 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
High-dimensional Bayesian Optimization via Semi-supervised Learning with Optimized Unlabeled Data Sampling
May 04, 2023

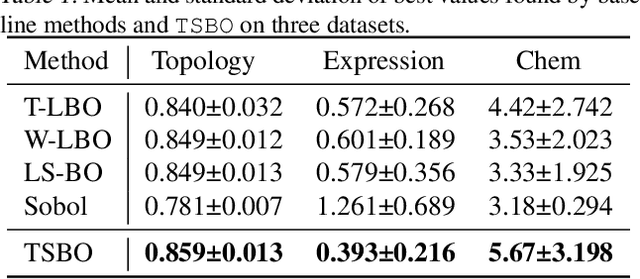
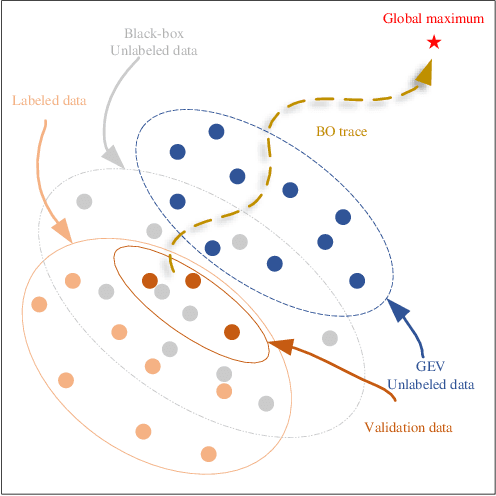
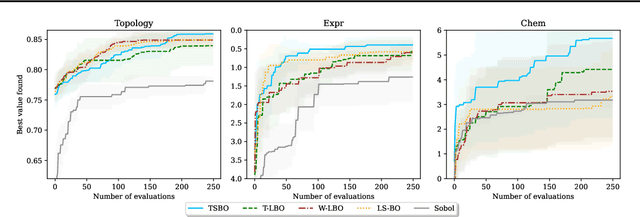
Bayesian optimization (BO) is a powerful tool for seeking the global optimum of black-box functions. While evaluations of the black-box functions can be highly costly, it is desirable to reduce the use of expensive labeled data. For the first time, we introduce a teacher-student model to exploit semi-supervised learning that can make use of large amounts of unlabelled data under the context of BO. Importantly, we show that the selection of the validation and unlabeled data is key to the performance of BO. To optimize the sampling of unlabeled data, we employ a black-box parameterized sampling distribution optimized as part of the employed bi-level optimization framework. Taking one step further, we demonstrate that the performance of BO can be further improved by selecting unlabeled data from a dynamically fitted extreme value distribution. Our BO method operates in a learned latent space with reduced dimensionality, making it scalable to high-dimensional problems. The proposed approach outperforms significantly the existing BO methods on several synthetic and real-world optimization tasks.
Critical heat flux diagnosis using conditional generative adversarial networks
May 04, 2023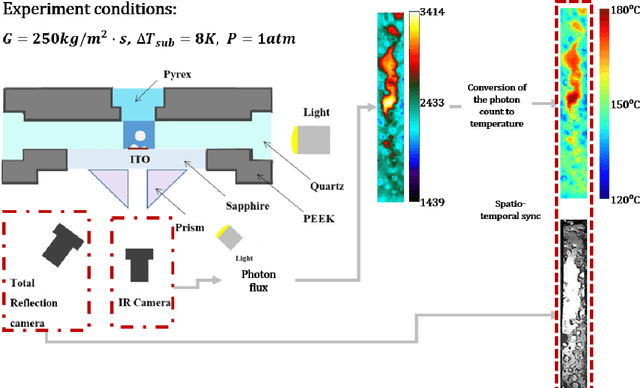
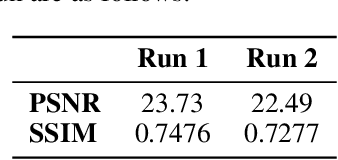
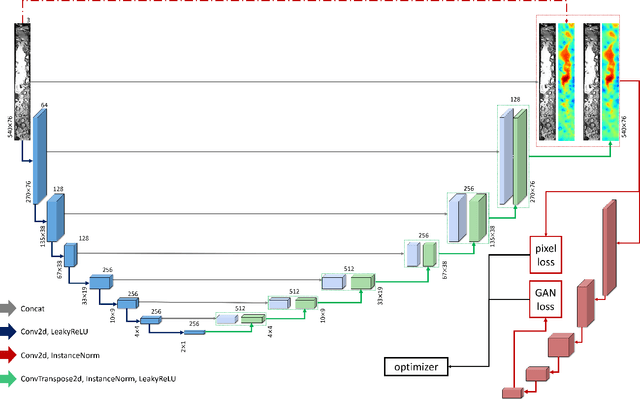

The critical heat flux (CHF) is an essential safety boundary in boiling heat transfer processes employed in high heat flux thermal-hydraulic systems. Identifying CHF is vital for preventing equipment damage and ensuring overall system safety, yet it is challenging due to the complexity of the phenomena. For an in-depth understanding of the complicated phenomena, various methodologies have been devised, but the acquisition of high-resolution data is limited by the substantial resource consumption required. This study presents a data-driven, image-to-image translation method for reconstructing thermal data of a boiling system at CHF using conditional generative adversarial networks (cGANs). The supervised learning process relies on paired images, which include total reflection visualizations and infrared thermometry measurements obtained from flow boiling experiments. Our proposed approach has the potential to not only provide evidence connecting phase interface dynamics with thermal distribution but also to simplify the laborious and time-consuming experimental setup and data-reduction procedures associated with infrared thermal imaging, thereby providing an effective solution for CHF diagnosis.
