 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Optimal and Adaptive Non-Stationary Dueling Bandits Under a Generalized Borda Criterion
Mar 19, 2024
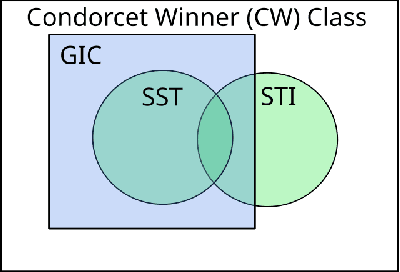

In dueling bandits, the learner receives preference feedback between arms, and the regret of an arm is defined in terms of its suboptimality to a winner arm. The more challenging and practically motivated non-stationary variant of dueling bandits, where preferences change over time, has been the focus of several recent works (Saha and Gupta, 2022; Buening and Saha, 2023; Suk and Agarwal, 2023). The goal is to design algorithms without foreknowledge of the amount of change. The bulk of known results here studies the Condorcet winner setting, where an arm preferred over any other exists at all times. Yet, such a winner may not exist and, to contrast, the Borda version of this problem (which is always well-defined) has received little attention. In this work, we establish the first optimal and adaptive Borda dynamic regret upper bound, which highlights fundamental differences in the learnability of severe non-stationarity between Condorcet vs. Borda regret objectives in dueling bandits. Surprisingly, our techniques for non-stationary Borda dueling bandits also yield improved rates within the Condorcet winner setting, and reveal new preference models where tighter notions of non-stationarity are adaptively learnable. This is accomplished through a novel generalized Borda score framework which unites the Borda and Condorcet problems, thus allowing reduction of Condorcet regret to a Borda-like task. Such a generalization was not previously known and is likely to be of independent interest.
Digital Twin-Driven Reinforcement Learning for Obstacle Avoidance in Robot Manipulators: A Self-Improving Online Training Framework
Mar 19, 2024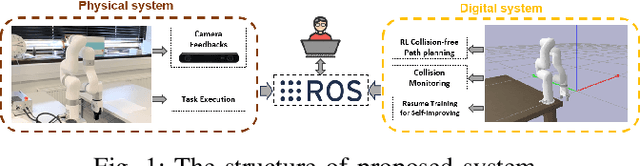
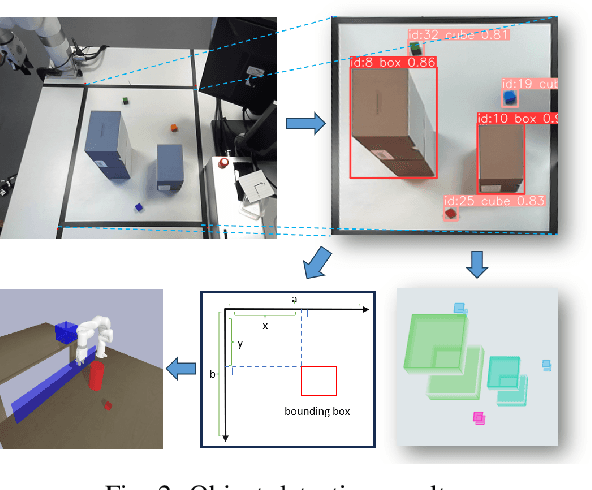
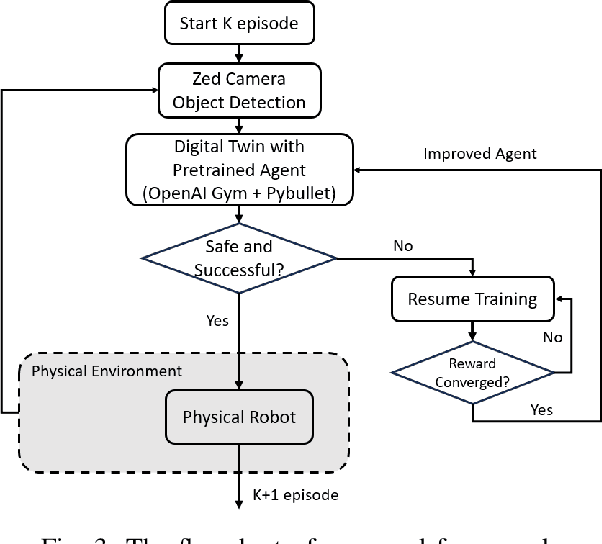

The evolution and growing automation of collaborative robots introduce more complexity and unpredictability to systems, highlighting the crucial need for robot's adaptability and flexibility to address the increasing complexities of their environment. In typical industrial production scenarios, robots are often required to be re-programmed when facing a more demanding task or even a few changes in workspace conditions. To increase productivity, efficiency and reduce human effort in the design process, this paper explores the potential of using digital twin combined with Reinforcement Learning (RL) to enable robots to generate self-improving collision-free trajectories