 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
River of No Return: Graph Percolation Embeddings for Efficient Knowledge Graph Reasoning
May 17, 2023
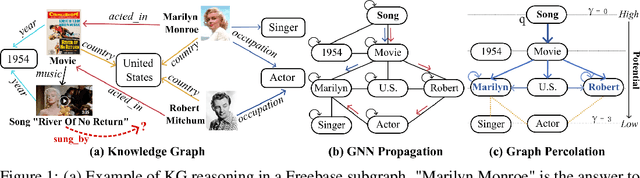
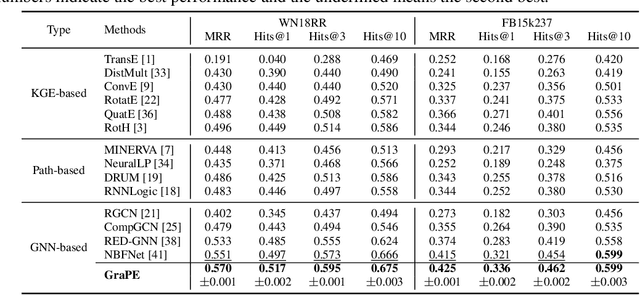

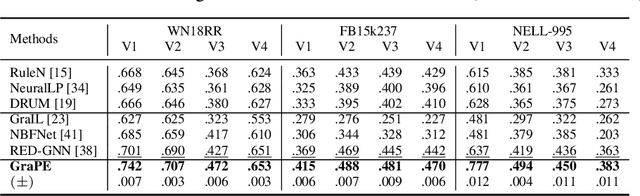
We study Graph Neural Networks (GNNs)-based embedding techniques for knowledge graph (KG) reasoning. For the first time, we link the path redundancy issue in the state-of-the-art KG reasoning models based on path encoding and message passing to the transformation error in model training, which brings us new theoretical insights into KG reasoning, as well as high efficacy in practice. On the theoretical side, we analyze the entropy of transformation error in KG paths and point out query-specific redundant paths causing entropy increases. These findings guide us to maintain the shortest paths and remove redundant paths for minimized-entropy message passing. To achieve this goal, on the practical side, we propose an efficient Graph Percolation Process motivated by the percolation model in Fluid Mechanics, and design a lightweight GNN-based KG reasoning framework called Graph Percolation Embeddings (GraPE). GraPE outperforms previous state-of-the-art methods in both transductive and inductive reasoning tasks while requiring fewer training parameters and less inference time.
TemporAI: Facilitating Machine Learning Innovation in Time Domain Tasks for Medicine
Jan 28, 2023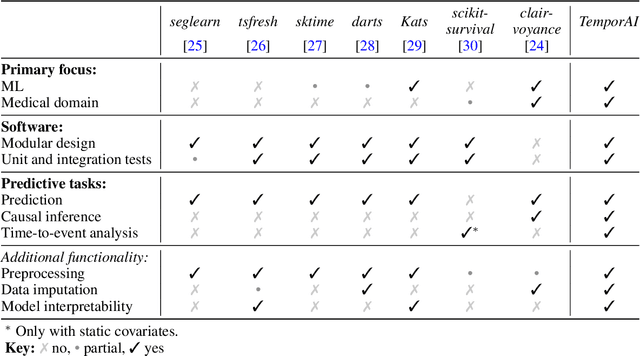
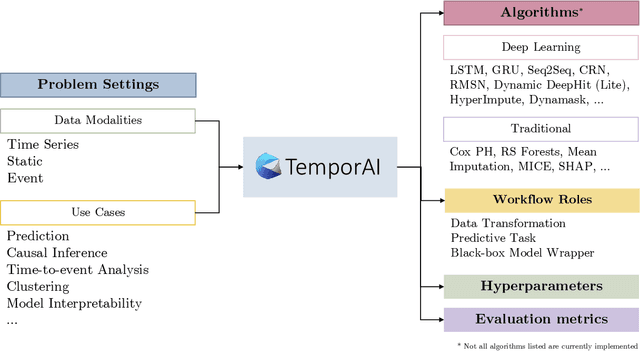
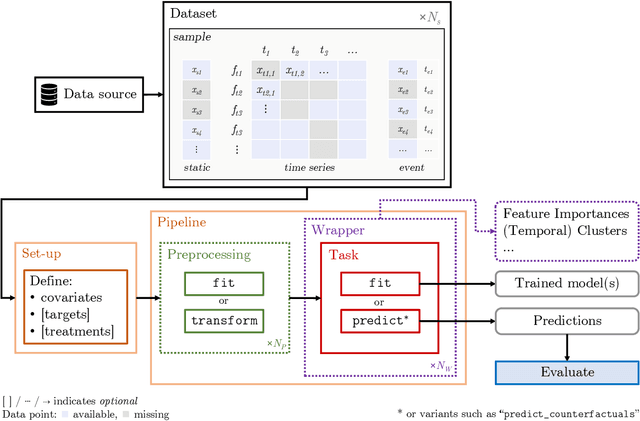
TemporAI is an open source Python software library for machine learning (ML) tasks involving data with a time component, focused on medicine and healthcare use cases. It supports data in time series, static, and eventmodalities and provides an interface for prediction, causal inference, and time-to-event analysis, as well as common preprocessing utilities and model interpretability methods. The library aims to facilitate innovation in the medical ML space by offering a standardized temporal setting toolkit for model development, prototyping and benchmarking, bridging the gaps in the ML research, healthcare professional, medical/pharmacological industry, and data science communities. TemporAI is available on GitHub (https://github.com/vanderschaarlab/temporai) and we welcome community engagement through use, feedback, and code contributions.
