 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
4D iRIOM: 4D Imaging Radar Inertial Odometry and Mapping
Apr 03, 2023
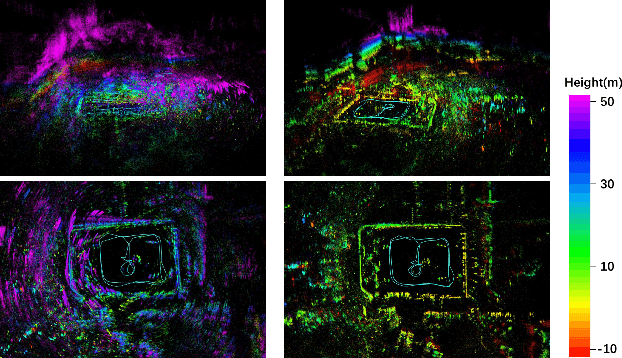
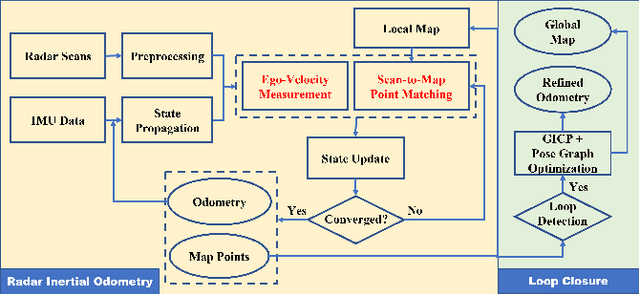

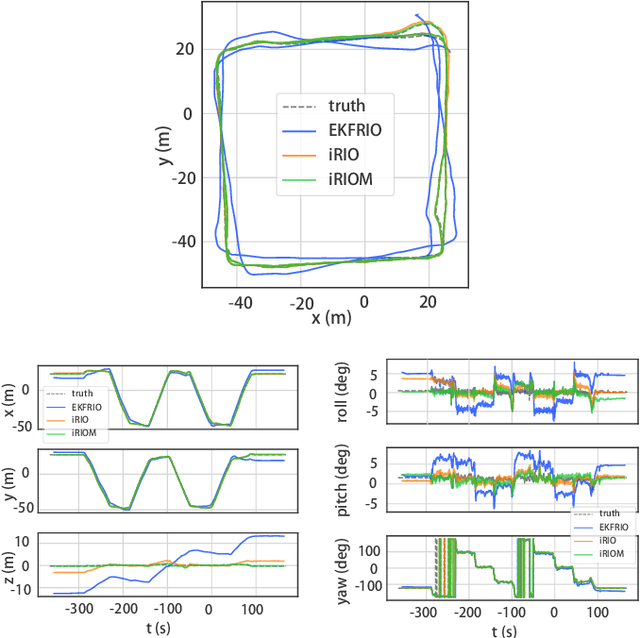
Millimeter wave radar can measure distances, directions, and Doppler velocity for objects in harsh conditions such as fog. The 4D imaging radar with both vertical and horizontal data resembling an image can also measure objects' height. Previous studies have used 3D radars for ego-motion estimation. But few methods leveraged the rich data of imaging radars, and they usually omitted the mapping aspect, thus leading to inferior odometry accuracy. This paper presents a real-time imaging radar inertial odometry and mapping method, iRIOM, based on the submap concept. To deal with moving objects and multipath reflections, we use the graduated non-convexity method to robustly and efficiently estimate ego-velocity from a single scan. To measure the agreement between sparse non-repetitive radar scan points and submap points, the distribution-to-multi-distribution distance for matches is adopted. The ego-velocity, scan-to-submap matches are fused with the 6D inertial data by an iterative extended Kalman filter to get the platform's 3D position and orientation. A loop closure module is also developed to curb the odometry module's drift. To our knowledge, iRIOM based on the two modules is the first 4D radar inertial SLAM system. On our and third-party data, we show iRIOM's favorable odometry accuracy and mapping consistency against the FastLIO-SLAM and the EKFRIO. Also, the ablation study reveal the benefit of inertial data versus the constant velocity model, and scan-to-submap matching versus scan-to-scan matching.
