 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Tracking-Assisted Object Detection with Event Cameras
Mar 27, 2024
Event-based object detection has recently garnered attention in the computer vision community due to the exceptional properties of event cameras, such as high dynamic range and no motion blur. However, feature asynchronism and sparsity cause invisible objects due to no relative motion to the camera, posing a significant challenge in the task. Prior works have studied various memory mechanisms to preserve as many features as possible at the current time, guided by temporal clues. While these implicit-learned memories retain some short-term information, they still struggle to preserve long-term features effectively. In this paper, we consider those invisible objects as pseudo-occluded objects and aim to reveal their features. Firstly, we introduce visibility attribute of objects and contribute an auto-labeling algorithm to append additional visibility labels on an existing event camera dataset. Secondly, we exploit tracking strategies for pseudo-occluded objects to maintain their permanence and retain their bounding boxes, even when features have not been available for a very long time. These strategies can be treated as an explicit-learned memory guided by the tracking objective to record the displacements of objects across frames. Lastly, we propose a spatio-temporal feature aggregation module to enrich the latent features and a consistency loss to increase the robustness of the overall pipeline. We conduct comprehensive experiments to verify our method's effectiveness where still objects are retained but real occluded objects are discarded. The results demonstrate that (1) the additional visibility labels can assist in supervised training, and (2) our method outperforms state-of-the-art approaches with a significant improvement of 7.9% absolute mAP.
Beyond Suspension: A Two-phase Methodology for Concluding Sports Leagues
Mar 29, 2024Problem definition: Professional sports leagues may be suspended due to various reasons such as the recent COVID-19 pandemic. A critical question the league must address when re-opening is how to appropriately select a subset of the remaining games to conclude the season in a shortened time frame. Academic/practical relevance: Despite the rich literature on scheduling an entire season starting from a blank slate, concluding an existing season is quite different. Our approach attempts to achieve team rankings similar to that which would have resulted had the season been played out in full. Methodology: We propose a data-driven model which exploits predictive and prescriptive analytics to produce a schedule for the remainder of the season comprised of a subset of originally-scheduled games. Our model introduces novel rankings-based objectives within a stochastic optimization model, whose parameters are first estimated using a predictive model. We introduce a deterministic equivalent reformulation along with a tailored Frank-Wolfe algorithm to efficiently solve our problem, as well as a robust counterpart based on min-max regret. Results: We present simulation-based numerical experiments from previous National Basketball Association (NBA) seasons 2004--2019, and show that our models are computationally efficient, outperform a greedy benchmark that approximates a non-rankings-based scheduling policy, and produce interpretable results. Managerial implications: Our data-driven decision-making framework may be used to produce a shortened season with 25-50\% fewer games while still producing an end-of-season ranking similar to that of the full season, had it been played.
Efficient and Sharp Off-Policy Evaluation in Robust Markov Decision Processes
Mar 29, 2024We study evaluating a policy under best- and worst-case perturbations to a Markov decision process (MDP), given transition observations from the original MDP, whether under the same or different policy. This is an important problem when there is the possibility of a shift between historical and future environments, due to e.g. unmeasured confounding, distributional shift, or an adversarial environment. We propose a perturbation model that can modify transition kernel densities up to a given multiplicative factor or its reciprocal, which extends the classic marginal sensitivity model (MSM) for single time step decision making to infinite-horizon RL. We characterize the sharp bounds on policy value under this model, that is, the tightest possible bounds given by the transition observations from the original MDP, and we study the estimation of these bounds from such transition observations. We develop an estimator with several appealing guarantees: it is semiparametrically efficient, and remains so even when certain necessary nuisance functions such as worst-case Q-functions are estimated at slow nonparametric rates. It is also asymptotically normal, enabling easy statistical inference using Wald confidence intervals. In addition, when certain nuisances are estimated inconsistently we still estimate a valid, albeit possibly not sharp bounds on the policy value. We validate these properties in numeric simulations. The combination of accounting for environment shifts from train to test (robustness), being insensitive to nuisance-function estimation (orthogonality), and accounting for having only finite samples to learn from (inference) together leads to credible and reliable policy evaluation.
