 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Situational-Aware Multi-Graph Convolutional Recurrent Network (SA-MGCRN) for Travel Demand Forecasting During Wildfires
Apr 13, 2023
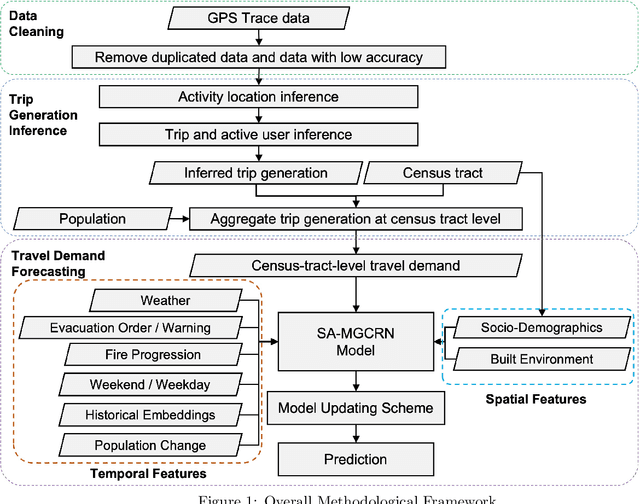
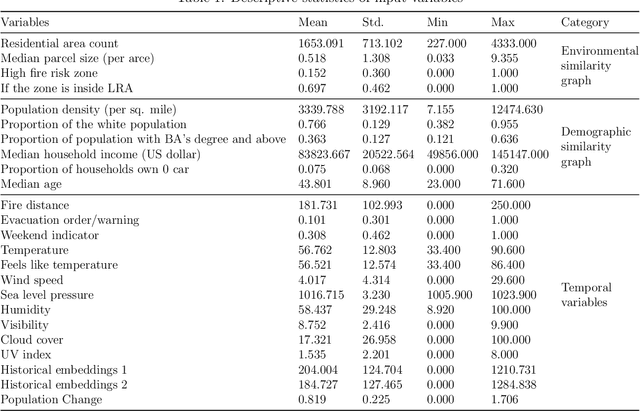
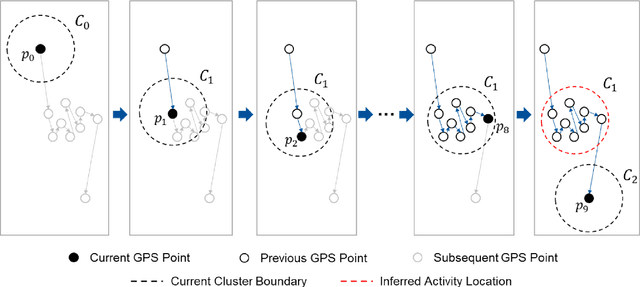
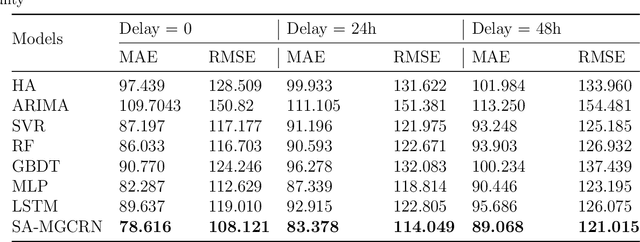
Real-time forecasting of travel demand during wildfire evacuations is crucial for emergency managers and transportation planners to make timely and better-informed decisions. However, few studies focus on accurate travel demand forecasting in large-scale emergency evacuations. Therefore, this study develops and tests a new methodological framework for modeling trip generation in wildfire evacuations by using (a) large-scale GPS data generated by mobile devices and (b) state-of-the-art AI technologies. The proposed methodology aims at forecasting evacuation trips and other types of trips. Based on the travel demand inferred from the GPS data, we develop a new deep learning model, i.e., Situational-Aware Multi-Graph Convolutional Recurrent Network (SA-MGCRN), along with a model updating scheme to achieve real-time forecasting of travel demand during wildfire evacuations. The proposed methodological framework is tested in this study for a real-world case study: the 2019 Kincade Fire in Sonoma County, CA. The results show that SA-MGCRN significantly outperforms all the selected state-of-the-art benchmarks in terms of prediction performance. Our finding suggests that the most important model components of SA-MGCRN are evacuation order/warning information, proximity to fire, and population change, which are consistent with behavioral theories and empirical findings.
