 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Restart Sampling for Improving Generative Processes
Jun 26, 2023
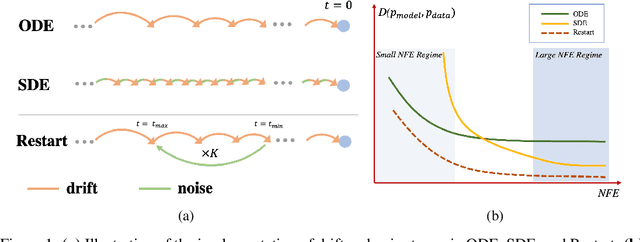
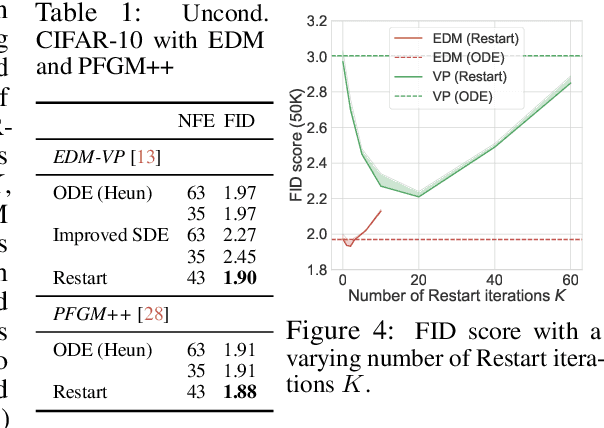
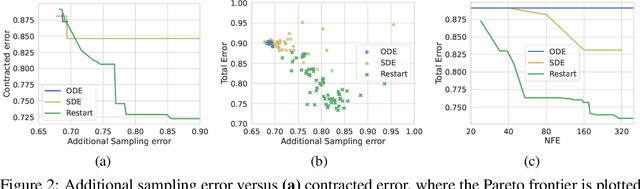

Generative processes that involve solving differential equations, such as diffusion models, frequently necessitate balancing speed and quality. ODE-based samplers are fast but plateau in performance while SDE-based samplers deliver higher sample quality at the cost of increased sampling time. We attribute this difference to sampling errors: ODE-samplers involve smaller discretization errors while stochasticity in SDE contracts accumulated errors. Based on these findings, we propose a novel sampling algorithm called Restart in order to better balance discretization errors and contraction. The sampling method alternates between adding substantial noise in additional forward steps and strictly following a backward ODE. Empirically, Restart sampler surpasses previous SDE and ODE samplers in both speed and accuracy. Restart not only outperforms the previous best SDE results, but also accelerates the sampling speed by 10-fold / 2-fold on CIFAR-10 / ImageNet $64 \times 64$. In addition, it attains significantly better sample quality than ODE samplers within comparable sampling times. Moreover, Restart better balances text-image alignment/visual quality versus diversity than previous samplers in the large-scale text-to-image Stable Diffusion model pre-trained on LAION $512 \times 512$. Code is available at https://github.com/Newbeeer/diffusion_restart_sampling
Balanced Filtering via Non-Disclosive Proxies
Jun 26, 2023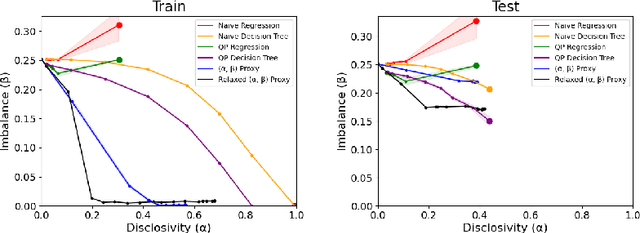
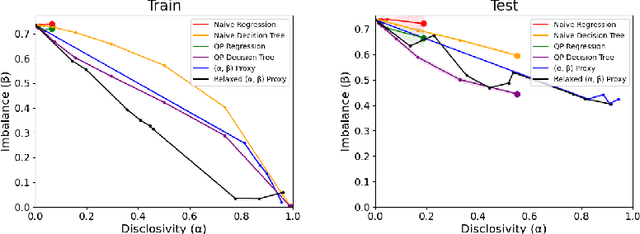
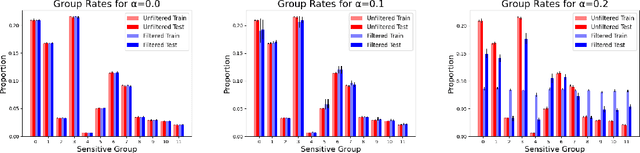
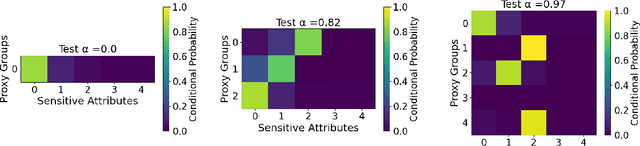
We study the problem of non-disclosively collecting a sample of data that is balanced with respect to sensitive groups when group membership is unavailable or prohibited from use at collection time. Specifically, our collection mechanism does not reveal significantly more about group membership of any individual sample than can be ascertained from base rates alone. To do this, we adopt a fairness pipeline perspective, in which a learner can use a small set of labeled data to train a proxy function that can later be used for this filtering task. We then associate the range of the proxy function with sampling probabilities; given a new candidate, we classify it using our proxy function, and then select it for our sample with probability proportional to the sampling probability corresponding to its proxy classification. Importantly, we require that the proxy classification itself not reveal significant information about the sensitive group membership of any individual sample (i.e., it should be sufficiently non-disclosive). We show that under modest algorithmic assumptions, we find such a proxy in a sample- and oracle-efficient manner. Finally, we experimentally evaluate our algorithm and analyze generalization properties.
