 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Prompt-Based Monte-Carlo Tree Search for Goal-Oriented Dialogue Policy Planning
May 23, 2023
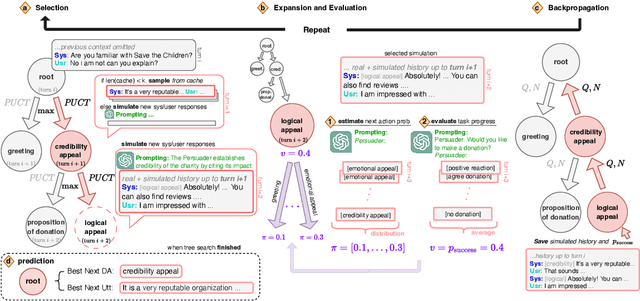
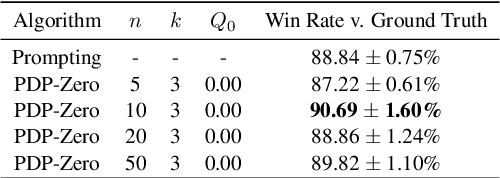
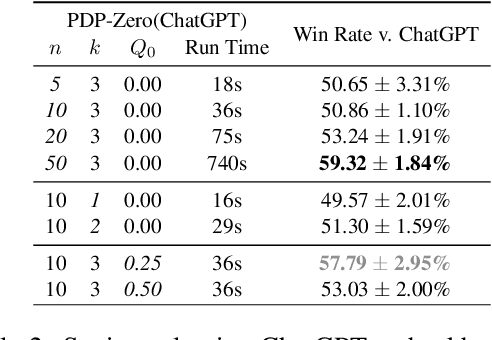
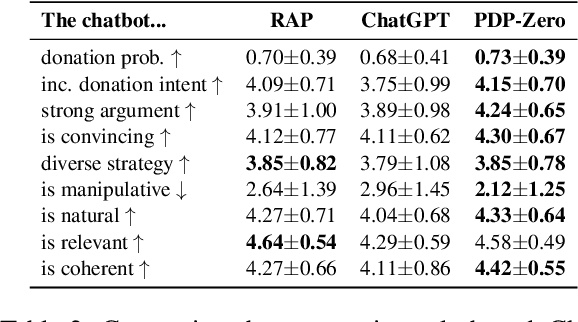
Planning for goal-oriented dialogue often requires simulating future dialogue interactions and estimating task progress. Many approaches thus consider training neural networks to perform look-ahead search algorithms such as A* search and Monte Carlo Tree Search (MCTS). However, this training often require abundant annotated data, which creates challenges when faced with noisy annotations or low-resource settings. We introduce GDP-Zero, an approach using Open-Loop MCTS to perform goal-oriented dialogue policy planning without any model training. GDP-Zero prompts a large language model to act as a policy prior, value function, user simulator, and system model during the tree search. We evaluate GDP-Zero on the goal-oriented task PersuasionForGood, and find that its responses are preferred over ChatGPT up to 59.32% of the time, and are rated more persuasive than ChatGPT during interactive evaluations.
