 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Strategic Trading in Quantitative Markets through Multi-Agent Reinforcement Learning
Mar 15, 2023
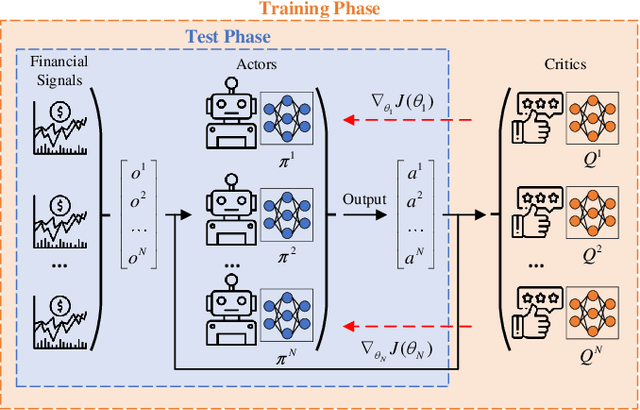
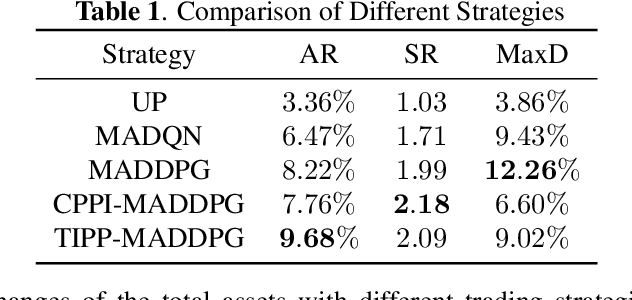


Due to the rapid dynamics and a mass of uncertainties in the quantitative markets, the issue of how to take appropriate actions to make profits in stock trading remains a challenging one. Reinforcement learning (RL), as a reward-oriented approach for optimal control, has emerged as a promising method to tackle this strategic decision-making problem in such a complex financial scenario. In this paper, we integrated two prior financial trading strategies named constant proportion portfolio insurance (CPPI) and time-invariant portfolio protection (TIPP) into multi-agent deep deterministic policy gradient (MADDPG) and proposed two specifically designed multi-agent RL (MARL) methods: CPPI-MADDPG and TIPP-MADDPG for investigating strategic trading in quantitative markets. Afterward, we selected 100 different shares in the real financial market to test these specifically proposed approaches. The experiment results show that CPPI-MADDPG and TIPP-MADDPG approaches generally outperform the conventional ones.
Implementing Continuous HRTF Measurement in Near-Field
Mar 15, 2023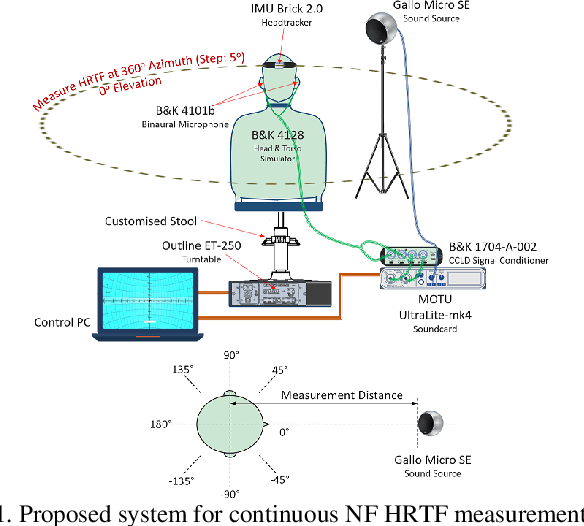
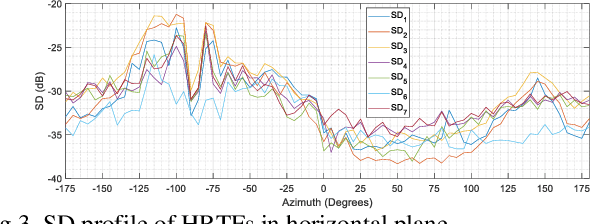
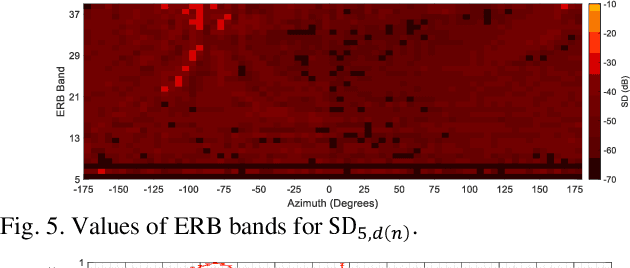
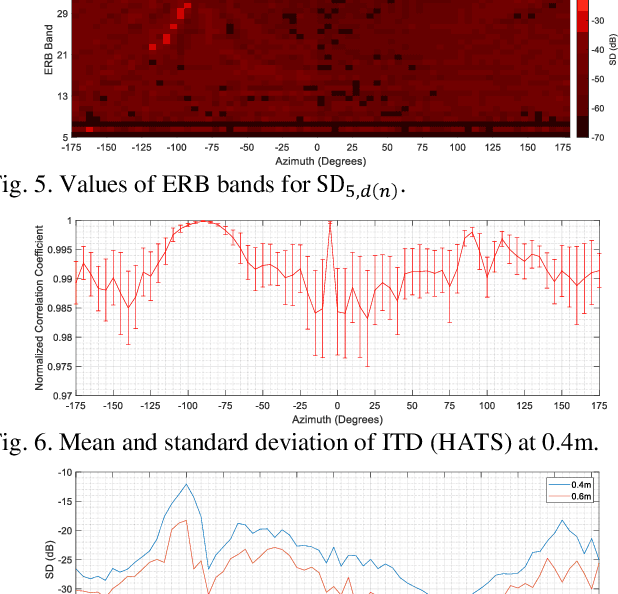