Tuning Traditional Language Processing Approaches for Pashto Text Classification
May 04, 2023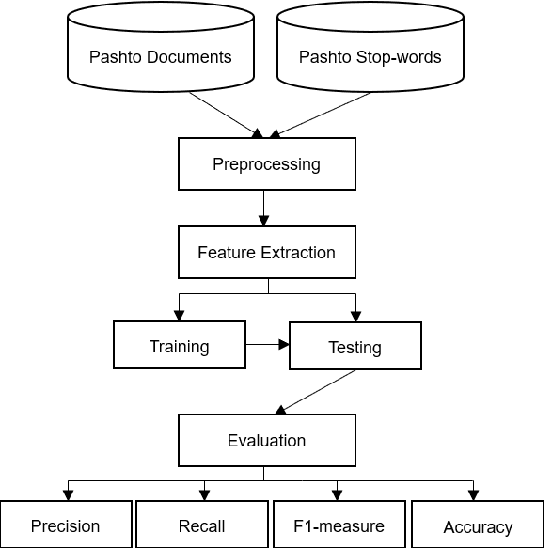

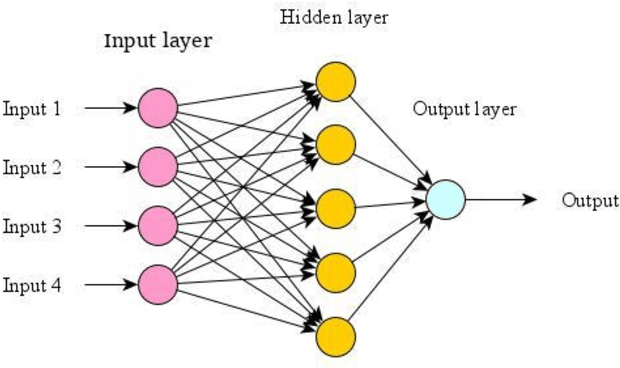
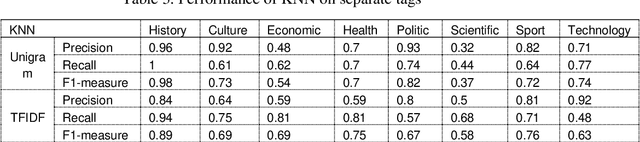
Today text classification becomes critical task for concerned individuals for numerous purposes. Hence, several researches have been conducted to develop automatic text classification for national and international languages. However, the need for an automatic text categorization system for local languages is felt. The main aim of this study is to establish a Pashto automatic text classification system. In order to pursue this work, we built a Pashto corpus which is a collection of Pashto documents due to the unavailability of public datasets of Pashto text documents. Besides, this study compares several models containing both statistical and neural network machine learning techniques including Multilayer Perceptron (MLP), Support Vector Machine (SVM), K Nearest Neighbor (KNN), decision tree, gaussian na\"ive Bayes, multinomial na\"ive Bayes, random forest, and logistic regression to discover the most effective approach. Moreover, this investigation evaluates two different feature extraction methods including unigram, and Time Frequency Inverse Document Frequency (IFIDF). Subsequently, this research obtained average testing accuracy rate 94% using MLP classification algorithm and TFIDF feature extraction method in this context.
