 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Comparative Study of Machine Learning Algorithms for Anomaly Detection in Industrial Environments: Performance and Environmental Impact
Jul 01, 2023
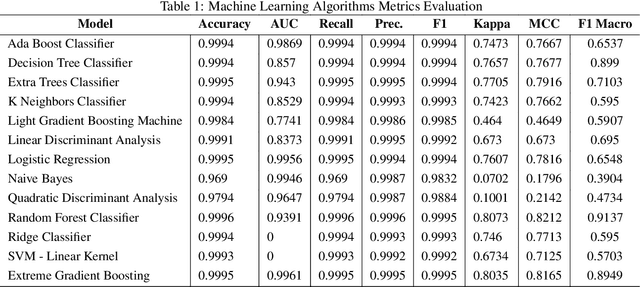
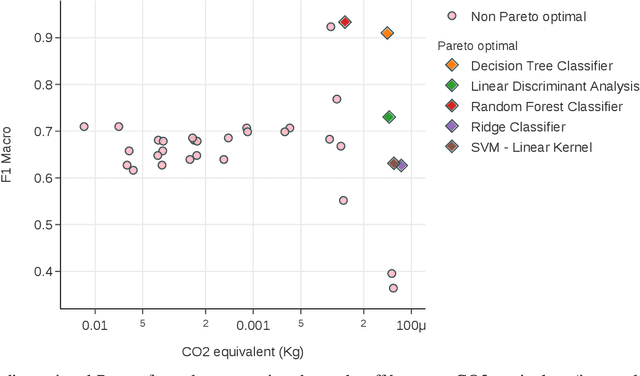
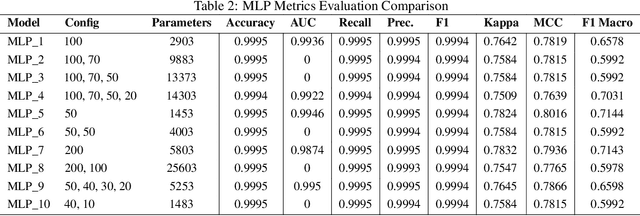
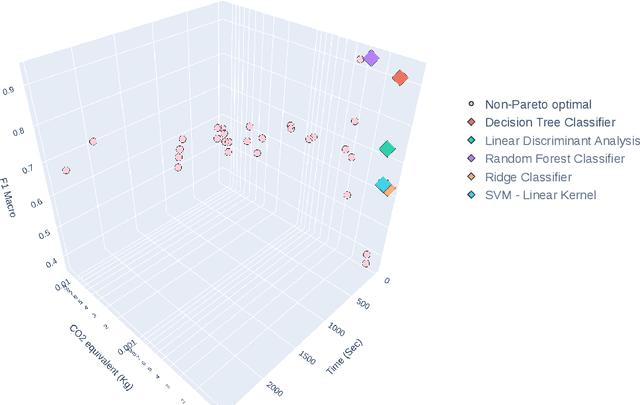
In the context of Industry 4.0, the use of artificial intelligence (AI) and machine learning for anomaly detection is being hampered by high computational requirements and associated environmental effects. This study seeks to address the demands of high-performance machine learning models with environmental sustainability, contributing to the emerging discourse on 'Green AI.' An extensive variety of machine learning algorithms, coupled with various Multilayer Perceptron (MLP) configurations, were meticulously evaluated. Our investigation encapsulated a comprehensive suite of evaluation metrics, comprising Accuracy, Area Under the Curve (AUC), Recall, Precision, F1 Score, Kappa Statistic, Matthews Correlation Coefficient (MCC), and F1 Macro. Simultaneously, the environmental footprint of these models was gauged through considerations of time duration, CO2 equivalent, and energy consumption during the training, cross-validation, and inference phases. Traditional machine learning algorithms, such as Decision Trees and Random Forests, demonstrate robust efficiency and performance. However, superior outcomes were obtained with optimised MLP configurations, albeit with a commensurate increase in resource consumption. The study incorporated a multi-objective optimisation approach, invoking Pareto optimality principles, to highlight the trade-offs between a model's performance and its environmental impact. The insights derived underscore the imperative of striking a balance between model performance, complexity, and environmental implications, thus offering valuable directions for future work in the development of environmentally conscious machine learning models for industrial applications.
