 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
On the Fly Neural Style Smoothing for Risk-Averse Domain Generalization
Jul 17, 2023
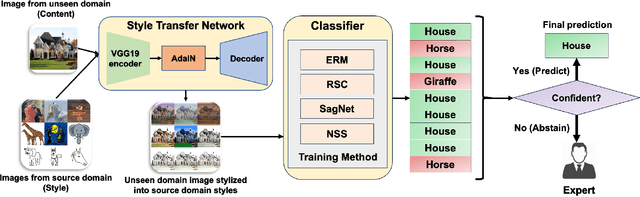
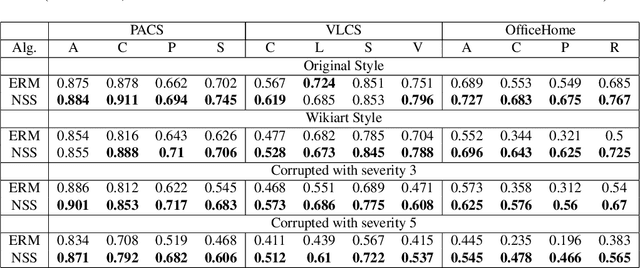
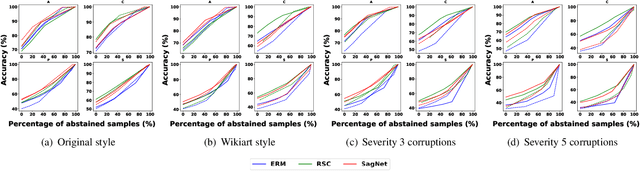
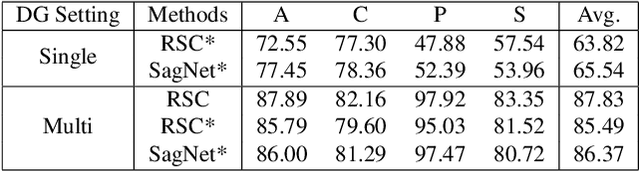
Achieving high accuracy on data from domains unseen during training is a fundamental challenge in domain generalization (DG). While state-of-the-art DG classifiers have demonstrated impressive performance across various tasks, they have shown a bias towards domain-dependent information, such as image styles, rather than domain-invariant information, such as image content. This bias renders them unreliable for deployment in risk-sensitive scenarios such as autonomous driving where a misclassification could lead to catastrophic consequences. To enable risk-averse predictions from a DG classifier, we propose a novel inference procedure, Test-Time Neural Style Smoothing (TT-NSS), that uses a "style-smoothed" version of the DG classifier for prediction at test time. Specifically, the style-smoothed classifier classifies a test image as the most probable class predicted by the DG classifier on random re-stylizations of the test image. TT-NSS uses a neural style transfer module to stylize a test image on the fly, requires only black-box access to the DG classifier, and crucially, abstains when predictions of the DG classifier on the stylized test images lack consensus. Additionally, we propose a neural style smoothing (NSS) based training procedure that can be seamlessly integrated with existing DG methods. This procedure enhances prediction consistency, improving the performance of TT-NSS on non-abstained samples. Our empirical results demonstrate the effectiveness of TT-NSS and NSS at producing and improving risk-averse predictions on unseen domains from DG classifiers trained with SOTA training methods on various benchmark datasets and their variations.
Information-theoretic Analysis of Test Data Sensitivity in Uncertainty
Jul 23, 2023Bayesian inference is often utilized for uncertainty quantification tasks. A recent analysis by Xu and Raginsky 2022 rigorously decomposed the predictive uncertainty in Bayesian inference into two uncertainties, called aleatoric and epistemic uncertainties, which represent the inherent randomness in the data-generating process and the variability due to insufficient data, respectively. They analyzed those uncertainties in an information-theoretic way, assuming that the model is well-specified and treating the model's parameters as latent variables. However, the existing information-theoretic analysis of uncertainty cannot explain the widely believed property of uncertainty, known as the sensitivity between the test and training data. It implies that when test data are similar to training data in some sense, the epistemic uncertainty should become small. In this work, we study such uncertainty sensitivity using our novel decomposition method for the predictive uncertainty. Our analysis successfully defines such sensitivity using information-theoretic quantities. Furthermore, we extend the existing analysis of Bayesian meta-learning and show the novel sensitivities among tasks for the first time.