* arXiv admin note: substantial text overlap with arXiv:2305.03201
Masked Trajectory Models for Prediction, Representation, and Control
May 04, 2023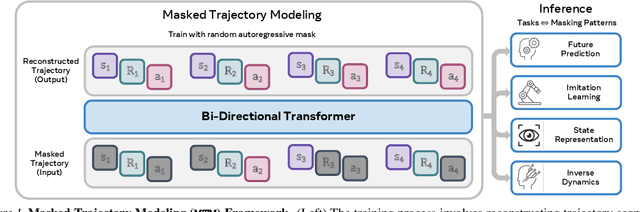
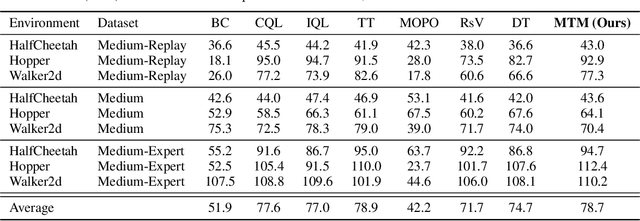
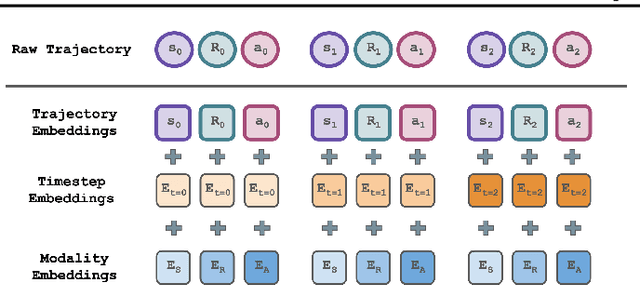
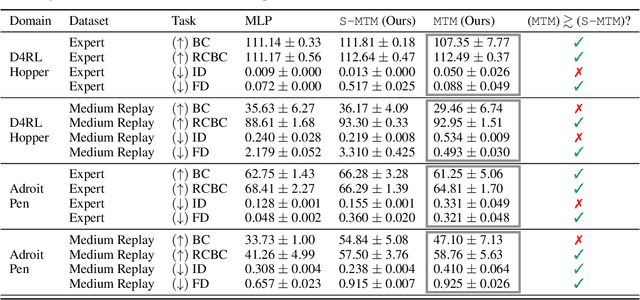
We introduce Masked Trajectory Models (MTM) as a generic abstraction for sequential decision making. MTM takes a trajectory, such as a state-action sequence, and aims to reconstruct the trajectory conditioned on random subsets of the same trajectory. By training with a highly randomized masking pattern, MTM learns versatile networks that can take on different roles or capabilities, by simply choosing appropriate masks at inference time. For example, the same MTM network can be used as a forward dynamics model, inverse dynamics model, or even an offline RL agent. Through extensive experiments in several continuous control tasks, we show that the same MTM network -- i.e. same weights -- can match or outperform specialized networks trained for the aforementioned capabilities. Additionally, we find that state representations learned by MTM can significantly accelerate the learning speed of traditional RL algorithms. Finally, in offline RL benchmarks, we find that MTM is competitive with specialized offline RL algorithms, despite MTM being a generic self-supervised learning method without any explicit RL components. Code is available at https://github.com/facebookresearch/mtm
Change Detection Methods for Remote Sensing in the Last Decade: A Comprehensive Review
May 09, 2023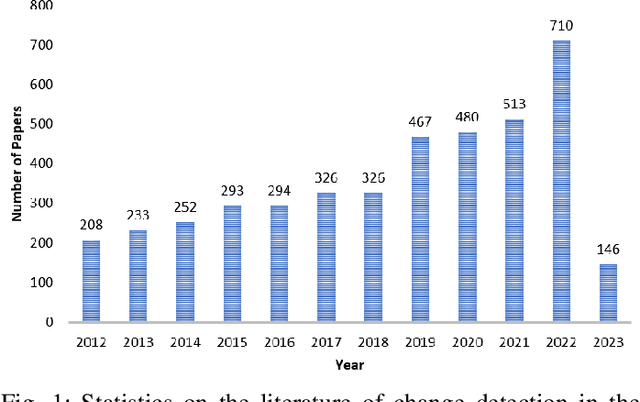
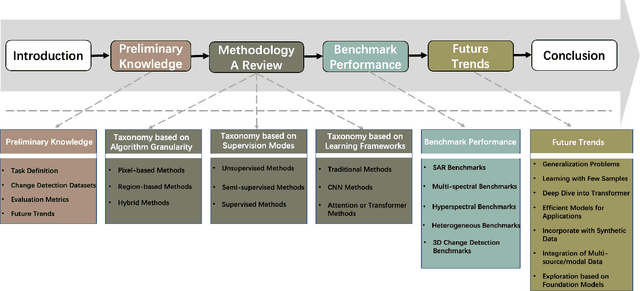
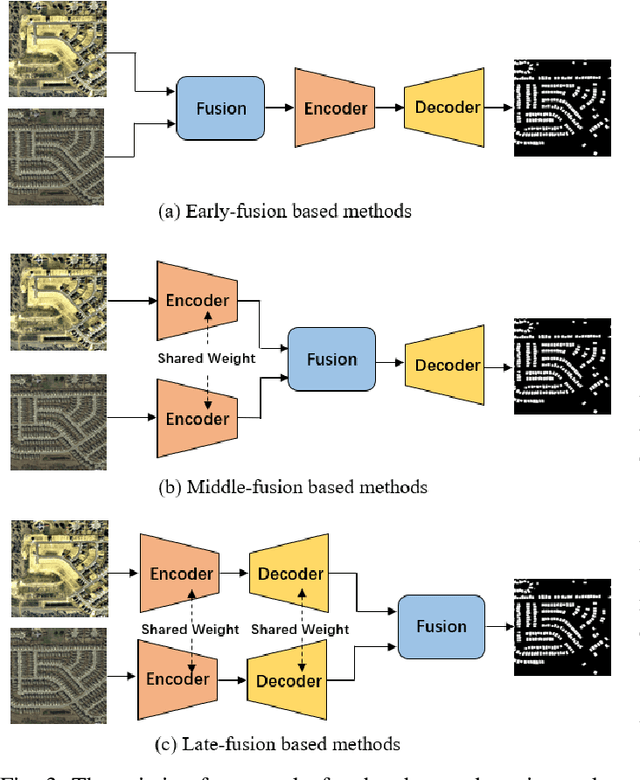