The future of human-centric eXplainable Artificial Intelligence (XAI) is not post-hoc explanations
Jul 01, 2023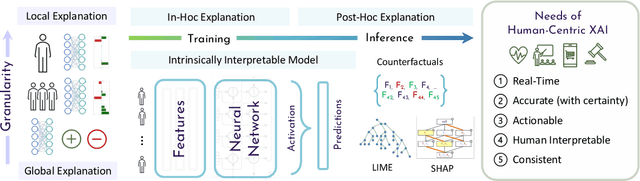
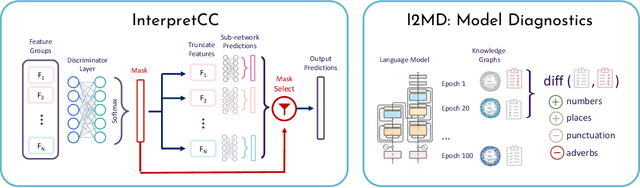
Explainable Artificial Intelligence (XAI) plays a crucial role in enabling human understanding and trust in deep learning systems, often defined as determining which features are most important to a model's prediction. As models get larger, more ubiquitous, and pervasive in aspects of daily life, explainability is necessary to avoid or minimize adverse effects of model mistakes. Unfortunately, current approaches in human-centric XAI (e.g. predictive tasks in healthcare, education, or personalized ads) tend to rely on a single explainer. This is a particularly concerning trend when considering that recent work has identified systematic disagreement in explainability methods when applied to the same points and underlying black-box models. In this paper, we therefore present a call for action to address the limitations of current state-of-the-art explainers. We propose to shift from post-hoc explainability to designing interpretable neural network architectures; moving away from approximation techniques in human-centric and high impact applications. We identify five needs of human-centric XAI (real-time, accurate, actionable, human-interpretable, and consistent) and propose two schemes for interpretable-by-design neural network workflows (adaptive routing for interpretable conditional computation and diagnostic benchmarks for iterative model learning). We postulate that the future of human-centric XAI is neither in explaining black-boxes nor in reverting to traditional, interpretable models, but in neural networks that are intrinsically interpretable.
Temporal Causal Mediation through a Point Process: Direct and Indirect Effects of Healthcare Interventions
Jun 16, 2023Deciding on an appropriate intervention requires a causal model of a treatment, the outcome, and potential mediators. Causal mediation analysis lets us distinguish between direct and indirect effects of the intervention, but has mostly been studied in a static setting. In healthcare, data come in the form of complex, irregularly sampled time-series, with dynamic interdependencies between a treatment, outcomes, and mediators across time. Existing approaches to dynamic causal mediation analysis are limited to regular measurement intervals, simple parametric models, and disregard long-range mediator--outcome interactions. To address these limitations, we propose a non-parametric mediator--outcome model where the mediator is assumed to be a temporal point process that interacts with the outcome process. With this model, we estimate the direct and indirect effects of an external intervention on the outcome, showing how each of these affects the whole future trajectory. We demonstrate on semi-synthetic data that our method can accurately estimate direct and indirect effects. On real-world healthcare data, our model infers clinically meaningful direct and indirect effect trajectories for blood glucose after a surgery.
