 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-Time Superficial Vein Imaging System for Observing Abnormalities on Vascular Structures
Apr 29, 2023
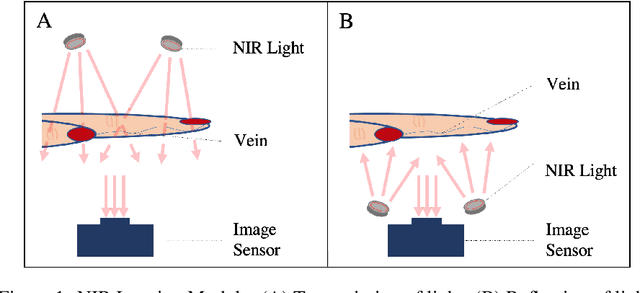
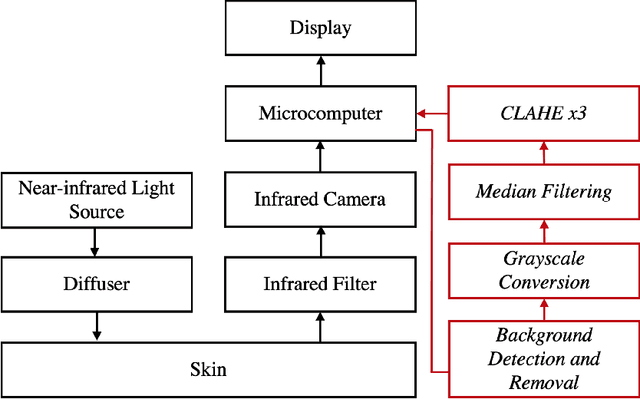

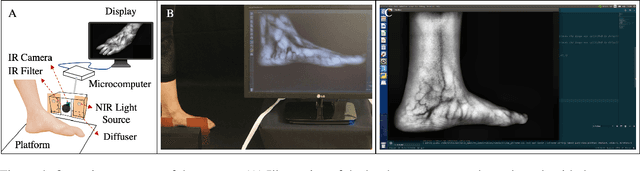
Circulatory system abnormalities might be an indicator of diseases or tissue damage. Early detection of vascular abnormalities might have an important role during treatment and also raise the patient's awarenes. Current detection methods for vascular imaging are high-cost, invasive, and mostly radiation-based. In this study, a low-cost and portable microcomputer-based tool has been developed as a near-infrared (NIR) superficial vascular imaging device. The device uses NIR light-emitting diode (LED) light at 850 nm along with other electronic and optical components. It operates as a non-contact and safe infrared (IR) imaging method in real-time. Image and video analysis are carried out using OpenCV (Open-Source Computer Vision), a library of programming functions mainly used in computer vision. Various tests were carried out to optimize the imaging system and set up a suitable external environment. To test the performance of the device, the images taken from three diabetic volunteers, who are expected to have abnormalities in the vascular structure due to the possibility of deformation caused by high glucose levels in the blood, were compared with the images taken from two non-diabetic volunteers. As a result, tortuosity was observed successfully in the superficial vascular structures, where the results need to be interpreted by the medical experts in the field to understand the underlying reasons. Although this study is an engineering study and does not have an intention to diagnose any diseases, the developed system here might assist healthcare personnel in early diagnosis and treatment follow-up for vascular structures and may enable further opportunities.
