 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Heat flux for semi-local machine-learning potentials
Mar 25, 2023
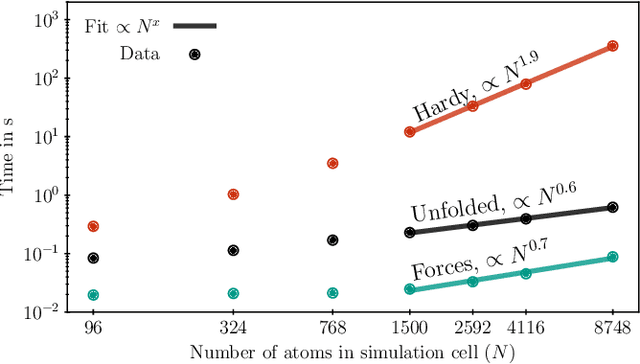
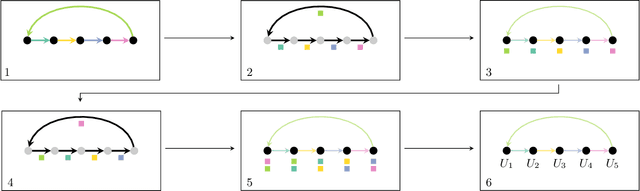
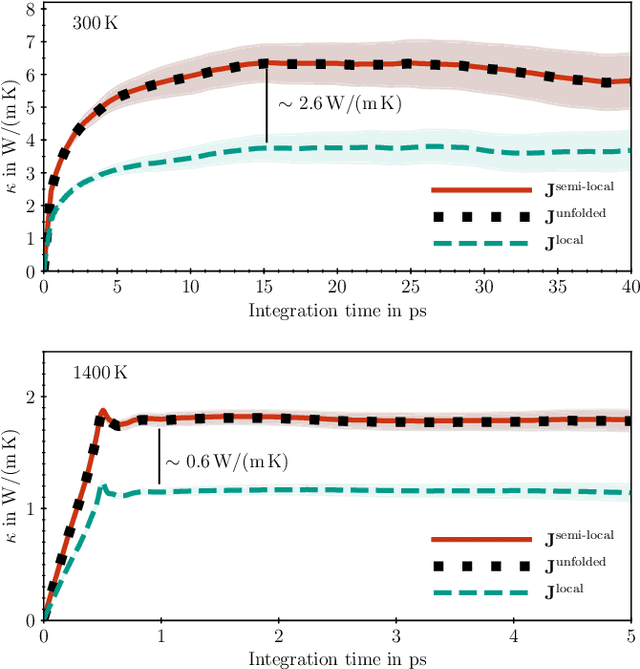
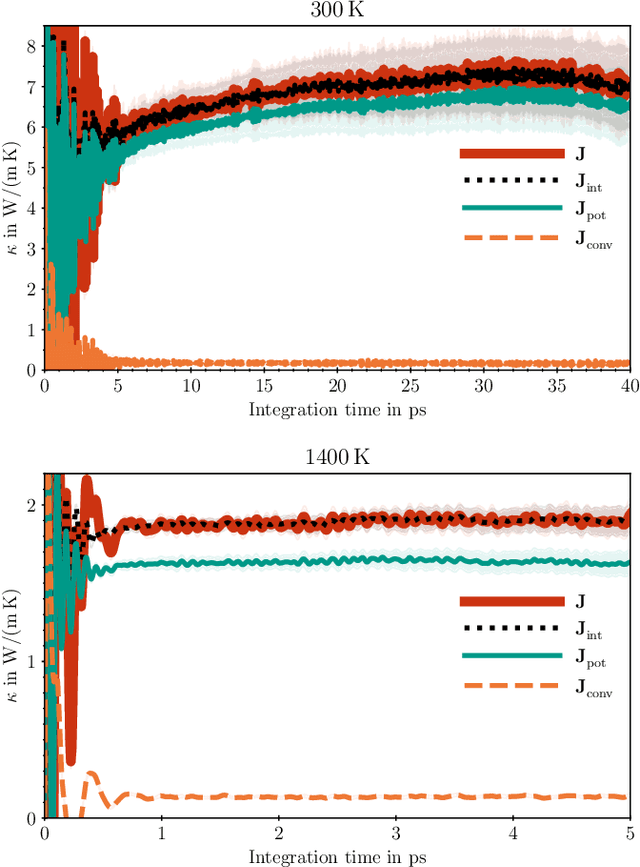
The Green-Kubo (GK) method is a rigorous framework for heat transport simulations in materials. However, it requires an accurate description of the potential-energy surface and carefully converged statistics. Machine-learning potentials can achieve the accuracy of first-principles simulations while allowing to reach well beyond their simulation time and length scales at a fraction of the cost. In this paper, we explain how to apply the GK approach to the recent class of message-passing machine-learning potentials, which iteratively consider semi-local interactions beyond the initial interaction cutoff. We derive an adapted heat flux formulation that can be implemented using automatic differentiation without compromising computational efficiency. The approach is demonstrated and validated by calculating the thermal conductivity of zirconium dioxide across temperatures.