in real time. The digital twin, acting as a virtual counterpart of the physical system, serves as a 'forward run' for monitoring, controlling, and optimizing the physical system in a safe and cost-effective manner. The physical system sends data to synchronize the digital system through the video feeds from cameras, which allows the virtual robot to update its observation and policy based on real scenarios. The bidirectional communication between digital and physical systems provides a promising platform for hardware-in-the-loop RL training through trial and error until the robot successfully adapts to its new environment. The proposed online training framework is demonstrated on the Unfactory Xarm5 collaborative robot, where the robot end-effector aims to reach the target position while avoiding obstacles. The experiment suggest that proposed framework is capable of performing policy online training, and that there remains significant room for improvement.
FUELVISION: A Multimodal Data Fusion and Multimodel Ensemble Algorithm for Wildfire Fuels Mapping
Mar 19, 2024Accurate assessment of fuel conditions is a prerequisite for fire ignition and behavior prediction, and risk management. The method proposed herein leverages diverse data sources including Landsat-8 optical imagery, Sentinel-1 (C-band) Synthetic Aperture Radar (SAR) imagery, PALSAR (L-band) SAR imagery, and terrain features to capture comprehensive information about fuel types and distributions. An ensemble model was trained to predict landscape-scale fuels such as the 'Scott and Burgan 40' using the as-received Forest Inventory and Analysis (FIA) field survey plot data obtained from the USDA Forest Service. However, this basic approach yielded relatively poor results due to the inadequate amount of training data. Pseudo-labeled and fully synthetic datasets were developed using generative AI approaches to address the limitations of ground truth data availability. These synthetic datasets were used for augmenting the FIA data from California to enhance the robustness and coverage of model training. The use of an ensemble of methods including deep learning neural networks, decision trees, and gradient boosting offered a fuel mapping accuracy of nearly 80\%. Through extensive experimentation and evaluation, the effectiveness of the proposed approach was validated for regions of the 2021 Dixie and Caldor fires. Comparative analyses against high-resolution data from the National Agriculture Imagery Program (NAIP) and timber harvest maps affirmed the robustness and reliability of the proposed approach, which is capable of near-real-time fuel mapping.