Head-related transfer function (HRTF) is an essential component to create an immersive listening experience over headphones for virtual reality (VR) and augmented reality (AR) applications. Metaverse combines VR and AR to create immersive digital experiences, and users are very likely to interact with virtual objects in the near-field (NF). The HRTFs of such objects are highly individualized and dependent on directions and distances. Hence, a significant number of HRTF measurements at different distances in the NF would be needed. Using conventional static stop-and-go HRTF measurement methods to acquire these measurements would be time-consuming and tedious for human listeners. In this paper, we propose a continuous measurement system targeted for the NF, and efficiently capturing HRTFs in the horizontal plane within 45 secs. Comparative experiments are performed on head and torso similar (HATS) and human listeners to evaluate system consistency and robustness.
Authorship Conflicts in Academia: an International Cross-Discipline Survey
Mar 15, 2023
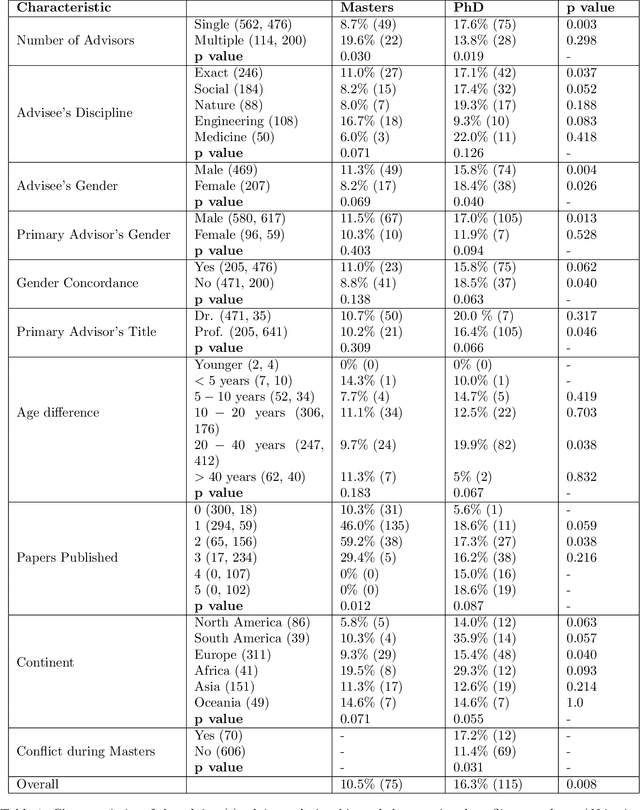
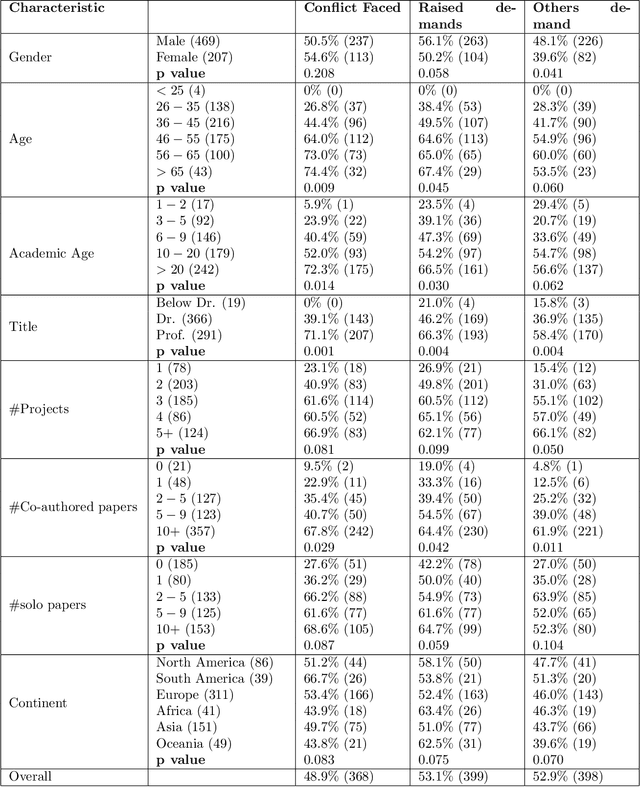
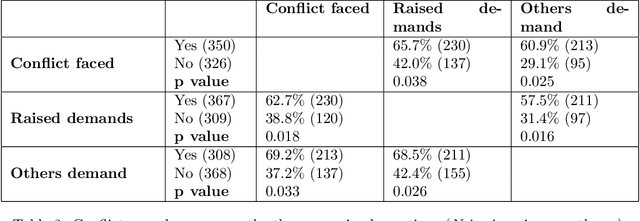
Collaboration among scholars has emerged as a significant characteristic of contemporary science. As a result, the number of authors listed in publications continues to rise steadily. Unfortunately, determining the authors to be included in the byline and their respective order entails multiple difficulties which often lead to conflicts. Despite the large volume of literature about conflicts in academia, it remains