 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADAPT: Benchmarking Commonsense Planning under Unspecified Affordance Constraints
Apr 16, 2026Intelligent embodied agents should not simply follow instructions, as real-world environments often involve unexpected conditions and exceptions. However, existing methods usually focus on directly executing instructions, without considering whether the target objects can actually be manipulated, meaning they fail to assess available affordances. To address this limitation, we introduce DynAfford, a benchmark that evaluates embodied agents in dynamic environments where object affordances may change over time and are not specified in the instruction. DynAfford requires agents to perceive object states, infer implicit preconditions, and adapt their actions accordingly. To enable this capability, we introduce ADAPT, a plug-and-play module that augments existing planners with explicit affordance reasoning. Experiments demonstrate that incorporating ADAPT significantly improves robustness and task success across both seen and unseen environments. We also show that a domain-adapted, LoRA-finetuned vision-language model used as the affordance inference backend outperforms a commercial LLM (GPT-4o), highlighting the importance of task-aligned affordance grounding.
Tracking-Assisted Object Detection with Event Cameras
Mar 27, 2024



Event-based object detection has recently garnered attention in the computer vision community due to the exceptional properties of event cameras, such as high dynamic range and no motion blur. However, feature asynchronism and sparsity cause invisible objects due to no relative motion to the camera, posing a significant challenge in the task. Prior works have studied various memory mechanisms to preserve as many features as possible at the current time, guided by temporal clues. While these implicit-learned memories retain some short-term information, they still struggle to preserve long-term features effectively. In this paper, we consider those invisible objects as pseudo-occluded objects and aim to reveal their features. Firstly, we introduce visibility attribute of objects and contribute an auto-labeling algorithm to append additional visibility labels on an existing event camera dataset. Secondly, we exploit tracking strategies for pseudo-occluded objects to maintain their permanence and retain their bounding boxes, even when features have not been available for a very long time. These strategies can be treated as an explicit-learned memory guided by the tracking objective to record the displacements of objects across frames. Lastly, we propose a spatio-temporal feature aggregation module to enrich the latent features and a consistency loss to increase the robustness of the overall pipeline. We conduct comprehensive experiments to verify our method's effectiveness where still objects are retained but real occluded objects are discarded. The results demonstrate that (1) the additional visibility labels can assist in supervised training, and (2) our method outperforms state-of-the-art approaches with a significant improvement of 7.9% absolute mAP.
MiniSUPERB: Lightweight Benchmark for Self-supervised Speech Models
May 30, 2023



Self-supervised learning (SSL) is a popular research topic in speech processing. Successful SSL speech models must generalize well. SUPERB was proposed to evaluate the ability of SSL speech models across many speech tasks. However, due to the diversity of tasks, the evaluation process requires huge computational costs. We present MiniSUPERB, a lightweight benchmark that efficiently evaluates SSL speech models with comparable results to SUPERB while greatly reducing the computational cost. We select representative tasks and sample datasets and extract model representation offline, achieving 0.954 and 0.982 Spearman's rank correlation with SUPERB Paper and SUPERB Challenge, respectively. In the meanwhile, the computational cost is reduced by 97% in regard to MACs (number of Multiply-ACcumulate operations) in the tasks we choose. To the best of our knowledge, this is the first study to examine not only the computational cost of a model itself but the cost of evaluating it on a benchmark.