AutoHLS: Learning to Accelerate Design Space Exploration for HLS Designs
Mar 15, 2024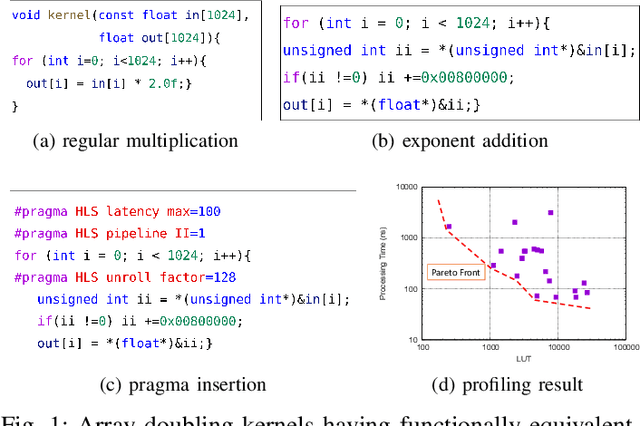
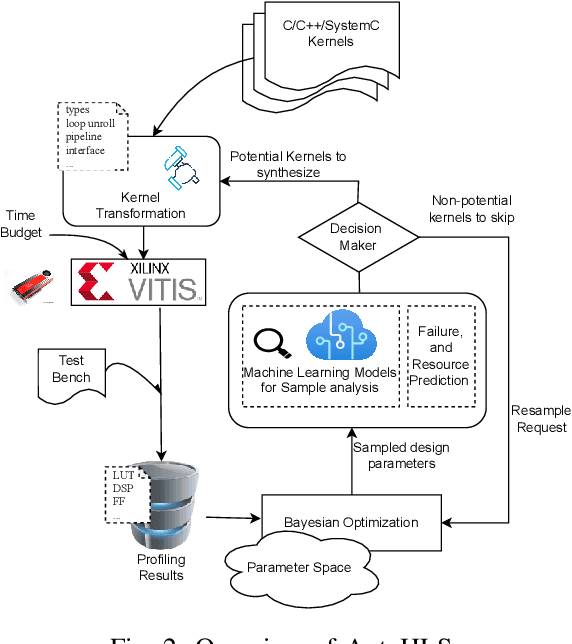
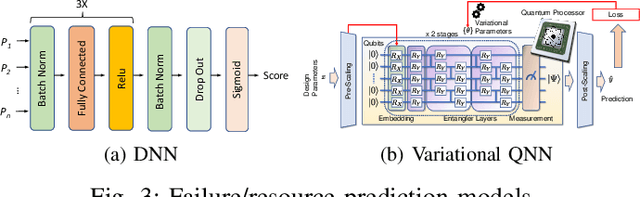
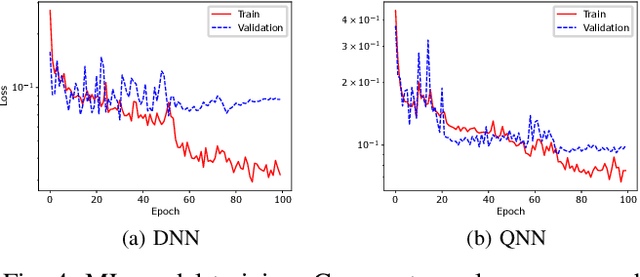
High-level synthesis (HLS) is a design flow that leverages modern language features and flexibility, such as complex data structures, inheritance, templates, etc., to prototype hardware designs rapidly. However, exploring various design space parameters can take much time and effort for hardware engineers to meet specific design specifications. This paper proposes a novel framework called AutoHLS, which integrates a deep neural network (DNN) with Bayesian optimization (BO) to accelerate HLS hardware design optimization. Our tool focuses on HLS pragma exploration and operation transformation. It utilizes integrated DNNs to predict synthesizability within a given FPGA resource budget. We also investigate the potential of emerging quantum neural networks (QNNs) instead of classical DNNs for the AutoHLS pipeline. Our experimental results demonstrate up to a 70-fold speedup in exploration time.