Leveraging Predictive Models for Adaptive Sampling of Spatiotemporal Fluid Processes
Apr 03, 2023
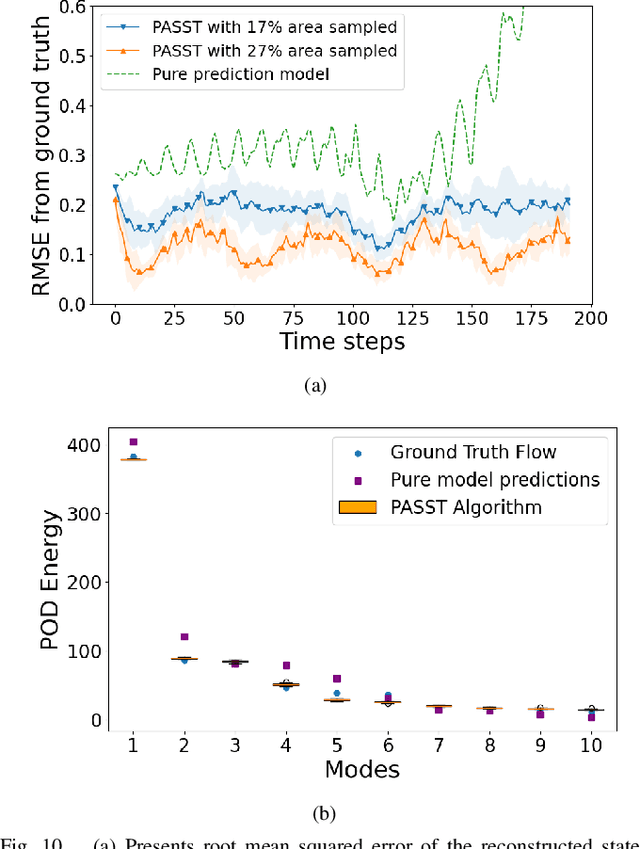
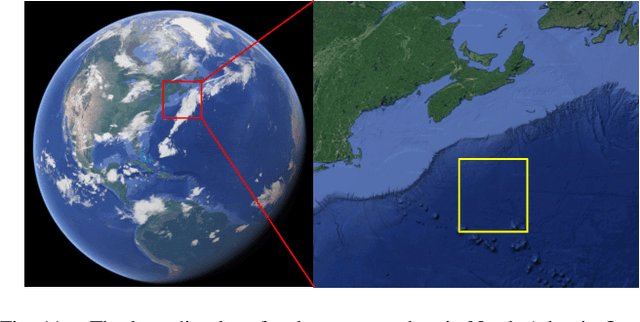
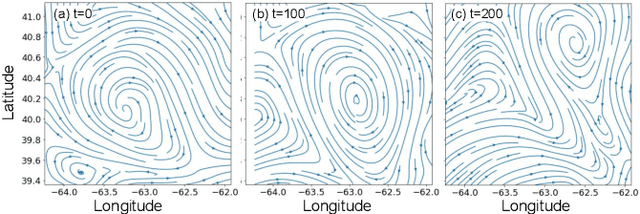
Persistent monitoring of a spatiotemporal fluid process requires data sampling and predictive modeling of the process being monitored. In this paper we present PASST algorithm: Predictive-model based Adaptive Sampling of a Spatio-Temporal process. PASST is an adaptive robotic sampling algorithm that leverages predictive models to efficiently and persistently monitor a fluid process in a given region of interest. Our algorithm makes use of the predictions from a learned prediction model to plan a path for an autonomous vehicle to adaptively and efficiently survey the region of interest. In turn, the sampled data is used to obtain better predictions by giving an updated initial state to the predictive model. For predictive model, we use Knowledged-based Neural Ordinary Differential Equations to train models of fluid processes. These models are orders of magnitude smaller in size and run much faster than fluid data obtained from direct numerical simulations of the partial differential equations that describe the fluid processes or other comparable computational fluids models. For path planning, we use reinforcement learning based planning algorithms that use the field predictions as reward functions. We evaluate our adaptive sampling path planning algorithm on both numerically simulated fluid data and real-world nowcast ocean flow data to show that we can sample the spatiotemporal field in the given region of interest for long time horizons. We also evaluate PASST algorithm's generalization ability to sample from fluid processes that are not in the training repertoire of the learned models.