Power-Aperture Resource Allocation for a MPAR with Communications Capabilities
Jul 06, 2023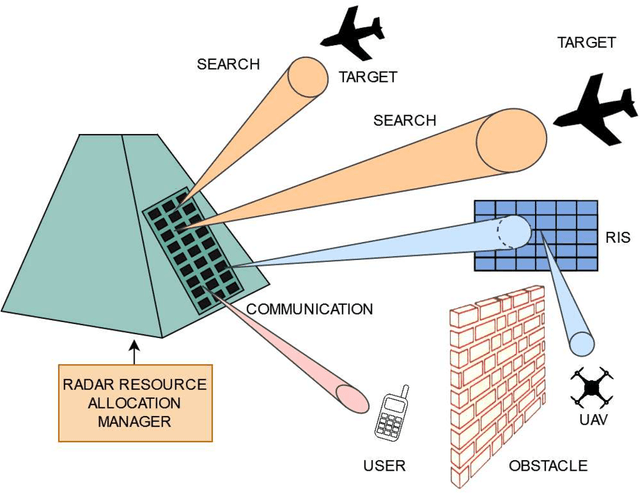
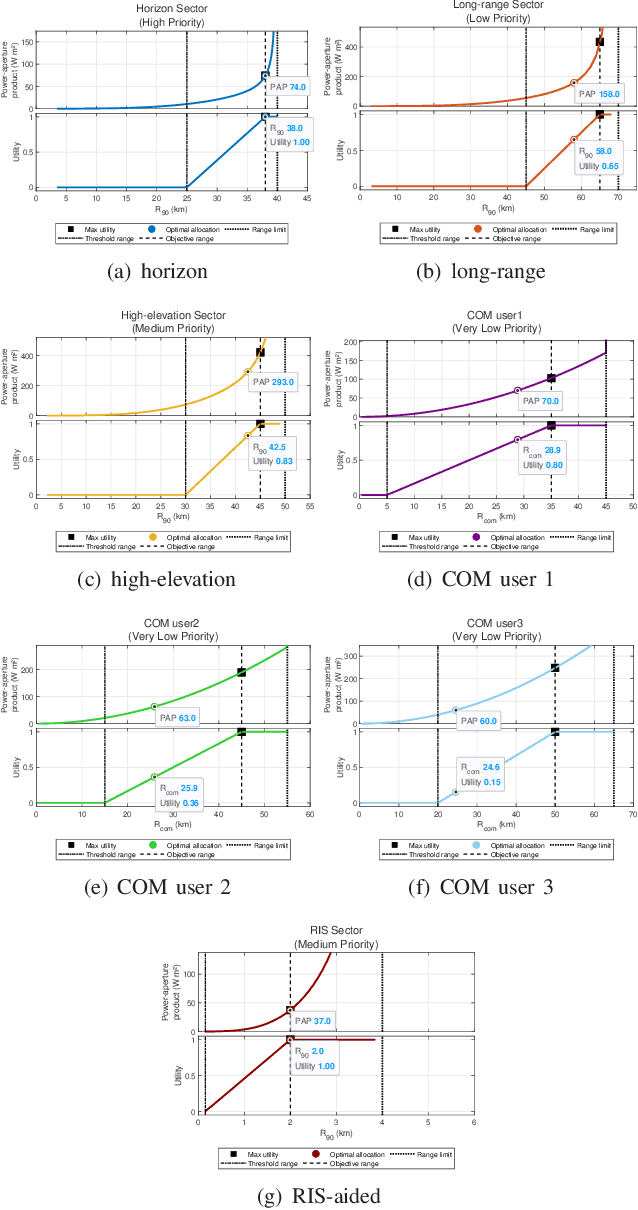
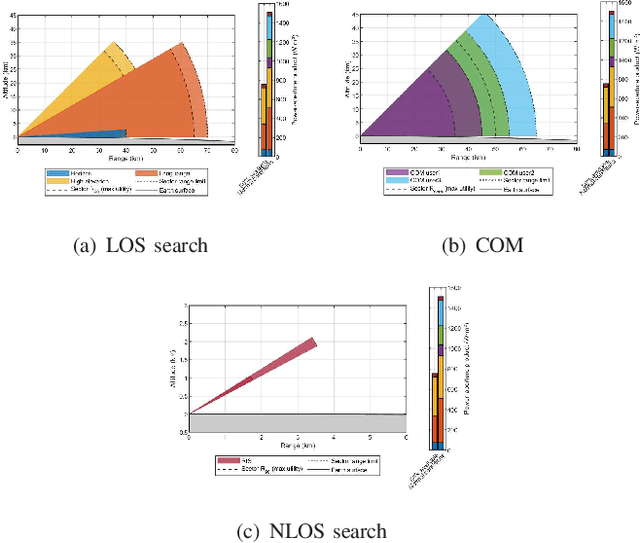
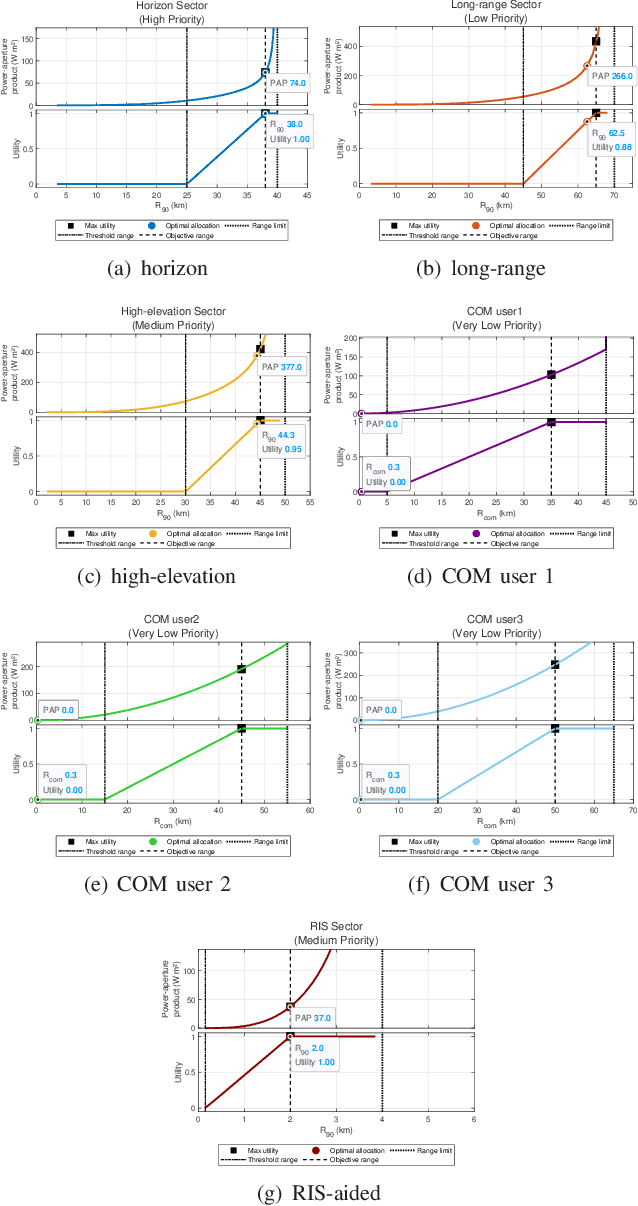
Multifunction phased array radars (MPARs) exploit the intrinsic flexibility of their active electronically steered array (ESA) to perform, at the same time, a multitude of operations, such as search, tracking, fire control, classification, and communications. This paper aims at addressing the MPAR resource allocation so as to satisfy the quality of service (QoS) demanded by both line of sight (LOS) and non line of sight (NLOS) search operations along with communications tasks. To this end, the ranges at which the cumulative detection probability and the channel capacity per bandwidth reach a desired value are introduced as task quality metrics for the search and communication functions, respectively. Then, to quantify the satisfaction level of each task, for each of them a bespoke utility function is defined to map the associated quality metric into the corresponding perceived utility. Hence, assigning different priority weights to each task, the resource allocation problem, in terms of radar power aperture (PAP) specification, is formulated as a constrained optimization problem whose solution optimizes the global radar QoS. Several simulations are conducted in scenarios of practical interest to prove the effectiveness of the approach.
