 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
FaceFusion: Exploiting Full Spectrum of Multiple Datasets
May 24, 2023
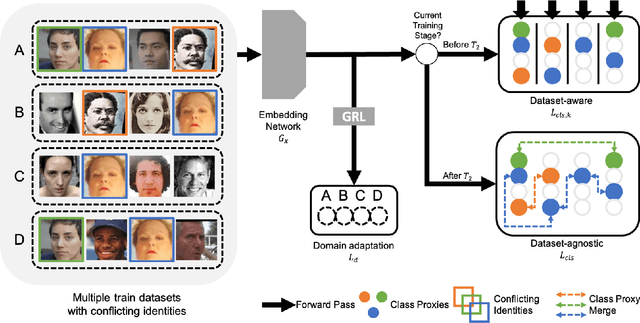
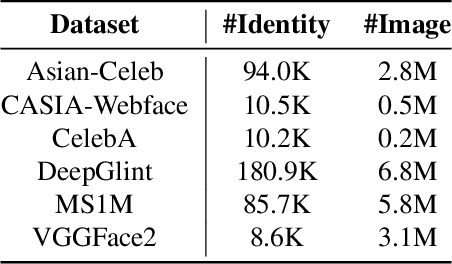
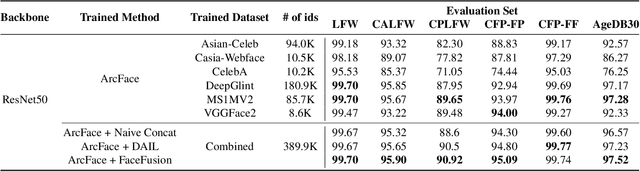

The size of training dataset is known to be among the most dominating aspects of training high-performance face recognition embedding model. Building a large dataset from scratch could be cumbersome and time-intensive, while combining multiple already-built datasets poses the risk of introducing large amount of label noise. We present a novel training method, named FaceFusion. It creates a fused view of different datasets that is untainted by identity conflicts, while concurrently training an embedding network using the view in an end-to-end fashion. Using the unified view of combined datasets enables the embedding network to be trained against the entire spectrum of the datasets, leading to a noticeable performance boost. Extensive experiments confirm superiority of our method, whose performance in public evaluation datasets surpasses not only that of using a single training dataset, but also that of previously known methods under various training circumstances.
Flexible conditional density estimation for time series
Jan 23, 2023
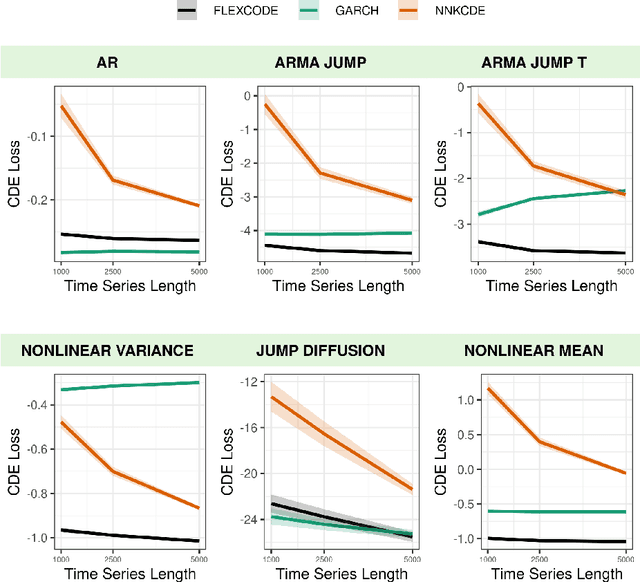
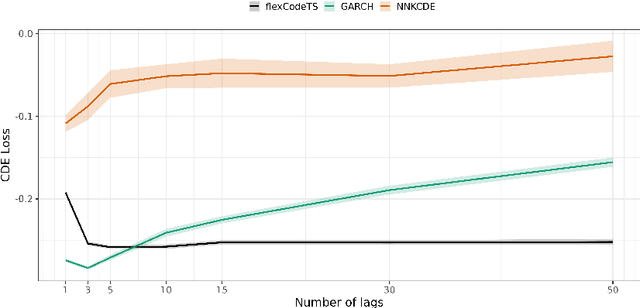
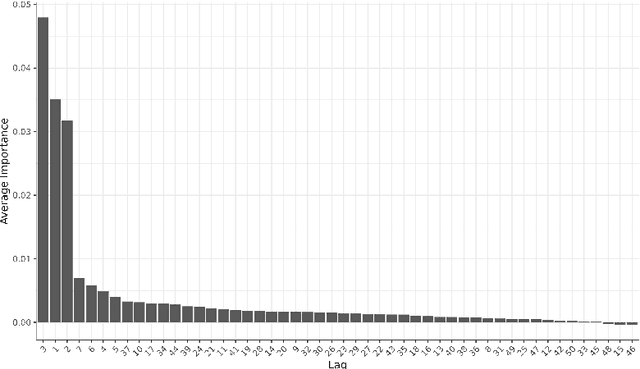
This paper introduces FlexCodeTS, a new conditional density estimator for time series. FlexCodeTS is a flexible nonparametric conditional density estimator, which can be based on an arbitrary regression method. It is shown that FlexCodeTS inherits the rate of convergence of the chosen regression method. Hence, FlexCodeTS