SIMF: Semantics-aware Interactive Motion Forecasting for Autonomous Driving
Jun 26, 2023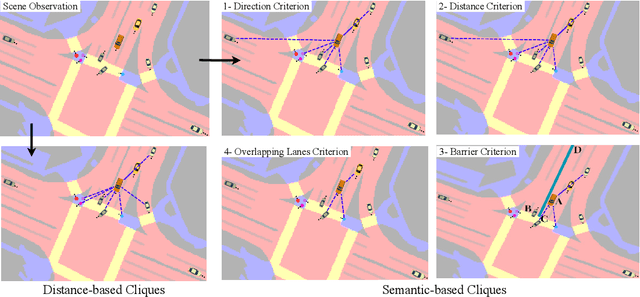
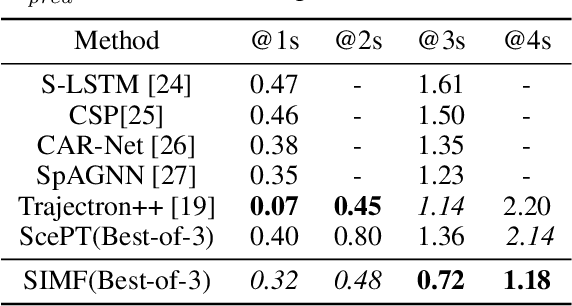
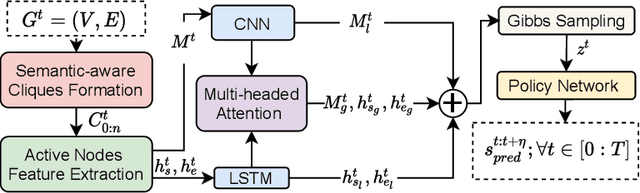
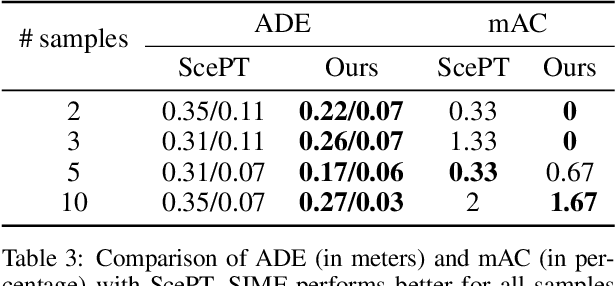
Autonomous vehicles require motion forecasting of their surrounding multi-agents (pedestrians and vehicles) to make optimal decisions for navigation. The existing methods focus on techniques to utilize the positions and velocities of these agents and fail to capture semantic information from the scene. Moreover, to mitigate the increase in computational complexity associated with the number of agents in the scene, some works leverage Euclidean distance to prune far-away agents. However, distance-based metric alone is insufficient to select relevant agents and accurately perform their predictions. To resolve these issues, we propose Semantics-aware Interactive Motion Forecasting (SIMF) method to capture semantics along with spatial information, and optimally select relevant agents for motion prediction. Specifically, we achieve this by implementing a semantic-aware selection of relevant agents from the scene and passing them through an attention mechanism to extract global encodings. These encodings along with agents' local information are passed through an encoder to obtain time-dependent latent variables for a motion policy predicting the future trajectories. Our results show that the proposed approach outperforms state-of-the-art baselines and provides more accurate predictions in a scene-consistent manner.
