 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Rollover Prevention for Mobile Robots with Control Barrier Functions: Differentiator-Based Adaptation and Projection-to-State Safety
Mar 13, 2024
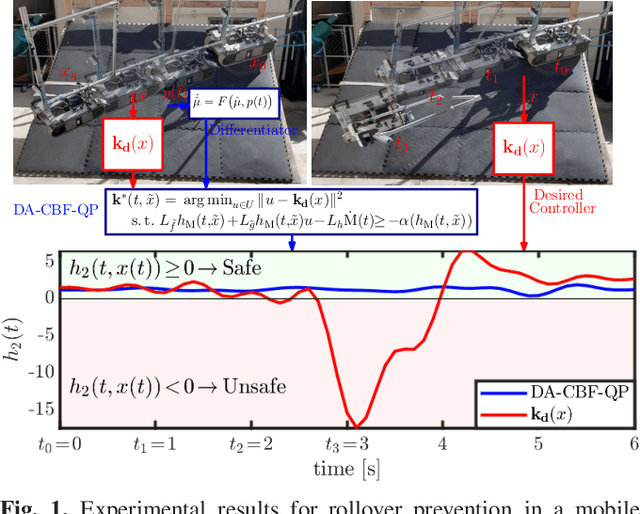
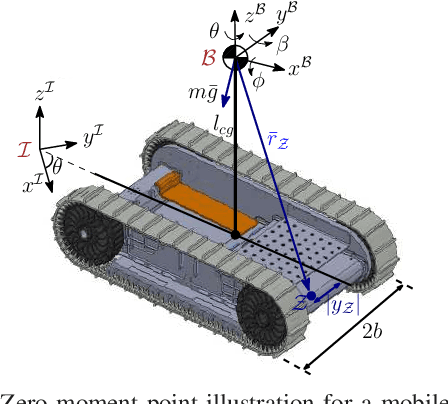
This paper develops rollover prevention guarantees for mobile robots using control barrier function (CBF) theory, and demonstrates these formal results experimentally. To this end, we consider a safety measure based on the zero moment point to provide conditions on the control input through the lens of CBFs. However, these conditions depend on time-varying and noisy parameters. To address this, we present a differentiator-based safety-critical controller that estimates these parameters and pairs Input-to-State Stable (ISS) differentiator dynamics with CBFs to achieve rigorous guarantees of safety. Additionally, to ensure safety in the presence of disturbance, we utilize a time-varying extension of Projection-to-State Safety (PSSf). The effectiveness of the proposed method is demonstrated through experiments on a tracked robot with a rollover potential on steep slopes.
SplattingAvatar: Realistic Real-Time Human Avatars with Mesh-Embedded Gaussian Splatting
Mar 08, 2024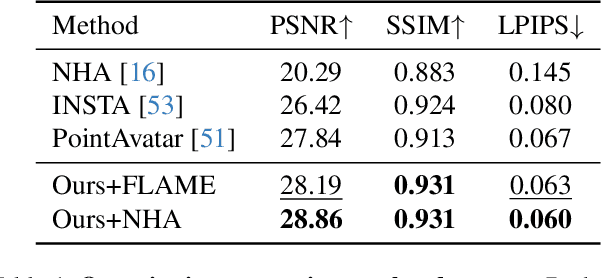
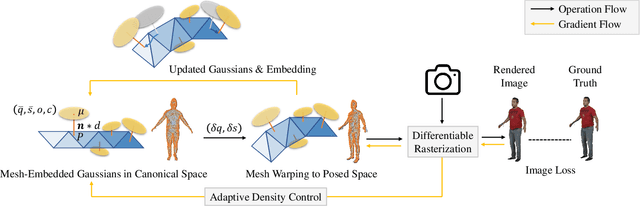


We present SplattingAvatar, a hybrid 3D representation of photorealistic human avatars with Gaussian Splatting embedded on a triangle mesh, which renders over 300 FPS on a modern GPU and 30 FPS on a mobile device. We disentangle the motion and appearance of a virtual human with explicit mesh geometry and implicit appearance modeling with Gaussian Splatting. The Gaussians are defined by barycentric coordinates and displacement on a triangle mesh as Phong surfaces. We extend lifted optimization to simultaneously optimize the parameters of the Gaussians while walking on the triangle mesh. SplattingAvatar is a hybrid representation of virtual humans where the mesh represents low-frequency motion and surface deformation, while the Gaussians take over the high-frequency geometry and detailed appearance. Unlike existing deformation methods that rely on an MLP-based linear blend skinning (LBS) field for motion, we control the rotation and translation of the Gaussians directly by mesh, which empowers its compatibility with various animation techniques, e.g., skeletal animation, blend shapes, and mesh editing. Trainable from monocular videos for both full-body and head avatars, SplattingAvatar shows state-of-the-art rendering quality across multiple datasets.