Kernel Interpolation with Sparse Grids
May 23, 2023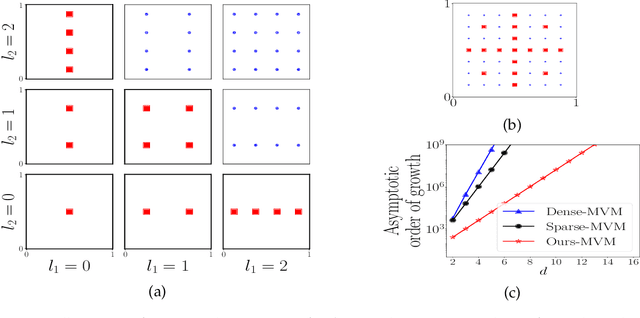
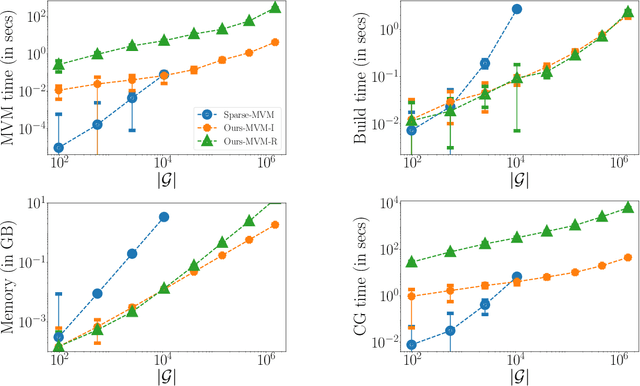
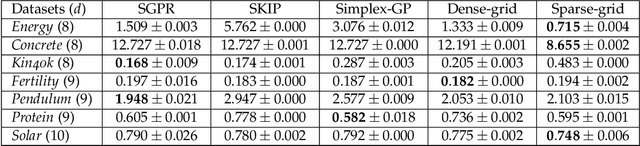
Structured kernel interpolation (SKI) accelerates Gaussian process (GP) inference by interpolating the kernel covariance function using a dense grid of inducing points, whose corresponding kernel matrix is highly structured and thus amenable to fast linear algebra. Unfortunately, SKI scales poorly in the dimension of the input points, since the dense grid size grows exponentially with the dimension. To mitigate this issue, we propose the use of sparse grids within the SKI framework. These grids enable accurate interpolation, but with a number of points growing more slowly with dimension. We contribute a novel nearly linear time matrix-vector multiplication algorithm for the sparse grid kernel matrix. Next, we describe how sparse grids can be combined with an efficient interpolation scheme based on simplices. With these changes, we demonstrate that SKI can be scaled to higher dimensions while maintaining accuracy.
Do Not Train It: A Linear Neural Architecture Search of Graph Neural Networks
May 23, 2023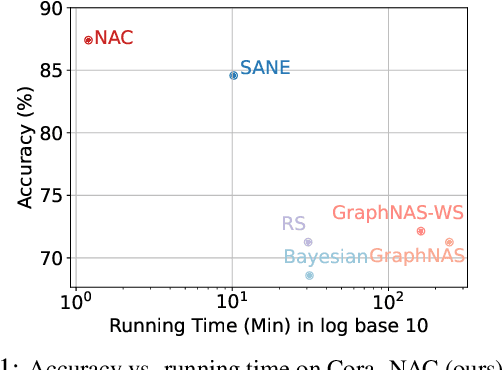
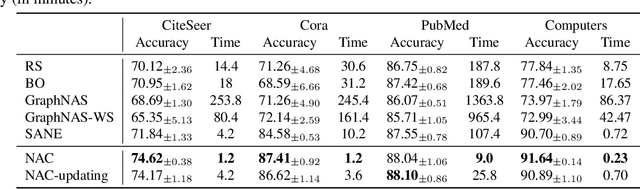
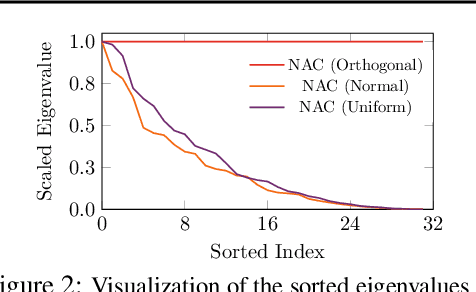
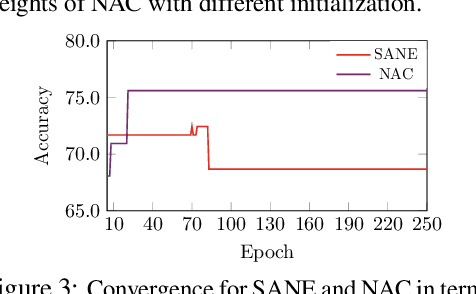
Neural architecture search (NAS) for Graph neural networks (GNNs), called NAS-GNNs, has achieved significant performance over manually designed GNN architectures. However, these methods inherit issues from the conventional NAS methods, such as high computational cost and optimization difficulty. More importantly, previous NAS methods have ignored the uniqueness of GNNs, where GNNs possess expressive power without training. With the randomly-initialized weights, we can then seek the optimal architecture parameters via the sparse coding objective and derive a novel NAS-GNNs method, namely neural architecture coding (NAC). Consequently, our NAC holds a no-update scheme on GNNs and can efficiently compute in linear time. Empirical evaluations on multiple GNN benchmark datasets demonstrate that our approach leads to state-of-the-art performance, which is up to $200\times$ faster and $18.8\%$ more accurate than the strong baselines.