Meta-Auxiliary Learning for Adaptive Human Pose Prediction
Apr 13, 2023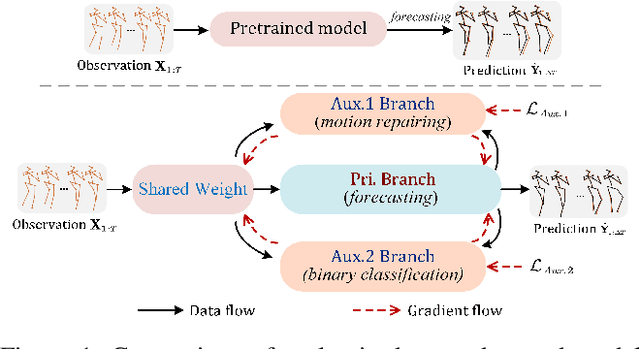
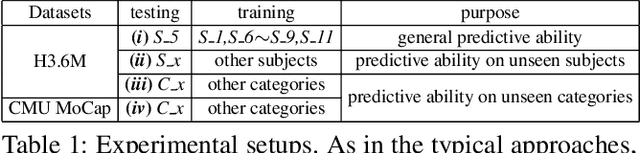
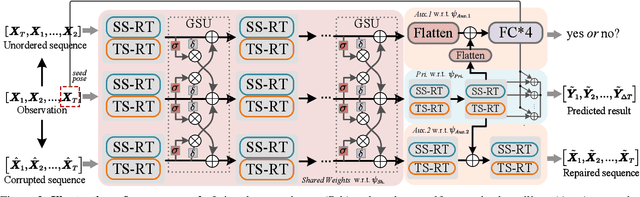
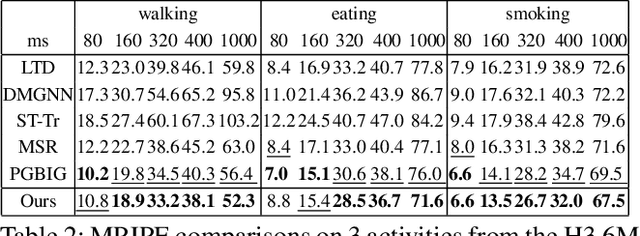
Predicting high-fidelity future human poses, from a historically observed sequence, is decisive for intelligent robots to interact with humans. Deep end-to-end learning approaches, which typically train a generic pre-trained model on external datasets and then directly apply it to all test samples, emerge as the dominant solution to solve this issue. Despite encouraging progress, they remain non-optimal, as the unique properties (e.g., motion style, rhythm) of a specific sequence cannot be adapted. More generally, at test-time, once encountering unseen motion categories (out-of-distribution), the predicted poses tend to be unreliable. Motivated by this observation, we propose a novel test-time adaptation framework that leverages two self-supervised auxiliary tasks to help the primary forecasting network adapt to the test sequence. In the testing phase, our model can adjust the model parameters by several gradient updates to improve the generation quality. However, due to catastrophic forgetting, both auxiliary tasks typically tend to the low ability to automatically present the desired positive incentives for the final prediction performance. For this reason, we also propose a meta-auxiliary learning scheme for better adaptation. In terms of general setup, our approach obtains higher accuracy, and under two new experimental designs for out-of-distribution data (unseen subjects and categories), achieves significant improvements.
