 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Terraforming -- Environment Manipulation during Disruptions for Multi-Agent Pickup and Delivery
May 19, 2023
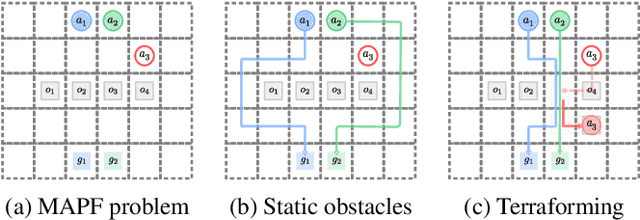
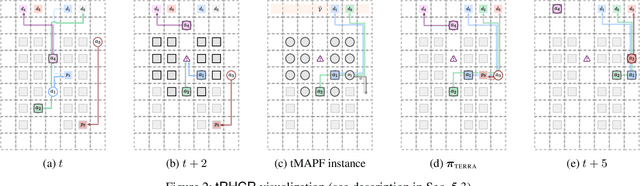
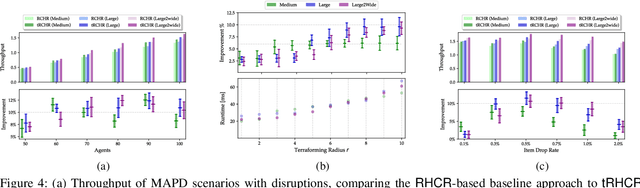
In automated warehouses, teams of mobile robots fulfill the packaging process by transferring inventory pods to designated workstations while navigating narrow aisles formed by tightly packed pods. This problem is typically modeled as a Multi-Agent Pickup and Delivery (MAPD) problem, which is then solved by repeatedly planning collision-free paths for agents on a fixed graph, as in the Rolling-Horizon Collision Resolution (RHCR) algorithm. However, existing approaches make the limiting assumption that agents are only allowed to move pods that correspond to their current task, while considering the other pods as stationary obstacles (even though all pods are movable). This behavior can result in unnecessarily long paths which could otherwise be avoided by opening additional corridors via pod manipulation. To this end, we explore the implications of allowing agents the flexibility of dynamically relocating pods. We call this new problem Terraforming MAPD (tMAPD) and develop an RHCR-based approach to tackle it. As the extra flexibility of terraforming comes at a significant computational cost, we utilize this capability judiciously by identifying situations where it could make a significant impact on the solution quality. In particular, we invoke terraforming in response to disruptions that often occur in automated warehouses, e.g., when an item is dropped from a pod or when agents malfunction. Empirically, using our approach for tMAPD, where disruptions are modeled via a stochastic process, we improve throughput by over 10%, reduce the maximum service time (the difference between the drop-off time and the pickup time of a pod) by more than 50%, without drastically increasing the runtime, compared to the MAPD setting.
Navigating the Metric Maze: A Taxonomy of Evaluation Metrics for Anomaly Detection in Time Series
Mar 02, 2023
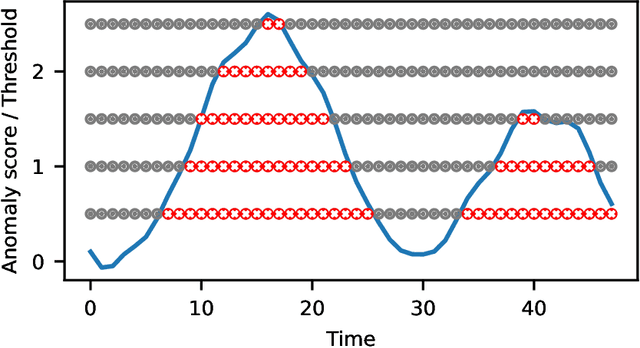
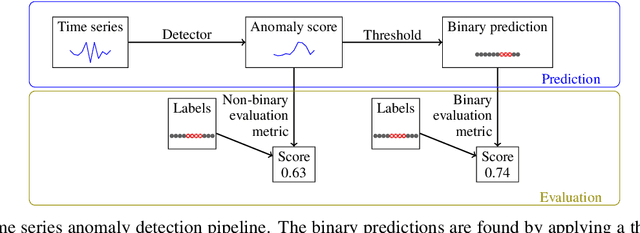
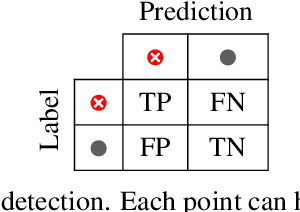
The field of time series anomaly detection is constantly advancing, with several methods available, making it a challenge to determine the most appropriate method for a specific domain. The evaluation of these methods is facilitated by the use of metrics, which vary widely in their properties. Despite the existence of new evaluation metrics, there is limited agreement on which metrics are best suited for specific scenarios and domain, and the most commonly used metrics have faced criticism in the literature. This paper provides a comprehensive overview of the metrics used for the evaluation of time series anomaly detection methods, and also defines a taxonomy of these based on how they are calculated. By defining a set of properties for evaluation metrics and a set of specific case studies and experiments, twenty metrics are analyzed and discussed in detail, highlighting the unique suitability of each for specific tasks. Through extensive experimentation and analysis, this paper argues that the choice of evaluation metric must be made with care, taking into account the specific requirements of the task at hand.
