 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Fast Attention Requires Bounded Entries
Feb 26, 2023
In modern machine learning, inner product attention computation is a fundamental task for training large language models such as Transformer, GPT-1, BERT, GPT-2, GPT-3 and ChatGPT. Formally, in this problem, one is given as input three matrices $Q, K, V \in [-B,B]^{n \times d}$, and the goal is to construct the matrix $\mathrm{Att}(Q,K,V) := \mathrm{diag}(A {\bf 1}_n)^{-1} A V \in \mathbb{R}^{n \times d}$, where $A = \exp(QK^\top/d)$ is the `attention matrix', and $\exp$ is applied entry-wise. Straightforward methods for this problem explicitly compute the $n \times n$ attention matrix $A$, and hence require time $\Omega(n^2)$ even when $d = n^{o(1)}$ is small. In this paper, we investigate whether faster algorithms are possible by implicitly making use of the matrix $A$. We present two results, showing that there is a sharp transition at $B = \Theta(\sqrt{\log n})$. $\bullet$ If $d = O(\log n)$ and $B = o(\sqrt{\log n})$, there is an $n^{1+o(1)}$ time algorithm to approximate $\mathrm{Att}(Q,K,V)$ up to $1/\mathrm{poly}(n)$ additive error. $\bullet$ If $d = O(\log n)$ and $B = \Theta (\sqrt{\log n})$, assuming the Strong Exponential Time Hypothesis from fine-grained complexity theory, it is impossible to approximate $\mathrm{Att}(Q,K,V)$ up to $1/\mathrm{poly}(n)$ additive error in truly subquadratic time $n^{2 - \Omega(1)}$. This gives a theoretical explanation for the phenomenon observed in practice that attention computation is much more efficient when the input matrices have smaller entries.
MoRF: Mobile Realistic Fullbody Avatars from a Monocular Video
Mar 17, 2023
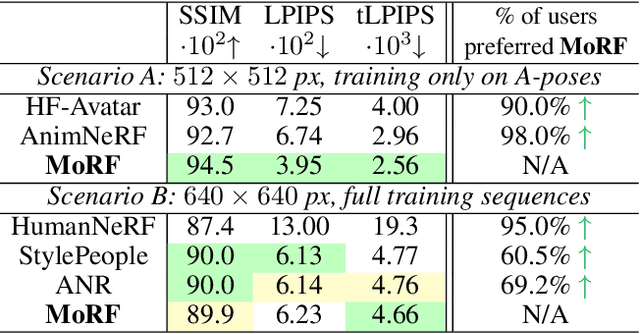
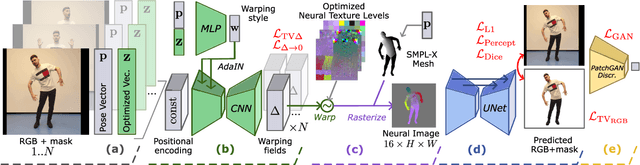
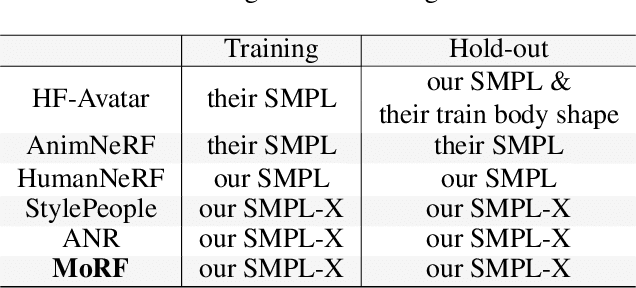
We present a new approach for learning Mobile Realistic Fullbody (MoRF) avatars. MoRF avatars can be rendered in real-time on mobile phones, have high realism, and can be learned from monocular videos. As in previous works, we use a combination of neural textures and the mesh-based body geometry modeling SMPL-X. We improve on prior work, by learning per-frame warping fields in the neural texture space, allowing to better align the training signal between different frames. We also apply existing SMPL-X fitting procedure refinements for videos to improve overall avatar quality. In the comparisons to other monocular video-based avatar systems, MoRF avatars achieve higher image sharpness and temporal consistency. Participants of our user study also preferred avatars generated by MoRF.