K-Link: Knowledge-Link Graph from LLMs for Enhanced Representation Learning in Multivariate Time-Series Data
Mar 06, 2024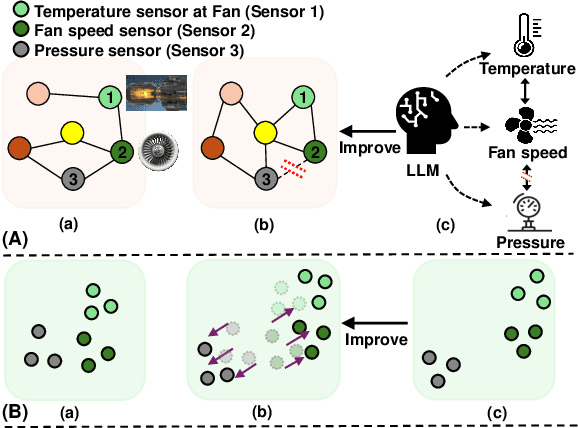
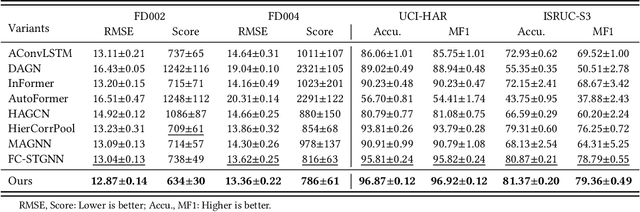
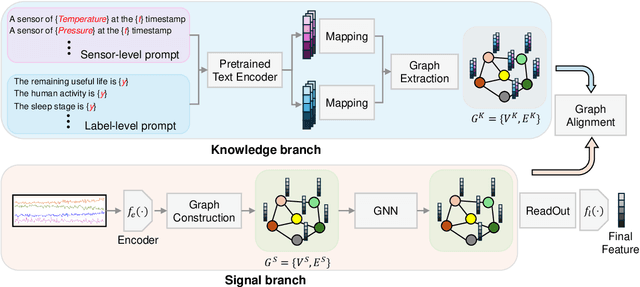
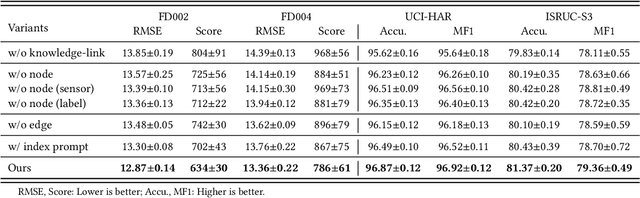
Sourced from various sensors and organized chronologically, Multivariate Time-Series (MTS) data involves crucial spatial-temporal dependencies, e.g., correlations among sensors. To capture these dependencies, Graph Neural Networks (GNNs) have emerged as powerful tools, yet their effectiveness is restricted by the quality of graph construction from MTS data. Typically, existing approaches construct graphs solely from MTS signals, which may introduce bias due to a small training dataset and may not accurately represent underlying dependencies. To address this challenge, we propose a novel framework named K-Link, leveraging Large Language Models (LLMs) to encode extensive general knowledge and thereby providing effective solutions to reduce the bias. Leveraging the knowledge embedded in LLMs, such as physical principles, we extract a \textit{Knowledge-Link graph}, capturing vast semantic knowledge of sensors and the linkage of the sensor-level knowledge. To harness the potential of the knowledge-link graph in enhancing the graph derived from MTS data, we propose a graph alignment module, facilitating the transfer of semantic knowledge within the knowledge-link graph into the MTS-derived graph. By doing so, we can improve the graph quality, ensuring effective representation learning with GNNs for MTS data. Extensive experiments demonstrate the efficacy of our approach for superior performance across various MTS-related downstream tasks.