Shallow Cross-Encoders for Low-Latency Retrieval
Mar 29, 2024Transformer-based Cross-Encoders achieve state-of-the-art effectiveness in text retrieval. However, Cross-Encoders based on large transformer models (such as BERT or T5) are computationally expensive and allow for scoring only a small number of documents within a reasonably small latency window. However, keeping search latencies low is important for user satisfaction and energy usage. In this paper, we show that weaker shallow transformer models (i.e., transformers with a limited number of layers) actually perform better than full-scale models when constrained to these practical low-latency settings since they can estimate the relevance of more documents in the same time budget. We further show that shallow transformers may benefit from the generalized Binary Cross-Entropy (gBCE) training scheme, which has recently demonstrated success for recommendation tasks. Our experiments with TREC Deep Learning passage ranking query sets demonstrate significant improvements in shallow and full-scale models in low-latency scenarios. For example, when the latency limit is 25ms per query, MonoBERT-Large (a cross-encoder based on a full-scale BERT model) is only able to achieve NDCG@10 of 0.431 on TREC DL 2019, while TinyBERT-gBCE (a cross-encoder based on TinyBERT trained with gBCE) reaches NDCG@10 of 0.652, a +51% gain over MonoBERT-Large. We also show that shallow Cross-Encoders are effective even when used without a GPU (e.g., with CPU inference, NDCG@10 decreases only by 3% compared to GPU inference with 50ms latency), which makes Cross-Encoders practical to run even without specialized hardware acceleration.
A Peg-in-hole Task Strategy for Holes in Concrete
Mar 29, 2024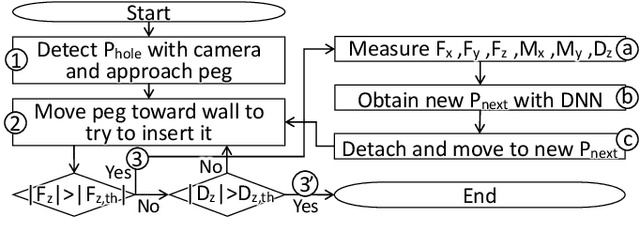
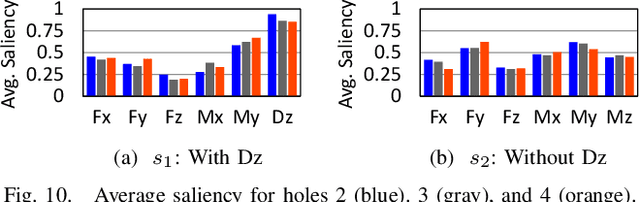
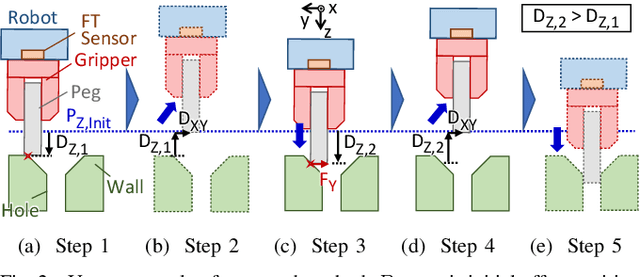
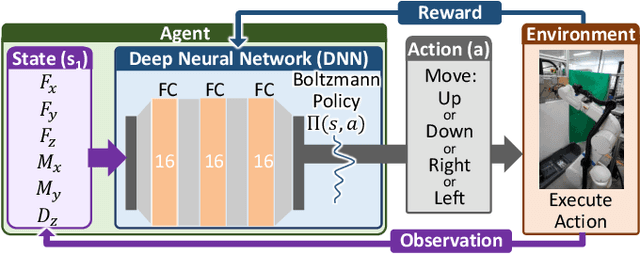
A method that enables an industrial robot to accomplish the peg-in-hole task for holes in concrete is proposed. The proposed method involves slightly detaching the peg from the wall, when moving between search positions, to avoid the negative influence of the concrete's high friction coefficient. It uses a deep neural network (DNN), trained via reinforcement learning, to effectively find holes with variable shape and surface finish (due to the brittle nature of concrete) without analytical modeling or control parameter tuning. The method uses displacement of the peg toward the wall surface, in addition to force and torque, as one of the inputs of the DNN. Since the displacement increases as the peg gets closer to the hole (due to the chamfered shape of holes in concrete), it is a useful parameter for inputting in the DNN. The proposed method was evaluated by training the DNN on a hole 500 times and attempting to find 12 unknown holes. The results of the evaluation show the DNN enabled a robot to find the unknown holes with average success rate of 96.1% and average execution time of 12.5 seconds. Additional evaluations with random initial positions and a different type of peg demonstrate the trained DNN can generalize well to different conditions. Analyses of the influence of the peg displacement input showed the success rate of the DNN is increased by utilizing this parameter. These results validate the proposed method in terms of its effectiveness and applicability to the construction industry.