Pose Graph Optimization for a MAV Indoor Localization Fusing 5GNR TOA with an IMU
Jun 16, 2023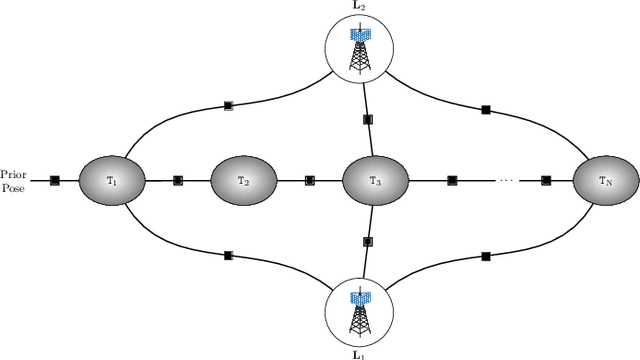
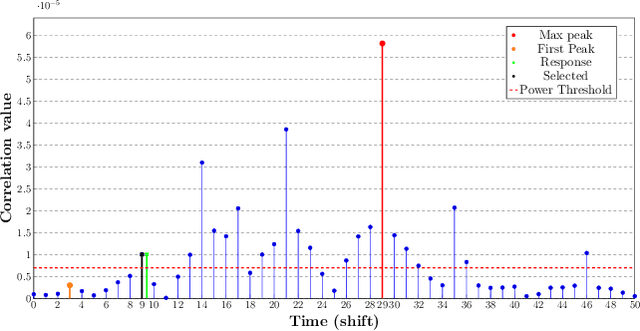
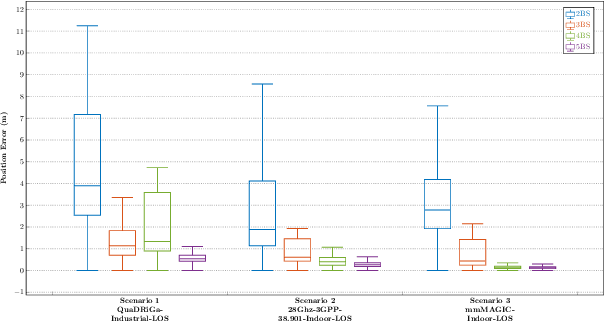
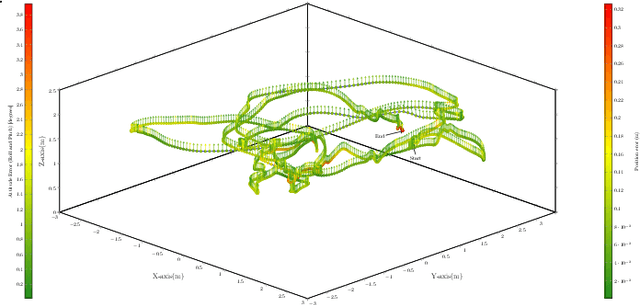
This paper explores the potential of 5G new radio (NR) Time-of-Arrival (TOA) data for indoor drone localization under different scenarios and conditions when fused with inertial measurement unit (IMU) data. Our approach involves performing graph-based optimization to estimate the drone's position and orientation from the multiple sensor measurements. Due to the lack of real-world data, we use Matlab 5G toolbox and QuaDRiGa (quasi-deterministic radio channel generator) channel simulator to generate TOA measurements for the EuRoC MAV indoor dataset that provides IMU readings and ground truths 6DoF poses of a flying drone. Hence, we create twelve sequences combining three predefined indoor scenarios setups of QuaDRiGa with 2 to 5 base station antennas. Therefore, experimental results demonstrate that, for a sufficient number of base stations and a high bandwidth 5G configuration, the pose graph optimization approach achieves accurate drone localization, with an average error of less than 15 cm on the overall trajectory. Furthermore, the adopted graph-based optimization algorithm is fast and can be easily implemented for onboard real-time pose tracking on a micro aerial vehicle (MAV).