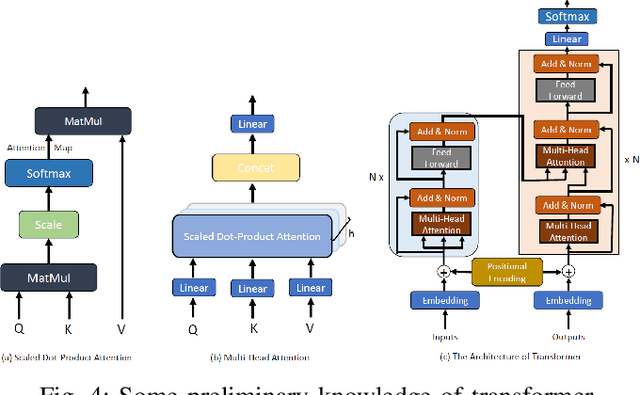
Change detection is an essential and widely utilized task in remote sensing that aims to detect and analyze changes occurring in the same geographical area over time, which has broad applications in urban development, agricultural surveys, and land cover monitoring. Detecting changes in remote sensing images is a complex challenge due to various factors, including variations in image quality, noise, registration errors, illumination changes, complex landscapes, and spatial heterogeneity. In recent years, deep learning has emerged as a powerful tool for feature extraction and addressing these challenges. Its versatility has resulted in its widespread adoption for numerous image-processing tasks. This paper presents a comprehensive survey of significant advancements in change detection for remote sensing images over the past decade. We first introduce some preliminary knowledge for the change detection task, such as problem definition, datasets, evaluation metrics, and transformer basics, as well as provide a detailed taxonomy of existing algorithms from three different perspectives: algorithm granularity, supervision modes, and learning frameworks in the methodology section. This survey enables readers to gain systematic knowledge of change detection tasks from various angles. We then summarize the state-of-the-art performance on several dominant change detection datasets, providing insights into the strengths and limitations of existing algorithms. Based on our survey, some future research directions for change detection in remote sensing are well identified. This survey paper will shed some light on the community and inspire further research efforts in the change detection task.