Coupled Gradient Flows for Strategic Non-Local Distribution Shift
Jul 07, 2023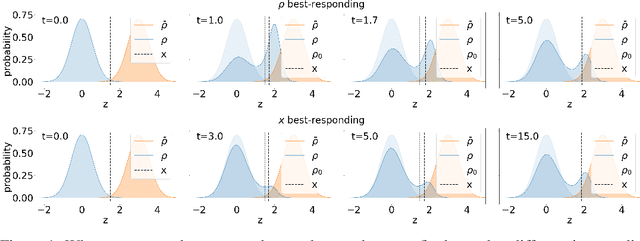

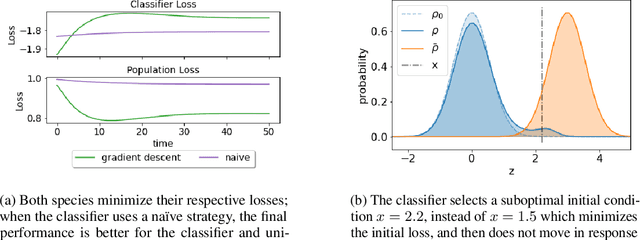
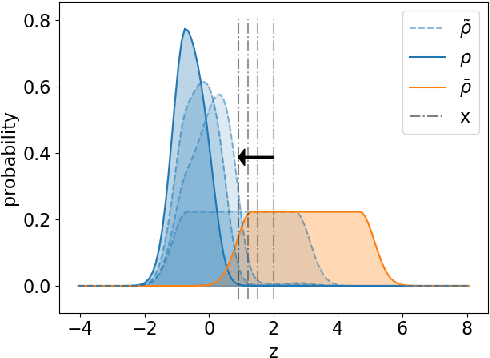
We propose a novel framework for analyzing the dynamics of distribution shift in real-world systems that captures the feedback loop between learning algorithms and the distributions on which they are deployed. Prior work largely models feedback-induced distribution shift as adversarial or via an overly simplistic distribution-shift structure. In contrast, we propose a coupled partial differential equation model that captures fine-grained changes in the distribution over time by accounting for complex dynamics that arise due to strategic responses to algorithmic decision-making, non-local endogenous population interactions, and other exogenous sources of distribution shift. We consider two common settings in machine learning: cooperative settings with information asymmetries, and competitive settings where a learner faces strategic users. For both of these settings, when the algorithm retrains via gradient descent, we prove asymptotic convergence of the retraining procedure to a steady-state, both in finite and in infinite dimensions, obtaining explicit rates in terms of the model parameters. To do so we derive new results on the convergence of coupled PDEs that extends what is known on multi-species systems. Empirically, we show that our approach captures well-documented forms of distribution shifts like polarization and disparate impacts that simpler models cannot capture.
Gesper: A Restoration-Enhancement Framework for General Speech Reconstruction
Jun 14, 2023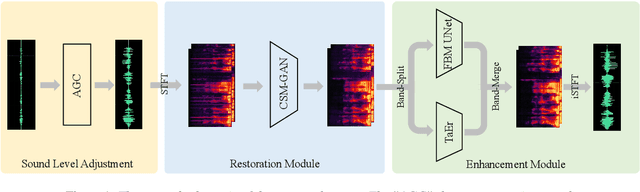
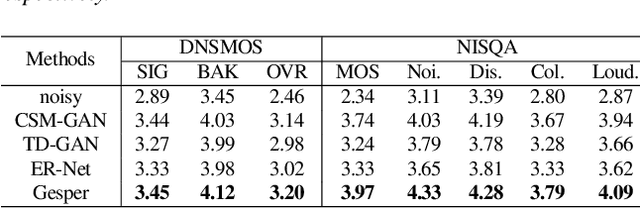
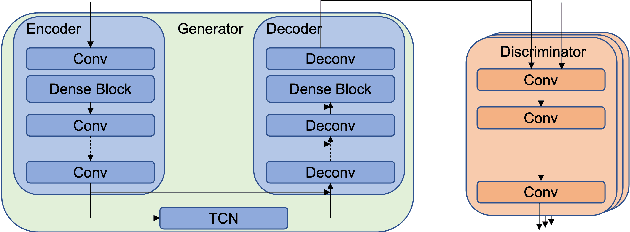
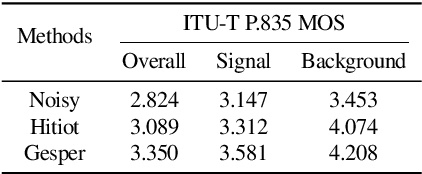
This paper describes a real-time General Speech Reconstruction (Gesper) system submitted to the ICASSP 2023 Speech Signal Improvement (SSI) Challenge. This novel proposed system is a two-stage architecture, in which the speech restoration is performed, and then cascaded by speech enhancement. We propose a complex spectral mapping-based generative adversarial network (CSM-GAN) as the speech restoration module for the first time. For noise suppression and dereverberation, the enhancement module is performed with fullband-wideband parallel processing. On the blind test set of ICASSP 2023 SSI Challenge, the proposed Gesper system, which satisfies the real-time condition, achieves 3.27 P.804 overall mean opinion score (MOS) and 3.35 P.835 overall MOS, ranked 1st in both track 1 and track 2.