FishEye8K: A Benchmark and Dataset for Fisheye Camera Object Detection
Jun 06, 2023
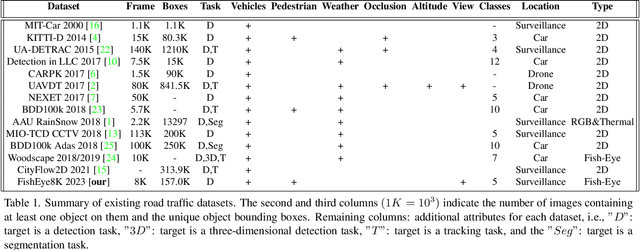
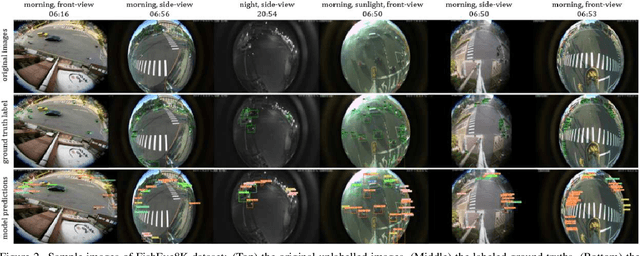
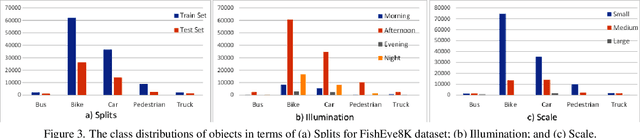
With the advance of AI, road object detection has been a prominent topic in computer vision, mostly using perspective cameras. Fisheye lens provides omnidirectional wide coverage for using fewer cameras to monitor road intersections, however with view distortions. To our knowledge, there is no existing open dataset prepared for traffic surveillance on fisheye cameras. This paper introduces an open FishEye8K benchmark dataset for road object detection tasks, which comprises 157K bounding boxes across five classes (Pedestrian, Bike, Car, Bus, and Truck). In addition, we present benchmark results of State-of-The-Art (SoTA) models, including variations of YOLOv5, YOLOR, YOLO7, and YOLOv8. The dataset comprises 8,000 images recorded in 22 videos using 18 fisheye cameras for traffic monitoring in Hsinchu, Taiwan, at resolutions of 1080$\times$1080 and 1280$\times$1280. The data annotation and validation process were arduous and time-consuming, due to the ultra-wide panoramic and hemispherical fisheye camera images with large distortion and numerous road participants, particularly people riding scooters. To avoid bias, frames from a particular camera were assigned to either the training or test sets, maintaining a ratio of about 70:30 for both the number of images and bounding boxes in each class. Experimental results show that YOLOv8 and YOLOR outperform on input sizes 640$\times$640 and 1280$\times$1280, respectively. The dataset will be available on GitHub with PASCAL VOC, MS COCO, and YOLO annotation formats. The FishEye8K benchmark will provide significant contributions to the fisheye video analytics and smart city applications.