Lung-Originated Tumor Segmentation from Computed Tomography Scan (LOTUS) Benchmark
Jan 03, 2022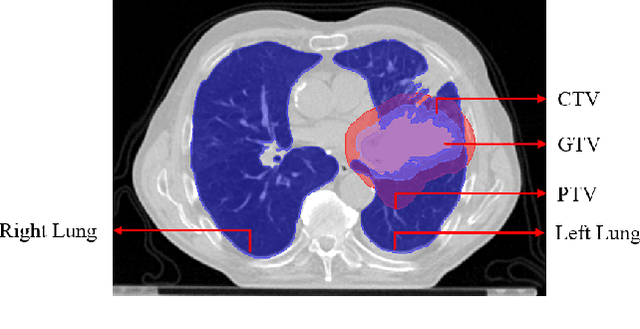
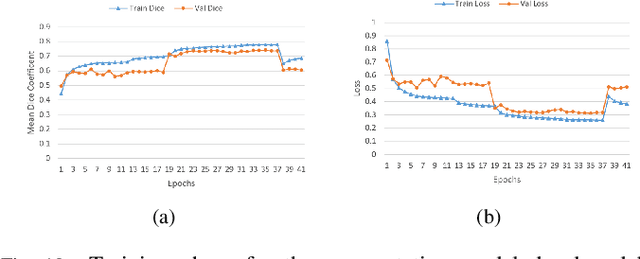
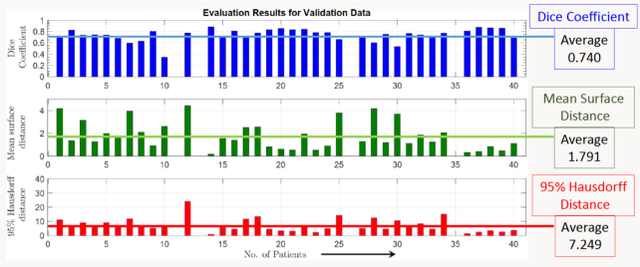
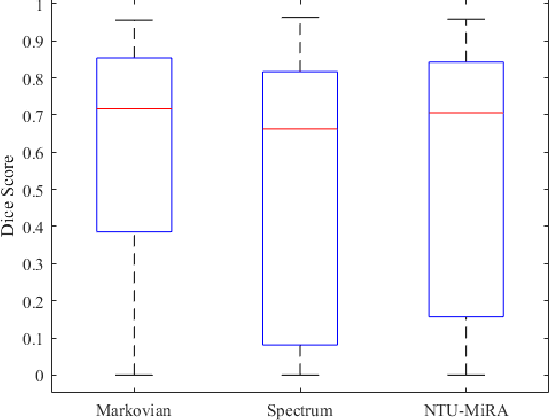
Lung cancer is one of the deadliest cancers, and in part its effective diagnosis and treatment depend on the accurate delineation of the tumor. Human-centered segmentation, which is currently the most common approach, is subject to inter-observer variability, and is also time-consuming, considering the fact that only experts are capable of providing annotations. Automatic and semi-automatic tumor segmentation methods have recently shown promising results. However, as different researchers have validated their algorithms using various datasets and performance metrics, reliably evaluating these methods is still an open challenge. The goal of the Lung-Originated Tumor Segmentation from Computed Tomography Scan (LOTUS) Benchmark created through 2018 IEEE Video and Image Processing (VIP) Cup competition, is to provide a unique dataset and pre-defined metrics, so that different researchers can develop and evaluate their methods in a unified fashion. The 2018 VIP Cup started with a global engagement from 42 countries to access the competition data. At the registration stage, there were 129 members clustered into 28 teams from 10 countries, out of which 9 teams made it to the final stage and 6 teams successfully completed all the required tasks. In a nutshell, all the algorithms proposed during the competition, are based on deep learning models combined with a false positive reduction technique. Methods developed by the three finalists show promising results in tumor segmentation, however, more effort should be put into reducing the false positive rate. This competition manuscript presents an overview of the VIP-Cup challenge, along with the proposed algorithms and results.
