 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Tabular Foundation Models for Conditional Density Estimation in Regression
Mar 27, 2026Conditional density estimation (CDE) - recovering the full conditional distribution of a response given tabular covariates - is essential in settings with heteroscedasticity, multimodality, or asymmetric uncertainty. Recent tabular foundation models, such as TabPFN and TabICL, naturally produce predictive distributions, but their effectiveness as general-purpose CDE methods has not been systematically evaluated, unlike their performance for point prediction, which is well studied. We benchmark three tabular foundation model variants against a diverse set of parametric, tree-based, and neural CDE baselines on 39 real-world datasets, across training sizes from 50 to 20,000, using six metrics covering density accuracy, calibration, and computation time. Across all sample sizes, foundation models achieve the best CDE loss, log-likelihood, and CRPS on the large majority of datasets tested. Calibration is competitive at small sample sizes but, for some metrics and datasets, lags behind task-specific neural baselines at larger sample sizes, suggesting that post-hoc recalibration may be a valuable complement. In a photometric redshift case study using SDSS DR18, TabPFN exposed to 50,000 training galaxies outperforms all baselines trained on the full 500,000-galaxy dataset. Taken together, these results establish tabular foundation models as strong off-the-shelf conditional density estimators.
Trustworthy predictive distributions for rare events via diagnostic transport maps
Mar 11, 2026Forecast systems in science and technology are increasingly moving beyond point prediction toward methods that produce full predictive distributions of future outcomes y, conditional on high-dimensional and complex sequences of inputs x. However, even when forecast systems provide a full predictive distribution, the result is rarely calibrated with respect to all x and y. The estimated density can be especially unreliable in low-frequency or out-of-distribution regimes, where accurate uncertainty quantification and a means for human experts to verify results are most needed to establish trust in models. In this paper, we take an initial predictive distribution as given and treat it as a useful but potentially misspecified base model. WE then introduce diagnostic transport maps, covariate-dependent probability-to-probability maps that quantify how the base model's probabilities should be adjusted to better match the true conditional distribution of calibration data. At deployment, these maps provide the user with real-time local diagnostics that reveal where the model fails and how it fails (including bias, dispersion, skewness, and tail errors), while also producing a recalibrated predictive distribution through a simple composition with the base model. We apply diagnostic transport maps to short-term tropical cyclone intensity forecasting and show that an easy-to-fit parametric version identifies evolutionary modes associated with local miscalibration and improves the predictive performance for rare events, including 24-hour rapid intensity change, as compared to the operational forecasts of the National Hurricane Center.
LOCUS: A Distribution-Free Loss-Quantile Score for Risk-Aware Predictions
Mar 02, 2026Modern machine learning models can be accurate on average yet still make mistakes that dominate deployment cost. We introduce Locus, a distribution-free wrapper that produces a per-input loss-scale reliability score for a fixed prediction function. Rather than quantifying uncertainty about the label, Locus models the realized loss of the prediction function using any engine that outputs a predictive distribution for the loss given an input. A simple split-calibration step turns this function into a distribution-free interpretable score that is comparable across inputs and can be read as an upper loss level. The score is useful on its own for ranking, and it can optionally be thresholded to obtain a transparent flagging rule with distribution-free control of large-loss events. Experiments across 13 regression benchmarks show that Locus yields effective risk ranking and reduces large-loss frequency compared to standard heuristics.
LoBoost: Fast Model-Native Local Conformal Prediction for Gradient-Boosted Trees
Feb 25, 2026Gradient-boosted decision trees are among the strongest off-the-shelf predictors for tabular regression, but point predictions alone do not quantify uncertainty. Conformal prediction provides distribution-free marginal coverage, yet split conformal uses a single global residual quantile and can be poorly adaptive under heteroscedasticity. Methods that improve adaptivity typically fit auxiliary nuisance models or introduce additional data splits/partitions to learn the conformal score, increasing cost and reducing data efficiency. We propose LoBoost, a model-native local conformal method that reuses the fitted ensemble's leaf structure to define multiscale calibration groups. Each input is encoded by its sequence of visited leaves; at resolution level k, we group points by matching prefixes of leaf indices across the first k trees and calibrate residual quantiles within each group. LoBoost requires no retraining, auxiliary models, or extra splitting beyond the standard train/calibration split. Experiments show competitive interval quality, improved test MSE on most datasets, and large calibration speedups.