* Published in 2021 IEEE International Conference on Robotics and Automation (ICRA) on 30 May 2021
V2X Enabled Emergency Vehicle Alert System
Mar 28, 2024
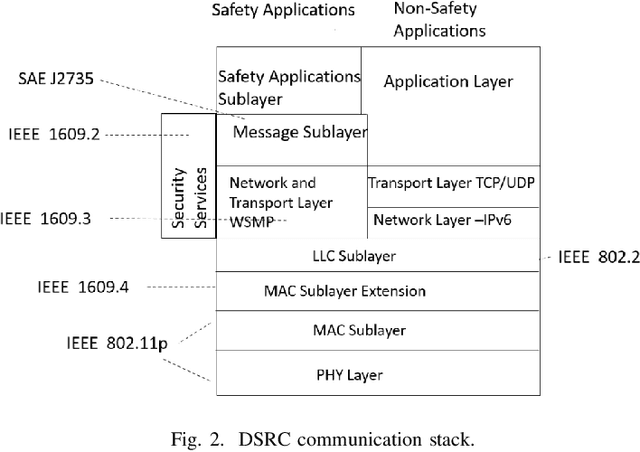


Today's major concern in traffic management systems includes time-efficient emergency transports. The awareness of environment and vehicle information is necessary for the emergency vehicles as well as the surrounding commercial vehicles that might be driven by inexperienced drivers to act accordingly if they both interact. The information exchange should be quick and accurate along with how much interactive the alerting system is with the drivers. Therefore, technologies like V2X-based alert systems can deal with such emergency situations and hence prevent potential health or social hazards. An alerting system as a part of a smart-connected city is proposed in this paper. The Dedicated Short Range Communication (DSRC) based system has tried to cover the major domain of information about misbehaving vehicles, any pedestrians on the road, and information about the emergency vehicle itself. The commercial vehicle also will have a similar alert system as an application of V2V and V2I. Further in this paper, a realtime monitoring system was developed using grafana dashboard which will be installed in the area's base station to monitor the vehicles in that area.