VMesh: Hybrid Volume-Mesh Representation for Efficient View Synthesis
Mar 28, 2023
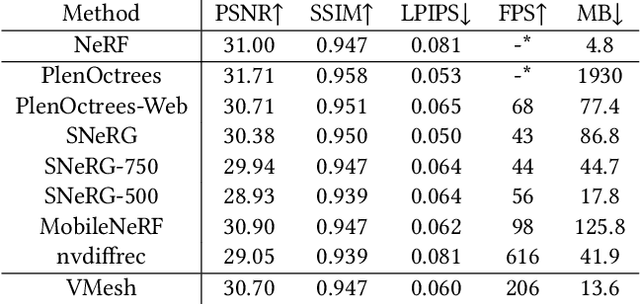
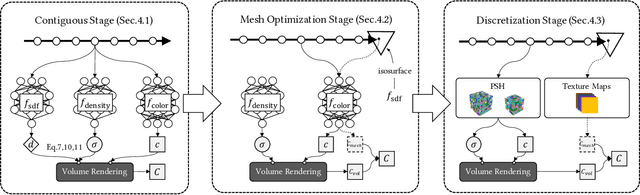
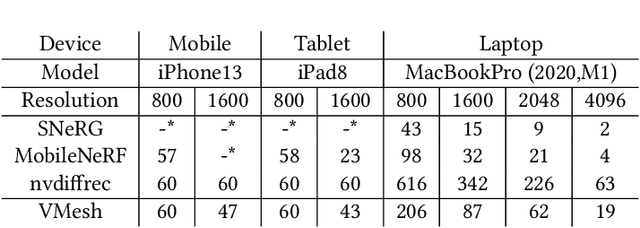
With the emergence of neural radiance fields (NeRFs), view synthesis quality has reached an unprecedented level. Compared to traditional mesh-based assets, this volumetric representation is more powerful in expressing scene geometry but inevitably suffers from high rendering costs and can hardly be involved in further processes like editing, posing significant difficulties in combination with the existing graphics pipeline. In this paper, we present a hybrid volume-mesh representation, VMesh, which depicts an object with a textured mesh along with an auxiliary sparse volume. VMesh retains the advantages of mesh-based assets, such as efficient rendering, compact storage, and easy editing, while also incorporating the ability to represent subtle geometric structures provided by the volumetric counterpart. VMesh can be obtained from multi-view images of an object and renders at 2K 60FPS on common consumer devices with high fidelity, unleashing new opportunities for real-time immersive applications.
Adversarial Robustness of Learning-based Static Malware Classifiers
Mar 20, 2023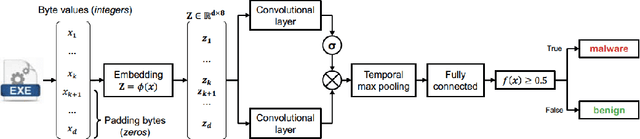
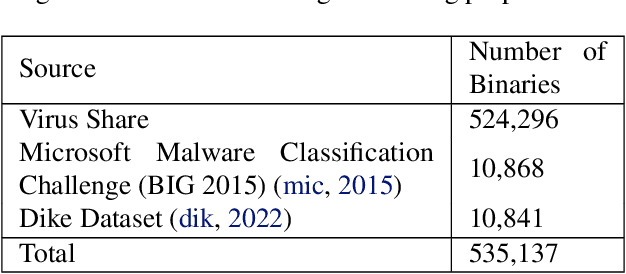
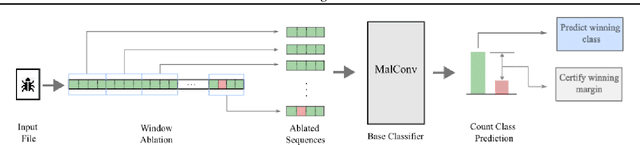
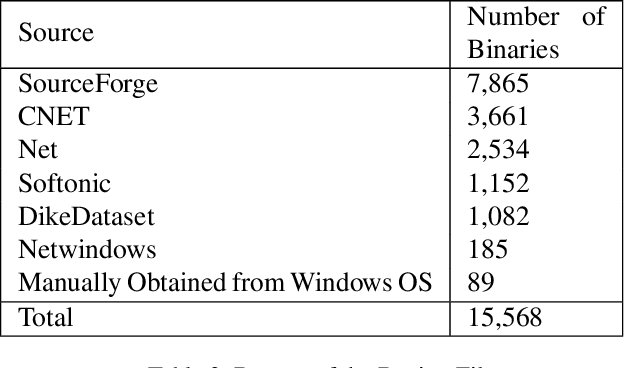
Malware detection has long been a stage for an ongoing arms race between malware authors and anti-virus systems. Solutions that utilize machine learning (ML) gain traction as the scale of this arms race increases. This trend, however, makes performing attacks directly on ML an attractive prospect for adversaries. We study this arms race from both perspectives in the context of MalConv, a popular convolutional neural network-based malware classifier that operates on raw bytes of files. First, we show that MalConv is vulnerable to adversarial patch attacks: appending a byte-level patch to malware files bypasses detection 94.3% of the time. Moreover, we develop a universal adversarial patch (UAP) attack where a single patch can drop the detection rate in constant time of any malware file that contains it by 80%. These patches are effective even being relatively small with respect to the original file size -- between 2%-8%. As a countermeasure, we then perform window ablation that allows us to apply de-randomized smoothing, a modern certified defense to patch attacks in vision tasks, to raw files. The resulting `smoothed-MalConv' can detect over 80% of malware that contains the universal patch and provides certified robustness up to 66%, outlining a promising step towards robust malware detection. To our knowledge, we are the first to apply universal adversarial patch attack and certified defense using ablations on byte level in the malware field.