PoseMatcher: One-shot 6D Object Pose Estimation by Deep Feature Matching
Apr 03, 2023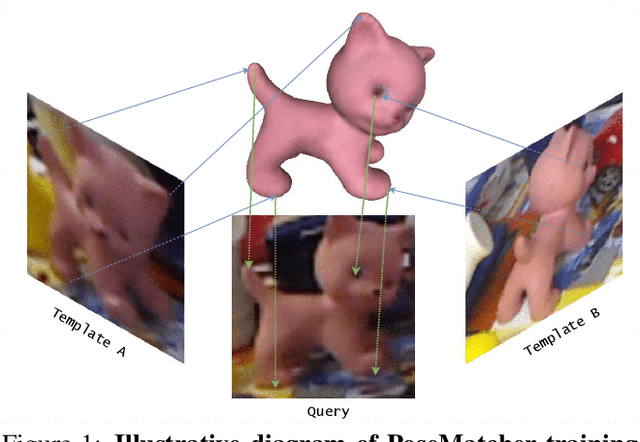
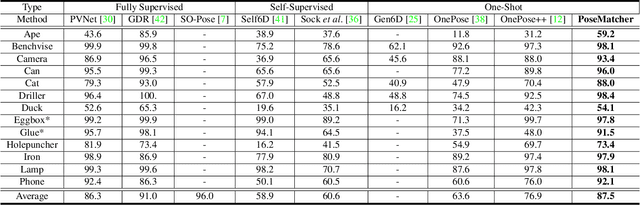
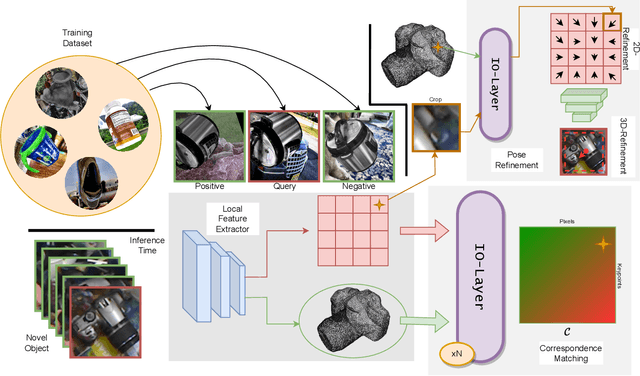
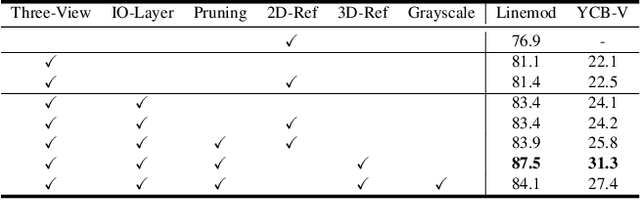
Estimating the pose of an unseen object is the goal of the challenging one-shot pose estimation task. Previous methods have heavily relied on feature matching with great success. However, these methods are often inefficient and limited by their reliance on pre-trained models that have not be designed specifically for pose estimation. In this paper we propose PoseMatcher, an accurate model free one-shot object pose estimator that overcomes these limitations. We create a new training pipeline for object to image matching based on a three-view system: a query with a positive and negative templates. This simple yet effective approach emulates test time scenarios by cheaply constructing an approximation of the full object point cloud during training. To enable PoseMatcher to attend to distinct input modalities, an image and a pointcloud, we introduce IO-Layer, a new attention layer that efficiently accommodates self and cross attention between the inputs. Moreover, we propose a pruning strategy where we iteratively remove redundant regions of the target object to further reduce the complexity and noise of the network while maintaining accuracy. Finally we redesign commonly used pose refinement strategies, zoom and 2D offset refinements, and adapt them to the one-shot paradigm. We outperform all prior one-shot pose estimation methods on the Linemod and YCB-V datasets as well achieve results rivaling recent instance-level methods. The source code and models are available at https://github.com/PedroCastro/PoseMatcher.