DAMO-StreamNet: Optimizing Streaming Perception in Autonomous Driving
Mar 30, 2023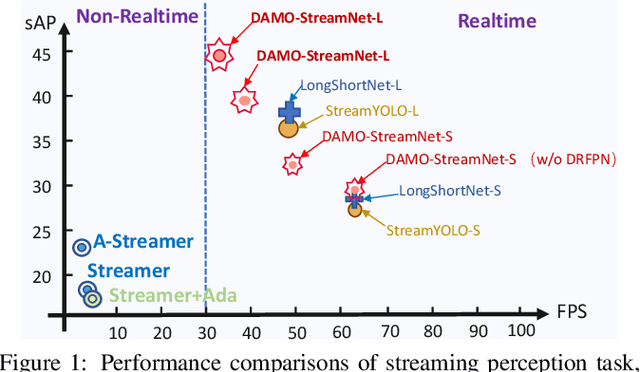
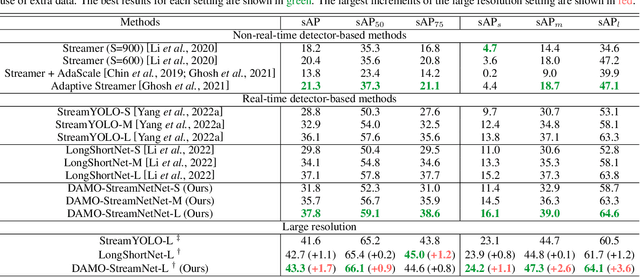
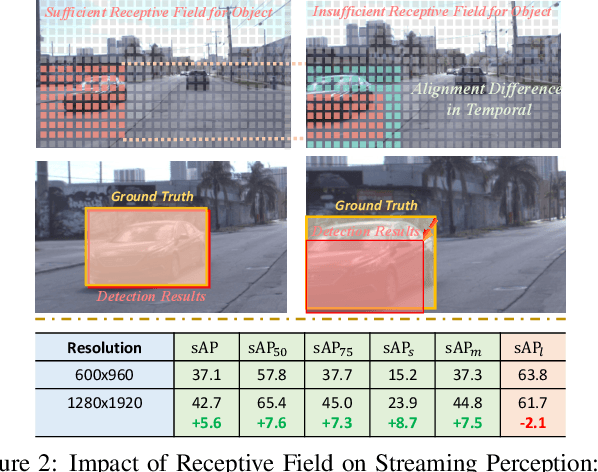
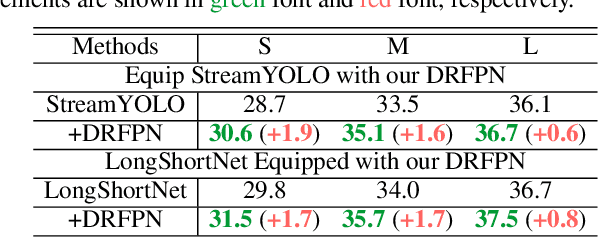
Real-time perception, or streaming perception, is a crucial aspect of autonomous driving that has yet to be thoroughly explored in existing research. To address this gap, we present DAMO-StreamNet, an optimized framework that combines recent advances from the YOLO series with a comprehensive analysis of spatial and temporal perception mechanisms, delivering a cutting-edge solution. The key innovations of DAMO-StreamNet are: (1) A robust neck structure incorporating deformable convolution, enhancing the receptive field and feature alignment capabilities. (2) A dual-branch structure that integrates short-path semantic features and long-path temporal features, improving motion state prediction accuracy. (3) Logits-level distillation for efficient optimization, aligning the logits of teacher and student networks in semantic space. (4) A real-time forecasting mechanism that updates support frame features with the current frame, ensuring seamless streaming perception during inference. Our experiments demonstrate that DAMO-StreamNet surpasses existing state-of-the-art methods, achieving 37.8% (normal size (600, 960)) and 43.3% (large size (1200, 1920)) sAP without using extra data. This work not only sets a new benchmark for real-time perception but also provides valuable insights for future research. Additionally, DAMO-StreamNet can be applied to various autonomous systems, such as drones and robots, paving the way for real-time perception.