Obscured Wildfire Flame Detection By Temporal Analysis of Smoke Patterns Captured by Unmanned Aerial Systems
Jun 30, 2023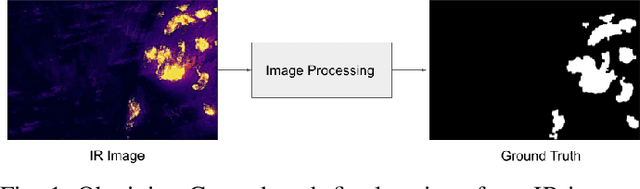

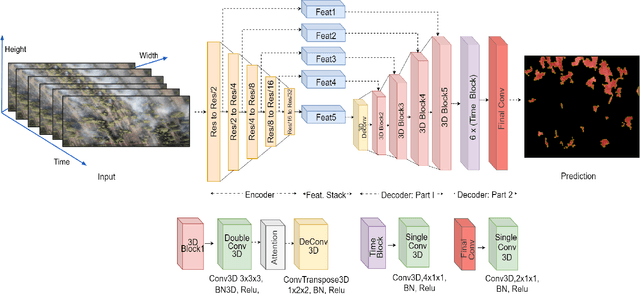
This research paper addresses the challenge of detecting obscured wildfires (when the fire flames are covered by trees, smoke, clouds, and other natural barriers) in real-time using drones equipped only with RGB cameras. We propose a novel methodology that employs semantic segmentation based on the temporal analysis of smoke patterns in video sequences. Our approach utilizes an encoder-decoder architecture based on deep convolutional neural network architecture with a pre-trained CNN encoder and 3D convolutions for decoding while using sequential stacking of features to exploit temporal variations. The predicted fire locations can assist drones in effectively combating forest fires and pinpoint fire retardant chemical drop on exact flame locations. We applied our method to a curated dataset derived from the FLAME2 dataset that includes RGB video along with IR video to determine the ground truth. Our proposed method has a unique property of detecting obscured fire and achieves a Dice score of 85.88%, while achieving a high precision of 92.47% and classification accuracy of 90.67% on test data showing promising results when inspected visually. Indeed, our method outperforms other methods by a significant margin in terms of video-level fire classification as we obtained about 100% accuracy using MobileNet+CBAM as the encoder backbone.
Locking On: Leveraging Dynamic Vehicle-Imposed Motion Constraints to Improve Visual Localization
Jun 30, 2023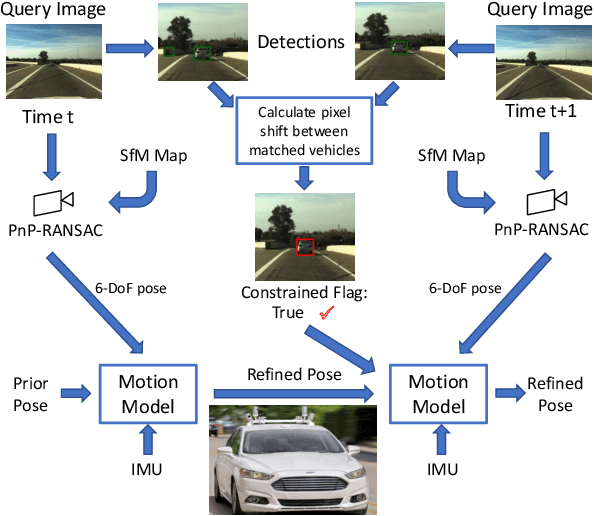
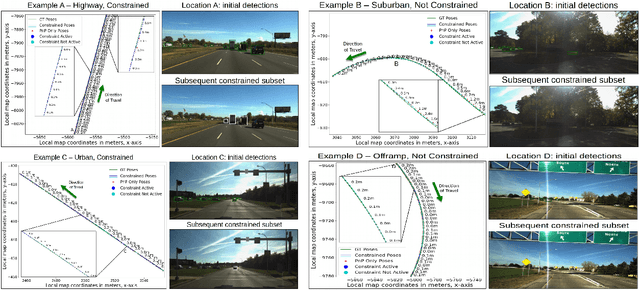

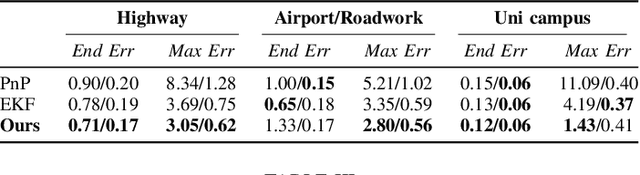
Most 6-DoF localization and SLAM systems use static landmarks but ignore dynamic objects because they cannot be usefully incorporated into a typical pipeline. Where dynamic objects have been incorporated, typical approaches have attempted relatively sophisticated identification and localization of these objects, limiting their robustness or general utility. In this research, we propose a middle ground, demonstrated in the context of autonomous vehicles, using dynamic vehicles to provide limited pose constraint information in a 6-DoF frame-by-frame PnP-RANSAC localization pipeline. We refine initial pose