 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Skin Lesion Diagnosis Using Convolutional Neural Networks
May 18, 2023
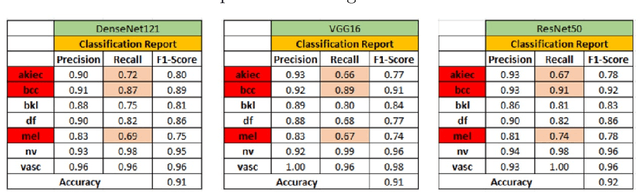
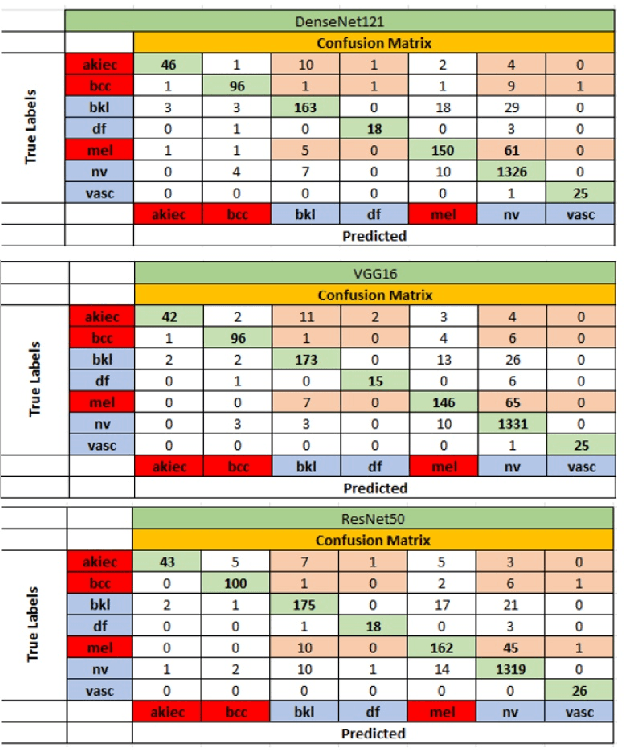
Cancerous skin lesions are one of the most common malignancies detected in humans, and if not detected at an early stage, they can lead to death. Therefore, it is crucial to have access to accurate results early on to optimize the chances of survival. Unfortunately, accurate results are typically obtained by highly trained dermatologists, who may not be accessible to many people, particularly in low-income and middle-income countries. Artificial Intelligence (AI) appears to be a potential solution to this problem, as it has proven to provide equal or even better diagnoses than healthcare professionals. This project aims to address the issue by collecting state-of-the-art techniques for image classification from various fields and implementing them. Some of these techniques include mixup, presizing, and test-time augmentation, among others. Three architectures were used for the implementation: DenseNet121, VGG16 with batch normalization, and ResNet50. The models were designed with two main purposes. First, to classify images into seven categories, including melanocytic nevus, melanoma, benign keratosis-like lesions, basal cell carcinoma, actinic keratoses and intraepithelial carcinoma, vascular lesions, and dermatofibroma. Second, to classify images into benign or malignant. The models were trained using a dataset of 8012 images, and their performance was evaluated using 2003 images. It's worth noting that this model is trained end-to-end, directly from the image to the labels, without the need for handcrafted feature extraction.