Organ At Risk Segmentation with Multiple Modality
Oct 17, 2019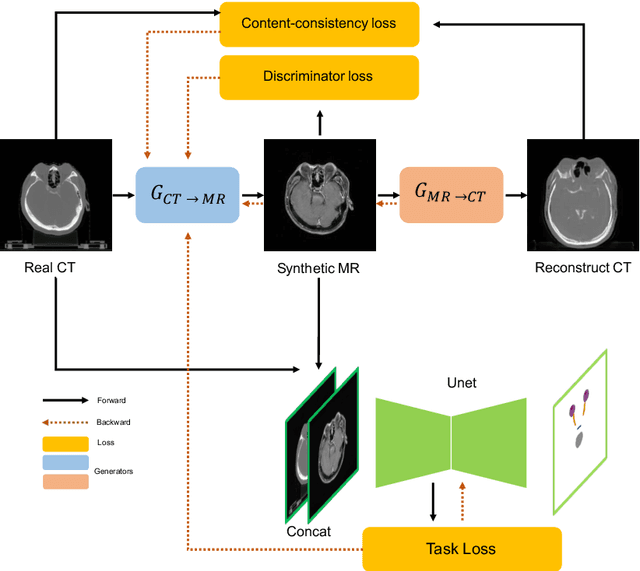

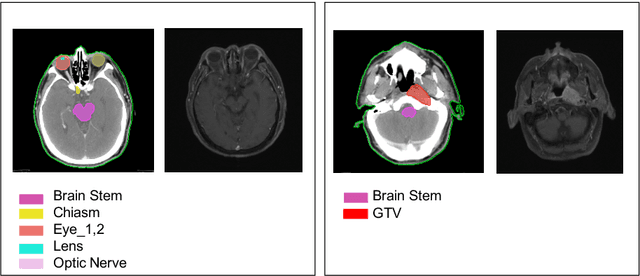
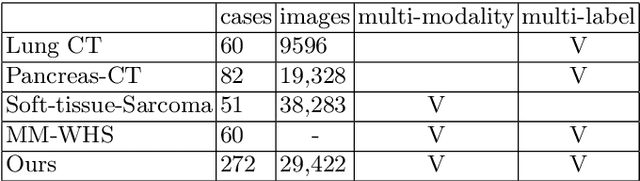
With the development of image segmentation in computer vision, biomedical image segmentation have achieved remarkable progress on brain tumor segmentation and Organ At Risk (OAR) segmentation. However, most of the research only uses single modality such as Computed Tomography (CT) scans while in real world scenario doctors often use multiple modalities to get more accurate result. To better leverage different modalities, we have collected a large dataset consists of 136 cases with CT and MR images which diagnosed with nasopharyngeal cancer. In this paper, we propose to use Generative Adversarial Network to perform CT to MR transformation to synthesize MR images instead of aligning two modalities. The synthesized MR can be jointly trained with CT to achieve better performance. In addition, we use instance segmentation model to extend the OAR segmentation task to segment both organs and tumor region. The collected dataset will be made public soon.
Learnable Gated Temporal Shift Module for Deep Video Inpainting
Jul 09, 2019
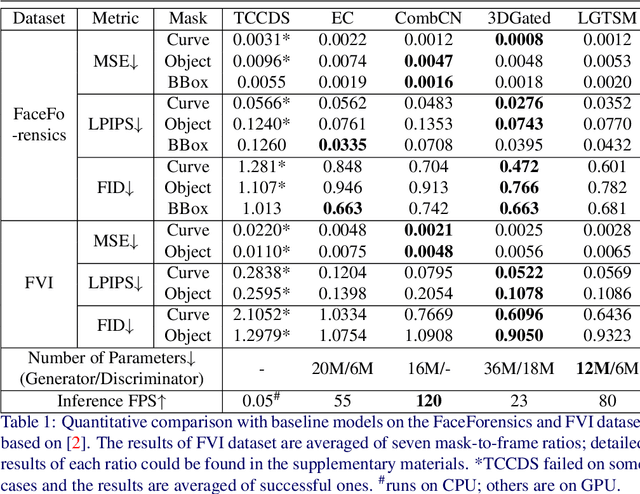
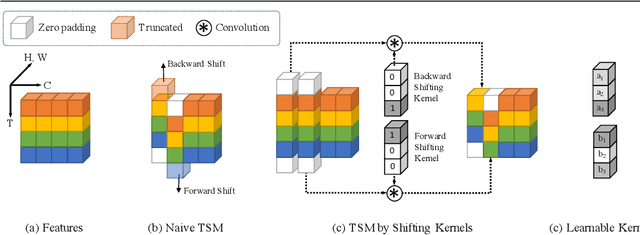
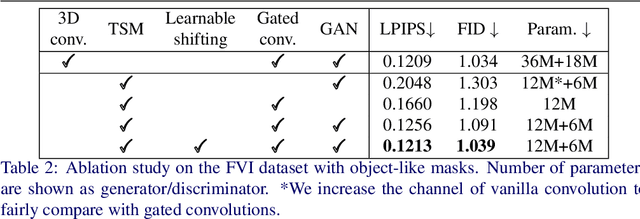
How to efficiently utilize temporal information to recover videos in a consistent way is the main issue for video inpainting problems. Conventional 2D CNNs have achieved good performance on image inpainting but often lead to temporally inconsistent results where frames will flicker when applied to videos (see https://www.youtube.com/watch?v=87Vh1HDBjD0&list=PLPoVtv-xp_dL5uckIzz1PKwNjg1yI0I94&index=1); 3D CNNs can capture temporal information but are computationally intensive and hard to train. In this paper, we present a novel component termed Learnable Gated Temporal Shift Module (LGTSM) for video inpainting models that could effectively tackle arbitrary video masks without additional parameters from 3D convolutions. LGTSM is designed to let 2D convolutions make use of neighboring frames more efficiently, which is crucial for video inpainting. Specifically, in each layer, LGTSM learns to shift some channels to its temporal neighbors so that 2D convolutions could be enhanced to handle temporal information. Meanwhile, a gated convolution is applied to the layer to identify the masked areas that are poisoning for conventional convolutions. On the FaceForensics and Free-form Video Inpainting (FVI) dataset, our model achieves state-of-the-art results with simply 33% of parameters and inference time.