ALBERTI, a Multilingual Domain Specific Language Model for Poetry Analysis
Jul 03, 2023

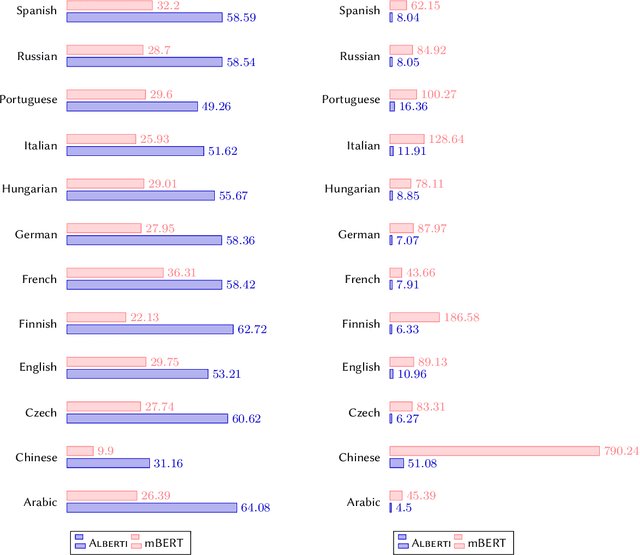

The computational analysis of poetry is limited by the scarcity of tools to automatically analyze and scan poems. In a multilingual settings, the problem is exacerbated as scansion and rhyme systems only exist for individual languages, making comparative studies very challenging and time consuming. In this work, we present \textsc{Alberti}, the first multilingual pre-trained large language model for poetry. Through domain-specific pre-training (DSP), we further trained multilingual BERT on a corpus of over 12 million verses from 12 languages. We evaluated its performance on two structural poetry tasks: Spanish stanza type classification, and metrical pattern prediction for Spanish, English and German. In both cases, \textsc{Alberti} outperforms multilingual BERT and other transformers-based models of similar sizes, and even achieves state-of-the-art results for German when compared to rule-based systems, demonstrating the feasibility and effectiveness of DSP in the poetry domain.
Soft Dynamic Time Warping for Multi-Pitch Estimation and Beyond
Apr 11, 2023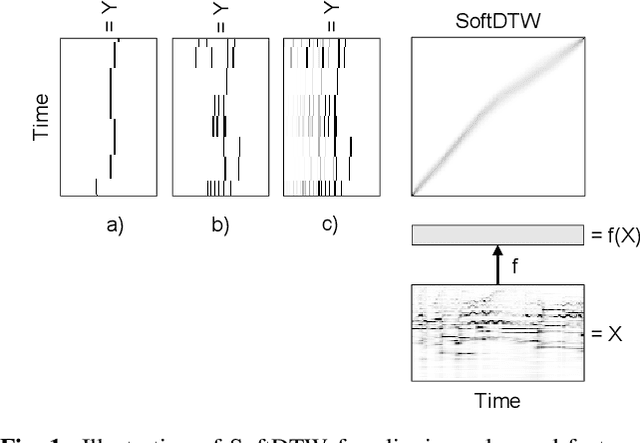
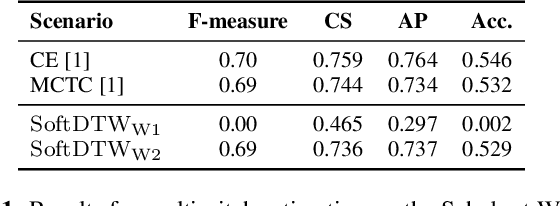
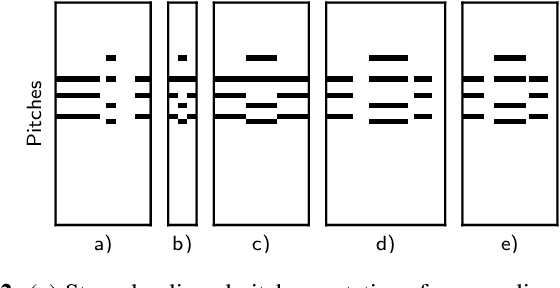
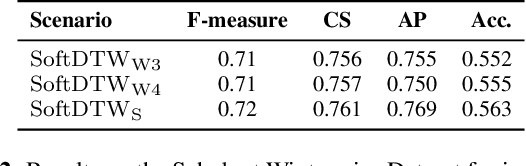
Many tasks in music information retrieval (MIR) involve weakly aligned data, where exact temporal correspondences are unknown. The connectionist temporal classification (CTC) loss is a standard technique to learn feature representations based on weakly aligned training data. However, CTC is limited to discrete-valued target sequences and can be difficult to extend to multi-label problems. In this article, we show how soft dynamic time warping (SoftDTW), a differentiable variant of classical DTW, can be used as an alternative to CTC. Using multi-pitch estimation as an example scenario, we show that SoftDTW yields results on par with a state-of-the-art multi-label extension of CTC. In addition to being more elegant in terms of its algorithmic formulation, SoftDTW naturally extends to real-valued target sequences.