Sampling and Ranking for Digital Ink Generation on a tight computational budget
Jun 02, 2023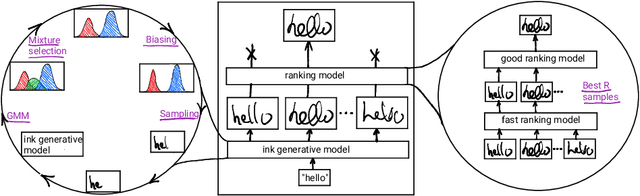
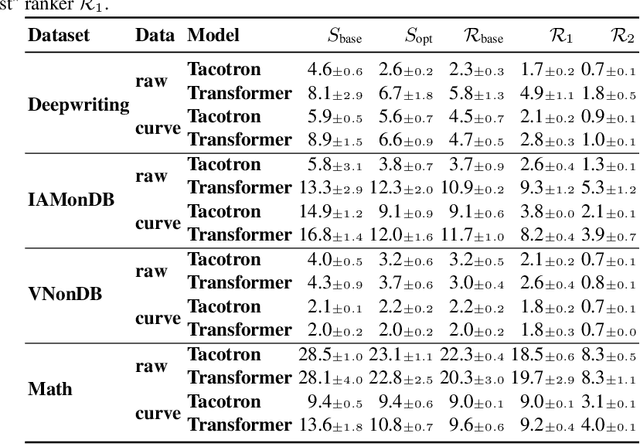
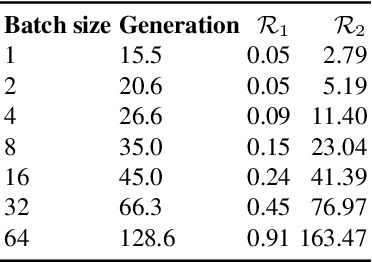
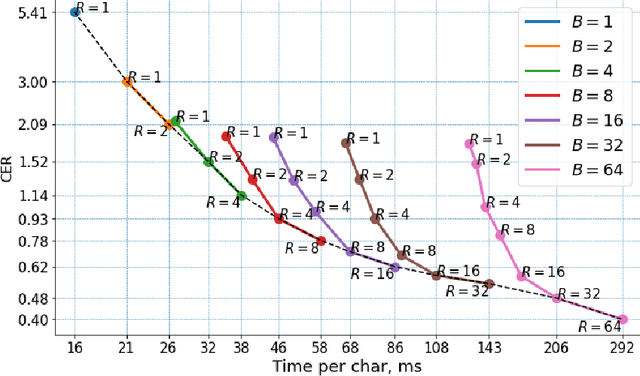
Digital ink (online handwriting) generation has a number of potential applications for creating user-visible content, such as handwriting autocompletion, spelling correction, and beautification. Writing is personal and usually the processing is done on-device. Ink generative models thus need to produce high quality content quickly, in a resource constrained environment. In this work, we study ways to maximize the quality of the output of a trained digital ink generative model, while staying within an inference time budget. We use and compare the effect of multiple sampling and ranking techniques, in the first ablation study of its kind in the digital ink domain. We confirm our findings on multiple datasets - writing in English and Vietnamese, as well as mathematical formulas - using two model types and two common ink data representations. In all combinations, we report a meaningful improvement in the recognizability of the synthetic inks, in some cases more than halving the character error rate metric, and describe a way to select the optimal combination of sampling and ranking techniques for any given computational budget.