Flow-Based Visual Stream Compression for Event Cameras
Mar 12, 2024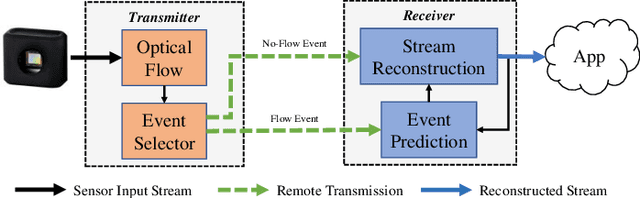
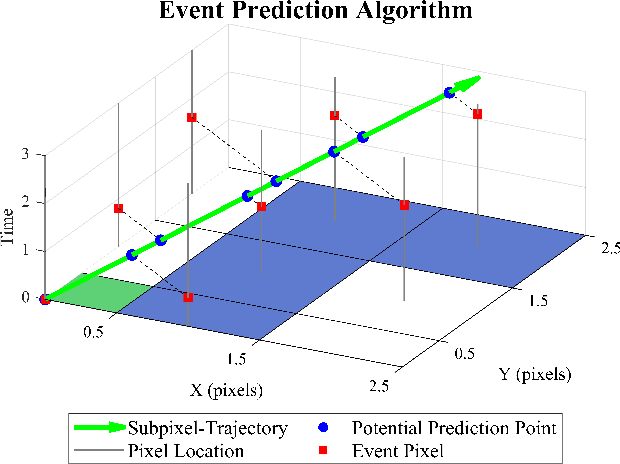
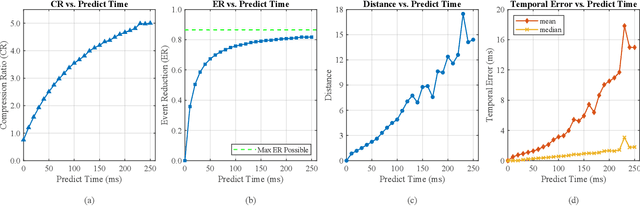
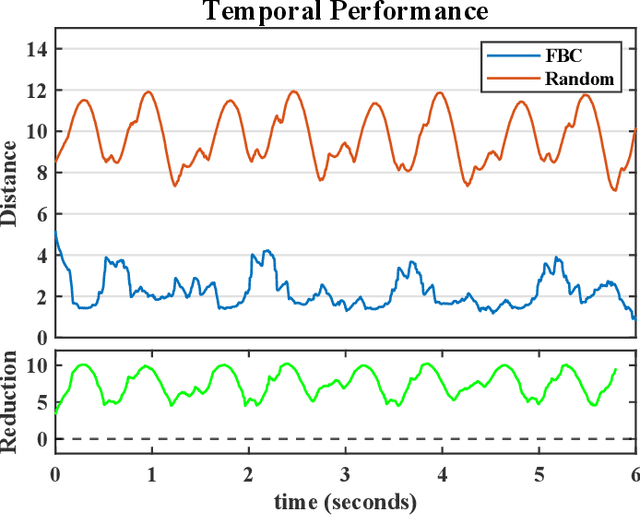
As the use of neuromorphic, event-based vision sensors expands, the need for compression of their output streams has increased. While their operational principle ensures event streams are spatially sparse, the high temporal resolution of the sensors can result in high data rates from the sensor depending on scene dynamics. For systems operating in communication-bandwidth-constrained and power-constrained environments, it is essential to compress these streams before transmitting them to a remote receiver. Therefore, we introduce a flow-based method for the real-time asynchronous compression of event streams as they are generated. This method leverages real-time optical flow estimates to predict future events without needing to transmit them, therefore, drastically reducing the amount of data transmitted. The flow-based compression introduced is evaluated using a variety of methods including spatiotemporal distance between event streams. The introduced method itself is shown to achieve an average compression ratio of 2.81 on a variety of event-camera datasets with the evaluation configuration used. That