Quadrupedal Footstep Planning using Learned Motion Models of a Black-Box Controller
Jul 23, 2023
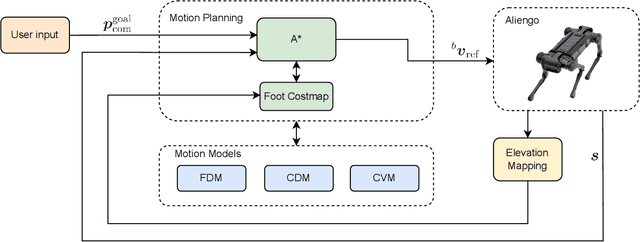
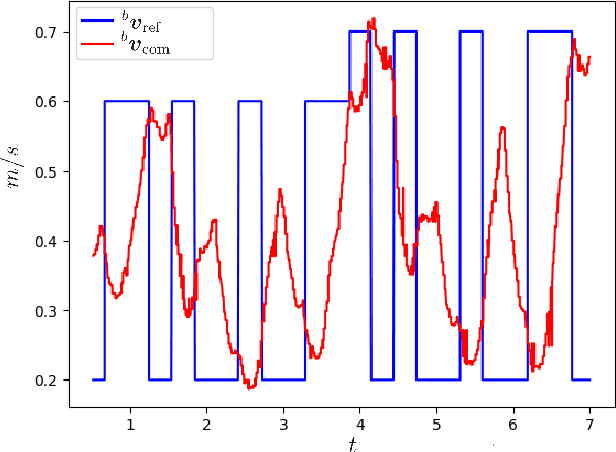

Legged robots are increasingly entering new domains and applications, including search and rescue, inspection, and logistics. However, for such systems to be valuable in real-world scenarios, they must be able to autonomously and robustly navigate irregular terrains. In many cases, robots that are sold on the market do not provide such abilities, being able to perform only blind locomotion. Furthermore, their controller cannot be easily modified by the end-user, requiring a new and time-consuming control synthesis. In this work, we present a fast local motion planning pipeline that extends the capabilities of a black-box walking controller that is only able to track high-level reference velocities. More precisely, we learn a set of motion models for such a controller that maps high-level velocity commands to Center of Mass (CoM) and footstep motions. We then integrate these models with a variant of the A star algorithm to plan the CoM trajectory, footstep sequences, and corresponding high-level velocity commands based on visual information, allowing the quadruped to safely traverse irregular terrains at demand.
Graphs in State-Space Models for Granger Causality in Climate Science
Jul 20, 2023
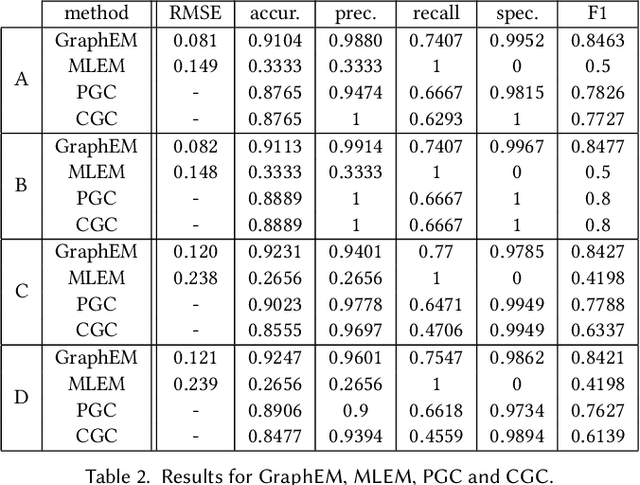

Granger causality (GC) is often considered not an actual form of causality. Still, it is arguably the most widely used method to assess the predictability of a time series from another one. Granger causality has been widely used in many applied disciplines, from neuroscience and econometrics to Earth sciences. We revisit GC under a graphical perspective of state-space models. For that, we use GraphEM, a recently presented expectation-maximisation algorithm for estimating the linear matrix operator in the state equation of a linear-Gaussian state-space model. Lasso regularisation is included in the M-step, which is solved using a proximal splitting Douglas-Rachford algorithm. Experiments in toy examples and challenging climate problems illustrate the benefits of the proposed model and inference technique over standard Granger causality methods.