unclear how exactly it is distributed over the main socio-demographic properties, as well as the different types of interactions academics experience. To address this gap, we conducted an international and cross-disciplinary survey answered by 752 academics from 41 fields of research and 93 countries that statistically well-represent the overall academic workforce. Our findings are concerning and suggest that authorship credit conflicts arise very early in one's academic career, even at the level of Master and Ph.D., and become increasingly common over time.
On Neural Architectures for Deep Learning-based Source Separation of Co-Channel OFDM Signals
Mar 15, 2023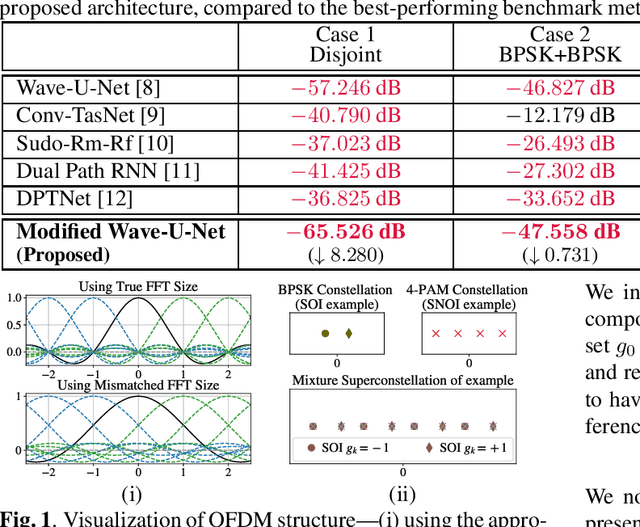
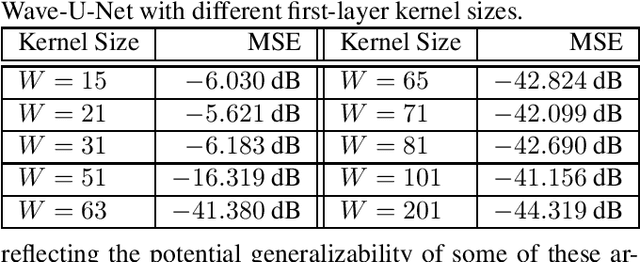
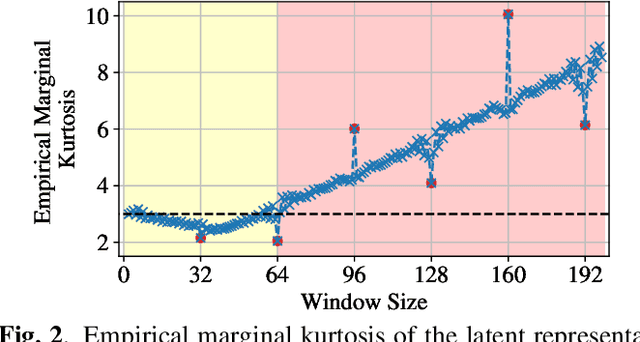
We study the single-channel source separation problem involving orthogonal frequency-division multiplexing (OFDM) signals, which are ubiquitous in many modern-day digital communication systems. Related efforts have been pursued in monaural source separation, where state-of-the-art neural architectures have been adopted to train an end-to-end separator for audio signals (as 1-dimensional time series). In this work, through a prototype problem based on the OFDM source model, we assess -- and question -- the efficacy of using audio-oriented neural architectures in separating signals based on features pertinent to communication waveforms. Perhaps surprisingly, we demonstrate that in some configurations, where perfect separation is theoretically