Distilling Script Knowledge from Large Language Models for Constrained Language Planning
May 10, 2023
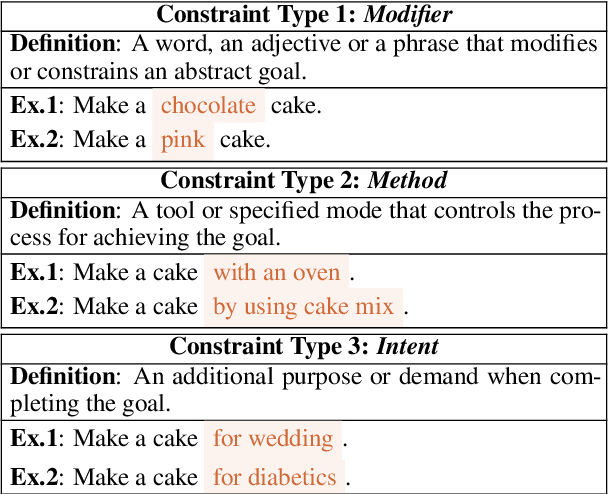
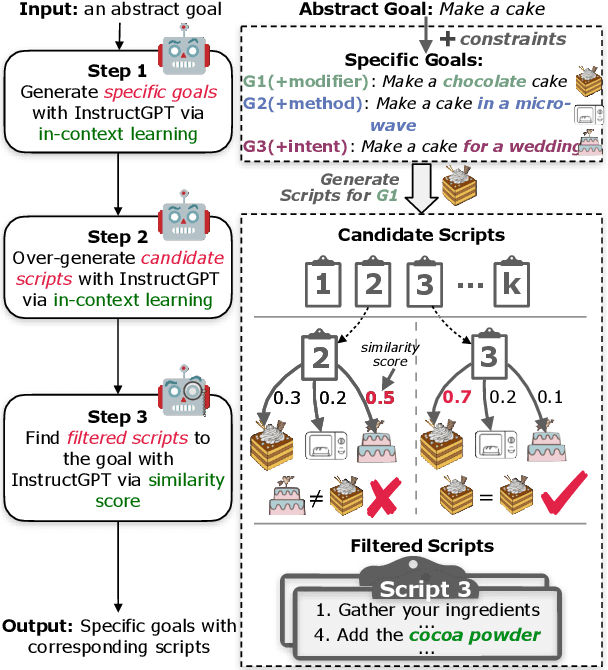

In everyday life, humans often plan their actions by following step-by-step instructions in the form of goal-oriented scripts. Previous work has exploited language models (LMs) to plan for abstract goals of stereotypical activities (e.g., "make a cake"), but leaves more specific goals with multi-facet constraints understudied (e.g., "make a cake for diabetics"). In this paper, we define the task of constrained language planning for the first time. We propose an overgenerate-then-filter approach to improve large language models (LLMs) on this task, and use it to distill a novel constrained language planning dataset, CoScript, which consists of 55,000 scripts. Empirical results demonstrate that our method significantly improves the constrained language planning ability of LLMs, especially on constraint faithfulness. Furthermore, CoScript is demonstrated to be quite effective in endowing smaller LMs with constrained language planning ability.
Reconstructing Animatable Categories from Videos
May 10, 2023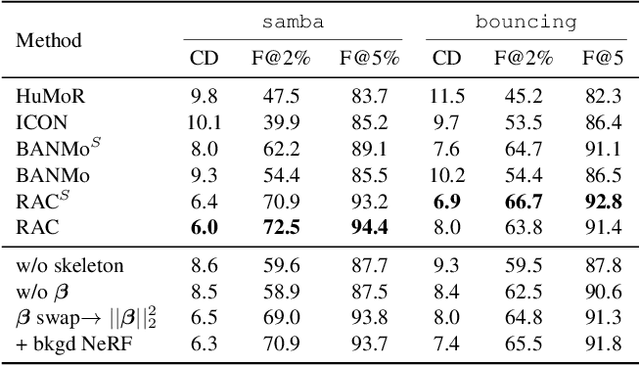



Building animatable 3D models is challenging due to the need for 3D scans, laborious registration, and manual rigging, which are difficult to scale to arbitrary categories. Recently, differentiable rendering provides a pathway to obtain high-quality 3D models from monocular videos, but these are limited to rigid categories or single instances. We present RAC that builds category 3D models from monocular videos while disentangling variations over instances and motion over time. Three key ideas are introduced to solve this problem: (1) specializing a skeleton to instances via optimization, (2) a method for latent space regularization that encourages shared structure across a category while maintaining instance details, and (3) using 3D background models to disentangle objects from the background. We show that 3D models of humans, cats, and dogs can be learned from 50-100 internet videos.