can adapt its convergence by employing the regression method that best fits the structure of data. From an empirical perspective, FlexCodeTS is compared to NNKCDE and GARCH in both simulated and real data. FlexCodeTS is shown to generally obtain the best performance among the selected methods according to either the CDE loss or the pinball loss.
Unsupervised Melody-Guided Lyrics Generation
May 26, 2023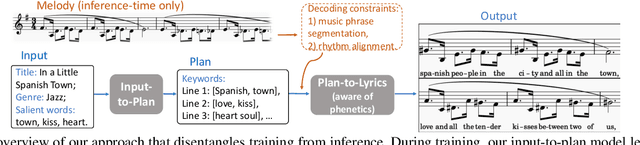

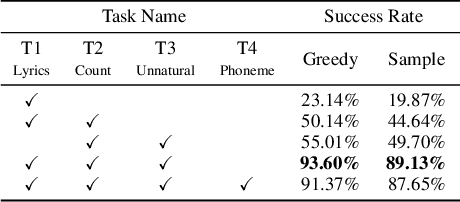
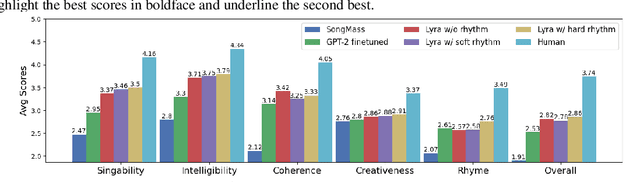
Automatic song writing is a topic of significant practical interest. However, its research is largely hindered by the lack of training data due to copyright concerns and challenged by its creative nature. Most noticeably, prior works often fall short of modeling the cross-modal correlation between melody and lyrics due to limited parallel data, hence generating lyrics that are less singable. Existing works also lack effective mechanisms for content control, a much desired feature for democratizing song creation for people with limited music background. In this work, we propose to generate pleasantly listenable lyrics without training on melody-lyric aligned data. Instead, we design a hierarchical lyric generation framework that disentangles training (based purely on text) from inference (melody-guided text generation). At inference time, we leverage the crucial alignments between melody and lyrics and compile the given melody into constraints to guide the generation process. Evaluation results show that our model can generate high-quality lyrics that are more singable, intelligible, coherent, and in rhyme than strong baselines including those supervised on parallel data.
