 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Reducing Down(stream)time: Pretraining Molecular GNNs using Heterogeneous AI Accelerators
Nov 08, 2022
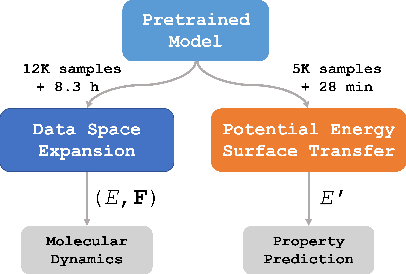

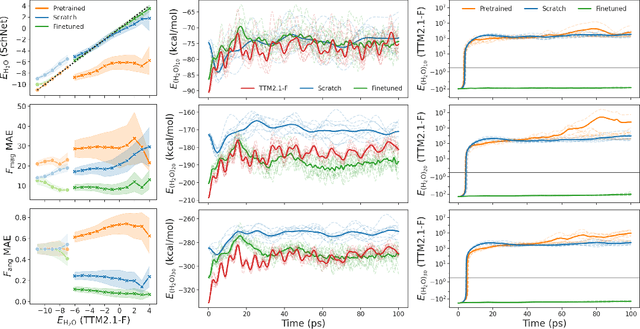
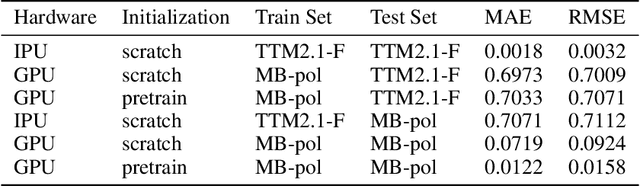
The demonstrated success of transfer learning has popularized approaches that involve pretraining models from massive data sources and subsequent finetuning towards a specific task. While such approaches have become the norm in fields such as natural language processing, implementation and evaluation of transfer learning approaches for chemistry are in the early stages. In this work, we demonstrate finetuning for downstream tasks on a graph neural network (GNN) trained over a molecular database containing 2.7 million water clusters. The use of Graphcore IPUs as an AI accelerator for training molecular GNNs reduces training time from a reported 2.7 days on 0.5M clusters to 1.2 hours on 2.7M clusters. Finetuning the pretrained model for downstream tasks of molecular dynamics and transfer to a different potential energy surface took only 8.3 hours and 28 minutes, respectively, on a single GPU.
Time Minimization in Hierarchical Federated Learning
Oct 07, 2022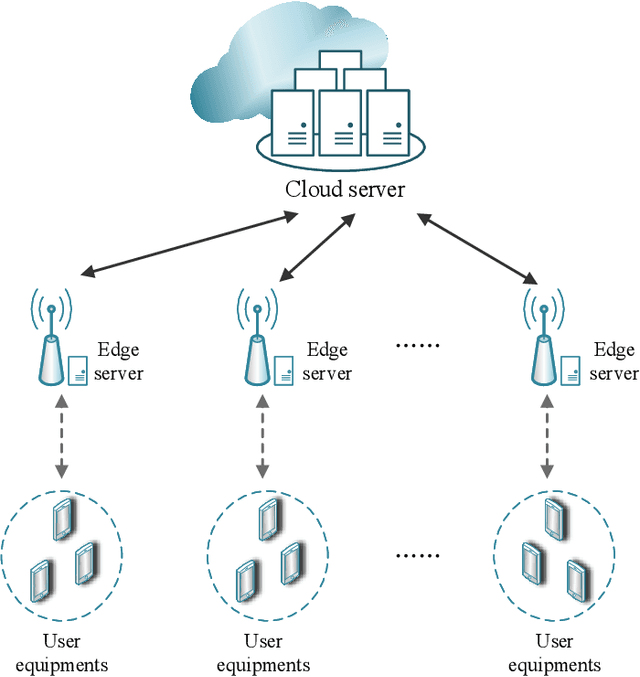