Efficient Transformer-based Hyper-parameter Optimization for Resource-constrained IoT Environments
Mar 18, 2024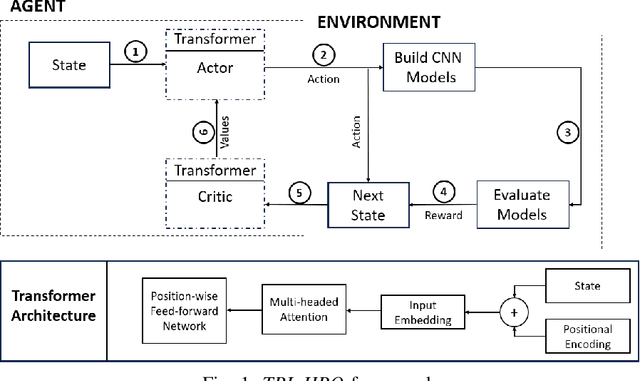
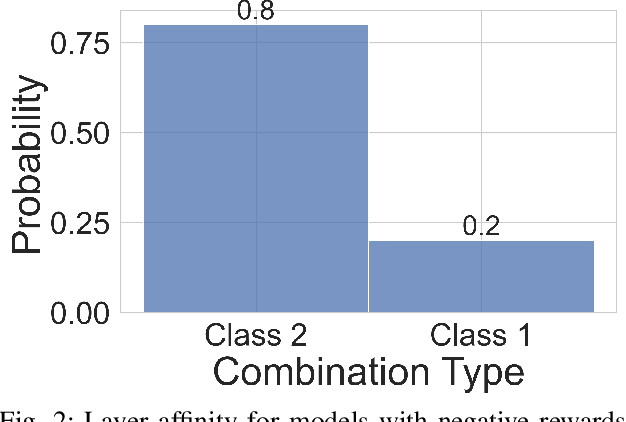
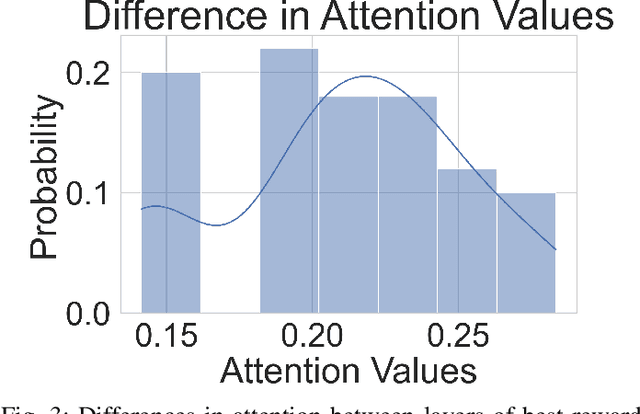
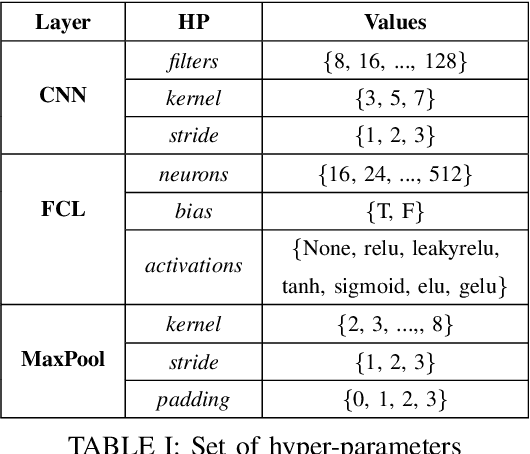
The hyper-parameter optimization (HPO) process is imperative for finding the best-performing Convolutional Neural Networks (CNNs). The automation process of HPO is characterized by its sizable computational footprint and its lack of transparency; both important factors in a resource-constrained Internet of Things (IoT) environment. In this paper, we address these problems by proposing a novel approach that combines transformer architecture and actor-critic Reinforcement Learning (RL) model, TRL-HPO, equipped with multi-headed attention that enables parallelization and progressive generation of layers. These assumptions are founded empirically by evaluating TRL-HPO on the MNIST dataset and comparing it with state-of-the-art approaches that build CNN models from scratch. The results show that TRL-HPO outperforms the classification results of these approaches by 6.8% within the same time frame, demonstrating the efficiency of TRL-HPO for the HPO process. The analysis of the results identifies the main culprit for performance degradation attributed to stacking fully connected layers. This paper identifies new avenues for improving RL-based HPO processes in resource-constrained environments.