Detecting post-stroke aphasia using EEG-based neural envelope tracking of natural speech
Mar 14, 2023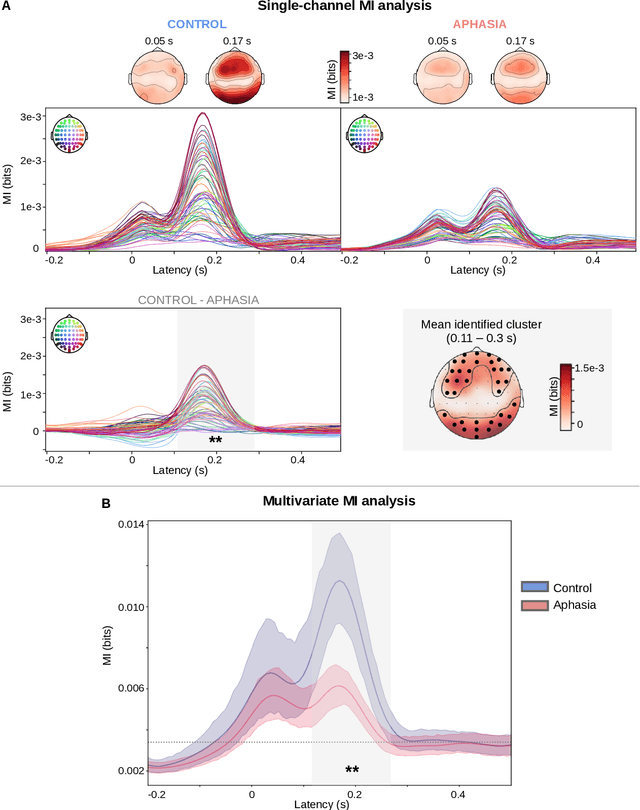
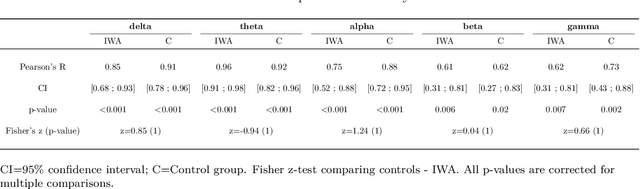
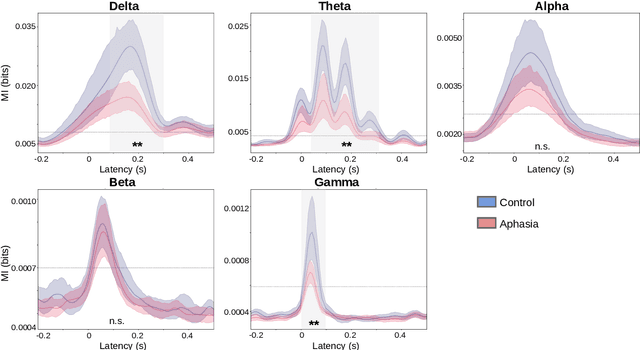
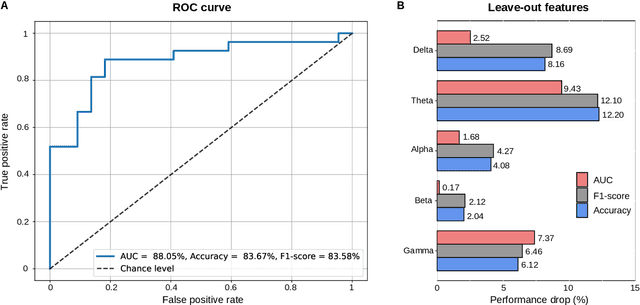
[Objective]. After a stroke, one-third of patients suffer from aphasia, a language disorder that impairs communication ability. The standard behavioral tests used to diagnose aphasia are time-consuming and have low ecological validity. Neural tracking of the speech envelope is a promising tool for investigating brain responses to natural speech. The speech envelope is crucial for speech understanding, encompassing cues for processing linguistic units. In this study, we aimed to test the potential of the neural envelope tracking technique for detecting language impairments in individuals with aphasia (IWA). [Approach]. We recorded EEG from 27 IWA in the chronic phase after stroke and 22 controls while they listened to a story. We quantified neural envelope tracking in a broadband frequency range as well as in the delta, theta, alpha, beta, and gamma frequency bands using mutual information analysis. Besides group differences in neural tracking measures, we also tested its suitability for detecting aphasia using a Support Vector Machine (SVM) classifier. We further investigated the required recording length for the SVM to detect aphasia and to obtain reliable outcomes. [Results]. IWA displayed decreased neural envelope tracking compared to controls in the broad, delta, theta, and gamma band. Neural tracking in these frequency bands effectively captured aphasia at the individual level (SVM accuracy 84%, AUC 88%). High-accuracy and reliable detection could be obtained with 5-7 minutes of recording time. [Significance]. Our study shows that neural tracking of speech is an effective biomarker for aphasia. We demonstrated its potential as a diagnostic tool with high reliability, individual-level detection of aphasia, and time-efficient assessment. This work represents a significant step towards more automatic, objective, and ecologically valid assessments of language impairments in aphasia.
