 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Impact of velocity and impact angle on football shot accuracy during fundamental trainings
Feb 07, 2023
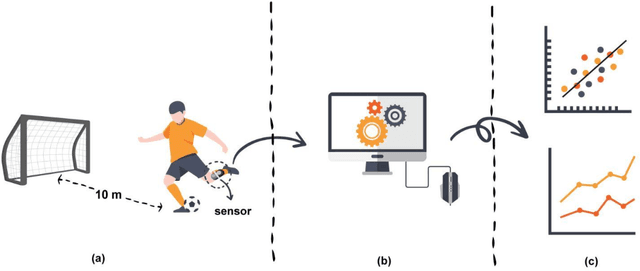

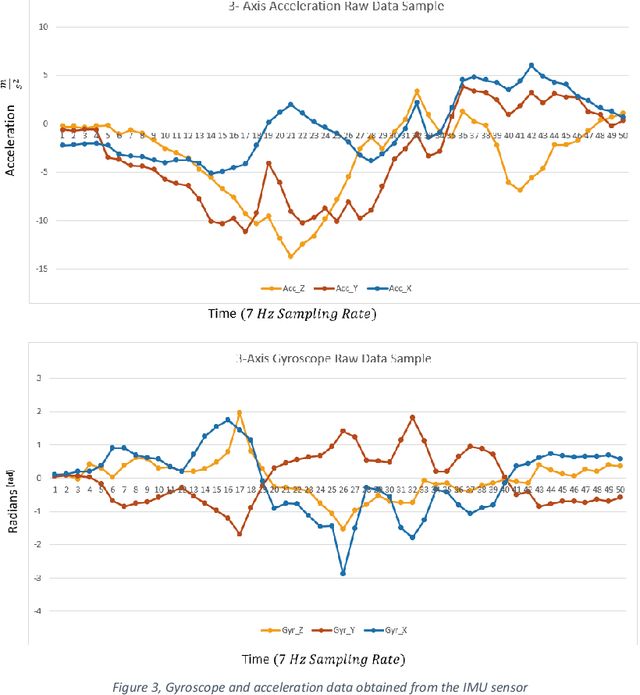
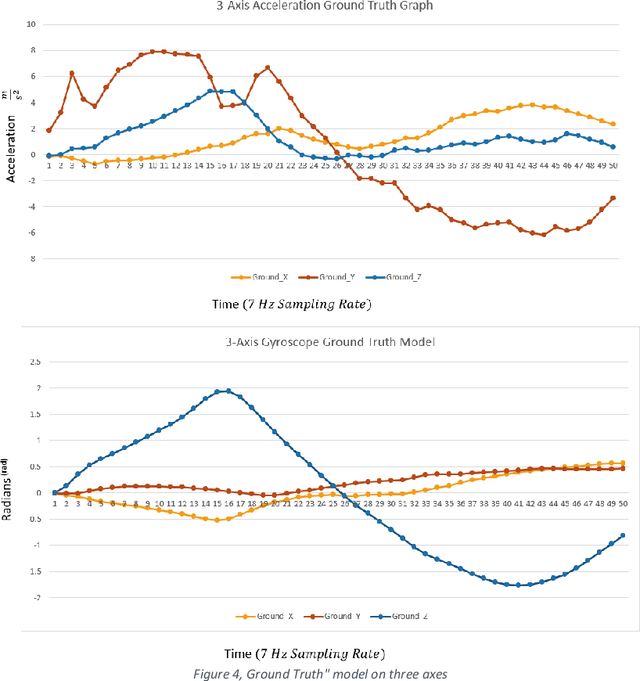
The purpose of this research is to create a machine learning-based smart coaching approach for football that can replace manual analysis with real-time feedback for trainers. In-depth analysis of football player data by humans is time-consuming, error-prone, and requires a lot of effort. This exploratory study demonstrates the feasibility of using a machine learning algorithm to enhance the effectiveness of player monitoring and training. The suggested approach uses machine learning to generate analytical insights and enable long-term monitoring of player performance. In the future, machine learning could use this technique to offer constructive criticism of football players. The system incorporates a homemade ball-throwing mechanism capable of launching the ball in a variety of directions and at varying velocities. The ball kicker is equipped with a gyroscope and accelerometer sensors for measuring velocity and acceleration. The gathered data is filtered initially, and then the data that has been processed is fed into the machine-learning algorithm. The algorithm will be trained on player performance data and will be able to provide real-time feedback to coaches on player performance and potential areas for improvement. Additionally, the system will be able to track player progress over time and provide coaches with a comprehensive view of player development. The ultimate goal is to improve player performance and reduce the workload for coaches by automating the analysis process.
