 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Agricultural Robotic System: The Automation of Detection and Speech Control
Jul 19, 2023
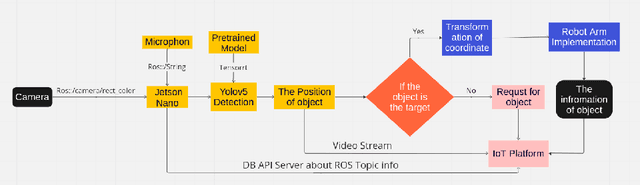
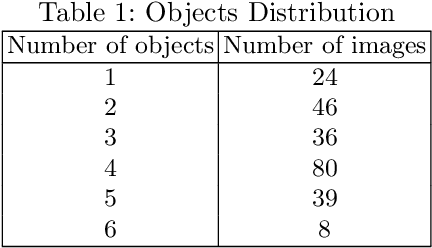
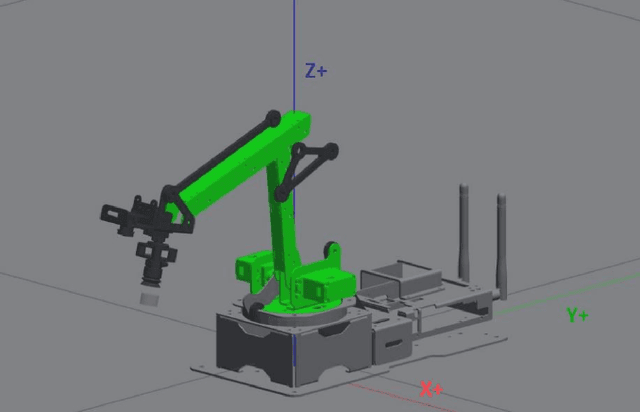
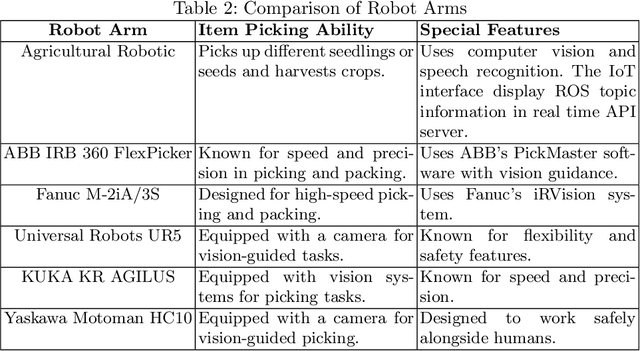
Agriculture industries often face challenges in manual tasks such as planting, harvesting, fertilizing, and detection, which can be time consuming and prone to errors. The "Agricultural Robotic System" project addresses these issues through a modular design that integrates advanced visual, speech recognition, and robotic technologies. This system is comprised of separate but interconnected modules for vision detection and speech recognition, creating a flexible and adaptable solution. The vision detection module uses computer vision techniques, trained on YOLOv5 and deployed on the Jetson Nano in TensorRT format, to accurately detect and identify different items. A robotic arm module then precisely controls the picking up of seedlings or seeds, and arranges them in specific locations. The speech recognition module enhances intelligent human robot interaction, allowing for efficient and intuitive control of the system. This modular approach improves the efficiency and accuracy of agricultural tasks, demonstrating the potential of robotics in the agricultural industry.