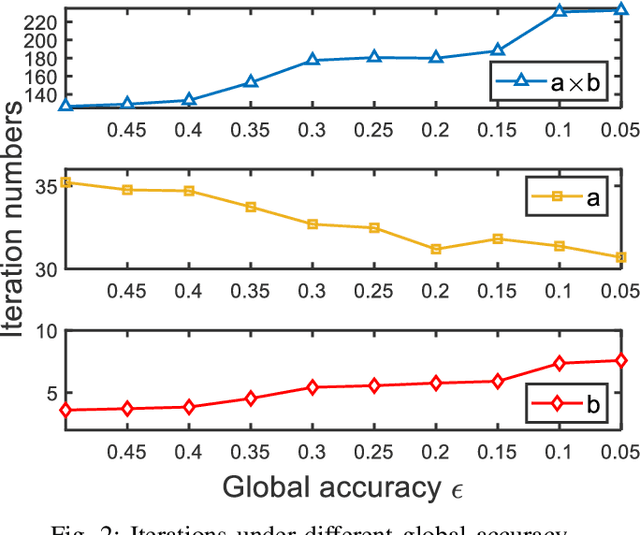
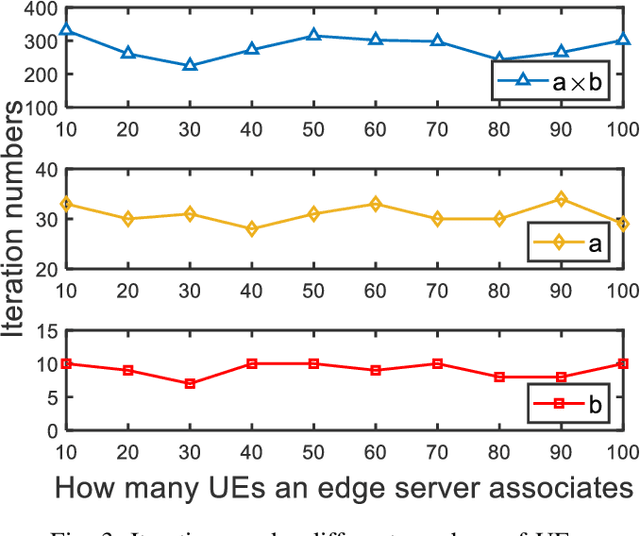
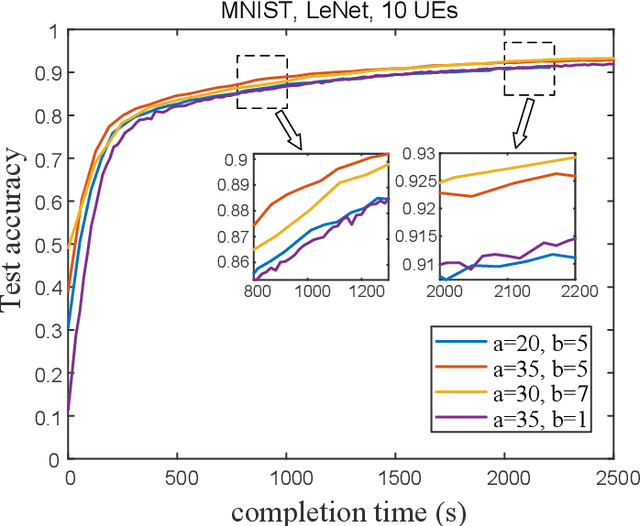
Federated Learning is a modern decentralized machine learning technique where user equipments perform machine learning tasks locally and then upload the model parameters to a central server. In this paper, we consider a 3-layer hierarchical federated learning system which involves model parameter exchanges between the cloud and edge servers, and the edge servers and user equipment. In a hierarchical federated learning model, delay in communication and computation of model parameters has a great impact on achieving a predefined global model accuracy. Therefore, we formulate a joint learning and communication optimization problem to minimize total model parameter communication and computation delay, by optimizing local iteration counts and edge iteration counts. To solve the problem, an iterative algorithm is proposed. After that, a time-minimized UE-to-edge association algorithm is presented where the maximum latency of the system is reduced. Simulation results show that the global model converges faster under optimal edge server and local iteration counts. The hierarchical federated learning latency is minimized with the proposed UE-to-edge association strategy.