Tightness of prescriptive tree-based mixed-integer optimization formulations
Feb 28, 2023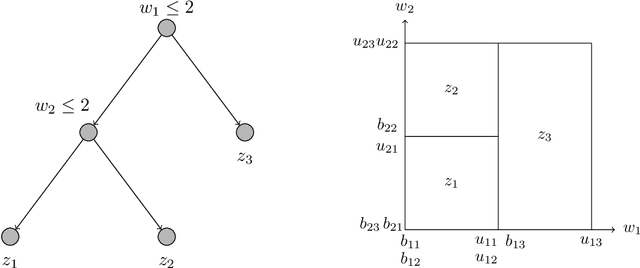
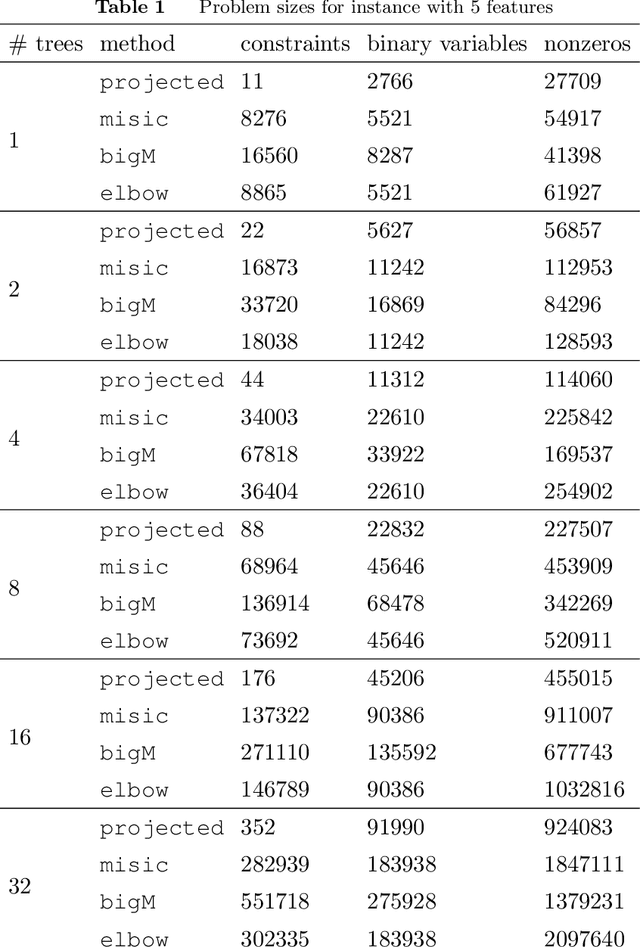
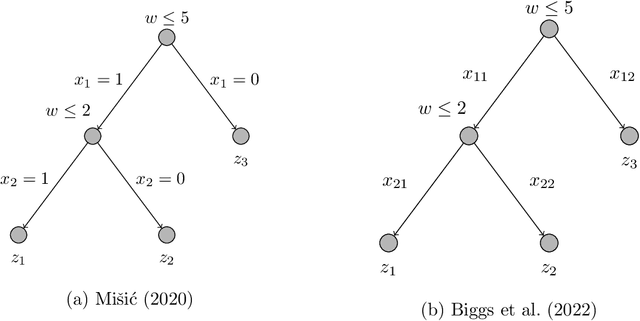
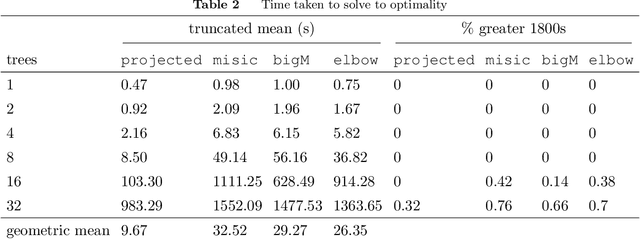
We focus on modeling the relationship between an input feature vector and the predicted outcome of a trained decision tree using mixed-integer optimization. This can be used in many practical applications where a decision tree or tree ensemble is incorporated into an optimization problem to model the predicted outcomes of a decision. We propose tighter mixed-integer optimization formulations than those previously introduced. Existing formulations can be shown to have linear relaxations that have fractional extreme points, even for the simple case of modeling a single decision tree. A formulation we propose, based on a projected union of polyhedra approach, is ideal for a single decision tree. While the formulation is generally not ideal for tree ensembles or if additional constraints are added, it generally has fewer extreme points, leading to a faster time to solve, particularly if the formulation has relatively few trees. However, previous work has shown that formulations based on a binary representation of the feature vector perform well computationally and hence are attractive for use in practical applications. We present multiple approaches to tighten existing formulations with binary vectors, and show that fractional extreme points are removed when there are multiple splits on the same feature. At an extreme, we prove that this results in ideal formulations for tree ensembles modeling a one-dimensional feature vector. Building on this result, we also show via numerical simulations that these additional constraints result in significantly tighter linear relaxations when the feature vector is low dimensional. We also present instances where the time to solve to optimality is significantly improved using these formulations.