Curriculum-Based Augmented Fourier Domain Adaptation for Robust Medical Image Segmentation
Jun 06, 2023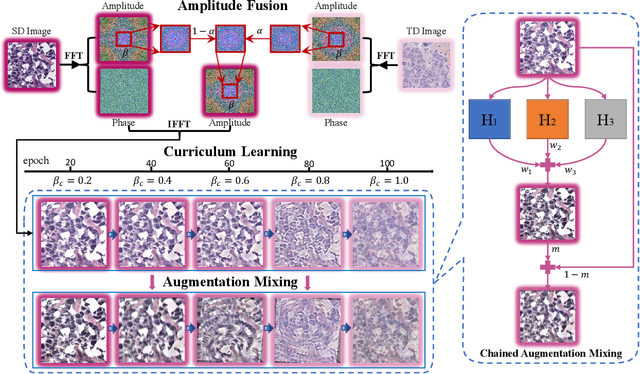

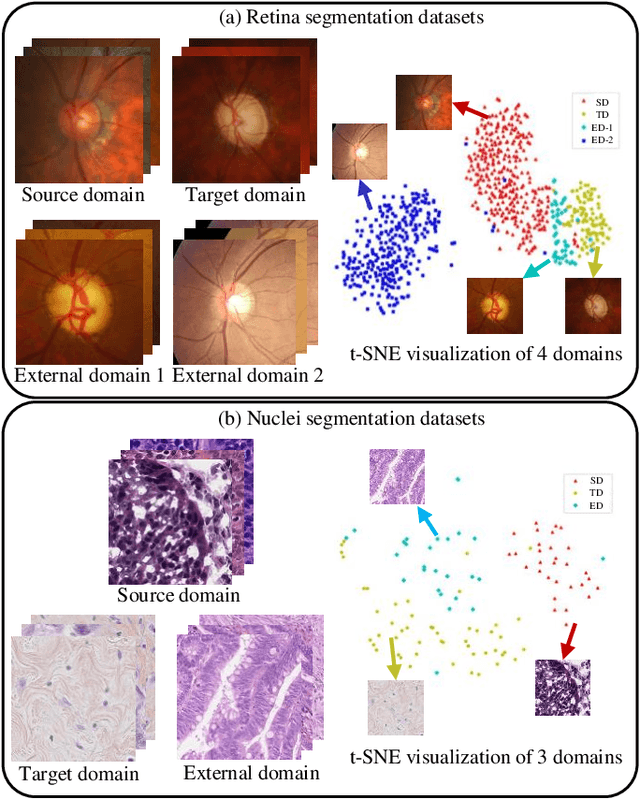
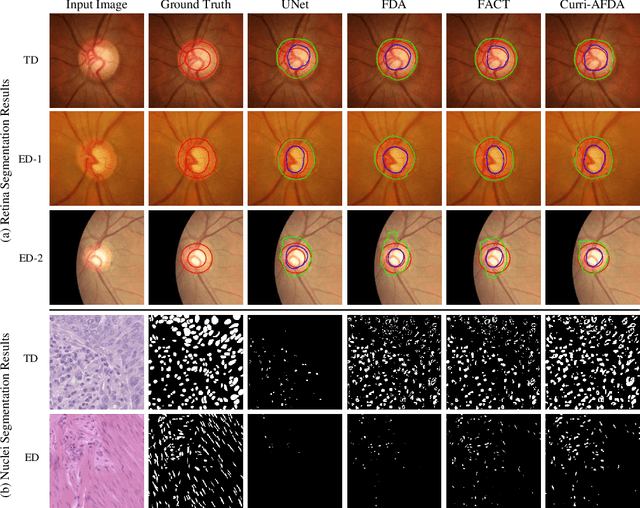
Accurate and robust medical image segmentation is fundamental and crucial for enhancing the autonomy of computer-aided diagnosis and intervention systems. Medical data collection normally involves different scanners, protocols, and populations, making domain adaptation (DA) a highly demanding research field to alleviate model degradation in the deployment site. To preserve the model performance across multiple testing domains, this work proposes the Curriculum-based Augmented Fourier Domain Adaptation (Curri-AFDA) for robust medical image segmentation. In particular, our curriculum learning strategy is based on the causal relationship of a model under different levels of data shift in the deployment phase, where the higher the shift is, the harder to recognize the variance. Considering this, we progressively introduce more amplitude information from the target domain to the source domain in the frequency space during the curriculum-style training to smoothly schedule the semantic knowledge transfer in an easier-to-harder manner. Besides, we incorporate the training-time chained augmentation mixing to help expand the data distributions while preserving the domain-invariant semantics, which is beneficial for the acquired model to be more robust and generalize better to unseen domains. Extensive experiments on two segmentation tasks of Retina and Nuclei collected from multiple sites and scanners suggest that our proposed method yields superior adaptation and generalization performance. Meanwhile, our approach proves to be more robust under various corruption types and increasing severity levels. In addition, we show our method is also beneficial in the domain-adaptive classification task with skin lesion datasets. The code is available at https://github.com/lofrienger/Curri-AFDA.