EdGCon: Auto-assigner of Iconicity Ratings Grounded by Lexical Properties to Aid in Generation of Technical Gestures
Jun 02, 2023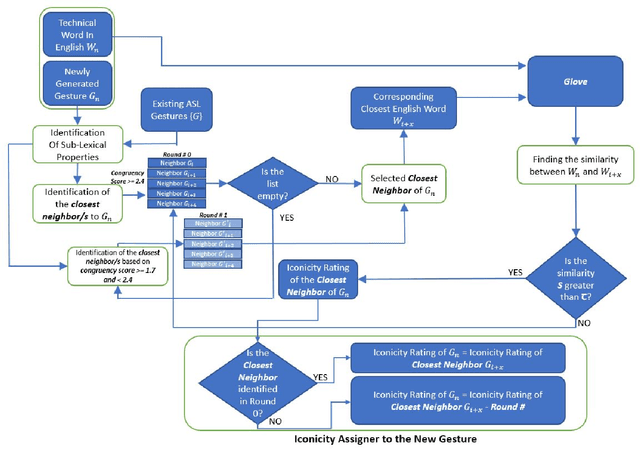
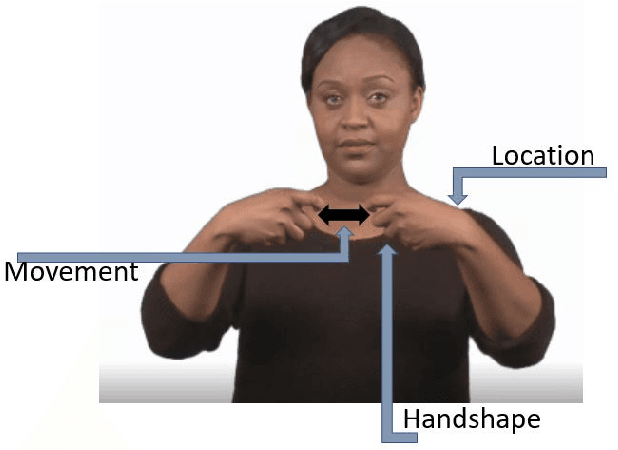
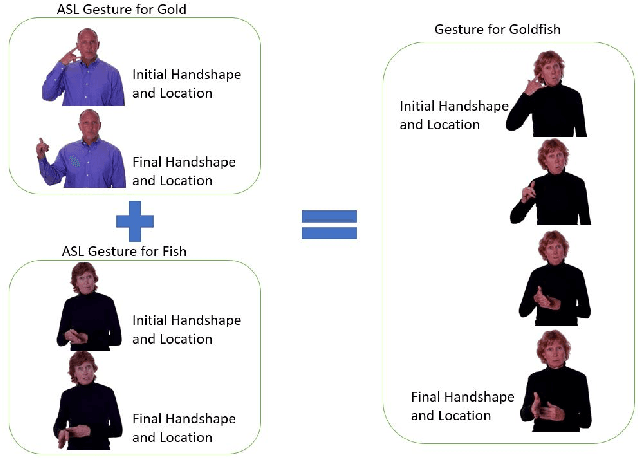
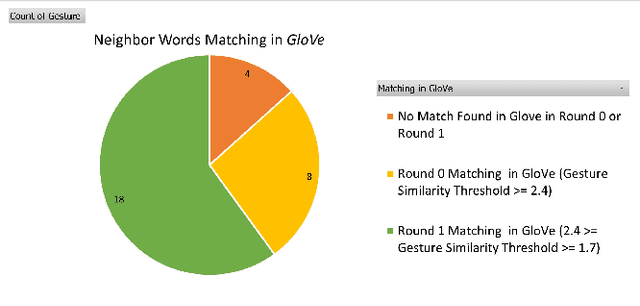
Gestures that share similarities in their forms and are related in their meanings, should be easier for learners to recognize and incorporate into their existing lexicon. In that regard, to be more readily accepted as standard by the Deaf and Hard of Hearing community, technical gestures in American Sign Language (ASL) will optimally share similar in forms with their lexical neighbors. We utilize a lexical database of ASL, ASL-LEX, to identify lexical relations within a set of technical gestures. We use automated identification for 3 unique sub-lexical properties in ASL- location, handshape and movement. EdGCon assigned an iconicity rating based on the lexical property similarities of the new gesture with an existing set of technical gestures and the relatedness of the meaning of the new technical word to that of the existing set of technical words. We collected 30 ad hoc crowdsourced technical gestures from different internet websites and tested them against 31 gestures from the DeafTEC technical corpus. We found that EdGCon was able to correctly auto-assign the iconicity ratings 80.76% of the time.