SOC: Semantic-Assisted Object Cluster for Referring Video Object Segmentation
May 26, 2023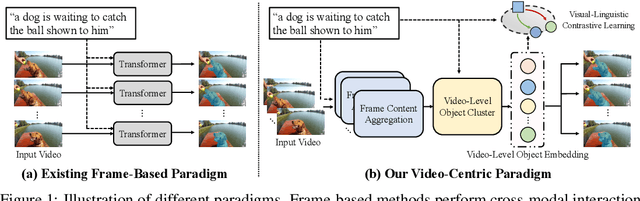
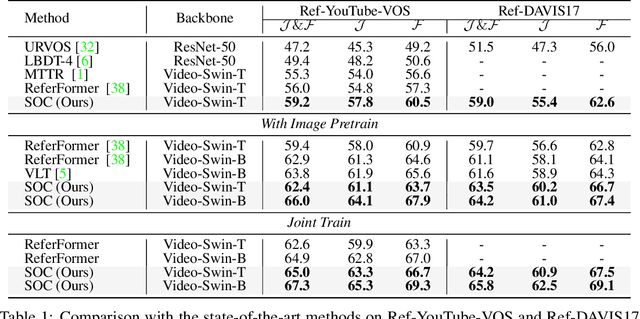
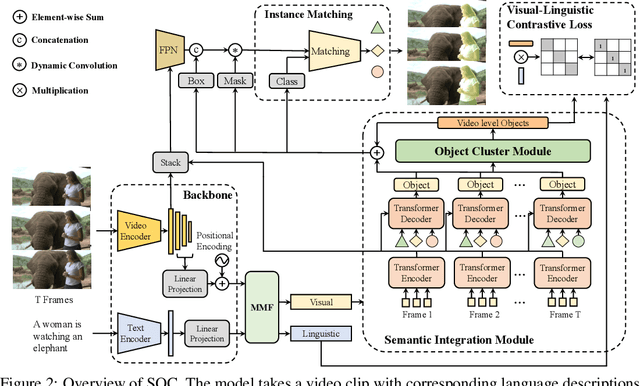
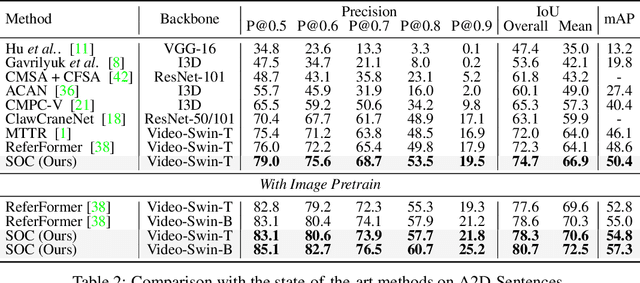
This paper studies referring video object segmentation (RVOS) by boosting video-level visual-linguistic alignment. Recent approaches model the RVOS task as a sequence prediction problem and perform multi-modal interaction as well as segmentation for each frame separately. However, the lack of a global view of video content leads to difficulties in effectively utilizing inter-frame relationships and understanding textual descriptions of object temporal variations. To address this issue, we propose Semantic-assisted Object Cluster (SOC), which aggregates video content and textual guidance for unified temporal modeling and cross-modal alignment. By associating a group of frame-level object embeddings with language tokens, SOC facilitates joint space learning across modalities and time steps. Moreover, we present multi-modal contrastive supervision to help construct well-aligned joint space at the video level. We conduct extensive experiments on popular RVOS benchmarks, and our method outperforms state-of-the-art competitors on all benchmarks by a remarkable margin. Besides, the emphasis on temporal coherence enhances the segmentation stability and adaptability of our method in processing text expressions with temporal variations. Code will be available.