Beyond Black-Box Advice: Learning-Augmented Algorithms for MDPs with Q-Value Predictions
Jul 20, 2023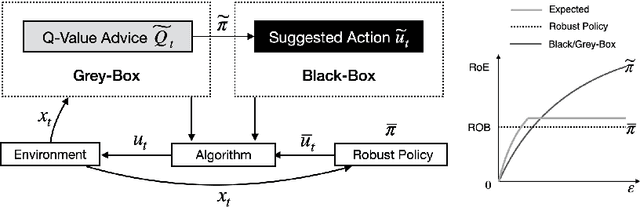


We study the tradeoff between consistency and robustness in the context of a single-trajectory time-varying Markov Decision Process (MDP) with untrusted machine-learned advice. Our work departs from the typical approach of treating advice as coming from black-box sources by instead considering a setting where additional information about how the advice is generated is available. We prove a first-of-its-kind consistency and robustness tradeoff given Q-value advice under a general MDP model that includes both continuous and discrete state/action spaces. Our results highlight that utilizing Q-value advice enables dynamic pursuit of the better of machine-learned advice and a robust baseline, thus result in near-optimal performance guarantees, which provably improves what can be obtained solely with black-box advice.
Ensemble Learning for CME Arrival Time Prediction
Apr 29, 2023
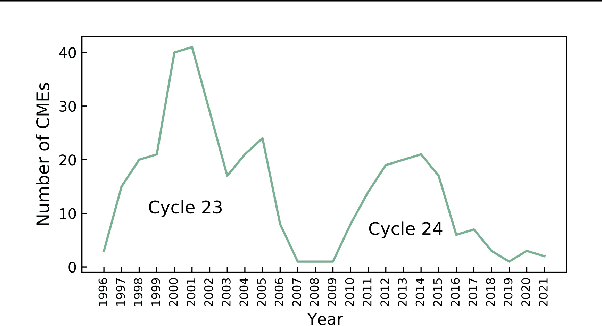
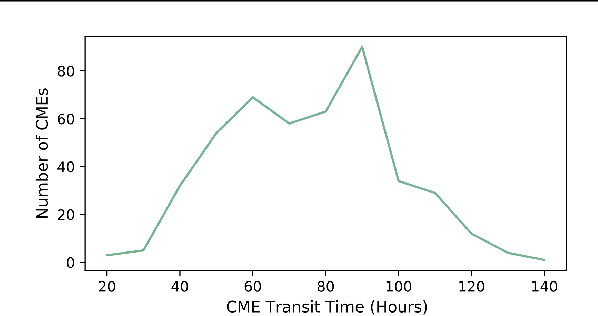
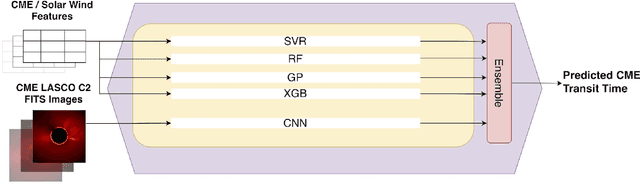
The Sun constantly releases radiation and plasma into the heliosphere. Sporadically, the Sun launches solar eruptions such as flares and coronal mass ejections (CMEs). CMEs carry away a huge amount of mass and magnetic flux with them. An Earth-directed CME can cause serious consequences to the human system. It can destroy power grids/pipelines, satellites, and communications. Therefore, accurately monitoring and predicting CMEs is important to minimize damages to the human system. In this study we propose an ensemble learning approach, named CMETNet, for predicting the arrival time of CMEs from the Sun to the Earth. We collect and integrate eruptive events from two solar cycles, #23 and #24, from 1996 to 2021 with a total of 363 geoeffective CMEs. The data used for making predictions include CME features, solar wind parameters and CME images obtained from the SOHO/LASCO C2 coronagraph. Our ensemble learning framework comprises regression algorithms for numerical data analysis and a convolutional neural network for image processing. Experimental results show that CMETNet performs better than existing machine learning methods reported in the literature, with a Pearson product-moment correlation coefficient of 0.83 and a mean absolute error of 9.75 hours.