Real-time and Robust Feature Detection of Continuous Marker Pattern for Dense 3-D Deformation Measurement
May 22, 2023
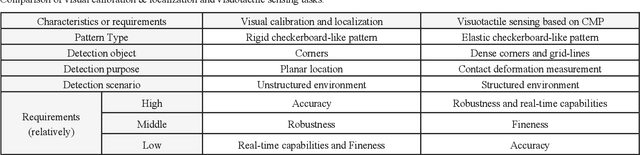
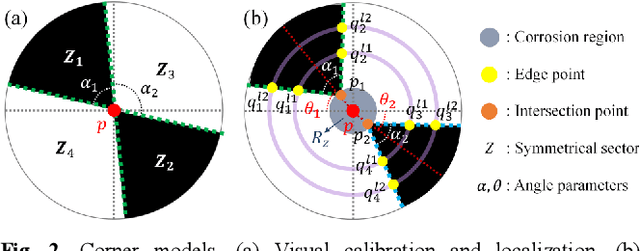
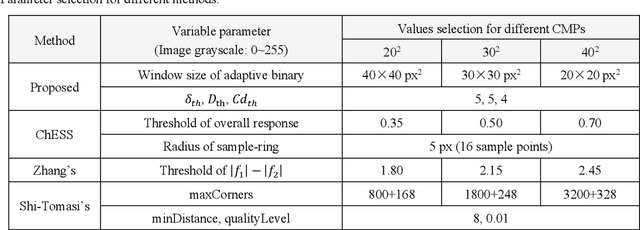
Visuotactile sensing technology has received much attention in recent years. This article proposes a feature detection method applicable to visuotactile sensors based on continuous marker patterns (CMP) to measure 3-d deformation. First, we construct the feature model of checkerboard-like corners under contact deformation, and design a novel double-layer circular sampler. Then, we propose the judging criteria and response function of corner features by analyzing sampling signals' amplitude-frequency characteristics and circular cross-correlation behavior. The proposed feature detection algorithm fully considers the boundary characteristics retained by the corners with geometric distortion, thus enabling reliable detection at a low calculation cost. The experimental results show that the proposed method has significant advantages in terms of real-time and robustness. Finally, we have achieved the high-density 3-d contact deformation visualization based on this detection method. This technique is able to clearly record the process of contact deformation, thus enabling inverse sensing of dynamic contact processes.
FedDCT: A Dynamic Cross-Tier Federated Learning Scheme in Wireless Communication Networks
Jul 10, 2023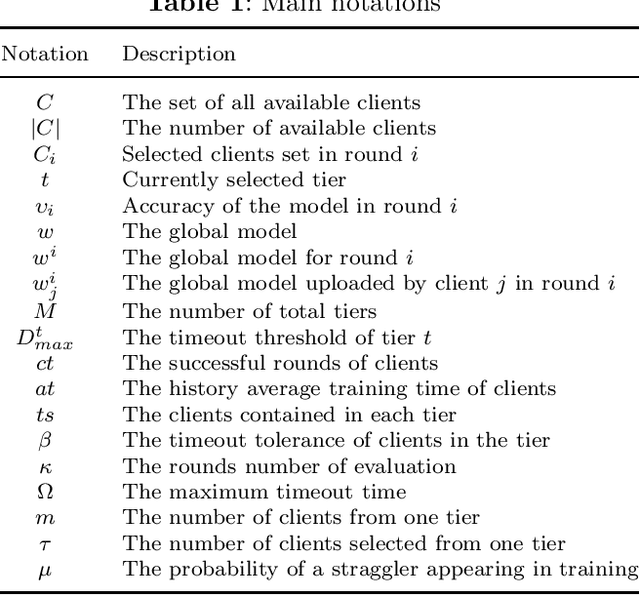
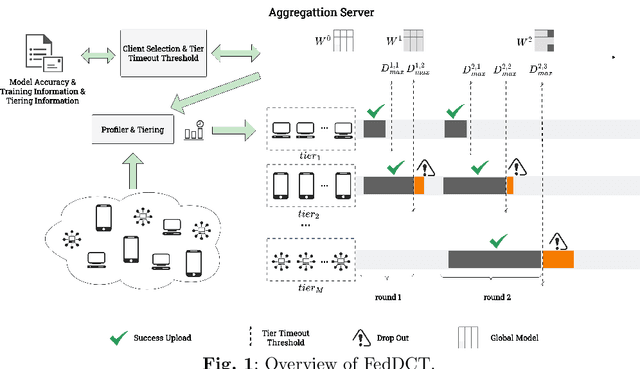
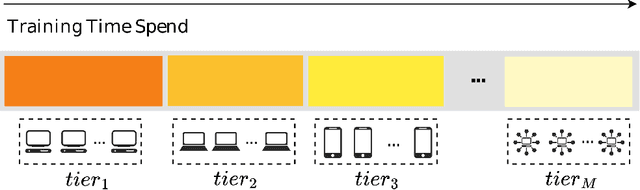
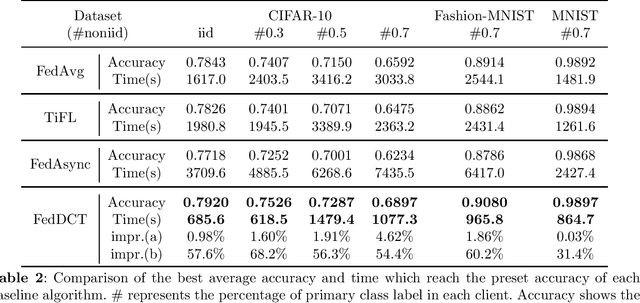
With the rapid proliferation of Internet of Things (IoT) devices and the growing concern for data privacy among the public, Federated Learning (FL) has gained significant attention as a privacy-preserving machine learning paradigm. FL enables the training of a global model among clients without exposing local data. However, when a federated learning system runs on wireless communication