Who is Speaking Actually? Robust and Versatile Speaker Traceability for Voice Conversion
May 09, 2023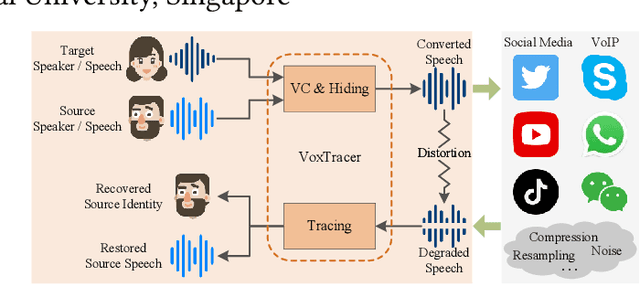
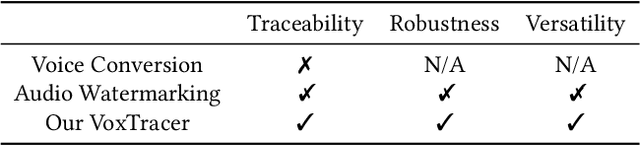
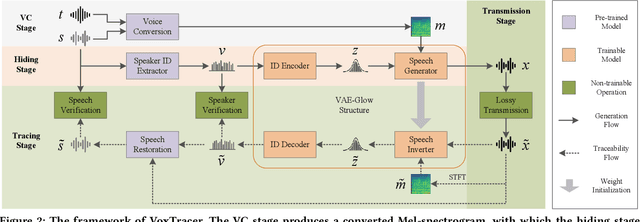
Voice conversion (VC), as a voice style transfer technology, is becoming increasingly prevalent while raising serious concerns about its illegal use. Proactively tracing the origins of VC-generated speeches, i.e., speaker traceability, can prevent the misuse of VC, but unfortunately has not been extensively studied. In this paper, we are the first to investigate the speaker traceability for VC and propose a traceable VC framework named VoxTracer. Our VoxTracer is similar to but beyond the paradigm of audio watermarking. We first use unique speaker embedding to represent speaker identity. Then we design a VAE-Glow structure, in which the hiding process imperceptibly integrates the source speaker identity into the VC, and the tracing process accurately recovers the source speaker identity and even the source speech in spite of severe speech quality degradation. To address the speech mismatch between the hiding and tracing processes affected by different distortions, we also adopt an asynchronous training strategy to optimize the VAE-Glow models. The VoxTracer is versatile enough to be applied to arbitrary VC methods and popular audio coding standards. Extensive experiments demonstrate that the VoxTracer achieves not only high imperceptibility in hiding, but also nearly 100% tracing accuracy against various types of audio lossy compressions (AAC, MP3, Opus and SILK) with a broad range of bitrates (16 kbps - 128 kbps) even in a very short time duration (0.74s). Our speech demo is available at https://anonymous.4open.science/w/DEMOofVoxTracer.
ColonMapper: topological mapping and localization for colonoscopy
May 09, 2023
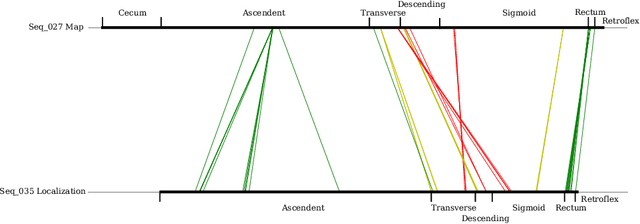
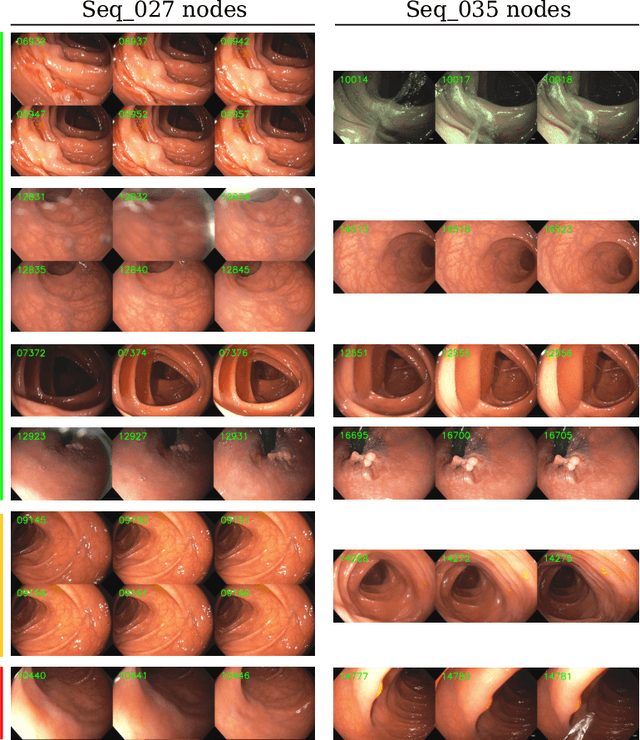
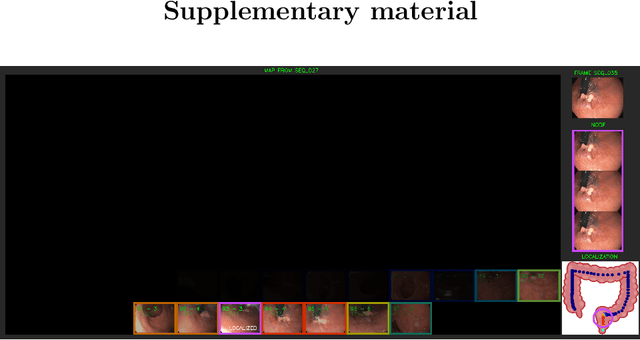