CP4SBI: Local Conformal Calibration of Credible Sets in Simulation-Based Inference
Aug 23, 2025



Current experimental scientists have been increasingly relying on simulation-based inference (SBI) to invert complex non-linear models with intractable likelihoods. However, posterior approximations obtained with SBI are often miscalibrated, causing credible regions to undercover true parameters. We develop $\texttt{CP4SBI}$, a model-agnostic conformal calibration framework that constructs credible sets with local Bayesian coverage. Our two proposed variants, namely local calibration via regression trees and CDF-based calibration, enable finite-sample local coverage guarantees for any scoring function, including HPD, symmetric, and quantile-based regions. Experiments on widely used SBI benchmarks demonstrate that our approach improves the quality of uncertainty quantification for neural posterior estimators using both normalizing flows and score-diffusion modeling.
Epistemic Uncertainty in Conformal Scores: A Unified Approach
Feb 10, 2025Conformal prediction methods create prediction bands with distribution-free guarantees but do not explicitly capture epistemic uncertainty, which can lead to overconfident predictions in data-sparse regions. Although recent conformal scores have been developed to address this limitation, they are typically designed for specific tasks, such as regression or quantile regression. Moreover, they rely on particular modeling choices for epistemic uncertainty, restricting their applicability. We introduce $\texttt{EPICSCORE}$, a model-agnostic approach that enhances any conformal score by explicitly integrating epistemic uncertainty. Leveraging Bayesian techniques such as Gaussian Processes, Monte Carlo Dropout, or Bayesian Additive Regression Trees, $\texttt{EPICSCORE}$ adaptively expands predictive intervals in regions with limited data while maintaining compact intervals where data is abundant. As with any conformal method, it preserves finite-sample marginal coverage. Additionally, it also achieves asymptotic conditional coverage. Experiments demonstrate its good performance compared to existing methods. Designed for compatibility with any Bayesian model, but equipped with distribution-free guarantees, $\texttt{EPICSCORE}$ provides a general-purpose framework for uncertainty quantification in prediction problems.
Distribution-Free Calibration of Statistical Confidence Sets
Nov 28, 2024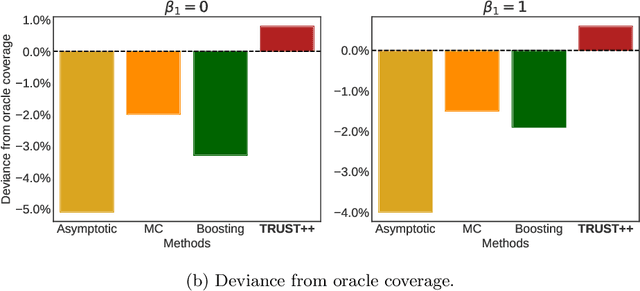
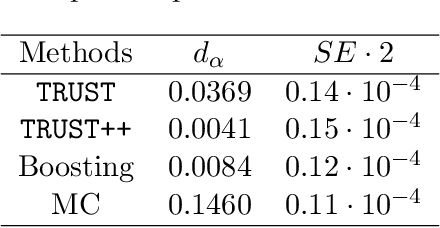
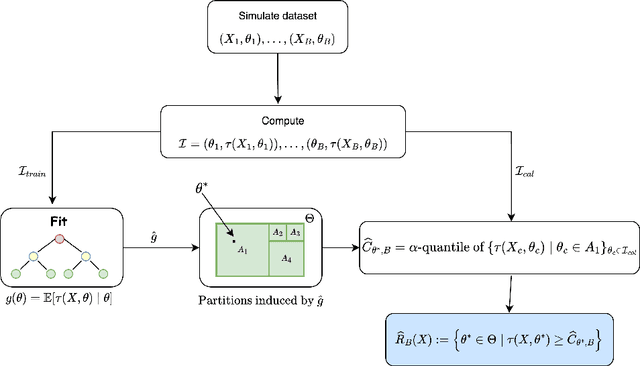
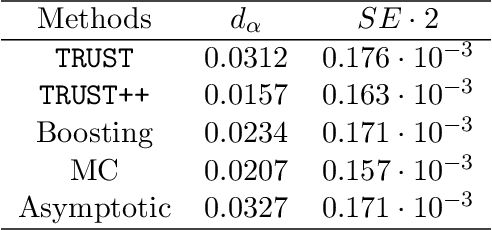
Constructing valid confidence sets is a crucial task in statistical inference, yet traditional methods often face challenges when dealing with complex models or limited observed sample sizes. These challenges are frequently encountered in modern applications, such as Likelihood-Free Inference (LFI). In these settings, confidence sets may fail to maintain a confidence level close to the nominal value. In this paper, we introduce two novel methods, TRUST and TRUST++, for calibrating confidence sets to achieve distribution-free conditional coverage. These methods rely entirely on simulated data from the statistical model to perform calibration. Leveraging insights from conformal prediction techniques adapted to the statistical inference context, our methods ensure both finite-sample local coverage and asymptotic conditional coverage as the number of simulations increases, even if n is small. They effectively handle nuisance parameters and provide computationally efficient uncertainty quantification for the estimated confidence sets. This allows users to assess whether additional simulations are necessary for robust inference. Through theoretical analysis and experiments on models with both tractable and intractable likelihoods, we demonstrate that our methods outperform existing approaches, particularly in small-sample regimes. This work bridges the gap between conformal prediction and statistical inference, offering practical tools for constructing valid confidence sets in complex models.