FLex: Joint Pose and Dynamic Radiance Fields Optimization for Stereo Endoscopic Videos
Mar 18, 2024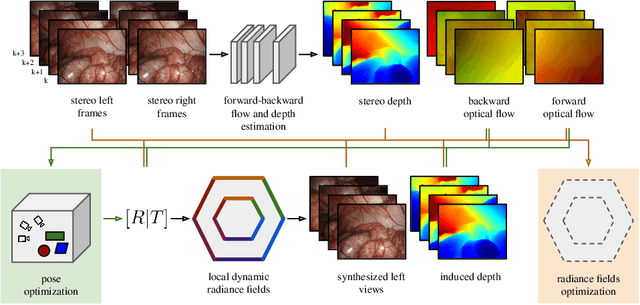
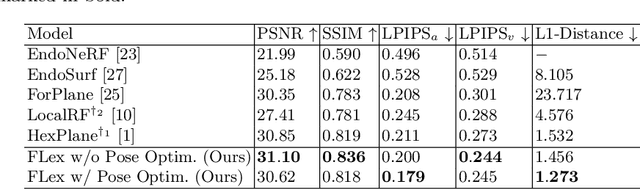
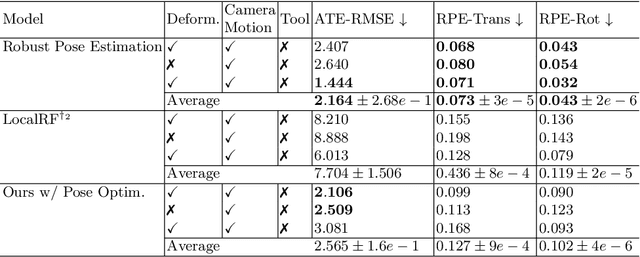
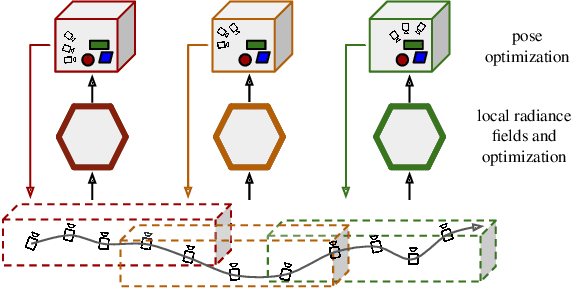
Reconstruction of endoscopic scenes is an important asset for various medical applications, from post-surgery analysis to educational training. Neural rendering has recently shown promising results in endoscopic reconstruction with deforming tissue. However, the setup has been restricted to a static endoscope, limited deformation, or required an external tracking device to retrieve camera pose information of the endoscopic camera. With FLex we adress the challenging setup of a moving endoscope within a highly dynamic environment of deforming tissue. We propose an implicit scene separation into multiple overlapping 4D neural radiance fields (NeRFs) and a progressive optimization scheme jointly optimizing for reconstruction and camera poses from scratch. This improves the ease-of-use and allows to scale reconstruction capabilities in time to process surgical videos of 5,000 frames and more; an improvement of more than ten times compared to the state of the art while being agnostic to external tracking information. Extensive evaluations on the StereoMIS dataset show that FLex significantly improves the quality of novel view synthesis while maintaining competitive pose accuracy.