GVdoc: Graph-based Visual Document Classification
May 26, 2023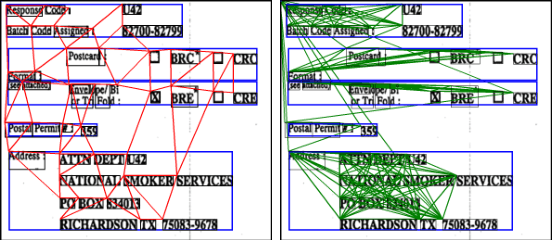
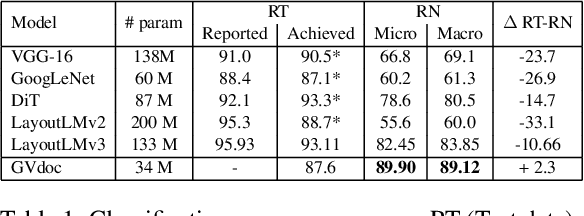
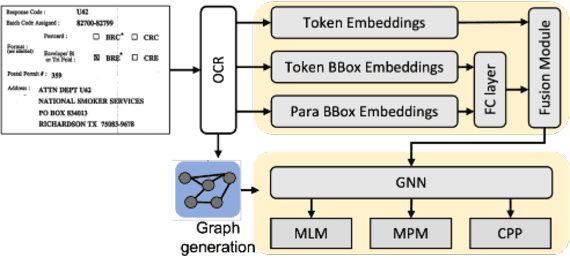

The robustness of a model for real-world deployment is decided by how well it performs on unseen data and distinguishes between in-domain and out-of-domain samples. Visual document classifiers have shown impressive performance on in-distribution test sets. However, they tend to have a hard time correctly classifying and differentiating out-of-distribution examples. Image-based classifiers lack the text component, whereas multi-modality transformer-based models face the token serialization problem in visual documents due to their diverse layouts. They also require a lot of computing power during inference, making them impractical for many real-world applications. We propose, GVdoc, a graph-based document classification model that addresses both of these challenges. Our approach generates a document graph based on its layout, and then trains a graph neural network to learn node and graph embeddings. Through experiments, we show that our model, even with fewer parameters, outperforms state-of-the-art models on out-of-distribution data while retaining comparable performance on the in-distribution test set.
Comparing Long Short-Term Memory (LSTM) and Bidirectional LSTM Deep Neural Networks for power consumption prediction
May 26, 2023
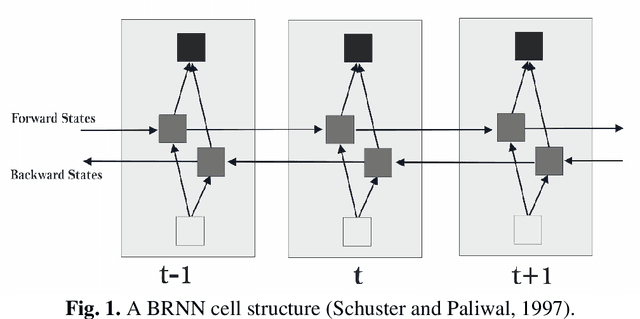
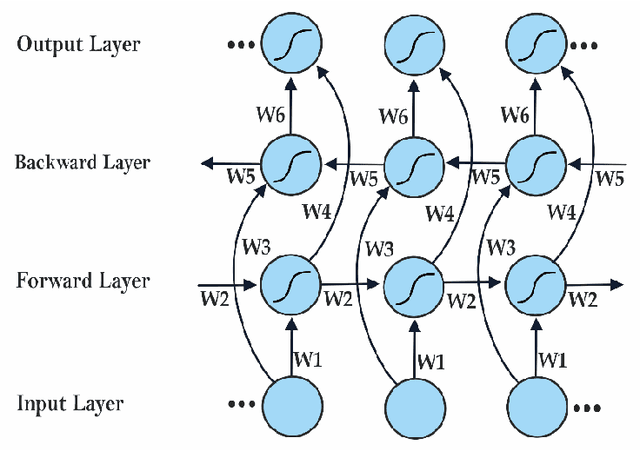
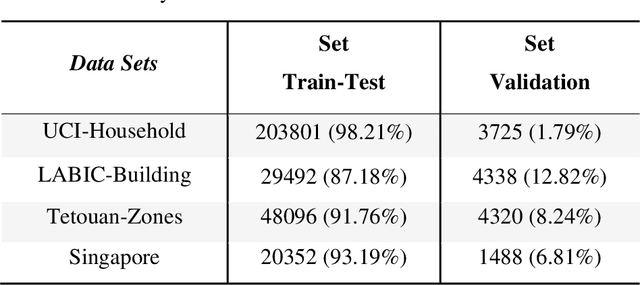
Electric consumption prediction methods are investigated for many reasons such as decision-making related to energy efficiency as well as for anticipating demand in the energy market dynamics. The objective of the present work is the comparison between two Deep Learning models, namely the Long Short-Term Memory (LSTM) and Bi-directional LSTM (BLSTM) for univariate electric consumption Time Series (TS) short-term forecast. The Data Sets (DSs) were selected for their different contexts and scales, aiming the assessment of the models' robustness. Four DSs were used, related to the power consumption of: (a) a household in France; (b) a university building in Santar\'em, Brazil; (c) the T\'etouan city zones, in Morocco; and (c) the Singapore aggregated electric demand. The metrics RMSE, MAE, MAPE and R2 were calculated in a TS cross-validation scheme. The Friedman's test was applied to normalized RMSE (NRMSE) results, showing that BLSTM outperforms LSTM with statistically significant difference (p = 0.0455), corroborating the fact that bidirectional weight updating improves significantly the LSTM performance concerning different scales of electric power consumption.