compression is achieved with a median temporal error of 0.48 ms and an average spatiotemporal event-stream distance of 3.07. When combined with LZMA compression for non-real-time applications, our method can achieve state-of-the-art average compression ratios ranging from 10.45 to 17.24. Additionally, we demonstrate that the proposed prediction algorithm is capable of performing real-time, low-latency event prediction.
A time-stepping deep gradient flow method for option pricing in (rough) diffusion models
Mar 01, 2024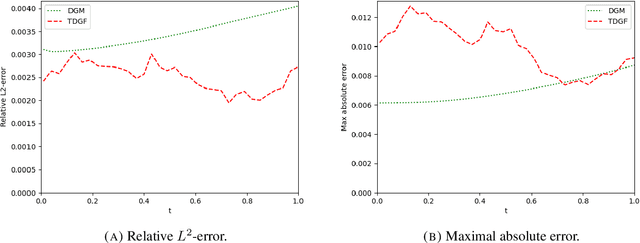

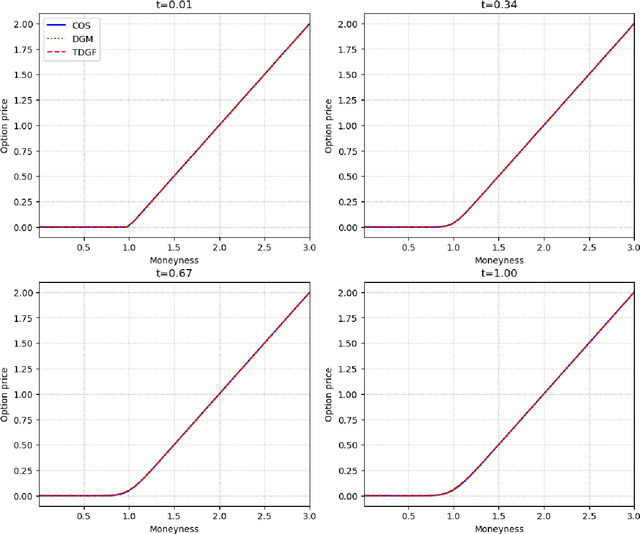
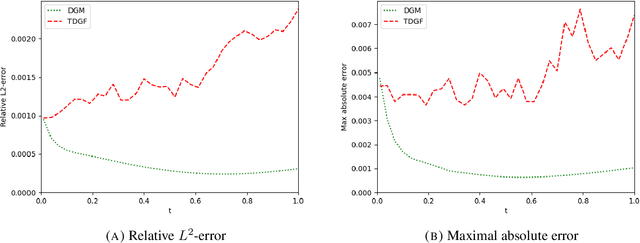
We develop a novel deep learning approach for pricing European options in diffusion models, that can efficiently handle high-dimensional problems resulting from Markovian approximations of rough volatility models. The option pricing partial differential equation is reformulated as an energy minimization problem, which is approximated in a time-stepping fashion by deep artificial neural networks. The proposed scheme respects the asymptotic behavior of option prices for large levels of moneyness, and adheres to a priori known bounds for option prices. The accuracy and efficiency of the proposed method is assessed in a series of numerical examples, with particular focus in the lifted Heston model.