attainable, these audio-oriented neural architectures perform poorly in separating co-channel OFDM waveforms. Yet, we propose critical domain-informed modifications to the network parameterization, based on insights from OFDM structures, that can confer about 30 dB improvement in performance.
Bayesian Learning for the Robust Verification of Autonomous Robots
Mar 15, 2023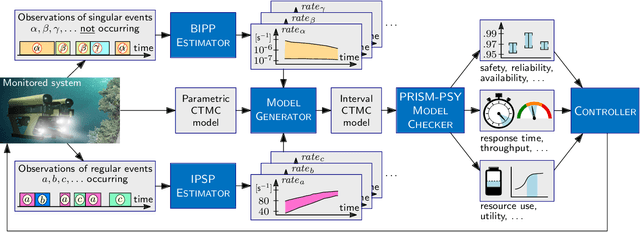

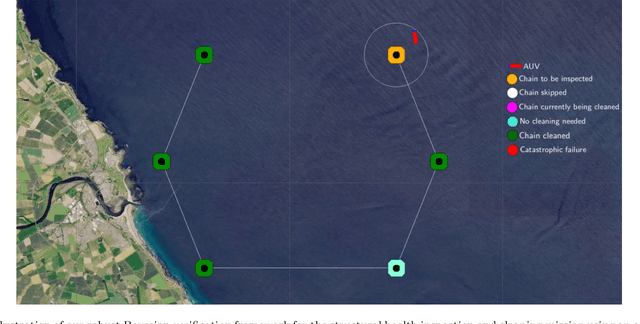
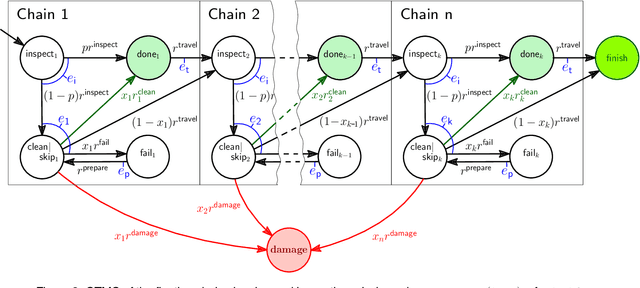
We develop a novel Bayesian learning framework that enables the runtime verification of autonomous robots performing critical missions in uncertain environments. Our framework exploits prior knowledge and observations of the verified robotic system to learn expected ranges of values for the occurrence rates of its events. We support both events observed regularly during system operation, and singular events such as catastrophic failures or the completion of difficult one-off tasks. Furthermore, we use the learnt event-rate ranges to assemble interval continuous-time Markov models, and we apply quantitative verification to these models to compute expected intervals of variation for key system properties. These intervals reflect the uncertainty intrinsic to many real-world systems, enabling the robust verification of their quantitative properties under parametric uncertainty. We apply the proposed framework to the case study of verification of an autonomous robotic mission for underwater infrastructure inspection and repair.