Power Grid Behavioral Patterns and Risks of Generalization in Applied Machine Learning
Apr 21, 2023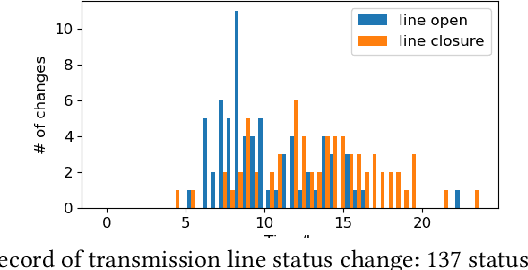
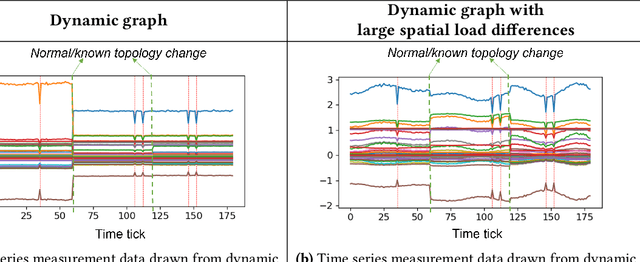
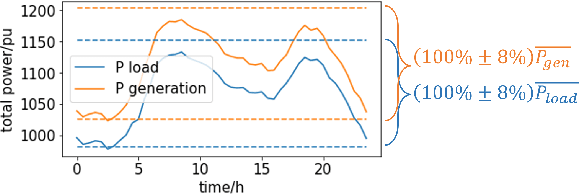
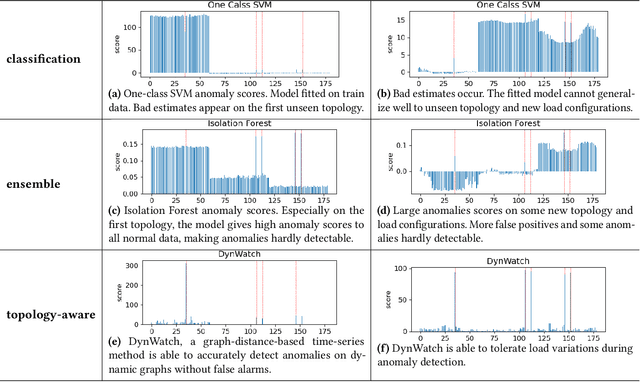
Recent years have seen a rich literature of data-driven approaches designed for power grid applications. However, insufficient consideration of domain knowledge can impose a high risk to the practicality of the methods. Specifically, ignoring the grid-specific spatiotemporal patterns (in load, generation, and topology, etc.) can lead to outputting infeasible, unrealizable, or completely meaningless predictions on new inputs. To address this concern, this paper investigates real-world operational data to provide insights into power grid behavioral patterns, including the time-varying topology, load, and generation, as well as the spatial differences (in peak hours, diverse styles) between individual loads and generations. Then based on these observations, we evaluate the generalization risks in some existing ML works causedby ignoring these grid-specific patterns in model design and training.
Towards Better Long-range Time Series Forecasting using Generative Forecasting
Dec 09, 2022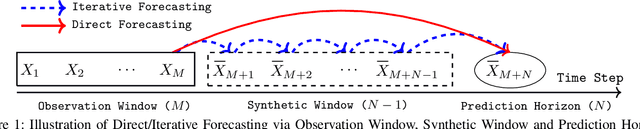
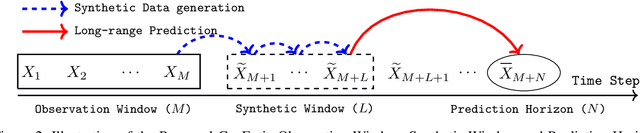
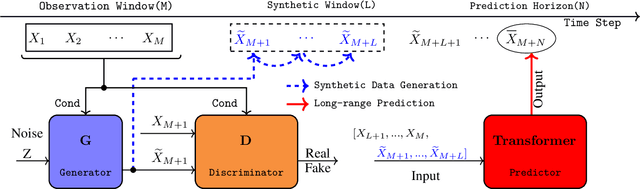
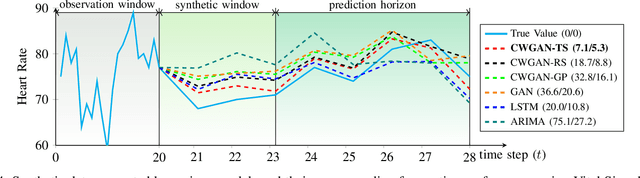
Long-range time series forecasting is usually based on one of two existing forecasting strategies: Direct Forecasting and Iterative Forecasting, where the former provides low bias, high variance forecasts and the latter leads to low variance, high bias forecasts. In this paper, we propose a new forecasting strategy called Generative Forecasting (GenF), which generates synthetic data for the next few time steps and then makes long-range forecasts based on generated and observed data. We theoretically prove that GenF is able to better balance the forecasting variance and bias, leading to a much smaller forecasting error. We implement GenF via three components: (i) a novel conditional Wasserstein Generative Adversarial Network (GAN) based generator for synthetic time series data generation, called CWGAN-TS. (ii) a transformer based predictor, which