 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Temporal Fusion Beyond the Field of View for Camera-based Semantic Scene Completion
Nov 16, 2025



Recent camera-based 3D semantic scene completion (SSC) methods have increasingly explored leveraging temporal cues to enrich the features of the current frame. However, while these approaches primarily focus on enhancing in-frame regions, they often struggle to reconstruct critical out-of-frame areas near the sides of the ego-vehicle, although previous frames commonly contain valuable contextual information about these unseen regions. To address this limitation, we propose the Current-Centric Contextual 3D Fusion (C3DFusion) module, which generates hidden region-aware 3D feature geometry by explicitly aligning 3D-lifted point features from both current and historical frames. C3DFusion performs enhanced temporal fusion through two complementary techniques-historical context blurring and current-centric feature densification-which suppress noise from inaccurately warped historical point features by attenuating their scale, and enhance current point features by increasing their volumetric contribution. Simply integrated into standard SSC architectures, C3DFusion demonstrates strong effectiveness, significantly outperforming state-of-the-art methods on the SemanticKITTI and SSCBench-KITTI-360 datasets. Furthermore, it exhibits robust generalization, achieving notable performance gains when applied to other baseline models.
Fine-Tuning Diffusion-Based Recommender Systems via Reinforcement Learning with Reward Function Optimization
Nov 10, 2025Diffusion models recently emerged as a powerful paradigm for recommender systems, offering state-of-the-art performance by modeling the generative process of user-item interactions. However, training such models from scratch is both computationally expensive and yields diminishing returns once convergence is reached. To remedy these challenges, we propose ReFiT, a new framework that integrates Reinforcement learning (RL)-based Fine-Tuning into diffusion-based recommender systems. In contrast to prior RL approaches for diffusion models depending on external reward models, ReFiT adopts a task-aligned design: it formulates the denoising trajectory as a Markov decision process (MDP) and incorporates a collaborative signal-aware reward function that directly reflects recommendation quality. By tightly coupling the MDP structure with this reward signal, ReFiT empowers the RL agent to exploit high-order connectivity for fine-grained optimization, while avoiding the noisy or uninformative feedback common in naive reward designs. Leveraging policy gradient optimization, ReFiT maximizes exact log-likelihood of observed interactions, thereby enabling effective post hoc fine-tuning of diffusion recommenders. Comprehensive experiments on wide-ranging real-world datasets demonstrate that the proposed ReFiT framework (a) exhibits substantial performance gains over strong competitors (up to 36.3% on sequential recommendation), (b) demonstrates strong efficiency with linear complexity in the number of users or items, and (c) generalizes well across multiple diffusion-based recommendation scenarios. The source code and datasets are publicly available at https://anonymous.4open.science/r/ReFiT-4C60.
Learning to reason about rare diseases through retrieval-augmented agents
Nov 06, 2025Rare diseases represent the long tail of medical imaging, where AI models often fail due to the scarcity of representative training data. In clinical workflows, radiologists frequently consult case reports and literature when confronted with unfamiliar findings. Following this line of reasoning, we introduce RADAR, Retrieval Augmented Diagnostic Reasoning Agents, an agentic system for rare disease detection in brain MRI. Our approach uses AI agents with access to external medical knowledge by embedding both case reports and literature using sentence transformers and indexing them with FAISS to enable efficient similarity search. The agent retrieves clinically relevant evidence to guide diagnostic decision making on unseen diseases, without the need of additional training. Designed as a model-agnostic reasoning module, RADAR can be seamlessly integrated with diverse large language models, consistently improving their rare pathology recognition and interpretability. On the NOVA dataset comprising 280 distinct rare diseases, RADAR achieves up to a 10.2% performance gain, with the strongest improvements observed for open source models such as DeepSeek. Beyond accuracy, the retrieved examples provide interpretable, literature grounded explanations, highlighting retrieval-augmented reasoning as a powerful paradigm for low-prevalence conditions in medical imaging.
MVFormer: Diversifying Feature Normalization and Token Mixing for Efficient Vision Transformers
Nov 28, 2024