EventRPG: Event Data Augmentation with Relevance Propagation Guidance
Mar 14, 2024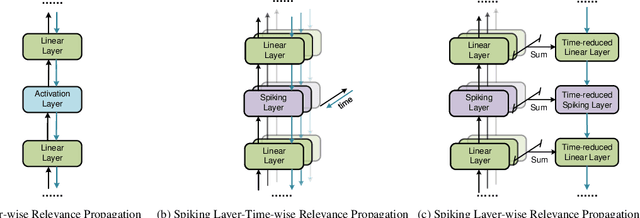
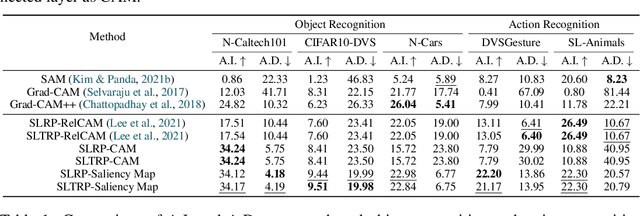
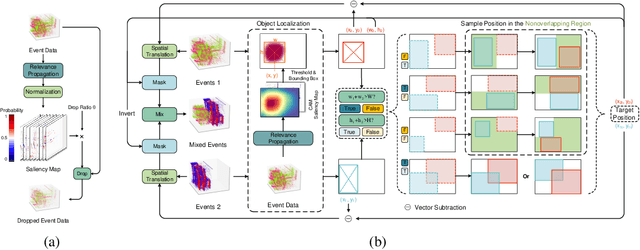

Event camera, a novel bio-inspired vision sensor, has drawn a lot of attention for its low latency, low power consumption, and high dynamic range. Currently, overfitting remains a critical problem in event-based classification tasks for Spiking Neural Network (SNN) due to its relatively weak spatial representation capability. Data augmentation is a simple but efficient method to alleviate overfitting and improve the generalization ability of neural networks, and saliency-based augmentation methods are proven to be effective in the image processing field. However, there is no approach available for extracting saliency maps from SNNs. Therefore, for the first time, we present Spiking Layer-Time-wise Relevance Propagation rule (SLTRP) and Spiking Layer-wise Relevance Propagation rule (SLRP) in order for SNN to generate stable and accurate CAMs and saliency maps. Based on this, we propose EventRPG, which leverages relevance propagation on the spiking neural network for more efficient augmentation. Our proposed method has been evaluated on several SNN structures, achieving state-of-the-art performance in object recognition tasks including N-Caltech101, CIFAR10-DVS, with accuracies of 85.62% and 85.55%, as well as action recognition task SL-Animals with an accuracy of 91.59%. Our code is available at https://github.com/myuansun/EventRPG.