CoralStyleCLIP: Co-optimized Region and Layer Selection for Image Editing
Mar 09, 2023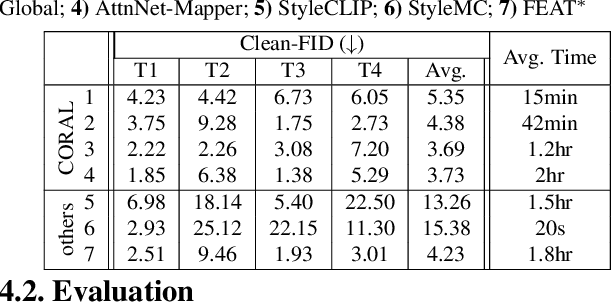

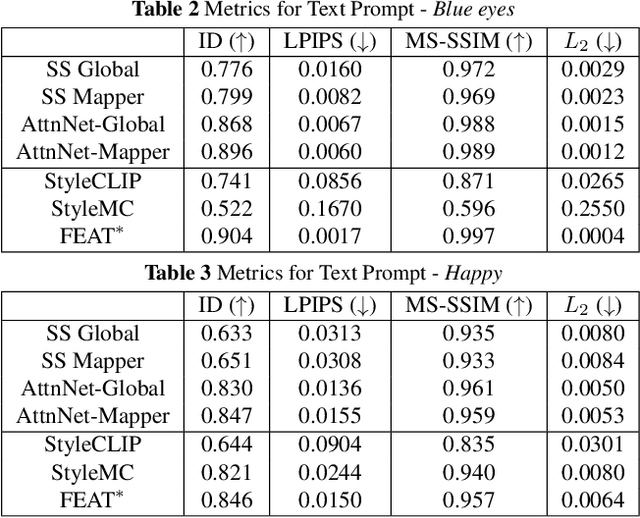
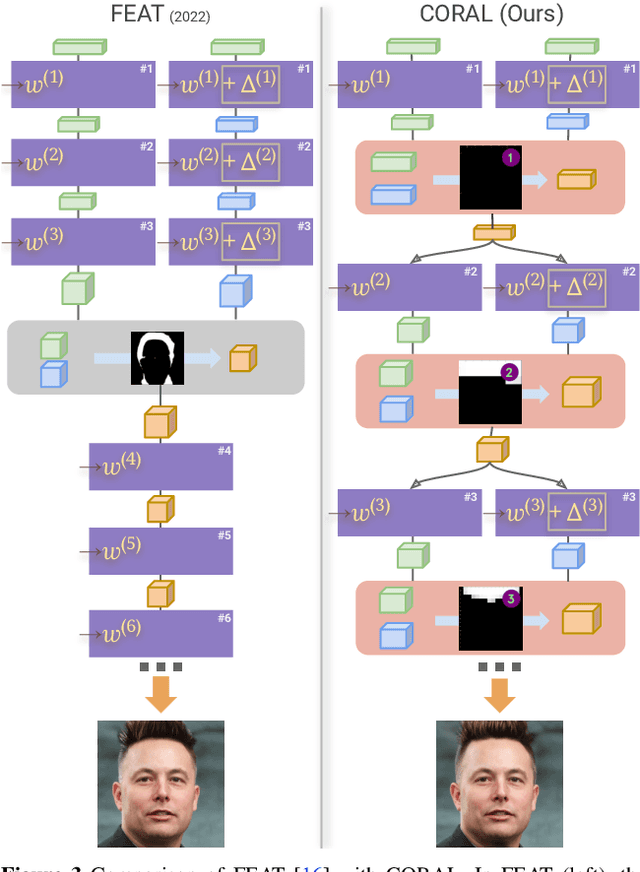
Edit fidelity is a significant issue in open-world controllable generative image editing. Recently, CLIP-based approaches have traded off simplicity to alleviate these problems by introducing spatial attention in a handpicked layer of a StyleGAN. In this paper, we propose CoralStyleCLIP, which incorporates a multi-layer attention-guided blending strategy in the feature space of StyleGAN2 for obtaining high-fidelity edits. We propose multiple forms of our co-optimized region and layer selection strategy to demonstrate the variation of time complexity with the quality of edits over different architectural intricacies while preserving simplicity. We conduct extensive experimental analysis and benchmark our method against state-of-the-art CLIP-based methods. Our findings suggest that CoralStyleCLIP results in high-quality edits while preserving the ease of use.