Single-shot 3D photoacoustic computed tomography with a densely packed array for transcranial functional imaging
Jun 26, 2023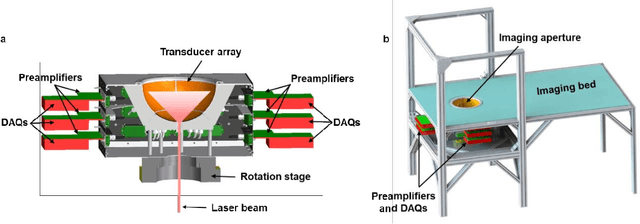
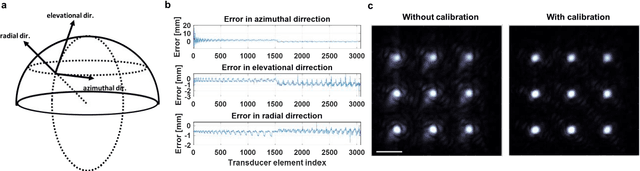

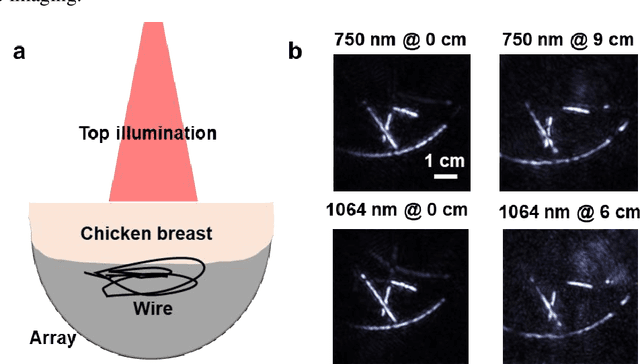
Photoacoustic computed tomography (PACT) is emerging as a new technique for functional brain imaging, primarily due to its capabilities in label-free hemodynamic imaging. Despite its potential, the transcranial application of PACT has encountered hurdles, such as acoustic attenuations and distortions by the skull and limited light penetration through the skull. To overcome these challenges, we have engineered a PACT system that features a densely packed hemispherical ultrasonic transducer array with 3072 channels, operating at a central frequency of 1 MHz. This system allows for single-shot 3D imaging at a rate equal to the laser repetition rate, such as 20 Hz. We have achieved a single-shot light penetration depth of approximately 9 cm in chicken breast tissue utilizing a 750 nm laser (withstanding 3295-fold light attenuation and still retaining an SNR of 74) and successfully performed transcranial imaging through an ex vivo human skull using a 1064 nm laser. Moreover, we have proven the capacity of our system to perform single-shot 3D PACT imaging in both tissue phantoms and human subjects. These results suggest that our PACT system is poised to unlock potential for real-time, in vivo transcranial functional imaging in humans.
Iterative-in-Iterative Super-Resolution Biomedical Imaging Using One Real Image
Jun 26, 2023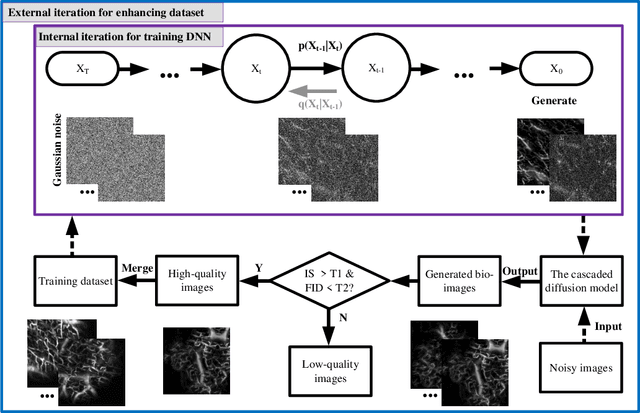
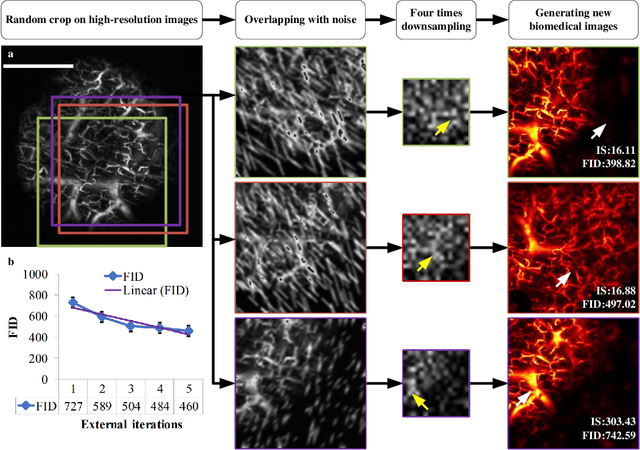
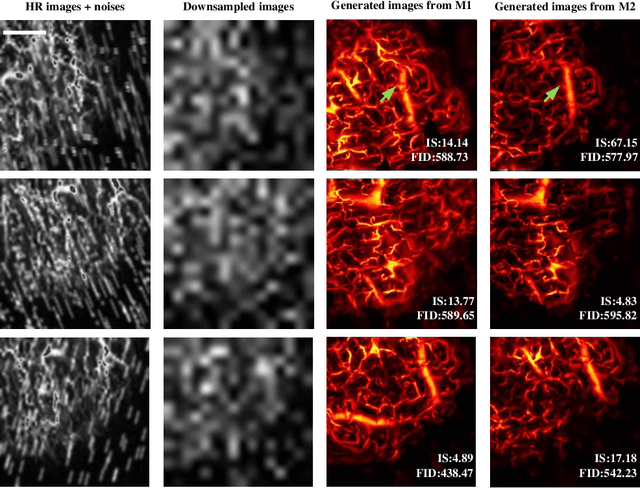
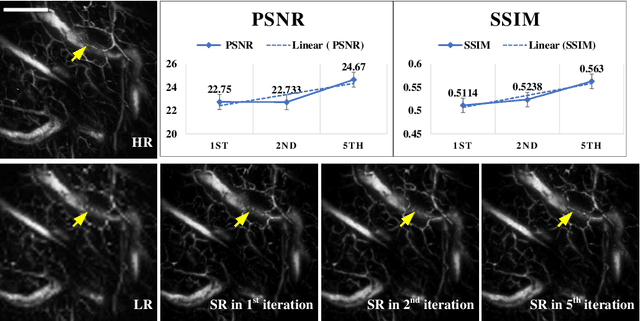