dugMatting: Decomposed-Uncertainty-Guided Matting
Jun 02, 2023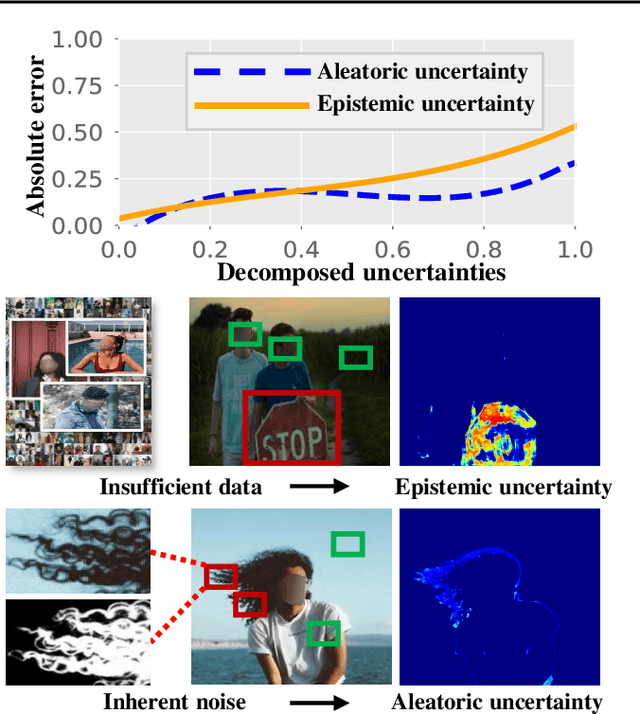
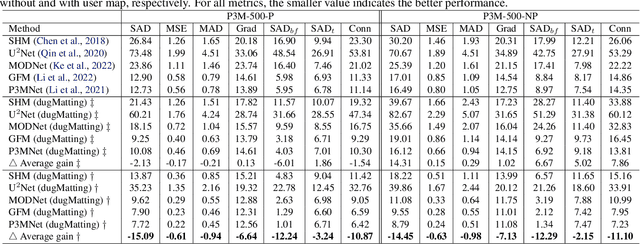
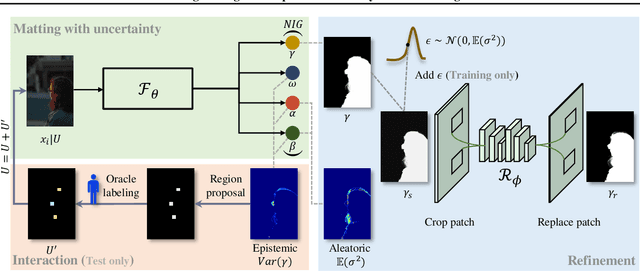
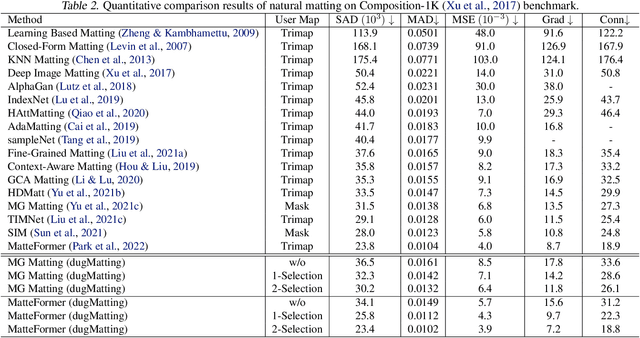
Cutting out an object and estimating its opacity mask, known as image matting, is a key task in image and video editing. Due to the highly ill-posed issue, additional inputs, typically user-defined trimaps or scribbles, are usually needed to reduce the uncertainty. Although effective, it is either time consuming or only suitable for experienced users who know where to place the strokes. In this work, we propose a decomposed-uncertainty-guided matting (dugMatting) algorithm, which explores the explicitly decomposed uncertainties to efficiently and effectively improve the results. Basing on the characteristic of these uncertainties, the epistemic uncertainty is reduced in the process of guiding interaction (which introduces prior knowledge), while the aleatoric uncertainty is reduced in modeling data distribution (which introduces statistics for both data and possible noise). The proposed matting framework relieves the requirement for users to determine the interaction areas by using simple and efficient labeling. Extensively quantitative and qualitative results validate that the proposed method significantly improves the original matting algorithms in terms of both efficiency and efficacy.
