 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Policy Optimization for Personalized Interventions in Behavioral Health
Mar 21, 2023
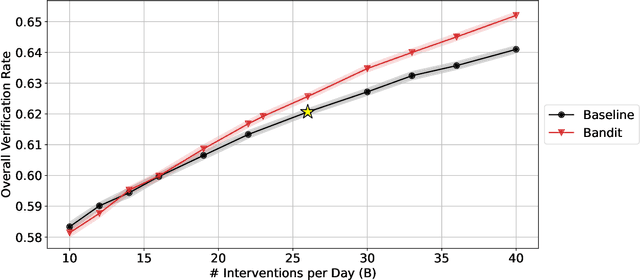

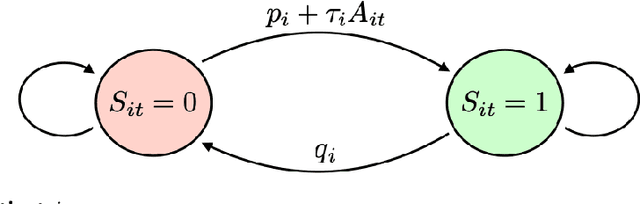
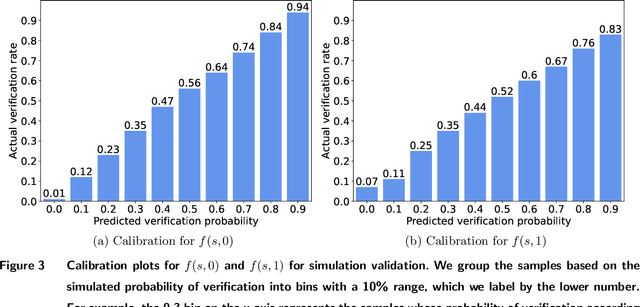
Problem definition: Behavioral health interventions, delivered through digital platforms, have the potential to significantly improve health outcomes, through education, motivation, reminders, and outreach. We study the problem of optimizing personalized interventions for patients to maximize some long-term outcome, in a setting where interventions are costly and capacity-constrained. Methodology/results: This paper provides a model-free approach to solving this problem. We find that generic model-free approaches from the reinforcement learning literature are too data intensive for healthcare applications, while simpler bandit approaches make progress at the expense of ignoring long-term patient dynamics. We present a new algorithm we dub DecompPI that approximates one step of policy iteration. Implementing DecompPI simply consists of a prediction task from offline data, alleviating the need for online experimentation. Theoretically, we show that under a natural set of structural assumptions on patient dynamics, DecompPI surprisingly recovers at least 1/2 of the improvement possible between a naive baseline policy and the optimal policy. At the same time, DecompPI is both robust to estimation errors and interpretable. Through an empirical case study on a mobile health platform for improving treatment adherence for tuberculosis, we find that DecompPI can provide the same efficacy as the status quo with approximately half the capacity of interventions. Managerial implications: DecompPI is general and is easily implementable for organizations aiming to improve long-term behavior through targeted interventions. Our case study suggests that the platform's costs of deploying interventions can potentially be cut by 50%, which facilitates the ability to scale up the system in a cost-efficient fashion.