Route to Time and Time to Route: Travel Time Estimation from Sparse Trajectories
Jun 21, 2022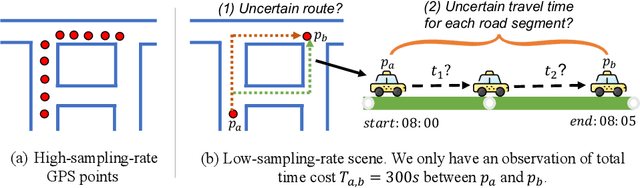
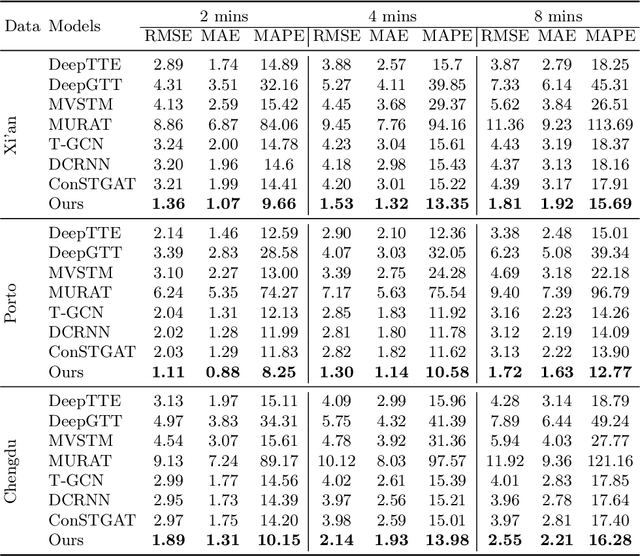
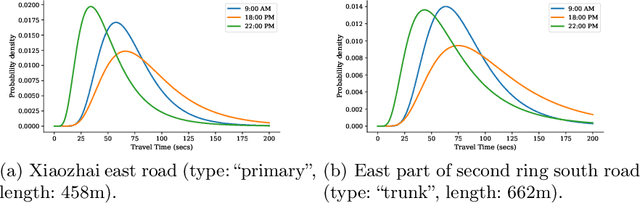
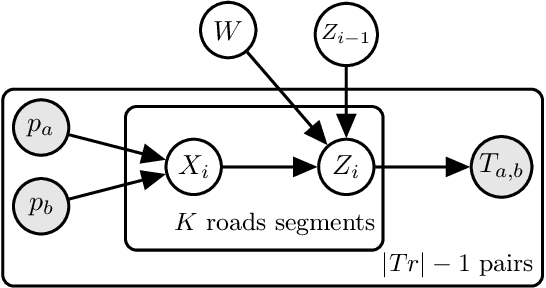
Due to the rapid development of Internet of Things (IoT) technologies, many online web apps (e.g., Google Map and Uber) estimate the travel time of trajectory data collected by mobile devices. However, in reality, complex factors, such as network communication and energy constraints, make multiple trajectories collected at a low sampling rate. In this case, this paper aims to resolve the problem of travel time estimation (TTE) and route recovery in sparse scenarios, which often leads to the uncertain label of travel time and route between continuously sampled GPS points. We formulate this problem as an inexact supervision problem in which the training data has coarsely grained labels and jointly solve the tasks of TTE and route recovery. And we argue that both two tasks are complementary to each other in the model-learning procedure and hold such a relation: more precise travel time can lead to better inference for routes, in turn, resulting in a more accurate time estimation). Based on this assumption, we propose an EM algorithm to alternatively estimate the travel time of inferred route through weak supervision in E step and retrieve the route based on estimated travel time in M step for sparse trajectories. We conducted experiments on three real-world trajectory datasets and demonstrated the effectiveness of the proposed method.