A Closer Look at the Adversarial Robustness of Deep Equilibrium Models
Jun 02, 2023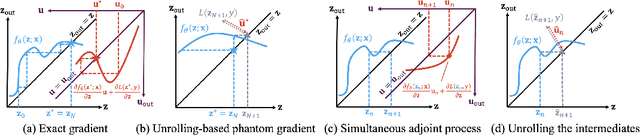

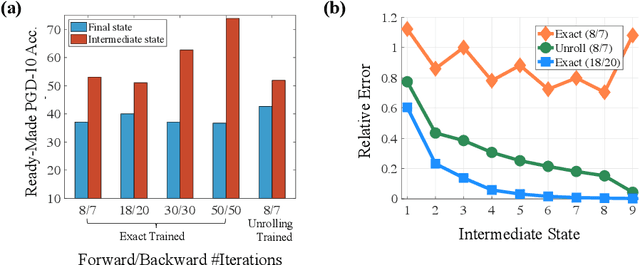
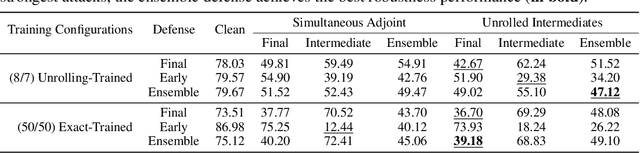
Deep equilibrium models (DEQs) refrain from the traditional layer-stacking paradigm and turn to find the fixed point of a single layer. DEQs have achieved promising performance on different applications with featured memory efficiency. At the same time, the adversarial vulnerability of DEQs raises concerns. Several works propose to certify robustness for monotone DEQs. However, limited efforts are devoted to studying empirical robustness for general DEQs. To this end, we observe that an adversarially trained DEQ requires more forward steps to arrive at the equilibrium state, or even violates its fixed-point structure. Besides, the forward and backward tracks of DEQs are misaligned due to the black-box solvers. These facts cause gradient obfuscation when applying the ready-made attacks to evaluate or adversarially train DEQs. Given this, we develop approaches to estimate the intermediate gradients of DEQs and integrate them into the attacking pipelines. Our approaches facilitate fully white-box evaluations and lead to effective adversarial defense for DEQs. Extensive experiments on CIFAR-10 validate the adversarial robustness of DEQs competitive with deep networks of similar sizes.
ERSAM: Neural Architecture Search For Energy-Efficient and Real-Time Social Ambiance Measurement
Mar 19, 2023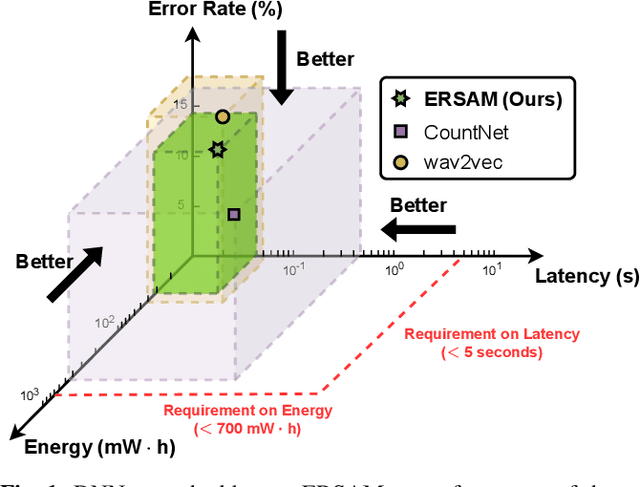
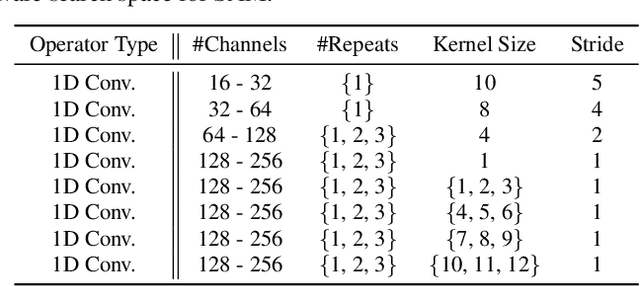
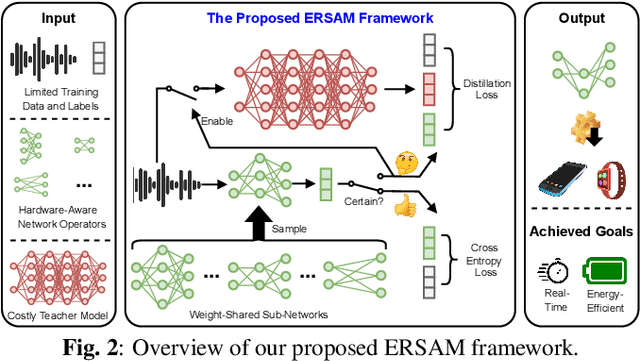

Social ambiance describes the context in which social interactions happen, and can be measured using speech audio by counting the number of concurrent speakers. This measurement has enabled various mental health tracking and human-centric IoT applications. While on-device Socal Ambiance Measure (SAM) is highly desirable to ensure user privacy and thus facilitate wide adoption of the aforementioned applications, the required computational complexity of state-of-the-art