networks, limited wireless resources, heterogeneity of clients, and network transmission failures affect its performance and accuracy. In this study, we propose a novel dynamic cross-tier FL scheme, named FedDCT to increase training accuracy and performance in wireless communication networks. We utilize a tiering algorithm that dynamically divides clients into different tiers according to specific indicators and assigns specific timeout thresholds to each tier to reduce the training time required. To improve the accuracy of the model without increasing the training time, we introduce a cross-tier client selection algorithm that can effectively select the tiers and participants. Simulation experiments show that our scheme can make the model converge faster and achieve a higher accuracy in wireless communication networks.
Combining DVL-INS and Laser-Based Loop Closures in a Batch Estimation Framework for Underwater Positioning
Jul 10, 2023Correcting gradual position drift is a challenge in long-term subsea navigation. Though highly accurate, modern inertial navigation system (INS) estimates will drift over time due to the accumulated effects of sensor noise and biases, even with acoustic aiding from a Doppler velocity log (DVL). The raw sensor measurements and estimation algorithms used by the DVL-aided INS are often proprietary, which restricts the fusion of additional sensors that could bound navigation drift over time. In this letter, the raw sensor measurements and their respective covariances are estimated from the DVL-aided INS output using semidefinite programming tools. The estimated measurements are then augmented with laser-based loop-closure measurements in a batch state estimation framework to correct planar position errors. The heading uncertainty from the DVL-aided INS is also considered in the estimation of the updated positions. The pipeline is tested in simulation and on experimental field data. The proposed methodology reduces the long-term navigation drift by more than 30 times compared to the DVL-aided INS estimate.