Deep trip generation with graph neural networks for bike sharing system expansion
Mar 20, 2023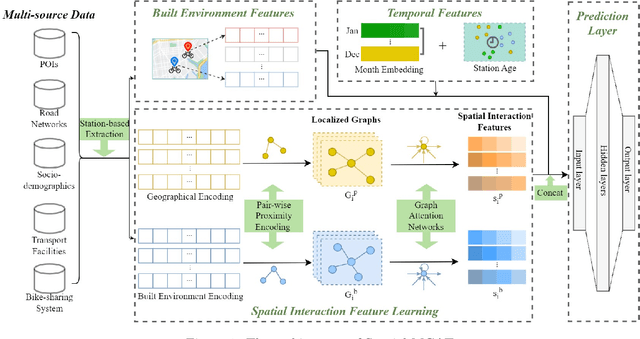
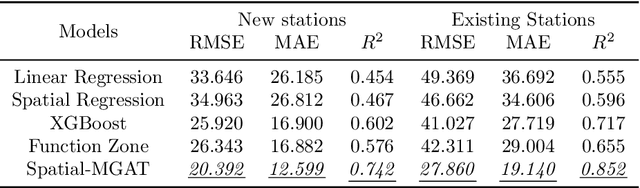
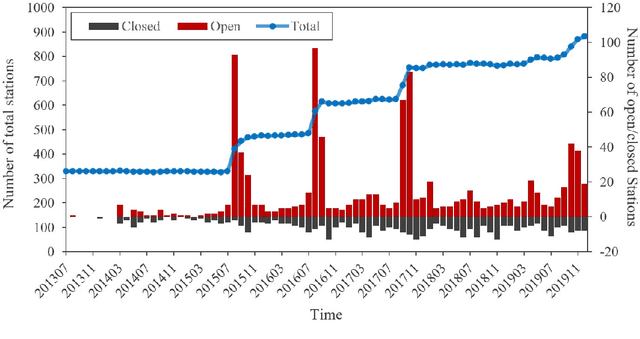
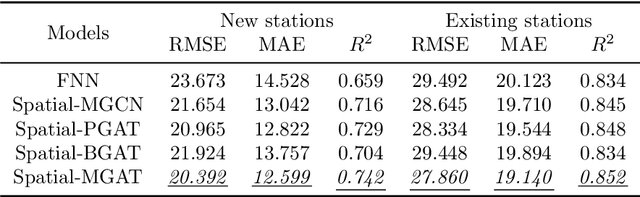
Bike sharing is emerging globally as an active, convenient, and sustainable mode of transportation. To plan successful bike-sharing systems (BSSs), many cities start from a small-scale pilot and gradually expand the system to cover more areas. For station-based BSSs, this means planning new stations based on existing ones over time, which requires prediction of the number of trips generated by these new stations across the whole system. Previous studies typically rely on relatively simple regression or machine learning models, which are limited in capturing complex spatial relationships. Despite the growing literature in deep learning methods for travel demand prediction, they are mostly developed for short-term prediction based on time series data, assuming no structural changes to the system. In this study, we focus on the trip generation problem for BSS expansion, and propose a graph neural network (GNN) approach to predicting the station-level demand based on multi-source urban built environment data. Specifically, it constructs multiple localized graphs centered on each target station and uses attention mechanisms to learn the correlation weights between stations. We further illustrate that the proposed approach can be regarded as a generalized spatial regression model, indicating the commonalities between spatial regression and GNNs. The model is evaluated based on realistic experiments using multi-year BSS data from New York City, and the results validate the superior performance of our approach compared to existing methods. We also demonstrate the interpretability of the model for uncovering the effects of built environment features and spatial interactions between stations, which can provide strategic guidance for BSS station location selection and capacity planning.