Estimation of continuous environments by robot swarms: Correlated networks and decision-making
Mar 15, 2023
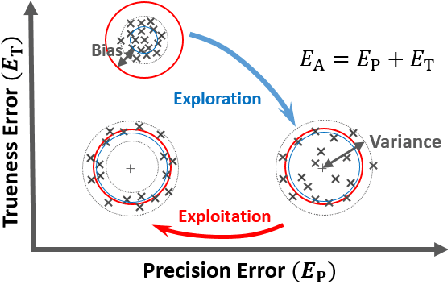
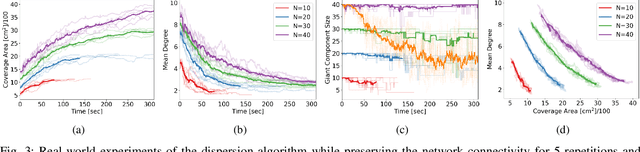
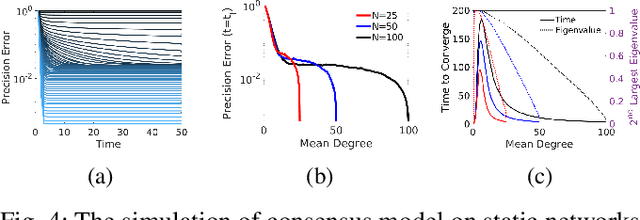
Collective decision-making is an essential capability of large-scale multi-robot systems to establish autonomy on the swarm level. A large portion of literature on collective decision-making in swarm robotics focuses on discrete decisions selecting from a limited number of options. Here we assign a decentralized robot system with the task of exploring an unbounded environment, finding consensus on the mean of a measurable environmental feature, and aggregating at areas where that value is measured (e.g., a contour line). A unique quality of this task is a causal loop between the robots' dynamic network topology and their decision-making. For example, the network's mean node degree influences time to convergence while the currently agreed-on mean value influences the swarm's aggregation location, hence, also the network structure as well as the precision error. We propose a control algorithm and study it in real-world robot swarm experiments in different environments. We show that our approach is effective and achieves higher precision than a control experiment. We anticipate applications, for example, in containing pollution with surface vehicles.
Decomposed Diffusion Models for High-Quality Video Generation
Mar 15, 2023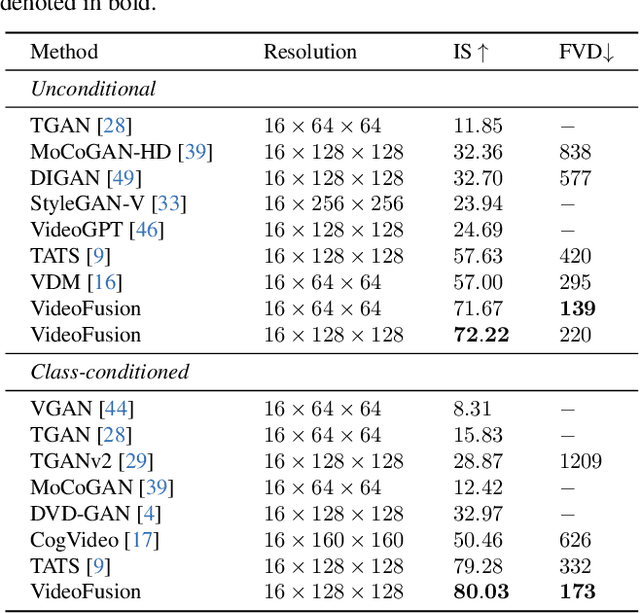


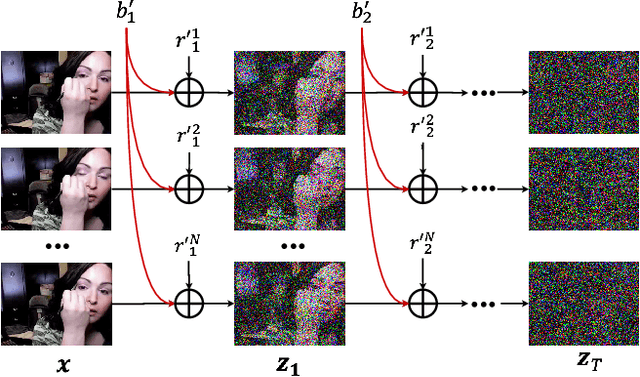
A diffusion probabilistic model (DPM), which constructs a forward diffusion process by gradually adding noise to data points and learns the reverse denoising process to generate new samples, has been shown to handle complex data distribution. Despite its recent success in image synthesis, applying DPMs to video generation is still challenging due to the high dimensional data space. Previous methods usually adopt a standard diffusion process, where frames in the same video clip are destroyed with independent noises, ignoring the content redundancy and temporal correlation. This work presents a decomposed diffusion process via resolving the per-frame noise into a base noise that is shared among all frames and a residual noise that varies along the time axis. The denoising pipeline employs two jointly-learned networks to match the noise decomposition accordingly. Experiments on various datasets confirm that our approach, termed as VideoFusion, surpasses both GAN-based and diffusion-based alternatives in high-quality video generation. We further show that our decomposed formulation can benefit from pre-trained image diffusion models and well-support text-conditioned video creation.