SpikingResformer: Bridging ResNet and Vision Transformer in Spiking Neural Networks
Mar 28, 2024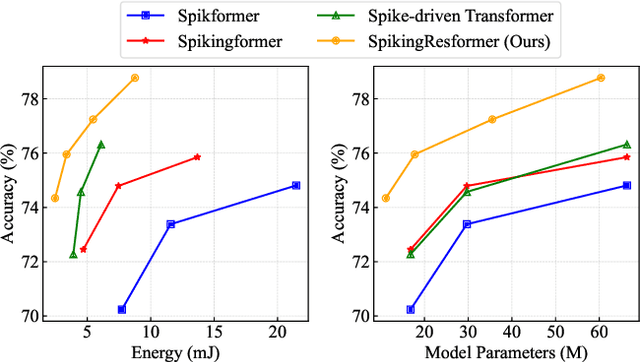

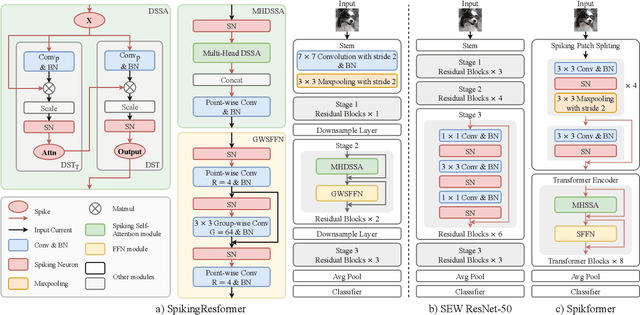
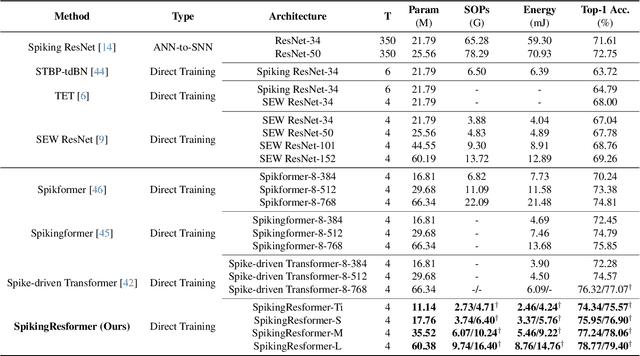
The remarkable success of Vision Transformers in Artificial Neural Networks (ANNs) has led to a growing interest in incorporating the self-attention mechanism and transformer-based architecture into Spiking Neural Networks (SNNs). While existing methods propose spiking self-attention mechanisms that are compatible with SNNs, they lack reasonable scaling methods, and the overall architectures proposed by these methods suffer from a bottleneck in effectively extracting local features. To address these challenges, we propose a novel spiking self-attention mechanism named Dual Spike Self-Attention (DSSA) with a reasonable scaling method. Based on DSSA, we propose a novel spiking Vision Transformer architecture called SpikingResformer, which combines the ResNet-based multi-stage architecture with our proposed DSSA to improve both performance and energy efficiency while reducing parameters. Experimental results show that SpikingResformer achieves higher accuracy with fewer parameters and lower energy consumption than other spiking Vision Transformer counterparts. Notably, our SpikingResformer-L achieves 79.40% top-1 accuracy on ImageNet with 4 time-steps, which is the state-of-the-art result in the SNN field.
Enhancing Research Information Systems with Identification of Domain Experts
Mar 28, 2024Research organisations and their research outputs have been growing considerably in the past decades. This large body of knowledge attracts various stakeholders, e.g., for knowledge sharing, technology transfer, or potential collaborations. However, due to the large amount of complex knowledge created, traditional methods of manually curating catalogues are often out of time, imprecise, and cumbersome. Finding domain experts and knowledge within any larger organisation, scientific and also industrial, has thus become a serious challenge. Hence, exploring an institutions domain knowledge and finding its experts can only be solved by an automated solution. This work presents the scheme of an automated approach for identifying scholarly experts based on their publications and, prospectively, their teaching materials. Based on a search engine, this approach is currently being implemented for two universities, for which some examples are presented. The proposed system will be helpful for finding peer researchers as well as starting points for knowledge exploitation and technology transfer. As the system is designed in a scalable manner, it can easily include additional institutions and hence provide a broader coverage of research facilities in the future.