makes long-range predictions using both generated and observed data. (iii) an information theoretic clustering algorithm to improve the training of both the CWGAN-TS and the transformer based predictor. The experimental results on five public datasets demonstrate that GenF significantly outperforms a diverse range of state-of-the-art benchmarks and classical approaches. Specifically, we find a 5% - 11% improvement in predictive performance (mean absolute error) while having a 15% - 50% reduction in parameters compared to the benchmarks. Lastly, we conduct an ablation study to further explore and demonstrate the effectiveness of the components comprising GenF.
SceneGenie: Scene Graph Guided Diffusion Models for Image Synthesis
Apr 28, 2023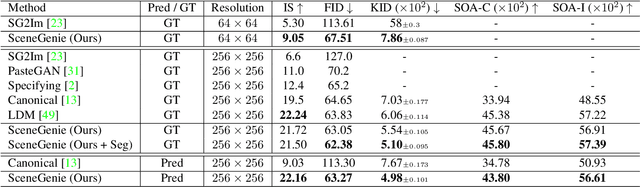
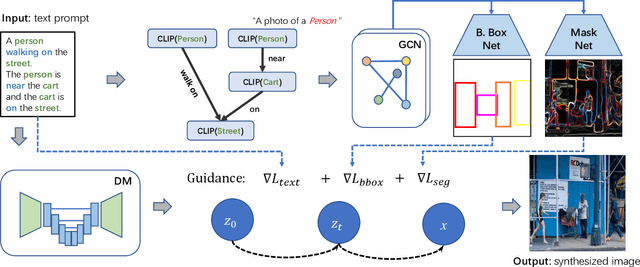
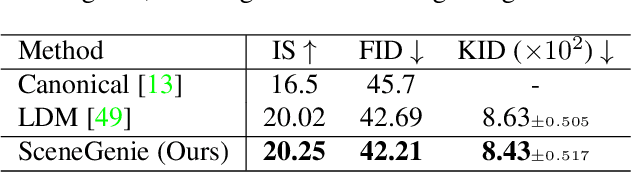
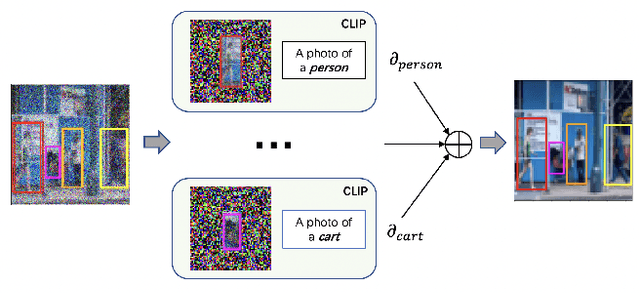
Text-conditioned image generation has made significant progress in recent years with generative adversarial networks and more recently, diffusion models. While diffusion models conditioned on text prompts have produced impressive and high-quality images, accurately representing complex text prompts such as the number of instances of a specific object remains challenging. To address this limitation, we propose a novel guidance approach for the sampling process in the diffusion model that leverages bounding box and segmentation map information at inference time without additional training data. Through a novel loss in the sampling process, our approach guides the model with semantic features from CLIP embeddings and enforces geometric constraints, leading to high-resolution images that accurately represent the scene. To obtain bounding box and segmentation map information, we structure the text prompt as a scene graph and enrich the nodes with CLIP embeddings. Our proposed model achieves state-of-the-art performance on two public benchmarks for image generation from scene graphs, surpassing both scene graph to image and text-based diffusion models in various metrics. Our results demonstrate the effectiveness of incorporating bounding box and segmentation map guidance in the diffusion model sampling process for more accurate text-to-image generation.