Inverting the Fundamental Diagram and Forecasting Boundary Conditions: How Machine Learning Can Improve Macroscopic Models for Traffic Flow
Mar 21, 2023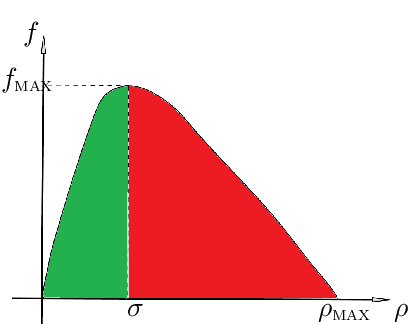
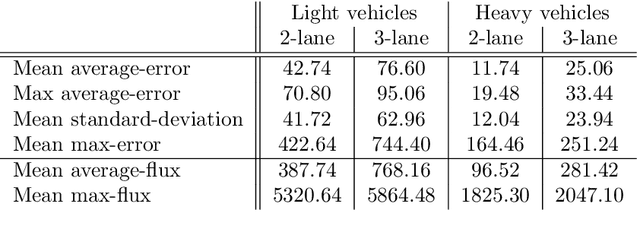
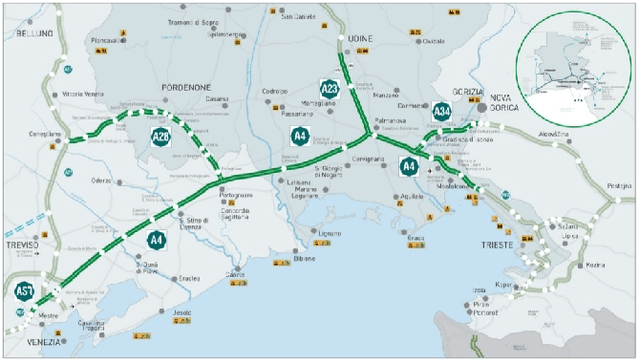
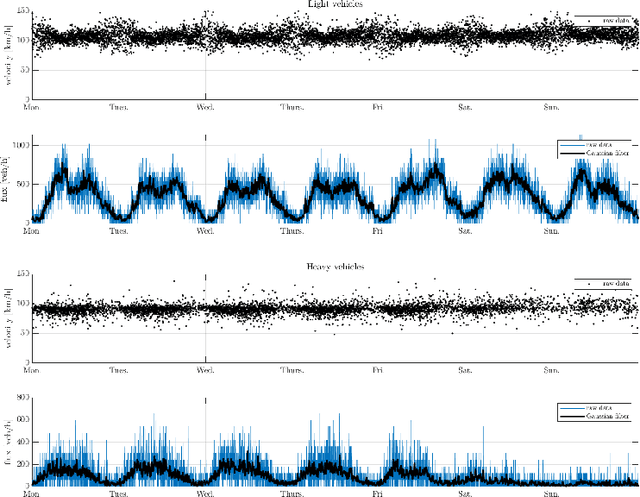
In this paper, we aim at developing new methods to join machine learning techniques and macroscopic differential models for vehicular traffic estimation and forecast. It is well known that data-driven and model-driven approaches have (sometimes complementary) advantages and drawbacks. We consider here a dataset with flux and velocity data of vehicles moving on a highway, collected by fixed sensors and classified by lane and by class of vehicle. By means of a machine learning model based on an LSTM recursive neural network, we extrapolate two important pieces of information: 1) if congestion is appearing under the sensor, and 2) the total amount of vehicles which is going to pass under the sensor in the next future (30 min). These pieces of information are then used to improve the accuracy of an LWR-based first-order multi-class model describing the dynamics of traffic flow between sensors. The first piece of information is used to invert the (concave) fundamental diagram, thus recovering the density of vehicles from the flux data, and then inject directly the density datum in the model. This allows one to better approximate the dynamics between sensors, especially if an accident happens in a not monitored stretch of the road. The second piece of information is used instead as boundary conditions for the equations underlying the traffic model, to better reconstruct the total amount of vehicles on the road at any future time. Some examples motivated by real scenarios will be discussed. Real data are provided by the Italian motorway company Autovie Venete S.p.A.