Active research is currently underway to enhance the efficiency of vision transformers (ViTs). Most studies have focused solely on effective token mixers, overlooking the potential relationship with normalization. To boost diverse feature learning, we propose two components: a normalization module called multi-view normalization (MVN) and a token mixer called multi-view token mixer (MVTM). The MVN integrates three differently normalized features via batch, layer, and instance normalization using a learnable weighted sum. Each normalization method outputs a different distribution, generating distinct features. Thus, the MVN is expected to offer diverse pattern information to the token mixer, resulting in beneficial synergy. The MVTM is a convolution-based multiscale token mixer with local, intermediate, and global filters, and it incorporates stage specificity by configuring various receptive fields for the token mixer at each stage, efficiently capturing ranges of visual patterns. We propose a novel ViT model, multi-vision transformer (MVFormer), adopting the MVN and MVTM in the MetaFormer block, the generalized ViT scheme. Our MVFormer outperforms state-of-the-art convolution-based ViTs on image classification, object detection, and instance and semantic segmentation with the same or lower parameters and MACs. Particularly, MVFormer variants, MVFormer-T, S, and B achieve 83.4%, 84.3%, and 84.6% top-1 accuracy, respectively, on ImageNet-1K benchmark.
DiffSLT: Enhancing Diversity in Sign Language Translation via Diffusion Model
Nov 26, 2024



Sign language translation (SLT) is challenging, as it involves converting sign language videos into natural language. Previous studies have prioritized accuracy over diversity. However, diversity is crucial for handling lexical and syntactic ambiguities in machine translation, suggesting it could similarly benefit SLT. In this work, we propose DiffSLT, a novel gloss-free SLT framework that leverages a diffusion model, enabling diverse translations while preserving sign language semantics. DiffSLT transforms random noise into the target latent representation, conditioned on the visual features of input video. To enhance visual conditioning, we design Guidance Fusion Module, which fully utilizes the multi-level spatiotemporal information of the visual features. We also introduce DiffSLT-P, a DiffSLT variant that conditions on pseudo-glosses and visual features, providing key textual guidance and reducing the modality gap. As a result, DiffSLT and DiffSLT-P significantly improve diversity over previous gloss-free SLT methods and achieve state-of-the-art performance on two SLT datasets, thereby markedly improving translation quality.
Three Cars Approaching within 100m! Enhancing Distant Geometry by Tri-Axis Voxel Scanning for Camera-based Semantic Scene Completion
Nov 25, 2024Camera-based Semantic Scene Completion (SSC) is gaining attentions in the 3D perception field. However, properties such as perspective and occlusion lead to the underestimation of the geometry in distant regions, posing a critical issue for safety-focused autonomous driving systems. To tackle this, we propose ScanSSC, a novel camera-based SSC model composed of a Scan Module and Scan Loss, both designed to enhance distant scenes by leveraging context from near-viewpoint scenes. The Scan Module uses axis-wise masked attention, where each axis employing a near-to-far cascade masking that enables distant voxels to capture relationships with preceding voxels. In addition, the Scan Loss computes the cross-entropy along each axis between cumulative logits and corresponding class distributions in a near-to-far direction, thereby propagating rich context-aware signals to distant voxels. Leveraging the synergy between these components, ScanSSC achieves state-of-the-art performance, with IoUs of 44.54 and 48.29, and mIoUs of 17.40 and 20.14 on the SemanticKITTI and SSCBench-KITTI-360 benchmarks.
Leveraging the Power of MLLMs for Gloss-Free Sign Language Translation
Nov 25, 2024Sign language translation (SLT) is a challenging task that involves translating sign language images into spoken language. For SLT models to perform this task successfully, they must bridge the modality gap and identify subtle variations in sign language components to understand their meanings accurately. To address these challenges, we propose a novel gloss-free SLT framework called Multimodal Sign Language Translation (MMSLT), which leverages the representational capabilities of off-the-shelf multimodal large language models (MLLMs). Specifically, we generate detailed textual descriptions of sign language components using MLLMs. Then, through our proposed multimodal-language pre-training module, we integrate these description features with sign video features to align them within the spoken sentence space. Our approach achieves state-of-the-art performance on benchmark datasets PHOENIX14T and CSL-Daily, highlighting the potential of MLLMs to be effectively utilized in SLT.
TiVaT: Joint-Axis Attention for Time Series Forecasting with Lead-Lag Dynamics
Oct 02, 2024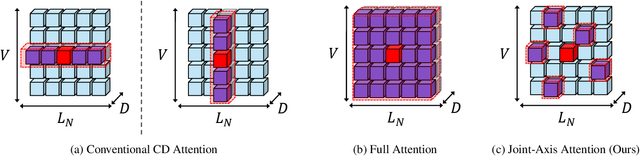