CoolPINNs: A Physics-informed Neural Network Modeling of Active Cooling in Vascular Systems
Mar 09, 2023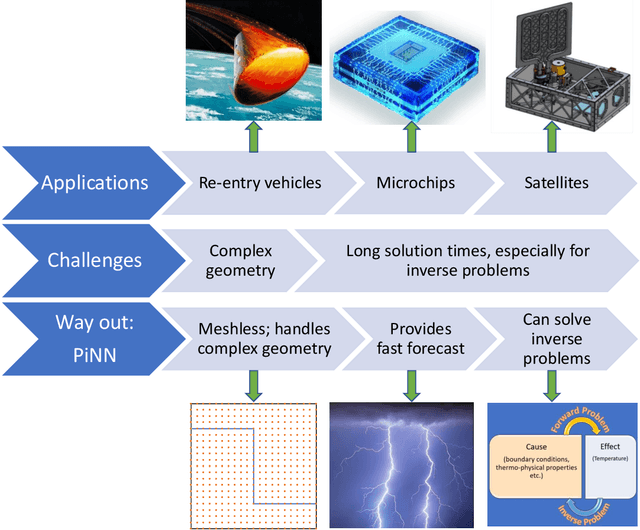

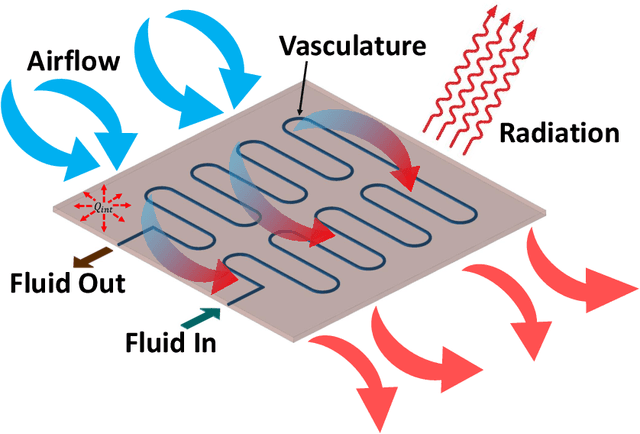
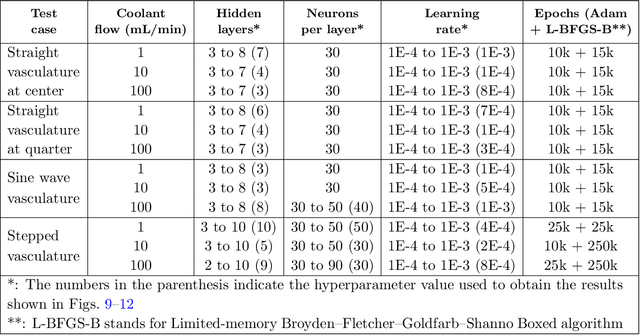
Emerging technologies like hypersonic aircraft, space exploration vehicles, and batteries avail fluid circulation in embedded microvasculatures for efficient thermal regulation. Modeling is vital during these engineered systems' design and operational phases. However, many challenges exist in developing a modeling framework. What is lacking is an accurate framework that (i) captures sharp jumps in the thermal flux across complex vasculature layouts, (ii) deals with oblique derivatives (involving tangential and normal components), (iii) handles nonlinearity because of radiative heat transfer, (iv) provides a high-speed forecast for real-time monitoring, and (v) facilitates robust inverse modeling. This paper addresses these challenges by availing the power of physics-informed neural networks (PINNs). We develop a fast, reliable, and accurate Scientific Machine Learning (SciML) framework for vascular-based thermal regulation -- called CoolPINNs: a PINNs-based modeling framework for active cooling. The proposed mesh-less framework elegantly overcomes all the mentioned challenges. The significance of the reported research is multi-fold. First, the framework is valuable for real-time monitoring of thermal regulatory systems because of rapid forecasting. Second, researchers can address complex thermoregulation designs inasmuch as the approach is mesh-less. Finally, the framework facilitates systematic parameter identification and inverse modeling studies, perhaps the current framework's most significant utility.