A Deep Learning Framework for Traffic Data Imputation Considering Spatiotemporal Dependencies
Apr 18, 2023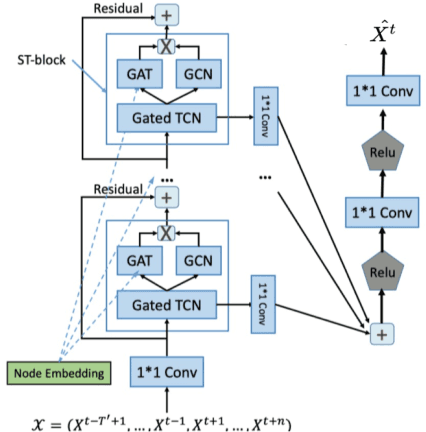
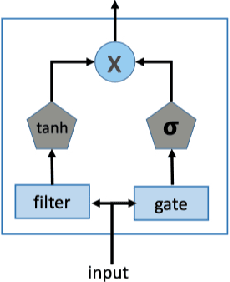

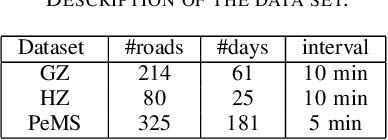
Spatiotemporal (ST) data collected by sensors can be represented as multi-variate time series, which is a sequence of data points listed in an order of time. Despite the vast amount of useful information, the ST data usually suffer from the issue of missing or incomplete data, which also limits its applications. Imputation is one viable solution and is often used to prepossess the data for further applications. However, in practice, n practice, spatiotemporal data imputation is quite difficult due to the complexity of spatiotemporal dependencies with dynamic changes in the traffic network and is a crucial prepossessing task for further applications. Existing approaches mostly only capture the temporal dependencies in time series or static spatial dependencies. They fail to directly model the spatiotemporal dependencies, and the representation ability of the models is relatively limited.
LATTE: Label-efficient Incident Phenotyping from Longitudinal Electronic Health Records
May 19, 2023
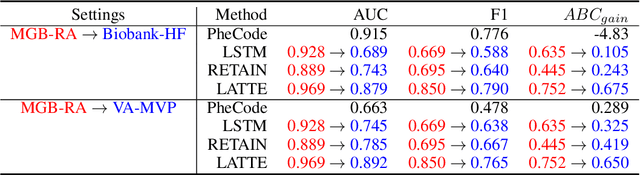
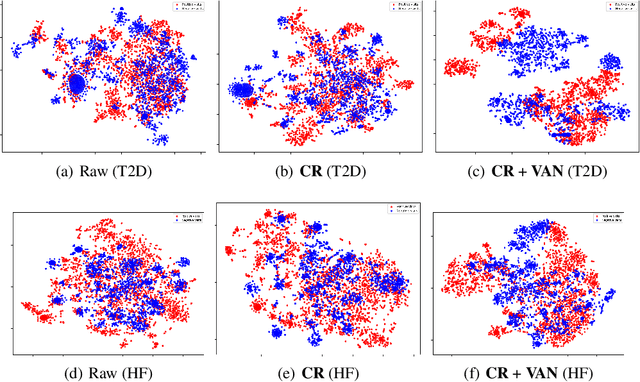

Electronic health record (EHR) data are increasingly used to support real-world evidence (RWE) studies. Yet its ability to generate reliable RWE is limited by the lack of readily available precise information on the timing of clinical events such as the onset time of heart failure. We propose a LAbel-efficienT incidenT phEnotyping (LATTE) algorithm to accurately annotate the timing of clinical events from longitudinal EHR data. By leveraging the pre-trained semantic embedding vectors from large-scale EHR data as prior knowledge, LATTE selects predictive EHR features in a concept re-weighting module by mining their relationship to the target event and compresses their information into longitudinal visit embeddings through a visit attention learning network. LATTE employs a recurrent neural network to capture the sequential dependency between the target event and visit embeddings before/after it. To improve label efficiency, LATTE constructs highly informative longitudinal silver-standard labels from large-scale unlabeled patients to perform unsupervised pre-training and semi-supervised joint training. Finally, LATTE enhances cross-site portability via contrastive representation learning. LATTE is evaluated on three analyses: the onset of type-2 diabetes, heart failure, and the onset and relapses of multiple sclerosis. We use various evaluation metrics present in the literature including the $ABC_{gain}$, the proportion of reduction in the area between the observed event indicator and the predicted cumulative incidences in reference to the prediction per incident prevalence. LATTE consistently achieves substantial improvement over benchmark methods such as SAMGEP and RETAIN in all settings.