CLSA: Contrastive Learning-based Survival Analysis for Popularity Prediction in MEC Networks
Mar 21, 2023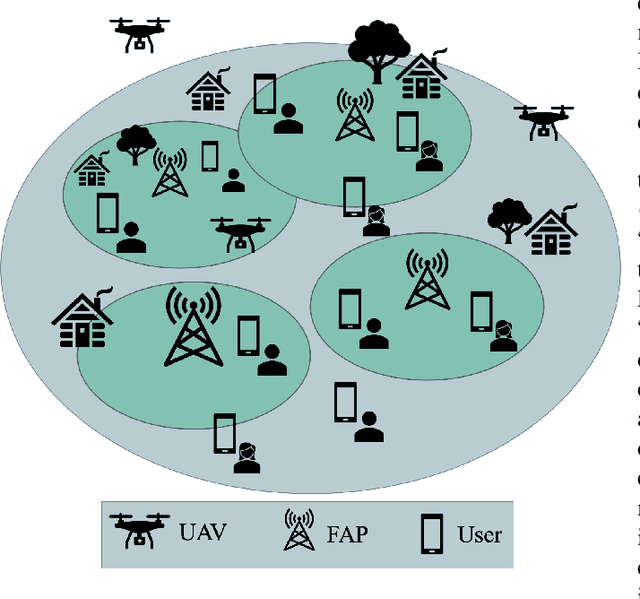
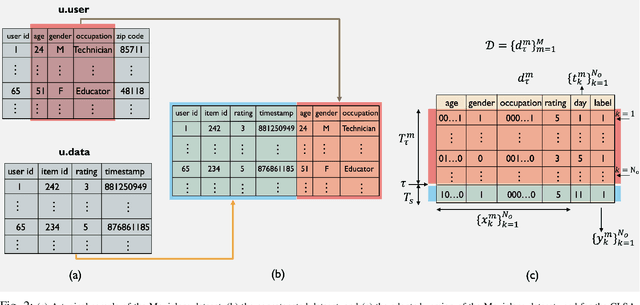
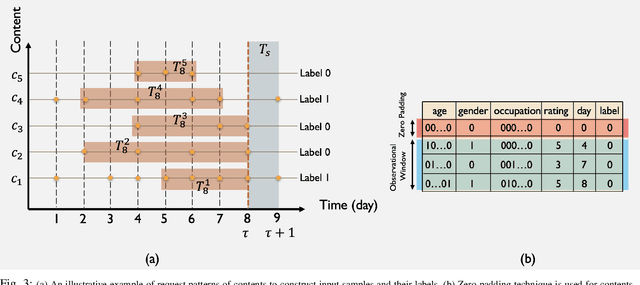
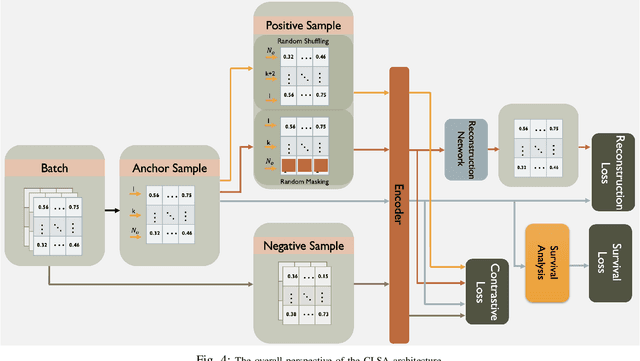
Mobile Edge Caching (MEC) integrated with Deep Neural Networks (DNNs) is an innovative technology with significant potential for the future generation of wireless networks, resulting in a considerable reduction in users' latency. The MEC network's effectiveness, however, heavily relies on its capacity to predict and dynamically update the storage of caching nodes with the most popular contents. To be effective, a DNN-based popularity prediction model needs to have the ability to understand the historical request patterns of content, including their temporal and spatial correlations. Existing state-of-the-art time-series DNN models capture the latter by simultaneously inputting the sequential request patterns of multiple contents to the network, considerably increasing the size of the input sample. This motivates us to address this challenge by proposing a DNN-based popularity prediction framework based on the idea of contrasting input samples against each other, designed for the Unmanned Aerial Vehicle (UAV)-aided MEC networks. Referred to as the Contrastive Learning-based Survival Analysis (CLSA), the proposed architecture consists of a self-supervised Contrastive Learning (CL) model, where the temporal information of sequential requests is learned using a Long Short Term Memory (LSTM) network as the encoder of the CL architecture. Followed by a Survival Analysis (SA) network, the output of the proposed CLSA architecture is probabilities for each content's future popularity, which are then sorted in descending order to identify the Top-K popular contents. Based on the simulation results, the proposed CLSA architecture outperforms its counterparts across the classification accuracy and cache-hit ratio.