Integrated Design of Cooperative Area Coverage and Target Tracking with Multi-UAV System
Mar 16, 2023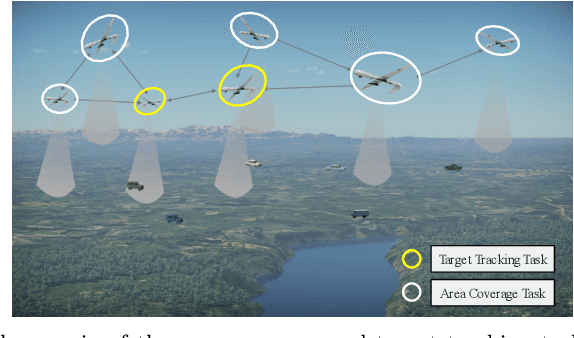

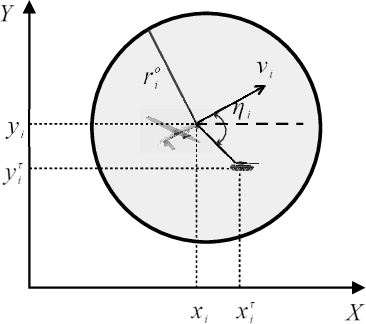

This paper systematically studies the cooperative area coverage and target tracking problem of multiple-unmanned aerial vehicles (multi-UAVs). The problem is solved by decomposing into three sub-problems: information fusion, task assignment, and multi-UAV behavior decision-making. Specifically, in the information fusion process, we use the maximum consistency protocol to update the joint estimation states of multi-targets (JESMT) and the area detection information. The area detection information is represented by the equivalent visiting time map (EVTM), which is built based on the detection probability and the actual visiting time of the area. Then, we model the task assignment problem of multi-UAV searching and tracking multi-targets as a network flow model with upper and lower flow bounds. An algorithm named task assignment minimum-cost maximum-flow (TAMM) is proposed. Cooperative behavior decision-making uses Fisher information as the mission reward to obtain the optimal tracking action of the UAV. Furthermore, a coverage behavior decision-making algorithm based on the anti-flocking method is designed for those UAVs assigned the coverage task. Finally, a distributed multi-UAV cooperative area coverage and target tracking algorithm is designed, which integrates information fusion, task assignment, and behavioral decision-making. Numerical and hardware-in-the-loop simulation results show that the proposed method can achieve persistent area coverage and cooperative target tracking.
Adaptive Modeling of Uncertainties for Traffic Forecasting
Mar 16, 2023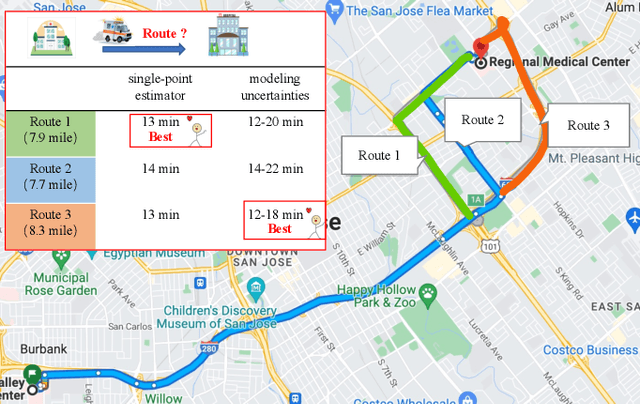


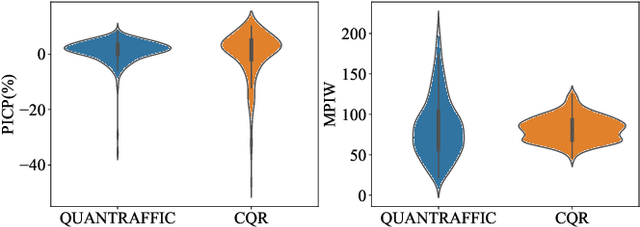
Deep neural networks (DNNs) have emerged as a dominant approach for developing traffic forecasting models. These models are typically trained to minimize error on averaged test cases and produce a single-point prediction, such as a scalar value for traffic speed or travel time. However, single-point predictions fail to account for prediction uncertainty that is critical for many transportation management scenarios, such as determining the best- or worst-case arrival time. We present QuanTraffic, a generic framework to enhance the capability of an arbitrary DNN model for uncertainty modeling. QuanTraffic requires little human involvement and does not change the base DNN architecture during deployment. Instead, it automatically learns a standard quantile function during the DNN model training to produce a prediction interval for the single-point prediction. The prediction interval defines a range where the true value of the traffic prediction is likely to fall. Furthermore, QuanTraffic develops an adaptive scheme that dynamically adjusts the prediction interval based on the location and prediction window of the test input. We evaluated QuanTraffic by applying it to five representative DNN models for traffic forecasting across seven public datasets. We then compared QuanTraffic against five uncertainty quantification methods. Compared to the baseline uncertainty modeling techniques, QuanTraffic with base DNN architectures delivers consistently better and more robust performance than the existing ones on the reported datasets.