Mapping and localization in endoluminal cavities from colonoscopies or gastroscopies has to overcome the challenge of significant shape and illumination changes between reobservations of the same endoluminal location. Instead of geometrical maps that strongly rely on a fixed scene geometry, topological maps are more adequate because they focus on visual place recognition, i.e. the capability to determine if two video shots are imaging the same location. We propose a topological mapping and localization system able to operate on real human colonoscopies. The map is a graph where each node codes a colon location by a set of real images of that location. The edges represent traversability between two nodes. For close-in-time images, where scene changes are minor, place recognition can be successfully managed with the recent transformers-based image-matching algorithms. However, under long-term changes -- such as different colonoscopies of the same patient -- feature-based matching fails. To address this, we propose a GeM global descriptor able to achieve high recall with significant changes in the scene. The addition of a Bayesian filter processing the map graph boosts the accuracy of the long-term place recognition, enabling relocalization in a previously built map. In the experiments, we construct a map during the withdrawal phase of a first colonoscopy. Subsequently, we prove the ability to relocalize within this map during a second colonoscopy of the same patient two weeks later. Code and models will be available upon acceptance.
Autoregressive models for biomedical signal processing
Apr 17, 2023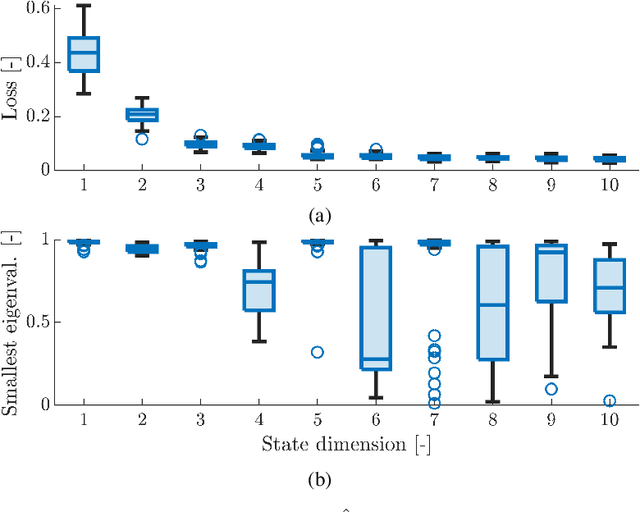
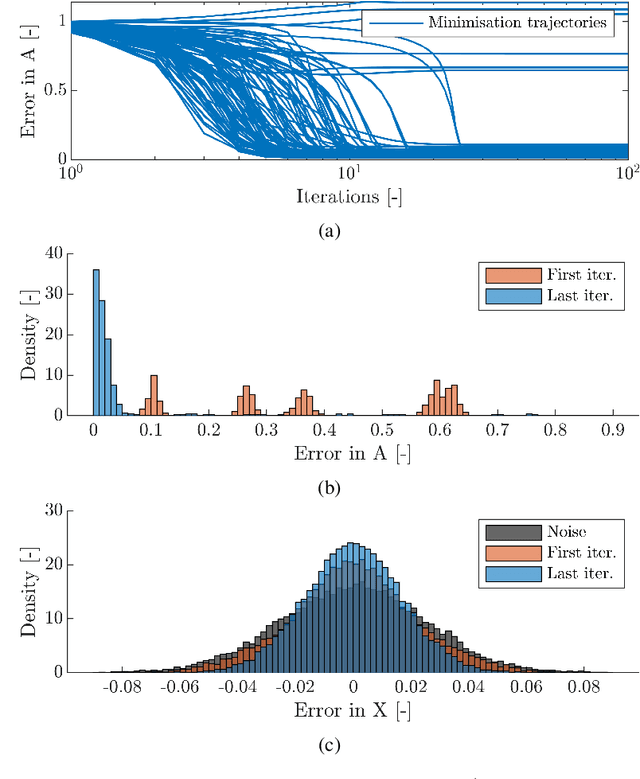
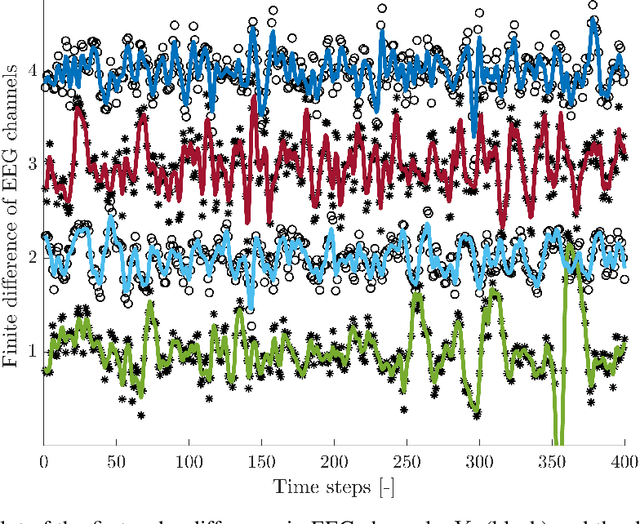
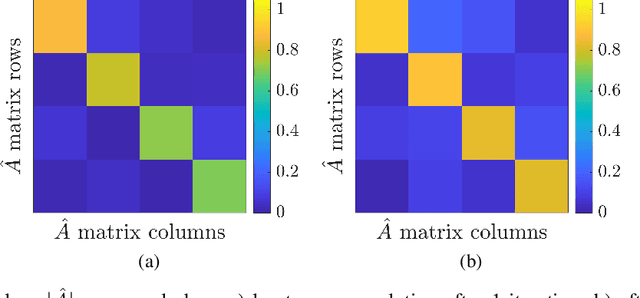
Autoregressive models are ubiquitous tools for the analysis of time series in many domains such as computational neuroscience and biomedical engineering. In these domains, data is, for example, collected from measurements of brain activity. Crucially, this data is subject to measurement errors as well as uncertainties in the underlying system model. As a result, standard signal processing using autoregressive model estimators may be biased. We present