HyperAttack: Multi-Gradient-Guided White-box Adversarial Structure Attack of Hypergraph Neural Networks
Feb 24, 2023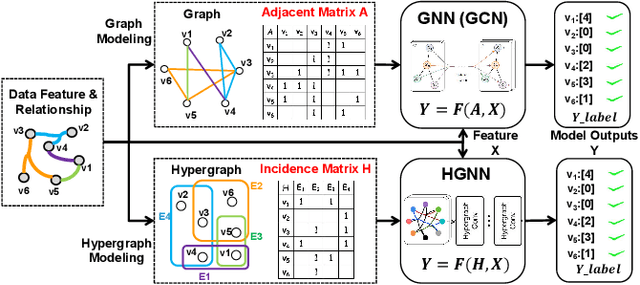

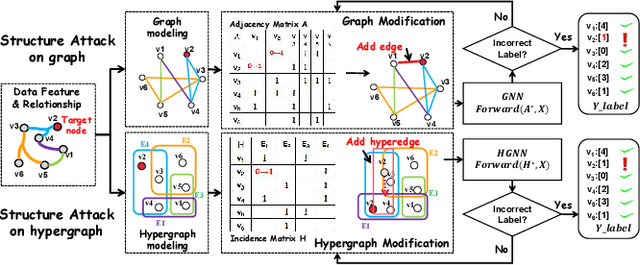
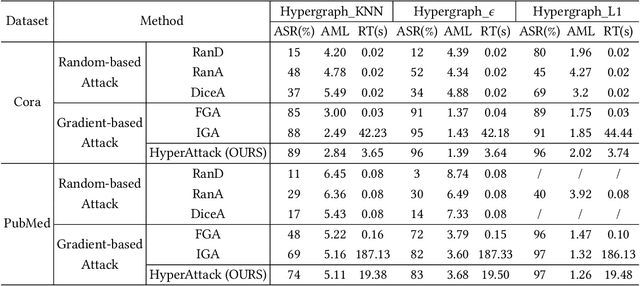
Hypergraph neural networks (HGNN) have shown superior performance in various deep learning tasks, leveraging the high-order representation ability to formulate complex correlations among data by connecting two or more nodes through hyperedge modeling. Despite the well-studied adversarial attacks on Graph Neural Networks (GNN), there is few study on adversarial attacks against HGNN, which leads to a threat to the safety of HGNN applications. In this paper, we introduce HyperAttack, the first white-box adversarial attack framework against hypergraph neural networks. HyperAttack conducts a white-box structure attack by perturbing hyperedge link status towards the target node with the guidance of both gradients and integrated gradients. We evaluate HyperAttack on the widely-used Cora and PubMed datasets and three hypergraph neural networks with typical hypergraph modeling techniques. Compared to state-of-the-art white-box structural attack methods for GNN, HyperAttack achieves a 10-20X improvement in time efficiency while also increasing attack success rates by 1.3%-3.7%. The results show that HyperAttack can achieve efficient adversarial attacks that balance effectiveness and time costs.
SuperTran: Reference Based Video Transformer for Enhancing Low Bitrate Streams in Real Time
Nov 22, 2022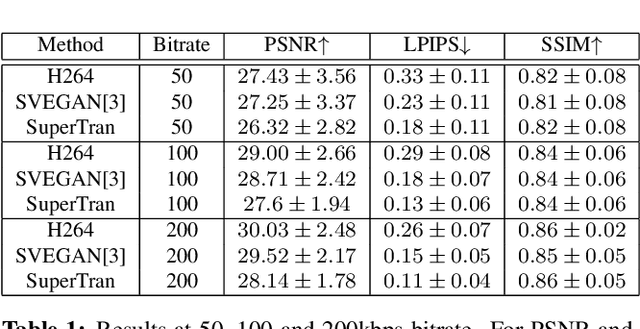
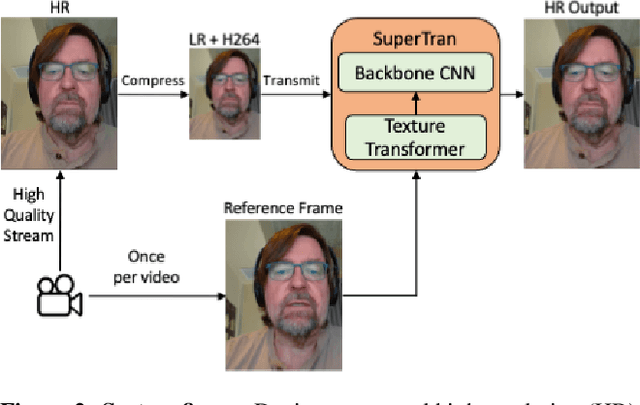
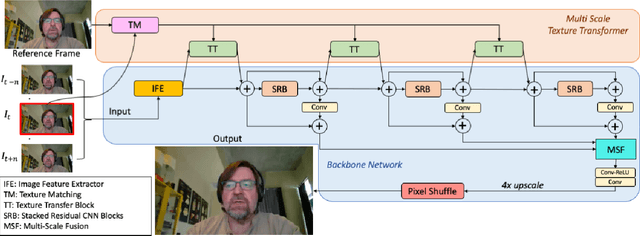