TMA: Temporal Motion Aggregation for Event-based Optical Flow
Mar 21, 2023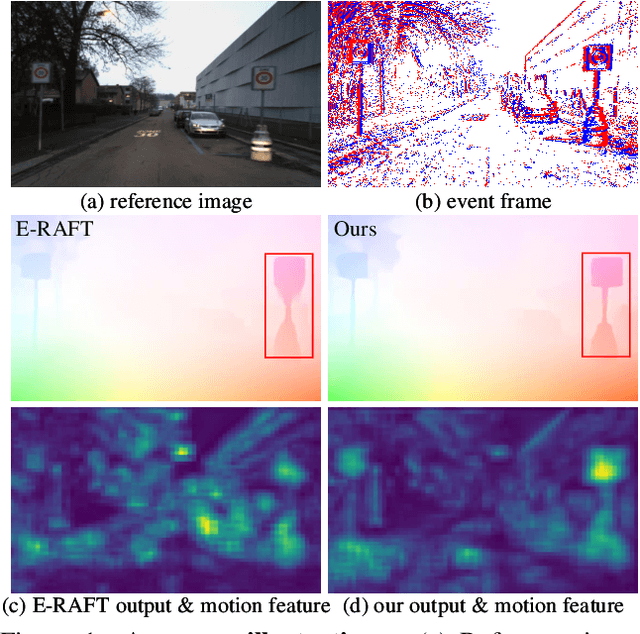
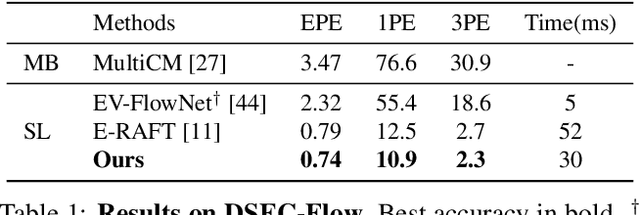
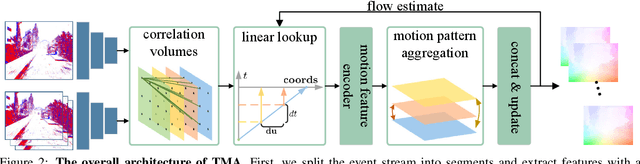
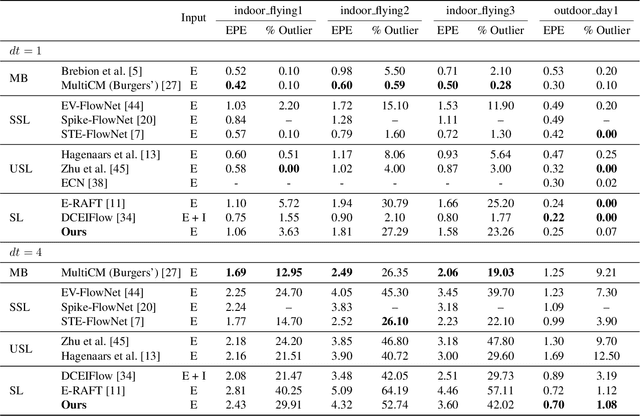
Event cameras have the ability to record continuous and detailed trajectories of objects with high temporal resolution, thereby providing intuitive motion cues for optical flow estimation. Nevertheless, most existing learning-based approaches for event optical flow estimation directly remould the paradigm of conventional images by representing the consecutive event stream as static frames, ignoring the inherent temporal continuity of event data. In this paper, we argue that temporal continuity is a vital element of event-based optical flow and propose a novel Temporal Motion Aggregation (TMA) approach to unlock its potential. Technically, TMA comprises three components: an event splitting strategy to incorporate intermediate motion information underlying the temporal context, a linear lookup strategy to align temporally continuous motion features and a novel motion pattern aggregation module to emphasize consistent patterns for motion feature enhancement. By incorporating temporally continuous motion information, TMA can derive better flow estimates than existing methods at early stages, which not only enables TMA to obtain more accurate final predictions, but also greatly reduces the demand for a number of refinements. Extensive experiments on DESC-Flow and MVSEC datasets verify the effectiveness and superiority of our TMA. Remarkably, compared to E-RAFT, TMA achieves a 6% improvement in accuracy and a 40% reduction in inference time on DSEC-Flow.