Deep-Unfolding for Next-Generation Transceivers
May 15, 2023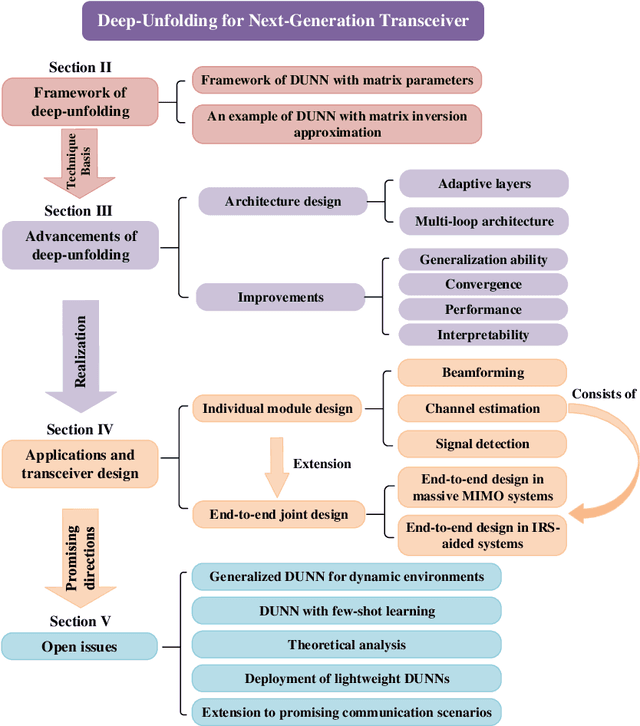
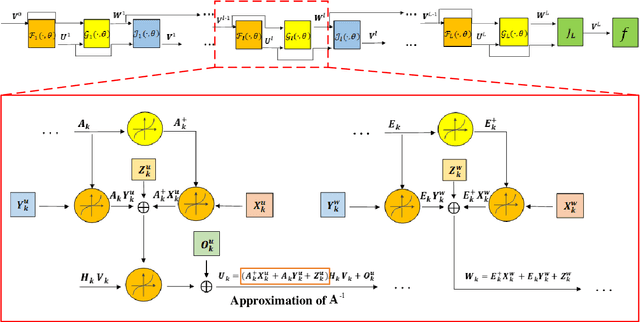
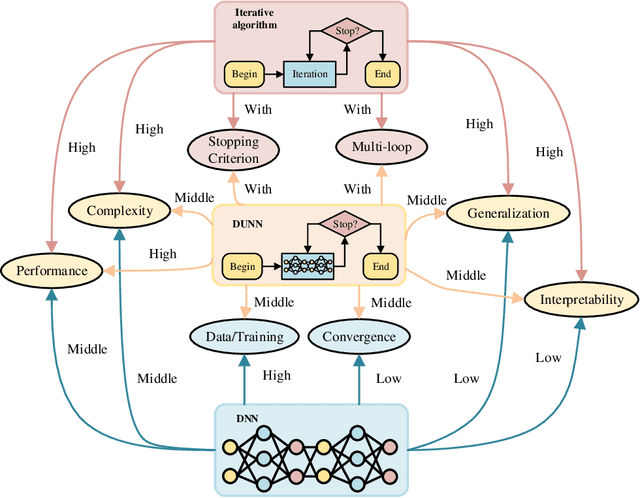
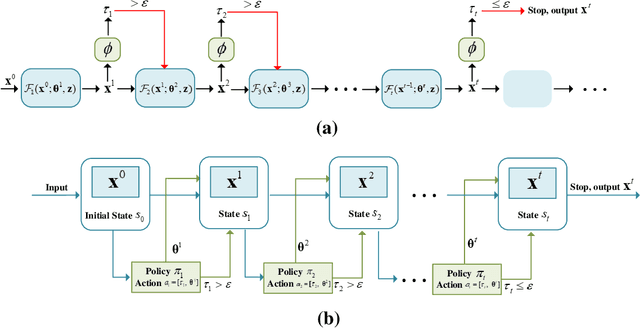
The stringent performance requirements of future wireless networks, such as ultra-high data rates, extremely high reliability and low latency, are spurring worldwide studies on defining the next-generation multiple-input multiple-output (MIMO) transceivers. For the design of advanced transceivers in wireless communications, optimization approaches often leading to iterative algorithms have achieved great success for MIMO transceivers. However, these algorithms generally require a large number of iterations to converge, which entails considerable computational complexity and often requires fine-tuning of various parameters. With the development of deep learning, approximating the iterative algorithms with deep neural networks (DNNs) can significantly reduce the computational time. However, DNNs typically lead to black-box solvers, which requires amounts of data and extensive training time. To further overcome these challenges, deep-unfolding has emerged which incorporates the benefits of both deep learning and iterative algorithms, by unfolding the iterative algorithm into a layer-wise structure analogous to DNNs. In this article, we first go through the framework of deep-unfolding for transceiver design with matrix parameters and its recent advancements. Then, some endeavors in applying deep-unfolding approaches in next-generation advanced transceiver design are presented. Moreover, some open issues for future research are highlighted.