Joint Graph Learning and Model Fitting in Laplacian Regularized Stratified Models
May 04, 2023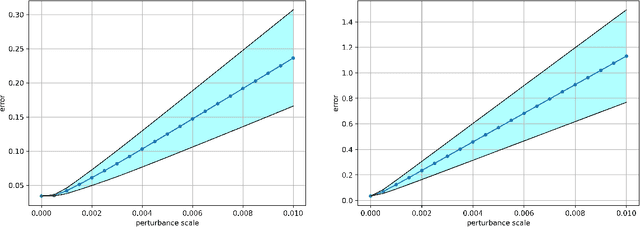
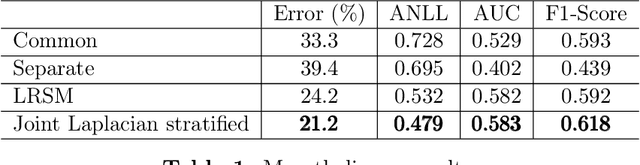
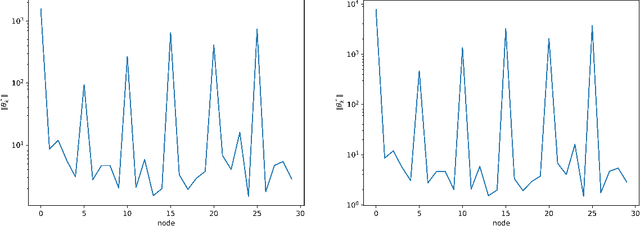
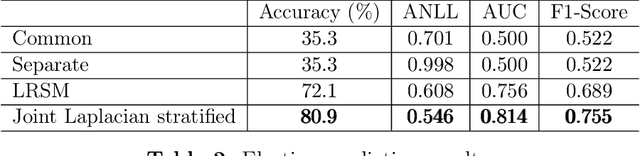
Laplacian regularized stratified models (LRSM) are models that utilize the explicit or implicit network structure of the sub-problems as defined by the categorical features called strata (e.g., age, region, time, forecast horizon, etc.), and draw upon data from neighboring strata to enhance the parameter learning of each sub-problem. They have been widely applied in machine learning and signal processing problems, including but not limited to time series forecasting, representation learning, graph clustering, max-margin classification, and general few-shot learning. Nevertheless, existing works on LRSM have either assumed a known graph or are restricted to specific applications. In this paper, we start by showing the importance and sensitivity of graph weights in LRSM, and provably show that the sensitivity can be arbitrarily large when the parameter scales and sample sizes are heavily imbalanced across nodes. We then propose a generic approach to jointly learn the graph while fitting the model parameters by solving a single optimization problem. We interpret the proposed formulation from both a graph connectivity viewpoint and an end-to-end Bayesian perspective, and propose an efficient algorithm to solve the problem. Convergence guarantees of the proposed optimization algorithm is also provided despite the lack of global strongly smoothness of the Laplacian regularization term typically required in the existing literature, which may be of independent interest. Finally, we illustrate the efficiency of our approach compared to existing methods by various real-world numerical examples.
Multilevel Sentence Embeddings for Personality Prediction
May 09, 2023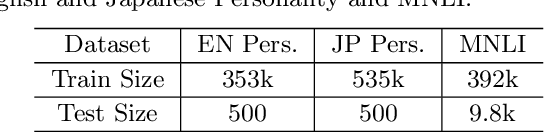
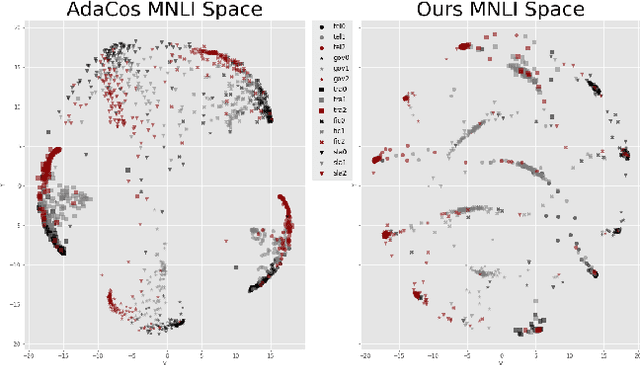