Deep learning-based super-resolution models have the potential to revolutionize biomedical imaging and diagnoses by effectively tackling various challenges associated with early detection, personalized medicine, and clinical automation. However, the requirement of an extensive collection of high-resolution images presents limitations for widespread adoption in clinical practice. In our experiment, we proposed an approach to effectively train the deep learning-based super-resolution models using only one real image by leveraging self-generated high-resolution images. We employed a mixed metric of image screening to automatically select images with a distribution similar to ground truth, creating an incrementally curated training data set that encourages the model to generate improved images over time. After five training iterations, the proposed deep learning-based super-resolution model experienced a 7.5\% and 5.49\% improvement in structural similarity and peak-signal-to-noise ratio, respectively. Significantly, the model consistently produces visually enhanced results for training, improving its performance while preserving the characteristics of original biomedical images. These findings indicate a potential way to train a deep neural network in a self-revolution manner independent of real-world human data.
Fast and Private Inference of Deep Neural Networks by Co-designing Activation Functions
Jun 14, 2023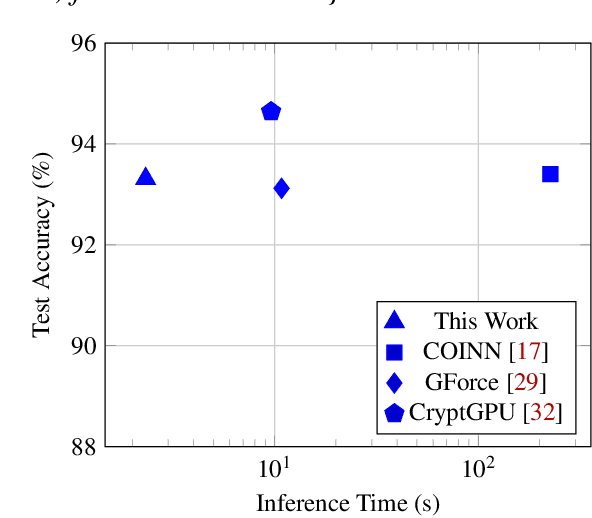
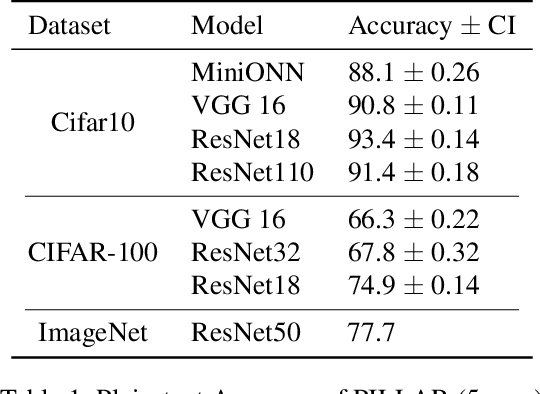
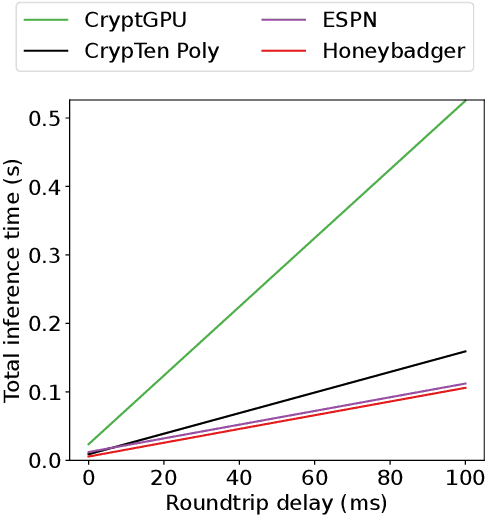
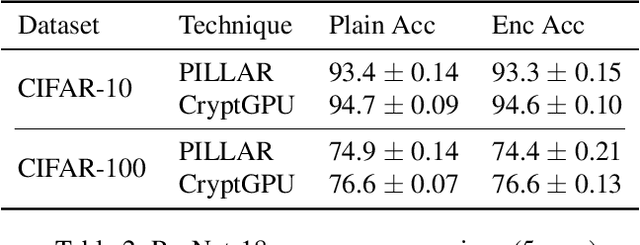
Machine Learning as a Service (MLaaS) is an increasingly popular design where a company with abundant computing resources trains a deep neural network and offers query access for tasks like image classification. The challenge with this design is that MLaaS requires the client to reveal their potentially sensitive queries to the company hosting the model. Multi-party computation (MPC) protects the client's data by allowing encrypted inferences. However, current approaches suffer prohibitively large inference times. The inference time bottleneck in MPC is the evaluation of non-linear layers such as ReLU activation