Coarse-to-Fine Active Segmentation of Interactable Parts in Real Scene Images
Mar 21, 2023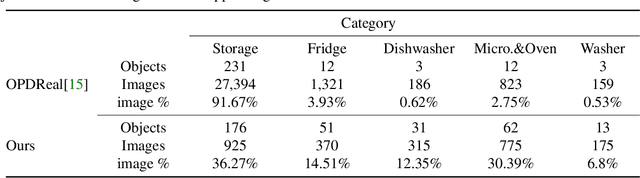
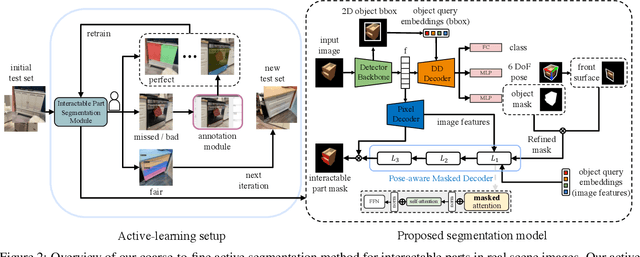


We introduce the first active learning (AL) framework for high-accuracy instance segmentation of dynamic, interactable parts from RGB images of real indoor scenes. As with most human-in-the-loop approaches, the key criterion for success in AL is to minimize human effort while still attaining high performance. To this end, we employ a transformer-based segmentation network that utilizes a masked-attention mechanism. To enhance the network, tailoring to our task, we introduce a coarse-to-fine model which first uses object-aware masked attention and then a pose-aware one, leveraging a correlation between interactable parts and object poses and leading to improved handling of multiple articulated objects in an image. Our coarse-to-fine active segmentation module learns both 2D instance and 3D pose information using the transformer, which supervises the active segmentation and effectively reduces human effort. Our method achieves close to fully accurate (96% and higher) segmentation results on real images, with 77% time saving over manual effort, where the training data consists of only 16.6% annotated real photographs. At last, we contribute a dataset of 2,550 real photographs with annotated interactable parts, demonstrating its superior quality and diversity over the current best alternative.
Efficiently Explaining CSPs with Unsatisfiable Subset Optimization (extended algorithms and examples)
Mar 21, 2023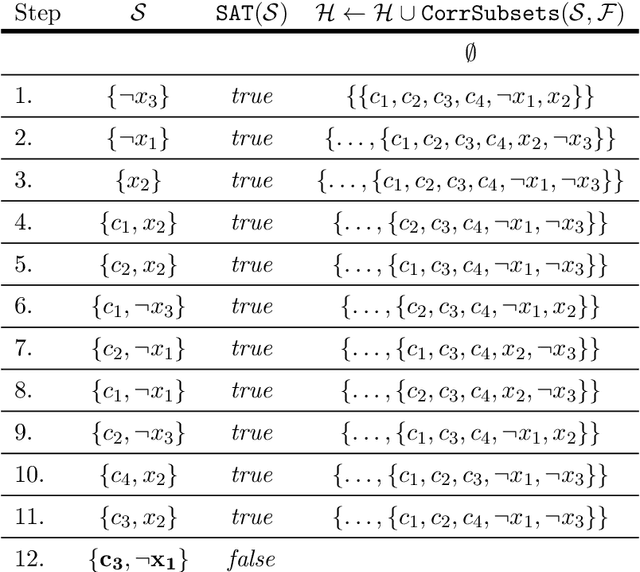
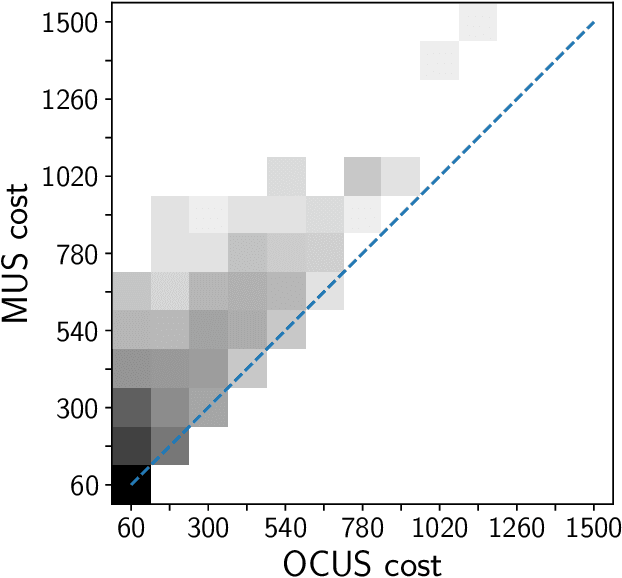

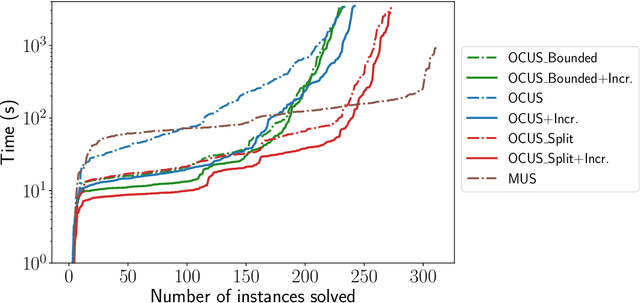
We build on a recently proposed method for stepwise explaining solutions of Constraint Satisfaction Problems (CSP) in a human-understandable way. An explanation here is a sequence of simple inference steps where simplicity is quantified using a cost function. The algorithms for explanation generation rely on extracting Minimal Unsatisfiable Subsets (MUS) of a derived unsatisfiable formula, exploiting a one-to-one correspondence between so-called non-redundant explanations and MUSs. However, MUS extraction algorithms do not provide any guarantee of subset minimality or optimality with respect to a