Multivariate time series (MTS) forecasting plays a crucial role in various real-world applications, yet simultaneously capturing both temporal and inter-variable dependencies remains a challenge. Conventional Channel-Dependent (CD) models handle these dependencies separately, limiting their ability to model complex interactions such as lead-lag dynamics. To address these limitations, we propose TiVaT (Time-Variable Transformer), a novel architecture that integrates temporal and variate dependencies through its Joint-Axis (JA) attention mechanism. TiVaT's ability to capture intricate variate-temporal dependencies, including asynchronous interactions, is further enhanced by the incorporation of Distance-aware Time-Variable (DTV) Sampling, which reduces noise and improves accuracy through a learned 2D map that focuses on key interactions. TiVaT effectively models both temporal and variate dependencies, consistently delivering strong performance across diverse datasets. Notably, it excels in capturing complex patterns within multivariate time series, enabling it to surpass or remain competitive with state-of-the-art methods. This positions TiVaT as a new benchmark in MTS forecasting, particularly in handling datasets characterized by intricate and challenging dependencies.
On Initializing Transformers with Pre-trained Embeddings
Jul 17, 2024



It has become common practice now to use random initialization schemes, rather than the pre-trained embeddings, when training transformer based models from scratch. Indeed, we find that pre-trained word embeddings from GloVe, and some sub-word embeddings extracted from language models such as T5 and mT5 fare much worse compared to random initialization. This is counter-intuitive given the well-known representational and transfer-learning advantages of pre-training. Interestingly, we also find that BERT and mBERT embeddings fare better than random initialization, showing the advantages of pre-trained representations. In this work, we posit two potential factors that contribute to these mixed results: the model sensitivity to parameter distribution and the embedding interactions with position encodings. We observe that pre-trained GloVe, T5, and mT5 embeddings have a wider distribution of values. As argued in the initialization studies, such large value initializations can lead to poor training because of saturated outputs. Further, the larger embedding values can, in effect, absorb the smaller position encoding values when added together, thus losing position information. Standardizing the pre-trained embeddings to a narrow range (e.g. as prescribed by Xavier) leads to substantial gains for Glove, T5, and mT5 embeddings. On the other hand, BERT pre-trained embeddings, while larger, are still relatively closer to Xavier initialization range which may allow it to effectively transfer the pre-trained knowledge.
On the Localization of Ultrasound Image Slices within Point Distribution Models
Sep 01, 2023Thyroid disorders are most commonly diagnosed using high-resolution Ultrasound (US). Longitudinal nodule tracking is a pivotal diagnostic protocol for monitoring changes in pathological thyroid morphology. This task, however, imposes a substantial cognitive load on clinicians due to the inherent challenge of maintaining a mental 3D reconstruction of the organ. We thus present a framework for automated US image slice localization within a 3D shape representation to ease how such sonographic diagnoses are carried out. Our proposed method learns a common latent embedding space between US image patches and the 3D surface of an individual's thyroid shape, or a statistical aggregation in the form of a statistical shape model (SSM), via contrastive metric learning. Using cross-modality registration and Procrustes analysis, we leverage features from our model to register US slices to a 3D mesh representation of the thyroid shape. We demonstrate that our multi-modal registration framework can localize images on the 3D surface topology of a patient-specific organ and the mean shape of an SSM. Experimental results indicate slice positions can be predicted within an average of 1.2 mm of the ground-truth slice location on the patient-specific 3D anatomy and 4.6 mm on the SSM, exemplifying its usefulness for slice localization during sonographic acquisitions. Code is publically available: \href{https://github.com/vuenc/slice-to-shape}{https://github.com/vuenc/slice-to-shape}