Reduced Kernel Dictionary Learning
Jul 17, 2023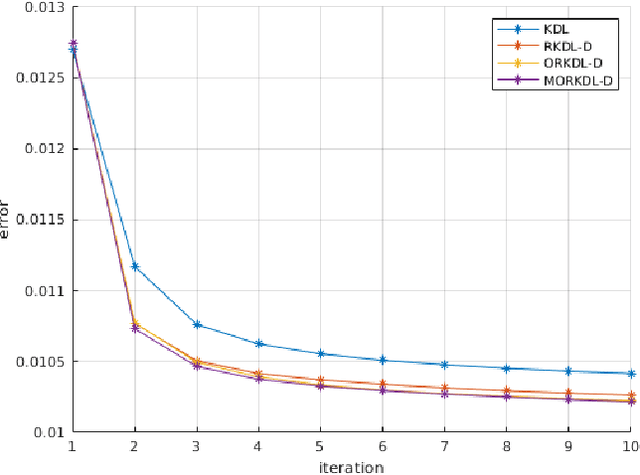
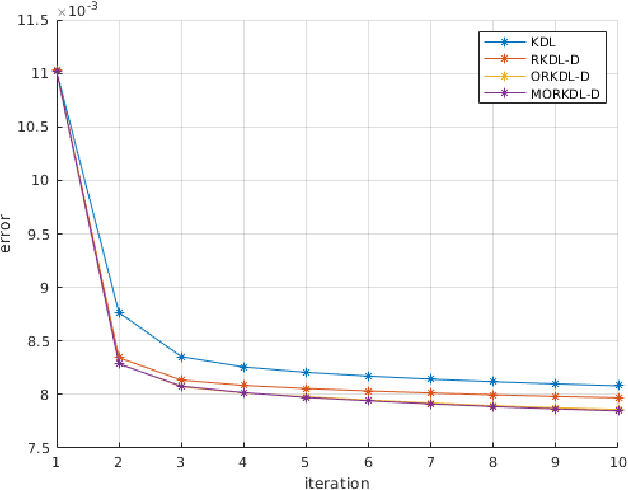
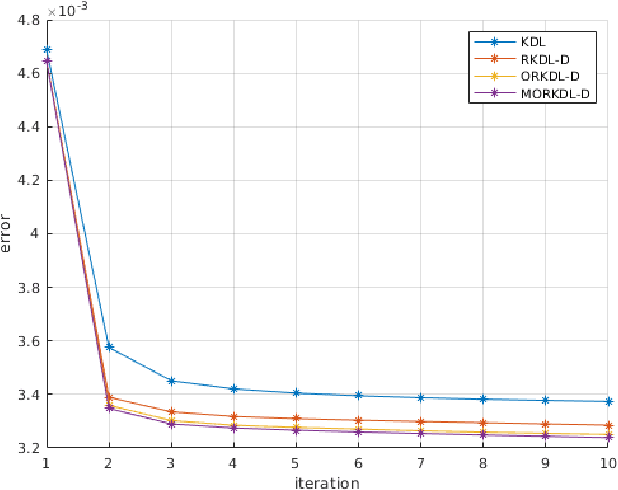
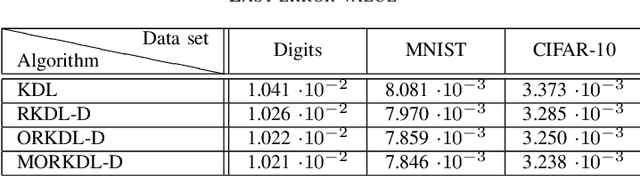
In this paper we present new algorithms for training reduced-size nonlinear representations in the Kernel Dictionary Learning (KDL) problem. Standard KDL has the drawback of a large size of the kernel matrix when the data set is large. There are several ways of reducing the kernel size, notably Nystr\"om sampling. We propose here a method more in the spirit of dictionary learning, where the kernel vectors are obtained with a trained sparse representation of the input signals. Moreover, we optimize directly the kernel vectors in the KDL process, using gradient descent steps. We show with three data sets that our algorithms are able to provide better representations, despite using a small number of kernel vectors, and also decrease the execution time with respect to KDL.
Vision-Based Reactive Planning and Control of Quadruped Robots in Unstructured Dynamic Environments
Jul 17, 2023
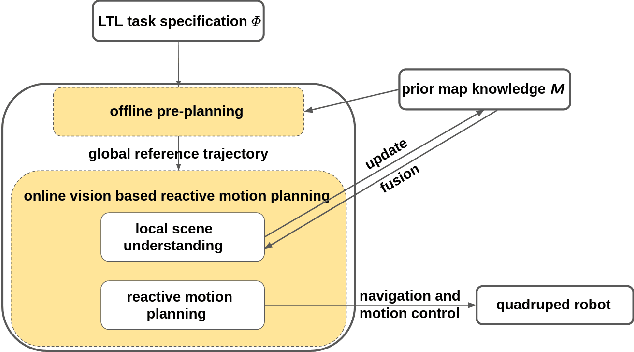

Quadruped robots have received increasing attention for the past few years. However, existing works primarily focus on static environments or assume the robot has full observations of the environment. This limits their practical applications since real-world environments are often dynamic and partially observable. To tackle these issues, vision-based reactive planning and control (V-RPC) is developed in this work. The V-RPC comprises two modules: offline pre-planning and online reactive planning. The pre-planning phase generates a reference trajectory over continuous workspace via sampling-based methods using prior environmental knowledge, given an LTL specification. The online reactive module dynamically adjusts the reference trajectory and control based on the robot's real-time visual perception to adapt to environmental changes.