Analysis of Expected Hitting Time for Designing Evolutionary Neural Architecture Search Algorithms
Oct 11, 2022
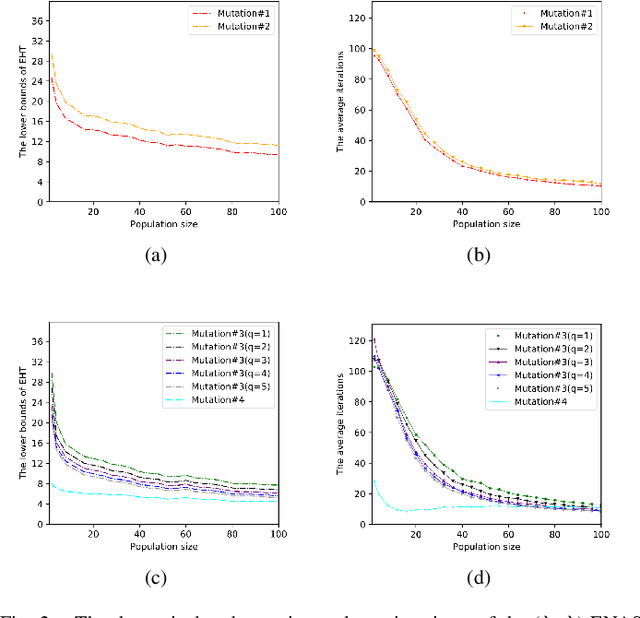
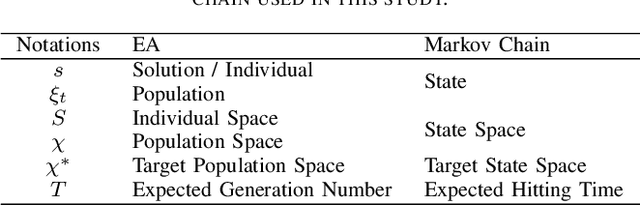
Evolutionary computation-based neural architecture search (ENAS) is a popular technique for automating architecture design of deep neural networks. In recent years, various ENAS algorithms have been proposed and shown promising performance on diverse real-world applications. In contrast to these groundbreaking applications, there is no theoretical guideline for assigning a reasonable running time (mainly affected by the generation number, population size, and evolution operator) given both the anticipated performance and acceptable computation budget on ENAS problems. The expected hitting time (EHT), which refers to the average generations, is considered to analyze the running time of ENAS algorithms. This paper proposes a general framework for estimating the EHT of ENAS algorithms, which includes common configuration, search space partition, transition probability estimation, and hitting time analysis. By exploiting the proposed framework, we consider the so-called ($\lambda$+$\lambda$)-ENAS algorithms with different mutation operators and manage to estimate the lower bounds of the EHT {which are critical for the algorithm to find the global optimum}. Furthermore, we study the theoretical results on the NAS-Bench-101 architecture searching problem, and the results show that the one-bit mutation with "bit-based fair mutation" strategy needs less time than the "offspring-based fair mutation" strategy, and the bitwise mutation operator needs less time than the $q$-bit mutation operator. To the best of our knowledge, this is the first work focusing on the theory of ENAS, and the above observation will be substantially helpful in designing efficient ENAS algorithms.
Hiding task-oriented programming complexity: an industrial case study
Mar 04, 2023

The ease of use of robot programming interfaces represents a barrier to robot adoption in several manufacturing sectors because of the need for more expertise from the end-users. Current robot programming methods are mostly the past heritage, with robot programmers reluctant to adopt new programming paradigms. This work aims to evaluate the impact on non-expert users of introducing a new task-oriented programming interface that hides the complexity of a programming framework based on ROS. The paper compares the programming performance of such an interface with a classic robot-oriented programming method based on a state-of-the-art robot teach pendant. An experimental campaign involved 22 non-expert users working on the programming of two industrial tasks. Task-oriented and robot-oriented programming showed comparable learning time, programming time and the number of questions raised during the programming phases, highlighting the possibility of a smooth introduction to task-oriented programming even to non-expert users.