CT-based Subchondral Bone Microstructural Analysis in Knee Osteoarthritis via MR-Guided Distillation Learning
Jul 11, 2023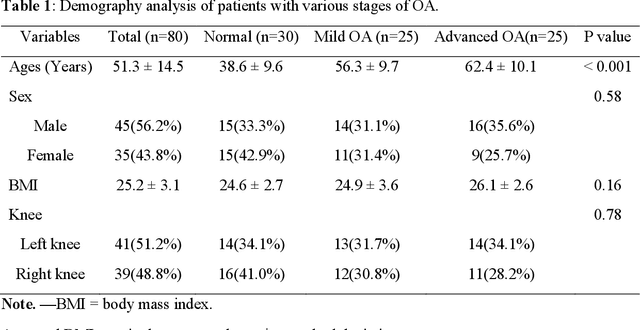

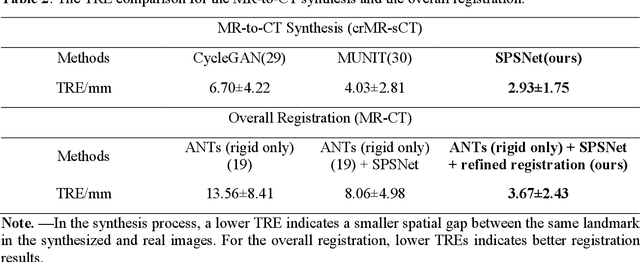
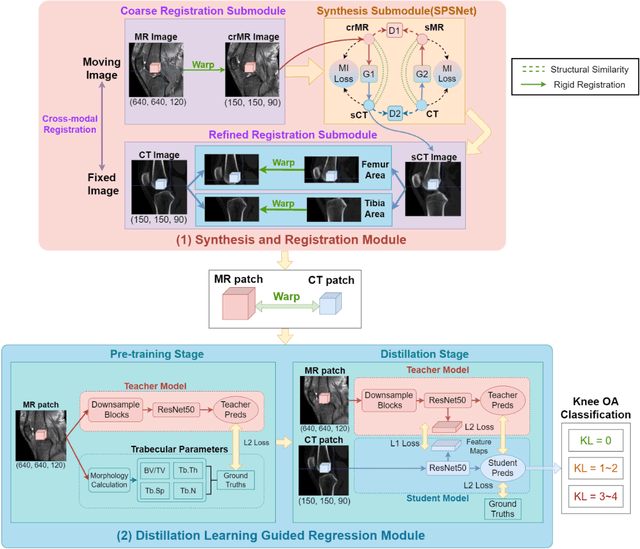
Background: MR-based subchondral bone effectively predicts knee osteoarthritis. However, its clinical application is limited by the cost and time of MR. Purpose: We aim to develop a novel distillation-learning-based method named SRRD for subchondral bone microstructural analysis using easily-acquired CT images, which leverages paired MR images to enhance the CT-based analysis model during training. Materials and Methods: Knee joint images of both CT and MR modalities were collected from October 2020 to May 2021. Firstly, we developed a GAN-based generative model to transform MR images into CT images, which was used to establish the anatomical correspondence between the two modalities. Next, we obtained numerous patches of subchondral bone regions of MR images, together with their trabecular parameters (BV / TV, Tb. Th, Tb. Sp, Tb. N) from the corresponding CT image patches via regression. The distillation-learning technique was used to train the regression model and transfer MR structural information to the CT-based model. The regressed trabecular parameters were further used for knee osteoarthritis classification. Results: A total of 80 participants were evaluated. CT-based regression results of trabecular parameters achieved intra-class correlation coefficients (ICCs) of 0.804, 0.773, 0.711, and 0.622 for BV / TV, Tb. Th, Tb. Sp, and Tb. N, respectively. The use of distillation learning significantly improved the performance of the CT-based knee osteoarthritis classification method using the CNN approach, yielding an AUC score of 0.767 (95% CI, 0.681-0.853) instead of 0.658 (95% CI, 0.574-0.742) (p<.001). Conclusions: The proposed SRRD method showed high reliability and validity in MR-CT registration, regression, and knee osteoarthritis classification, indicating the feasibility of subchondral bone microstructural analysis based on CT images.