Binary Noise for Binary Tasks: Masked Bernoulli Diffusion for Unsupervised Anomaly Detection
Mar 18, 2024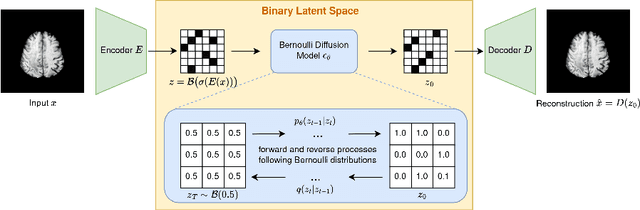
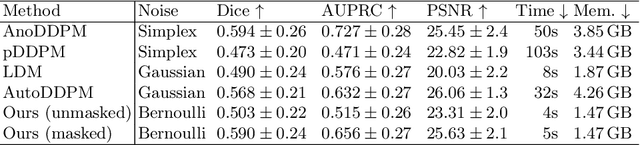
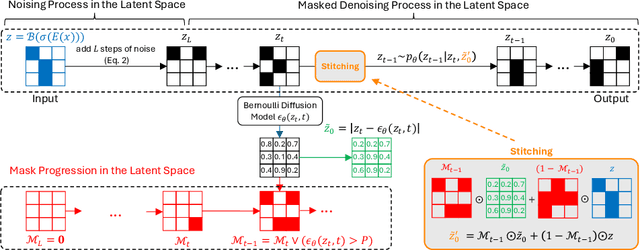
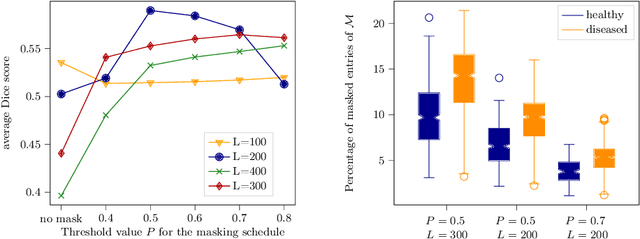
The high performance of denoising diffusion models for image generation has paved the way for their application in unsupervised medical anomaly detection. As diffusion-based methods require a lot of GPU memory and have long sampling times, we present a novel and fast unsupervised anomaly detection approach based on latent Bernoulli diffusion models. We first apply an autoencoder to compress the input images into a binary latent representation. Next, a diffusion model that follows a Bernoulli noise schedule is employed to this latent space and trained to restore binary latent representations from perturbed ones. The binary nature of this diffusion model allows us to identify entries in the latent space that have a high probability of flipping their binary code during the denoising process, which indicates out-of-distribution data. We propose a masking algorithm based on these probabilities, which improves the anomaly detection scores. We achieve state-of-the-art performance compared to other diffusion-based unsupervised anomaly detection algorithms while significantly reducing sampling time and memory consumption. The code is available at https://github.com/JuliaWolleb/Anomaly_berdiff.
VFusion3D: Learning Scalable 3D Generative Models from Video Diffusion Models
Mar 18, 2024
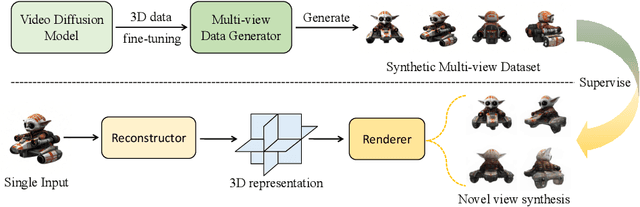
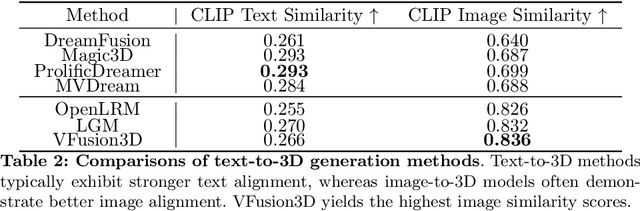

This paper presents a novel paradigm for building scalable 3D generative models utilizing pre-trained video diffusion models. The primary obstacle in developing foundation 3D generative models is the limited availability of 3D data. Unlike images, texts, or videos, 3D data are not readily accessible and are difficult to acquire. This results in a significant disparity in scale compared to the vast quantities of other types of data. To address this issue, we propose using a video diffusion model, trained with extensive volumes of text, images, and videos, as a knowledge source for 3D data. By unlocking its multi-view generative capabilities through fine-tuning, we generate a large-scale synthetic multi-view dataset to train a feed-forward 3D generative model. The proposed model, VFusion3D, trained on nearly 3M synthetic multi-view data, can generate a 3D asset from a single image in seconds and achieves superior performance when compared to current SOTA feed-forward 3D generative models, with users preferring our results over 70% of the time.