Making the Invisible Visible: Toward High-Quality Terahertz Tomographic Imaging via Physics-Guided Restoration
Apr 28, 2023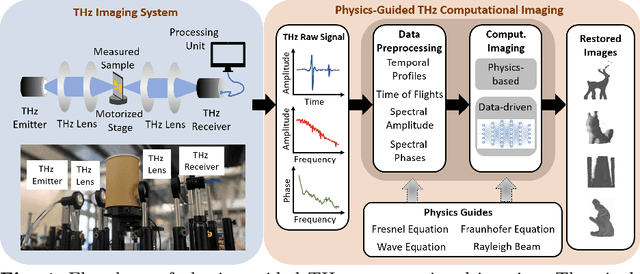
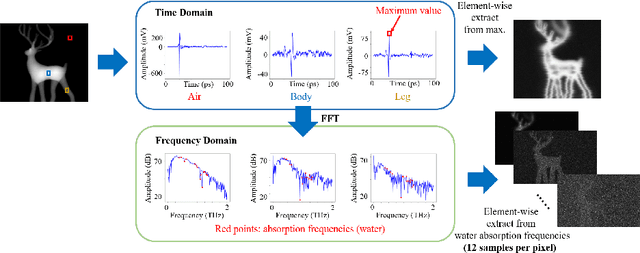
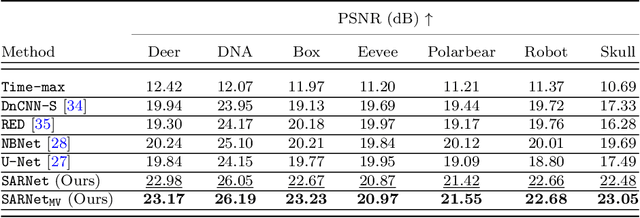
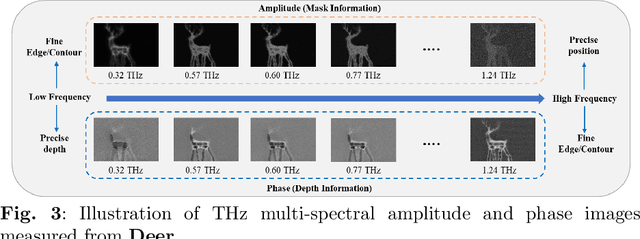
Terahertz (THz) tomographic imaging has recently attracted significant attention thanks to its non-invasive, non-destructive, non-ionizing, material-classification, and ultra-fast nature for object exploration and inspection. However, its strong water absorption nature and low noise tolerance lead to undesired blurs and distortions of reconstructed THz images. The diffraction-limited THz signals highly constrain the performances of existing restoration methods. To address the problem, we propose a novel multi-view Subspace-Attention-guided Restoration Network (SARNet) that fuses multi-view and multi-spectral features of THz images for effective image restoration and 3D tomographic reconstruction. To this end, SARNet uses multi-scale branches to extract intra-view spatio-spectral amplitude and phase features and fuse them via shared subspace projection and self-attention guidance. We then perform inter-view fusion to further improve the restoration of individual views by leveraging the redundancies between neighboring views. Here, we experimentally construct a THz time-domain spectroscopy (THz-TDS) system covering a broad frequency range from 0.1 THz to 4 THz for building up a temporal/spectral/spatial/ material THz database of hidden 3D objects. Complementary to a quantitative evaluation, we demonstrate the effectiveness of our SARNet model on 3D THz tomographic reconstruction applications.