Dynamically Expandable Graph Convolution for Streaming Recommendation
Mar 21, 2023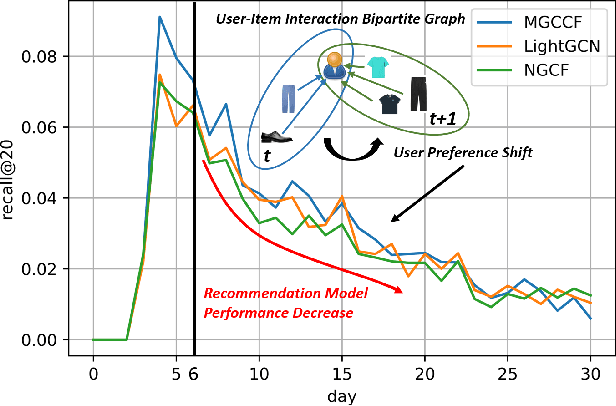
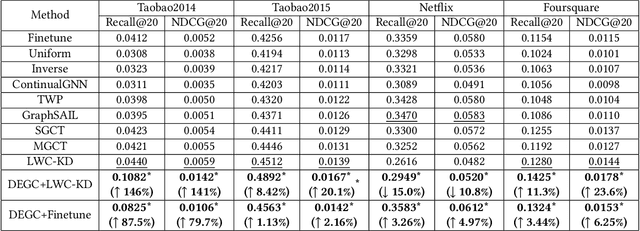
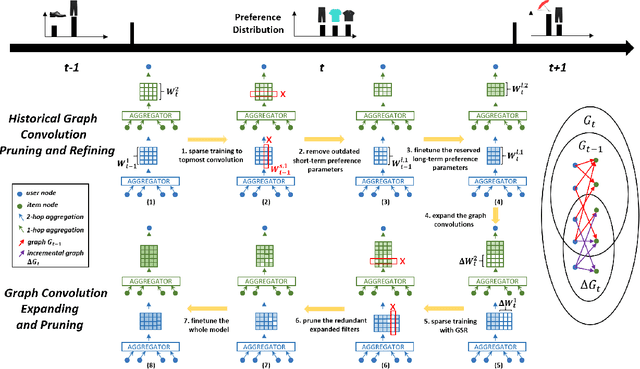
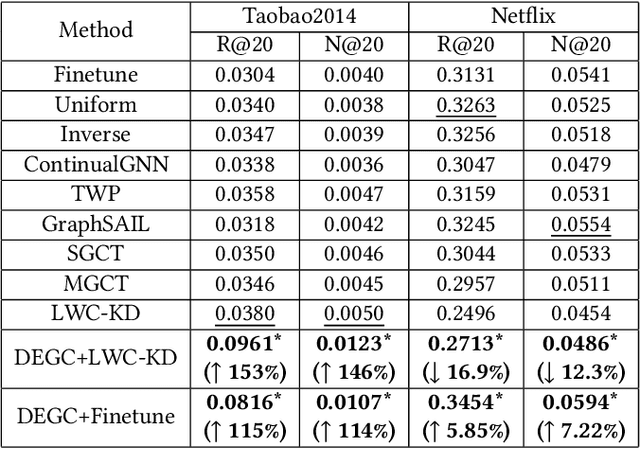
Personalized recommender systems have been widely studied and deployed to reduce information overload and satisfy users' diverse needs. However, conventional recommendation models solely conduct a one-time training-test fashion and can hardly adapt to evolving demands, considering user preference shifts and ever-increasing users and items in the real world. To tackle such challenges, the streaming recommendation is proposed and has attracted great attention recently. Among these, continual graph learning is widely regarded as a promising approach for the streaming recommendation by academia and industry. However, existing methods either rely on the historical data replay which is often not practical under increasingly strict data regulations, or can seldom solve the \textit{over-stability} issue. To overcome these difficulties, we propose a novel \textbf{D}ynamically \textbf{E}xpandable \textbf{G}raph \textbf{C}onvolution (DEGC) algorithm from a \textit{model isolation} perspective for the streaming recommendation which is orthogonal to previous methods. Based on the motivation of disentangling outdated short-term preferences from useful long-term preferences, we design a sequence of operations including graph convolution pruning, refining, and expanding to only preserve beneficial long-term preference-related parameters and extract fresh short-term preferences. Moreover, we model the temporal user preference, which is utilized as user embedding initialization, for better capturing the individual-level preference shifts. Extensive experiments on the three most representative GCN-based recommendation models and four industrial datasets demonstrate the effectiveness and robustness of our method.