Optimal Mixed-ADC arrangement for DOA Estimation via CRB using ULA
Mar 27, 2023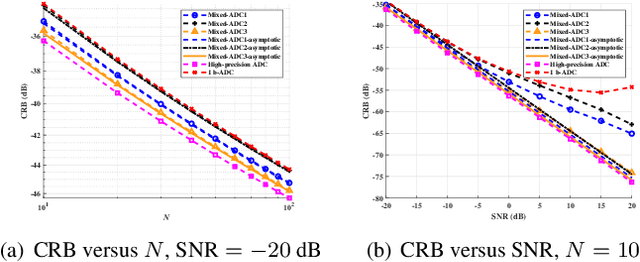
We consider a mixed analog-to-digital converter (ADC) based architecture for direction of arrival (DOA) estimation using a uniform linear array (ULA). We derive the Cram{\'e}r-Rao bound (CRB) of the DOA under the optimal time-varying threshold, and find that the asymptotic CRB is related to the arrangement of high-precision and one-bit ADCs for a fixed number of ADCs. Then, a new concept called ``mixed-precision arrangement" is proposed. It is proven that better performance for DOA estimation is achieved when high-precision ADCs are distributed evenly around the edges of the ULA. This result can be extended to a more general case where the ULA is equipped with various precision ADCs. Simulation results show the validity of the asymptotic CRB and better performance under the optimal mixed-precision arrangement.
Black Box Few-Shot Adaptation for Vision-Language models
Apr 04, 2023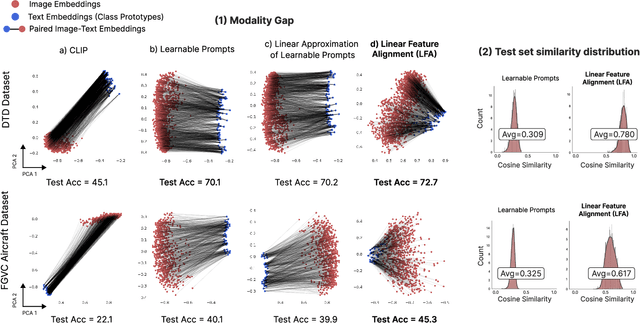
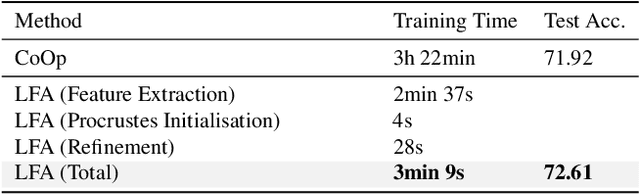
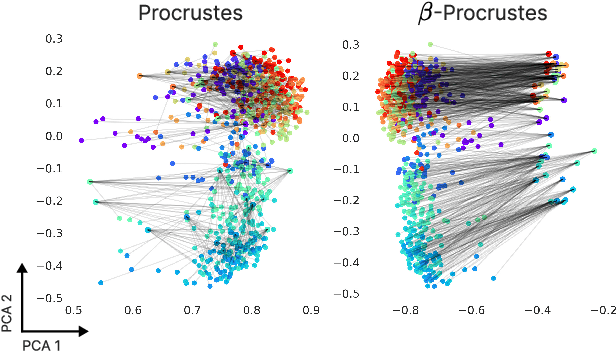
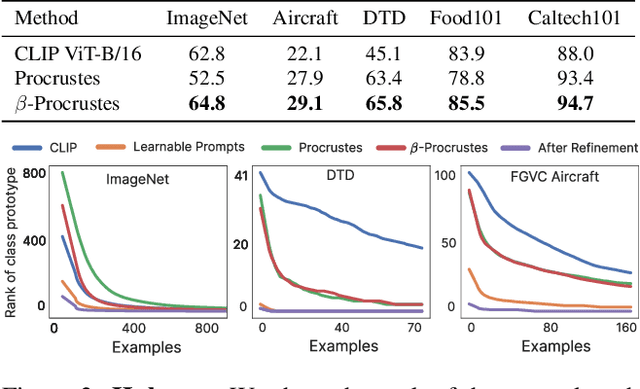
Vision-Language (V-L) models trained with contrastive learning to align the visual and language modalities have been shown to be strong few-shot learners. Soft prompt learning is the method of choice for few-shot downstream adaption aiming to bridge the modality gap caused by the distribution shift induced by the new domain. While parameter-efficient, prompt learning still requires access to the model weights and can be computationally infeasible for large models with billions of parameters. To address these shortcomings, in this work, we describe a black-box method for V-L few-shot adaptation that (a) operates on pre-computed image and text features and hence works without access to the model's weights, (b) it is orders of magnitude faster at training time, (c) it is amenable to both supervised and unsupervised training, and (d) it can be even used to align image and text features computed from uni-modal