Theoretically Guaranteed Policy Improvement Distilled from Model-Based Planning
Jul 24, 2023Model-based reinforcement learning (RL) has demonstrated remarkable successes on a range of continuous control tasks due to its high sample efficiency. To save the computation cost of conducting planning online, recent practices tend to distill optimized action sequences into an RL policy during the training phase. Although the distillation can incorporate both the foresight of planning and the exploration ability of RL policies, the theoretical understanding of these methods is yet unclear. In this paper, we extend the policy improvement step of Soft Actor-Critic (SAC) by developing an approach to distill from model-based planning to the policy. We then demonstrate that such an approach of policy improvement has a theoretical guarantee of monotonic improvement and convergence to the maximum value defined in SAC. We discuss effective design choices and implement our theory as a practical algorithm -- Model-based Planning Distilled to Policy (MPDP) -- that updates the policy jointly over multiple future time steps. Extensive experiments show that MPDP achieves better sample efficiency and asymptotic performance than both model-free and model-based planning algorithms on six continuous control benchmark tasks in MuJoCo.
SS-shapelets: Semi-supervised Clustering of Time Series Using Representative Shapelets
Apr 06, 2023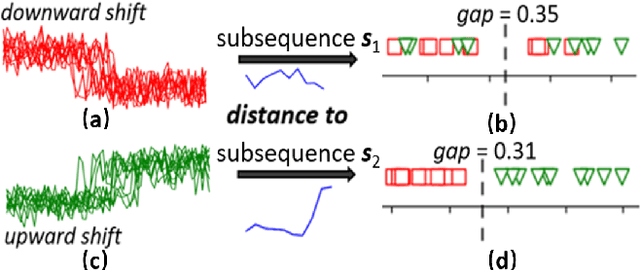
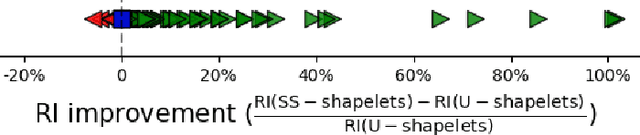
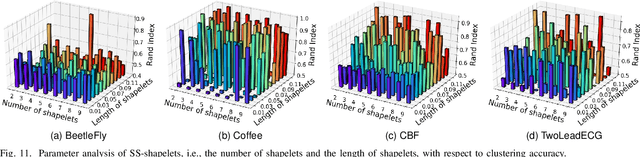
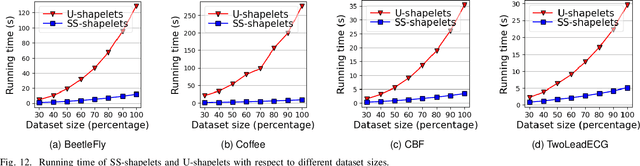
Shapelets that discriminate time series using local features (subsequences) are promising for time series clustering. Existing time series clustering methods may fail to capture representative shapelets because they discover shapelets from a large pool of uninformative subsequences, and thus result in low clustering accuracy. This paper proposes a Semi-supervised Clustering of Time Series Using Representative Shapelets (SS-Shapelets) method, which utilizes a small number of labeled and propagated pseudo-labeled time series to help discover representative shapelets, thereby improving the clustering accuracy. In SS-Shapelets, we propose two techniques to discover representative shapelets for the effective clustering of time series. 1) A \textit{salient subsequence chain} ($SSC$) that can extract salient subsequences (as candidate shapelets) of a labeled/pseudo-labeled time series, which helps remove massive uninformative subsequences from the pool. 2) A \textit{linear discriminant selection} ($LDS$) algorithm to identify shapelets that can capture representative local features of time series in different classes, for convenient clustering. Experiments on UCR time series datasets demonstrate that SS-shapelets discovers representative shapelets and achieves higher clustering accuracy than counterpart semi-supervised time series clustering methods.