a framework for autoregressive modelling that incorporates these uncertainties explicitly via an overparameterised loss function. To optimise this loss, we derive an algorithm that alternates between state and parameter estimation. Our work shows that the procedure is able to successfully denoise time series and successfully reconstruct system parameters. This new paradigm can be used in a multitude of applications in neuroscience such as brain-computer interface data analysis and better understanding of brain dynamics in diseases such as epilepsy.
Hyper-Laplacian Regularized Concept Factorization in Low-rank Tensor Space for Multi-view Clustering
Apr 22, 2023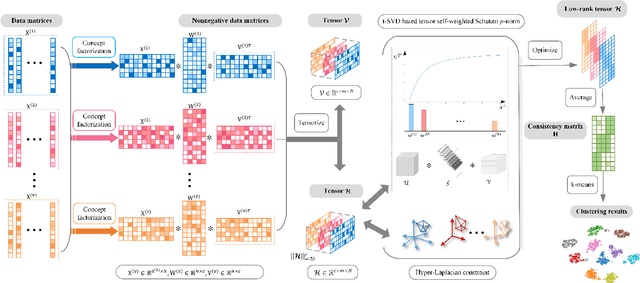
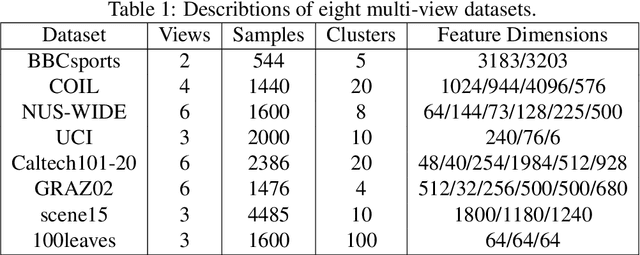
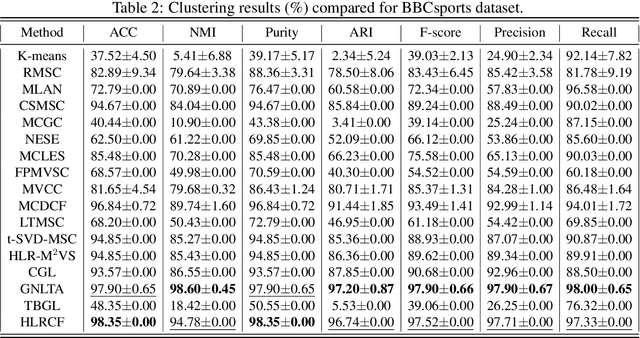

Tensor-oriented multi-view subspace clustering has achieved significant strides in assessing high-order correlations and improving clustering analysis of multi-view data. Nevertheless, most of existing investigations are typically hampered by the two flaws. First, self-representation based tensor subspace learning usually induces high time and space complexity, and is limited in perceiving nonlinear local structure in the embedding space. Second, the tensor singular value decomposition (t-SVD) model redistributes each singular value equally without considering the diverse importance among them. To well cope with the issues, we propose a hyper-Laplacian regularized concept factorization (HLRCF) in low-rank tensor space for multi-view clustering. Specifically, we adopt the concept factorization to explore the latent cluster-wise representation of each view. Further, the hypergraph Laplacian regularization endows the model with the capability of extracting the nonlinear local structures in the latent space. Considering that different tensor singular values associate structural information with unequal importance, we develop a self-weighted tensor Schatten p-norm to constrain the tensor comprised of all cluster-wise representations. Notably, the tensor with smaller size greatly decreases the time and space complexity in the low-rank optimization. Finally, experimental results on eight benchmark datasets exhibit that HLRCF outperforms other multi-view methods, showingcasing its superior performance.