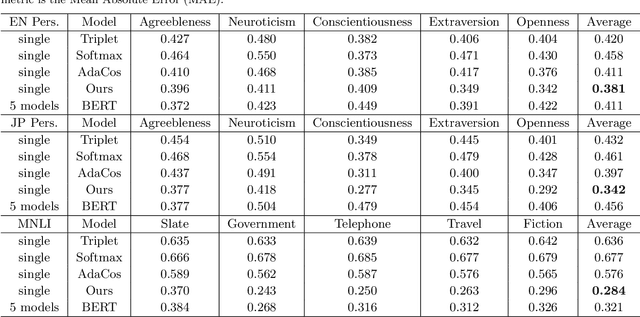
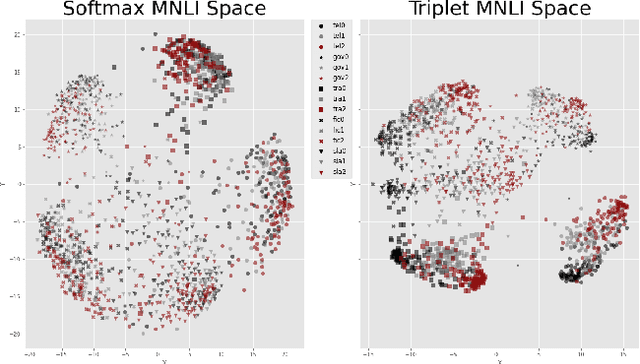
Representing text into a multidimensional space can be done with sentence embedding models such as Sentence-BERT (SBERT). However, training these models when the data has a complex multilevel structure requires individually trained class-specific models, which increases time and computing costs. We propose a two step approach which enables us to map sentences according to their hierarchical memberships and polarity. At first we teach the upper level sentence space through an AdaCos loss function and then finetune with a novel loss function mainly based on the cosine similarity of intra-level pairs. We apply this method to three different datasets: two weakly supervised Big Five personality dataset obtained from English and Japanese Twitter data and the benchmark MNLI dataset. We show that our single model approach performs better than multiple class-specific classification models.
* Copyright is owned by JSAI
Graph-Based Reductions for Parametric and Weighted MDPs
May 09, 2023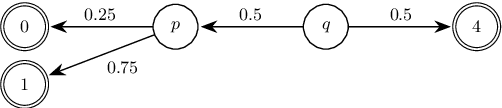
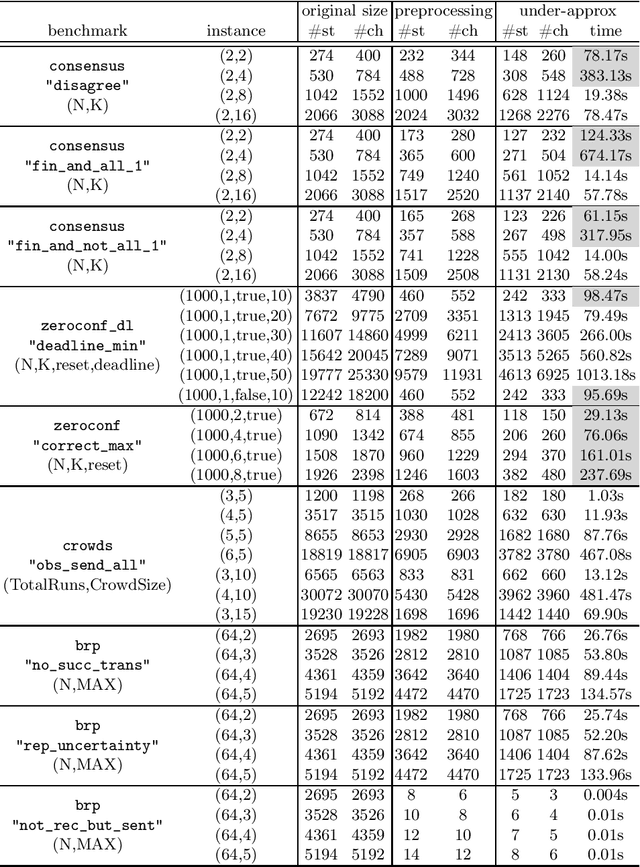
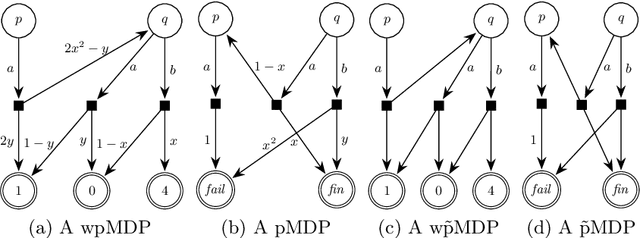
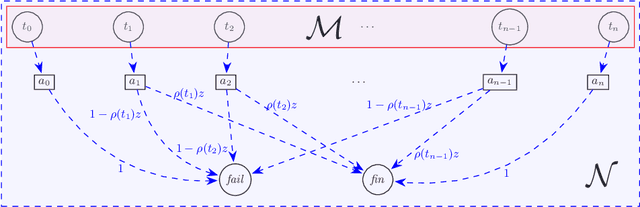
We study the complexity of reductions for weighted reachability in parametric Markov decision processes. That is, we say a state p is never worse than q if for all valuations of the polynomial indeterminates it is the case that the maximal expected weight that can be reached from p is greater than the same value from q. In terms of computational complexity, we establish that determining whether p is never worse than q is coETR-complete. On the positive side, we give a polynomial-time algorithm to compute the equivalence classes of the order we study for Markov chains. Additionally, we describe and implement two inference rules to under-approximate the never-worse relation and empirically show that it can be used as an efficient preprocessing step for the analysis of large Markov decision processes.