Policy Mirror Descent Inherently Explores Action Space
Mar 21, 2023Explicit exploration in the action space was assumed to be indispensable for online policy gradient methods to avoid a drastic degradation in sample complexity, for solving general reinforcement learning problems over finite state and action spaces. In this paper, we establish for the first time an $\tilde{\mathcal{O}}(1/\epsilon^2)$ sample complexity for online policy gradient methods without incorporating any exploration strategies. The essential development consists of two new on-policy evaluation operators and a novel analysis of the stochastic policy mirror descent method (SPMD). SPMD with the first evaluation operator, called value-based estimation, tailors to the Kullback-Leibler divergence. Provided the Markov chains on the state space of generated policies are uniformly mixing with non-diminishing minimal visitation measure, an $\tilde{\mathcal{O}}(1/\epsilon^2)$ sample complexity is obtained with a linear dependence on the size of the action space. SPMD with the second evaluation operator, namely truncated on-policy Monte Carlo (TOMC), attains an $\tilde{\mathcal{O}}(\mathcal{H}_{\mathcal{D}}/\epsilon^2)$ sample complexity, where $\mathcal{H}_{\mathcal{D}}$ mildly depends on the effective horizon and the size of the action space with properly chosen Bregman divergence (e.g., Tsallis divergence). SPMD with TOMC also exhibits stronger convergence properties in that it controls the optimality gap with high probability rather than in expectation. In contrast to explicit exploration, these new policy gradient methods can prevent repeatedly committing to potentially high-risk actions when searching for optimal policies.
3D-CLFusion: Fast Text-to-3D Rendering with Contrastive Latent Diffusion
Mar 21, 2023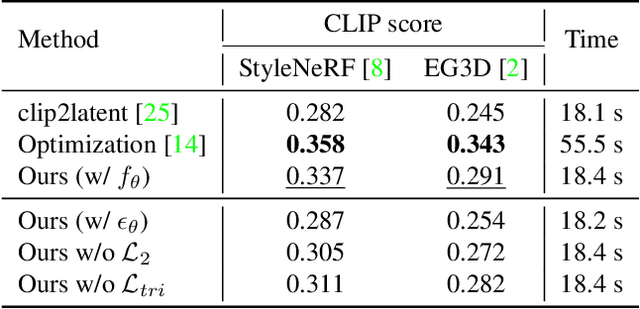
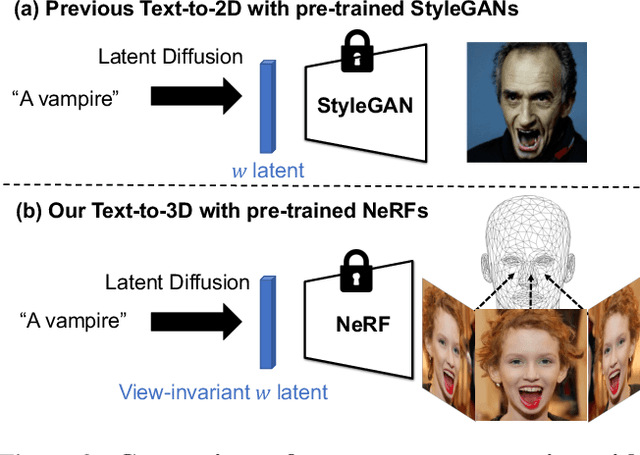
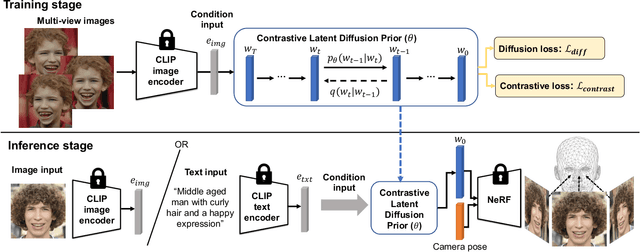