User-Centric Clustering Under Fairness Scheduling in Cell-Free Massive MIMO
May 15, 2023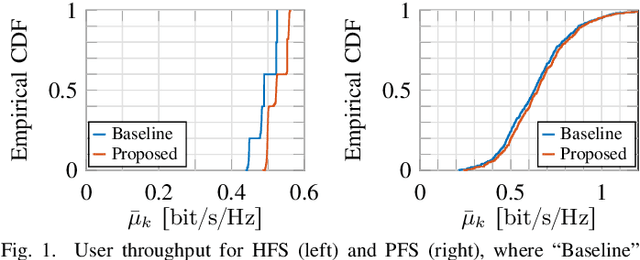
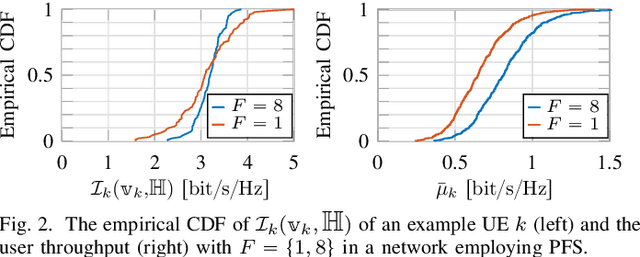
We consider fairness scheduling in a user-centric cell-free massive MIMO network, where $L$ remote radio units, each with $M$ antennas, serve $K_{\rm tot} \approx LM$ user equipments (UEs). Recent results show that the maximum network sum throughput is achieved where $K_{\rm act} \approx \frac{LM}{2}$ UEs are simultaneously active in any given time-frequency slots. However, the number of users $K_{\rm tot}$ in the network is usually much larger. This requires that users are scheduled over the time-frequency resource and achieve a certain throughput rate as an average over the slots. We impose throughput fairness among UEs with a scheduling approach aiming to maximize a concave component-wise non-decreasing network utility function of the per-user throughput rates. In cell-free user-centric networks, the pilot and cluster assignment is usually done for a given set of active users. Combined with fairness scheduling, this requires pilot and cluster reassignment at each scheduling slot, involving an enormous overhead of control signaling exchange between network entities. We propose a fixed pilot and cluster assignment scheme (independent of the scheduling decisions), which outperforms the baseline method in terms of UE throughput, while requiring much less control information exchange between network entities.
Flexible conditional density estimation for time series
Jan 23, 2023
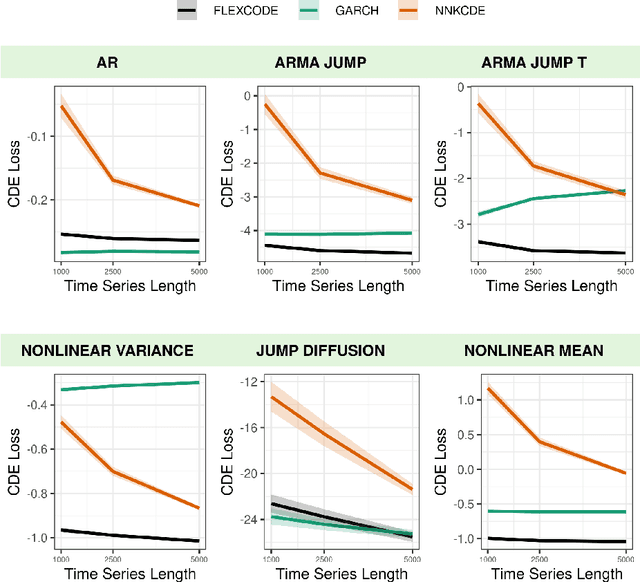