deep neural networks (DNNs) powered SAM solutions stands at odds with the often constrained resources on mobile devices. Furthermore, only limited labeled data is available or practical when it comes to SAM under clinical settings due to various privacy constraints and the required human effort, further challenging the achievable accuracy of on-device SAM solutions. To this end, we propose a dedicated neural architecture search framework for Energy-efficient and Real-time SAM (ERSAM). Specifically, our ERSAM framework can automatically search for DNNs that push forward the achievable accuracy vs. hardware efficiency frontier of mobile SAM solutions. For example, ERSAM-delivered DNNs only consume 40 mW x 12 h energy and 0.05 seconds processing latency for a 5 seconds audio segment on a Pixel 3 phone, while only achieving an error rate of 14.3% on a social ambiance dataset generated by LibriSpeech. We can expect that our ERSAM framework can pave the way for ubiquitous on-device SAM solutions which are in growing demand.
Unsupervised Semantic Variation Prediction using the Distribution of Sibling Embeddings
May 15, 2023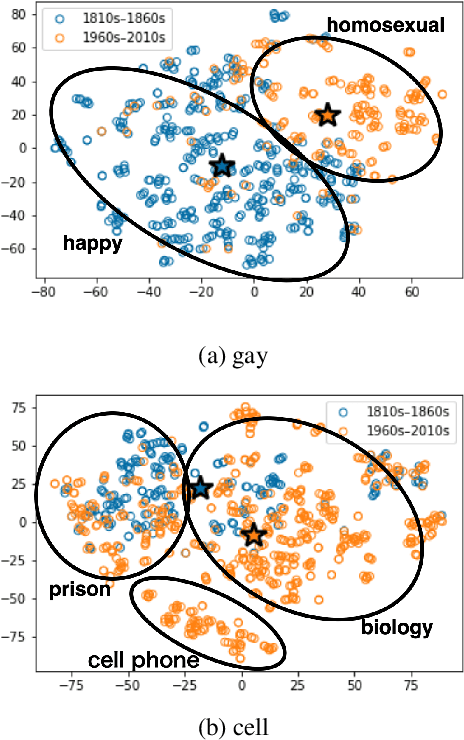

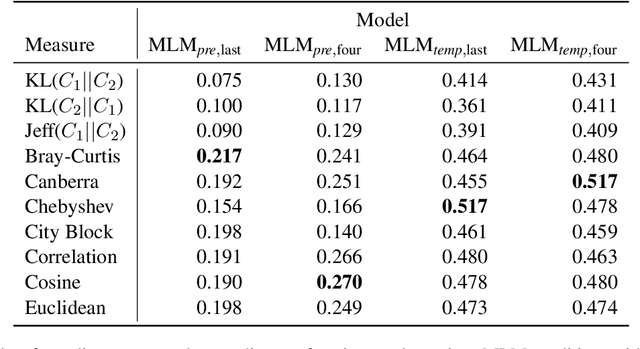
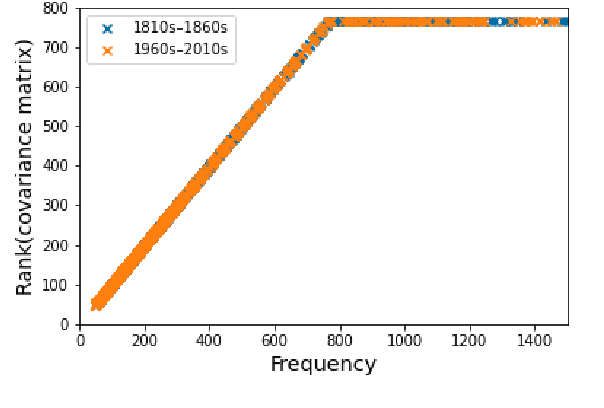
Languages are dynamic entities, where the meanings associated with words constantly change with time. Detecting the semantic variation of words is an important task for various NLP applications that must make time-sensitive predictions. Existing work on semantic variation prediction have predominantly focused on comparing some form of an averaged contextualised representation of a target word computed from a given corpus. However, some of the previously associated meanings of a target word can become obsolete over time (e.g. meaning of gay as happy), while novel usages of existing words are observed (e.g. meaning of cell as a mobile phone). We argue that mean representations alone cannot accurately capture such semantic variations and propose a method that uses the entire cohort of the contextualised embeddings of the target word, which we refer