We tackle the task of text-to-3D creation with pre-trained latent-based NeRFs (NeRFs that generate 3D objects given input latent code). Recent works such as DreamFusion and Magic3D have shown great success in generating 3D content using NeRFs and text prompts, but the current approach of optimizing a NeRF for every text prompt is 1) extremely time-consuming and 2) often leads to low-resolution outputs. To address these challenges, we propose a novel method named 3D-CLFusion which leverages the pre-trained latent-based NeRFs and performs fast 3D content creation in less than a minute. In particular, we introduce a latent diffusion prior network for learning the w latent from the input CLIP text/image embeddings. This pipeline allows us to produce the w latent without further optimization during inference and the pre-trained NeRF is able to perform multi-view high-resolution 3D synthesis based on the latent. We note that the novelty of our model lies in that we introduce contrastive learning during training the diffusion prior which enables the generation of the valid view-invariant latent code. We demonstrate through experiments the effectiveness of our proposed view-invariant diffusion process for fast text-to-3D creation, e.g., 100 times faster than DreamFusion. We note that our model is able to serve as the role of a plug-and-play tool for text-to-3D with pre-trained NeRFs.
Adaptive Goal Management System of Robots
Mar 21, 2023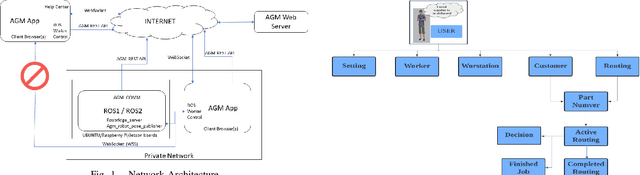
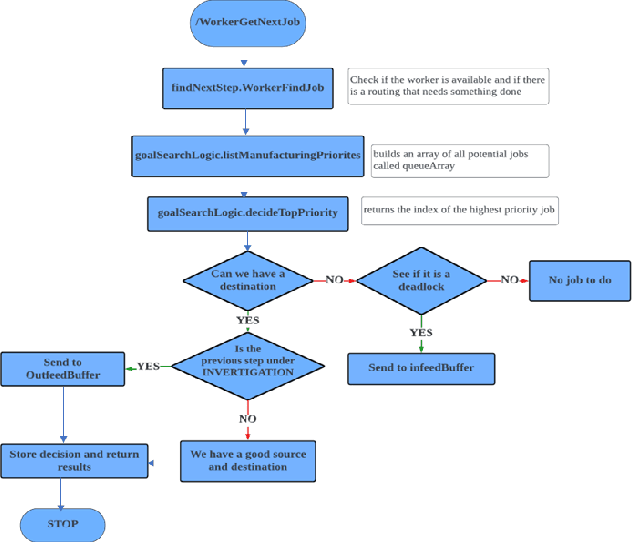
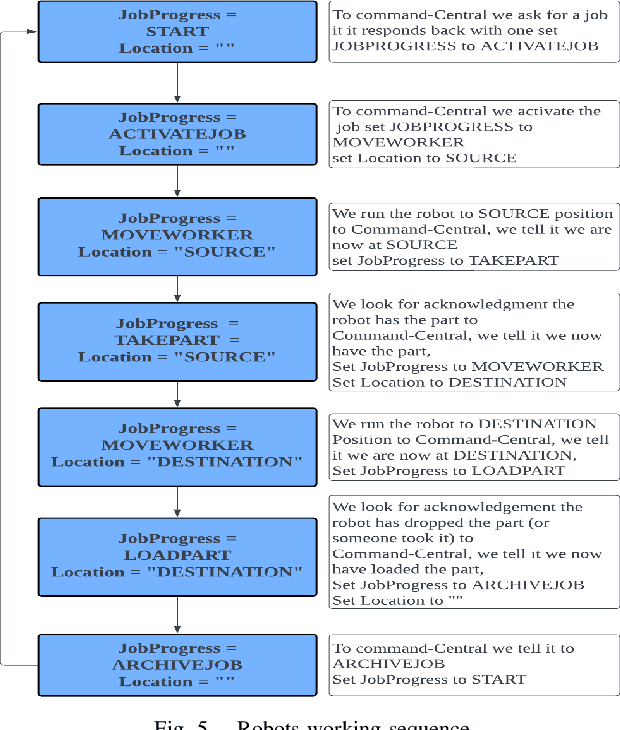
This paper considers the problem of managing single or multiple robots and proposes a cloud-based robot fleet manager, Adaptive Goal Management (AGM) System, for teams of unmanned mobile robots. The AGM system uses an adaptive goal execution approach and provides a restful API for communication between single or multiple robots, enabling real-time monitoring and control. The overarching goal of AGM is to coordinate single or multiple robots to productively complete tasks in an environment. There are some existing works that provide various solutions for managing single or multiple robots, but the proposed AGM system is designed to be adaptable and scalable, making it suitable for managing multiple heterogeneous robots