JANA: Jointly Amortized Neural Approximation of Complex Bayesian Models
Feb 17, 2023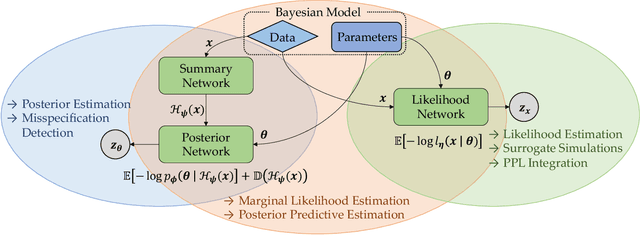
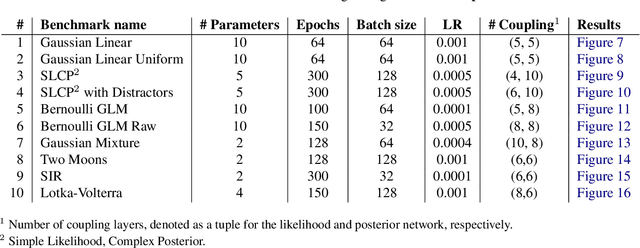
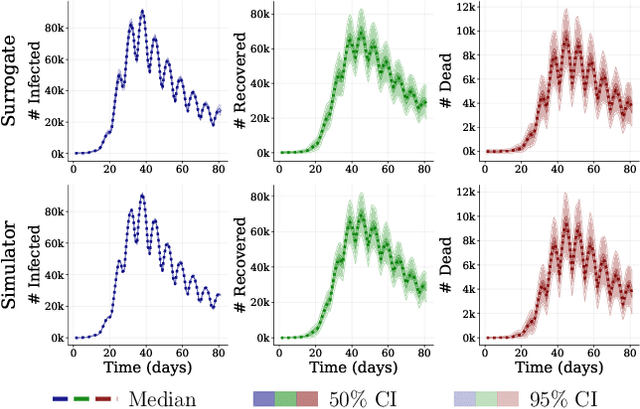
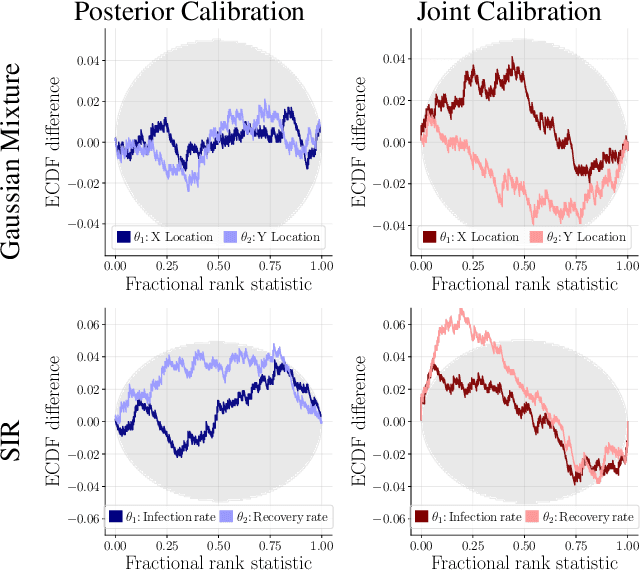
This work proposes ''jointly amortized neural approximation'' (JANA) of intractable likelihood functions and posterior densities arising in Bayesian surrogate modeling and simulation-based inference. We train three complementary networks in an end-to-end fashion: 1) a summary network to compress individual data points, sets, or time series into informative embedding vectors; 2) a posterior network to learn an amortized approximate posterior; and 3) a likelihood network to learn an amortized approximate likelihood. Their interaction opens a new route to amortized marginal likelihood and posterior predictive estimation -- two important ingredients of Bayesian workflows that are often too expensive for standard methods. We benchmark the fidelity of JANA on a variety of simulation models against state-of-the-art Bayesian methods and propose a powerful and interpretable diagnostic for joint calibration. In addition, we investigate the ability of recurrent likelihood networks to emulate complex time series models without resorting to hand-crafted summary statistics.