functions. Motivated by the success of previous work co-designing machine learning and MPC aspects, we develop an activation function co-design. We replace all ReLUs with a polynomial approximation and evaluate them with single-round MPC protocols, which give state-of-the-art inference times in wide-area networks. Furthermore, to address the accuracy issues previously encountered with polynomial activations, we propose a novel training algorithm that gives accuracy competitive with plaintext models. Our evaluation shows between $4$ and $90\times$ speedups in inference time on large models with up to $23$ million parameters while maintaining competitive inference accuracy.
Scissorhands: Exploiting the Persistence of Importance Hypothesis for LLM KV Cache Compression at Test Time
May 26, 2023
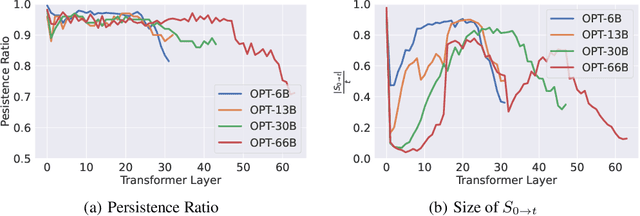
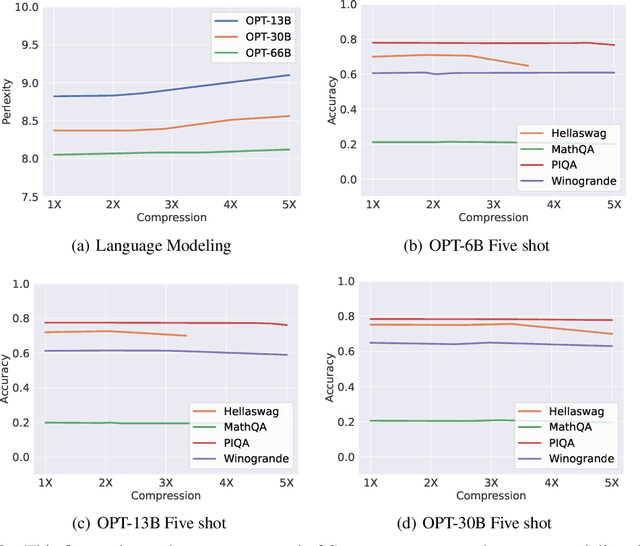
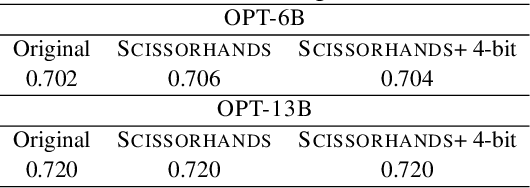
Large language models(LLMs) have sparked a new wave of exciting AI applications. Hosting these models at scale requires significant memory resources. One crucial memory bottleneck for the deployment stems from the context window. It is commonly recognized that model weights are memory hungry; however, the size of key-value embedding stored during the generation process (KV cache) can easily surpass the model size. The enormous size of the KV cache puts constraints on the inference batch size, which is crucial for high throughput inference workload. Inspired by an interesting observation of the attention scores, we hypothesize the persistence of importance: only pivotal tokens, which had a substantial influence at one step, will significantly influence future generations. Based on our empirical verification and theoretical analysis around this hypothesis, we propose Scissorhands, a system that maintains the memory usage of the KV cache at a fixed budget without finetuning the model. In essence, Scissorhands manages the KV cache by storing the pivotal tokens