PersonalizedUS: Interpretable Breast Cancer Risk Assessment with Local Coverage Uncertainty Quantification
Aug 28, 2024



Correctly assessing the malignancy of breast lesions identified during ultrasound examinations is crucial for effective clinical decision-making. However, the current "golden standard" relies on manual BI-RADS scoring by clinicians, often leading to unnecessary biopsies and a significant mental health burden on patients and their families. In this paper, we introduce PersonalizedUS, an interpretable machine learning system that leverages recent advances in conformal prediction to provide precise and personalized risk estimates with local coverage guarantees and sensitivity, specificity, and predictive values above 0.9 across various threshold levels. In particular, we identify meaningful lesion subgroups where distribution-free, model-agnostic conditional coverage holds, with approximately 90% of our prediction sets containing only the ground truth in most lesion subgroups, thus explicitly characterizing for which patients the model is most suitably applied. Moreover, we make available a curated tabular dataset of 1936 biopsied breast lesions from a recent observational multicenter study and benchmark the performance of several state-of-the-art learning algorithms. We also report a successful case study of the deployed system in the same multicenter context. Concrete clinical benefits include up to a 65% reduction in requested biopsies among BI-RADS 4a and 4b lesions, with minimal to no missed cancer cases.
Regression Trees for Fast and Adaptive Prediction Intervals
Feb 13, 2024



Predictive models make mistakes. Hence, there is a need to quantify the uncertainty associated with their predictions. Conformal inference has emerged as a powerful tool to create statistically valid prediction regions around point predictions, but its naive application to regression problems yields non-adaptive regions. New conformal scores, often relying upon quantile regressors or conditional density estimators, aim to address this limitation. Although they are useful for creating prediction bands, these scores are detached from the original goal of quantifying the uncertainty around an arbitrary predictive model. This paper presents a new, model-agnostic family of methods to calibrate prediction intervals for regression problems with local coverage guarantees. Our approach is based on pursuing the coarsest partition of the feature space that approximates conditional coverage. We create this partition by training regression trees and Random Forests on conformity scores. Our proposal is versatile, as it applies to various conformity scores and prediction settings and demonstrates superior scalability and performance compared to established baselines in simulated and real-world datasets. We provide a Python package clover that implements our methods using the standard scikit-learn interface.
Classification under Nuisance Parameters and Generalized Label Shift in Likelihood-Free Inference
Feb 08, 2024



An open scientific challenge is how to classify events with reliable measures of uncertainty, when we have a mechanistic model of the data-generating process but the distribution over both labels and latent nuisance parameters is different between train and target data. We refer to this type of distributional shift as generalized label shift (GLS). Direct classification using observed data $\mathbf{X}$ as covariates leads to biased predictions and invalid uncertainty estimates of labels $Y$. We overcome these biases by proposing a new method for robust uncertainty quantification that casts classification as a hypothesis testing problem under nuisance parameters. The key idea is to estimate the classifier's receiver operating characteristic (ROC) across the entire nuisance parameter space, which allows us to devise cutoffs that are invariant under GLS. Our method effectively endows a pre-trained classifier with domain adaptation capabilities and returns valid prediction sets while maintaining high power. We demonstrate its performance on two challenging scientific problems in biology and astroparticle physics with data from realistic mechanistic models.