Vid2Seq: Large-Scale Pretraining of a Visual Language Model for Dense Video Captioning
Mar 21, 2023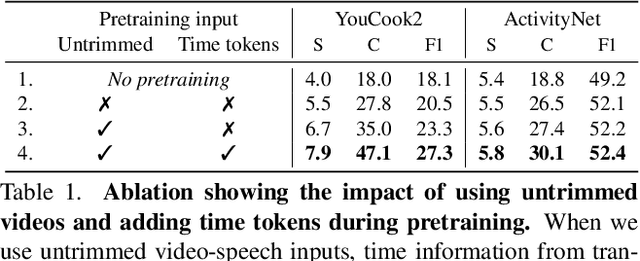
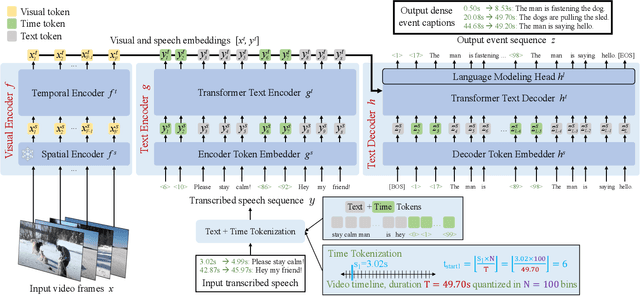
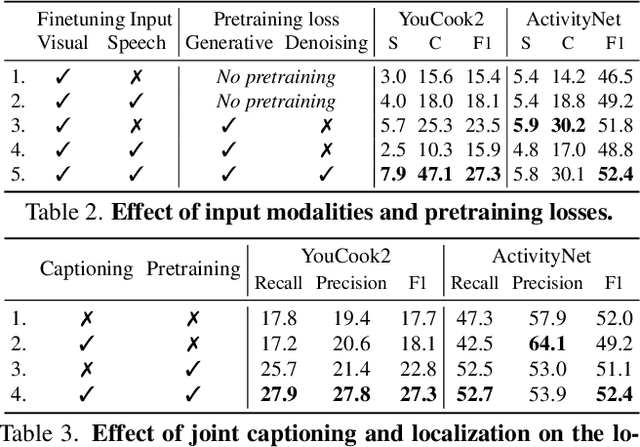
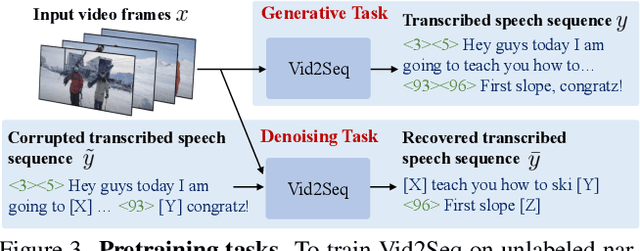
In this work, we introduce Vid2Seq, a multi-modal single-stage dense event captioning model pretrained on narrated videos which are readily-available at scale. The Vid2Seq architecture augments a language model with special time tokens, allowing it to seamlessly predict event boundaries and textual descriptions in the same output sequence. Such a unified model requires large-scale training data, which is not available in current annotated datasets. We show that it is possible to leverage unlabeled narrated videos for dense video captioning, by reformulating sentence boundaries of transcribed speech as pseudo event boundaries, and using the transcribed speech sentences as pseudo event captions. The resulting Vid2Seq model pretrained on the YT-Temporal-1B dataset improves the state of the art on a variety of dense video captioning benchmarks including YouCook2, ViTT and ActivityNet Captions. Vid2Seq also generalizes well to the tasks of video paragraph captioning and video clip captioning, and to few-shot settings. Our code is publicly available at https://antoyang.github.io/vid2seq.html.