ESGCN: Edge Squeeze Attention Graph Convolutional Network for Traffic Flow Forecasting
Jul 12, 2023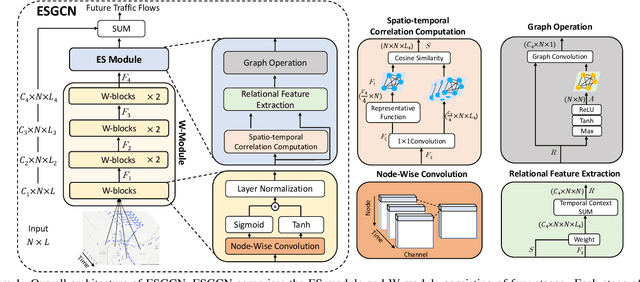
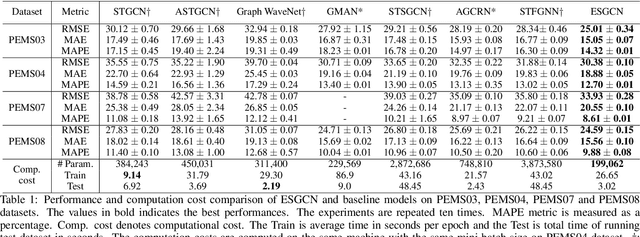
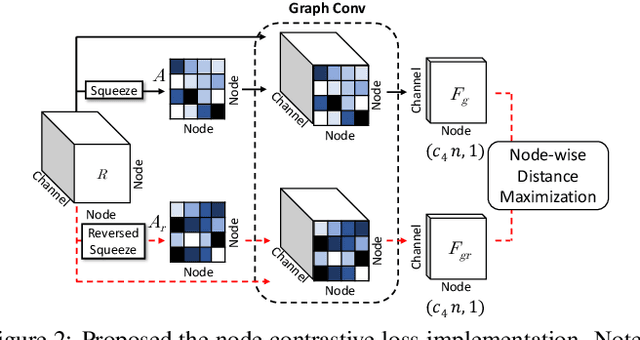
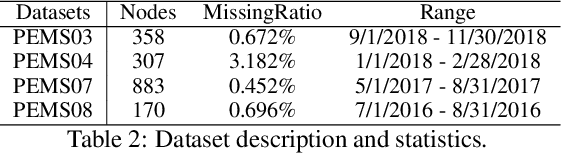
Traffic forecasting is a highly challenging task owing to the dynamical spatio-temporal dependencies of traffic flows. To handle this, we focus on modeling the spatio-temporal dynamics and propose a network termed Edge Squeeze Graph Convolutional Network (ESGCN) to forecast traffic flow in multiple regions. ESGCN consists of two modules: W-module and ES module. W-module is a fully node-wise convolutional network. It encodes the time-series of each traffic region separately and decomposes the time-series at various scales to capture fine and coarse features. The ES module models the spatio-temporal dynamics using Graph Convolutional Network (GCN) and generates an Adaptive Adjacency Matrix (AAM) with temporal features. To improve the accuracy of AAM, we introduce three key concepts. 1) Using edge features to directly capture the spatiotemporal flow representation among regions. 2) Applying an edge attention mechanism to GCN to extract the AAM from the edge features. Here, the attention mechanism can effectively determine important spatio-temporal adjacency relations. 3) Proposing a novel node contrastive loss to suppress obstructed connections and emphasize related connections. Experimental results show that ESGCN achieves state-of-the-art performance by a large margin on four real-world datasets (PEMS03, 04, 07, and 08) with a low computational cost.
A Mapping Study of Machine Learning Methods for Remaining Useful Life Estimation of Lead-Acid Batteries
Jul 11, 2023Energy storage solutions play an increasingly important role in modern infrastructure and lead-acid batteries are among the most commonly used in the rechargeable category. Due to normal degradation over time, correctly determining the battery's State of Health (SoH) and Remaining Useful Life (RUL) contributes to enhancing predictive maintenance, reliability, and longevity of battery systems. Besides improving the cost savings, correct estimation of the SoH can lead to reduced pollution though reuse of retired batteries. This paper presents a mapping study of the state-of-the-art in machine learning methods for estimating the SoH and RUL of lead-acid batteries. These two indicators are critical in the battery management systems of electric vehicles, renewable energy systems, and other applications that rely heavily on this battery technology. In this study, we analyzed the types of machine learning algorithms employed for estimating SoH and RUL, and evaluated their performance in terms of accuracy and inference time. Additionally, this mapping identifies and analyzes the most commonly used combinations of sensors in specific applications, such as vehicular batteries. The mapping concludes by highlighting potential gaps and opportunities for future research, which lays the foundation for further advancements in the field.