Sharpend Cosine Similarity based Neural Network for Hyperspectral Image Classification
May 26, 2023
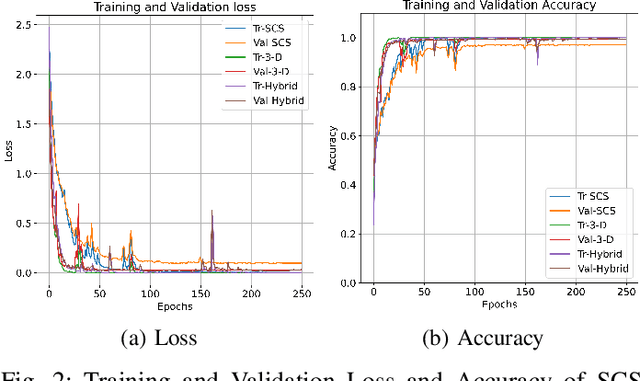

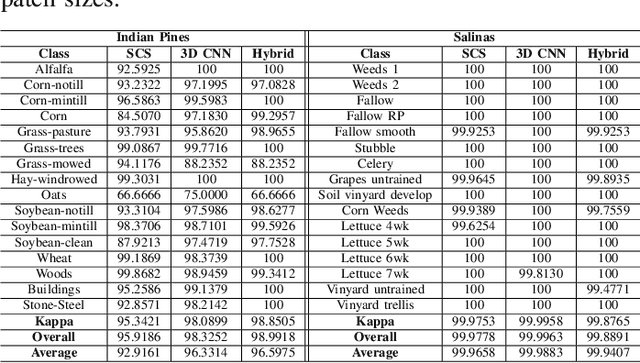
Hyperspectral Image Classification (HSIC) is a difficult task due to high inter and intra-class similarity and variability, nested regions, and overlapping. 2D Convolutional Neural Networks (CNN) emerged as a viable network whereas, 3D CNNs are a better alternative due to accurate classification. However, 3D CNNs are highly computationally complex due to their volume and spectral dimensions. Moreover, down-sampling and hierarchical filtering (high frequency) i.e., texture features need to be smoothed during the forward pass which is crucial for accurate HSIC. Furthermore, CNN requires tons of tuning parameters which increases the training time. Therefore, to overcome the aforesaid issues, Sharpened Cosine Similarity (SCS) concept as an alternative to convolutions in a Neural Network for HSIC is introduced. SCS is exceptionally parameter efficient due to skipping the non-linear activation layers, normalization, and dropout after the SCS layer. Use of MaxAbsPool instead of MaxPool which selects the element with the highest magnitude of activity, even if it's negative. Experimental results on publicly available HSI datasets proved the performance of SCS as compared to the convolutions in Neural Networks.