SAMoSSA: Multivariate Singular Spectrum Analysis with Stochastic Autoregressive Noise
May 25, 2023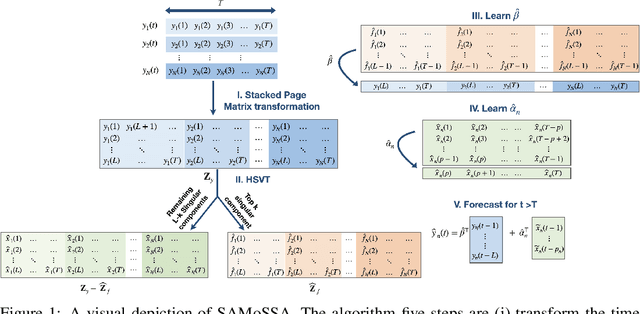

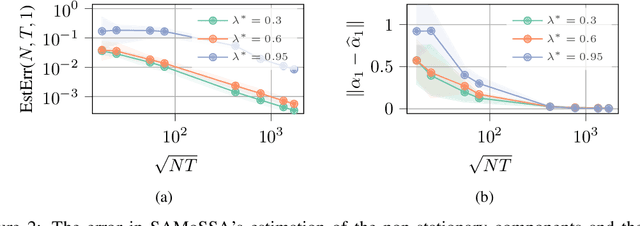

The well-established practice of time series analysis involves estimating deterministic, non-stationary trend and seasonality components followed by learning the residual stochastic, stationary components. Recently, it has been shown that one can learn the deterministic non-stationary components accurately using multivariate Singular Spectrum Analysis (mSSA) in the absence of a correlated stationary component; meanwhile, in the absence of deterministic non-stationary components, the Autoregressive (AR) stationary component can also be learnt readily, e.g. via Ordinary Least Squares (OLS). However, a theoretical underpinning of multi-stage learning algorithms involving both deterministic and stationary components has been absent in the literature despite its pervasiveness. We resolve this open question by establishing desirable theoretical guarantees for a natural two-stage algorithm, where mSSA is first applied to estimate the non-stationary components despite the presence of a correlated stationary AR component, which is subsequently learned from the residual time series. We provide a finite-sample forecasting consistency bound for the proposed algorithm, SAMoSSA, which is data-driven and thus requires minimal parameter tuning. To establish theoretical guarantees, we overcome three hurdles: (i) we characterize the spectra of Page matrices of stable AR processes, thus extending the analysis of mSSA; (ii) we extend the analysis of AR process identification in the presence of arbitrary bounded perturbations; (iii) we characterize the out-of-sample or forecasting error, as opposed to solely considering model identification. Through representative empirical studies, we validate the superior performance of SAMoSSA compared to existing baselines. Notably, SAMoSSA's ability to account for AR noise structure yields improvements ranging from 5% to 37% across various benchmark datasets.