Wearing face mask detection using deep learning through COVID-19 pandemic
Apr 28, 2023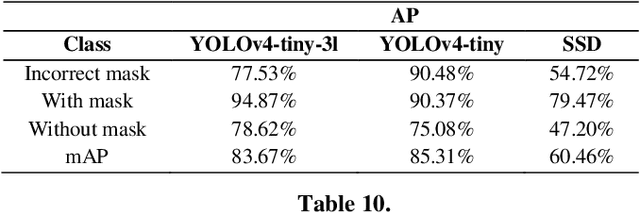

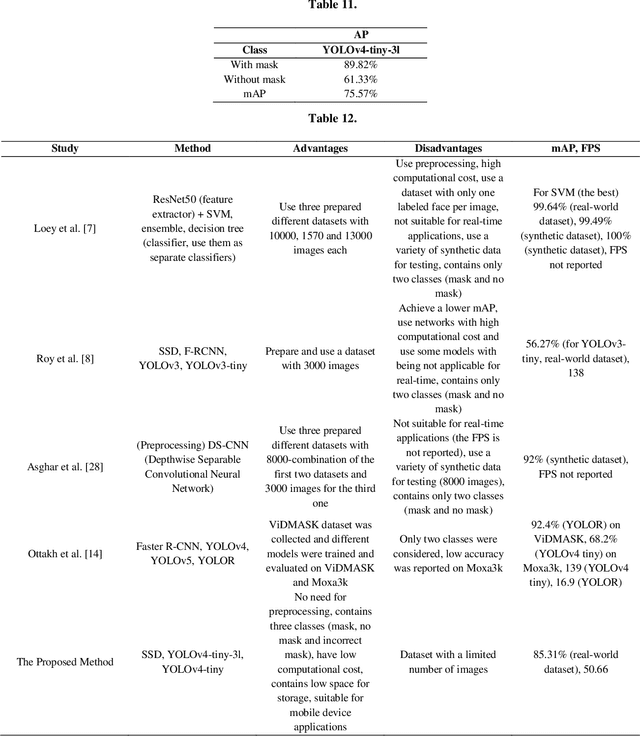

During the COVID-19 pandemic, wearing a face mask has been known to be an effective way to prevent the spread of COVID-19. In lots of monitoring tasks, humans have been replaced with computers thanks to the outstanding performance of the deep learning models. Monitoring the wearing of a face mask is another task that can be done by deep learning models with acceptable accuracy. The main challenge of this task is the limited amount of data because of the quarantine. In this paper, we did an investigation on the capability of three state-of-the-art object detection neural networks on face mask detection for real-time applications. As mentioned, here are three models used, Single Shot Detector (SSD), two versions of You Only Look Once (YOLO) i.e., YOLOv4-tiny, and YOLOv4-tiny-3l from which the best was selected. In the proposed method, according to the performance of different models, the best model that can be suitable for use in real-world and mobile device applications in comparison to other recent studies was the YOLOv4-tiny model, with 85.31% and 50.66 for mean Average Precision (mAP) and Frames Per Second (FPS), respectively. These acceptable values were achieved using two datasets with only 1531 images in three separate classes.