given cost function. Therefore, we build on these formal foundations and tackle the main points of improvement, namely how to generate explanations efficiently that are provably optimal (with respect to the given cost metric). For that, we developed (1) a hitting set-based algorithm for finding the optimal constrained unsatisfiable subsets; (2) a method for re-using relevant information over multiple algorithm calls; and (3) methods exploiting domain-specific information to speed up the explanation sequence generation. We experimentally validated our algorithms on a large number of CSP problems. We found that our algorithms outperform the MUS approach in terms of explanation quality and computational time (on average up to 56 % faster than a standard MUS approach).
Full or Weak annotations? An adaptive strategy for budget-constrained annotation campaigns
Mar 21, 2023
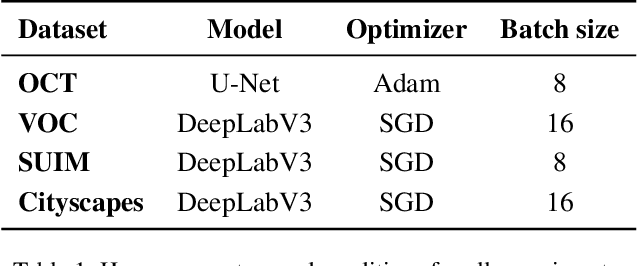
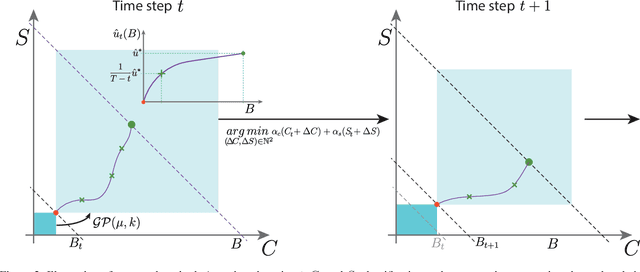

Annotating new datasets for machine learning tasks is tedious, time-consuming, and costly. For segmentation applications, the burden is particularly high as manual delineations of relevant image content are often extremely expensive or can only be done by experts with domain-specific knowledge. Thanks to developments in transfer learning and training with weak supervision, segmentation models can now also greatly benefit from annotations of different kinds. However, for any new domain application looking to use weak supervision, the dataset builder still needs to define a strategy to distribute full segmentation and other weak annotations. Doing so is challenging, however, as it is a priori unknown how to distribute an annotation budget for a given new dataset. To this end, we propose a novel approach to determine annotation strategies for segmentation datasets, whereby estimating what proportion of segmentation and classification annotations should be collected given a fixed budget. To do so, our method sequentially determines proportions of segmentation and classification annotations to collect for budget-fractions by modeling the expected improvement of the final segmentation model. We show in our experiments that our approach yields annotations that perform very close to the optimal for a number of different annotation budgets and datasets.