A Three-Phase Artificial Orcas Algorithm for Continuous and Discrete Problems
Feb 17, 2023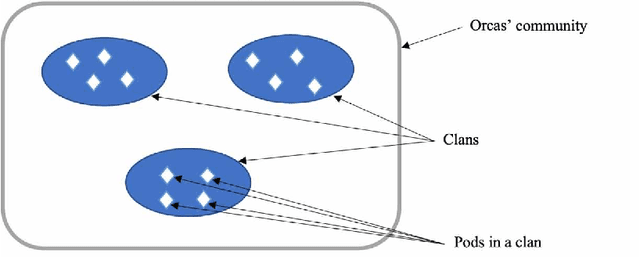
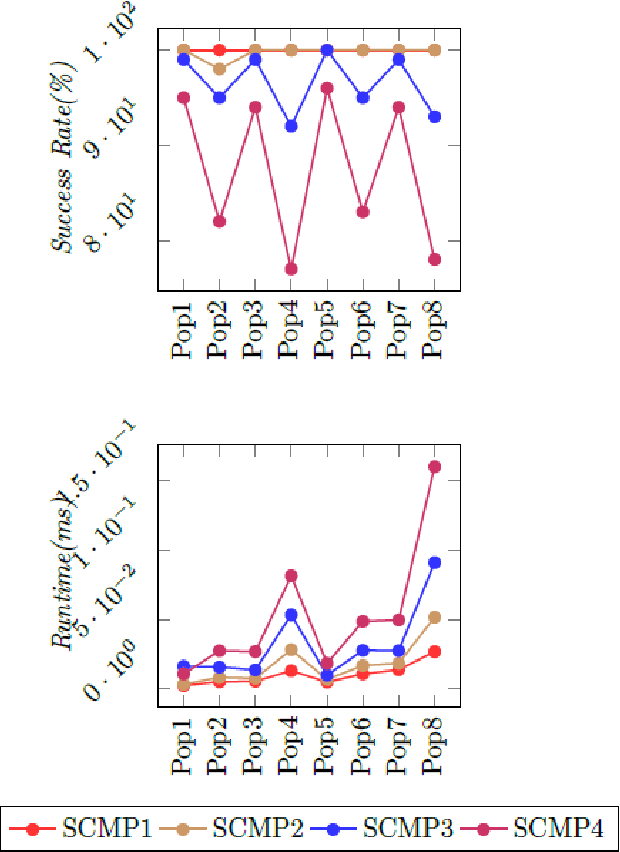
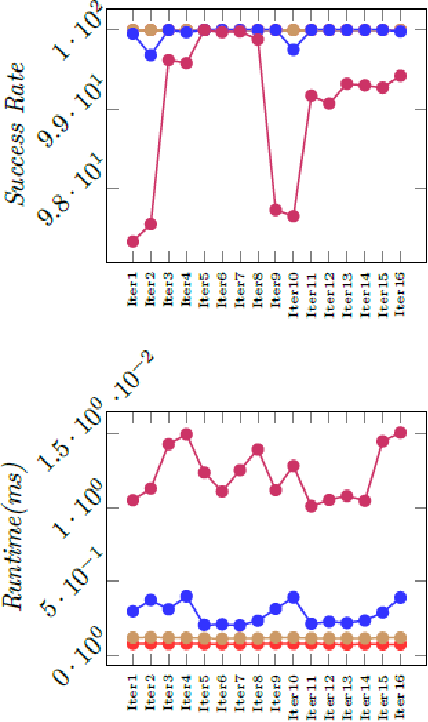
In this paper, a new swarm intelligence algorithm based on orca behaviors is proposed for problem solving. The algorithm called artificial orca algorithm (AOA) consists of simulating the orca lifestyle and in particular the social organization, the echolocation mechanism, and some hunting techniques. The originality of the proposal is that for the first time a meta-heuristic simulates simultaneously several behaviors of just one animal species. AOA was adapted to discrete problems and applied on the maze game with four level of complexity. A bunch of substantial experiments were undertaken to set the algorithm parameters for this issue. The algorithm performance was assessed by considering the success rate, the run time, and the solution path size. Finally, for comparison purposes, the authors conducted a set of experiments on state-of-the-art evolutionary algorithms, namely ACO, BA, BSO, EHO, PSO, and WOA. The overall obtained results clearly show the superiority of AOA over the other tested algorithms.