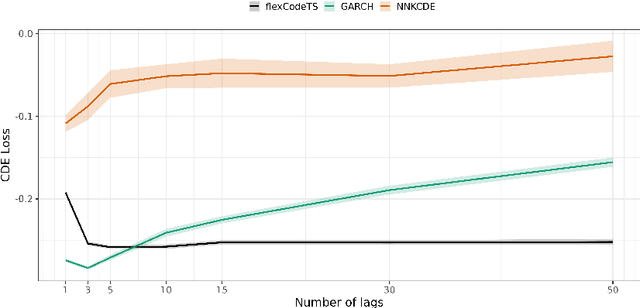
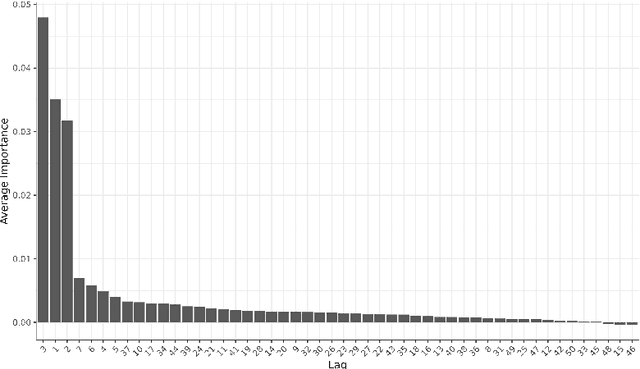
This paper introduces FlexCodeTS, a new conditional density estimator for time series. FlexCodeTS is a flexible nonparametric conditional density estimator, which can be based on an arbitrary regression method. It is shown that FlexCodeTS inherits the rate of convergence of the chosen regression method. Hence, FlexCodeTS can adapt its convergence by employing the regression method that best fits the structure of data. From an empirical perspective, FlexCodeTS is compared to NNKCDE and GARCH in both simulated and real data. FlexCodeTS is shown to generally obtain the best performance among the selected methods according to either the CDE loss or the pinball loss.
Stability and Convergence of Distributed Stochastic Approximations with large Unbounded Stochastic Information Delays
May 11, 2023We generalize the Borkar-Meyn stability Theorem (BMT) to distributed stochastic approximations (SAs) with information delays that possess an arbitrary moment bound. To model the delays, we introduce Age of Information Processes (AoIPs): stochastic processes on the non-negative integers with a unit growth property. We show that AoIPs with an arbitrary moment bound cannot exceed any fraction of time infinitely often. In combination with a suitably chosen stepsize, this property turns out to be sufficient for the stability of distributed SAs. Compared to the BMT, our analysis requires crucial modifications and a new line of argument to handle the SA errors caused by AoI. In our analysis, we show that these SA errors satisfy a recursive inequality. To