A Step Closer Towards 5G mmWave-based Multipath Positioning in Dense Urban Environments
Mar 02, 2023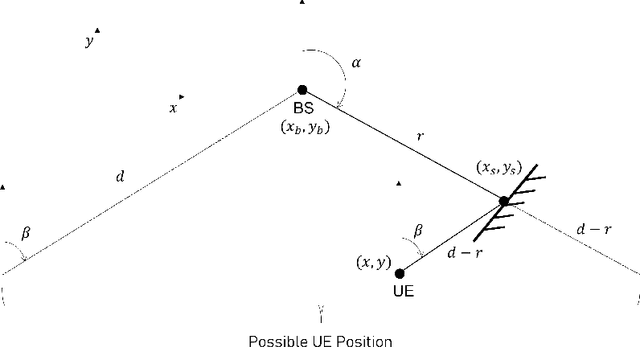
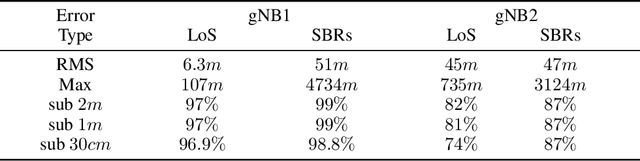
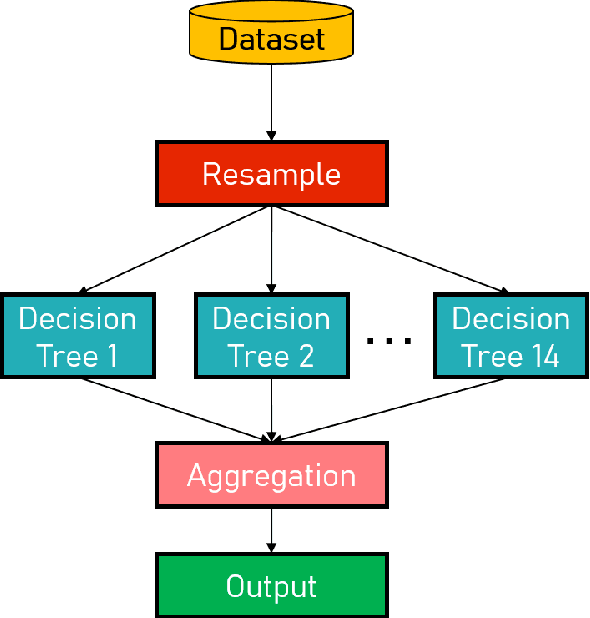
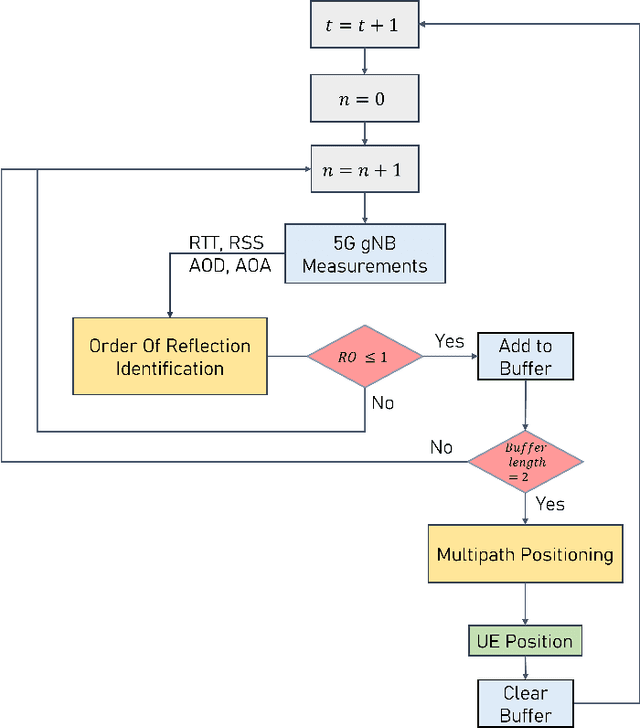
5G mmWave technology can turn multipath into a friend, as multipath components become highly resolvable in the time and angle domains. Multipath signals have not only been used in the literature to position the user equipment (UE) but also to create a map of the surrounding environment. Yet, many multipath-based methods in the literature share a common assumption, which entails that multipath signals are caused by single-bounce reflections only, which is not usually the case. There are very few methods in the literature that accurately filters out higher-order reflections, which renders the exploitation of multipath signals challenging. This paper proposes an ensemble learning-based model for classifying signal paths based on their order of reflection using 5G channel parameters. The model is trained on a large dataset of 3.6 million observations obtained from a quasi-real ray-tracing based 5G simulator that utilizes 3D maps of real-world downtown environments. The trained model had a testing accuracy of 99.5%. A single-bounce reflection-based positioning method was used to validate the positioning error. The trained model enabled the positioning solution to maintain sub-30cm level accuracy 97% of the time.