A feature selection method based on Shapley values robust to concept shift in regression
Apr 28, 2023
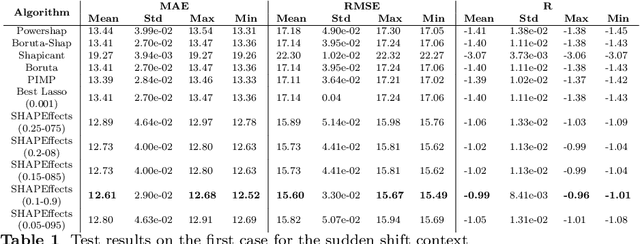
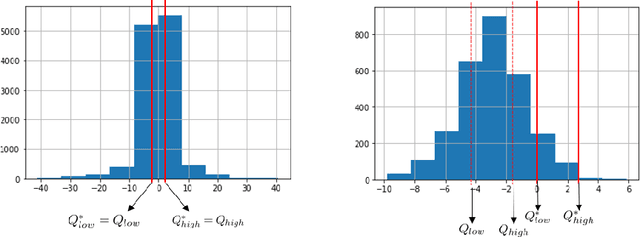
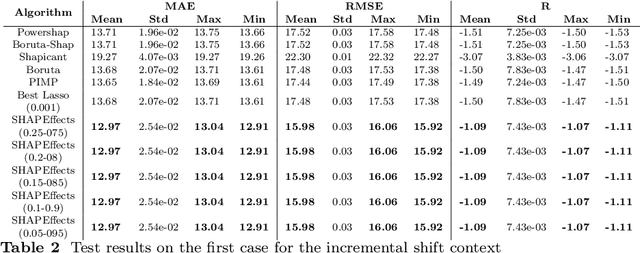
Feature selection is one of the most relevant processes in any methodology for creating a statistical learning model. Generally, existing algorithms establish some criterion to select the most influential variables, discarding those that do not contribute any relevant information to the model. This methodology makes sense in a classical static situation where the joint distribution of the data does not vary over time. However, when dealing with real data, it is common to encounter the problem of the dataset shift and, specifically, changes in the relationships between variables (concept shift). In this case, the influence of a variable cannot be the only indicator of its quality as a regressor of the model, since the relationship learned in the traning phase may not correspond to the current situation. Thus, we propose a new feature selection methodology for regression problems that takes this fact into account, using Shapley values to study the effect that each variable has on the predictions. Five examples are analysed: four correspond to typical situations where the method matches the state of the art and one example related to electricity price forecasting where a concept shift phenomenon has occurred in the Iberian market. In this case the proposed algorithm improves the results significantly.
Musical Voice Separation as Link Prediction: Modeling a Musical Perception Task as a Multi-Trajectory Tracking Problem
Apr 28, 2023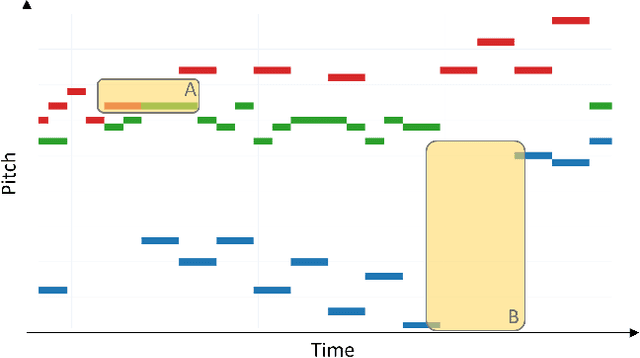
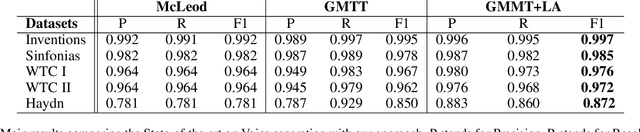

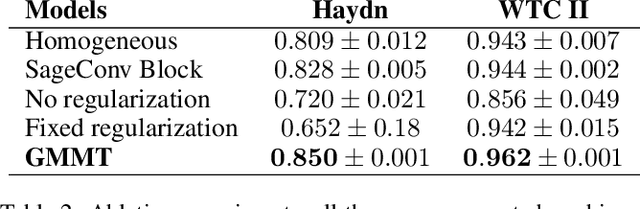
This paper targets the perceptual task of separating the different interacting voices, i.e., monophonic melodic streams, in a polyphonic musical piece. We target symbolic music, where notes are explicitly encoded, and model this task as a Multi-Trajectory Tracking (MTT) problem from discrete observations, i.e., notes in a pitch-time space. Our approach builds a graph from a musical piece, by creating one node for every note, and separates the melodic trajectories by predicting a link between two notes if they are consecutive in the same voice/stream. This kind of local, greedy prediction is made possible by node embeddings created by a heterogeneous graph neural network that can capture inter- and intra-trajectory information. Furthermore, we propose a new regularization loss that encourages the output to respect the MTT premise of at most one incoming and one outgoing link for every node, favouring monophonic (voice) trajectories; this loss function might also be useful in other general MTT scenarios. Our approach does not use domain-specific heuristics, is scalable to longer sequences and a higher number of voices, and can handle complex cases such as voice inversions and overlaps. We reach new state-of-the-art results for the voice separation task in classical music of different styles.