estimates with a motion model and propose a method for calculating the predicted quality of future pose estimates, triggered based on whether or not the autonomous vehicle's motion is constrained by the relative frame-to-frame location of dynamic vehicles in the environment. Our approach detects and identifies suitable dynamic vehicles to define these pose constraints to modify a pose filter, resulting in improved recall across a range of localization tolerances from $0.25m$ to $5m$, compared to a state-of-the-art baseline single image PnP method and its vanilla pose filtering. Our constraint detection system is active for approximately $35\%$ of the time on the Ford AV dataset and localization is particularly improved when the constraint detection is active.
A Personalized Household Assistive Robot that Learns and Creates New Breakfast Options through Human-Robot Interaction
Jun 30, 2023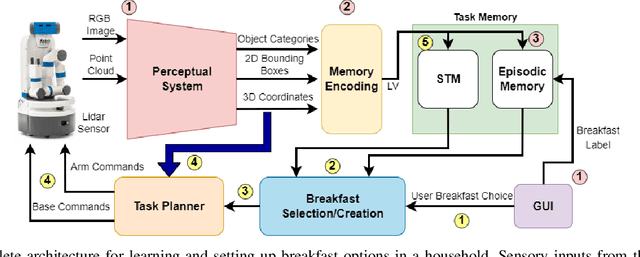
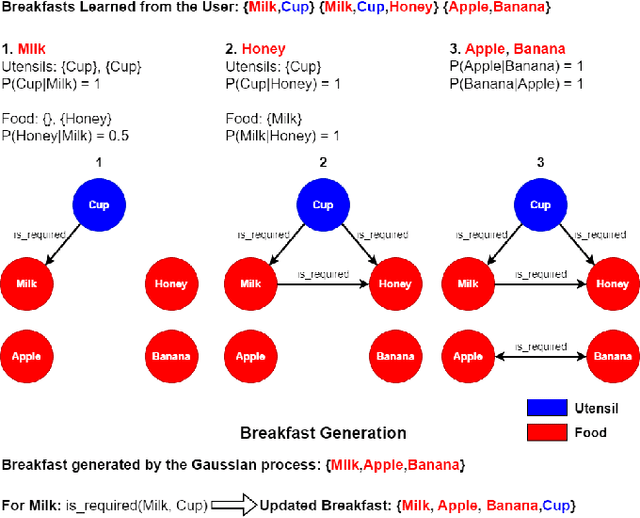
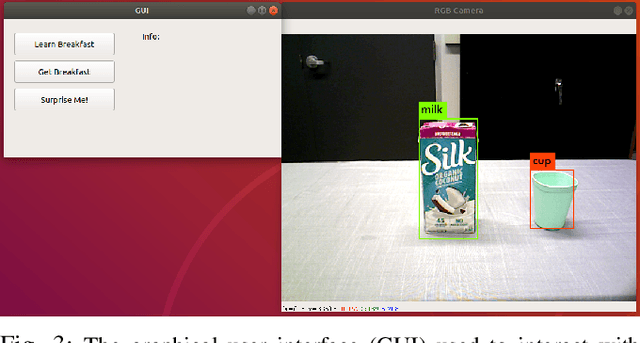

For robots to assist users with household tasks, they must first learn about the tasks from the users. Further, performing the same task every day, in the same way, can become boring for the robot's user(s), therefore, assistive robots must find creative ways to perform tasks in the household. In this paper, we present a cognitive architecture for a household assistive robot that can learn personalized breakfast options from its users and then use the learned knowledge to set up a table for breakfast. The architecture can also use the learned knowledge to create new breakfast options over a longer period of time. The proposed cognitive architecture combines state-of-the-art perceptual learning algorithms, computational implementation of cognitive models of memory encoding and learning, a task planner for picking and placing objects in the household, a graphical user interface (GUI) to interact with the user and a novel approach for creating new breakfast options using the learned knowledge. The architecture is integrated with the Fetch mobile manipulator robot and validated, as a proof-of-concept system evaluation in a large indoor environment with multiple kitchen objects. Experimental results demonstrate the effectiveness of our architecture to learn personalized breakfast options from the user and generate new breakfast options never learned by the robot.