This work focuses on low bitrate video streaming scenarios (e.g. 50 - 200Kbps) where the video quality is severely compromised. We present a family of novel deep generative models for enhancing perceptual video quality of such streams by performing super-resolution while also removing compression artifacts. Our model, which we call SuperTran, consumes as input a single high-quality, high-resolution reference images in addition to the low-quality, low-resolution video stream. The model thus learns how to borrow or copy visual elements like textures from the reference image and fill in the remaining details from the low resolution stream in order to produce perceptually enhanced output video. The reference frame can be sent once at the start of the video session or be retrieved from a gallery. Importantly, the resulting output has substantially better detail than what has been otherwise possible with methods that only use a low resolution input such as the SuperVEGAN method. SuperTran works in real-time (up to 30 frames/sec) on the cloud alongside standard pipelines.
UATTA-ENS: Uncertainty Aware Test Time Augmented Ensemble for PIRC Diabetic Retinopathy Detection
Nov 08, 2022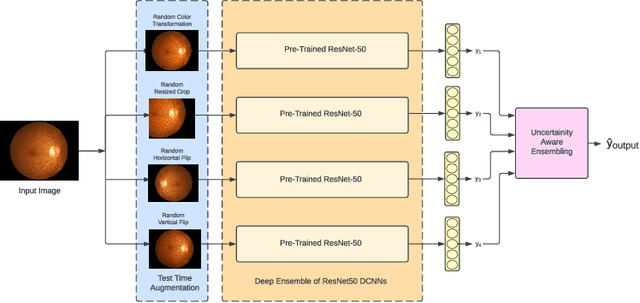
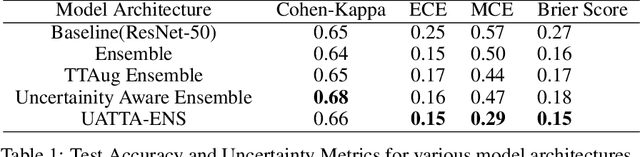
Deep Ensemble Convolutional Neural Networks has become a methodology of choice for analyzing medical images with a diagnostic performance comparable to a physician, including the diagnosis of Diabetic Retinopathy. However, commonly used techniques are deterministic and are therefore unable to provide any estimate of predictive uncertainty. Quantifying model uncertainty is crucial for reducing the risk of misdiagnosis. A reliable architecture should be well-calibrated to avoid over-confident predictions. To address this, we propose a UATTA-ENS: Uncertainty-Aware Test-Time Augmented Ensemble Technique for 5 Class PIRC Diabetic Retinopathy Classification to produce reliable and well-calibrated predictions.