Train/Test-Time Adaptation with Retrieval
Mar 25, 2023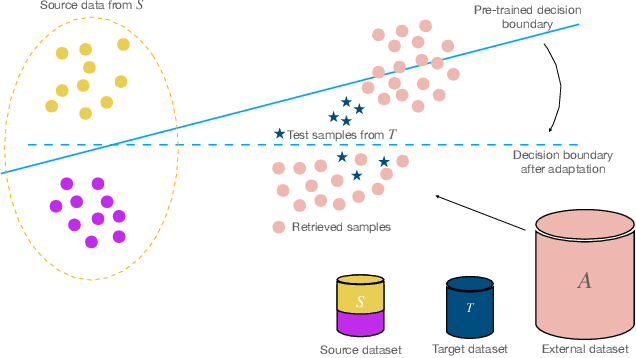
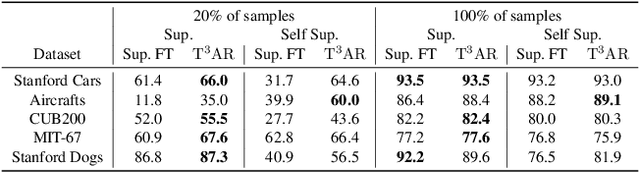
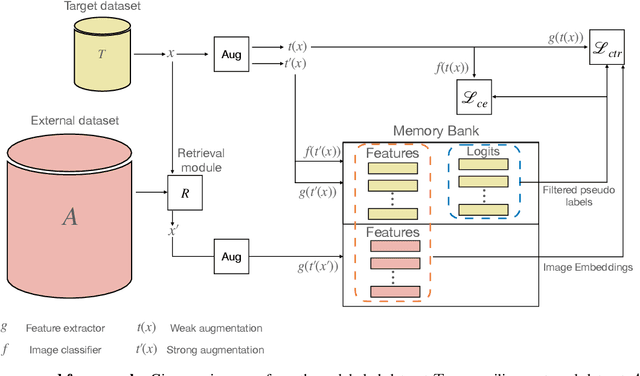
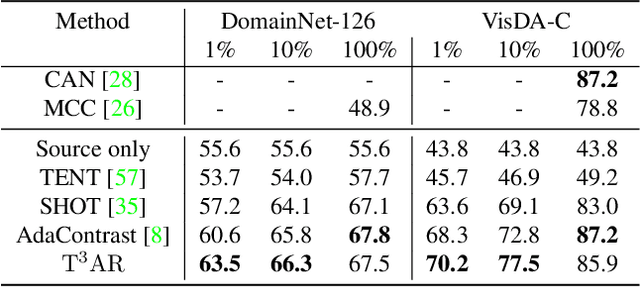
We introduce Train/Test-Time Adaptation with Retrieval (${\rm T^3AR}$), a method to adapt models both at train and test time by means of a retrieval module and a searchable pool of external samples. Before inference, ${\rm T^3AR}$ adapts a given model to the downstream task using refined pseudo-labels and a self-supervised contrastive objective function whose noise distribution leverages retrieved real samples to improve feature adaptation on the target data manifold. The retrieval of real images is key to ${\rm T^3AR}$ since it does not rely solely on synthetic data augmentations to compensate for the lack of adaptation data, as typically done by other adaptation algorithms. Furthermore, thanks to the retrieval module, our method gives the user or service provider the possibility to improve model adaptation on the downstream task by incorporating further relevant data or to fully remove samples that may no longer be available due to changes in user preference after deployment. First, we show that ${\rm T^3AR}$ can be used at training time to improve downstream fine-grained