to as the sibling distribution. Experimental results on SemEval-2020 Task 1 benchmark dataset for semantic variation prediction show that our method outperforms prior work that consider only the mean embeddings, and is comparable to the current state-of-the-art. Moreover, a qualitative analysis shows that our method detects important semantic changes in words that are not captured by the existing methods. Source code is available at https://github.com/a1da4/svp-gauss .
Online Sequence Clustering Algorithm for Video Trajectory Analysis
May 15, 2023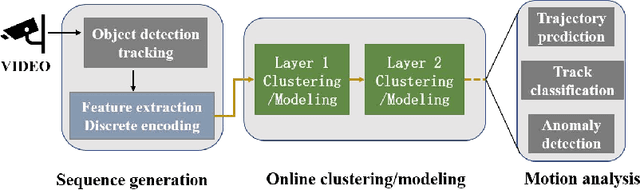
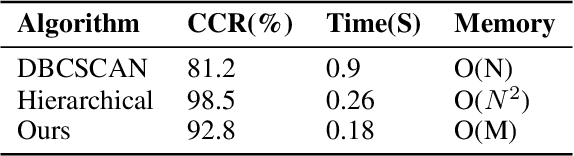
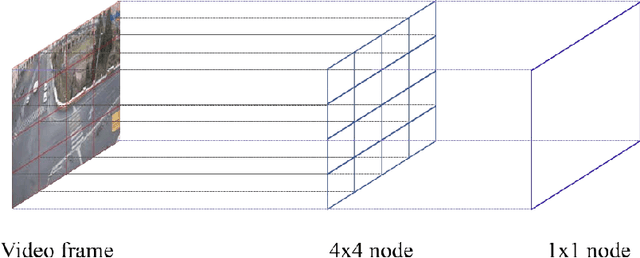
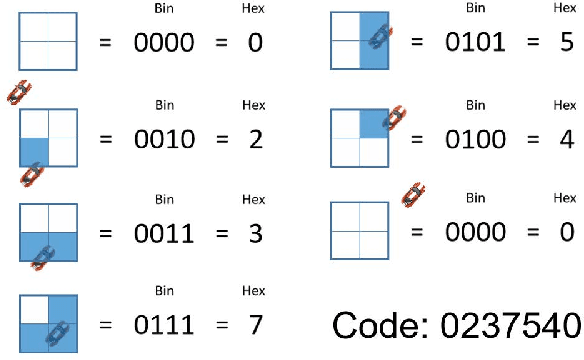
Target tracking and trajectory modeling have important applications in surveillance video analysis and have received great attention in the fields of road safety and community security. In this work, we propose a lightweight real-time video analysis scheme that uses a model learned from motion patterns to monitor the behavior of objects, which can be used for applications such as real-time representation and prediction. The proposed sequence clustering algorithm based on discrete sequences makes the system have continuous online learning ability. The intrinsic repeatability of the target object trajectory is used to automatically construct the behavioral model in the three processes of feature extraction, cluster learning, and model application. In addition to the discretization of trajectory features and simple model applications, this paper focuses on online clustering algorithms and their incremental learning processes. Finally, through the learning of the trajectory model of the actual surveillance video image, the feasibility of the algorithm is verified. And the characteristics and performance of the clustering algorithm are discussed in the analysis. This scheme has real-time online learning and processing of motion models while avoiding a large number of arithmetic operations, which is more in line with the application scenarios of front-end intelligent perception.