Sound Demixing Challenge 2023 Music Demixing Track Technical Report: TFC-TDF-UNet v3
Jun 26, 2023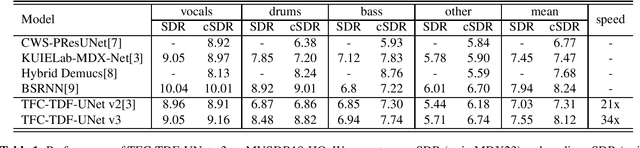
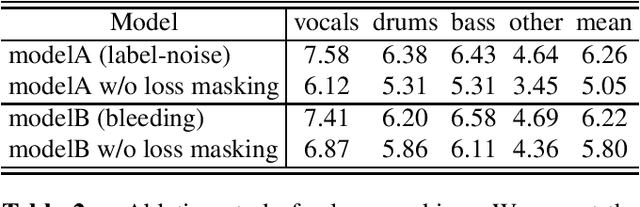
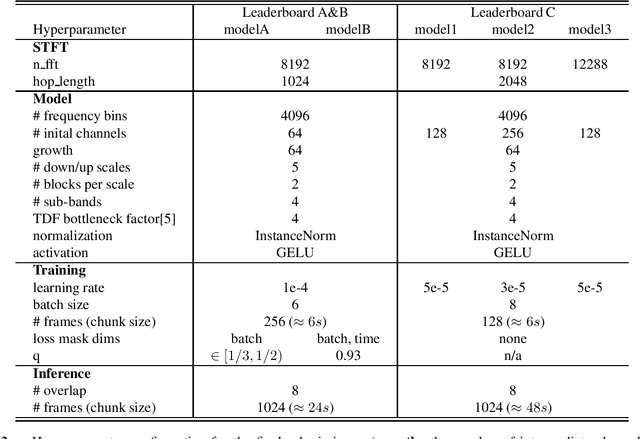
In this report, we present our award-winning solutions for the Music Demixing Track of Sound Demixing Challenge 2023. First, we propose TFC-TDF-UNet v3, a time-efficient music source separation model that achieves state-of-the-art results on the MUSDB benchmark. We then give full details regarding our solutions for each Leaderboard, including a loss masking approach for noise-robust training. Code for reproducing model training and final submissions is available at github.com/kuielab/sdx23.