Diable: Efficient Dialogue State Tracking as Operations on Tables
May 26, 2023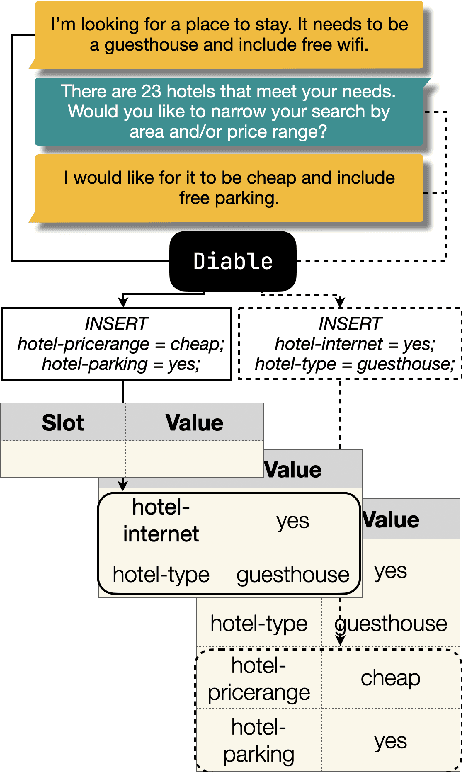
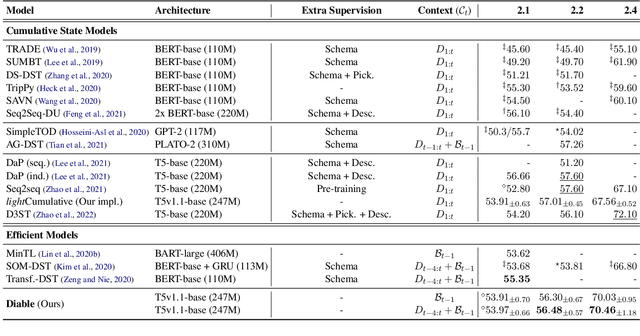

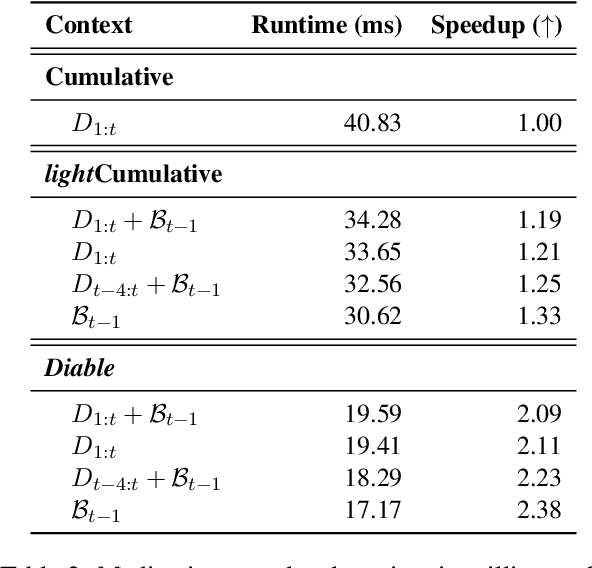
Sequence-to-sequence state-of-the-art systems for dialogue state tracking (DST) use the full dialogue history as input, represent the current state as a list with all the slots, and generate the entire state from scratch at each dialogue turn. This approach is inefficient, especially when the number of slots is large and the conversation is long. In this paper, we propose Diable, a new task formalisation that simplifies the design and implementation of efficient DST systems and allows one to easily plug and play large language models. We represent the dialogue state as a table and formalise DST as a table manipulation task. At each turn, the system updates the previous state by generating table operations based on the dialogue context. Extensive experimentation on the MultiWoz datasets demonstrates that Diable (i) outperforms strong efficient DST baselines, (ii) is 2.4x more time efficient than current state-of-the-art methods while retaining competitive Joint Goal Accuracy, and (iii) is robust to noisy data annotations due to the table operations approach.