models. To achieve this, we propose Linear Feature Alignment (LFA), a simple linear approach for V-L re-alignment in the target domain. LFA is initialized from a closed-form solution to a least-squares problem and then it is iteratively updated by minimizing a re-ranking loss. Despite its simplicity, our approach can even surpass soft-prompt learning methods as shown by extensive experiments on 11 image and 2 video datasets.
Hierarchical Supervision and Shuffle Data Augmentation for 3D Semi-Supervised Object Detection
Apr 04, 2023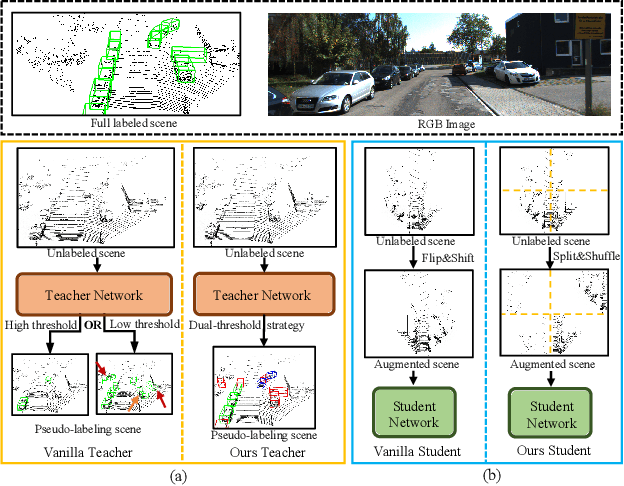

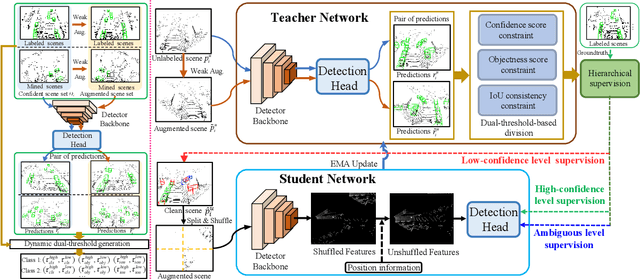

State-of-the-art 3D object detectors are usually trained on large-scale datasets with high-quality 3D annotations. However, such 3D annotations are often expensive and time-consuming, which may not be practical for real applications. A natural remedy is to adopt semi-supervised learning (SSL) by leveraging a limited amount of labeled samples and abundant unlabeled samples. Current pseudolabeling-based SSL object detection methods mainly adopt a teacher-student framework, with a single fixed threshold strategy to generate supervision signals, which inevitably brings confused supervision when guiding the student network training. Besides, the data augmentation of the point cloud in the typical teacher-student framework is too weak, and only contains basic down sampling and flip-and-shift (i.e., rotate and scaling), which hinders the effective learning of feature information. Hence, we address these issues by introducing a novel approach of Hierarchical Supervision and Shuffle Data Augmentation (HSSDA), which is a simple yet effective teacher-student framework. The teacher network generates more reasonable supervision for the student network by designing a dynamic dual-threshold strategy. Besides, the shuffle data augmentation strategy is designed to strengthen the feature representation ability of the student network. Extensive experiments show that HSSDA consistently outperforms the recent state-of-the-art methods on different datasets. The code will be released at https://github.com/azhuantou/HSSDA.
