stage, we refine the pre-extracted target speech with the self-enrolled contextual cues. Experimental results on the real-world Lip Reading Sentences 3 (LRS3) database demonstrate that our proposed VCSE network consistently outperforms other state-of-the-art baselines.
Resource saving taxonomy classification with k-mer distributions and machine learning
Mar 10, 2023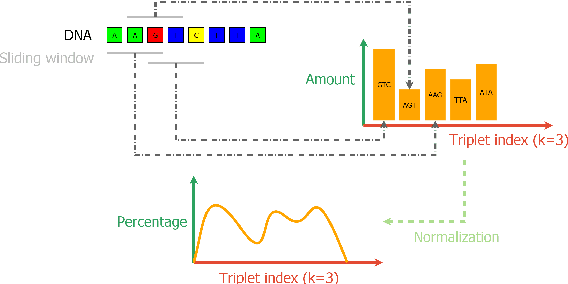
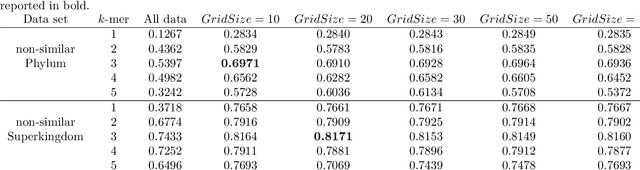
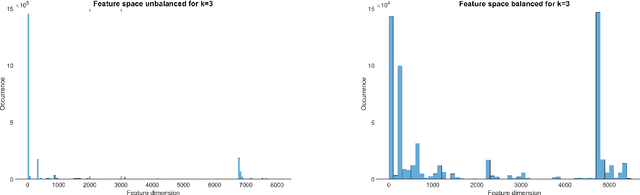

Modern high throughput sequencing technologies like metagenomic sequencing generate millions of sequences which have to be classified based on their taxonomic rank. Modern approaches either apply local alignment and comparison to existing data sets like MMseqs2 or use deep neural networks as it is done in DeepMicrobes and BERTax. Alignment-based approaches are costly in terms of runtime, especially since databases get larger and larger. For the deep learning-based approaches, specialized hardware is necessary for a computation, which consumes large amounts of energy. In this paper, we propose to use $k$-mer distributions obtained from DNA as features to classify its taxonomic origin using machine learning approaches like the subspace $k$-nearest neighbors algorithm, neural networks or bagged decision trees. In addition, we propose a feature space data set balancing approach, which allows reducing the data set for training and improves the performance of the classifiers. By comparing performance, time, and memory consumption of our approach to those of state-of-the-art algorithms (BERTax and MMseqs2) using several datasets, we show that our approach improves the classification on the genus level and achieves comparable results for the superkingdom and phylum level. Link: https://es-cloud.cs.uni-tuebingen.de/d/8e2ab8c3fdd444e1a135/?p=%2FTaxonomyClassification&mode=list
Towards MoE Deployment: Mitigating Inefficiencies in Mixture-of-Expert (MoE) Inference
Mar 10, 2023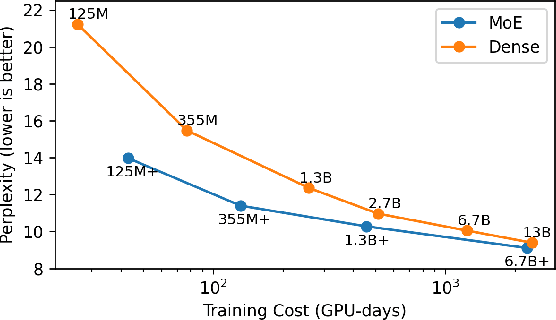
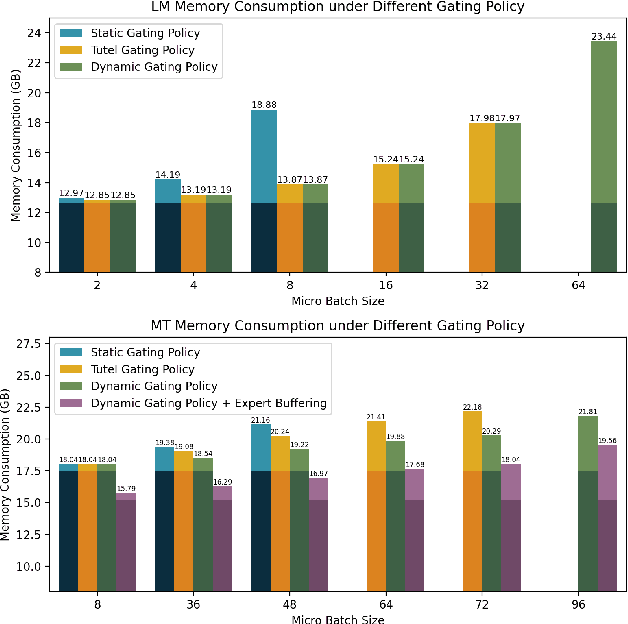
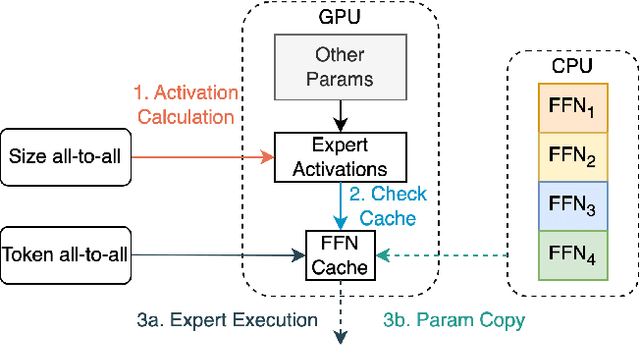
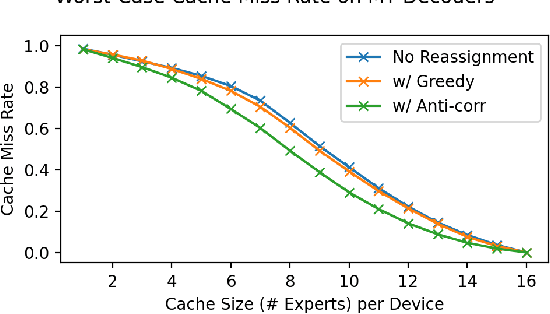
Mixture-of-Experts (MoE) models have recently gained steam in achieving the state-of-the-art performance in a wide range of tasks in computer vision and natural language processing. They effectively expand the model capacity while incurring a minimal increase in computation cost during training. However, deploying such models for inference is difficult due to their large model size and complex communication pattern. In this work, we provide a characterization of two MoE workloads, namely Language Modeling (LM) and Machine Translation (MT) and identify their sources of inefficiencies at deployment. We propose three optimization techniques to mitigate sources of inefficiencies, namely (1) Dynamic gating, (2) Expert Buffering, and (3) Expert load balancing. We show that dynamic gating improves execution time by 1.25-4$\times$ for LM, 2-5$\times$ for MT Encoder and 1.09-1.5$\times$ for MT Decoder. It also reduces memory usage by up to 1.36$\times$ for LM and up to 1.1$\times$ for MT. We further propose Expert Buffering, a new caching mechanism that only keeps hot, active experts in GPU memory while buffering the rest in CPU memory. This reduces static memory allocation by 1.47$\times$. We finally propose a load balancing methodology that provides additional robustness to the workload. The code will be open-sourced upon acceptance.