RefVSR++: Exploiting Reference Inputs for Reference-based Video Super-resolution
Jul 06, 2023
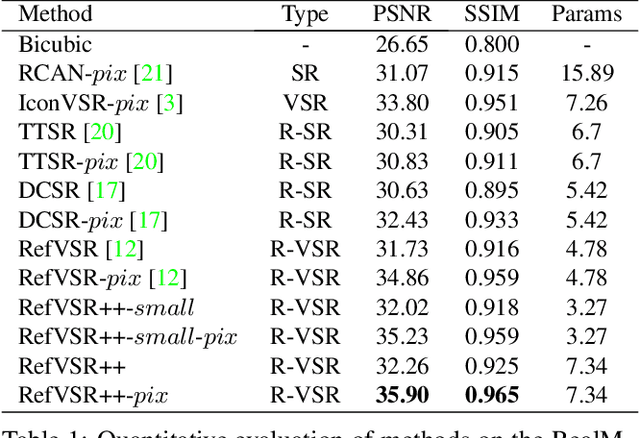
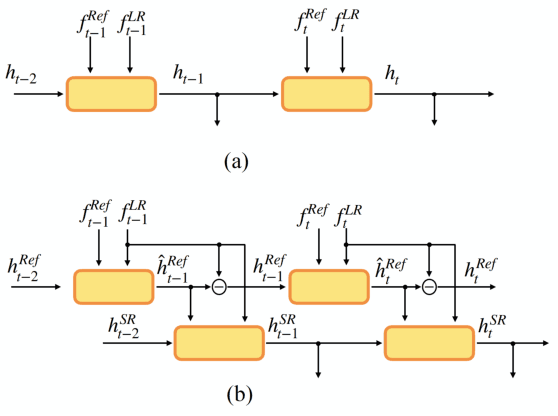
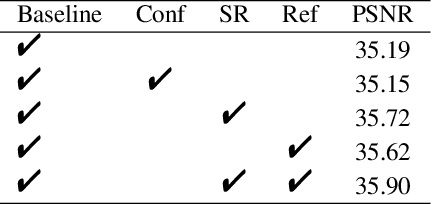
Smartphones equipped with a multi-camera system comprising multiple cameras with different field-of-view (FoVs) are becoming more prevalent. These camera configurations are compatible with reference-based SR and video SR, which can be executed simultaneously while recording video on the device. Thus, combining these two SR methods can improve image quality. Recently, Lee et al. have presented such a method, RefVSR. In this paper, we consider how to optimally utilize the observations obtained, including input low-resolution (LR) video and reference (Ref) video. RefVSR extends conventional video SR quite simply, aggregating the LR and Ref inputs over time in a single bidirectional stream. However, considering the content difference between LR and Ref images due to their FoVs, we can derive the maximum information from the two image sequences by aggregating them independently in the temporal direction. Then, we propose an improved method, RefVSR++, which can aggregate two features in parallel in the temporal direction, one for aggregating the fused LR and Ref inputs and the other for Ref inputs over time. Furthermore, we equip RefVSR++ with enhanced mechanisms to align image features over time, which is the key to the success of video SR. We experimentally show that RefVSR++ outperforms RefVSR by over 1dB in PSNR, achieving the new state-of-the-art.