End-to-End Latency Optimization of Multi-view 3D Reconstruction for Disaster Response
Apr 04, 2023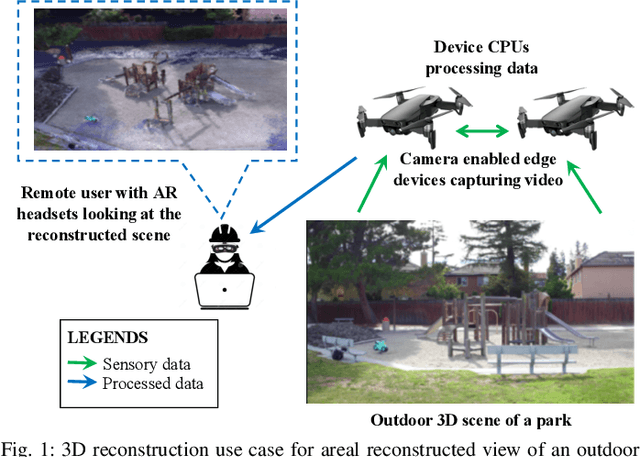
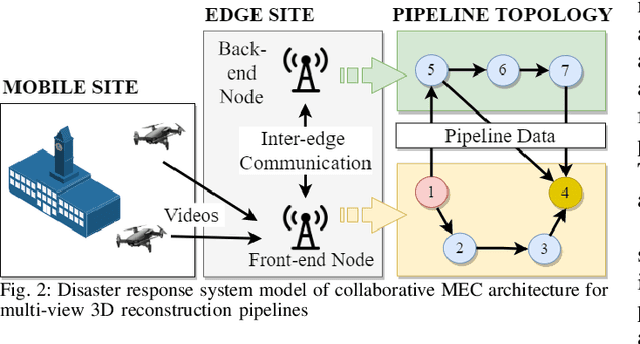

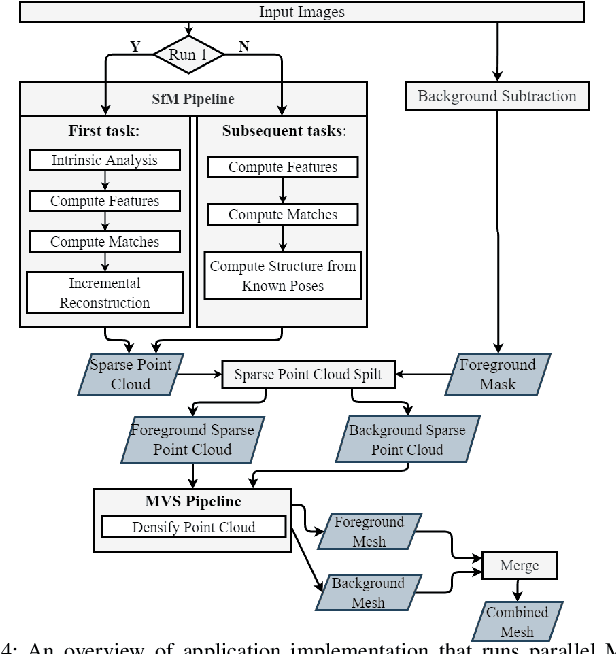
In order to plan rapid response during disasters, first responder agencies often adopt `bring your own device' (BYOD) model with inexpensive mobile edge devices (e.g., drones, robots, tablets) for complex video analytics applications, e.g., 3D reconstruction of a disaster scene. Unlike simpler video applications, widely used Multi-view Stereo (MVS) based 3D reconstruction applications (e.g., openMVG/openMVS) are exceedingly time consuming, especially when run on such computationally constrained mobile edge devices. Additionally, reducing the reconstruction latency of such inherently sequential algorithms is challenging as unintelligent, application-agnostic strategies can drastically degrade the reconstruction (i.e., application outcome) quality making them useless. In this paper, we aim to design a latency optimized MVS algorithm pipeline, with the objective to best balance the end-to-end latency and reconstruction quality by running the pipeline on a collaborative mobile edge environment. The overall optimization approach is two-pronged where: (a) application optimizations introduce data-level parallelism by splitting the pipeline into high frequency and low frequency reconstruction components and (b) system optimizations incorporate task-level parallelism to the pipelines by running them opportunistically on available resources with online quality control in order to balance both latency and quality. Our evaluation on a hardware testbed using publicly available datasets shows upto ~54% reduction in latency with negligible loss (~4-7%) in reconstruction quality.