Cellular-enabled Collaborative Robots Planning and Operations for Search-and-Rescue Scenarios
Mar 14, 2024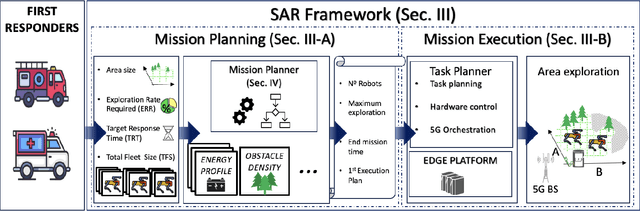
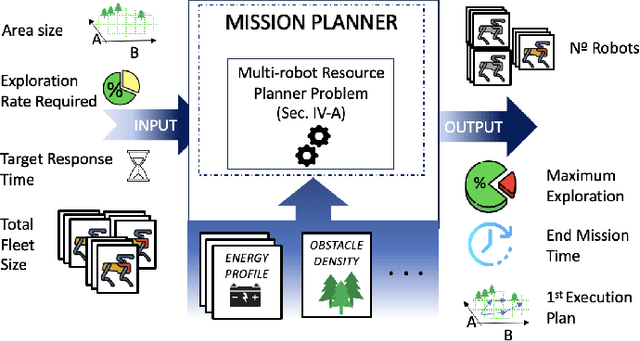
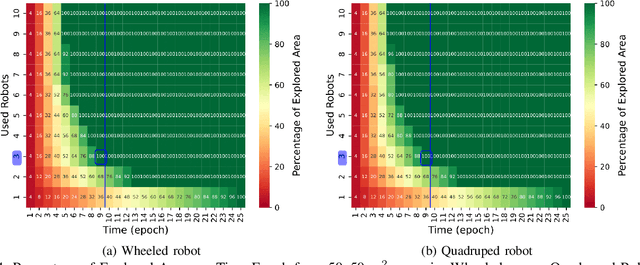
Mission-critical operations, particularly in the context of Search-and-Rescue (SAR) and emergency response situations, demand optimal performance and efficiency from every component involved to maximize the success probability of such operations. In these settings, cellular-enabled collaborative robotic systems have emerged as invaluable assets, assisting first responders in several tasks, ranging from victim localization to hazardous area exploration. However, a critical limitation in the deployment of cellular-enabled collaborative robots in SAR missions is their energy budget, primarily supplied by batteries, which directly impacts their task execution and mobility. This paper tackles this problem, and proposes a search-and-rescue framework for cellular-enabled collaborative robots use cases that, taking as input the area size to be explored, the robots fleet size, their energy profile, exploration rate required and target response time, finds the minimum number of robots able to meet the SAR mission goals and the path they should follow to explore the area. Our results, i) show that first responders can rely on a SAR cellular-enabled robotics framework when planning mission-critical operations to take informed decisions with limited resources, and, ii) illustrate the number of robots versus explored area and response time trade-off depending on the type of robot: wheeled vs quadruped.
Towards Diverse Perspective Learning with Selection over Multiple Temporal Poolings
Mar 14, 2024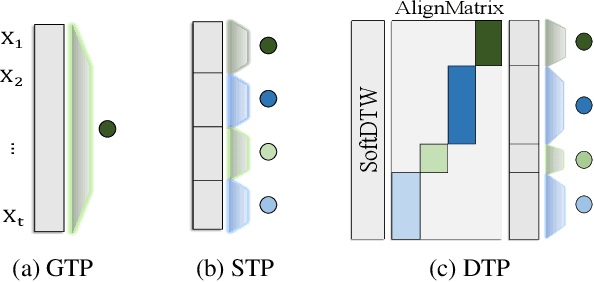
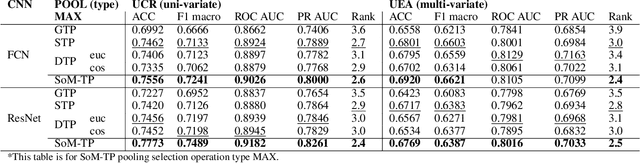
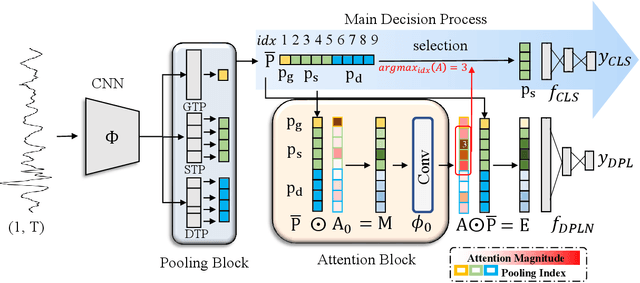
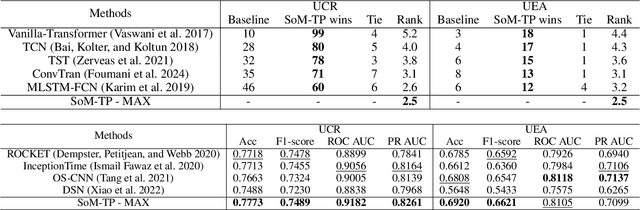
In Time Series Classification (TSC), temporal pooling methods that consider sequential information have been proposed. However, we found that each temporal pooling has a distinct mechanism, and can perform better or worse depending on time series data. We term this fixed pooling mechanism a single perspective of temporal poolings. In this paper, we propose a novel temporal pooling method with diverse perspective learning: Selection over Multiple Temporal Poolings (SoM-TP). SoM-TP dynamically selects the optimal temporal pooling among multiple methods for each data by attention. The dynamic pooling selection is motivated by the ensemble concept of Multiple Choice Learning (MCL), which selects the best among multiple outputs. The pooling selection by SoM-TP's attention enables a non-iterative pooling ensemble within a single classifier. Additionally, we define a perspective loss and Diverse Perspective Learning Network (DPLN). The loss works as a regularizer to reflect all the pooling perspectives from DPLN. Our perspective analysis using Layer-wise Relevance Propagation (LRP) reveals the limitation of a single perspective and ultimately demonstrates diverse perspective learning of SoM-TP. We also show that SoM-TP outperforms CNN models based on other temporal poolings and state-of-the-art models in TSC with extensive UCR/UEA repositories.