evaluate this recursion, we propose a new Gronwall-type inequality for time-varying lower limits of summations. As applications to our distributed BMT, we discuss distributed gradient-based optimization and a new approach to analyzing SAs with momentum.
Distracting Downpour: Adversarial Weather Attacks for Motion Estimation
May 11, 2023

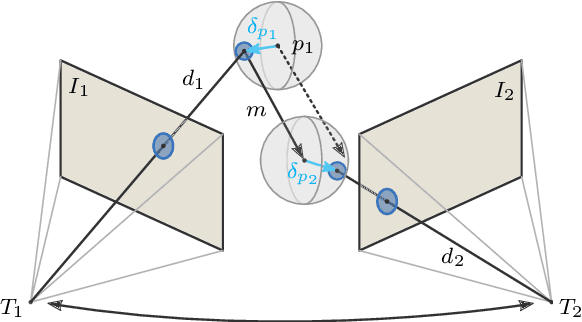
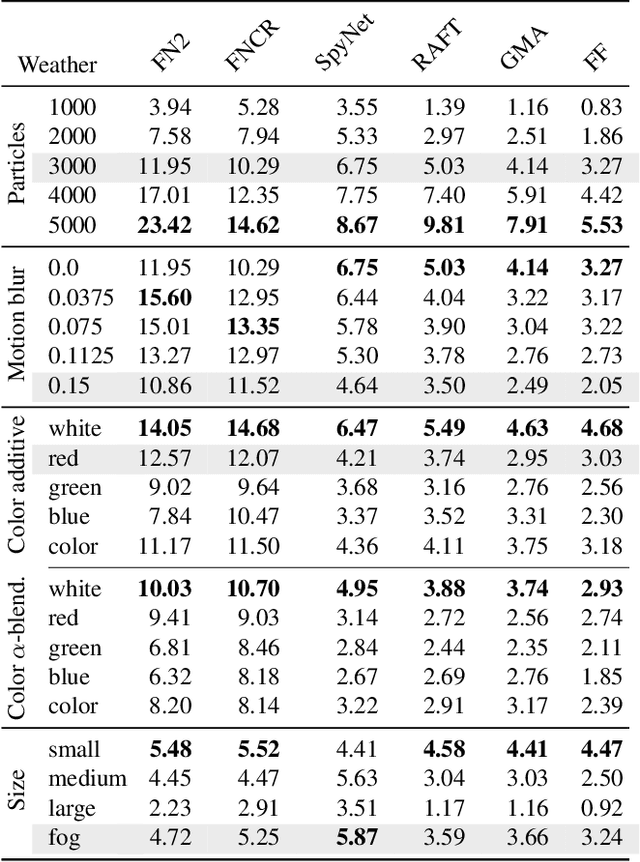
Current adversarial attacks on motion estimation, or optical flow, optimize small per-pixel perturbations, which are unlikely to appear in the real world. In contrast, adverse weather conditions constitute a much more realistic threat scenario. Hence, in this work, we present a novel attack on motion estimation that exploits adversarially optimized particles to mimic weather effects like snowflakes, rain streaks or fog clouds. At the core of our attack framework is a differentiable particle rendering system that integrates particles (i) consistently over multiple time steps (ii) into the 3D space (iii) with a photo-realistic appearance. Through optimization, we obtain adversarial weather that significantly impacts the motion estimation. Surprisingly, methods that previously showed good robustness towards small per-pixel perturbations are particularly vulnerable to adversarial weather. At the same time, augmenting the training with non-optimized weather increases a method's robustness towards weather effects and improves generalizability at almost no additional cost.
Towards Real-time Text-driven Image Manipulation with Unconditional Diffusion Models