Generalized Representations Learning for Time Series Classification
Sep 15, 2022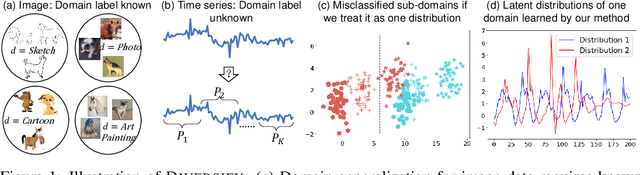
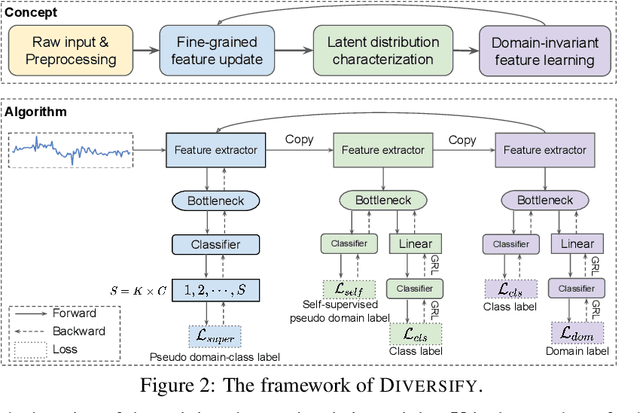
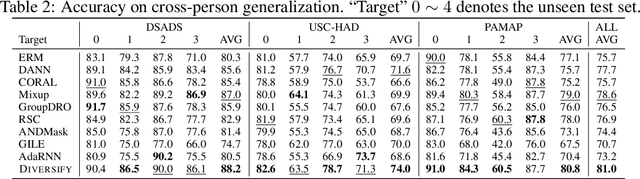
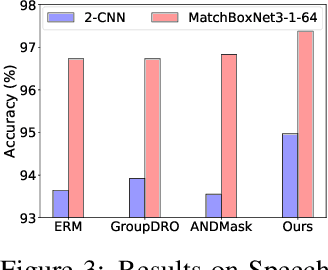
Time series classification is an important problem in real world. Due to its non-stationary property that the distribution changes over time, it remains challenging to build models for generalization to unseen distributions. In this paper, we propose to view the time series classification problem from the distribution perspective. We argue that the temporal complexity attributes to the unknown latent distributions within. To this end, we propose DIVERSIFY to learn generalized representations for time series classification. DIVERSIFY takes an iterative process: it first obtains the worst-case distribution scenario via adversarial training, then matches the distributions of the obtained sub-domains. We also present some theoretical insights. We conduct experiments on gesture recognition, speech commands recognition, wearable stress and affect detection, and sensor-based human activity recognition with a total of seven datasets in different settings. Results demonstrate that DIVERSIFY significantly outperforms other baselines and effectively characterizes the latent distributions by qualitative and quantitative analysis.
Bistatic CRLBs for TTD array resource allocation during JCAS
Mar 13, 2023
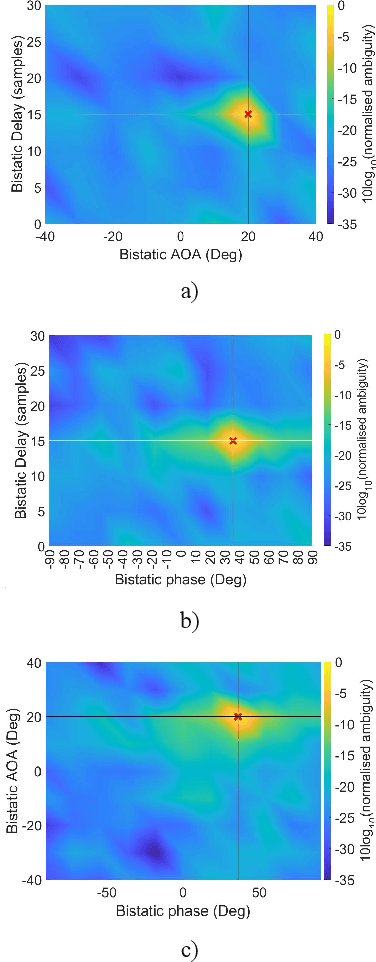
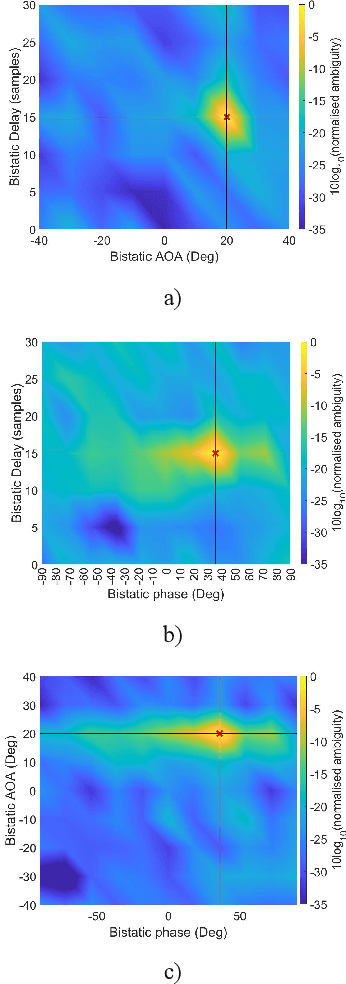
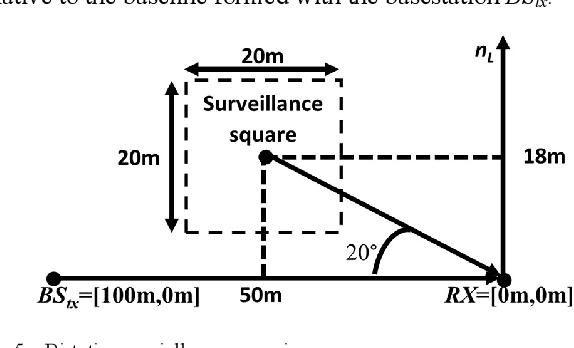
This paper conveys the theoretical sensing capability of a Joint Communication and Sensing (JCAS) system that utilizes a True-Time-Delay (TTD) array configuration. The TTD beamformer separates subcarrier beams into different angular locations for wide-beam coverage. The bistatic sensing performance of a TTD array configuration is modeled as a function of the number of array elements and the fractional