Better (pseudo-)labels for semi-supervised instance segmentation
Mar 18, 2024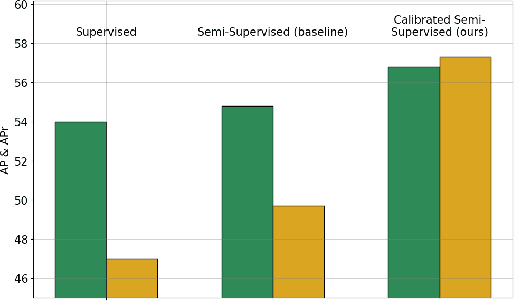
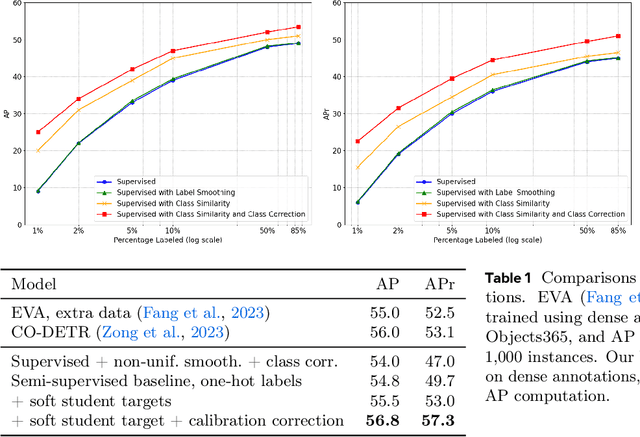
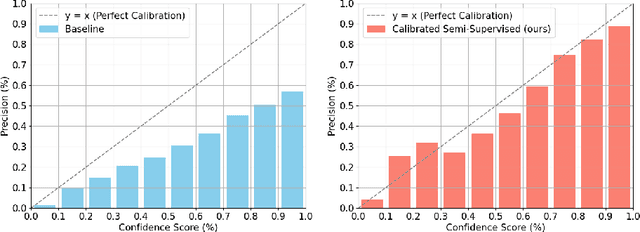
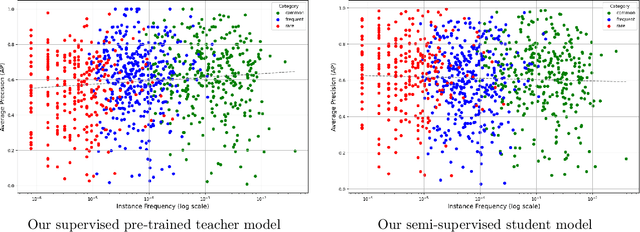
Despite the availability of large datasets for tasks like image classification and image-text alignment, labeled data for more complex recognition tasks, such as detection and segmentation, is less abundant. In particular, for instance segmentation annotations are time-consuming to produce, and the distribution of instances is often highly skewed across classes. While semi-supervised teacher-student distillation methods show promise in leveraging vast amounts of unlabeled data, they suffer from miscalibration, resulting in overconfidence in frequently represented classes and underconfidence in rarer ones. Additionally, these methods encounter difficulties in efficiently learning from a limited set of examples. We introduce a dual-strategy to enhance the teacher model's training process, substantially improving the performance on few-shot learning. Secondly, we propose a calibration correction mechanism that that enables the student model to correct the teacher's calibration errors. Using our approach, we observed marked improvements over a state-of-the-art supervised baseline performance on the LVIS dataset, with an increase of 2.8% in average precision (AP) and 10.3% gain in AP for rare classes.