CERiL: Continuous Event-based Reinforcement Learning
Feb 15, 2023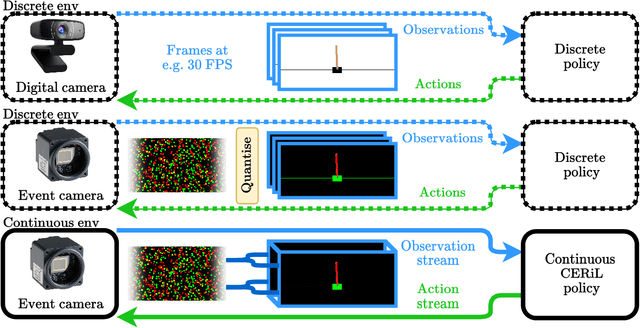

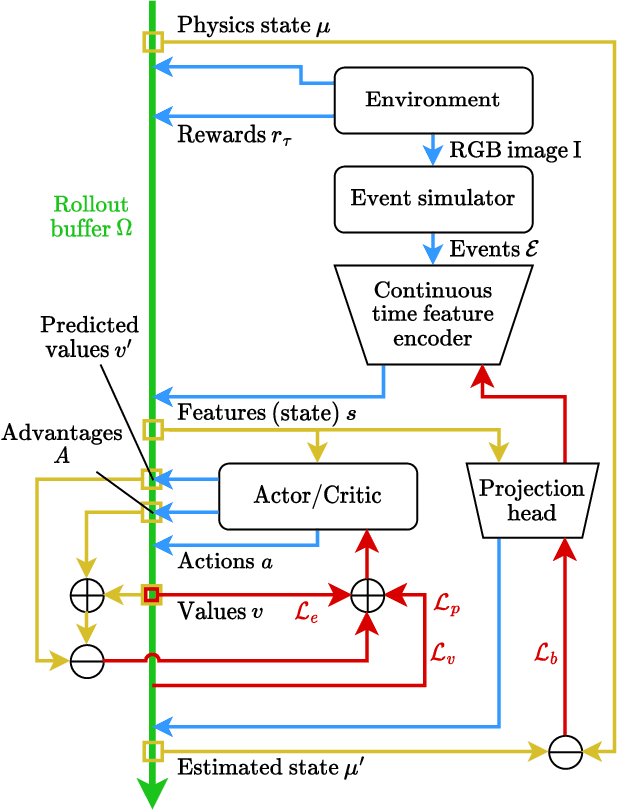

This paper explores the potential of event cameras to enable continuous time reinforcement learning. We formalise this problem where a continuous stream of unsynchronised observations is used to produce a corresponding stream of output actions for the environment. This lack of synchronisation enables greatly enhanced reactivity. We present a method to train on event streams derived from standard RL environments, thereby solving the proposed continuous time RL problem. The CERiL algorithm uses specialised network layers which operate directly on an event stream, rather than aggregating events into quantised image frames. We show the advantages of event streams over less-frequent RGB images. The proposed system outperforms networks typically used in RL, even succeeding at tasks which cannot be solved traditionally. We also demonstrate the value of our CERiL approach over a standard SNN baseline using event streams.
Real-time Action Recognition for Fine-Grained Actions and The Hand Wash Dataset
Oct 13, 2022
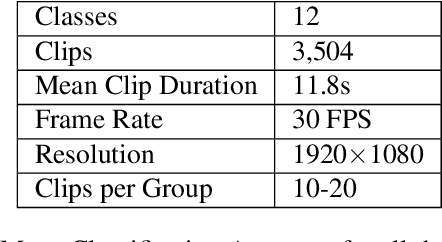
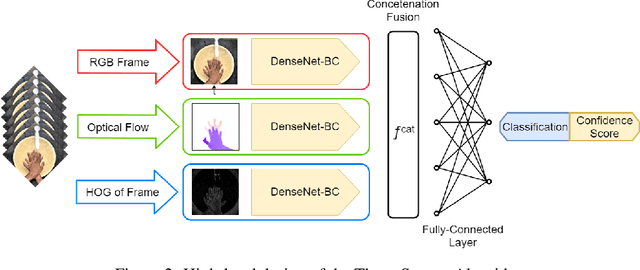
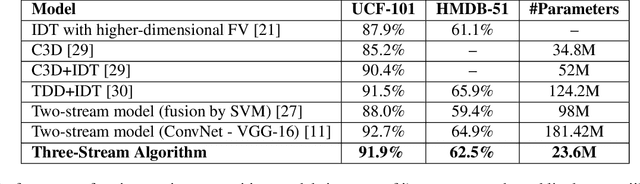
In this paper we present a three-stream algorithm for real-time action recognition and a new dataset of handwash videos, with the intent of aligning action recognition with real-world constraints to yield effective conclusions. A three-stream fusion algorithm is proposed, which runs both accurately and efficiently, in real-time even on low-powered systems such as a Raspberry Pi. The cornerstone of the proposed algorithm is the incorporation of both spatial and temporal information, as well as the information of the objects in a video while using an efficient architecture, and Optical Flow computation to achieve commendable results in real-time. The results achieved by this algorithm are benchmarked on the UCF-101 as well as the HMDB-51 datasets, achieving an accuracy of 92.7% and 64.9% respectively. An important point to note is that the algorithm is novel in the aspect that it is also able to learn the intricate differences between extremely similar actions, which would be difficult even for the human eye. Additionally, noticing a dearth in the number of datasets for the recognition of very similar or fine-grained actions, this paper also introduces a new dataset that is made publicly available, the Hand Wash Dataset with the intent of introducing a new benchmark for fine-grained action recognition tasks in the future.