classification over standard fine-tuning baselines, and the fewer the adaptation data the higher the relative improvement (up to 13%). Second, we apply ${\rm T^3AR}$ for test-time adaptation and show that exploiting a pool of external images at test-time leads to more robust representations over existing methods on DomainNet-126 and VISDA-C, especially when few adaptation data are available (up to 8%).
Beyond Intuition, a Framework for Applying GPs to Real-World Data
Jul 17, 2023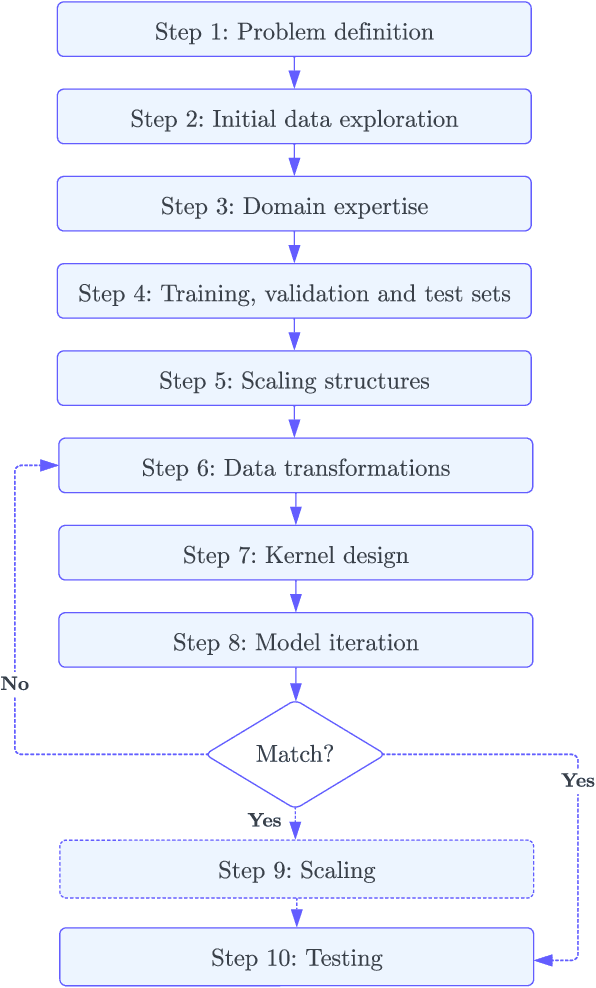
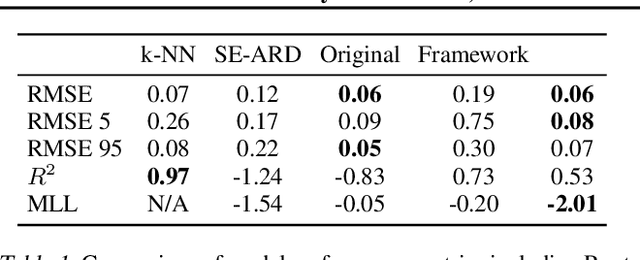
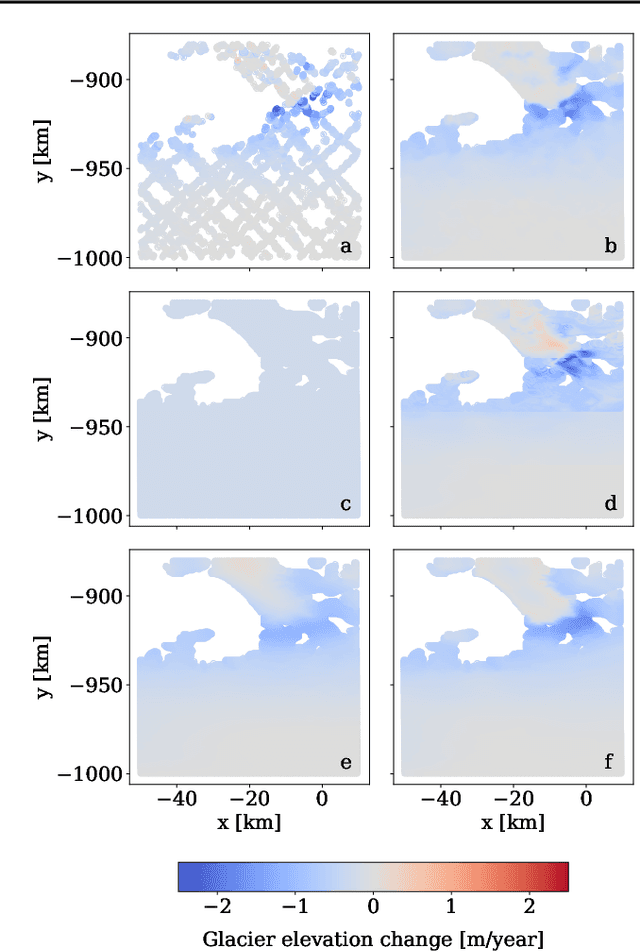
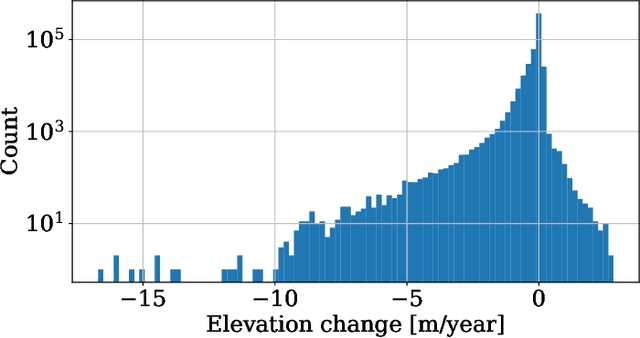
Gaussian Processes (GPs) offer an attractive method for regression over small, structured and correlated datasets. However, their deployment is hindered by computational costs and limited guidelines on how to apply GPs beyond simple low-dimensional datasets. We propose a framework to identify the suitability of GPs to a given problem and how to set up a robust and well-specified GP model. The guidelines formalise the decisions of experienced GP practitioners, with an emphasis on kernel design and options for computational scalability. The framework is then applied to a case study of glacier elevation change yielding more accurate results at test time.