Polarimetric iToF: Measuring High-Fidelity Depth through Scattering Media
Jun 30, 2023
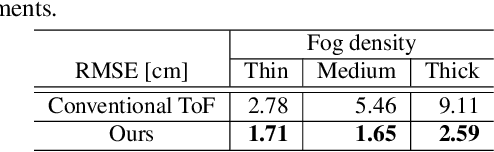
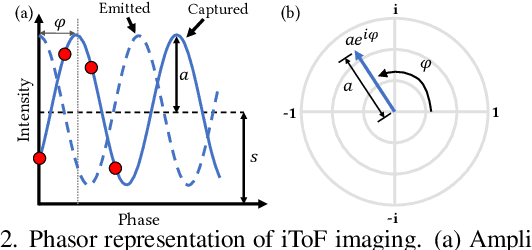

Indirect time-of-flight (iToF) imaging allows us to capture dense depth information at a low cost. However, iToF imaging often suffers from multipath interference (MPI) artifacts in the presence of scattering media, resulting in severe depth-accuracy degradation. For instance, iToF cameras cannot measure depth accurately through fog because ToF active illumination scatters back to the sensor before reaching the farther target surface. In this work, we propose a polarimetric iToF imaging method that can capture depth information robustly through scattering media. Our observations on the principle of indirect ToF imaging and polarization of light allow us to formulate a novel computational model of scattering-aware polarimetric phase measurements that enables us to correct MPI errors. We first devise a scattering-aware polarimetric iToF model that can estimate the phase of unpolarized backscattered light. We then combine the optical filtering of polarization and our computational modeling of unpolarized backscattered light via scattering analysis of phase and amplitude. This allows us to tackle the MPI problem by estimating the scattering energy through the participating media. We validate our method on an experimental setup using a customized off-the-shelf iToF camera. Our method outperforms baseline methods by a significant margin by means of our scattering model and polarimetric phase measurements.
Concept-aware clustering for decentralized deep learning under temporal shift
Jun 22, 2023
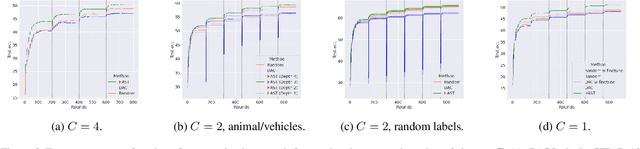
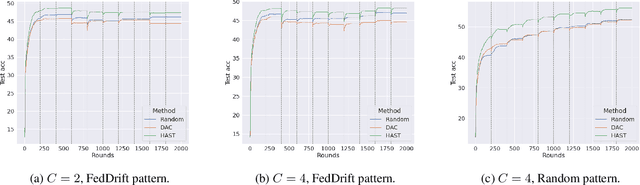
Decentralized deep learning requires dealing with non-iid data across clients, which may also change over time due to temporal shifts. While non-iid data has been extensively studied in distributed settings, temporal shifts have received no attention. To the best of our knowledge, we are first with tackling the novel and challenging problem of decentralized learning with non-iid and dynamic data. We propose a novel algorithm that can automatically discover and adapt to the evolving concepts in the network, without any prior knowledge or estimation of the number of concepts. We evaluate our algorithm on standard benchmark datasets and demonstrate that it outperforms previous methods for decentralized learning.