A Classification of Feedback Loops and Their Relation to Biases in Automated Decision-Making Systems
May 10, 2023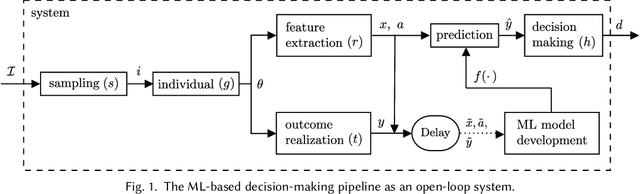

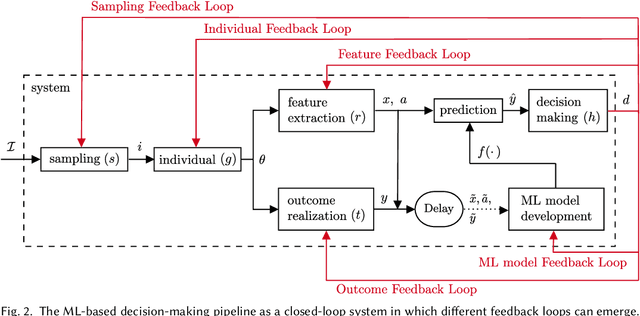
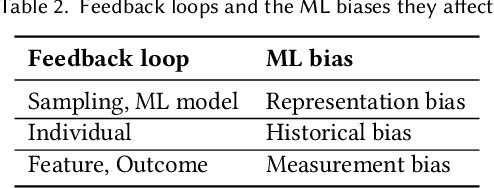
Prediction-based decision-making systems are becoming increasingly prevalent in various domains. Previous studies have demonstrated that such systems are vulnerable to runaway feedback loops, e.g., when police are repeatedly sent back to the same neighborhoods regardless of the actual rate of criminal activity, which exacerbate existing biases. In practice, the automated decisions have dynamic feedback effects on the system itself that can perpetuate over time, making it difficult for short-sighted design choices to control the system's evolution. While researchers started proposing longer-term solutions to prevent adverse outcomes (such as bias towards certain groups), these interventions largely depend on ad hoc modeling assumptions and a rigorous theoretical understanding of the feedback dynamics in ML-based decision-making systems is currently missing. In this paper, we use the language of dynamical systems theory, a branch of applied mathematics that deals with the analysis of the interconnection of systems with dynamic behaviors, to rigorously classify the different types of feedback loops in the ML-based decision-making pipeline. By reviewing existing scholarly work, we show that this classification covers many examples discussed in the algorithmic fairness community, thereby providing a unifying and principled framework to study feedback loops. By qualitative analysis, and through a simulation example of recommender systems, we show which specific types of ML biases are affected by each type of feedback loop. We find that the existence of feedback loops in the ML-based decision-making pipeline can perpetuate, reinforce, or even reduce ML biases.