Video Question Generation via Cross-Modal Self-Attention Networks Learning
Jul 05, 2019
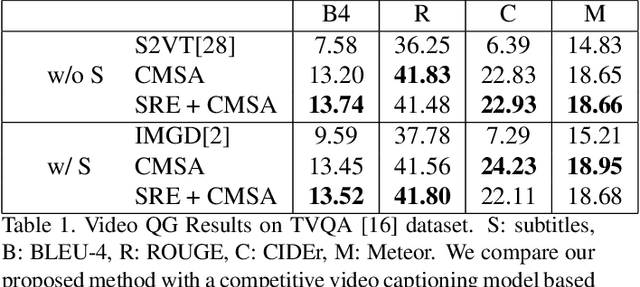
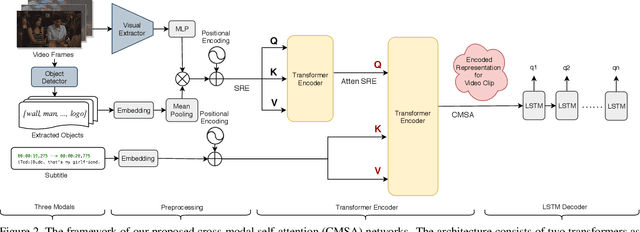
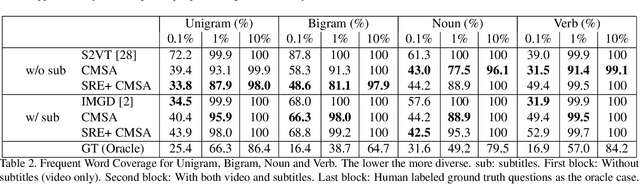
Video Question Answering (Video QA) is a critical and challenging task in multimedia comprehension. While deep learning based models are extremely capable of representing and understanding videos, these models heavily rely on massive data, which is expensive to label. In this paper, we introduce a novel task for automatically generating questions given a sequence of video frames and the corresponding subtitles from a clip of video to reduce the huge annotation cost. Learning to ask a question based on a video requires the model to comprehend the rich semantics in the scene and the interplay between the vision and the language. To address this, we propose a novel cross-modal self-attention (CMSA) network to aggregate the diverse features from video frames and subtitles. Excitingly, we demonstrate that our proposed model can improve the (strong) baseline from 0.0738 to 0.1374 in BLEU4 score -- more than 0.063 improvement (i.e., 85\% relatively). Most of all, We arguably pave a novel path toward solving the challenging Video QA task and provide detailed analysis which ushers the avenues for future investigations.