Time series anomaly detection with sequence reconstruction based state-space model
Mar 06, 2023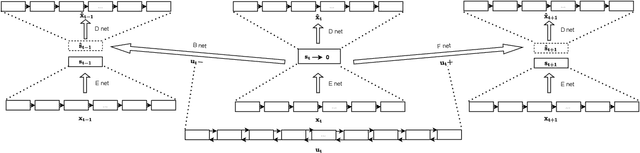
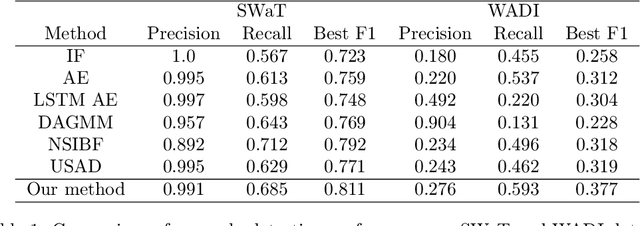
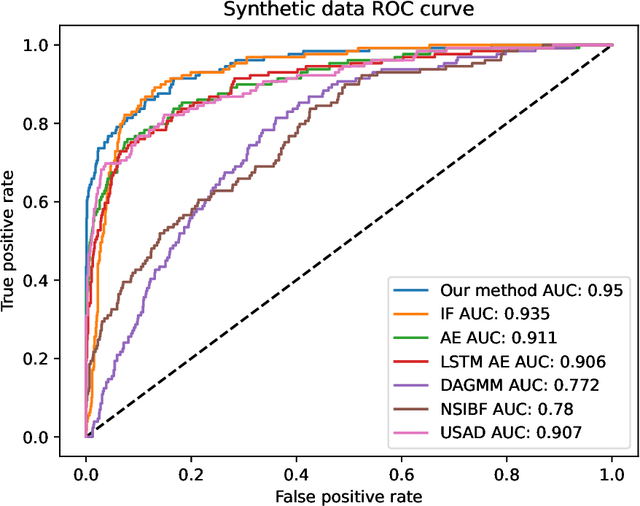
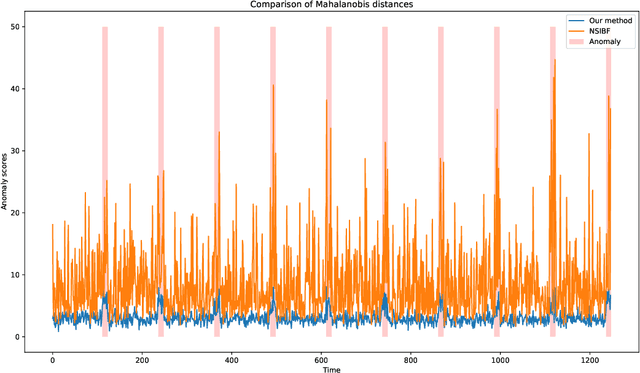
Recent advances in digitization has led to availability of multivariate time series data in various domains, in order to monitor operations in real time. Identifying abnormal data pattern and detect potential failures in these scenarios are important yet rather difficult tasks. We propose a novel unsupervised anomaly detection method for time series data. Our approach uses sequence encoder and decoder to represent the mapping between time series and hidden state, and learns bidirectional dynamics simultaneously by leveraging backward and forward temporal information in the training process. We further regularize the state space to place constraints on states of normal samples, and use Mahalanobis distance to evaluate abnormality level. Results on synthetic and real-world datasets show the superiority of the proposed method.