with a higher probability. We validate that Scissorhands reduces the inference memory usage of the KV cache by up to 5X without compromising model quality. We further demonstrate that Scissorhands can be combined with 4-bit quantization, traditionally used to compress model weights, to achieve up to 20X compression.
Enrollment-stage Backdoor Attacks on Speaker Recognition Systems via Adversarial Ultrasound
Jun 28, 2023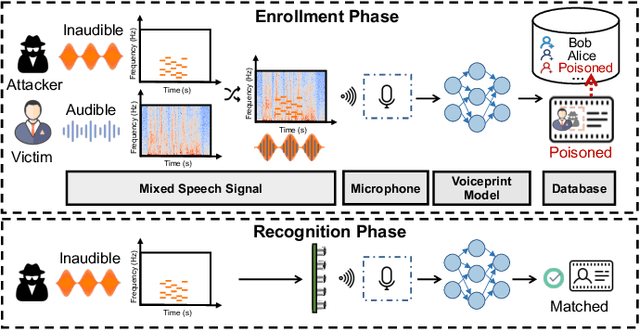
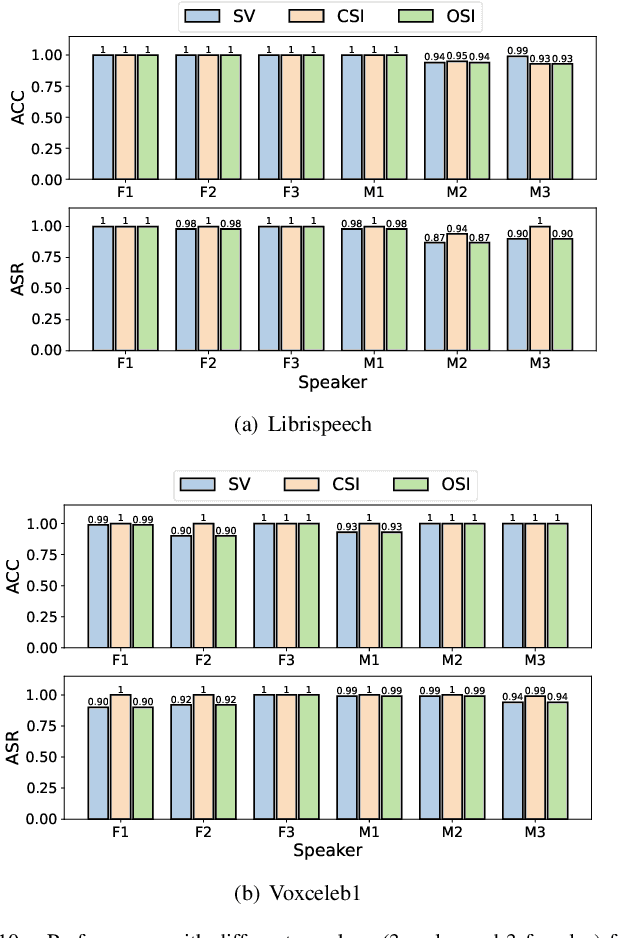
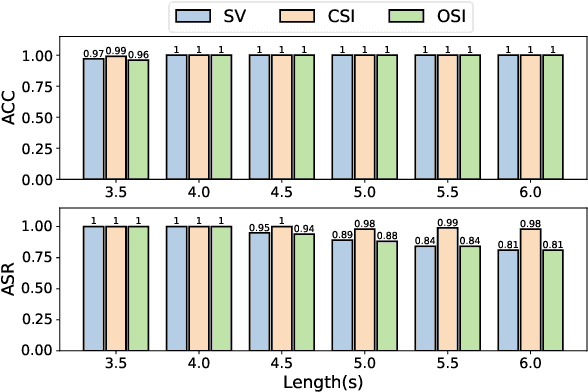
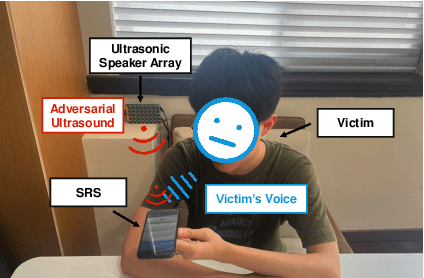
Automatic Speaker Recognition Systems (SRSs) have been widely used in voice applications for personal identification and access control. A typical SRS consists of three stages, i.e., training, enrollment, and recognition. Previous work has revealed that SRSs can be bypassed by backdoor attacks at the training stage or by adversarial example attacks at the recognition stage. In this paper, we propose TUNER, a new type of backdoor attack against the enrollment stage of SRS via adversarial ultrasound modulation, which is inaudible, synchronization-free, content-independent, and black-box. Our key idea is to first inject the backdoor into the SRS with modulated ultrasound when a legitimate user initiates the enrollment, and afterward, the polluted SRS will grant access to both the legitimate user and the adversary with high confidence. Our attack faces a major challenge of unpredictable user articulation at the enrollment stage. To overcome this challenge, we generate the ultrasonic backdoor by augmenting the optimization process with random speech content, vocalizing time, and volume of the user. Furthermore, to achieve real-world robustness, we improve the ultrasonic signal over traditional methods using sparse frequency points, pre-compensation, and single-sideband (SSB) modulation. We extensively evaluate TUNER on two common datasets and seven representative SRS models. Results show that our attack can successfully bypass speaker recognition systems while remaining robust to various speakers, speech content, et