Free-form Video Inpainting with 3D Gated Convolution and Temporal PatchGAN
Apr 28, 2019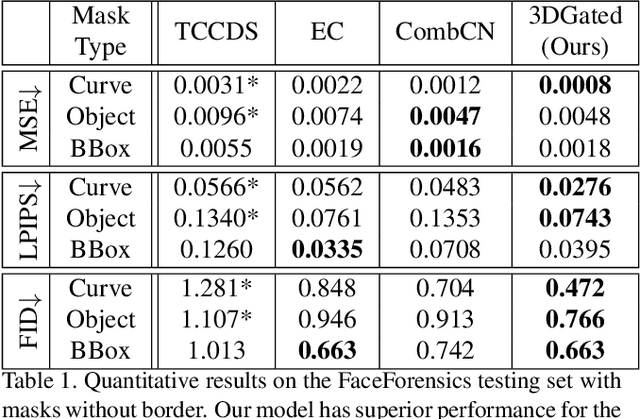
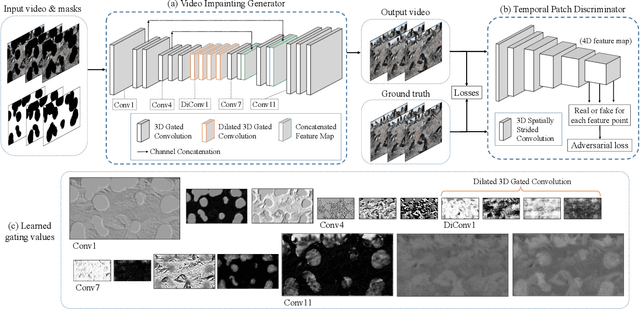
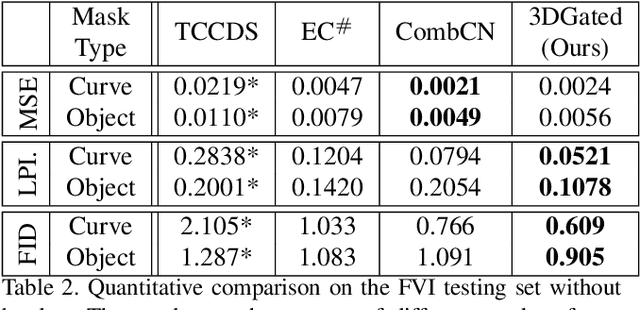
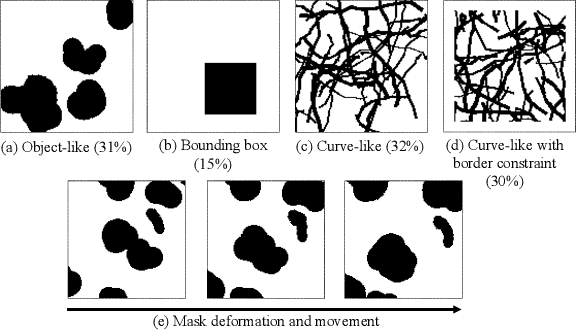
Free-form video inpainting is a very challenging task that could be widely used for video editing such as text removal. Existing patch-based methods could not handle non-repetitive structures such as faces, while directly applying image-based inpainting models to videos will result in temporal inconsistency (see http://bit.ly/2Fu1n6b). In this paper, we introduce a deep learn-ing based free-form video inpainting model, with proposed 3D gated convolutions to tackle the uncertainty of free-form masks and a novel Temporal PatchGAN loss to enhance temporal consistency. In addition, we collect videos and design a free-form mask generation algorithm to build the free-form video inpainting (FVI) dataset for training and evaluation of video inpainting models. We demonstrate the benefits of these components and experiments on both the FaceForensics and our FVI dataset suggest that our method is superior to existing ones.
FishNet: A Camera Localizer using Deep Recurrent Networks
Apr 22, 2019
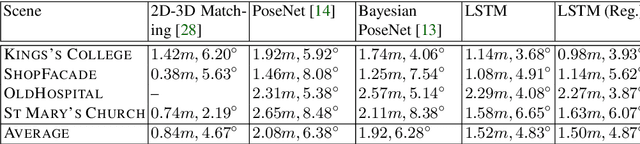
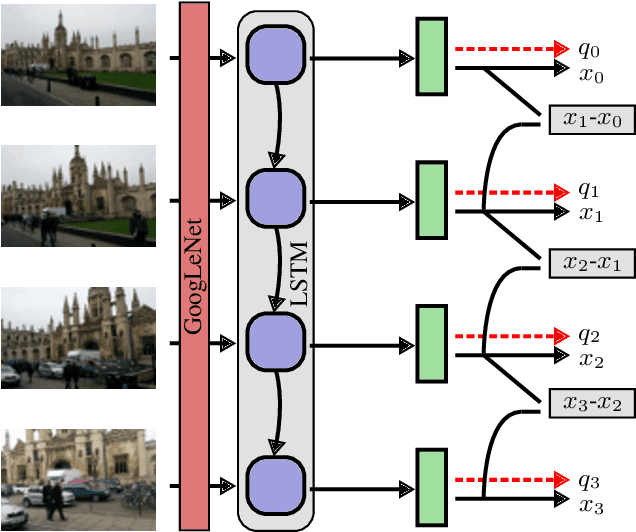
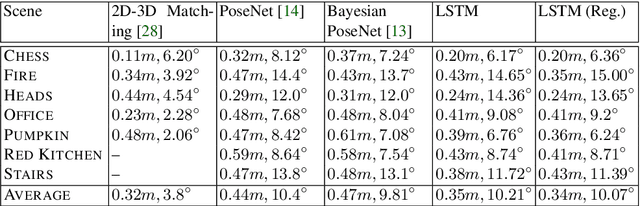
This paper proposes a robust localization system that employs deep learning for better scene representation, and enhances the accuracy of 6-DOF camera pose estimation. Inspired by the fact that global scene structure can be revealed by wide field-of-view, we leverage the large overlap of a fisheye camera between adjacent frames, and the powerful high-level feature representations of deep learning. Our main contribution is the novel network architecture that extracts both temporal and spatial information using a Recurrent Neural Network. Specifically, we propose a novel pose regularization term combined with LSTM. This leads to smoother pose estimation, especially for large outdoor scenery. Promising experimental results on three benchmark datasets manifest the effectiveness of the proposed approach.