power supplied by the transmitter. The sensing capability when employing a TTD array configuration is derived using the Cram\'er-Rao Lower Bound (CRLB) of a bistatic delay-AOA(Angle Of Arrival)-phase log-likelihood function which is obtained by cross-correlating complex eigenvectors extracted from the quadratic time-frequency domain representation of multicomponent phase-coded signals. The multicomponent phase-codes used here are synchronization signals that are defined by the 5G communications standard. The bistatic delay-AOA-phase estimation capability whilst utilizing these signals and a TTD configuration was seen to be highly non-linear with respect to the number of elements and fractional power supplied for the surveillance scenario shown; an allocation of 30 antenna elements supplied with maximum power made a sub-meter and sub-degree estimation capability theoretically possible.
A Smoothing Algorithm for Minimum Sensing Path Plans in Gaussian Belief Space
Mar 13, 2023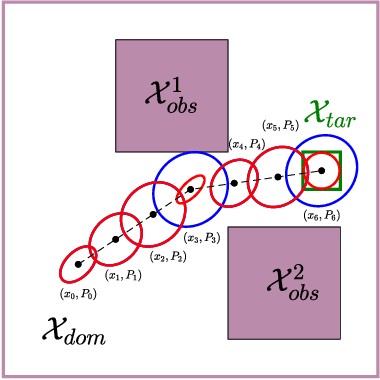
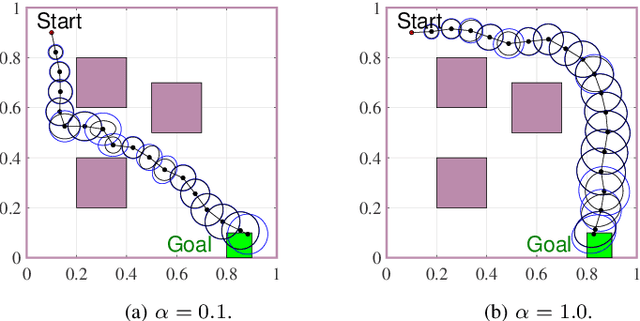
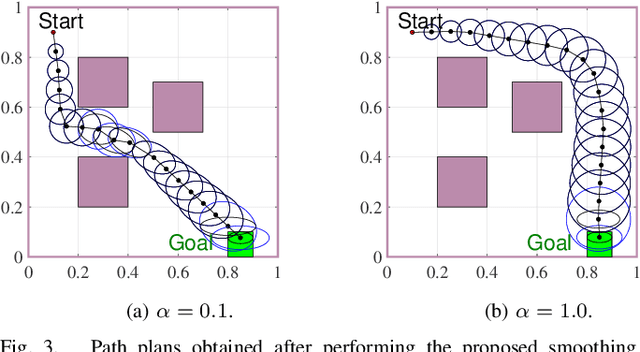
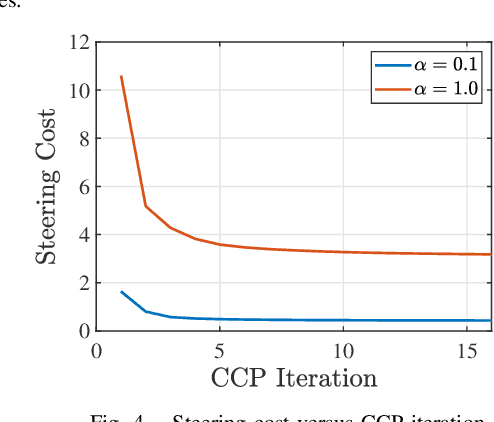
This paper explores minimum sensing navigation of robots in environments cluttered with obstacles. The general objective is to find a path plan to a goal region that requires minimal sensing effort. In [1], the information-geometric RRT* (IG-RRT*) algorithm was proposed to efficiently find such a path. However, like any stochastic sampling-based planner, the computational complexity of IG-RRT* grows quickly, impeding its use with a large number of nodes. To remedy this limitation, we suggest running IG-RRT* with a moderate number of nodes, and then using a smoothing algorithm to adjust the path obtained. To develop a smoothing algorithm, we explicitly formulate the minimum sensing path planning problem as an optimization problem. For this formulation, we introduce a new safety constraint to impose a bound on the probability