Streaming Active Learning with Deep Neural Networks
Mar 05, 2023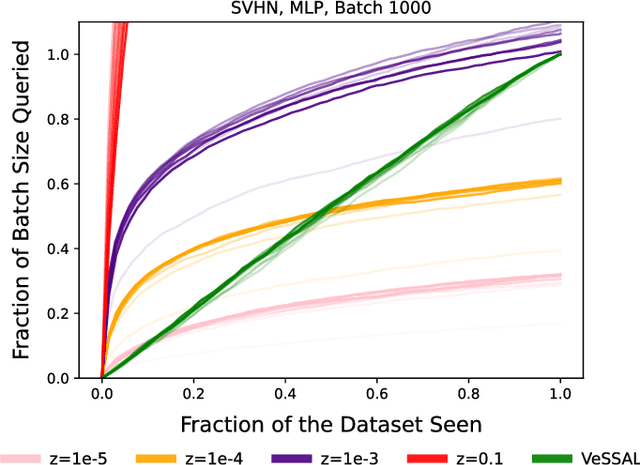
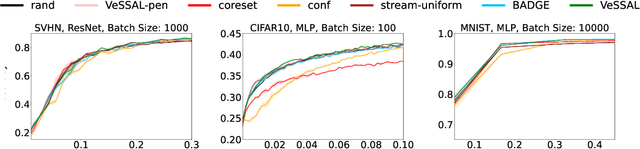
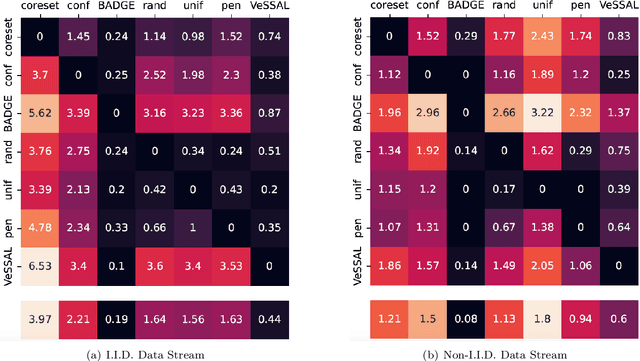
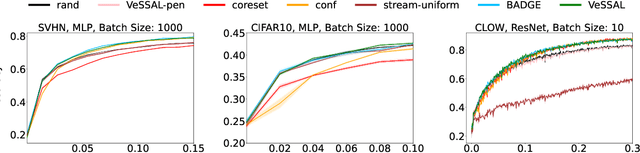
Active learning is perhaps most naturally posed as an online learning problem. However, prior active learning approaches with deep neural networks assume offline access to the entire dataset ahead of time. This paper proposes VeSSAL, a new algorithm for batch active learning with deep neural networks in streaming settings, which samples groups of points to query for labels at the moment they are encountered. Our approach trades off between uncertainty and diversity of queried samples to match a desired query rate without requiring any hand-tuned hyperparameters. Altogether, we expand the applicability of deep neural networks to realistic active learning scenarios, such as applications relevant to HCI and large, fractured datasets.
Time-Domain Based Embeddings for Spoofed Audio Representation
Oct 27, 2022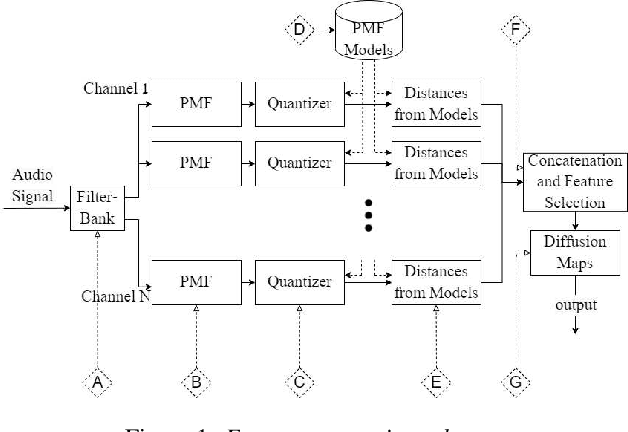
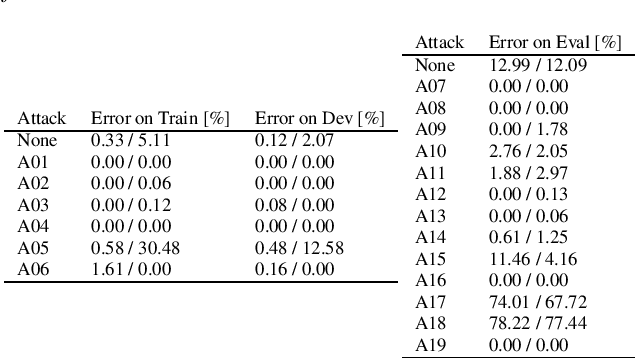
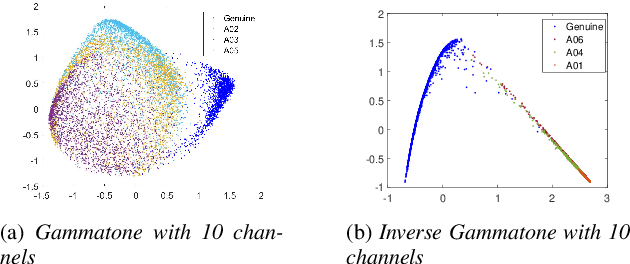
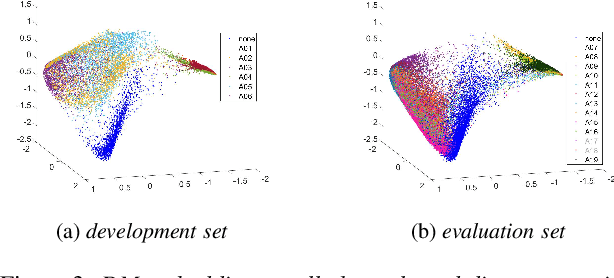
Anti-spoofing is the task of speech authentication. That is, identifying genuine human speech compared to spoofed speech. The main focus of this paper is to suggest new representations for genuine and spoofed speech, based on the probability mass function (PMF) estimation of the audio waveforms' amplitude. We introduce a new feature extraction method for speech audio signals: unlike traditional methods, our method is based on direct processing of time-domain audio samples. The PMF is utilized by designing a feature extractor based on different PMF distances and similarity measures. As an additional step, we used filter-bank preprocessing, which significantly affects the discriminative characteristics