Apr 10, 2023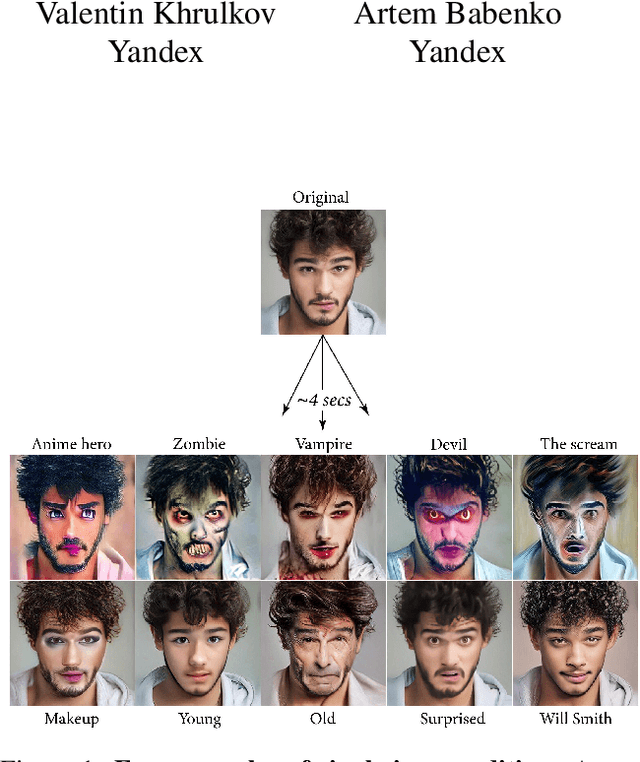
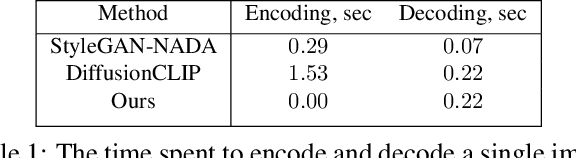
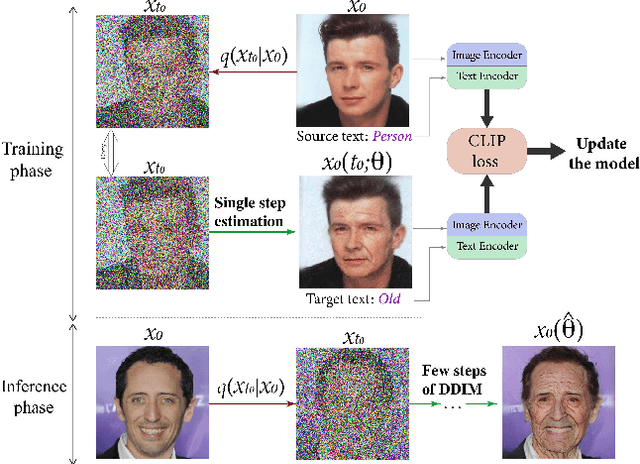
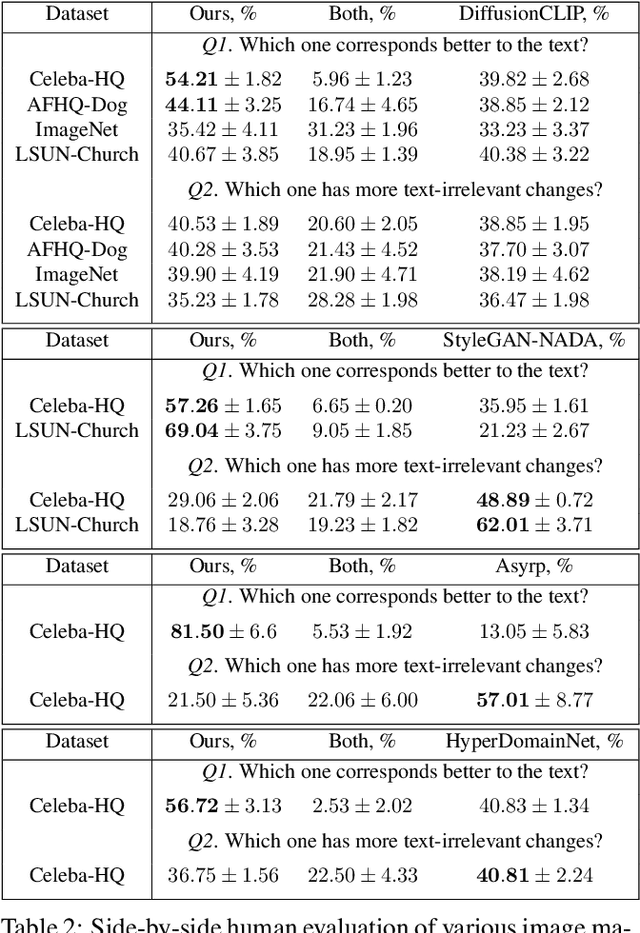
Recent advances in diffusion models enable many powerful instruments for image editing. One of these instruments is text-driven image manipulations: editing semantic attributes of an image according to the provided text description. % Popular text-conditional diffusion models offer various high-quality image manipulation methods for a broad range of text prompts. Existing diffusion-based methods already achieve high-quality image manipulations for a broad range of text prompts. However, in practice, these methods require high computation costs even with a high-end GPU. This greatly limits potential real-world applications of diffusion-based image editing, especially when running on user devices. In this paper, we address efficiency of the recent text-driven editing methods based on unconditional diffusion models and develop a novel algorithm that learns image manipulations 4.5-10 times faster and applies them 8 times faster. We carefully evaluate the visual quality and expressiveness of our approach on multiple datasets using human annotators. Our experiments demonstrate that our algorithm achieves the quality of much more expensive methods. Finally, we show that our approach can adapt the pretrained model to the user-specified image and text description on the fly just for 4 seconds. In this setting, we notice that more compact unconditional diffusion models can be considered as a rational alternative to the popular text-conditional counterparts.