in diverse environments with dynamic changes. The proposed AGM system presents a versatile and efficient solution for managing single or multiple robots across multiple industries, such as healthcare, agriculture, airports, manufacturing, and logistics. By enhancing the capabilities of these robots and enabling seamless task execution, the AGM system offers a powerful tool for facilitating complex operations. The effectiveness of the proposed AGM system is demonstrated through simulation experiments in diverse environments using ROS1 with Gazebo. The results show that the AGM system efficiently manages the allocated tasks and missions. Tests conducted in the manufacturing industry have shown promising results in task and mission management for both a single Mobile Industrial Robot and multiple Turtlebot3 robots. To provide further insights, a supplementary video showcasing the experiments can be found at https://github.com/mukmalone/ AdaptiveGoalManagement.
Deep probabilistic model for lossless scalable point cloud attribute compression
Mar 11, 2023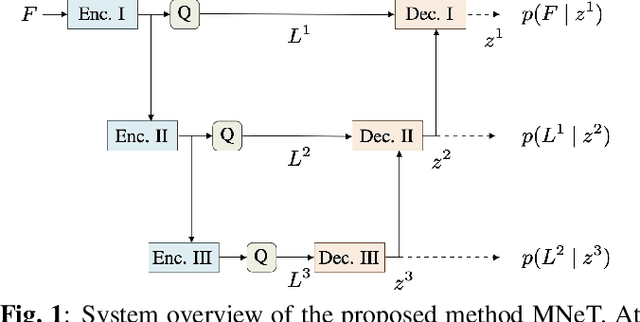
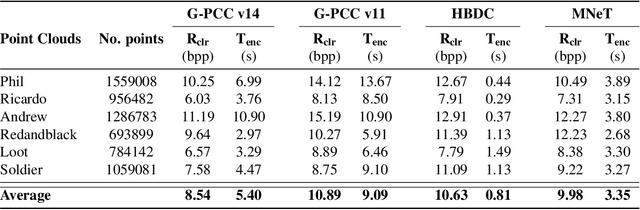
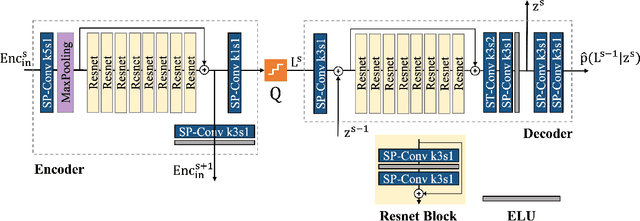

In recent years, several point cloud geometry compression methods that utilize advanced deep learning techniques have been proposed, but there are limited works on attribute compression, especially lossless compression. In this work, we build an end-to-end multiscale point cloud attribute coding method (MNeT) that progressively projects the attributes onto multiscale latent spaces. The multiscale architecture provides an accurate context for the attribute probability modeling and thus minimizes the coding bitrate with a single network prediction. Besides, our method allows scalable coding that lower quality versions can be easily extracted from the losslessly compressed bitstream. We validate our method on a set of point clouds from MVUB and MPEG and show that our method outperforms recently proposed methods and on par with the latest G-PCC version 14. Besides, our coding time is substantially faster than G-PCC.