Calculating the matrix profile from noisy data
Jun 16, 2023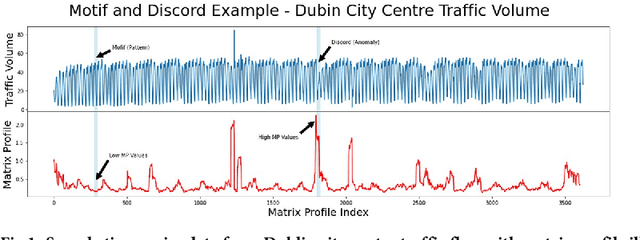
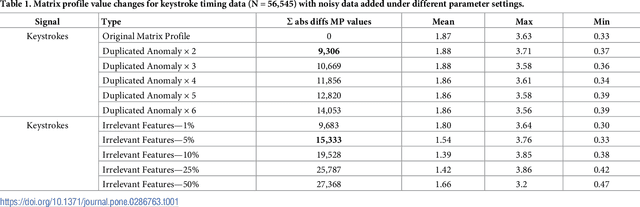
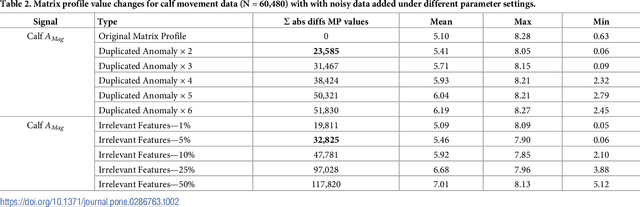
The matrix profile (MP) is a data structure computed from a time series which encodes the data required to locate motifs and discords, corresponding to recurring patterns and outliers respectively. When the time series contains noisy data then the conventional approach is to pre-filter it in order to remove noise but this cannot apply in unsupervised settings where patterns and outliers are not annotated. The resilience of the algorithm used to generate the MP when faced with noisy data remains unknown. We measure the similarities between the MP from original time series data with MPs generated from the same data with noisy data added under a range of parameter settings including adding duplicates and adding irrelevant data. We use three real world data sets drawn from diverse domains for these experiments Based on dissimilarities between the MPs, our results suggest that MP generation is resilient to a small amount of noise being introduced into the data but as the amount of noise increases this resilience disappears
* 16 pages
Temporal Difference Learning with Experience Replay
Jun 16, 2023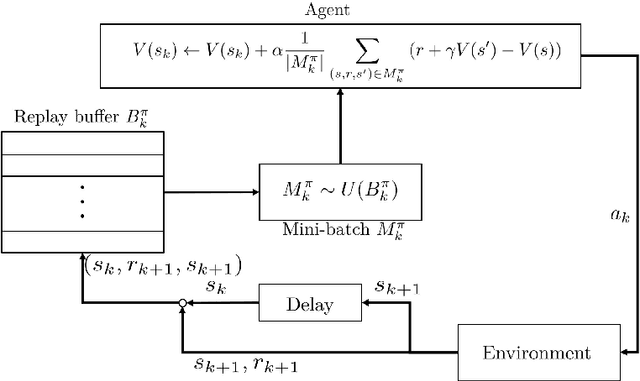
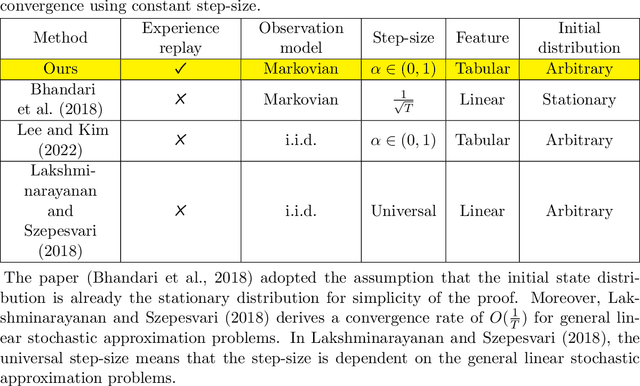
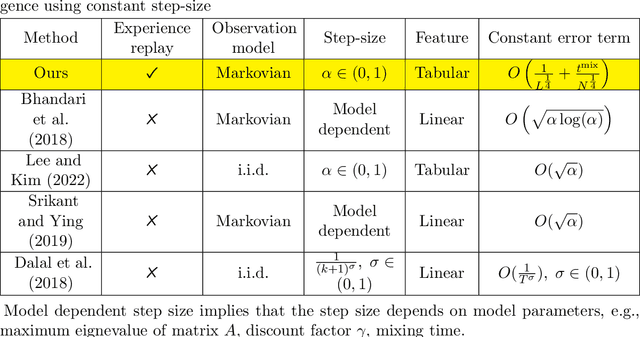
Temporal-difference (TD) learning is widely regarded as one of the most popular algorithms in reinforcement learning (RL). Despite its widespread use, it has only been recently that researchers have begun to actively study its finite time behavior, including the finite time bound on mean squared error and sample complexity. On the empirical side, experience replay has been a key ingredient in the success of deep RL algorithms, but its theoretical effects on RL have yet to be fully understood. In this paper, we present a simple decomposition of the Markovian noise terms and provide finite-time error bounds for TD-learning with experience replay. Specifically, under the Markovian observation model, we demonstrate that for both the averaged iterate and final iterate cases, the error term induced by a constant step-size can be effectively controlled by the size of the replay buffer and the mini-batch sampled from the experience replay buffer.