rPPG-MAE: Self-supervised Pre-training with Masked Autoencoders for Remote Physiological Measurement
Jun 04, 2023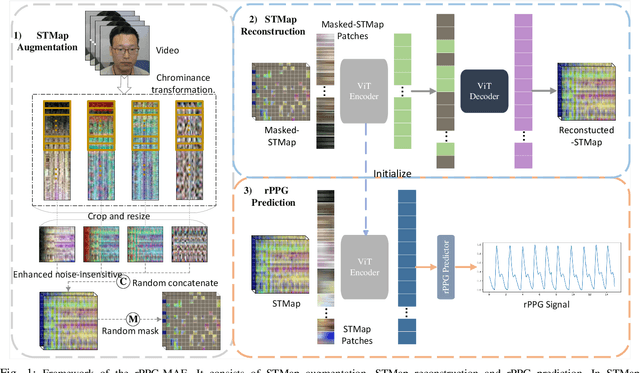
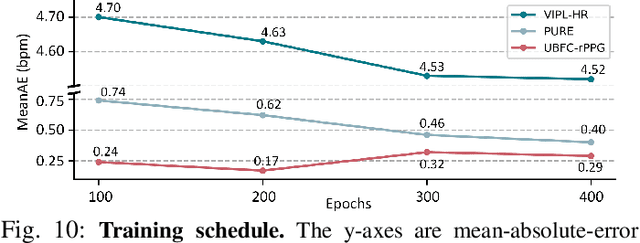
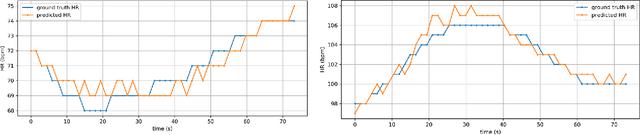
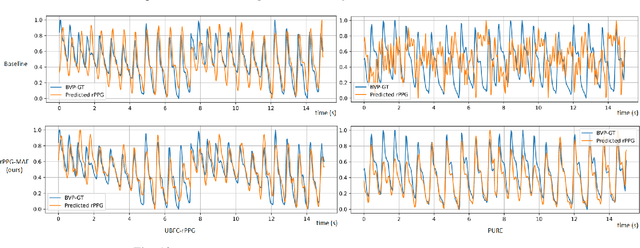
Remote photoplethysmography (rPPG) is an important technique for perceiving human vital signs, which has received extensive attention. For a long time, researchers have focused on supervised methods that rely on large amounts of labeled data. These methods are limited by the requirement for large amounts of data and the difficulty of acquiring ground truth physiological signals. To address these issues, several self-supervised methods based on contrastive learning have been proposed. However, they focus on the contrastive learning between samples, which neglect the inherent self-similar prior in physiological signals and seem to have a limited ability to cope with noisy. In this paper, a linear self-supervised reconstruction task was designed for extracting the inherent self-similar prior in physiological signals. Besides, a specific noise-insensitive strategy was explored for reducing the interference of motion and illumination. The proposed framework in this paper, namely rPPG-MAE, demonstrates excellent performance even on the challenging VIPL-HR dataset. We also evaluate the proposed method on two public datasets, namely PURE and UBFC-rPPG. The results show that our method not only outperforms existing self-supervised methods but also exceeds the state-of-the-art (SOTA) supervised methods. One important observation is that the quality of the dataset seems more important than the size in self-supervised pre-training of rPPG. The source code is released at https://github.com/linuxsino/rPPG-MAE.