Multi-Stage Monte Carlo Tree Search for Non-Monotone Object Rearrangement Planning in Narrow Confined Environments
May 26, 2023
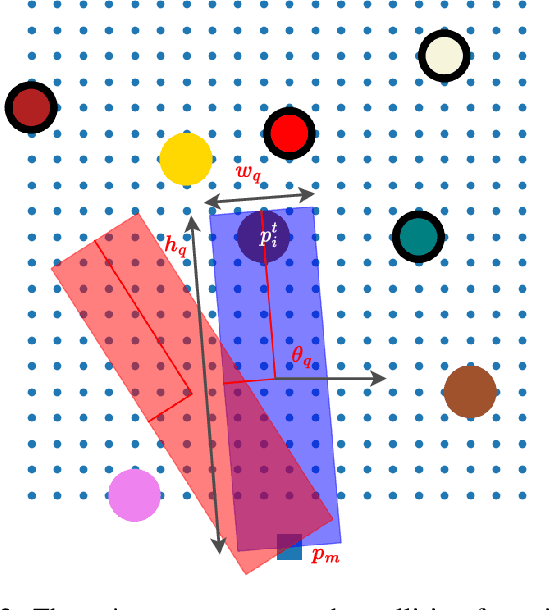


Non-monotone object rearrangement planning in confined spaces such as cabinets and shelves is a widely occurring but challenging problem in robotics. Both the robot motion and the available regions for object relocation are highly constrained because of the limited space. This work proposes a Multi-Stage Monte Carlo Tree Search (MS-MCTS) method to solve non-monotone object rearrangement planning problems in confined spaces. Our approach decouples the complex problem into simpler subproblems using an object stage topology. A subgoal-focused tree expansion algorithm that jointly considers the high-level planning and the low-level robot motion is designed to reduce the search space and better guide the search process. By fitting the task into the MCTS paradigm, our method produces optimistic solutions by balancing exploration and exploitation. The experiments demonstrate that our method outperforms the existing methods regarding the planning time, the number of steps, and the total move distance. Moreover, we deploy our MS-MCTS to a real-world robot system and verify its performance in different confined environments.
Efficient Open Domain Multi-Hop Question Answering with Few-Shot Data Synthesis
May 23, 2023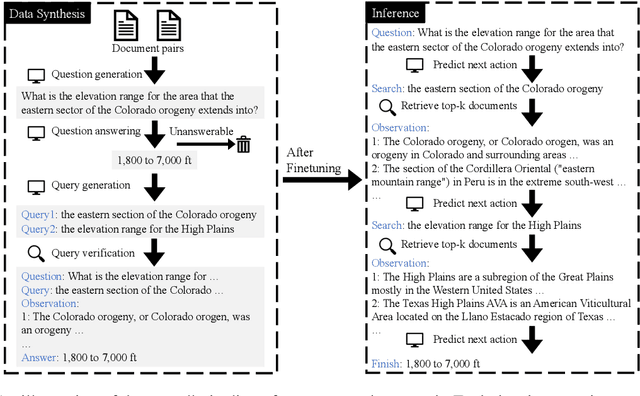
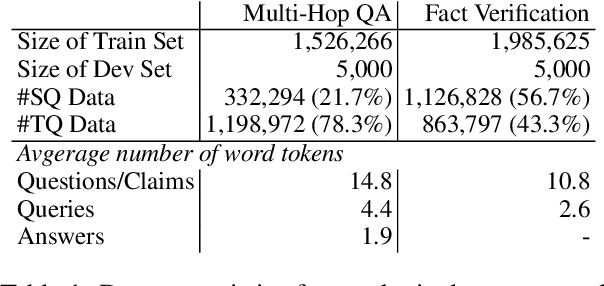

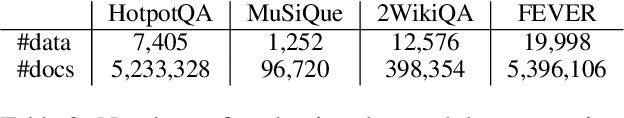
Few-shot learning for open domain multi-hop question answering typically relies on large language models (LLMs). While powerful, LLMs are inefficient at the inference time. We propose a data synthesis framework for multi-hop question answering that allows for improving smaller language models with less than 10 human-annotated question answer pairs. The framework is built upon the data generation functions parameterized by LLMs and prompts, which requires minimal hand-crafted features. Empirically, we synthesize millions of multi-hop questions and claims. After finetuning language models on the synthetic data, we evaluate the models on popular benchmarks on multi-hop question answering and fact verification. Our experimental results show that finetuning on the synthetic data improves model performance significantly, allowing our finetuned models to be competitive with prior models while being almost one-third the size in terms of parameter counts.