Adversarial Attacks on Online Learning to Rank with Stochastic Click Models
May 30, 2023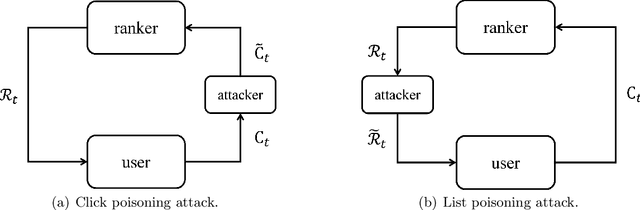
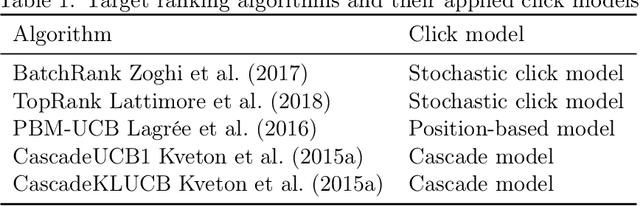
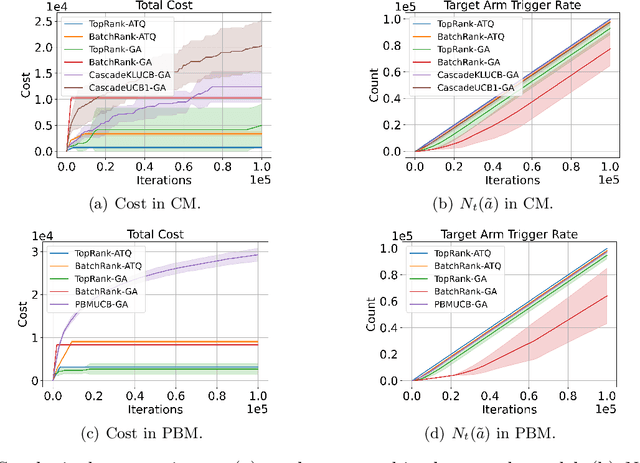
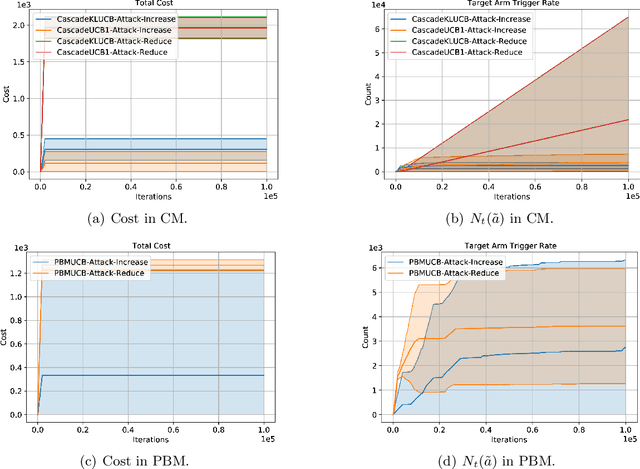
We propose the first study of adversarial attacks on online learning to rank. The goal of the adversary is to misguide the online learning to rank algorithm to place the target item on top of the ranking list linear times to time horizon $T$ with a sublinear attack cost. We propose generalized list poisoning attacks that perturb the ranking list presented to the user. This strategy can efficiently attack any no-regret ranker in general stochastic click models. Furthermore, we propose a click poisoning-based strategy named attack-then-quit that can efficiently attack two representative OLTR algorithms for stochastic click models. We theoretically analyze the success and cost upper bound of the two proposed methods. Experimental results based on synthetic and real-world data further validate the effectiveness and cost-efficiency of the proposed attack strategies.