Fast Continual Multi-View Clustering with Incomplete Views
Jun 04, 2023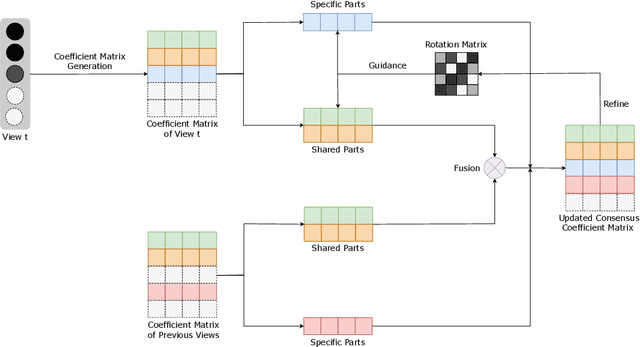

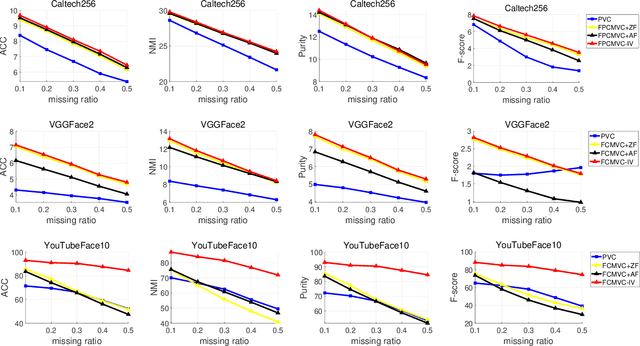
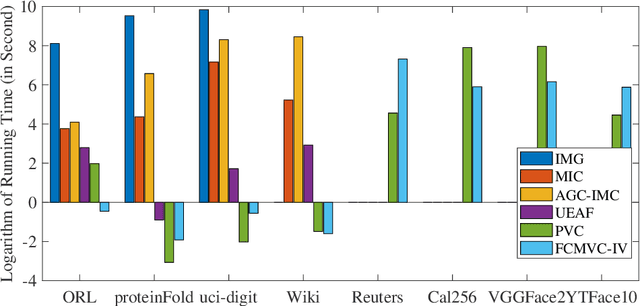
Multi-view clustering (MVC) has gained broad attention owing to its capacity to exploit consistent and complementary information across views. This paper focuses on a challenging issue in MVC called the incomplete continual data problem (ICDP). In specific, most existing algorithms assume that views are available in advance and overlook the scenarios where data observations of views are accumulated over time. Due to privacy considerations or memory limitations, previous views cannot be stored in these situations. Some works are proposed to handle it, but all fail to address incomplete views. Such an incomplete continual data problem (ICDP) in MVC is tough to solve since incomplete information with continual data increases the difficulty of extracting consistent and complementary knowledge among views. We propose Fast Continual Multi-View Clustering with Incomplete Views (FCMVC-IV) to address it. Specifically, it maintains a consensus coefficient matrix and updates knowledge with the incoming incomplete view rather than storing and recomputing all the data matrices. Considering that the views are incomplete, the newly collected view might contain samples that have yet to appear; two indicator matrices and a rotation matrix are developed to match matrices with different dimensions. Besides, we design a three-step iterative algorithm to solve the resultant problem in linear complexity with proven convergence. Comprehensive experiments on various datasets show the superiority of FCMVC-IV.
ORRN: An ODE-based Recursive Registration Network for Deformable Respiratory Motion Estimation with Lung 4DCT Images
May 24, 2023
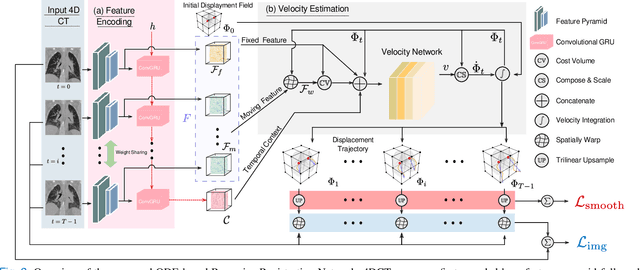
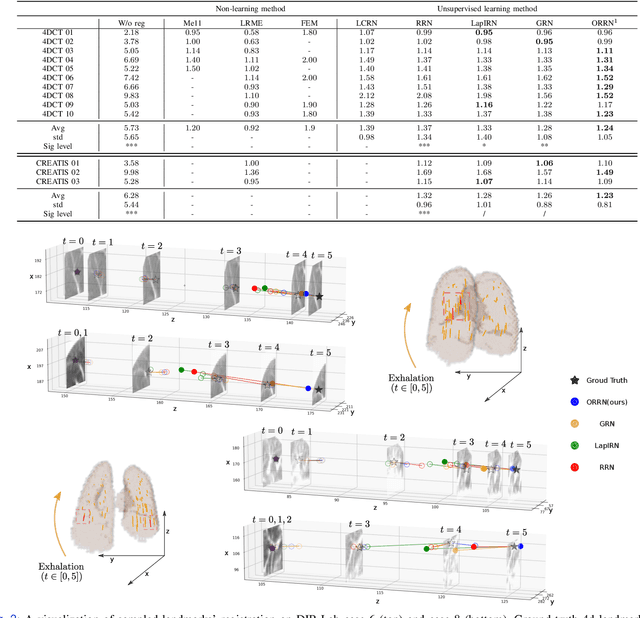
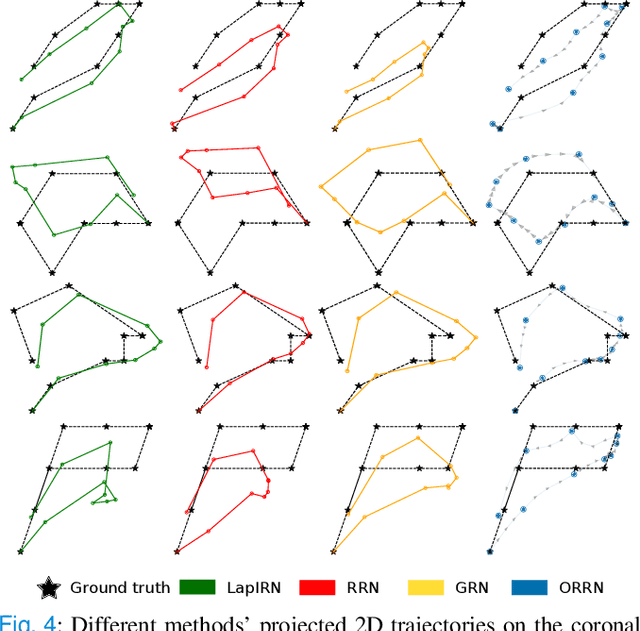
Deformable Image Registration (DIR) plays a significant role in quantifying deformation in medical data. Recent Deep Learning methods have shown promising accuracy and speedup for registering a pair of medical images. However, in 4D (3D + time) medical data, organ motion, such as respiratory motion and heart beating, can not be effectively modeled by pair-wise methods as they were optimized for image pairs but did not consider the organ motion patterns necessary when considering 4D data. This paper presents ORRN, an Ordinary Differential Equations (ODE)-based recursive image registration network. Our network learns to estimate time-varying voxel velocities for an ODE that models deformation in 4D image data. It adopts a recursive registration strategy to progressively estimate a deformation field through ODE integration of voxel velocities. We evaluate the proposed method