Foundational Models Defining a New Era in Vision: A Survey and Outlook
Jul 25, 2023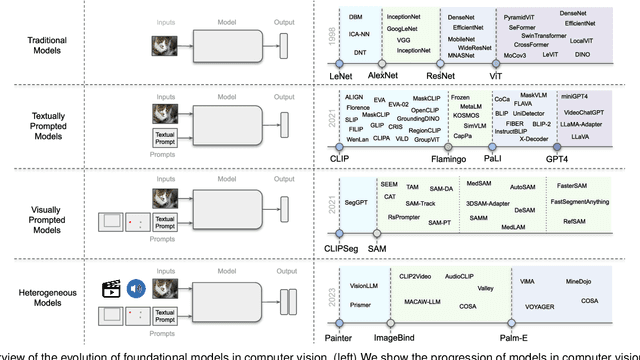
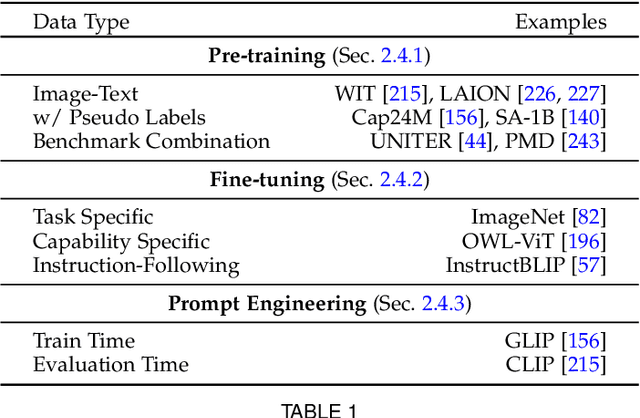
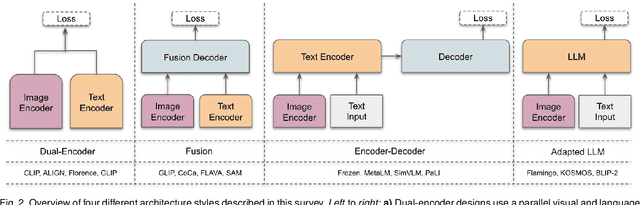
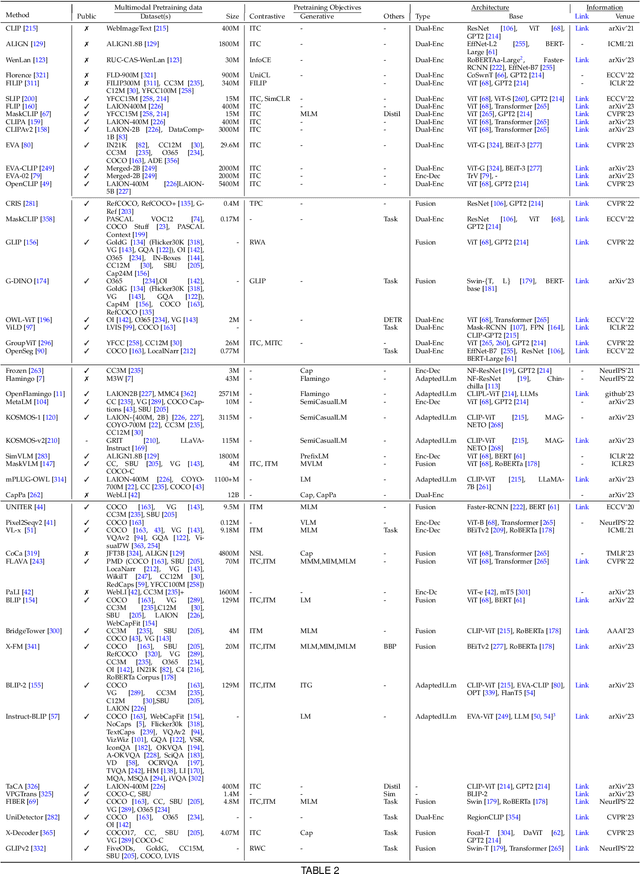
Vision systems to see and reason about the compositional nature of visual scenes are fundamental to understanding our world. The complex relations between objects and their locations, ambiguities, and variations in the real-world environment can be better described in human language, naturally governed by grammatical rules and other modalities such as audio and depth. The models learned to bridge the gap between such modalities coupled with large-scale training data facilitate contextual reasoning, generalization, and prompt capabilities at test time. These models are referred to as foundational models. The output of such models can be modified through human-provided prompts without retraining, e.g., segmenting a particular object by providing a bounding box, having interactive dialogues by asking questions about an image or video scene or manipulating the robot's behavior through language instructions. In this survey, we provide a comprehensive review of such emerging foundational models, including typical architecture designs to combine different modalities (vision, text, audio, etc), training objectives (contrastive, generative), pre-training datasets, fine-tuning mechanisms, and the common prompting patterns; textual, visual, and heterogeneous. We discuss the open challenges and research directions for foundational models in computer vision, including difficulties in their evaluations and benchmarking, gaps in their real-world understanding, limitations of their contextual understanding, biases, vulnerability to adversarial attacks, and interpretability issues. We review recent developments in this field, covering a wide range of applications of foundation models systematically and comprehensively. A comprehensive list of foundational models studied in this work is available at \url{https://github.com/awaisrauf/Awesome-CV-Foundational-Models}.