New Linear-time Algorithm for SubTree Kernel Computation based on Root-Weighted Tree Automata
Feb 02, 2023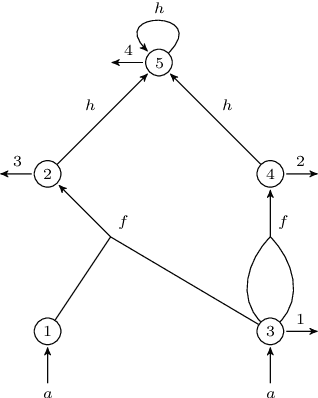

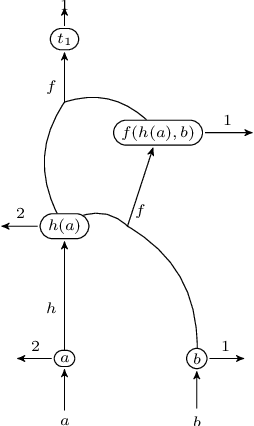
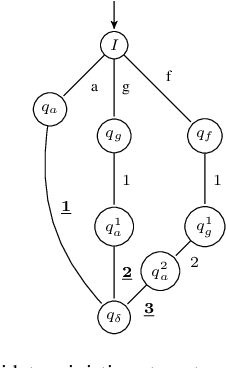
Tree kernels have been proposed to be used in many areas as the automatic learning of natural language applications. In this paper, we propose a new linear time algorithm based on the concept of weighted tree automata for SubTree kernel computation. First, we introduce a new class of weighted tree automata, called Root-Weighted Tree Automata, and their associated formal tree series. Then we define, from this class, the SubTree automata that represent compact computational models for finite tree languages. This allows us to design a theoretically guaranteed linear-time algorithm for computing the SubTree Kernel based on weighted tree automata intersection. The key idea behind the proposed algorithm is to replace DAG reduction and nodes sorting steps used in previous approaches by states equivalence classes computation allowed in the weighted tree automata approach. Our approach has three major advantages: it is output-sensitive, it is free sensitive from the tree types (ordered trees versus unordered trees), and it is well adapted to any incremental tree kernel based learning methods. Finally, we conduct a variety of comparative experiments on a wide range of synthetic tree languages datasets adapted for a deep algorithm analysis. The obtained results show that the proposed algorithm outperforms state-of-the-art methods.