VORNet: Spatio-temporally Consistent Video Inpainting for Object Removal
Apr 14, 2019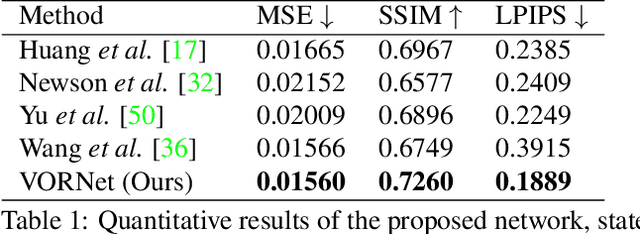
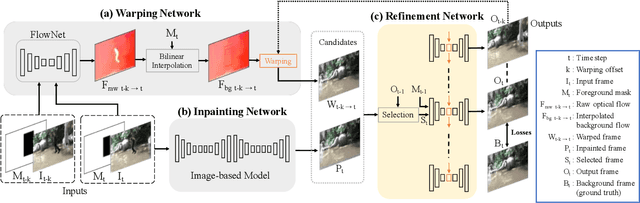
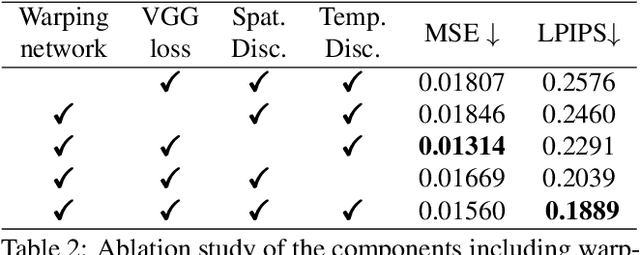
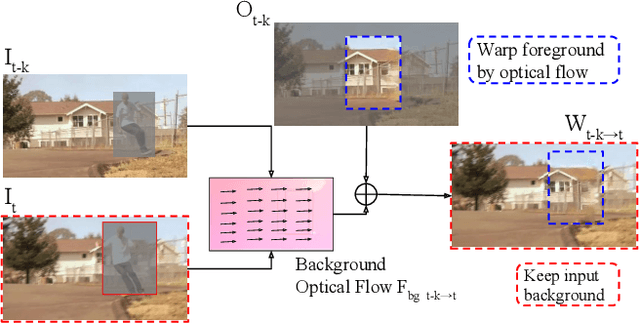
Video object removal is a challenging task in video processing that often requires massive human efforts. Given the mask of the foreground object in each frame, the goal is to complete (inpaint) the object region and generate a video without the target object. While recently deep learning based methods have achieved great success on the image inpainting task, they often lead to inconsistent results between frames when applied to videos. In this work, we propose a novel learning-based Video Object Removal Network (VORNet) to solve the video object removal task in a spatio-temporally consistent manner, by combining the optical flow warping and image-based inpainting model. Experiments are done on our Synthesized Video Object Removal (SVOR) dataset based on the YouTube-VOS video segmentation dataset, and both the objective and subjective evaluation demonstrate that our VORNet generates more spatially and temporally consistent videos compared with existing methods.