on two publicly available lung 4DCT datasets, DIRLab and CREATIS, for two tasks: 1) registering all images to the extreme inhale image for 3D+t deformation tracking and 2) registering extreme exhale to inhale phase images. Our method outperforms other learning-based methods in both tasks, producing the smallest Target Registration Error of 1.24mm and 1.26mm, respectively. Additionally, it produces less than 0.001\% unrealistic image folding, and the computation speed is less than 1 second for each CT volume. ORRN demonstrates promising registration accuracy, deformation plausibility, and computation efficiency on group-wise and pair-wise registration tasks. It has significant implications in enabling fast and accurate respiratory motion estimation for treatment planning in radiation therapy or robot motion planning in thoracic needle insertion.
Behavior quantification as the missing link between fields: Tools for digital psychiatry and their role in the future of neurobiology
May 24, 2023The great behavioral heterogeneity observed between individuals with the same psychiatric disorder and even within one individual over time complicates both clinical practice and biomedical research. However, modern technologies are an exciting opportunity to improve behavioral characterization. Existing psychiatry methods that are qualitative or unscalable, such as patient surveys or clinical interviews, can now be collected at a greater capacity and analyzed to produce new quantitative measures. Furthermore, recent capabilities for continuous collection of passive sensor streams, such as phone GPS or smartwatch accelerometer, open avenues of novel questioning that were previously entirely unrealistic. Their temporally dense nature enables a cohesive study of real-time neural and behavioral signals. To develop comprehensive neurobiological models of psychiatric disease, it will be critical to first develop strong methods for behavioral quantification. There is huge potential in what can theoretically be captured by current technologies, but this in itself presents a large computational challenge -- one that will necessitate new data processing tools, new machine learning techniques, and ultimately a shift in how interdisciplinary work is conducted. In my thesis, I detail research projects that take different perspectives on digital psychiatry, subsequently tying ideas together with a concluding discussion on the future of the field. I also provide software infrastructure where relevant, with extensive documentation. Major contributions include scientific arguments and proof of concept results for daily free-form audio journals as an underappreciated psychiatry research datatype, as well as novel stability theorems and pilot empirical success for a proposed multi-area recurrent neural network architecture.