* 17 pages, 9 figures
Federated Learning based on Pruning and Recovery
Mar 16, 2024A novel federated learning training framework for heterogeneous environments is presented, taking into account the diverse network speeds of clients in realistic settings. This framework integrates asynchronous learning algorithms and pruning techniques, effectively addressing the inefficiencies of traditional federated learning algorithms in scenarios involving heterogeneous devices, as well as tackling the staleness issue and inadequate training of certain clients in asynchronous algorithms. Through the incremental restoration of model size during training, the framework expedites model training while preserving model accuracy. Furthermore, enhancements to the federated learning aggregation process are introduced, incorporating a buffering mechanism to enable asynchronous federated learning to operate akin to synchronous learning. Additionally, optimizations in the process of the server transmitting the global model to clients reduce communication overhead. Our experiments across various datasets demonstrate that: (i) significant reductions in training time and improvements in convergence accuracy are achieved compared to conventional asynchronous FL and HeteroFL; (ii) the advantages of our approach are more pronounced in scenarios with heterogeneous clients and non-IID client data.
Deep Reinforcement Learning-based Large-scale Robot Exploration
Mar 16, 2024
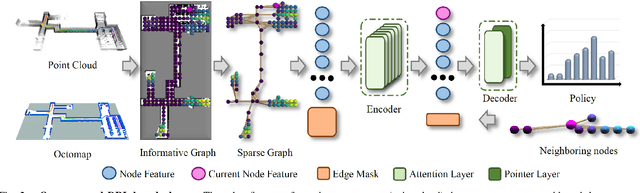
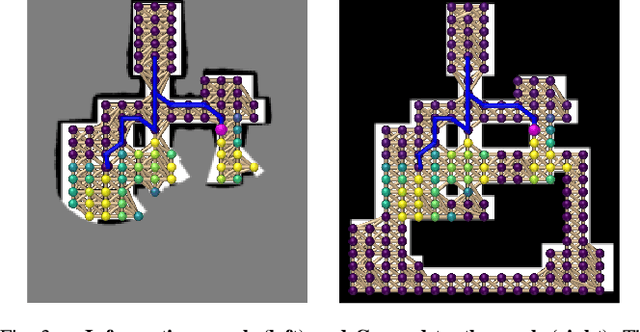
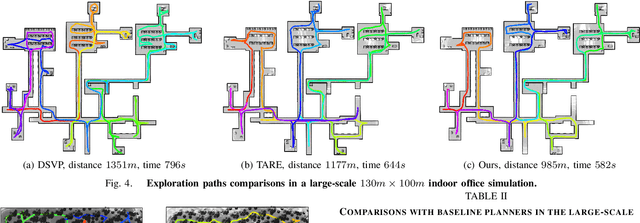
In this work, we propose a deep reinforcement learning (DRL) based reactive planner to solve large-scale Lidar-based autonomous robot exploration problems in 2D action space. Our DRL-based planner allows the agent to reactively plan its exploration path by making implicit predictions about unknown areas, based on a learned estimation of the underlying transition model of the environment. To this end, our approach relies on learned attention mechanisms for their powerful ability to capture long-term dependencies at different spatial scales to reason about the robot's entire belief over known areas. Our approach relies on ground truth information (i.e., privileged learning) to guide the environment estimation during training, as well as on a graph rarefaction algorithm, which allows models trained in small-scale environments to scale to large-scale ones. Simulation results show that our model exhibits better exploration efficiency (12% in path length, 6% in makespan) and lower planning time (60%) than the state-of-the-art planners in a 130m x 100m benchmark scenario. We also validate our learned model on hardware.