Retrieval-Enhanced Knowledge Editing for Multi-Hop Question Answering in Language Models
Mar 28, 2024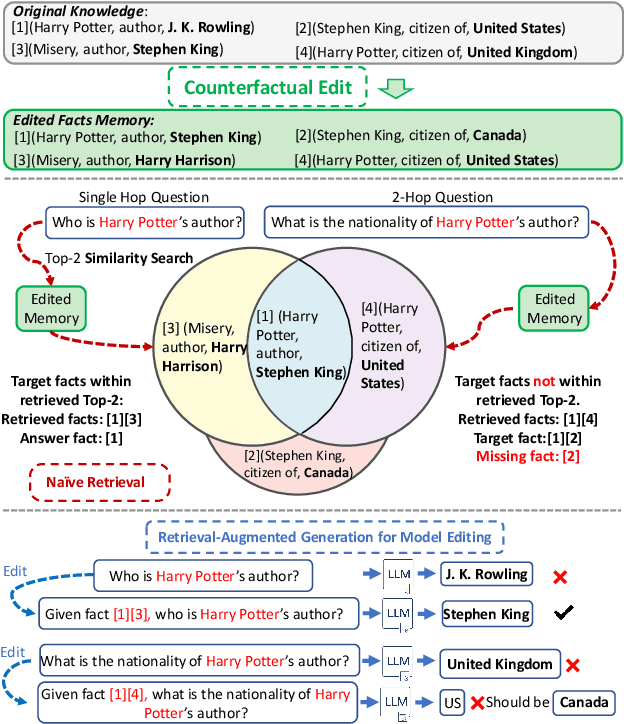

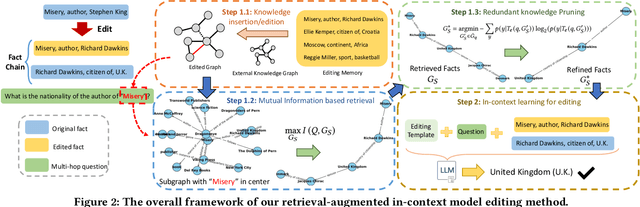
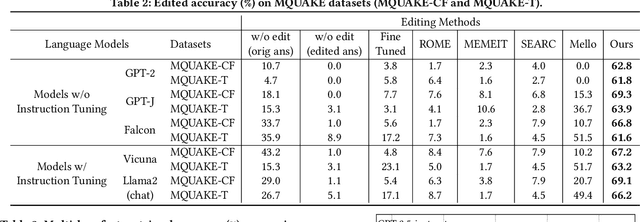
Large Language Models (LLMs) have shown proficiency in question-answering tasks but often struggle to integrate real-time knowledge updates, leading to potentially outdated or inaccurate responses. This problem becomes even more challenging when dealing with multi-hop questions since they require LLMs to update and integrate multiple knowledge pieces relevant to the questions. To tackle the problem, we propose the Retrieval-Augmented model Editing (RAE) framework tailored for multi-hop question answering. RAE first retrieves edited facts and then refines the language model through in-context learning. Specifically, our retrieval approach, based on mutual information maximization, leverages the reasoning abilities of LLMs to identify chain facts that na\"ive similarity-based searches might miss. Additionally, our framework incorporates a pruning strategy to eliminate redundant information from the retrieved facts, which enhances the editing accuracy and mitigates the hallucination problem. Our framework is supported by theoretical justification for its fact retrieval efficacy. Finally, comprehensive evaluation across various LLMs validates RAE's ability in providing accurate answers with updated knowledge.
A diverse Multilingual News Headlines Dataset from around the World
Mar 28, 2024Babel Briefings is a novel dataset featuring 4.7 million news headlines from August 2020 to November 2021, across 30 languages and 54 locations worldwide with English translations of all articles included. Designed for natural language processing and media studies, it serves as a high-quality dataset for training or evaluating language models as well as offering a simple, accessible collection of articles, for example, to analyze global news coverage and cultural narratives. As a simple demonstration of the analyses facilitated by this dataset, we use a basic procedure using a TF-IDF weighted similarity metric to group articles into clusters about the same event. We then visualize the \emph{event signatures} of the event showing articles of which languages appear over time, revealing intuitive features based on the proximity of the event and unexpectedness of the event. The dataset is available on \href{https://www.kaggle.com/datasets/felixludos/babel-briefings}{Kaggle} and \href{https://huggingface.co/datasets/felixludos/babel-briefings}{HuggingFace} with accompanying \href{https://github.com/felixludos/babel-briefings}{GitHub} code.