MESAHA-Net: Multi-Encoders based Self-Adaptive Hard Attention Network with Maximum Intensity Projections for Lung Nodule Segmentation in CT Scan
Apr 04, 2023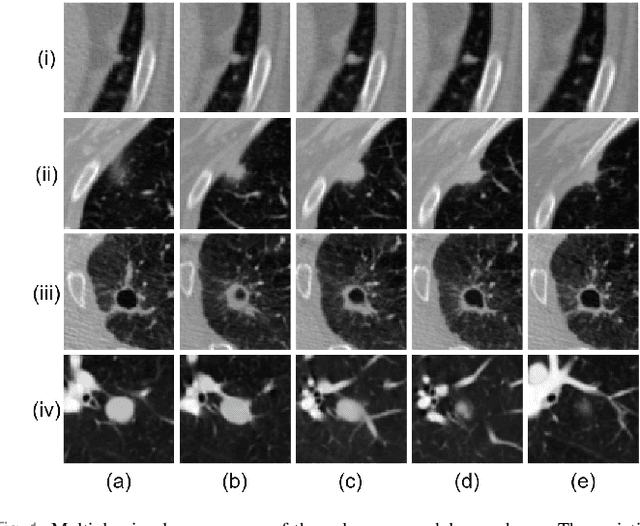
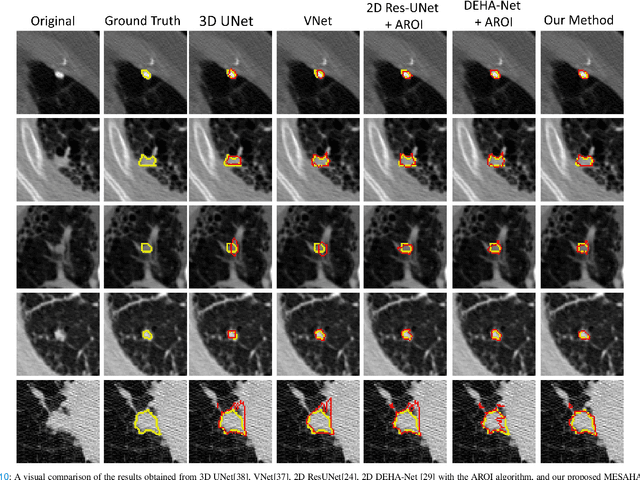
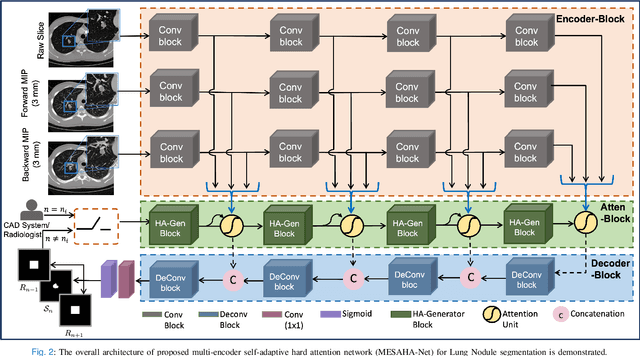
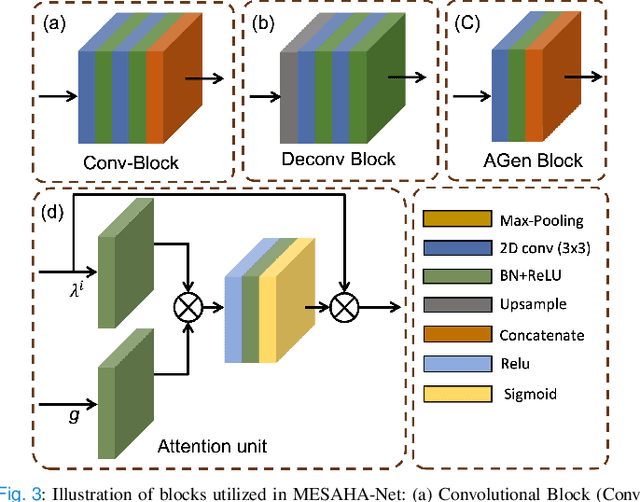
Accurate lung nodule segmentation is crucial for early-stage lung cancer diagnosis, as it can substantially enhance patient survival rates. Computed tomography (CT) images are widely employed for early diagnosis in lung nodule analysis. However, the heterogeneity of lung nodules, size diversity, and the complexity of the surrounding environment pose challenges for developing robust nodule segmentation methods. In this study, we propose an efficient end-to-end framework, the multi-encoder-based self-adaptive hard attention network (MESAHA-Net), for precise lung nodule segmentation in CT scans. MESAHA-Net comprises three encoding paths, an attention block, and a decoder block, facilitating the integration of three types of inputs: CT slice patches, forward and backward maximum intensity projection (MIP) images, and region of interest (ROI) masks encompassing the nodule. By employing a novel adaptive hard attention mechanism, MESAHA-Net iteratively performs slice-by-slice 2D segmentation of lung nodules, focusing on the nodule region in each slice to generate 3D volumetric segmentation of lung nodules. The proposed framework has been comprehensively evaluated on the LIDC-IDRI dataset, the largest publicly available dataset for lung nodule segmentation. The results demonstrate that our approach is highly robust for various lung nodule types, outperforming previous state-of-the-art techniques in terms of segmentation accuracy and computational complexity, rendering it suitable for real-time clinical implementation.