Generalizing Surgical Instruments Segmentation to Unseen Domains with One-to-Many Synthesis
Jun 28, 2023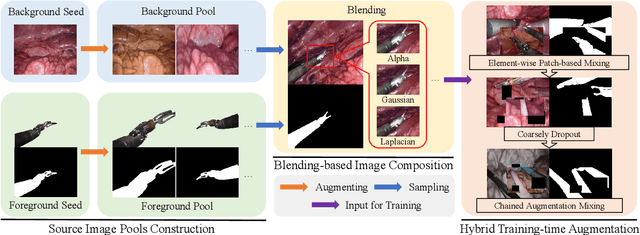

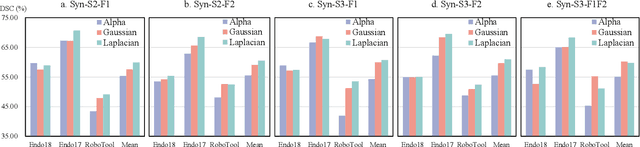
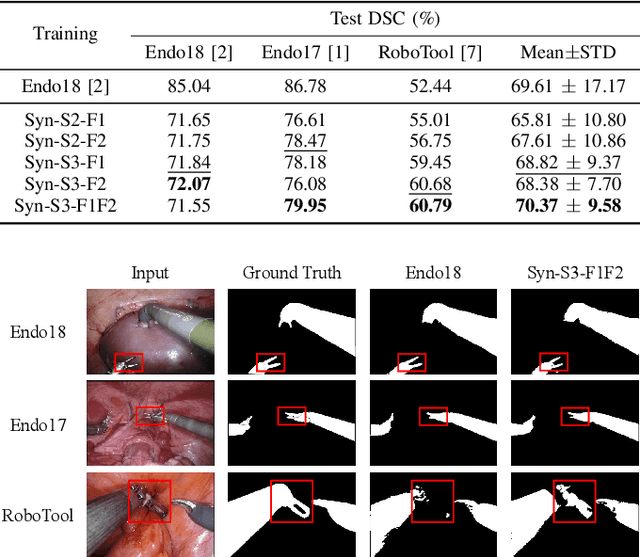
Despite their impressive performance in various surgical scene understanding tasks, deep learning-based methods are frequently hindered from deploying to real-world surgical applications for various causes. Particularly, data collection, annotation, and domain shift in-between sites and patients are the most common obstacles. In this work, we mitigate data-related issues by efficiently leveraging minimal source images to generate synthetic surgical instrument segmentation datasets and achieve outstanding generalization performance on unseen real domains. Specifically, in our framework, only one background tissue image and at most three images of each foreground instrument are taken as the seed images. These source images are extensively transformed and employed to build up the foreground and background image pools, from which randomly sampled tissue and instrument images are composed with multiple blending techniques to generate new surgical scene images. Besides, we introduce hybrid training-time augmentations to diversify the training data further. Extensive evaluation on three real-world datasets, i.e., Endo2017, Endo2018, and RoboTool, demonstrates that our one-to-many synthetic surgical instruments datasets generation and segmentation framework can achieve encouraging performance compared with training with real data. Notably, on the RoboTool dataset, where a more significant domain gap exists, our framework shows its superiority of generalization by a considerable margin. We expect that our inspiring results will attract research attention to improving model generalization with data synthesizing.