Optimization of RIS-aided SISO Systems Based on a Mutually Coupled Loaded Wire Dipole Model
May 22, 2023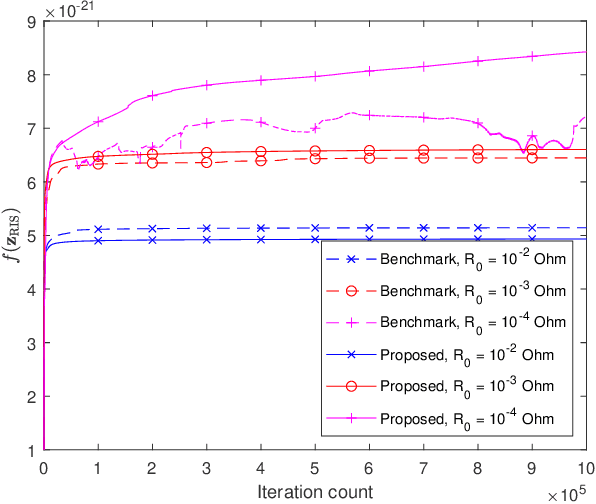
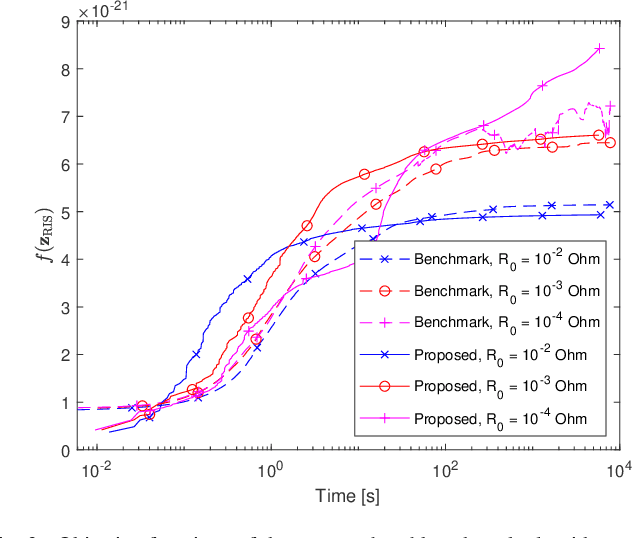
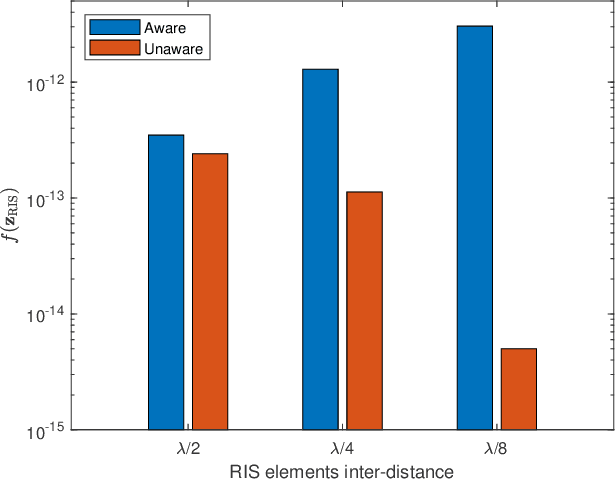
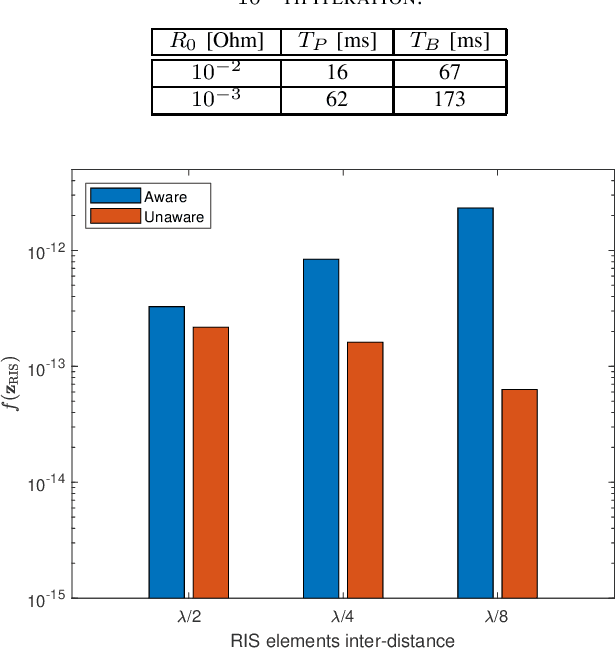
The electromagnetic (EM) features of reconfigurable intelligent surfaces (RISs) fundamentally determine their operating principles and performance. Motivated by these considerations, we study a single-input single-output (SISO) system in the presence of an RIS, which is characterized by a circuit-based EM-compliant model. Specifically, we model the RIS as a collection of thin wire dipoles controlled by tunable load impedances, and we propose a gradient-based algorithm for calculating the optimal impedances of the scattering elements of the RIS in the presence of mutual coupling. Furthermore, we prove the convergence of the proposed algorithm and derive its computational complexity in terms of number of complex multiplications. Numerical results show that the proposed algorithm provides better performance than a benchmark algorithm and that it converges in a shorter amount of time.