of the features and facilitates convenient visualization of possible clustering of spoofing attacks. Furthermore, we use diffusion maps to reveal the underlying manifold on which the data lies. The suggested embeddings allow the use of simple linear separators to achieve decent performance. In addition, we present a convenient way to visualize the data, which helps to assess the efficiency of different spoofing techniques. The experimental results show the potential of using multi-channel PMF based features for the anti-spoofing task, in addition to the benefits of using diffusion maps both as an analysis tool and as an embedding tool.
LMPDNet: TOF-PET list-mode image reconstruction using model-based deep learning method
Feb 21, 2023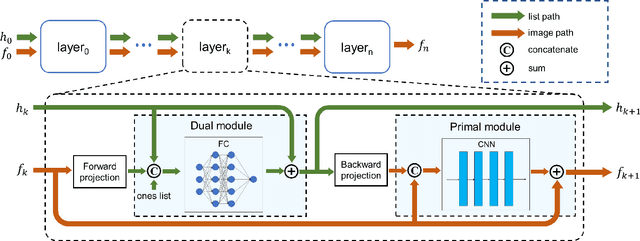
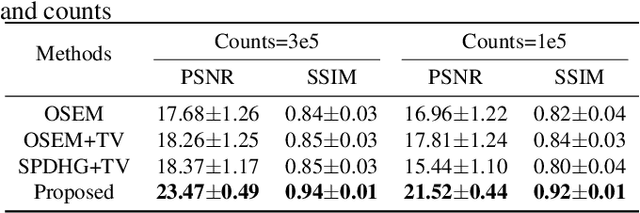
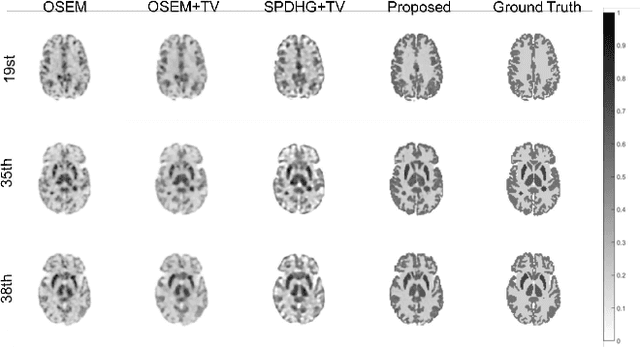
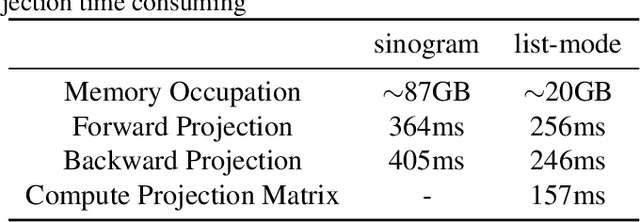
The integration of Time-of-Flight (TOF) information in the reconstruction process of Positron Emission Tomography (PET) yields improved image properties. However, implementing the cutting-edge model-based deep learning methods for TOF-PET reconstruction is challenging due to the substantial memory requirements. In this study, we present a novel model-based deep learning approach, LMPDNet, for TOF-PET reconstruction from list-mode data. We address the issue of real-time parallel computation of the projection matrix for list-mode data, and propose an iterative model-based module that utilizes a dedicated network model for list-mode data. Our experimental results indicate that the proposed LMPDNet outperforms traditional iteration-based TOF-PET list-mode reconstruction algorithms. Additionally, we compare the spatial and temporal consumption of list-mode data and sinogram data in model-based deep learning methods, demonstrating the superiority of list-mode data in model-based TOF-PET reconstruction.