Reinforcing User Retention in a Billion Scale Short Video Recommender System
Feb 12, 2023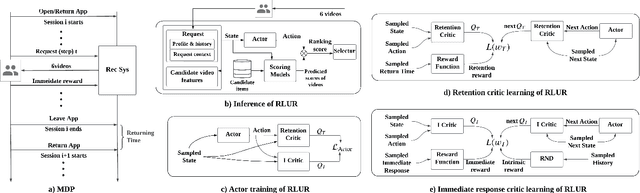
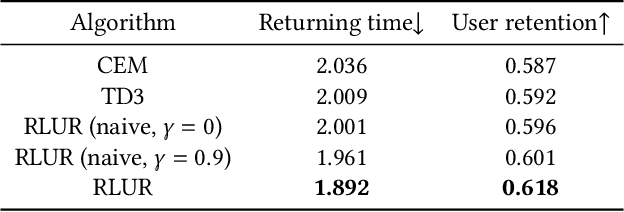
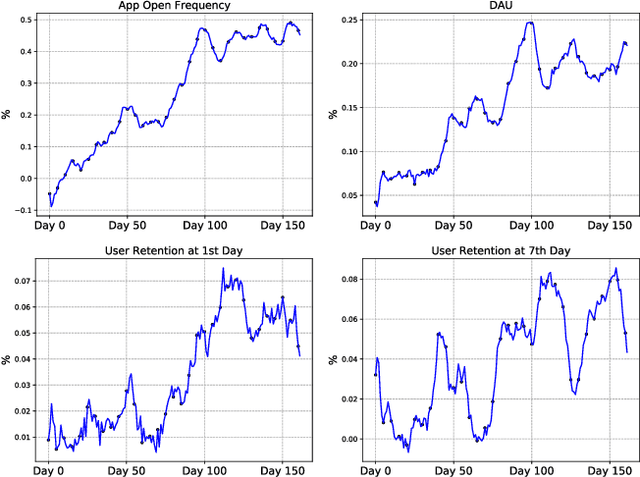
Recently, short video platforms have achieved rapid user growth by recommending interesting content to users. The objective of the recommendation is to optimize user retention, thereby driving the growth of DAU (Daily Active Users). Retention is a long-term feedback after multiple interactions of users and the system, and it is hard to decompose retention reward to each item or a list of items. Thus traditional point-wise and list-wise models are not able to optimize retention. In this paper, we choose reinforcement learning methods to optimize the retention as they are designed to maximize the long-term performance. We formulate the problem as an infinite-horizon request-based Markov Decision Process, and our objective is to minimize the accumulated time interval of multiple sessions, which is equal to improving the app open frequency and user retention. However, current reinforcement learning algorithms can not be directly applied in this setting due to uncertainty, bias, and long delay time incurred by the properties of user retention. We propose a novel method, dubbed RLUR, to address the aforementioned challenges. Both offline and live experiments show that RLUR can significantly improve user retention. RLUR has been fully launched in Kuaishou app for a long time, and achieves consistent performance improvement on user retention and DAU.