Match-Stereo-Videos: Bidirectional Alignment for Consistent Dynamic Stereo Matching
Mar 16, 2024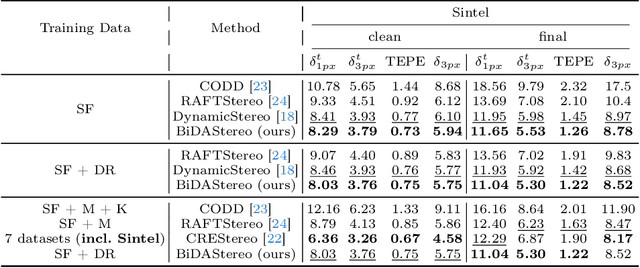
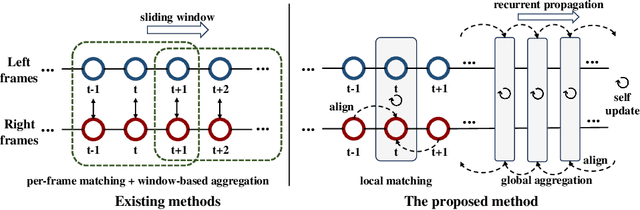
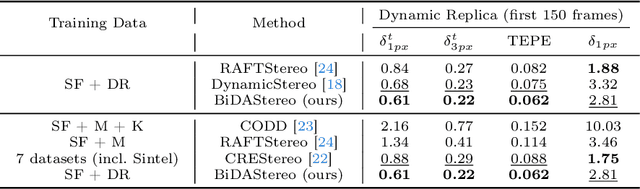
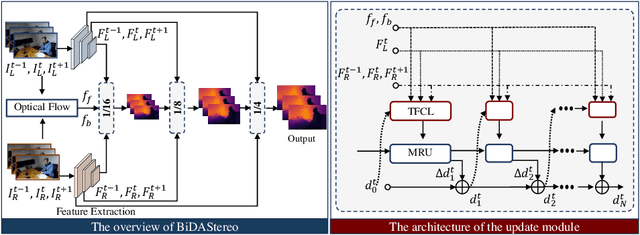
Dynamic stereo matching is the task of estimating consistent disparities from stereo videos with dynamic objects. Recent learning-based methods prioritize optimal performance on a single stereo pair, resulting in temporal inconsistencies. Existing video methods apply per-frame matching and window-based cost aggregation across the time dimension, leading to low-frequency oscillations at the scale of the window size. Towards this challenge, we develop a bidirectional alignment mechanism for adjacent frames as a fundamental operation. We further propose a novel framework, BiDAStereo, that achieves consistent dynamic stereo matching. Unlike the existing methods, we model this task as local matching and global aggregation. Locally, we consider correlation in a triple-frame manner to pool information from adjacent frames and improve the temporal consistency. Globally, to exploit the entire sequence's consistency and extract dynamic scene cues for aggregation, we develop a motion-propagation recurrent unit. Extensive experiments demonstrate the performance of our method, showcasing improvements in prediction quality and achieving state-of-the-art results on various commonly used benchmarks.