Robust Outlier Rejection for 3D Registration with Variational Bayes
Apr 04, 2023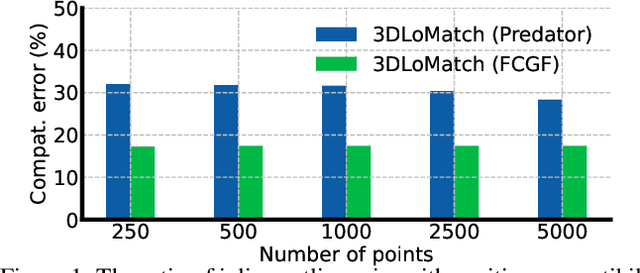
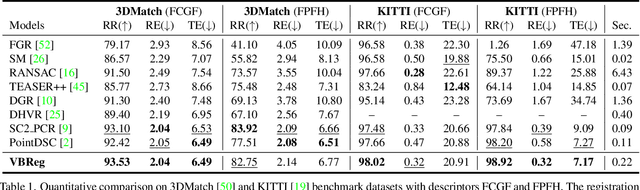
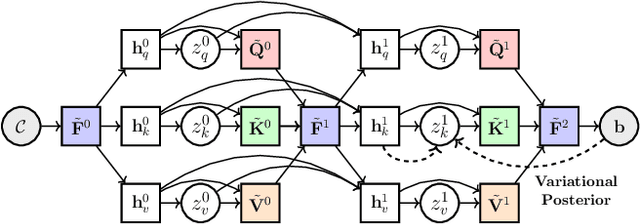
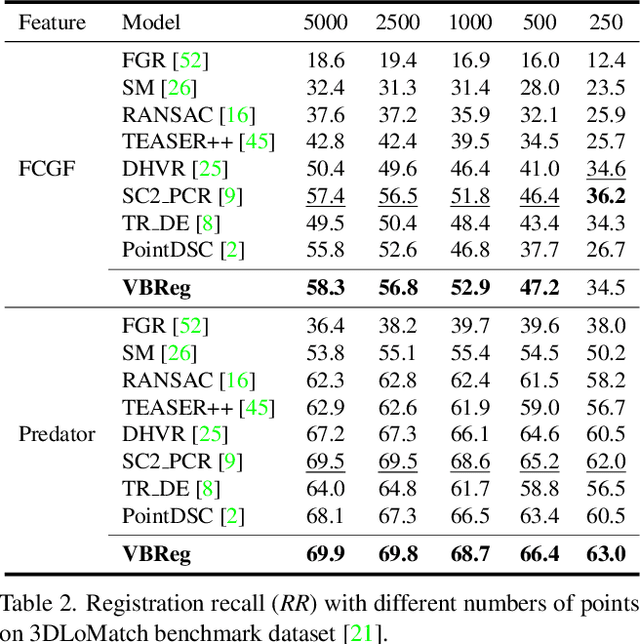
Learning-based outlier (mismatched correspondence) rejection for robust 3D registration generally formulates the outlier removal as an inlier/outlier classification problem. The core for this to be successful is to learn the discriminative inlier/outlier feature representations. In this paper, we develop a novel variational non-local network-based outlier rejection framework for robust alignment. By reformulating the non-local feature learning with variational Bayesian inference, the Bayesian-driven long-range dependencies can be modeled to aggregate discriminative geometric context information for inlier/outlier distinction. Specifically, to achieve such Bayesian-driven contextual dependencies, each query/key/value component in our non-local network predicts a prior feature distribution and a posterior one. Embedded with the inlier/outlier label, the posterior feature distribution is label-dependent and discriminative. Thus, pushing the prior to be close to the discriminative posterior in the training step enables the features sampled from this prior at test time to model high-quality long-range dependencies. Notably, to achieve effective posterior feature guidance, a specific probabilistic graphical model is designed over our non-local model, which lets us derive a variational low bound as our optimization objective for model training. Finally, we propose a voting-based inlier searching strategy to cluster the high-quality hypothetical inliers for transformation estimation. Extensive experiments on 3DMatch, 3DLoMatch, and KITTI datasets verify the effectiveness of our method.