GridCLIP: One-Stage Object Detection by Grid-Level CLIP Representation Learning
Mar 16, 2023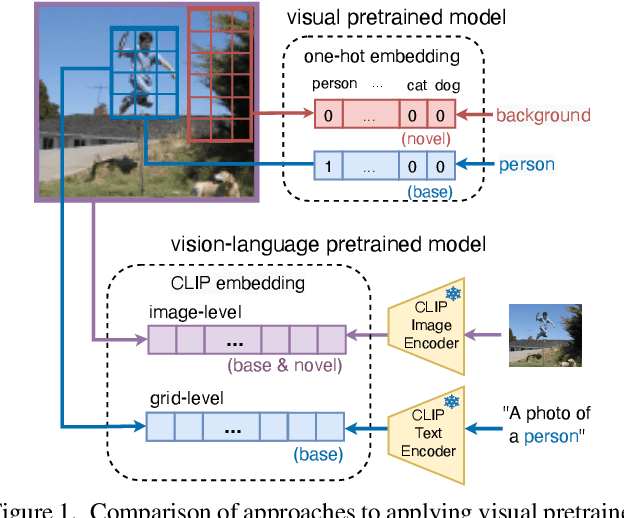
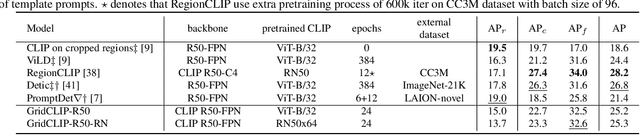
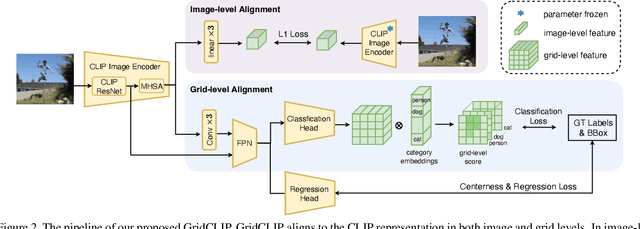

A vision-language foundation model pretrained on very large-scale image-text paired data has the potential to provide generalizable knowledge representation for downstream visual recognition and detection tasks, especially on supplementing the undersampled categories in downstream model training. Recent studies utilizing CLIP for object detection have shown that a two-stage detector design typically outperforms a one-stage detector, while requiring more expensive training resources and longer inference time. In this work, we propose a one-stage detector GridCLIP that narrows its performance gap to those of two-stage detectors, with approximately 43 and 5 times faster than its two-stage counterpart (ViLD) in the training and test process respectively. GridCLIP learns grid-level representations to adapt to the intrinsic principle of one-stage detection learning by expanding the conventional CLIP image-text holistic mapping to a more fine-grained, grid-text alignment. This differs from the region-text mapping in two-stage detectors that apply CLIP directly by treating regions as images. Specifically, GridCLIP performs Grid-level Alignment to adapt the CLIP image-level representations to grid-level representations by aligning to CLIP category representations to learn the annotated (especially frequent) categories. To learn generalizable visual representations of broader categories, especially undersampled ones, we perform Image-level Alignment during training to propagate broad pre-learned categories in the CLIP image encoder from the image-level to the grid-level representations. Experiments show that the learned CLIP-based grid-level representations boost the performance of undersampled (infrequent and novel) categories, reaching comparable detection performance on the LVIS benchmark.
Full-Body Cardiovascular Sensing with Remote Photoplethysmography
Mar 16, 2023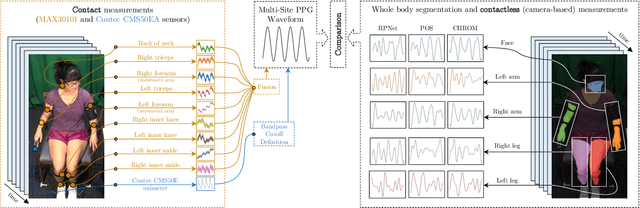


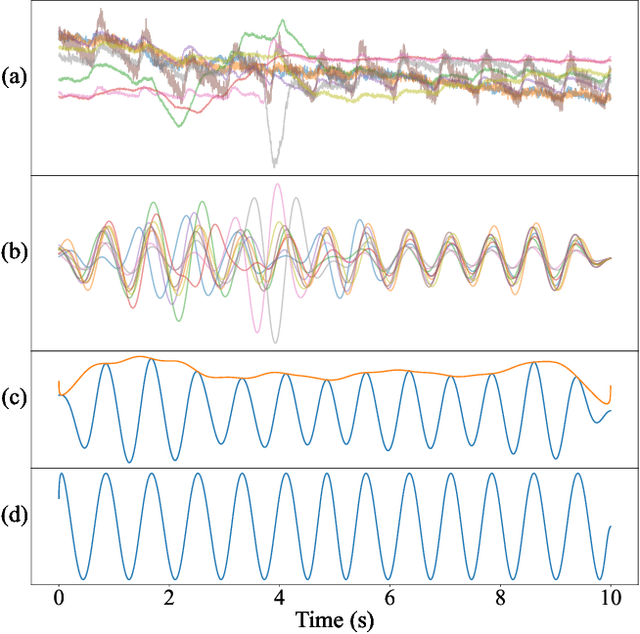
Remote photoplethysmography (rPPG) allows for noncontact monitoring of blood volume changes from a camera by detecting minor fluctuations in reflected light. Prior applications of rPPG focused on face videos. In this paper we explored the feasibility of rPPG from non-face body regions such as the arms, legs, and hands. We collected a new dataset titled Multi-Site Physiological Monitoring (MSPM), which will be released with this paper. The dataset consists of 90 frames per second video of exposed arms, legs, and face, along with 10 synchronized PPG recordings. We performed baseline heart rate estimation experiments from non-face regions with several state-of-the-art rPPG approaches, including chrominance-based (CHROM), plane-orthogonal-to-skin (POS) and RemotePulseNet (RPNet). To our knowledge, this is the first evaluation of the fidelity of rPPG signals simultaneously obtained from multiple regions of a human body. Our experiments showed that skin pixels from arms, legs, and hands are all potential sources of the blood volume pulse. The best-performing approach, POS, achieved a mean absolute error peaking at 7.11 beats per minute from non-facial body parts compared to 1.38 beats per minute from the face. Additionally, we performed experiments on pulse transit time (PTT) from both the contact PPG and rPPG signals. We found that remote PTT is possible with moderately high frame rate video when distal locations on the body are visible. These findings and the supporting dataset should facilitate new research on non-face rPPG and monitoring blood flow dynamics over the whole body with a camera.