Weakly Supervised Realtime Dynamic Background Subtraction
Mar 06, 2023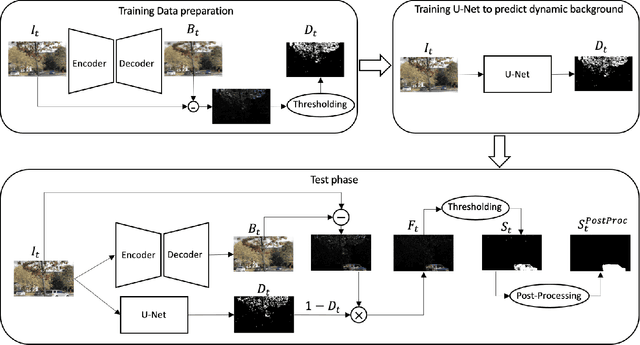
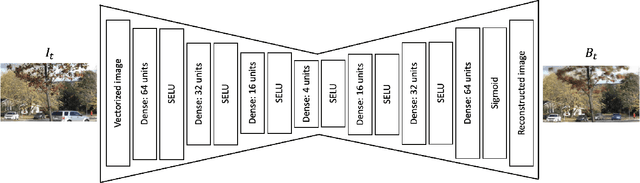

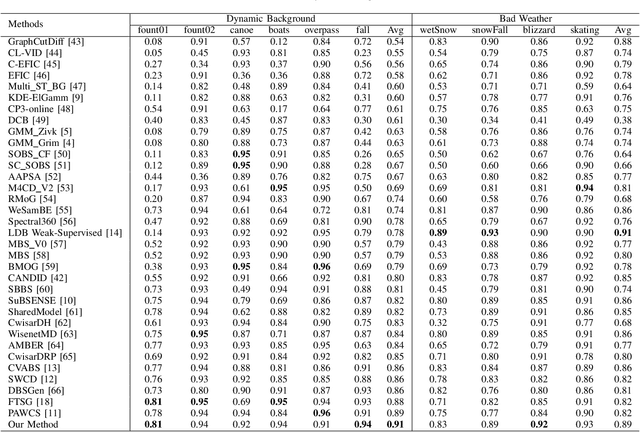
Background subtraction is a fundamental task in computer vision with numerous real-world applications, ranging from object tracking to video surveillance. Dynamic backgrounds poses a significant challenge here. Supervised deep learning-based techniques are currently considered state-of-the-art for this task. However, these methods require pixel-wise ground-truth labels, which can be time-consuming and expensive. In this work, we propose a weakly supervised framework that can perform background subtraction without requiring per-pixel ground-truth labels. Our framework is trained on a moving object-free sequence of images and comprises two networks. The first network is an autoencoder that generates background images and prepares dynamic background images for training the second network. The dynamic background images are obtained by thresholding the background-subtracted images. The second network is a U-Net that uses the same object-free video for training and the dynamic background images as pixel-wise ground-truth labels. During the test phase, the input images are processed by the autoencoder and U-Net, which generate background and dynamic background images, respectively. The dynamic background image helps remove dynamic motion from the background-subtracted image, enabling us to obtain a foreground image that is free of dynamic artifacts. To demonstrate the effectiveness of our method, we conducted experiments on selected categories of the CDnet 2014 dataset and the I2R dataset. Our method outperformed all top-ranked unsupervised methods. We also achieved better results than one of the two existing weakly supervised methods, and our performance was similar to the other. Our proposed method is online, real-time, efficient, and requires minimal frame-level annotation, making it suitable for a wide range of real-world applications.