LEAPT: Learning Adaptive Prefix-to-prefix Translation For Simultaneous Machine Translation
Mar 21, 2023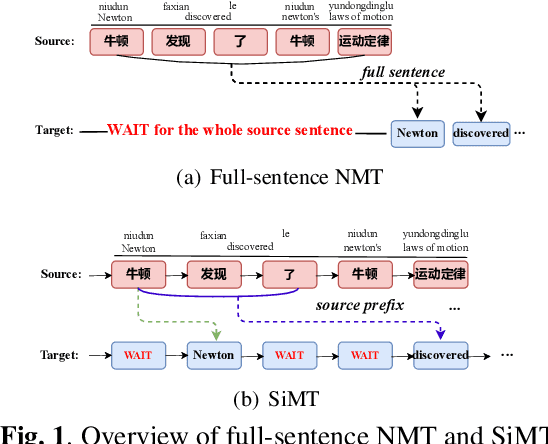

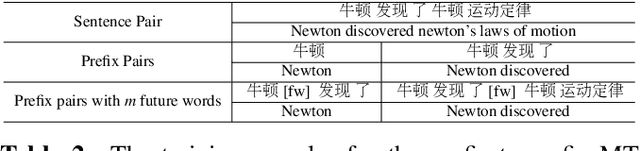
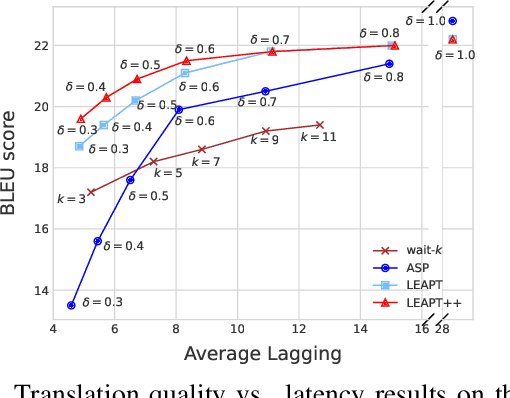
Simultaneous machine translation, which aims at a real-time translation, is useful in many live scenarios but very challenging due to the trade-off between accuracy and latency. To achieve the balance for both, the model needs to wait for appropriate streaming text (READ policy) and then generates its translation (WRITE policy). However, WRITE policies of previous work either are specific to the method itself due to the end-to-end training or suffer from the input mismatch between training and decoding for the non-end-to-end training. Therefore, it is essential to learn a generic and better WRITE policy for simultaneous machine translation. Inspired by strategies utilized by human interpreters and "wait" policies, we propose a novel adaptive prefix-to-prefix training policy called LEAPT, which allows our machine translation model to learn how to translate source sentence prefixes and make use of the future context. Experiments show that our proposed methods greatly outperform competitive baselines and achieve promising results.
Multimodal Continuous Emotion Recognition: A Technical Report for ABAW5
Mar 18, 2023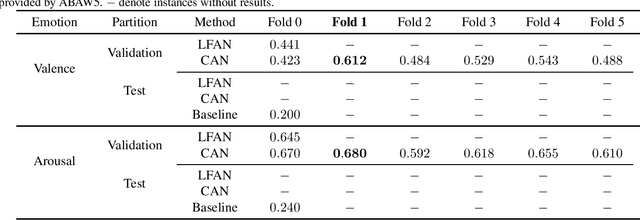
We used two multimodal models for continuous valence-arousal recognition using visual, audio, and linguistic information. The first model is the same as we used in ABAW2 and ABAW3, which employs the leader-follower attention. The second model has the same architecture for spatial and temporal encoding. As for the fusion block, it employs a compact and straightforward channel attention, borrowed from the End2You toolkit. Unlike our previous attempts that use Vggish feature directly as the audio feature, this time we feed the pre-trained VGG model using logmel-spectrogram and finetune it during the training. To make full use of the data and alleviate over-fitting, cross-validation is carried out. The fold with the highest concordance correlation coefficient is selected for submission. The code is to be available at https://github.com/sucv/ABAW5.
Chance-Constrained Multi-Robot Motion Planning under Gaussian Uncertainties
Mar 20, 2023We consider a chance-constrained multi-robot motion planning problem in the presence of Gaussian motion and sensor noise. Our proposed algorithm, CC-K-CBS, leverages the scalability of kinodynamic conflict-based search (K-CBS) in conjunction with the efficiency of the Gaussian belief trees used in the Belief-A framework, and inherits the completeness guarantees of Belief-A's low-level sampling-based planner. We also develop three different methods for robot-robot probabilistic collision checking, which trade off computation with accuracy. Our algorithm generates motion plans driving each robot from its initial state to its goal while accounting for the evolution of its uncertainty with chance-constrained safety guarantees. Benchmarks compare computation time to conservatism of the collision checkers, in addition to characterizing the performance of the planner as a whole. Results show that CC-K-CBS can scale up to 30 robots.