Causal Structural Learning from Time Series: A Convex Optimization Approach
Jan 26, 2023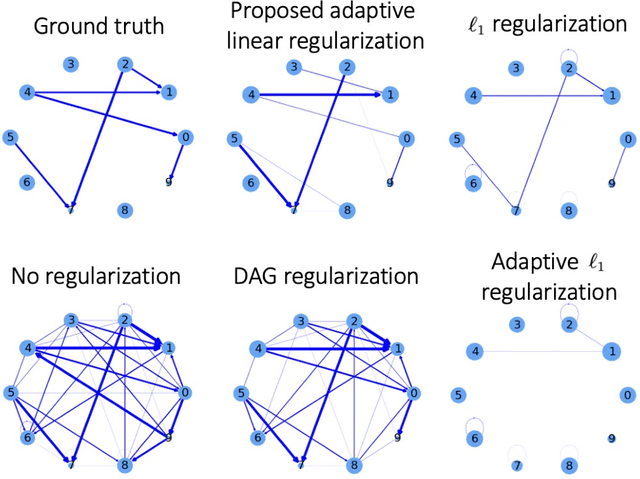
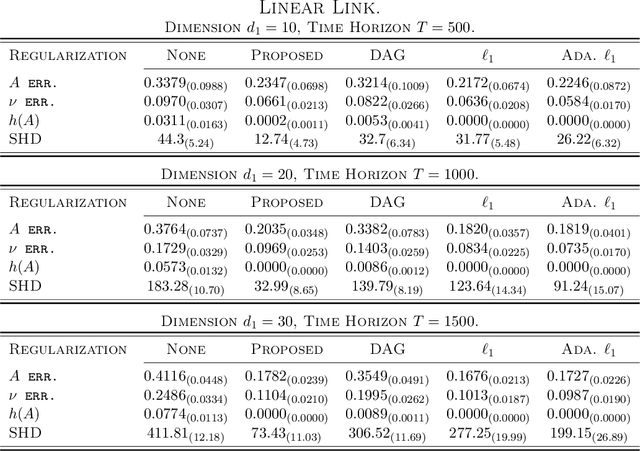
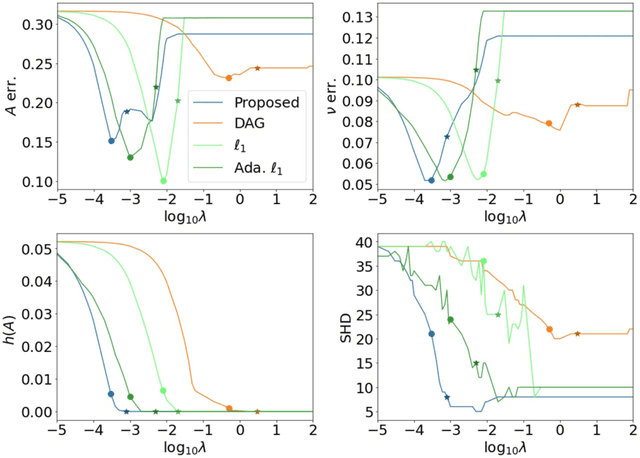
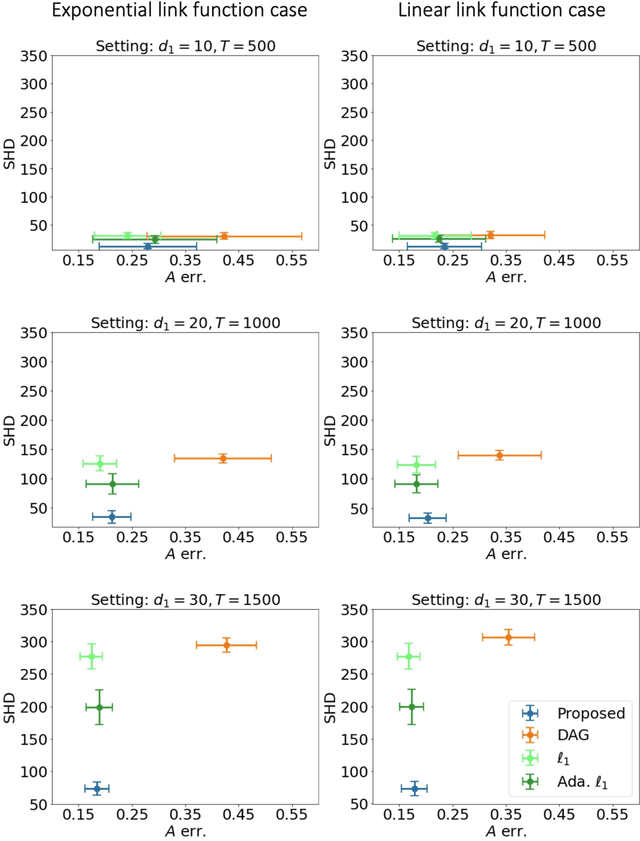
Structural learning, which aims to learn directed acyclic graphs (DAGs) from observational data, is foundational to causal reasoning and scientific discovery. Recent advancements formulate structural learning into a continuous optimization problem; however, DAG learning remains a highly non-convex problem, and there has not been much work on leveraging well-developed convex optimization techniques for causal structural learning. We fill this gap by proposing a data-adaptive linear approach for causal structural learning from time series data, which can be conveniently cast into a convex optimization problem using a recently developed monotone operator variational inequality (VI) formulation. Furthermore, we establish non-asymptotic recovery guarantee of the VI-based approach and show the superior performance of our proposed method on structure recovery over existing methods via extensive numerical experiments.