Watch Your Step: Real-Time Adaptive Character Stepping
Oct 26, 2022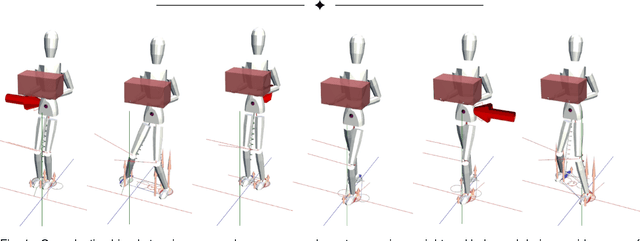
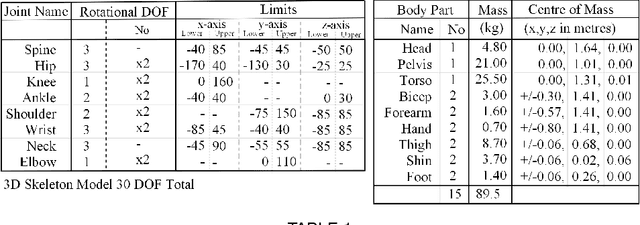
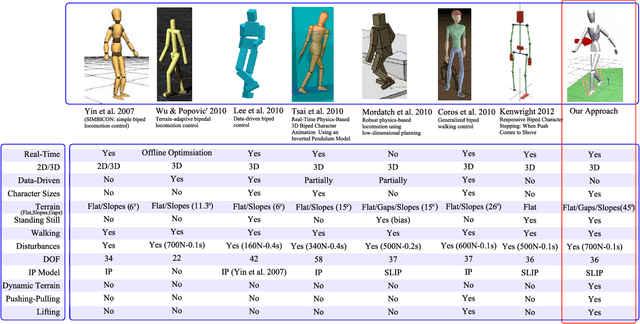
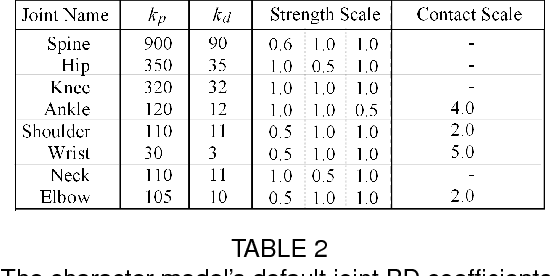
An effective 3D stepping control algorithm that is computationally fast, robust, and easy to implement is extremely important and valuable to character animation research. In this paper, we present a novel technique for generating dynamic, interactive, and controllable biped stepping motions. Our approach uses a low-dimensional physics-based model to create balanced humanoid avatars that can handle a wide variety of interactive situations, such as terrain height shifting and push exertions, while remaining upright and balanced. We accomplish this by combining the popular inverted-pendulum model with an ankle-feedback torque and variable leg-length mechanism to create a controllable solution that can adapt to unforeseen circumstances in real-time without key-framed data, any offline pre-processing, or on-line optimizations joint torque computations. We explain and address oversimplifications and limitations with the basic IP model and the reasons for extending the model by means of additional control mechanisms. We demonstrate a simple and fast approach for extending the IP model based on an ankle-torque and variable leg lengths approximation without hindering the extremely attractive properties (i.e., computational speed, robustness, and simplicity) that make the IP model so ideal for generating upright responsive balancing biped movements. Finally, while our technique focuses on lower body motions, it can, nevertheless, handle both small and large push forces even during terrain height variations. Moreover, our model effectively creates human-like motions that synthesize low-level upright stepping movements, and can be combined with additional controller techniques to produce whole body autonomous agents.