Pseudo-Bag Mixup Augmentation for Multiple Instance Learning Based Whole Slide Image Classification
Jun 28, 2023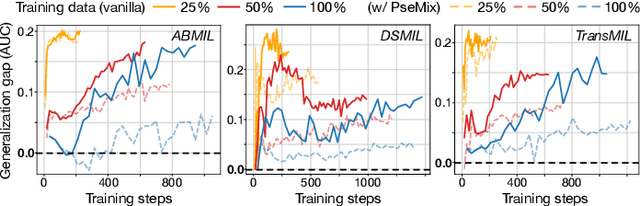
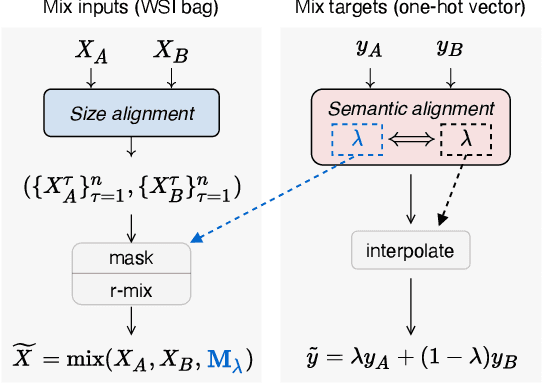
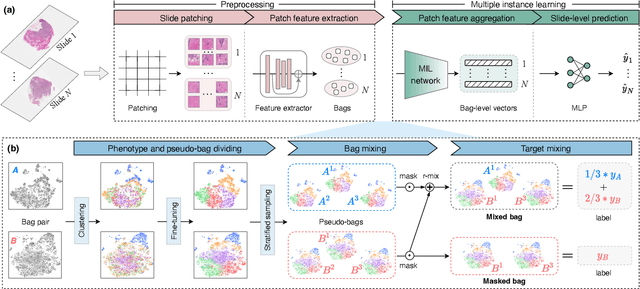
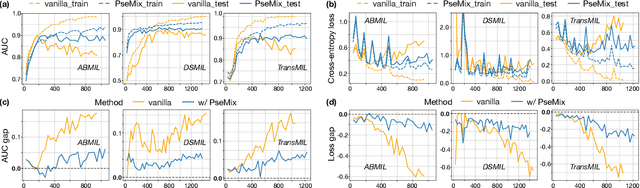
Given the special situation of modeling gigapixel images, multiple instance learning (MIL) has become one of the most important frameworks for Whole Slide Image (WSI) classification. In current practice, most MIL networks often face two unavoidable problems in training: i) insufficient WSI data, and ii) the data memorization nature inherent in neural networks. These problems may hinder MIL models from adequate and efficient training, suppressing the continuous performance promotion of classification models on WSIs. Inspired by the basic idea of Mixup, this paper proposes a Pseudo-bag Mixup (PseMix) data augmentation scheme to improve the training of MIL models. This scheme generalizes the Mixup strategy for general images to special WSIs via pseudo-bags so as to be applied in MIL-based WSI classification. Cooperated by pseudo-bags, our PseMix fulfills the critical size alignment and semantic alignment in Mixup strategy. Moreover, it is designed as an efficient and decoupled method adaptive to MIL, neither involving time-consuming operations nor relying on MIL model predictions. Comparative experiments and ablation studies are specially designed to evaluate the effectiveness and advantages of our PseMix. Test results show that PseMix could often improve the performance of MIL networks in WSI classification. Besides, it could also boost the generalization capacity of MIL models, and promote their robustness to patch occlusion and noisy labels. Our source code is available at https://github.com/liupei101/PseMix.