Reconstruction, forecasting, and stability of chaotic dynamics from partial data
May 24, 2023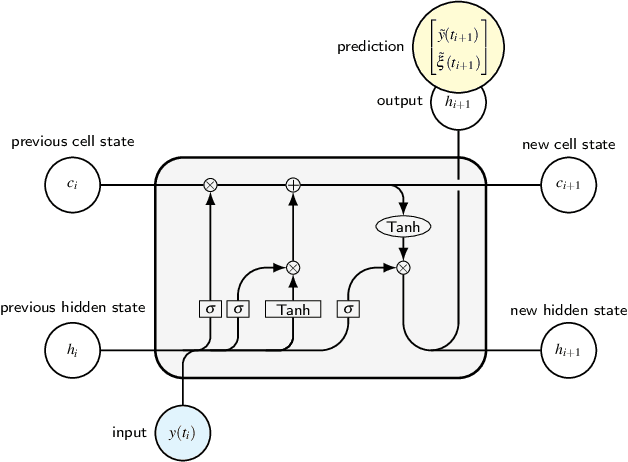
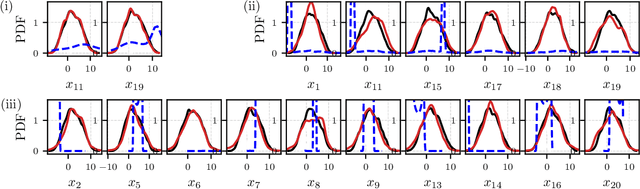
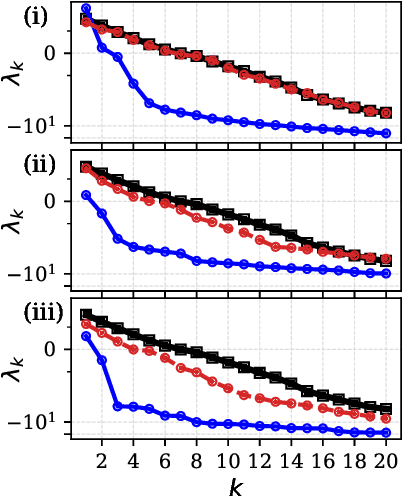
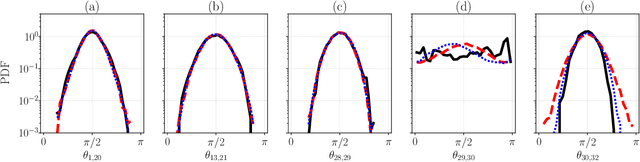
The forecasting and computation of the stability of chaotic systems from partial observations are tasks for which traditional equation-based methods may not be suitable. In this computational paper, we propose data-driven methods to (i) infer the dynamics of unobserved (hidden) chaotic variables (full-state reconstruction); (ii) time forecast the evolution of the full state; and (iii) infer the stability properties of the full state. The tasks are performed with long short-term memory (LSTM) networks, which are trained with observations (data) limited to only part of the state: (i) the low-to-high resolution LSTM (LH-LSTM), which takes partial observations as training input, and requires access to the full system state when computing the loss; and (ii) the physics-informed LSTM (PI-LSTM), which is designed to combine partial observations with the integral formulation of the dynamical system's evolution equations. First, we derive the Jacobian of the LSTMs. Second, we analyse a chaotic partial differential equation, the Kuramoto-Sivashinsky (KS), and the Lorenz-96 system. We show that the proposed networks can forecast the hidden variables, both time-accurately and statistically. The Lyapunov exponents and covariant Lyapunov vectors, which characterize the stability of the chaotic attractors, are correctly inferred from partial observations. Third, the PI-LSTM outperforms the LH-LSTM by successfully reconstructing the hidden chaotic dynamics when the input dimension is smaller or similar to the Kaplan-Yorke dimension of the attractor. This work opens new opportunities for reconstructing the full state, inferring hidden variables, and computing the stability of chaotic systems from partial data.