of collision with obstacles in continuous-time, in contrast to the common discrete-time approach. The problem is amenable to solution via the convex-concave procedure (CCP). We develop a CCP algorithm for the formulated optimization and use this algorithm for path smoothing. We demonstrate the efficacy of the proposed approach through numerical simulations.
NeurEPDiff: Neural Operators to Predict Geodesics in Deformation Spaces
Mar 13, 2023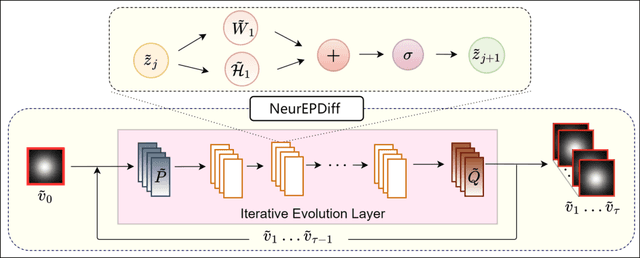
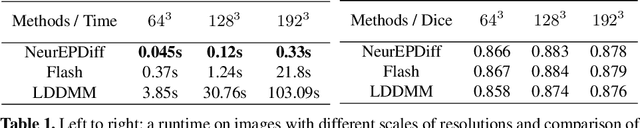
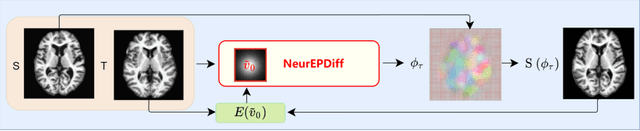

This paper presents NeurEPDiff, a novel network to fast predict the geodesics in deformation spaces generated by a well known Euler-Poincar\'e differential equation (EPDiff). To achieve this, we develop a neural operator that for the first time learns the evolving trajectory of geodesic deformations parameterized in the tangent space of diffeomorphisms(a.k.a velocity fields). In contrast to previous methods that purely fit the training images, our proposed NeurEPDiff learns a nonlinear mapping function between the time-dependent velocity fields. A composition of integral operators and smooth activation functions is formulated in each layer of NeurEPDiff to effectively approximate such mappings. The fact that NeurEPDiff is able to rapidly provide the numerical solution of EPDiff (given any initial condition) results in a significantly reduced computational cost of geodesic shooting of diffeomorphisms in a high-dimensional image space. Additionally, the properties of discretiztion/resolution-invariant of NeurEPDiff make its performance generalizable to multiple image resolutions after being trained offline. We demonstrate the effectiveness of NeurEPDiff in registering two image datasets: 2D synthetic data and 3D brain resonance imaging (MRI). The registration accuracy and computational efficiency are compared with the state-of-the-art diffeomophic registration algorithms with geodesic shooting.